Multimodale Datenintegration: Produktionsarchitekturen für KI im Gesundheitswesen
Die meisten multimodalen Healthcare-KI-Bemühungen scheitern vor der Produktion. Hier ist ein praktischer Blueprint, um Genomik, Bildgebung, klinische Notizen und Wearables mit Governance, Pipelines und Fusionsstrategien zu vereinheitlichen, die...
von Maks Khomutskyi
- Erstellen Sie ein gesteuertes multimodales Fundament: Erfassen Sie Genomik-, Bildgebungsmerkmale, klinische Notizen-Entitäten und Wearables-Streams in Delta mit Unity Catalog-Zugriffskontrollen, Audits, Lineage und gesteuerten Tags.
- Wählen Sie eine Fusion, die der Produktionsrealität standhält: Verwenden Sie Early/Intermediate/Late/Attention-basierte Fusion basierend auf Modalitätsverfügbarkeit, Dimensionalität und Zeit – entwickelt für fehlende Modalitäten, nicht für perfekte Kohorten.
- Operationalisieren Sie End-to-End: Verwenden Sie Lakeflow SDP für Streaming + Feature-Fenster, Vektorsuche für Ähnlichkeit/Kohortenbildung und reproduzierbare Pipelines (Versioning/Zeitreisen + CI/CD + MLflow), um von POC zur Produktion zu gelangen.
Die wertvollsten KI-Anwendungsfälle im Gesundheitswesen leben selten in einem einzigen Datensatz. Multimodale Datenintegration – die Kombination von Genomik, Bildgebung, klinischen Notizen und Wearables – ist für die Präzisionsonkologie und Früherkennung unerlässlich, doch viele Initiativen scheitern vor der Produktion.
Die Präzisionsonkologie erfordert das Verständnis sowohl molekularer Treiber aus der genomischen Profilierung als auch des anatomischen Kontexts aus der Bildgebung. Die Früherkennung verbessert sich, wenn erbliche Risikosignale auf Längsschnitt-Wearables treffen. Und viele der „Warum“-Details – Symptome, Reaktionen, Begründungen – leben immer noch in klinischen Notizen.
Trotz echter Fortschritte in der Forschung scheitern viele multimodale Initiativen vor der Produktion – nicht weil die Modellierung unmöglich ist, sondern weil die Daten und das Betriebsmodell nicht für die klinische Realität bereit sind. Die Einschränkung ist nicht die Modellkomplexität, sondern die Architektur: separate Stacks pro Modalität schaffen fragile Pipelines, duplizierte Governance und kostspielige Datenbewegungen, die unter den Anforderungen der klinischen Bereitstellung zusammenbrechen.
Dieser Beitrag beschreibt ein produktionsorientiertes Lakehouse-Muster für multimodale Präzisionsmedizin: wie jede Modalität in verwaltete Delta-Tabellen geladen wird, modalitätsübergreifende Merkmale erstellt werden und Fusionsstrategien ausgewählt werden, die reale fehlende Daten überstehen.
Referenzarchitektur
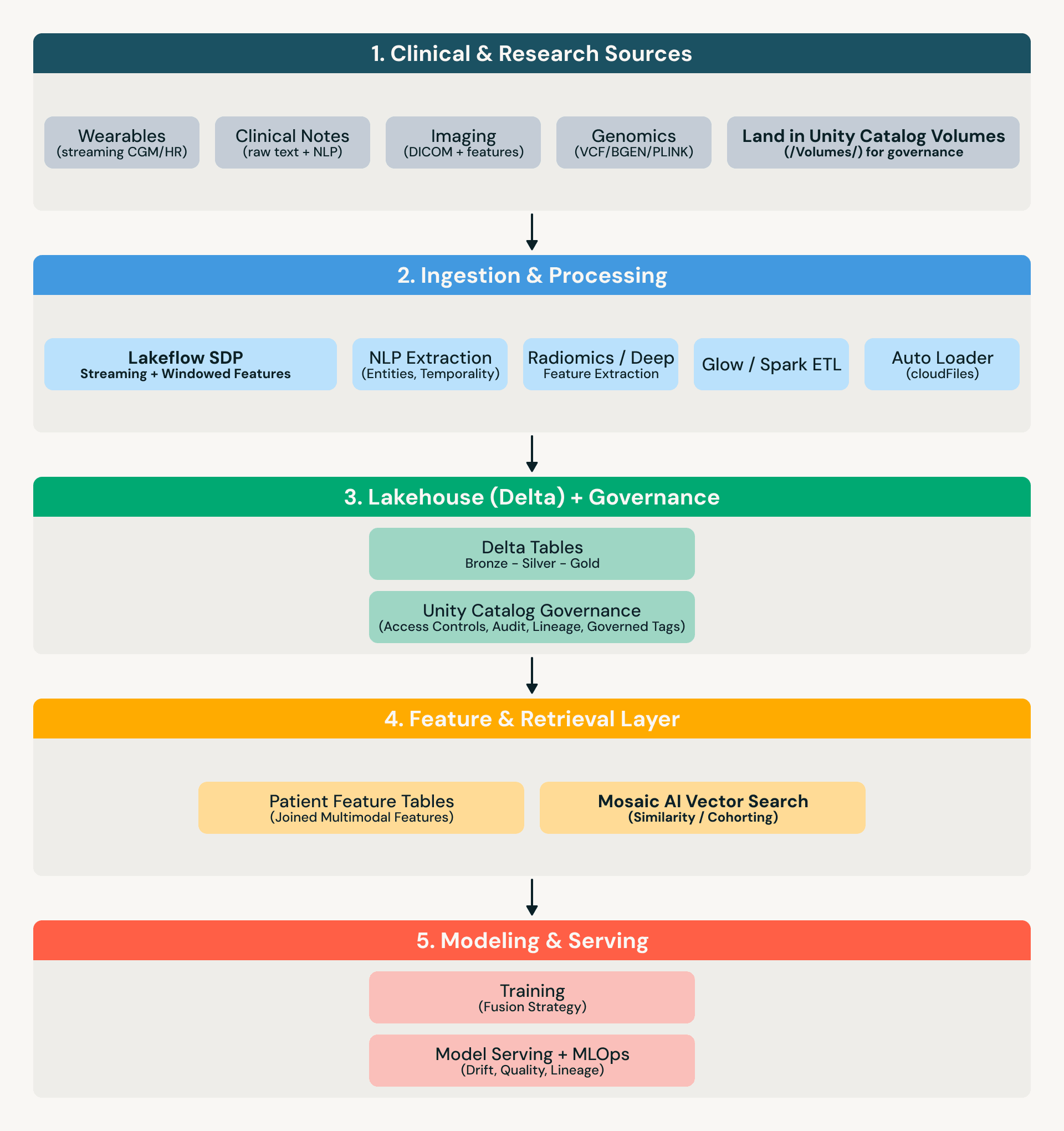
Was „verwaltet“ in der Praxis bedeutet
Im gesamten Beitrag bedeutet „verwaltete Tabellen“, dass die Daten mit Unity Catalog (oder gleichwertigen Kontrollen) gesichert und operationalisiert werden, einschließlich:
Datenklassifizierung mit verwalteten Tags: PHI/PII/28 CFR Part 202/StudyID/…
- Feingranulare Zugriffskontrollen: Berechtigungen für Katalog/Schema/Tabelle/Volume, plus Zeilen-/Spalten-Level-Kontrollen, wo für PHI erforderlich.
- Auditierbarkeit: wer hat wann auf was zugegriffen (entscheidend für regulierte Umgebungen).
- Abstammung: Merkmale und Modelleingaben bis zu den Quelldatensätzen zurückverfolgen.
- Kontrollierte gemeinsame Nutzung: konsistente Richtliniengrenzen über Teams und Tools hinweg.
Reproduzierbarkeit: Versionierung und Zeitreise für Datensätze, CI/CD für Pipelines/Jobs und MLflow für die Verfolgung von Experimenten und Modellversionen.
Dies verbindet die technische Architektur mit Geschäftsergebnissen: weniger Kopien sensibler Daten, reproduzierbare Analysen und schnellere Genehmigungen für die Produktion.
Warum multimodal zum Standard wird
Modelle mit einzelnen Modalitäten stoßen in unübersichtlichen klinischen Umgebungen an reale Grenzen. Bildgebung kann leistungsfähig sein, aber viele komplexe Vorhersagen profitieren von molekularem + longitudinalem Kontext. Genomik erfasst Treiber, aber nicht Phänotyp, Umwelt oder tägliche Physiologie. Notizen und Wearables fügen die „Zwischen den Zeilen“-Signale hinzu, die strukturierte Daten oft vermissen lassen.
Volumenrealität zählt: Databricks-Notizen besagen, dass etwa 80 % der medizinischen Daten unstrukturiert sind (z. B. Text und Bilder). Deshalb muss die multimodale Datenintegration unstrukturierte Notizen und Bilder in großem Maßstab verarbeiten – nicht nur strukturierte EHR-Felder.
Die praktische Schlussfolgerung: Jede Modalität ist für sich allein unvollständig. Multimodale Systeme funktionieren, wenn sie so konzipiert sind, dass sie:
- Modalspezifische Signale erhalten.
- Robust bleiben, wenn einige Eingaben fehlen.
Vier Fusionsstrategien (und wann jede Produktion übersteht)
Die Wahl der Fusion ist selten der einzige Grund für das Scheitern von Teams – aber sie erklärt oft, warum Piloten nicht übersetzt werden: Daten sind spärlich, Modalitäten kommen zu unterschiedlichen Zeiten an und die Governance-Anforderungen unterscheiden sich je nach Datentyp.
1) Frühe Fusion (Rohe Eingaben vor dem Training verketten.)
- Verwenden, wenn: kleine, eng kontrollierte Kohorten mit konsistenter Modalitätsverfügbarkeit.
- Kompromiss: Skaliert schlecht mit hochdimensionaler Genomik und großen Merkmalsmengen.
2) Zwischenfusion (Jede Modalität separat kodieren, dann versteckte Darstellungen zusammenführen.)
- Verwenden, wenn: Kombination von hochdimensionaler Omics mit niedrigdimensionalen EHR/klinischen Merkmalen.
- Kompromiss: Erfordert sorgfältiges Repräsentationslernen pro Modalität und disziplinierte Auswertung.
3) Späte Fusion (Pro-Modalitäts-Modelle trainieren, dann Vorhersagen kombinieren.)
- Verwenden, wenn: Produktions-Rollouts, bei denen fehlende Modalitäten häufig vorkommen.
- Vorteil: Verschlechtert sich anmutig, wenn eine oder mehrere Modalitäten fehlen.
4) Aufmerksamkeitsbasierte Fusion (Dynamische Gewichtung über Modalitäten und Zeit lernen.)
- Verwenden, wenn: Zeit wichtig ist (Wearables + Längsschnittnotizen, wiederholte Bildgebung) und Interaktionen komplex sind.
- Kompromiss: schwieriger zu validieren; erfordert sorgfältige Kontrollen, um Scheinkorrelationen zu vermeiden.
Entscheidungsrahmen: Passen Sie die Fusion an Ihre Bereitstellungsrealität an: Muster der Modalitätsverfügbarkeit, Dimensionalitätsbalance und zeitliche Dynamik.
Das Lakehouse als multimodales Substrat
Ein Lakehouse-Ansatz reduziert die Datenbewegung über Modalitäten hinweg: Genomik-Tabellen, Bildgebungsmetadaten/-merkmale, textbasierte Entitäten und Streaming-Wearables können an einem Ort verwaltet und abgefragt werden – ohne Pipelines für jedes Team neu erstellen zu müssen.
Genomik-Verarbeitung (Glow + Delta)
Glow ermöglicht die verteilte Genomik-Verarbeitung auf Spark über gängige Formate (z. B. VCF/BGEN/PLINK), wobei abgeleitete Ausgaben als Delta-Tabellen gespeichert werden, die mit klinischen Merkmalen verknüpft werden können.
Bildgebungsähnlichkeit (abgeleitete Merkmale + Vektorsuche)
Für die Bildgebung lautet das Muster: (1) Merkmale/Einbettungen vorgelagert ableiten (Radiomics oder Deep-Model-Ausgaben), (2) Merkmale als verwaltete Delta-Tabellen speichern (gesichert durch Unity Catalog) und (3) Vektorsuche für Ähnlichkeitsabfragen verwenden (z. B. „ähnliche Phänotypen innerhalb von Glioblastomen finden“).
Dies ermöglicht die Kohortenerkennung und retrospektive Vergleiche, ohne Daten in separate Systeme exportieren zu müssen.
Klinische Notizen (NLP zu verwalteten Merkmalen)
Notizen enthalten oft fehlenden Kontext – Zeitpläne, Symptome, Reaktionen, Begründungen. Ein praktischer Ansatz ist, Entitäten + Temporalität in Tabellen zu extrahieren (Medikamentenänderungen, Symptome, Verfahren, Familiengeschichte, Zeitpläne), Rohtext unter strenger Verwaltung zu belassen (Unity Catalog + Zugriffskontrollen) und aus Notizen abgeleitete Merkmale für Modellierung und Kohortenbildung mit Bildgebung und Omics zu verknüpfen.
Wearables-Daten (Lakeflow SDP für Streaming + Merkmalsfenster)
Wearables-Streams führen operative Anforderungen ein: Schemaentwicklung, spät ankommende Ereignisse und kontinuierliche Aggregation. Lakeflow Spark Declarative Pipelines (SDP) bietet ein robustes Ingestion-to-Features-Muster für Streaming-Tabellen und materialisierte Ansichten. Zur besseren Lesbarkeit beziehen wir uns unten auf Lakeflow SDP.
Syntaxhinweis: Das Modul pyspark.pipelines (importiert als dp) mit den Dekoratoren @dp.table und @dp.materialized_view folgt der aktuellen Databricks Lakeflow SDP Python-Semantik.
Warum das einheitliche Speicher- + Governance-Modell wichtig ist
Der operative Gewinn ist Kohärenz:
Ein häufiges Fehlerverhalten bei Cloud-Bereitstellungen ist ein Ansatz mit „spezialisiertem Speicher pro Modalität“ (z. B. ein FHIR-Speicher, ein separater Omics-Speicher, ein separater Bildgebungs-Speicher und ein separater Feature- oder Vektorspeicher). In der Praxis bedeutet dies oft duplizierte Governance und brüchige Cross-Store-Pipelines – was die Operationalisierung von Abstammung, Reproduzierbarkeit und multimodalen Joins erschwert.
- Reproduzierbarkeit: ACID + Zeitreise für konsistente Trainingsdatensätze und Neuanalysen.
- Auditierbarkeit: Zugriffsprotokolle + Lineage (welche Daten haben welches Feature/Modell erzeugt).
- Sicherheit: konsistente Richtliniengrenzen über Modalitäten hinweg (PHI-sicher-by-design).
- Geschwindigkeit: weniger Übergaben und weniger Datenkopien zwischen Teams.
Das ist es, was einen multimodalen Prototyp in etwas verwandelt, das Sie in der Produktion ausführen, überwachen und verteidigen können.
Das Problem der fehlenden Modalität lösen
Reale Einsätze konfrontieren unvollständige Daten. Nicht alle Patienten erhalten ein umfassendes genomisches Profiling. Bildgebungsstudien sind möglicherweise nicht verfügbar. Wearables existieren nur für eingeschriebene Populationen. Fehlende Daten sind kein Ausnahmefall – sie sind der Standard.
Produktionsdesigns sollten von Sparsity ausgehen und dafür planen:
- Modalitätsmaskierung während des Trainings: Eingaben während der Entwicklung entfernen, um die Realität des Einsatzes zu simulieren.
- Sparse Attention / Modalitäts-bewusste Modelle: lernen, das zu nutzen, was verfügbar ist, ohne sich zu sehr auf eine einzelne Modalität zu verlassen.
- Transfer-Learning-Strategien: auf reichhaltigeren Kohorten trainieren und mit sorgfältiger Validierung an spärlichen klinischen Populationen anpassen.
Schlüsselerkenntnis: Architekturen, die von vollständigen Daten ausgehen, scheitern in der Produktion. Architekturen, die für Sparsity entwickelt wurden, generalisieren.
Präzisionsonkologie-Muster: von der Architektur bis zum klinischen Workflow
Ein praktisches Muster für die Präzisionsonkologie sieht so aus:
- Genomisches Profiling -> verwaltete molekulare Tabellen (Unity Catalog). Speichern Sie Varianten, Biomarker und Annotationen als abfragbare Tabellen mit Lineage und kontrolliertem Zugriff.
- Aus Bildgebungsdaten abgeleitete Features -> Ähnlichkeit + Kohortenbildung. Indexieren Sie Feature-Vektoren aus Bildgebungsdaten für „ähnliche Fälle finden“ und Phänotyp-Genotyp-Korrelationen.
- Aus Notizen abgeleitete Zeitachsen -> Förderfähigkeit + Kontext. Extrahieren Sie zeitlich bewusste Entitäten, um die Screening von Studien und ein konsistentes longitudinales Verständnis zu unterstützen.
- Support-Layer für Tumorboards (Human-in-the-Loop). Kombinieren Sie multimodale Evidenz zu einer konsistenten Übersicht mit Herkunftsnachweis. Ziel ist es nicht, Entscheidungen zu automatisieren – es geht darum, die Zykluszeit zu verkürzen und die Konsistenz bei der Evidenzsammlung zu verbessern.
Geschäftsauswirkungen: Was sich ändert, wenn Multimodalität operativ wird
Marktwachstum ist ein Grund, warum dies wichtig ist – aber der unmittelbare Treiber ist operativer Natur:
- Schnellere Kohortenbildung und Neu-Analyse, wenn neue Modalitäten hinzukommen.
- Weniger Datenkopien und weniger einmalige Pipelines.
- Kürzere Iterationszyklen (Wochen statt Monate) für translationale Workflows.
Die Analyse von Patientenähnlichkeiten kann auch praktische „N-of-1“-Argumentationen ermöglichen, indem historische Übereinstimmungen mit ähnlichen multimodalen Profilen identifiziert werden – besonders wertvoll bei seltenen Krankheiten und heterogenen onkologischen Populationen.
Erste Schritte: eine pragmatische erste 30-Tage-Planung
- Wählen Sie eine klinische Entscheidung (z. B. Trial-Matching, Risikostratifizierung) und definieren Sie Erfolgsmetriken.
- Inventarisieren Sie Modalitäten + fehlende Daten (wer hat Genomik? Bildgebung? Längsschnitt-Wearables?).
- Richten Sie verwaltete Bronze/Silver/Gold-Tabellen ein, die über Unity Catalog gesichert sind.
- Wählen Sie eine Fusions-Baseline, die fehlende Daten toleriert (Late Fusion ist oft ein sicherer Start).
- Operationalisieren: Lineage, Datenqualitätsprüfungen, Drift-Monitoring, reproduzierbare Trainingsdatensätze.
- Planen Sie die Validierung: Evaluationskohorten, Bias-Checks, Checkpoints für klinische Workflows.
Schlüsselwörter: multimodale KI, Präzisionsmedizin, Genomik-Verarbeitung, medizinische Bildgebung KI, Integration von Gesundheitsdaten, Fusionsstrategien, Lakehouse-Architektur
Hohe Priorität
Unity Catalog: https://www.databricks.com/product/unity-catalog
Gesundheits- und Biowissenschaften: https://www.databricks.com/solutions/industries/healthcare-and-life-sciences
Data Intelligence Platform für Gesundheits- und Biowissenschaften: https://www.databricks.com/resources/guide/data-intelligence-platform-for-healthcare-and-life-sciences
Mittlere Priorität
Databricks AI Search Dokumentation: https://docs.databricks.com/en/generative-ai/vector-search.html
Delta Lake auf Databricks: https://www.databricks.com/product/delta-lake-on-databricks
Data Lakehouse (Glossar): https://www.databricks.com/glossary/data-lakehouse
Zusätzliche verwandte Blogs
Vereinen Sie die Daten Ihres Patienten mit Multi-Modal RAG: https://www.databricks.com/blog/unite-your-patients-data-multi-modal-rag
Transformation des Omics-Datenmanagements auf der Databricks Data Intelligence Platform: https://www.databricks.com/blog/transforming-omics-data-management-databricks-data-intelligence-platform
Einführung von Glow (Genomics): https://www.databricks.com/blog/2019/10/18/introducing-glow-an-open-source-toolkit-for-large-scale-genomic-analysis.html
Verarbeitung von DICOM-Bildern im großen Maßstab mit databricks.pixels: https://www.databricks.com/blog/2023/03/16/building-lakehouse-healthcare-and-life-sciences-processing-dicom-images.html
Healthcare and Life Sciences Solution Accelerators: https://www.databricks.com/solutions/accelerators
Sind Sie bereit, multimodale KI im Gesundheitswesen von Pilotprojekten zur Produktion zu bringen? Entdecken Sie Databricks-Ressourcen für HLS-Architekturen, Governance mit Unity Catalog und End-to-End-Implementierungsmuster.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.