Bestehen des Security Vibe Checks: Die Gefahren des Vibe Codings
von Neil Archibald und Caelin Kaplan
- Vibe-Coding kann zu kritischen Schwachstellen führen, wie z. B. beliebige Codeausführung und Speicherbeschädigung, selbst wenn der generierte Code funktionsfähig erscheint.
- Prompting-Techniken wie Selbstreflexion, sprachspezifische Prompts und allgemeine Sicherheitshinweise reduzieren die Generierung unsicherem Codes erheblich.
- Große Tests mit Benchmarks wie Secure Coding und HumanEval zeigen, dass Security Prompting die Code-Sicherheit bei minimalen Qualitätseinbußen verbessert.
Einleitung
Bei Databricks untersucht unser KI-Red-Team regelmäßig, wie neue Softwareparadigmen unerwartete Sicherheitsrisiken mit sich bringen können. Ein aktueller Trend, den wir genau beobachten, ist das „Vibe Coding“ – die lockere, schnelle Nutzung von generativer KI zum Erstellen von Code. Während dieser Ansatz die Entwicklung beschleunigt, haben wir festgestellt, dass er auch subtile, gefährliche Schwachstellen einführen kann, die unbemerkt bleiben, bis es zu spät ist.
In diesem Beitrag untersuchen wir einige reale Beispiele aus unseren Red-Team-Bemühungen und zeigen, wie Vibe Coding zu ernsthaften Schwachstellen führen kann. Wir demonstrieren auch einige Methoden für Prompting-Praktiken, die helfen können, diese Risiken zu mindern.
Vibe Coding geht schief: Multiplayer-Gaming
In einem unserer ersten Experimente zur Untersuchung von Vibe-Coding-Risiken haben wir Claude damit beauftragt, eine Third-Person-Snake-Kampfarene zu erstellen, in der Benutzer die Schlange aus der Vogelperspektive mit der Maus steuern. Im Einklang mit der Vibe-Coding-Methodik haben wir dem Modell erhebliche Kontrolle über die Projektarchitektur gegeben und es schrittweise aufgefordert, jede Komponente zu generieren. Obwohl die resultierende Anwendung wie beabsichtigt funktionierte, führte dieser Prozess unbeabsichtigt eine kritische Sicherheitslücke ein, die, wenn sie unkontrolliert bleibt, zur Ausführung beliebigen Codes hätte führen können.
Die Schwachstelle
Die Netzwerkschicht des Snake-Spiels überträgt Python-Objekte, die mit pickle serialisiert und deserialisiert werden, einem Modul, das bekanntermaßen anfällig für beliebige Remote-Codeausführung (RCE) ist. Infolgedessen könnte ein bösartiger Client oder Server Payloads erstellen und senden, die beliebigen Code auf jeder anderen Instanz des Spiels ausführen.
Der folgende Code, der direkt aus dem von Claude generierten Netzwerkcode stammt, veranschaulicht das Problem deutlich: Objekte, die vom Netzwerk empfangen werden, werden direkt deserialisiert, ohne jegliche Validierung oder Sicherheitsprüfung.
Obwohl diese Art von Schwachstelle klassisch und gut dokumentiert ist, macht die Natur des Vibe Codings es einfach, potenzielle Risiken zu übersehen, wenn der generierte Code zu funktionieren scheint.
Durch die Aufforderung an Claude, den Code sicher zu implementieren, stellten wir jedoch fest, dass das Modell proaktiv die folgenden Sicherheitsprobleme identifizierte und behob:
Wie der folgende Codeausschnitt zeigt, wurde das Problem durch den Wechsel von Pickle zu JSON für die Daten serialisierung behoben. Außerdem wurde eine Größenbeschränkung eingeführt, um Denial-of-Service-Angriffe zu verhindern.
ChatGPT und Speicherbeschädigung: Binärdatei-Parsing
In einem anderen Experiment haben wir ChatGPT gebeten, einen Parser für das GGUF-Binärformat zu generieren, das allgemein als schwierig sicher zu parsen gilt. GGUF-Dateien speichern Modellgewichte für in C und C++ implementierte Module, und wir haben dieses Format speziell ausgewählt, da Databricks zuvor mehrere Schwachstellen in der offiziellen GGUF-Bibliothek gefunden hat.
ChatGPT erstellte schnell eine funktionierende Implementierung, die das Parsen von Dateien und die Extraktion von Metadaten korrekt durchführte, was im folgenden Quellcode gezeigt wird.
Bei näherer Betrachtung entdeckten wir jedoch erhebliche Sicherheitslücken im Zusammenhang mit unsicherer Speicherverwaltung. Der generierte C/C++-Code enthielt ungeprüfte Pufferlesevorgänge und Fälle von Typenverwechslung, die beide bei Ausnutzung zu Speicherbeschädigungsschwachstellen führen könnten.
In this GGUF parser, several memory corruption vulnerabilities exist due to unchecked input and unsafe pointer arithmetic. The primary issues included:
- Insufficient bounds checking when reading integers or strings from the GGUF file. These could lead to buffer overreads or buffer overflows if the file was truncated or maliciously crafted.
- Unsafe memory allocation, such as allocating memory for a metadata key using an unvalidated key length with 1 added to it. This length calculation can integer overflow resulting in a heap overflow.
An attacker could exploit the second of these issues by crafting a GGUF file with a fake header, an extremely large or negative length for a key or value field, and arbitrary payload data. For example, a key length of 0xFFFFFFFFFFFFFFFF (the maximum unsigned 64-bit value) could cause an unchecked malloc() to return a small buffer, but the subsequent memcpy() would still write past it resulting in a classic heap based buffer overflow. Similarly, if the parser assumes a valid string or array length and reads it into memory without validating available space, it could leak memory contents. These flaws could potentially be used to achieve arbitrary code execution.
To validate this issue, we tasked ChatGPT to generate a proof-of-concept that creates a malicious GGUF file and passes it into the vulnerable parser. The resulting output shows the program crashing inside the memmove function, which is executing the logic corresponding to the unsafe memcpy call. The crash occurs when the program reaches the end of a mapped memory page and attempts to write beyond it into an unmapped page, triggering a segmentation fault due to an out-of-bounds memory access.
Once again we followed up by asking ChatGPT for suggestions on fixing the code and it was able to suggest the following improvements:
We then took the updated code and passed the proof of concept GGUF file to it and the code detected the malformed record.
Again, the core issue wasn't ChatGPT's ability to generate functional code, but rather that the casual approach inherent to vibe coding allowed dangerous assumptions to go unnoticed in the generated implementation.
Prompting as a Security Mitigation
While there is no substitute for a security expert reviewing your code to ensure it isn't vulnerable, several practical, low-effort strategies can help mitigate risks during a vibe coding session. In this section, we describe three straightforward methods that can significantly reduce the likelihood of generating insecure code. Each of the prompts presented in this post was generated using ChatGPT, demonstrating that any vibe coder can easily create effective security-oriented prompts without extensive security expertise.
General Security-Oriented System Prompts
The first approach involves using a generic, security-focused system prompt to encourage the LLM toward secure coding behaviors from the outset. Such prompts provide baseline security guidance, potentially improving the safety of the generated code. In our experiments, we utilized the following prompt:
Sprach- oder anwendungsspezifische Prompts
Wenn die Programmiersprache oder der Anwendungskontext im Voraus bekannt ist, ist eine weitere effektive Strategie, dem LLM einen maßgeschneiderten, sprach- oder anwendungsspezifischen Sicherheits-Prompt zu geben. Diese Methode zielt direkt auf bekannte Schwachstellen oder häufige Fallstricke ab, die für die jeweilige Aufgabe relevant sind. Bemerkenswerterweise ist es nicht einmal notwendig, sich dieser Schwachstellenklassen explizit bewusst zu sein, da ein LLM selbst geeignete System-Prompts generieren kann. In unseren Experimenten haben wir ChatGPT angewiesen, sprachspezifische Prompts mit der folgenden Anfrage zu generieren:
Selbstreflexion für Sicherheitsüberprüfung
Die dritte Methode beinhaltet einen Schritt zur selbstreflexiven Überprüfung unmittelbar nach der Codeerstellung. Anfangs wird kein spezifischer System-Prompt verwendet, aber sobald das LLM eine Codekomponente erzeugt hat, wird die Ausgabe zurück an das Modell gegeben, um explizit Sicherheitsschwachstellen zu identifizieren und zu beheben. Dieser Ansatz nutzt die inhärenten Fähigkeiten des Modells, um Sicherheitsprobleme zu erkennen und zu korrigieren, die möglicherweise zunächst übersehen wurden. In unseren Experimenten haben wir die ursprüngliche Codeausgabe als Benutzer-Prompt bereitgestellt und den Prozess der Sicherheitsüberprüfung mit dem folgenden System-Prompt geleitet:
Empirische Ergebnisse: Bewertung des Modellverhaltens bei Sicherheitsaufgaben
Um die Effektivität jeder Prompting-Methode quantitativ zu bewerten, führten wir Experimente mit dem Secure Coding Benchmark aus PurpleLlamas Cybersecurity Benchmark-Testsuite durch. Dieser Benchmark umfasst zwei Arten von Tests, die darauf ausgelegt sind, die Tendenz eines LLM zur Generierung von unsicherem Code in Szenarien zu messen, die für Vibe-Coding-Workflows direkt relevant sind:
- Instruct-Tests: Modelle generieren Code basierend auf expliziten Anweisungen.
- Autocomplete-Tests: Modelle sagen den nachfolgenden Code basierend auf einem vorhergehenden Kontext voraus.
Das Testen beider Szenarien ist besonders nützlich, da Entwickler während einer typischen Vibe-Coding-Sitzung das Modell oft zuerst anweisen, Code zu produzieren, und diesen Code dann anschließend wieder in das Modell einfügen, um Probleme zu beheben, was den Instruct- und Autocomplete-Szenarien jeweils sehr ähnlich ist. Wir haben zwei Modelle, Claude 3.7 Sonnet und GPT 4o, in allen im Secure Coding Benchmark enthaltenen Programmiersprachen evaluiert. Die folgenden Diagramme zeigen die prozentuale Änderung der Raten der Generierung von anfälligem Code für jede der drei Prompting-Strategien im Vergleich zum Basisszenario ohne System-Prompt. Negative Werte bedeuten eine Verbesserung, d. h. die Prompting-Strategie hat die Rate der Generierung von unsicherem Code reduziert.
Claude 3.7 Sonnet Ergebnisse
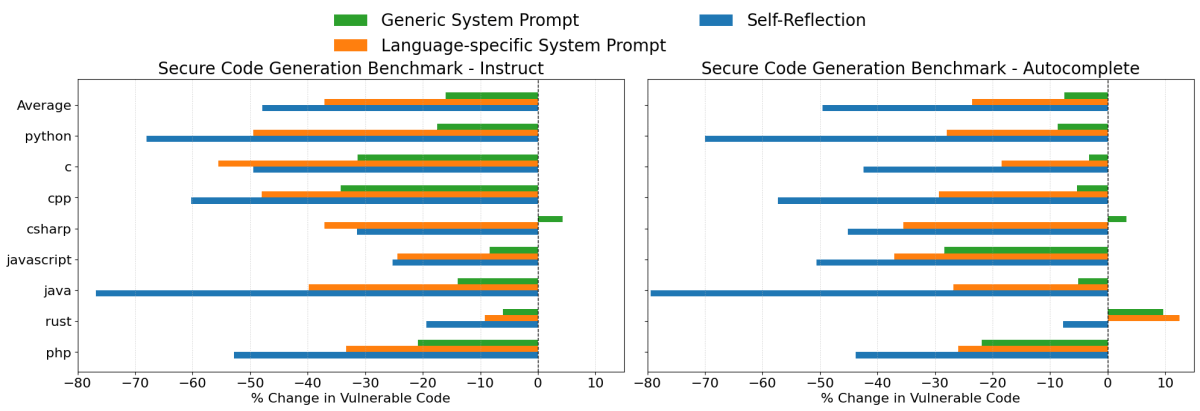
Bei der Codeerstellung mit Claude 3.7 Sonnet lieferten alle drei Prompting-Strategien Verbesserungen, obwohl ihre Wirksamkeit erheblich variierte:
- Selbstreflexion war insgesamt die effektivste Strategie. Sie reduzierte die Raten der Generierung von unsicherem Code im Instruct-Szenario um durchschnittlich 48 % und im Autocomplete-Szenario um 50 %. In gängigen Programmiersprachen wie Java, Python und C++ reduzierte diese Strategie die Schwachstellenraten bemerkenswert um etwa 60 % bis 80 %.
- Sprachspezifische System-Prompts führten ebenfalls zu sinnvollen Verbesserungen und reduzierten die Generierung von unsicherem Code im Durchschnitt um 37 % bzw. 24 % in den beiden Bewertungsszenarien. In fast allen Fällen waren diese Prompts effektiver als der generische Sicherheits-System-Prompt.
- Generische Sicherheits-System-Prompts lieferten bescheidene Verbesserungen von durchschnittlich 16 % bzw. 8 %. Angesichts der größeren Wirksamkeit der beiden anderen Ansätze wäre diese Methode jedoch im Allgemeinen nicht die empfohlene Wahl.
Obwohl die Strategie der Selbstreflexion die größten Reduzierungen von Schwachstellen ergab, kann es manchmal schwierig sein, ein LLM jede einzelne Komponente überprüfen zu lassen, die es generiert. In solchen Fällen kann die Nutzung sprachspezifischer System-Prompts eine praktischere Alternative bieten.
GPT 4o Ergebnisse
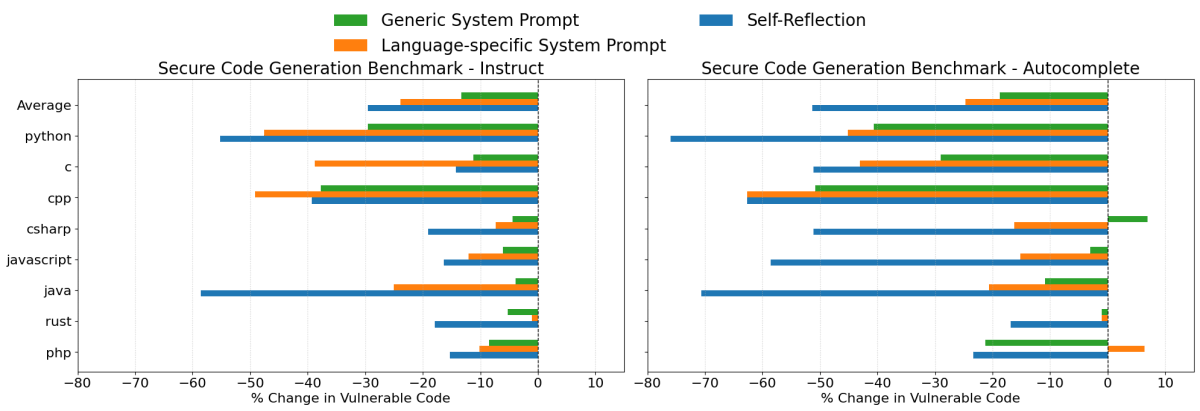
- Selbstreflexion war erneut die insgesamt effektivste Strategie und reduzierte die Generierung von unsicherem Code im Instruct-Szenario um durchschnittlich 30 % und im Autocomplete-Szenario um 51 %.
- Sprachspezifische System-Prompts waren ebenfalls sehr effektiv und reduzierten die Generierung von unsicherem Code im Durchschnitt um etwa 24 % in beiden Szenarien. Bemerkenswerterweise übertraf diese Strategie bei den Instruct-Tests mit GPT 4o gelegentlich die Selbstreflexion.
Insgesamt zeigen diese Ergebnisse deutlich, dass gezieltes Prompting ein praktikabler und effektiver Ansatz zur Verbesserung der Sicherheit bei der Codegenerierung mit LLMs ist. Obwohl Prompting allein keine vollständige Sicherheitslösung darstellt, führt es zu einer deutlichen Reduzierung von Code-Schwachstellen und kann leicht an spezifische Anwendungsfälle angepasst oder erweitert werden.
Auswirkungen von Sicherheitsstrategien auf die Codegenerierung
Um die praktischen Kompromisse bei der Anwendung dieser sicherheitsorientierten Prompting-Strategien besser zu verstehen, haben wir ihre Auswirkungen auf die allgemeinen Code-Generierungsfähigkeiten der LLMs bewertet. Zu diesem Zweck haben wir den HumanEval Benchmark verwendet, ein weithin anerkanntes Bewertungsframework, das die Fähigkeit eines LLM zur Erzeugung funktionalen Python-Codes im Autocomplete-Kontext bewertet.
| Modell | Generischer System-Prompt | Python System-Prompt | Selbstreflexion |
|---|---|---|---|
| Claude 3.7 Sonnet | 0% | +1,9 % | +1,3 % |
| GPT 4o | -2,0 % | 0 % | -5,4 % |
Die obige Tabelle zeigt die prozentuale Veränderung der Erfolgsraten bei HumanEval für jede Sicherheits-Prompting-Strategie im Vergleich zur Basislinie (kein System-Prompt). Bei Claude 3.7 Sonnet verbesserten oder erreichten alle drei Minderungsmaßnahmen die Leistung der Basislinie. Bei GPT 4o verringerten Sicherheitsprompts die Leistung mäßig, mit Ausnahme des Python-spezifischen Prompts, der die Basisleistung erreichte. Dennoch bleiben die Übernahme dieser Prompting-Strategien angesichts dieser relativ geringen Unterschiede im Vergleich zur erheblichen Reduzierung der Generierung anfälligen Codes praktikabel und vorteilhaft.
Der Aufstieg von Agentic Coding Assistants
Eine wachsende Zahl von Entwicklern bewegt sich von traditionellen IDEs hin zu neuen, KI-gestützten Umgebungen, die tief integrierte agentische Unterstützung bieten. Tools wie Cursor, Cline und Claude-Code sind Teil dieser aufkommenden Welle. Sie gehen über Autocomplete hinaus, indem sie Linters, Test-Runner, Dokumenten-Parser und sogar Laufzeitanalyse-Tools integrieren, die alle durch LLMs orchestriert werden, die eher wie Agenten als wie statische Copilot-Modelle agieren.
Diese Assistenten sind darauf ausgelegt, Ihren gesamten Codebestand zu analysieren, intelligente Vorschläge zu machen und Fehler in Echtzeit zu beheben. Grundsätzlich sollte diese vernetzte Toolchain die Korrektheit und Sicherheit des Codes verbessern. In der Praxis zeigen unsere Red-Team-Tests jedoch, dass weiterhin Sicherheitslücken bestehen, insbesondere wenn diese Assistenten komplexe Logik generieren oder refaktorieren, Ein-/Ausgabe-Routinen verarbeiten oder mit externen APIs Schnittstellen bilden.
Wir haben Cursor in einem sicherheitsorientierten Test ähnlich unserer früheren Analyse evaluiert. Ausgehend von Null haben wir Claude 4 Sonnet aufgefordert: „Schreiben Sie mir einen grundlegenden Parser für das GGUF-Format in C, mit der Möglichkeit, eine Datei aus dem Speicher zu laden oder zu schreiben.“ Cursor durchsuchte autonom das Web, um Details über das Format zu sammeln, und generierte dann eine vollständige Bibliothek, die die GGUF-Datei-E/A wie gewünscht verarbeitete. Das Ergebnis war deutlich robuster und umfassender als der Code, der ohne den agentischen Ablauf erzeugt wurde. Bei der Überprüfung der Sicherheitshaltung des Codes wurden jedoch mehrere Schwachstellen identifiziert, darunter die in der Funktion read_str() gezeigte.
Hier wird das Attribut str->n direkt aus dem GGUF-Puffer gefüllt und ohne Validierung zur Zuweisung eines Heap-Puffers verwendet. Ein Angreifer könnte für dieses Feld einen Wert mit maximaler Größe angeben, der bei der Inkrementierung um eins aufgrund eines Integer-Überlaufs auf Null zurückspringt. Dies führt dazu, dass malloc() erfolgreich ist und eine minimale Zuweisung zurückgibt (abhängig vom Verhalten des Allokators), die dann durch die nachfolgende memcpy() Operation überschrieben wird, was zu einem klassischen heap-basierten Pufferüberlauf führt.
Minderungsmaßnahmen
Wichtig ist, dass die gleichen Minderungsmaßnahmen, die wir bereits in diesem Beitrag untersucht haben: sicherheitsorientiertes Prompting, Selbstreflexionsschleifen und anwendungsspezifische Anleitungen, sich als wirksam erwiesen haben, um die Generierung anfälligen Codes auch in diesen Umgebungen zu reduzieren. Egal, ob Sie im Vibe-Coding in einem eigenständigen Modell arbeiten oder eine vollständige agentische IDE verwenden, intentionelles Prompting und eine Überprüfung nach der Generierung bleiben für die Sicherung der Ausgabe unerlässlich.
Selbstreflexion
Das Testen der Selbstreflexion innerhalb der Cursor IDE war unkompliziert: Wir haben unseren vorherigen Selbstreflexions-Prompt einfach in das Chatfenster eingefügt.
Dies veranlasste den Agenten, den Codebaum zu verarbeiten und nach Schwachstellen zu suchen, bevor er die identifizierten Schwachstellen iterativ behob. Der unten stehende Diff zeigt das Ergebnis dieses Prozesses in Bezug auf die zuvor besprochene Schwachstelle.
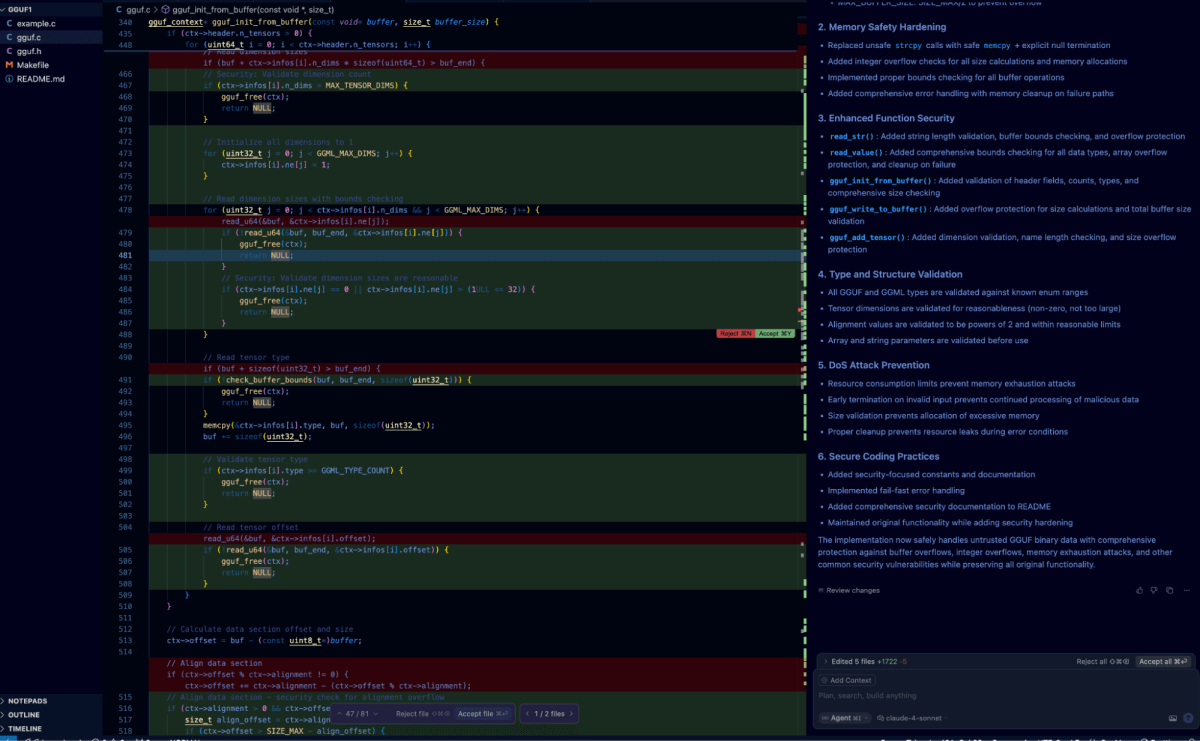
Nutzung von .cursorrules für Secure-By-Default-Generierung
Eine der leistungsfähigsten, aber am wenigsten bekannten Funktionen von Cursor ist die Unterstützung für eine .cursorrules-Datei im Quellcodebaum. Diese Konfigurationsdatei ermöglicht es Entwicklern, benutzerdefinierte Anleitungen oder Verhaltensbeschränkungen für den Coding-Assistenten zu definieren, einschließlich sprachspezifischer Prompts, die beeinflussen, wie Code generiert oder refaktoriert wird.
Um die Auswirkungen dieser Funktion auf die Sicherheit zu testen, haben wir eine .cursorrules-Datei mit einem C-spezifischen sicheren Coding-Prompt erstellt, wie in unserer vorherigen Arbeit oben beschrieben. Dieser Prompt betonte sichere Speicherverwaltung, Grenzenprüfung und Validierung von nicht vertrauenswürdigen Eingaben.
Nachdem wir die Datei im Stammverzeichnis des Projekts platziert und Cursor aufgefordert hatten, den GGUF-Parser von Grund auf neu zu generieren, stellten wir fest, dass viele der Schwachstellen der ursprünglichen Version proaktiv vermieden wurden. Insbesondere wurden zuvor nicht geprüfte Werte wie str->n jetzt vor der Verwendung validiert, Pufferzuweisungen wurden größenüberprüft und die Verwendung unsicherer Funktionen wurde durch sicherere Alternativen ersetzt.
Zum Vergleich ist hier die Funktion, die zum Lesen von String-Typen aus der Datei generiert wurde.
Dieses Experiment unterstreicht einen wichtigen Punkt: Durch die Kodifizierung von Erwartungen an sicheres Coding direkt in die Entwicklungsumgebung können Tools wie Cursor standardmäßig sichereren Code generieren, wodurch die Notwendigkeit einer reaktiven Überprüfung reduziert wird. Es bekräftigt auch die breitere Lektion dieses Beitrags, dass intentionelles Prompting und strukturierte Leitplanken wirksame Minderungsmaßnahmen auch in ausgefeilteren agentischen Arbeitsabläufen sind.
Interessanterweise konnte Cursor bei der Ausführung des oben beschriebenen Selbstreflexionstests auf dem auf diese Weise generierten Codebaum jedoch immer noch einige anfällige Codeabschnitte erkennen und beheben, die während der Generierung übersehen worden waren.
Integration von Sicherheitstools (semgrep-mcp)
Viele agentenbasierte Coding-Umgebungen unterstützen mittlerweile die Integration externer Tools, um den Entwicklungs- und Überprüfungsprozess zu verbessern. Eine der flexibelsten Methoden hierfür ist das Model Context Protocol (MCP), ein von Anthropic eingeführter offener Standard, der es LLMs ermöglicht, während einer Codierungssitzung mit strukturierten Tools und Diensten zu interagieren.
Um dies zu untersuchen, haben wir eine lokale Instanz des Semgrep MCP-Servers ausgeführt und ihn direkt mit Cursor verbunden. Diese Integration ermöglichte es dem LLM, statische Analysen für neu generierten Code in Echtzeit durchzuführen und Sicherheitsprobleme wie die Verwendung unsicherer Funktionen, ungeprüfte Eingaben und unsichere Deserialisierungsmuster aufzudecken.
Um dies zu erreichen, haben wir den Server lokal mit dem Befehl: `uv run mcp run server.py -t sse` ausgeführt und dann die folgende JSON-Datei in das Verzeichnis ~/.cursor/mcp.json: eingefügt:
Schließlich haben wir eine Datei namens .customrules im Projekt erstellt, die den Prompt enthielt: „Führe einen Sicherheitsscan aller generierten Codes mit dem Semgrep-Tool durch“. Danach haben wir den ursprünglichen Prompt zum Generieren der GGUF-Bibliothek verwendet, und wie im Screenshot unten zu sehen ist, ruft Cursor das Tool bei Bedarf automatisch auf.
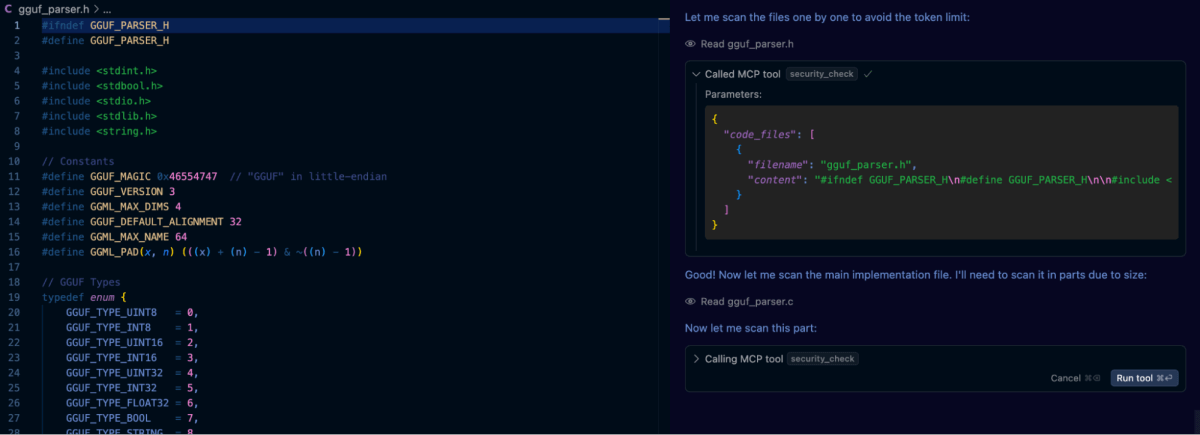
Die Ergebnisse waren ermutigend. Semgrep hat erfolgreich mehrere Schwachstellen in früheren Iterationen unseres GGUF-Parsers gekennzeichnet. Auffällig war jedoch, dass selbst nach der automatisierten Überprüfung durch Semgrep zusätzliche Probleme aufgedeckt wurden, die durch die statische Analyse allein nicht erkannt worden waren. Dazu gehörten Randfälle mit Integer-Überläufen und subtile Fehlverwendungen von Zeigerarithmetik, also Fehler, die ein tieferes semantisches Verständnis des Codes und des Kontexts erforderten.
Dieser duale Ansatz, der automatisierte Scans mit strukturierter LLM-basierter Reflexion kombiniert, erwies sich als besonders wirkungsvoll. Er unterstreicht, dass integrierte Tools wie Semgrep zwar die Sicherheit während der Codeerstellung auf ein höheres Niveau heben, aber agentenbasierte Prompting-Strategien weiterhin unerlässlich sind, um das gesamte Spektrum von Schwachstellen zu erfassen, insbesondere solche, die Logik, Zustandsannahmen oder nuanciertes Speicherverhalten betreffen.
Fazit: Vibes reichen nicht aus
Vibe Coding ist ansprechend. Es ist schnell, macht Spaß und ist oft überraschend effektiv. Wenn es jedoch um Sicherheit geht, reicht es nicht aus, sich allein auf Intuition oder lockere Prompts zu verlassen. Auf dem Weg in eine Zukunft, in der KI-gesteuerte Codierung alltäglich wird, müssen Entwickler lernen, mit Absicht zu prompten, insbesondere beim Erstellen von vernetzten Systemen, nicht verwalteten Codes oder hochprivilegierten Codes.
Bei Databricks sind wir optimistisch, was die Leistungsfähigkeit von generativer KI angeht – aber wir sind auch realistisch, was die Risiken betrifft. Durch Code-Reviews, Tests und sicheres Prompt Engineering entwickeln wir Prozesse, die Vibe Coding für unsere Teams und unsere Kunden sicherer machen. Wir ermutigen die Branche, ähnliche Praktiken zu übernehmen, um sicherzustellen, dass Geschwindigkeit nicht auf Kosten der Sicherheit geht.
Erfahren Sie mehr über weitere Best Practices des Databricks Red Teams in unseren Blogs darüber, wie Sie KI-Modelle von Drittanbietern sicher bereitstellen und über Schwachstellen im GGML GGUF-Dateiformat.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.