Der ultimative Leitfaden für skalierbares Logging für Praktiker
Standardisieren und strukturieren Sie die Produktionsprotokollierung für Spark-Jobs auf Databricks und holen Sie mehr aus Ihren Protokollen heraus, indem Sie Cluster-Protokolle für die Aufnahme und Analyse zentralisieren.
von Zach King
- Produktionsreife Best Practices für strukturierte, praktische Protokollierung in Databricks-Jobs.
- Zentralisierung der Protokollspeicherung, die skaliert und die Verarbeitung vereinfacht.
- Erstellung eines KI/BI-Dashboards zur Analyse von Protokollen.
Einleitung: Logging ist wichtig, hier ist warum
Die Skalierung von einigen Dutzend Aufträgen auf Hunderte ist aus mehreren Gründen eine Herausforderung, einer davon ist die Beobachtbarkeit. Beobachtbarkeit ist die Fähigkeit, das System zu verstehen, indem Komponenten wie Protokolle, Metriken und Spuren analysiert werden. Dies ist ebenso relevant für kleinere Datenteams mit nur wenigen zu überwachenden Pipelines, und verteilte Computing-Engines wie Spark können schwierig zuverlässig zu überwachen, zu debuggen und ausgereifte Eskalationsverfahren zu erstellen.
Protokollierung ist wohl die einfachste und wirkungsvollste dieser Beobachtbarkeitskomponenten. Das Klicken und Scrollen durch Protokolle, ein Auftragsdurchlauf nach dem anderen, ist nicht skalierbar. Es kann zeitaufwändig, schwer zu analysieren sein und erfordert oft Fachwissen über den Workflow. Ohne den Aufbau ausgereifter Protokollierungsstandards in Ihre Datenpipelines dauert die Fehlerbehebung bei Fehlern oder Auftragsausfällen erheblich länger, was zu kostspieligen Ausfällen, ineffektiven Eskalationsstufen und Alarmmüdigkeit führt.
In diesem Blog führen wir Sie durch:
- Schritte, um von einfachen Print-Anweisungen wegzukommen und ein richtiges Logging-Framework einzurichten.
- Wann die Spark log4j-Protokolle so konfigurieren, dass sie das JSON-Format verwenden.
- Warum die Speicherung von Cluster-Protokollen zentralisiert werden sollte, um die Analyse und Abfrage zu erleichtern.
- Wie Sie ein zentrales KI/BI-Dashboard in Databricks erstellen, das Sie in Ihrem eigenen Workspace einrichten können, um eine individuellere Protokollanalyse durchzuführen.
Wichtige architektonische Überlegungen
Die folgenden Überlegungen sind wichtig, um diese Protokollempfehlungen an Ihr Unternehmen anzupassen:
Logging-Bibliotheken
- Es gibt mehrere Logging-Bibliotheken für Python und Scala. Unsere Beispiele verwenden Log4j und das Standard-Python- logging-Modul.
- Die Konfiguration für Logging-Bibliotheken oder Frameworks ist unterschiedlich, und Sie sollten deren jeweilige Dokumentation konsultieren, wenn Sie ein nicht standardmäßiges Tool verwenden.
Clustertypen
- Die Beispiele in diesem Blog konzentrieren sich hauptsächlich auf die folgende Rechenleistung:
- Zum Zeitpunkt der Erstellung dieses Dokuments haben die folgenden Computertypen weniger Unterstützung für die Protokollbereitstellung, obwohl die Empfehlungen für Logging-Frameworks weiterhin gelten:
- Lakeflow Declarative Pipelines (früher DLT): Unterstützt nur Ereignisprotokolle
- Serverless Jobs: Unterstützt keine Protokollbereitstellung
- Serverless Notebooks: Unterstützt keine Protokollbereitstellung
Datengovernance
- Die Datengovernance sollte sich auf Clusterprotokolle erstrecken, da Protokolle versehentlich sensible Daten preisgeben können. Wenn Sie beispielsweise Protokolle in eine Tabelle schreiben, sollten Sie überlegen, welche Benutzer Zugriff auf die Tabelle haben und ein Design mit dem geringsten Privilegzugriff verwenden.
- Wir werden zeigen, wie Clusterprotokolle an Unity Catalog-Volumes geliefert werden, um die Zugriffssteuerung und die Datenherkunft zu vereinfachen. Die Protokollbereitstellung an Volumes befindet sich in der öffentlichen Vorschau und wird nur auf Unity Catalog-fähigen Compute-Instanzen mit dem Zugriffsmodus Standard oder dem Zugriffsmodus Dediziert, der einem Benutzer zugewiesen ist, unterstützt.
- Diese Funktion wird nicht auf Compute-Instanzen mit dem Zugriffsmodus Dediziert unterstützt, der einer Gruppe zugewiesen ist.
Technische Lösungsaufschlüsselung
Standardisierung ist der Schlüssel zur produktionsreifen Protokollbeobachtbarkeit. Idealerweise sollte die Lösung Hunderte oder sogar Tausende von Aufträgen/Pipelines/Clustern unterstützen.
Die vollständige Implementierung dieser Lösung finden Sie in diesem Repository hier: https://github.com/databricks-industry-solutions/watchtower
Erstellung eines Volumes für die zentrale Protokollbereitstellung
Zuerst können wir ein Unity Catalog Volume als zentralen Speicher für Protokolle erstellen. Wir empfehlen DBFS nicht, da es nicht das gleiche Maß an Datengovernance bietet. Wir empfehlen, Protokolle für jede Umgebung (z. B. Entwicklung, Staging, Produktion) in verschiedenen Verzeichnissen oder Volumes zu trennen, damit der Zugriff granularer gesteuert werden kann.
Sie können dies in der Benutzeroberfläche, innerhalb eines Databricks Asset Bundle (AWS | Azure | GCP) oder in unserem Fall mit Terraform erstellen:
Bitte stellen Sie sicher, dass Sie die Berechtigungen READ VOLUME und WRITE VOLUME für das Volume haben (AWS | Azure | GCP).
Konfigurieren der Cluster-Protokollbereitstellung
Nachdem wir nun einen zentralen Ort für unsere Protokolle haben, müssen wir die Cluster so konfigurieren, dass sie ihre Protokolle an dieses Ziel liefern. Konfigurieren Sie dazu die Compute-Protokollbereitstellung (AWS | Azure | GCP) auf dem Cluster.
Verwenden Sie wieder die Benutzeroberfläche, Terraform oder eine andere bevorzugte Methode; wir verwenden Databricks Asset Bundles (YAML):
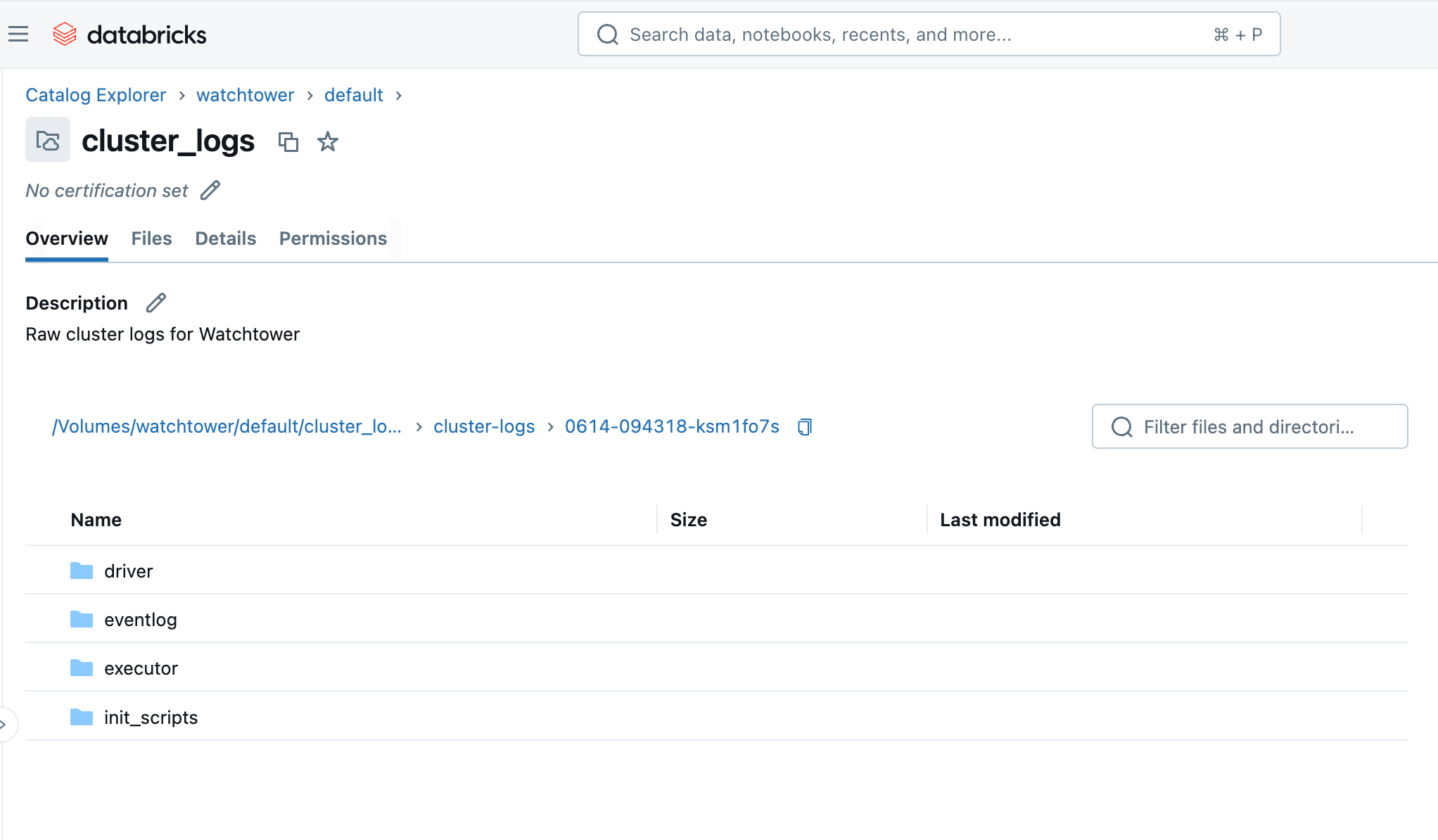
Nachdem der Cluster oder der Auftrag ausgeführt wurde, können wir innerhalb weniger Minuten das Volume im Catalog Explorer durchsuchen und die ankommenden Dateien sehen. Sie sehen einen Ordner mit der Cluster-ID (z. B. 0614-174319-rbzrs7rq), dann Ordner für jede Gruppe von Protokollen:
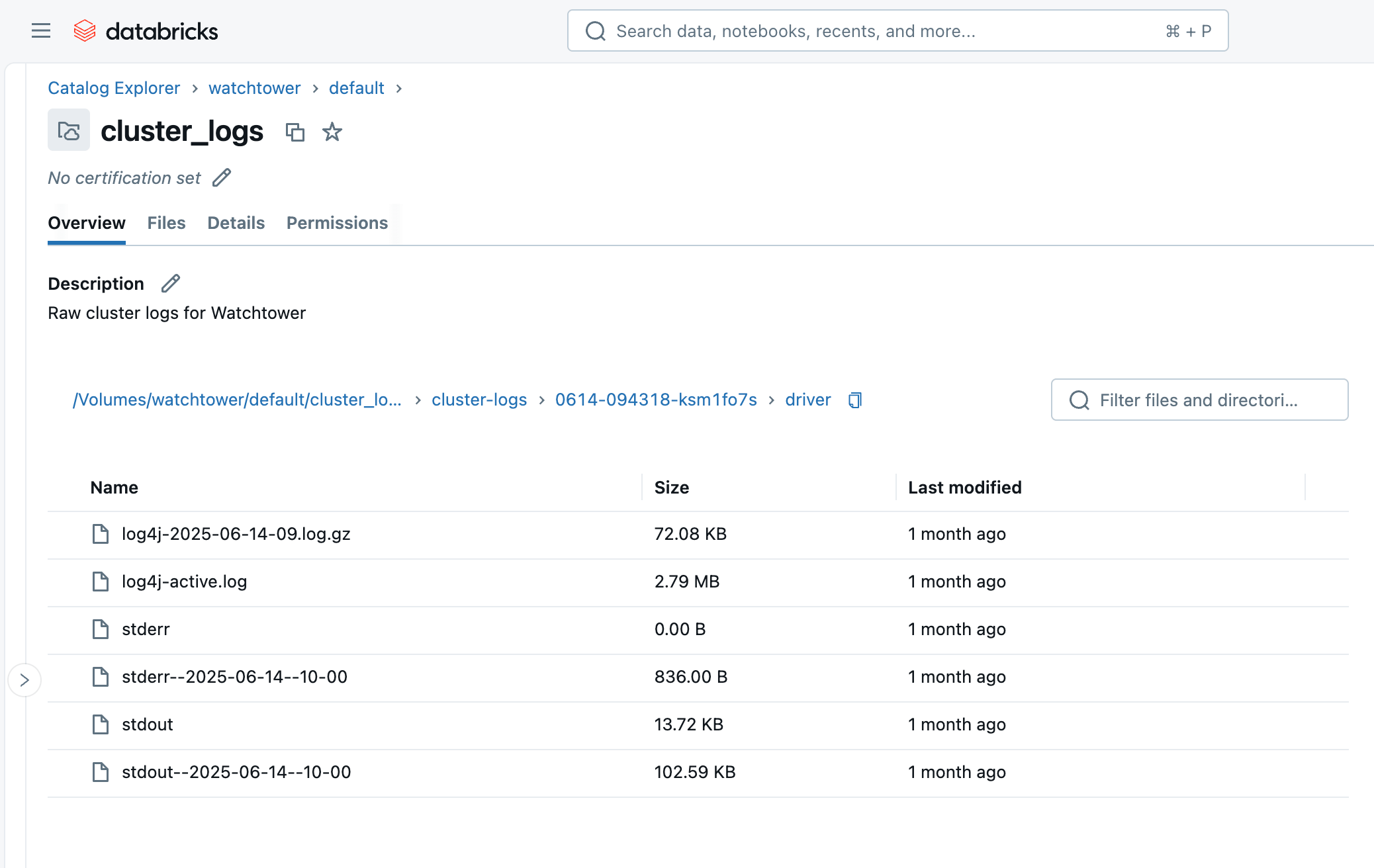
- driver: Protokolle vom Treiberknoten, an denen wir am meisten interessiert sind.
- executor: Protokolle von jedem Spark-Executor im Cluster.
- eventlog: Protokolle von Ereignissen, die Sie im Tab „Event Log“ des Clusters finden, wie z. B. Clusterstart, Clusterbeendigung, Größenänderung usw.
- init_scripts: Dieser Ordner wird generiert, wenn der Cluster Init-Skripte hat, wie unserer. Unterordner werden für jeden Knoten im Cluster erstellt, und dann können stdout- und stderr-Protokolle für jedes Init-Skript gefunden werden, das auf dem Knoten ausgeführt wurde.
Durchsetzung von Standards: Cluster-Richtlinie
Workspace-Administratoren sollten nach Möglichkeit Standardkonfigurationen erzwingen. Das bedeutet, den Zugriff auf die Clustererstellung einzuschränken und Benutzern eine Cluster-Richtlinie (AWS | Azure | GCP) mit der fest auf die unten gezeigten Werte eingestellten Cluster-Protokollkonfiguration zu geben:
Wenn diese Attribute auf einen „festen“ Wert gesetzt werden, wird das richtige Volume-Ziel automatisch konfiguriert und verhindert, dass Benutzer die Eigenschaft vergessen oder ändern.
Anstatt die cluster_log_conf in Ihrer Asset Bundle YAML explizit zu konfigurieren, können wir jetzt einfach die Cluster-Richtlinien-ID angeben, die verwendet werden soll:
Mehr als nur eine print()-Anweisung
Während print()-Anweisungen während der Entwicklung für schnelle Debugging-Zwecke nützlich sein können, reichen sie in Produktionsumgebungen aus mehreren Gründen nicht aus:
- Fehlende Struktur: Print-Anweisungen erzeugen unstrukturierte Texte, was das Parsen, Abfragen und Analysieren von Protokollen in großem Maßstab erschwert.
- Begrenzter Kontext: Ihnen fehlen oft wichtige Kontextinformationen wie Zeitstempel, Protokollebenen (z. B. INFO, WARNING, ERROR), Ursprungsmodul oder Job-ID, die für eine effektive Fehlerbehebung entscheidend sind.
- Leistungs-Overhead: Übermäßige print()-Anweisungen können einen Leistungs-Overhead verursachen, da sie eine Auswertung in Spark auslösen. Print-Anweisungen schreiben auch direkt in die Standardausgabe (stdout) ohne Pufferung oder optimierte Handhabung.
- Keine Kontrolle über die Ausführlichkeit: Es gibt keinen integrierten Mechanismus zur Steuerung der Ausführlichkeit von print()-Anweisungen, was dazu führt, dass Protokolle entweder zu unübersichtlich oder unzureichend detailliert sind.
Geeignete Protokollierungs-Frameworks wie Log4j für Scala/Java (JVM) oder das integrierte logging-Modul für Python lösen all diese Probleme und werden in der Produktion bevorzugt. Diese Frameworks ermöglichen es uns, Protokollebenen oder Ausführlichkeit zu definieren, maschinenfreundliche Formate wie JSON auszugeben und flexible Ziele festzulegen.
Bitte beachten Sie auch den Unterschied zwischen stdout, stderr und log4j in den Spark-Treiberprotokollen:
- stdout: Standardausgabepuffer der JVM des Treiberknotens. Hier werden standardmäßig
print()-Anweisungen und allgemeine Ausgaben geschrieben. - stderr: Standardfehlerausgabepuffer der JVM des Treiberknotens. Hier werden typischerweise Ausnahmen/Stacktraces geschrieben, und viele Protokollierungsbibliotheken leiten standardmäßig auch an stderr um.
- log4j: Speziell gefilterte Protokollnachrichten, die mit einem log4j-Logger geschrieben wurden. Diese können auch in stderr-Nachrichten angezeigt werden.
Python
In Python bedeutet dies, das Standard-Logging-Modul zu importieren, ein JSON-Format zu definieren und Ihre Protokollebene festzulegen.
Ab Spark 4 oder Databricks Runtime 17.0+ ist ein vereinfachter strukturierter Logger in PySpark integriert: https://spark.apache.org/docs/latest/api/python/development/logger.html. Das folgende Beispiel kann für PySpark 4 angepasst werden, indem die Logger-Instanz durch eine pyspark.logger.PySparkLogger-Instanz ersetzt wird.
Ein Großteil dieses Codes dient lediglich der Formatierung unserer Python-Protokollnachrichten als JSON. JSON ist semi-strukturiert und sowohl für Menschen als auch für Maschinen leicht lesbar, was wir zu schätzen wissen werden, wenn wir diese Protokolle später in diesem Blog aufnehmen und abfragen. Wenn wir diesen Schritt überspringen würden, müssten wir uns auf komplexe, ineffiziente reguläre Ausdrücke verlassen, um zu erraten, welcher Teil der Nachricht die Protokollebene, ein Zeitstempel oder die Nachricht usw. ist.
Natürlich ist dies ziemlich ausführlich, um es in jedes Notebook oder jedes Python-Paket aufzunehmen. Um Duplizierung zu vermeiden, kann dieser Boilerplate-Code als Utility-Code verpackt und auf Ihre Jobs geladen werden, und zwar auf verschiedene Arten:
- Legen Sie den Boilerplate-Code in ein Python-Modul auf dem Workspace und verwenden Sie Workspace-Datei-Importe (AWS | Azure | GCP), um den Code zu Beginn Ihrer Haupt-Notebooks auszuführen.
- Erstellen Sie den Boilerplate-Code in eine Python-Wheel-Datei und laden Sie ihn als Bibliothek auf die Cluster (AWS | Azure | GCP).
Scala
Die gleichen Prinzipien gelten für Scala, aber wir werden stattdessen Log4j oder genauer gesagt die SLF4j-Abstraktion verwenden:
Wenn wir die Treiberprotokolle in der Benutzeroberfläche anzeigen, finden wir unsere INFO- und WARN-Protokollnachrichten unter Log4j. Dies liegt daran, dass die Standardprotokollebene INFO ist, sodass die DEBUG- und TRACE-Nachrichten nicht geschrieben werden.

Die Log4j-Protokolle sind jedoch nicht im JSON-Format! Wir werden sehen, wie wir das als Nächstes beheben können.
Protokollierung für Spark Structured Streaming
Um nützliche Informationen für Streaming-Jobs zu erfassen, wie z. B. Streaming-Quellen- und Senkenmetriken sowie Abfragefortschritt, können wir auch den StreamingQueryListener von Spark implementieren.
Registrieren Sie dann den Protokollierungs-Listener mit Ihrer Spark-Sitzung:
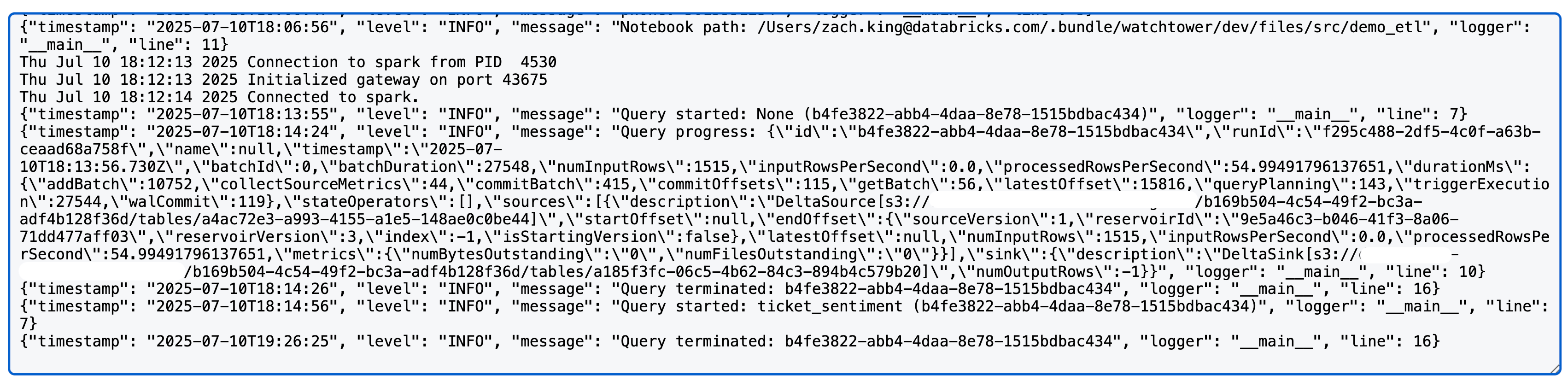
Nachdem Sie eine Spark Structured Streaming-Abfrage ausgeführt haben, sehen Sie nun etwas Ähnliches wie das Folgende in den Log4j-Protokollen (Hinweis: Wir verwenden hier eine Delta-Quelle und -Senke; detaillierte Metriken können je nach Quelle/Senke variieren):
Konfigurieren der Spark Log4j-Protokolle
Bisher haben wir nur die Protokollierung unseres eigenen Codes beeinflusst. Wenn wir uns jedoch die Treiberprotokolle des Clusters ansehen, sehen wir viele weitere Protokolle – tatsächlich die Mehrheit – von Spark-Interna. Wenn wir Python- oder Scala-Logger in unserem Code erstellen, beeinflusst dies nicht die Spark-internen Protokolle.
Wir werden nun untersuchen, wie die Spark-Protokolle für den Treiberknoten konfiguriert werden können, damit sie ein standardmäßiges JSON-Format verwenden, das wir leicht parsen können.
Log4j verwendet eine lokale Konfigurationsdatei, um Formatierung und Protokollebenen zu steuern, und wir können diese Konfiguration mit einem Cluster-Init-Skript (AWS | Azure | GCP) ändern. Bitte beachten Sie, dass vor DBR 11.0 Log4j v1.x verwendet wurde, das eine Java Properties (log4j.properties)-Datei verwendet. DBR 11.0+ verwendet Log4j v2.x, das stattdessen eine XML (log4j2.xml)-Datei verwendet.
Die Standard-log4j2.xml-Datei auf Databricks-Treiberknoten verwendet ein PatternLayout für ein grundlegendes Protokollformat:
Wir werden dies mit dem folgenden Init-Skript in das JsonTemplateLayout ändern:
Dieses Init-Skript tauscht einfach das PatternLayout gegen JsonTemplateLayout aus. Beachten Sie, dass Init-Skripte auf allen Knoten im Cluster ausgeführt werden, einschließlich der Worker-Knoten. In diesem Beispiel konfigurieren wir nur die Driver-Logs der Einfachheit halber und weil wir später nur die Driver-Logs erfassen werden. Die Konfigurationsdatei kann jedoch auch auf Worker-Knoten unter /home/ubuntu/databricks/spark/dbconf/log4j/executor/log4j.properties. gefunden werden.
Sie können dieses Skript nach Bedarf erweitern oder cat $LOG4J2_PATH verwenden, um den vollständigen Inhalt der ursprünglichen Datei für einfachere Änderungen anzuzeigen.
Als Nächstes laden wir dieses Init-Skript in das Unity Catalog Volume hoch. Zur Organisation erstellen wir ein separates Volume, anstatt unser rohes Log-Volume von zuvor wiederzuverwenden. Dies kann in Terraform wie folgt erreicht werden:
Dadurch wird das Volume erstellt und das Init-Skript automatisch hochgeladen.
Wir müssen jedoch noch unseren Cluster konfigurieren, um dieses Init-Skript zu verwenden. Zuvor haben wir eine Cluster Policy verwendet, um das Log Delivery-Ziel zu erzwingen, und wir können die gleiche Art von Erzwingung für dieses Init-Skript verwenden, um sicherzustellen, dass unsere Spark-Logs immer die strukturierte JSON-Formatierung haben. Wir werden die vorherige Policy JSON ändern, indem wir Folgendes hinzufügen:
Auch hier garantiert die Verwendung eines festen Werts, dass das Init-Skript immer auf dem Cluster gesetzt wird.
Wenn wir nun unseren Spark-Code von zuvor erneut ausführen, können wir alle Driver Logs im Log4j-Abschnitt schön als JSON formatiert sehen!
Erfassen der Logs
Zu diesem Zeitpunkt haben wir einfache Print-Anweisungen durch strukturiertes Logging ersetzt, dies mit den Spark-Logs vereinheitlicht und unsere Logs an ein zentrales Volume weitergeleitet. Dies ist bereits nützlich für das Durchsuchen und Herunterladen der Log-Dateien mit dem Catalog Explorer oder der Databricks CLI: databricks fs cp dbfs:/Volumes/watchtower/default/cluster_logs/cluster-logs/$CLUSTER_ID . --recursive.
Der wahre Wert dieser Logging-Hubs zeigt sich jedoch, wenn wir die Logs in eine Unity Catalog-Tabelle erfassen. Dies schließt den Kreis und gibt uns eine Tabelle, gegen die wir aussagekräftige Abfragen schreiben, Aggregationen durchführen und sogar häufige Leistungsprobleme erkennen können. All dies werden wir kurz behandeln!
Das Erfassen der Logs ist dank Lakeflow Declarative Pipelines einfach, und wir werden eine Medaillon-Architektur mit Auto Loader verwenden, um die Daten inkrementell zu laden.
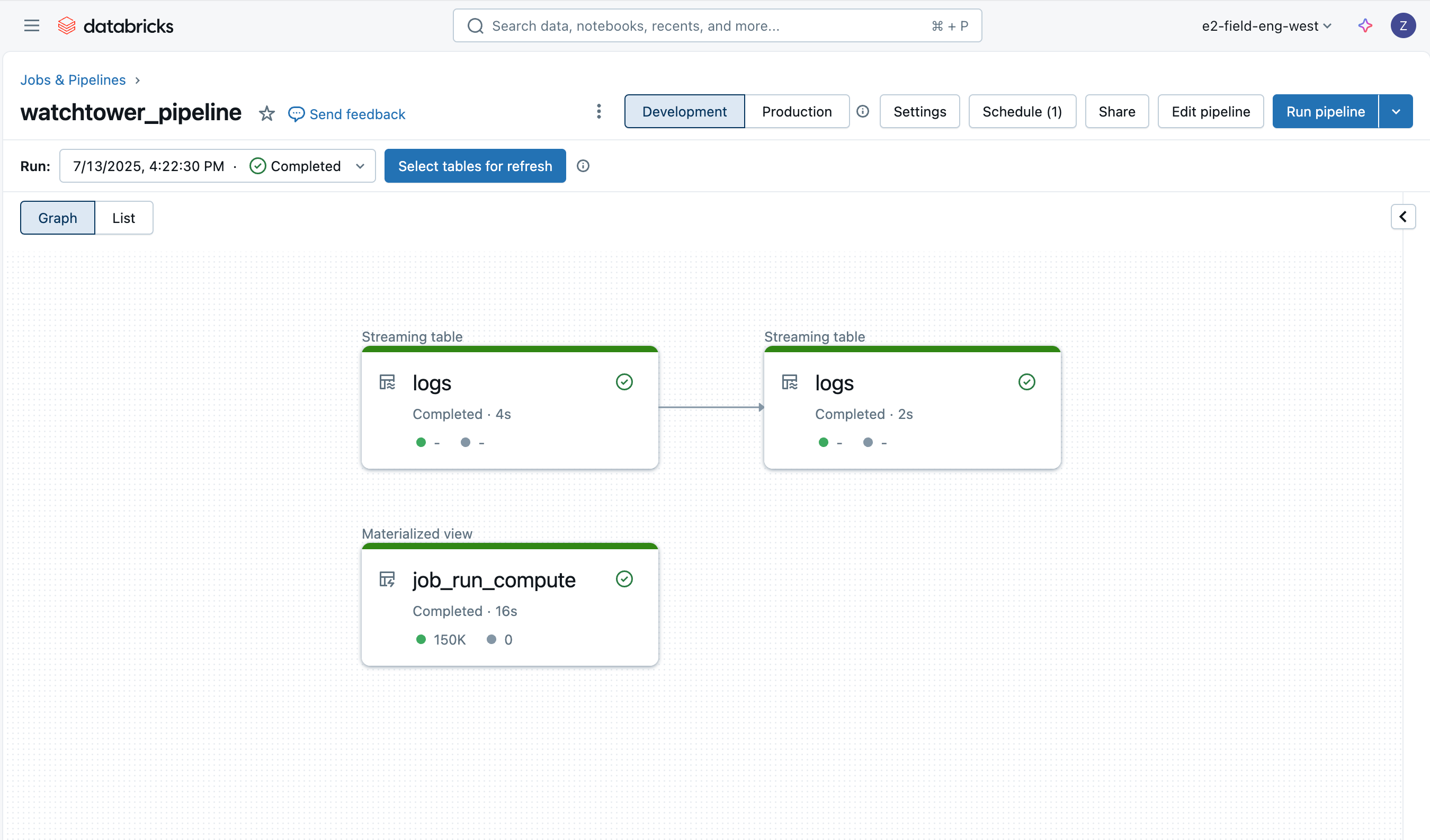
Bronze Logs
Die erste Tabelle ist einfach eine Bronze-Tabelle zum Laden der rohen Driver-Logdaten, wobei einige zusätzliche Spalten wie Dateiname, Größe, Pfad und letzter Änderungszeitpunkt hinzugefügt werden.
Mithilfe der Erwartungen von Lakeflow Declarative Pipeline (AWS | Azure | GCP) erhalten wir auch eine native Datenqualitätsüberwachung. Wir werden mehr dieser Datenqualitätsprüfungen bei den anderen Tabellen sehen.
Silver Logs
Die nächste (Silver) Tabelle ist kritischer; wir möchten jede Textzeile aus den Logs parsen und Informationen wie den Log-Level, den Log-Zeitstempel, die Cluster-ID und die Log-Quelle (stdout/stderr/log4j) extrahieren.
Hinweis: Obwohl wir JSON-Logging so weit wie möglich konfiguriert haben, werden wir immer einen gewissen Grad an Rohtext in unstrukturierter Form von anderen Tools haben, die beim Start gestartet werden. Die meisten davon werden in stdout sein, und unsere Silver-Transformation zeigt eine Möglichkeit, das Parsen flexibel zu halten, indem versucht wird, die Nachricht als JSON zu parsen und nur bei Bedarf auf Regex zurückzufallen.
Compute IDs
Die letzte Tabelle in unserer Pipeline ist eine materialisierte Ansicht, die auf Databricks System Tables aufbaut. Sie speichert die von jedem Job-Lauf verwendeten Compute-IDs und vereinfacht zukünftige Joins, wenn wir die Job-ID abrufen möchten, die bestimmte Logs erzeugt hat. Beachten Sie, dass ein einzelner Job mehrere Cluster haben kann, ebenso wie SQL-Aufgaben, die auf einem Warehouse und nicht auf einem Job-Cluster ausgeführt werden. Daher ist die Vorberechnung dieser Referenz nützlich.
Bereitstellen der Pipeline
Die Pipeline kann über die Benutzeroberfläche, Terraform oder innerhalb unseres Asset Bundles bereitgestellt werden. Wir werden das Asset Bundle verwenden und die folgende Ressourcen-YAML bereitstellen:
Logs mit KI/BI-Dashboard analysieren
Schließlich können wir die Protokolldaten über Jobs, Jobausführungen, Cluster und Arbeitsbereiche abfragen. Dank der Optimierungen der von Unity Catalog verwalteten Tabellen werden diese Abfragen auch schnell und skalierbar sein. Sehen wir uns ein paar Beispiele an.
Top N Fehler
Diese Abfrage ermittelt die häufigsten Fehler, die aufgetreten sind, und hilft bei der Priorisierung und Verbesserung der Fehlerbehandlung. Sie kann auch ein nützlicher Indikator für die Erstellung von Runbooks sein, die die häufigsten Probleme abdecken.
Top N Jobs nach Fehlern
Diese Abfrage ordnet Jobs nach der Anzahl der beobachteten Fehler, um die problematischsten Jobs zu finden.
KI/BI-Dashboard
Wenn wir diese Abfragen in ein Databricks KI/BI-Dashboard einfügen, haben wir nun eine zentrale Schnittstelle, um alle Protokolle zu durchsuchen und zu filtern, häufige Probleme zu erkennen und Fehler zu beheben.
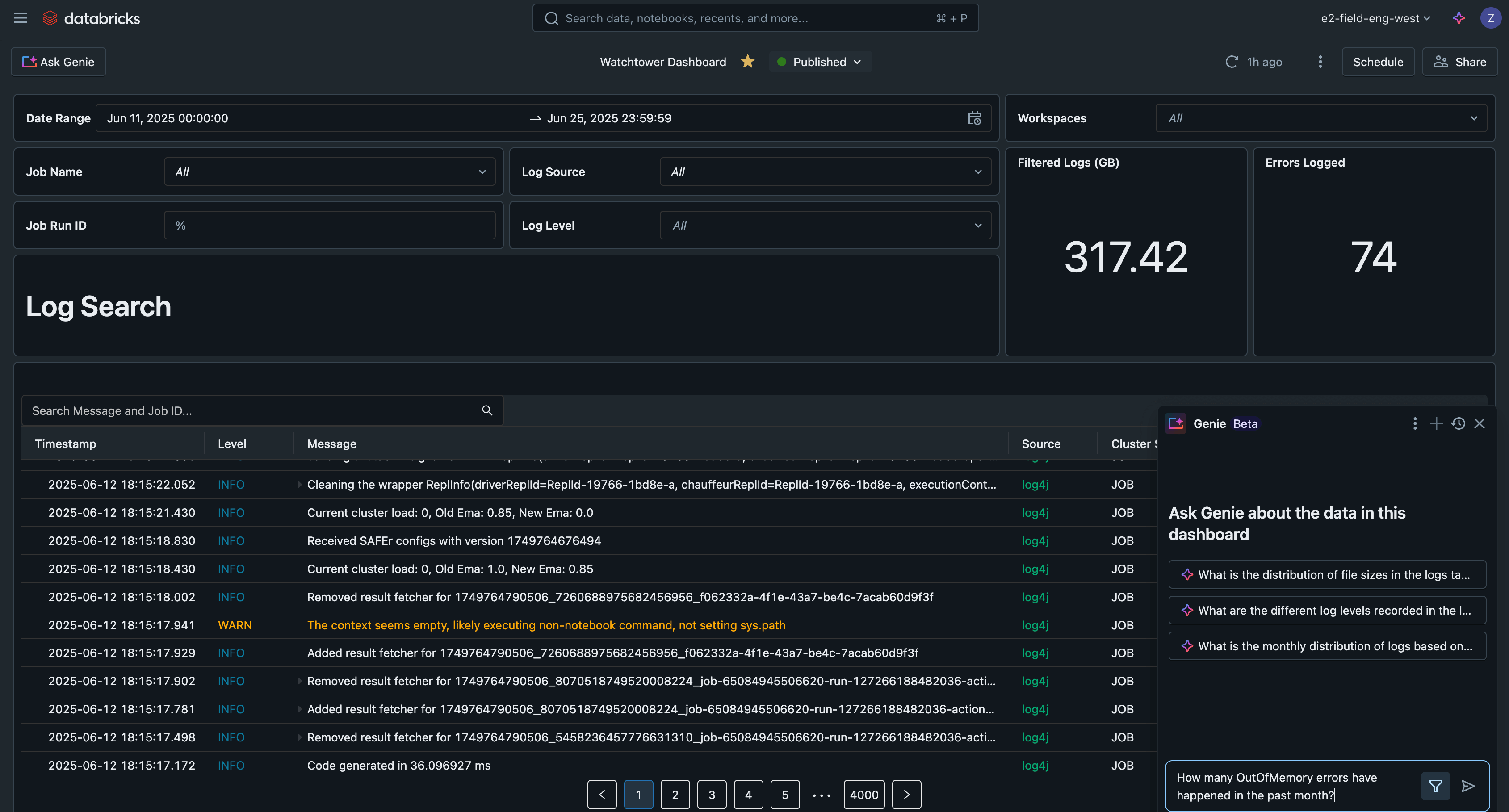
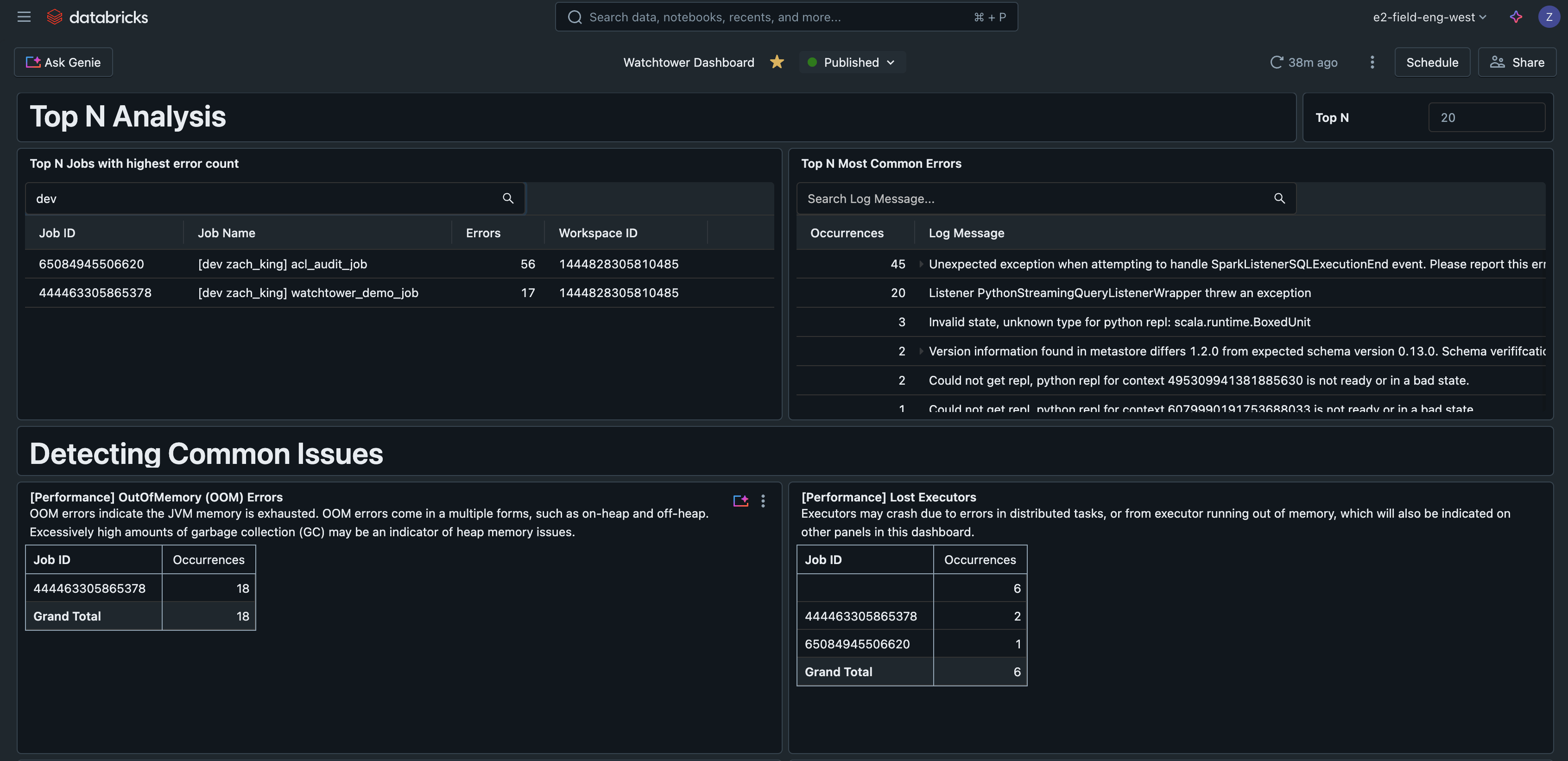
Dieses Beispiel für ein KI/BI-Dashboard ist zusammen mit allen anderen Codes für diese Lösung auf GitHub verfügbar.
Reale Szenarien
Wie wir im Referenz-Dashboard gezeigt haben, gibt es viele praktische Anwendungsfälle, die eine Protokollierungslösung wie diese unterstützt, wie zum Beispiel:
- Protokolle über alle Ausführungen eines einzelnen Jobs durchsuchen
- Protokolle über alle Jobs durchsuchen
- Protokolle auf die häufigsten Fehler analysieren
- Jobs mit der höchsten Fehleranzahl finden
- Überwachung von Leistungsproblemen oder Warnungen:
- GC-Overhead
- Spark-Überlauf
- Erkennung von PII in Protokollen
In einem realistischen Szenario springen Praktiker manuell von einer Jobausführung zur nächsten, um Fehler zu verstehen, und wissen nicht, wie sie Warnungen priorisieren sollen. Durch die Einrichtung robuster Protokolle und einer Standardtabelle zu deren Speicherung können Praktiker einfach die Protokolle nach dem häufigsten Fehler abfragen, der priorisiert werden soll. Angenommen, es gibt 1 fehlgeschlagene Jobausführung aufgrund eines OutOfMemory-Fehlers, während es 10 fehlgeschlagene Jobs aufgrund eines plötzlichen Berechtigungsfehlers gibt, als SELECT dem Dienstprinzipal unbeabsichtigt entzogen wurde; Ihr Bereitschaftsteam ist normalerweise durch die Flut von Benachrichtigungen ermüdet, kann aber jetzt schnell erkennen, dass der Berechtigungsfehler eine höhere Priorität hat und beginnt, an der Behebung des Problems zu arbeiten, um die 10 Jobs wiederherzustellen.
Ähnlich müssen Praktiker oft die Protokolle mehrerer Ausführungen desselben Jobs überprüfen, um Vergleiche anzustellen. Ein reales Beispiel ist die Korrelation von Zeitstempeln einer bestimmten Protokollnachricht aus jeder Batch-Ausführung des Jobs mit einer anderen Metrik oder einem Graphen (d. h. wann „Batch abgeschlossen“ protokolliert wurde im Vergleich zu einem Graphen des Anfrage-Durchsatzes einer API, die Sie aufgerufen haben). Die Erfassung der Protokolle vereinfacht dies, sodass wir die Tabelle abfragen und nach der Job-ID und optional einer Liste von Job-Ausführungs-IDs filtern können, ohne jede Ausführung einzeln anklicken zu müssen.
Betriebliche Überlegungen
- Cluster-Protokolle werden alle fünf Minuten geliefert und stündlich in Ihrem gewählten Zielort komprimiert.
- Denken Sie daran, von Unity Catalog verwaltete Tabellen mit Predictive Optimization und Liquid Clustering zu verwenden, um die beste Leistung auf Tabellen zu erzielen.
- Rohprotokolle müssen nicht unbegrenzt gespeichert werden, was das Standardverhalten bei der Verwendung der Cluster-Protokollbereitstellung ist. In unserer Declarative Pipelines-Pipeline verwenden Sie die Auto Loader-Option
cloudFiles.cleanSource, um Dateien nach einer bestimmten Aufbewahrungsdauer zu löschen, die ebenfalls alscloudFiles.cleanSource.retentionDurationdefiniert ist. Sie können auch Regeln für die Lebensdauer von Cloud-Speichern verwenden. - Executor-Protokolle können ebenfalls konfiguriert und erfasst werden, sind aber im Allgemeinen nicht erforderlich, da die meisten Fehler ohnehin an den Treiber weitergegeben werden.
- Erwägen Sie das Hinzufügen von Databricks SQL-Warnungen (AWS | Azure | GCP) für automatisierte Benachrichtigungen basierend auf der erfassten Protokolltabelle.
- Lakeflow Declarative Pipelines haben ihre eigenen Ereignisprotokolle, die Sie zur Überwachung und Inspektion der Pipeline-Aktivität verwenden können. Dieses Ereignisprotokoll kann auch in Unity Catalog geschrieben werden.
Integration und anstehende Aufgaben
Kunden möchten möglicherweise auch ihre Protokolle mit beliebten Protokollierungstools wie Loki, Logstash oder AWS CloudWatch integrieren. Während jede ihre eigenen Authentifizierungs-, Konfigurations- und Konnektivitätsanforderungen hat, würden diese alle einem sehr ähnlichen Muster folgen, indem sie das Cluster-Init-Skript verwenden, um einen Protokollweiterleitungsagenten zu konfigurieren und oft auszuführen.
Wichtige Erkenntnisse
Zusammenfassend lässt sich sagen, dass die wichtigsten Lektionen sind:
- Verwenden Sie standardisierte Protokollierungs-Frameworks, keine Print-Anweisungen, in der Produktion.
- Verwenden Sie Cluster-weite Init-Skripte, um die Log4j-Konfiguration anzupassen.
- Konfigurieren Sie die Cluster-Protokollbereitstellung, um Protokolle zu zentralisieren.
- Verwenden Sie von Unity Catalog verwaltete Tabellen mit Predictive Optimization und Liquid Clustering für die beste Tabellenleistung.
- Databricks ermöglicht es Ihnen, Protokolle für eine umfassendere Analyse zu erfassen und anzureichern.
Nächste Schritte
Beginnen Sie noch heute mit der Produktionsreifmachung Ihrer Protokolle, indem Sie sich das GitHub-Repository für diese vollständige Lösung hier ansehen: https://github.com/databricks-industry-solutions/watchtower!
Databricks Delivery Solutions Architects (DSAs) beschleunigen Daten- und KI-Initiativen in Organisationen. Sie bieten architektonische Führung, optimieren Plattformen für Kosten und Leistung, verbessern die Entwicklererfahrung und treiben die erfolgreiche Projektausführung voran. DSAs schließen die Lücke zwischen anfänglicher Bereitstellung und produktionsreifen Lösungen und arbeiten eng mit verschiedenen Teams zusammen, darunter Data Engineering, technische Leiter, Führungskräfte und andere Stakeholder, um maßgeschneiderte Lösungen und eine schnellere Wertschöpfung zu gewährleisten. Um von einem maßgeschneiderten Ausführungsplan, strategischer Beratung und Unterstützung während Ihrer Daten- und KI-Reise durch einen DSA zu profitieren, wenden Sie sich bitte an Ihr Databricks Account Team.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.