Primärschlüssel- und Fremdschlüsselbeschränkungen sind jetzt allgemein verfügbar und ermöglichen schnellere Abfragen
von Xinyi Yu, Justin Talbot und Serge Rielau
Databricks freut sich, die allgemeine Verfügbarkeit (GA) von Primärschlüssel- (PK) und Fremdschlüssel- (FK) Einschränkungen bekannt zu geben, beginnend mit Databricks Runtime 15.2 und Databricks SQL 2024.30. Diese Veröffentlichung folgt auf eine sehr erfolgreiche öffentliche Vorschau, die von Hunderten von wöchentlich aktiven Kunden angenommen wurde, und stellt einen weiteren wichtigen Meilenstein bei der Verbesserung der Datenintegrität und der Verwaltung relationaler Daten im Lakehouse dar.
Darüber hinaus kann Databricks diese Einschränkungen nun zur Optimierung von Abfragen verwenden und unnötige Operationen aus dem Abfrageplan eliminieren, was zu einer deutlich schnelleren Leistung führt.
Primärschlüssel- und Fremdschlüssel-Einschränkungen
Primärschlüssel (PKs) und Fremdschlüssel (FKs) sind wesentliche Elemente in relationalen Datenbanken und bilden die grundlegenden Bausteine für die Datenmodellierung. Sie liefern Informationen über die Datenbeziehungen im Schema an Benutzer, Tools und Anwendungen und ermöglichen Optimierungen, die Einschränkungen nutzen, um Abfragen zu beschleunigen. Primär- und Fremdschlüssel sind jetzt allgemein für Ihre Delta Lake-Tabellen verfügbar, die in Unity Catalog gehostet werden.
SQL-Sprache
Sie können Einschränkungen beim Erstellen einer Tabelle definieren:
Im obigen Beispiel definieren wir eine Primärschlüssel-Einschränkung für die Spalte UserID. Databricks unterstützt auch Einschränkungen für Spaltengruppen.
Sie können auch vorhandene Delta-Tabellen ändern, um Einschränkungen hinzuzufügen oder zu entfernen:
Hier erstellen wir den Primärschlüssel namens products_pk für die nicht-nullable Spalte ProductID in einer vorhandenen Tabelle. Um diese Operation erfolgreich auszuführen, müssen Sie der Eigentümer der Tabelle sein. Beachten Sie, dass Einschränkungsnamen innerhalb des Schemas eindeutig sein müssen.
Der nachfolgende Befehl entfernt den Primärschlüssel durch Angabe des Namens.
Der gleiche Prozess gilt für Fremdschlüssel. Die folgende Tabelle definiert zwei Fremdschlüssel bei der Tabellenerstellung:
Weitere Details zur Syntax und zu Operationen im Zusammenhang mit Einschränkungen finden Sie in der Dokumentation zu den Anweisungen CREATE TABLE und ALTER TABLE.
Primärschlüssel- und Fremdschlüssel-Einschränkungen werden in der Databricks-Engine nicht erzwungen, können aber nützlich sein, um eine Datenintegritätsbeziehung anzuzeigen, die gelten soll. Databricks kann stattdessen Primärschlüssel-Einschränkungen als Teil der Ingest-Pipeline vorgelagert erzwingen. Weitere Informationen zu erzwungenen Einschränkungen finden Sie unter Managed data quality with Delta Live Tables. Databricks unterstützt auch erzwungene NOT NULL- und CHECK-Einschränkungen (weitere Informationen finden Sie in der Constraints-Dokumentation).
Partner-Ökosystem
Tools und Anwendungen wie die neueste Version von Tableau und PowerBI können Ihre Primärschlüssel- und Fremdschlüsselbeziehungen von Databricks über JDBC- und ODBC-Konnektoren automatisch importieren und nutzen.
Einschränkungen anzeigen
Es gibt mehrere Möglichkeiten, die in der Tabelle definierten Primärschlüssel- und Fremdschlüssel-Einschränkungen anzuzeigen. Sie können auch einfach SQL-Befehle verwenden, um Einschränkungsinformationen mit dem Befehl DESCRIBE TABLE EXTENDED anzuzeigen:
Catalog Explorer und Entity Relationship Diagram
Sie können die Einschränkungsinformationen auch über den Catalog Explorer anzeigen:
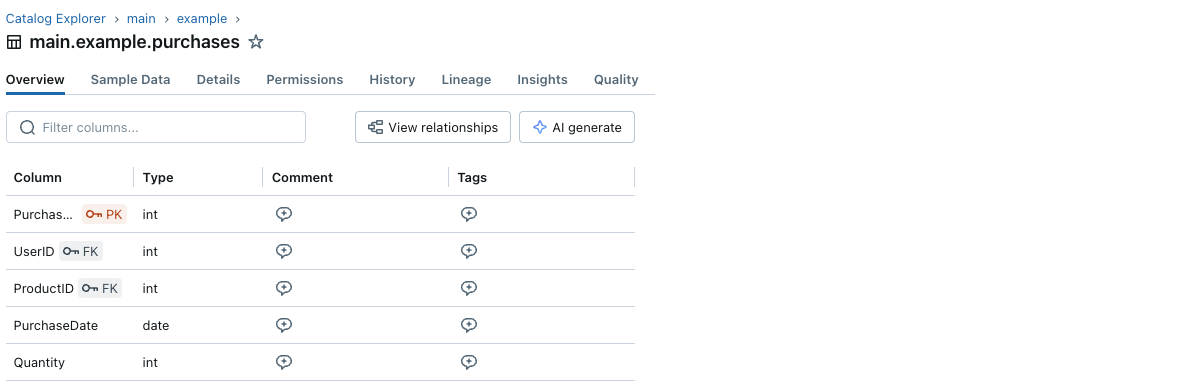
Jede Primärschlüssel- und Fremdschlüsselspalte hat ein kleines Schlüsselsymbol neben ihrem Namen.
Und Sie können die Primärschlüssel- und Fremdschlüsselinformationen und die Beziehungen zwischen Tabellen mit dem Entity Relationship Diagram im Catalog Explorer visualisieren. Unten sehen Sie ein Beispiel für eine Tabelle purchases, die auf zwei Tabellen verweist: users und products:

INFORMATION SCHEMA
Die folgenden INFORMATION_SCHEMA-Tabellen liefern ebenfalls Einschränkungsinformationen:
TABLE_CONSTRAINTS: Beschreibt Metadaten für alle Primär- und Fremdschlüssel-Einschränkungen im Katalog.KEY_COLUMN_USAGE: Listet die Spalten der Primär- oder Fremdschlüssel-Einschränkungen im Katalog auf.CONSTRAINT_TABLE_USAGE: Beschreibt die Einschränkungen, die auf Tabellen im Katalog verweisen.CONSTRAINT_COLUMN_USAGE: Beschreibt die Einschränkungen, die auf Spalten im Katalog verweisen.REFERENTIAL_CONSTRAINTS: Beschreibt referentielle (Fremdschlüssel-) Einschränkungen, die im Katalog definiert sind.
Verwenden Sie die RELY-Option, um Optimierungen zu aktivieren
Wenn Sie wissen, dass die Primärschlüssel-Einschränkung gültig ist (z. B. weil Ihre Datenpipeline oder Ihr ETL-Job sie erzwingt), können Sie Optimierungen basierend auf der Einschränkung aktivieren, indem Sie sie mit der RELY-Option angeben, z. B.:
Die Verwendung der RELY-Option ermöglicht es Databricks, Abfragen auf Arten zu optimieren, die von der Gültigkeit der Einschränkung abhängen, da Sie garantieren, dass die Datenintegrität gewahrt bleibt. Seien Sie hier vorsichtig, denn wenn eine Einschränkung als RELY markiert ist, die Daten aber gegen die Einschränkung verstoßen, können Ihre Abfragen falsche Ergebnisse liefern.
Wenn Sie die RELY-Option für eine Einschränkung nicht angeben, ist der Standard NORELY. In diesem Fall können Einschränkungen immer noch für Informations- oder statistische Zwecke verwendet werden, aber Abfragen verlassen sich nicht auf sie, um korrekt ausgeführt zu werden.
Die RELY-Option und die sie nutzenden Optimierungen sind derzeit für Primärschlüssel verfügbar und werden bald auch für Fremdschlüssel verfügbar sein.
Sie können den Primärschlüssel einer Tabelle ändern, um zu ändern, ob er RELY oder NORELY ist, indem Sie ALTER TABLE verwenden, zum Beispiel:
Beschleunigen Sie Ihre Abfragen, indem Sie unnötige Aggregationen eliminieren
Eine einfache Optimierung, die wir mit RELY-Primärschlüssel-Einschränkungen durchführen können, ist die Eliminierung unnötiger Aggregate. Zum Beispiel in einer Abfrage, die eine DISTINCT-Operation auf eine Tabelle mit einem Primärschlüssel mit RELY anwendet:
Wir können die unnötige DISTINCT-Operation entfernen:
Wie Sie sehen können, basiert diese Abfrage auf der Gültigkeit der RELY-Primärschlüssel-Einschränkung – wenn es doppelte Kunden-IDs in der Kundentabelle gibt, gibt die transformierte Abfrage falsche doppelte Ergebnisse zurück. Sie sind dafür verantwortlich, die Gültigkeit der Einschränkung zu erzwingen, wenn Sie die RELY-Option festlegen.
Wenn der Primärschlüssel NORELY (Standard) ist, entfernt der Optimizer die DISTINCT-Operation nicht aus der Abfrage. Sie läuft dann möglicherweise langsamer, gibt aber immer korrekte Ergebnisse zurück, auch wenn Duplikate vorhanden sind. Wenn der Primärschlüssel RELY ist, kann Databricks die DISTINCT-Operation entfernen, was die Abfrage erheblich beschleunigen kann – im obigen Beispiel um etwa das 2-fache.
Beschleunigen Sie Ihre Abfragen durch Eliminierung unnötiger Joins
Eine weitere sehr nützliche Optimierung, die wir mit RELY-Primärschlüsseln durchführen können, ist die Eliminierung unnötiger Joins. Wenn eine Abfrage eine Tabelle joined, die nirgendwo außer in der Join-Bedingung referenziert wird, kann der Optimizer feststellen, dass der Join unnötig ist und ihn aus dem Abfrageplan entfernen.
Als Beispiel nehmen wir an, wir haben eine Abfrage, die zwei Tabellen joined: store_sales und customer, joined über den Primärschlüssel der Kundentabelle PRIMARY KEY (c_customer_sk) RELY.
Wenn wir den Primärschlüssel nicht hätten, könnte jede Zeile von store_sales potenziell mit mehreren Zeilen in customer übereinstimmen, und wir müssten den Join ausführen, um den korrekten SUM-Wert zu berechnen. Da die Tabelle customer jedoch über ihren Primärschlüssel joined wird, wissen wir, dass der Join eine Zeile für jede Zeile von store_sales ausgibt.
Die Abfrage benötigt also eigentlich nur die Spalte ss_quantity aus der Faktentabelle store_sales. Daher kann der Abfrageoptimizer den Join vollständig aus der Abfrage eliminieren und sie in Folgendes umwandeln:
Dies läuft viel schneller, da der gesamte Join vermieden wird – in diesem Beispiel beobachten wir, wie die Optimierung die Abfrage von 1,5 Minuten auf 6 Sekunden beschleunigt!. Und die Vorteile können noch größer sein, wenn der Join viele Tabellen umfasst, die eliminiert werden können!
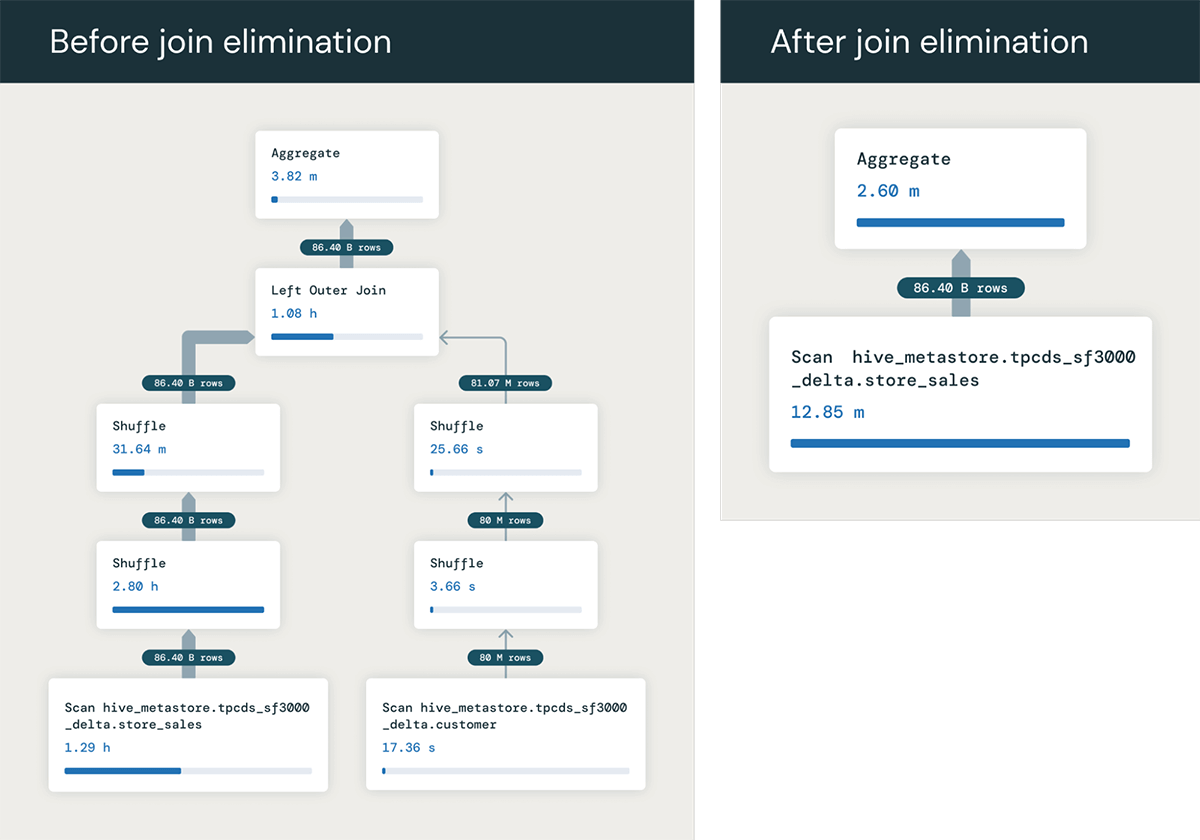
Sie fragen sich vielleicht, warum jemand eine solche Abfrage ausführen würde? Das ist tatsächlich viel häufiger, als Sie vielleicht denken! Ein häufiger Grund ist, dass Benutzer Views erstellen, die mehrere Tabellen miteinander verbinden, z. B. viele Fakten- und Dimensionstabellen. Sie schreiben Abfragen über diese Views, die oft Spalten aus nur einigen der Tabellen verwenden, nicht aus allen – und so kann der Optimizer die Joins mit den Tabellen eliminieren, die in jeder Abfrage nicht benötigt werden. Dieses Muster ist auch in vielen Business Intelligence (BI)-Tools üblich, die oft Abfragen generieren, die viele Tabellen in einem Schema verbinden, auch wenn eine Abfrage nur Spalten aus einigen der Tabellen verwendet.
Fazit
Seit der öffentlichen Vorschau haben über 2600+ Databricks-Kunden Primär- und Fremdschlüsselbeschränkungen genutzt. Heute freuen wir uns, die allgemeine Verfügbarkeit dieser Funktion bekannt zu geben, was eine neue Phase in unserem Engagement für die Verbesserung der Datenverwaltung und -integrität in Databricks markiert.
Darüber hinaus nutzt Databricks jetzt Schlüsselbeschränkungen mit der RELY-Option zur Optimierung von Abfragen, z. B. durch die Eliminierung unnötiger Aggregate und Joins, was zu einer deutlich schnelleren Abfrageleistung führt.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.