Von Monaten zu Minuten: Erstellen von Echtzeit-Pipelines für klinische Daten mit natürlicher Sprache
Databricks und Redox ermöglichen es Gesundheitsteams, Echtzeit-Pipelines für klinische Daten mithilfe von natürlicher Sprache zu erstellen, Daten mit Subsekundenlatenz in Cloud-Umgebungen zu streamen und KI-Ausgaben zurück in die EHR zu schreiben, um...
- Von Monaten zu Minuten — Das Erstellen von EHR-Datenpipelines erforderte früher wochenlange spezialisierte Integrationsarbeit. Die Partnerschaft zwischen Databricks und Redox ermöglicht es Teams, Echtzeit-Pipelines für klinische Daten mithilfe von natürlichsprachlichen Eingabeaufforderungen einzurichten, ganz ohne HL7-Experten.
- Echtzeit bedeutet tatsächlich Echtzeit — Redox's Zerobus streamt klinische Daten mit Subsekundenlatenz direkt in Databricks Unity Catalog, wodurch die zwischengeschalteten Speicherschichten eliminiert werden, die „Echtzeit“ zu „verzögert“ machen.
- Daten, die handeln, nicht nur informieren — KI-Ausgaben können in Echtzeit zurück in die EHR geschrieben werden, wodurch der Kreislauf zwischen Einblick und Intervention geschlossen wird — Databricks wird von einem Analysesystem zu einer operativen Schicht am Point of Care.
Dieser Beitrag wurde gemeinsam verfasst von Assunta Carey-Saylor (Senior Product Marketing bei Redox), Tim Kessler (Field Chief Technology Officer bei Redox) und Matt Giglia (Forward Deployed Engineer für Healthcare & Life Sciences bei Databricks)
Die meisten Datenteams im Gesundheitswesen verbringen Monate damit, Pipelines zum Verschieben von Daten aus EHR-Systemen in ihre Analyseumgebung zu erstellen und zu warten. Selbst nachdem diese Arbeit erledigt ist, werden Daten oft über zwischengeschaltete Speicherschichten geleitet, bevor sie verarbeitet werden können, was zu Latenzen führt, die Echtzeit-Anwendungsfälle einschränken.
Das Ergebnis ist ein System, das komplex zu warten und zu langsam zum Handeln ist.
Databricks und Redox haben sich zusammengetan, um dieses Modell zu ändern und zwei Kernbarrieren zu beseitigen:
- Die Komplexität der Erstellung von Datenintegrationen im Gesundheitswesen
- Die Latenz beim Abrufen von Daten in die Analyseumgebung
Jetzt können Teams Echtzeit-Pipelines für klinische Daten mit natürlichen Sprachaufforderungen direkt in Databricks einrichten, was den Zugriff und die Aktivierung von Daten vereinfacht.
TL;DR: Databricks und Redox ermöglichen es Gesundheitsteams, Echtzeit-Pipelines für klinische Daten mithilfe natürlicher Sprache zu erstellen, Daten mit Latenzzeiten von unter einer Sekunde in Cloud-Umgebungen zu streamen und KI-Ausgaben zurück in das EHR zu schreiben, um Maßnahmen am Point of Care zu ermöglichen.
Das Problem: KI-Strategie wird durch Integration + Latenz ausgebremst
Gesundheitsorganisationen stehen unter dem Druck, KI zu operationalisieren, aber die Ausführung wird durch die Integration klinischer Daten immer wieder ausgebremst.
Bevor Modelle oder Workflows bereitgestellt werden können, müssen Teams mit EHR-Systemen integrieren, Formate wie HL7, CCD und X12 normalisieren und ETL-Pipelines erstellen. Diese Arbeit ist zeitaufwendig und erfordert spezielle Fachkenntnisse.
Selbst wenn Pipelines vorhanden sind, fließen die Daten oft durch zwischengeschaltete Speicherschichten, bevor sie Databricks erreichen, was zu Latenzen und betrieblichem Mehraufwand führt. Was als „Echtzeit“ bezeichnet wird, verzögert sich, und die Engineering-Teams konzentrieren sich weiterhin auf die Infrastruktur, anstatt Erkenntnisse zu liefern.
Infolgedessen geraten KI-Initiativen ins Stocken und die Zeit bis zur Erkenntnis verlängert sich von Wochen auf Monate.
Ein neuer Ansatz
Databricks' Zerobus Ingest und der Redox MCP Server führen einen anderen Ansatz für die Erstellung und den Betrieb von Pipelines für klinische Daten in Databricks ein.
Der Redox MCP Server ermöglicht es Teams, Integrationen mithilfe natürlicher Sprache zu erstellen und zu verwalten, wodurch der Zeit- und Komplexitätsaufwand für die Erstellung neuer Datenpipelines reduziert wird. Zerobus streamt klinische Daten mit Latenzzeiten von unter einer Sekunde direkt in von Databricks Unity Catalog verwaltete Tabellen, wodurch die Notwendigkeit von zwischengeschalteten Speicherschichten oder Workflows zum Laden der Dateien für die Verarbeitung entfällt.
Gemeinsam verändern sie sowohl die Art und Weise, wie Pipelines erstellt werden, als auch die Geschwindigkeit, mit der Daten nutzbar werden. Die Integration wird durch Prompts anstelle von Code definiert, und Daten sind verfügbar, sobald sie generiert werden. Das bedeutet, dass Teams sich mit EHR-Systemen verbinden, klinische Daten streamen und Workflows direkt in Databricks aktivieren können.
So sieht das in der Praxis aus
Innerhalb der Databricks-Plattform verbindet sich ein Benutzer mit dem Redox MCP Server und beginnt mit einer Eingabeaufforderung. Innerhalb weniger Interaktionen:
- Das System identifiziert verfügbare Umgebungen und Datensätze
- Schlägt nächste Schritte zur Vervollständigung des Workflows vor
- Führt Integrationsaufgaben systemübergreifend aus
- Zeigt Validierungssignale wie Protokolle und Leistungszusammenfassungen an
Im Hintergrund übernimmt Zerobus die direkte Übertragung von Streaming-Daten in Databricks und eliminiert die Notwendigkeit von Staging-Schichten oder Batch-Ingestion. Dies ermöglicht es jedem Schritt des Workflows, mit Live-Daten zu arbeiten, sobald diese eintreffen.
In einem Beispiel rief das System eine aktuelle Patientenaufnahme ab und gab sowohl strukturierte Daten als auch eine Zusammenfassung in einfacher Sprache zurück. Komplexe klinische Daten wurden sofort für nachgelagerte Analysen und Entscheidungen nutzbar.
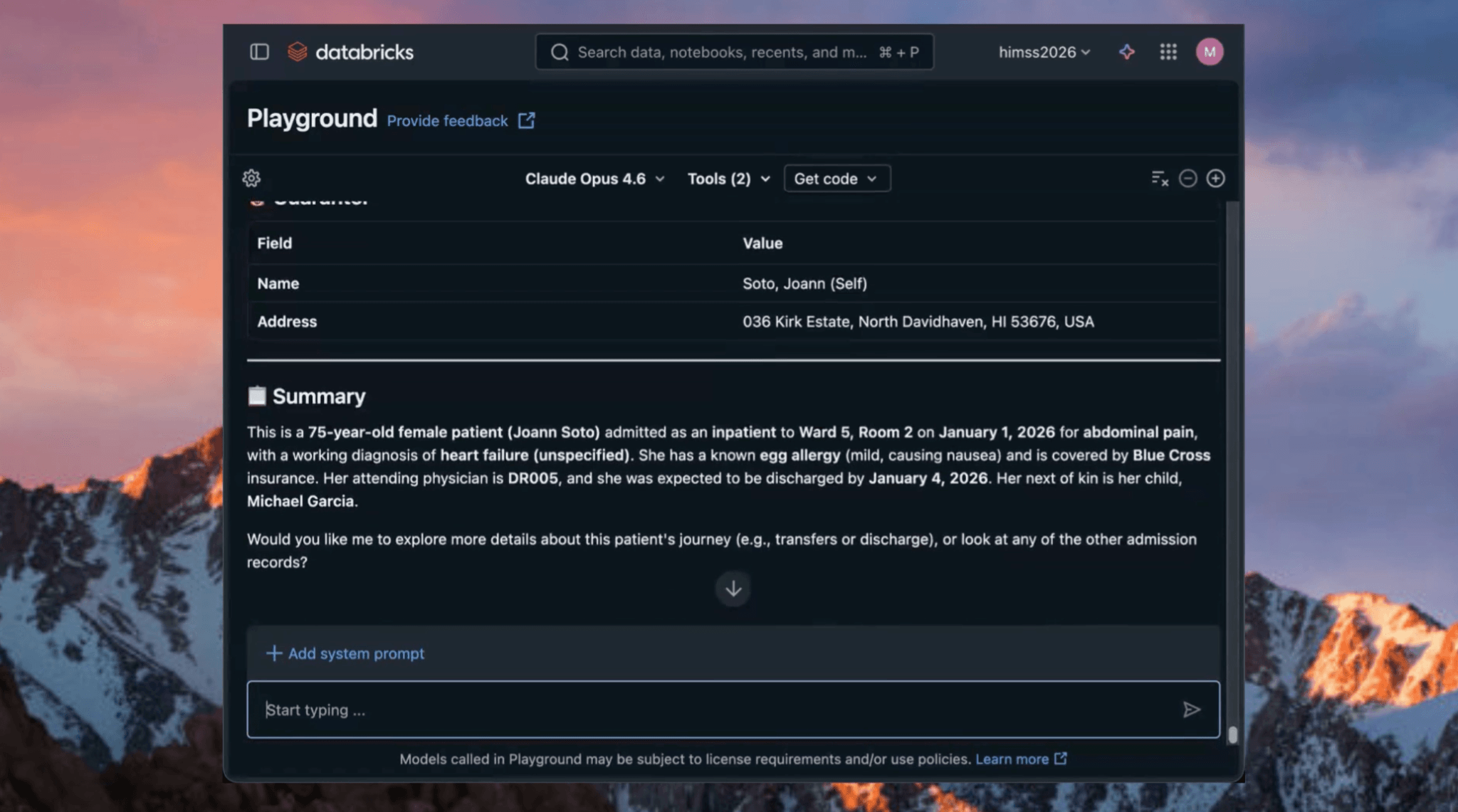
Abbildung 1. Das System fasste eine aktuelle Patientenaufnahme in einfacher Sprache zusammen.
Von Monaten zu Minuten: Beschleunigung der Time-to-Insight
Was zuvor Wochen oder Monate an Integrationsarbeit erforderte, kann jetzt in wenigen Minuten mit natürlicher Sprache initiiert werden, ohne Databricks verlassen zu müssen.
Durch die Eliminierung von zwischengeschalteten Datenspeicherschritten mit Zerobus und die Vereinfachung der Pipeline-Erstellung durch natürliche Sprachaufforderungen können Organisationen sowohl die Latenz als auch die Entwicklungszeit drastisch reduzieren. Dies ermöglicht es Teams, KI-Anwendungsfälle schneller zu validieren, Entwicklungszyklen zu verkürzen und schneller von der Experimentierphase zur Produktion zu gelangen.
Die Integration ist nicht länger der limitierende Faktor, und die Datenlatenz ist nicht länger die einschränkende Beschränkung.
Reduzierung der Abhängigkeit von spezialisierter Expertise
Die Integration im Gesundheitswesen erforderte traditionell tiefgreifende Kenntnisse in HL7, APIs und Datenorchestrierung.
Mit dem Redox MCP Server wird ein Großteil dieser Komplexität abstrahiert. Organisationen können ihre Abhängigkeit von HL7-Experten und Integrationsspezialisten reduzieren, wodurch breitere Teams mit klinischen Daten arbeiten können.
Datenwissenschaftler und ML-Ingenieure können sich auf die Erstellung von Modellen und die Generierung von Erkenntnissen konzentrieren, anstatt ETL-Pipelines zu verwalten. Engineering-Teams können von der Wartung von Integrationen zur Ermöglichung neuer Funktionen übergehen.
Der Fokus verschiebt sich von „Wie bekommen wir die Daten?“ zu „Wie nutzen wir die Daten?“.
Ermöglichung von Echtzeit-Klinik-Intelligenz
Mit Zerobus treffen klinische Daten mit Latenzzeiten von unter einer Sekunde in Databricks ein, ohne zwischengeschaltete Speicherschichten oder Batch-Verarbeitung. Dies ermöglicht es, FHIR so zu behandeln, wie es immer gedacht war – als transaktional und an REST-API-Endpunkte gesendet. Beispielsweise kann ein Krankenversicherer oder eine Anbieterorganisation priorisierungsautorisierungsbezogene Bundles über Redox direkt an einen dedizierten REST-API-Endpunkt senden, wo sie in Databricks benötigt werden, anstatt zuerst in einem FHIR-Speicher oder als substanziiertes FHIR-JSON-Datei zu landen.
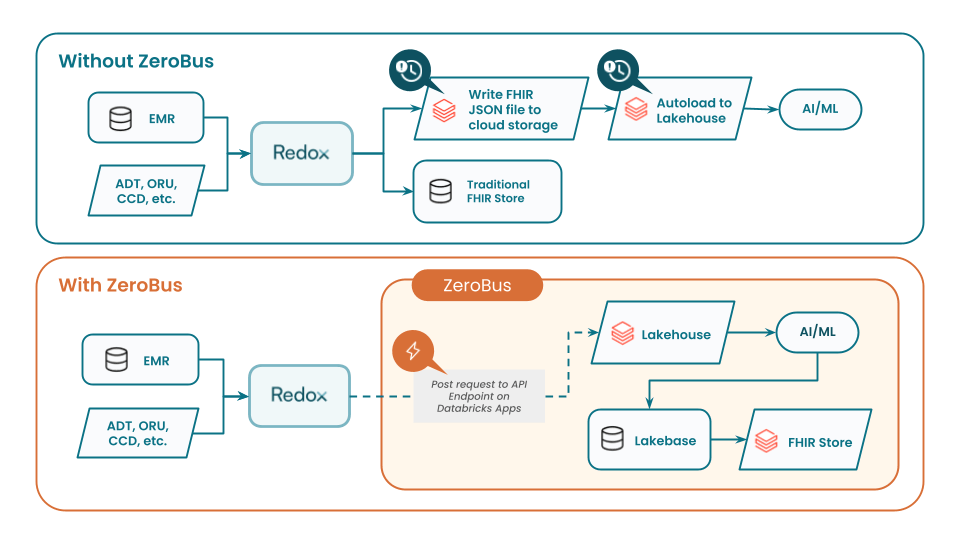
Dies ermöglicht ML- und KI-Agenten-Frameworks, Anfragen und Antworten zur Priorisierungsautorisierung sofort zu verarbeiten. Indem die Notwendigkeit zusätzlicher Datenabrufe oder der komplexen ETL zur Analyse von rohen FHIR-JSON-Dateien umgangen wird, können diese Systeme den Patientenpfad erfassen und darauf reagieren, während er sich entfaltet, nicht erst im Nachhinein.
In Verbindung mit den Redox EHR-Schreibback-Funktionen können diese Erkenntnisse direkt in klinische Workflows integriert werden. KI-generierte Ausgaben können in Echtzeit in das EHR zurückgeschrieben werden, wodurch der Kreislauf zwischen Daten, Intelligenz und Aktion am Point of Care geschlossen wird. Dies erweitert Databricks von einem reinen Analysesystem zu einer Anwendungsschicht für den Betrieb im Gesundheitswesen, in der Datenpipelines und KI-Modelle nicht nur Entscheidungen informieren, sondern aktiv Interventionen innerhalb zentraler klinischer Systeme steuern.
Dies eröffnet eine neue Klasse von Echtzeit-Anwendungsfällen:
Patientenzustand in Echtzeit verfolgen
Kontinuierliche Aktualisierung von Aufnahmen, Verlegungen, Entlassungen und klinischen Ereignissen, sobald sie eintretenKapazitäten optimieren, wenn sich Bedingungen ändern
Nutzung von Live-Patientenbewegungs- und Zensussignalen zur Verbesserung des Bettenmanagements, der Personalplanung und des DurchsatzesInterventionen zum richtigen Zeitpunkt auslösen
Einbindung von Patienten, Pflegeteams oder Systemen basierend auf Live-Kliniksignalen anstelle von verzögerten BerichtenRisiken erkennen, wenn sie auftreten
Identifizierung von Verschlechterungen, Versorgungslücken oder betrieblichen Engpässen, solange noch Zeit zum Reagieren bleibt
Entlassungs- und Versorgungspfade dynamisch anpassen
Nächste Schritte basierend auf dem aktuellen Patientenzustand statt auf statischen Momentaufnahmen anpassen
Klinische und finanzielle Arbeitsabläufe synchronisieren
Ereignisse bei ihrem Eintreten erfassen, um die Genauigkeit von Kodierung, Abrechnung und Umsatzzyklus zu verbessern
Jetzt können Gesundheitsorganisationen mit größerer Agilität und Reaktionsfähigkeit agieren und ihre Daten-Workflows an das Tempo der Patientenversorgung anpassen.
Warum das funktioniert: Eine vertrauenswürdige Grundlage, auf der KI aufbauen kann
Diese Funktion hängt von einer zuverlässigen, standardisierten klinischen Datenbasis ab. Redox bietet die standardisierte Ebene für den Datenaustausch zwischen EHRs und anderen nachgelagerten Systemen über eine einzige Plattform und API.
Zerobus stellt sicher, dass diese Daten ohne Verzögerung in Databricks ankommen. Der Redox MCP Server macht diese Daten durch natürliche Sprache zugänglich und nutzbar, indem er Absichten in Ausführungen übersetzt und gleichzeitig unternehmensweite Sicherheits-, Compliance- und Betriebskontrollen durchsetzt.
Zusammen bilden sie eine Echtzeit-Ausführungsebene für klinische Daten und KI-Workflows.
Mehr als nur Pipelines: Aufbau des „Redox Agent“
Und wir hören nicht bei der Datenerfassung auf. Da der Redox MCP Server neben Databricks Genie Spaces auf den klinischen Daten liegt, können KI-Teams jetzt Redox Agents auf Databricks aufbauen.
Diese spezialisierten Agenten sind in der Lage:
- Redox-Plattformprotokolle überprüfen, um Datenflüsse in Echtzeit zu beheben oder zu auditieren.
- Fragen zu den von Redox gesendeten klinischen Daten in natürlicher Sprache beantworten.
- Intelligenz direkt in klinische Anwendungen einbetten und dabei die strenge Governance, Sicherheit und Nachverfolgbarkeit beibehalten, die das unternehmensweite Gesundheitswesen erfordert.
Durch die Kombination der Leistungsfähigkeit von Redox MCP und Genie können Teams von der reinen Datenübertragung zur Erstellung von konversationellen, intelligenten Schnittstellen übergehen, die direkt in den bestehenden Workflow des Anbieters integriert sind.
Sehen Sie es in Aktion
In einem bevorstehenden Webinar von Redox und Databricks am 30. April werden wir demonstrieren, wie Zerobus und der MCP Server zusammenarbeiten, um Echtzeit-Datenpipelines in Databricks bereitzustellen.
Sie werden sehen, wie Teams mit natürlicher Sprache von der Absicht zur Ausführung gelangen und dabei Daten mit subsekündiger Latenz verarbeiten.
Hier registrieren, um zu erfahren, wie dieser Ansatz für Ihre Organisation gilt.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.