Veröffentlichen in mehreren Katalogen und Schemas aus einer einzigen DLT-Pipeline
Vereinfachen Sie die Syntax, optimieren Sie Kosten und reduzieren Sie die betriebliche Komplexität
von Zoé Durand, Jonathan Chang und Matt Jones
- Unterstützung für mehrere Schemata und Kataloge: Veröffentlichen Sie aus einer einzigen DLT-Pipeline in mehrere Schemata und Kataloge.
- Vereinfachte Syntax und reduzierte Kosten: Eliminieren Sie das LIVE-Schlüsselwort und reduzieren Sie den Infrastrukturaufwand.
- Bessere Beobachtbarkeit: Veröffentlichen Sie Event-Logs in Unity Catalog und verwalten Sie Daten über verschiedene Speicherorte hinweg mit SQL und Python.
DLT bietet eine robuste Plattform zum Erstellen zuverlässiger, wartbarer und testbarer Datenverarbeitungs-Pipelines innerhalb von Databricks. Durch die Nutzung seines deklarativen Frameworks und die automatische Bereitstellung optimaler serverloser Rechenleistung vereinfacht DLT die Komplexität von Streaming, Datentransformation und -verwaltung und liefert Skalierbarkeit und Effizienz für moderne Daten-Workflows.
Wir freuen uns, eine lang erwartete Verbesserung ankündigen zu können: die Möglichkeit, Tabellen in mehreren Schemas und Katalogen innerhalb einer einzigen DLT-Pipeline zu veröffentlichen. Diese Funktion reduziert die betriebliche Komplexität, senkt die Kosten und vereinfacht die Datenverwaltung, indem sie es Ihnen ermöglicht, Ihre Medaillon-Architektur (Bronze, Silber, Gold) in einer einzigen Pipeline zu konsolidieren und gleichzeitig organisatorische und Governance-Best-Practices beizubehalten.
Mit dieser Verbesserung können Sie:
- Vereinfachen Sie die Pipeline-Syntax – Keine Notwendigkeit für die
LIVE-Syntax, um Abhängigkeiten zwischen Tabellen zu kennzeichnen. Vollständig und teilweise qualifizierte Tabellennamen werden unterstützt, zusammen mitUSE SCHEMAundUSE CATALOG-Befehlen, genau wie in Standard-SQL. - Reduzieren Sie die betriebliche Komplexität – Verarbeiten und veröffentlichen Sie alle Tabellen innerhalb einer einheitlichen DLT-Pipeline, wodurch separate Pipelines pro Schema oder Katalog überflüssig werden.
- Senken Sie die Kosten – Minimieren Sie den Infrastruktur-Overhead, indem Sie mehrere Workloads in einer einzigen Pipeline konsolidieren.
- Verbessern Sie die Beobachtbarkeit – Veröffentlichen Sie Ihr Event-Log als Standardtabelle im Unity Catalog Metastore für verbesserte Überwachung und Governance.
„Die Möglichkeit, von einer DLT-Pipeline aus in mehrere Kataloge und Schemas zu veröffentlichen – und nicht mehr das LIVE-Schlüsselwort zu benötigen – hat uns geholfen, Best Practices für Pipelines zu standardisieren, unsere Entwicklungsbemühungen zu optimieren und den einfachen Übergang von Teams von Nicht-DLT-Workloads zu DLT im Rahmen unserer groß angelegten unternehmensweiten Einführung des Toolings zu erleichtern.“ —Ron DeFreitas, Principal Data Engineer, HealthVerity

Erste Schritte
Pipeline erstellen
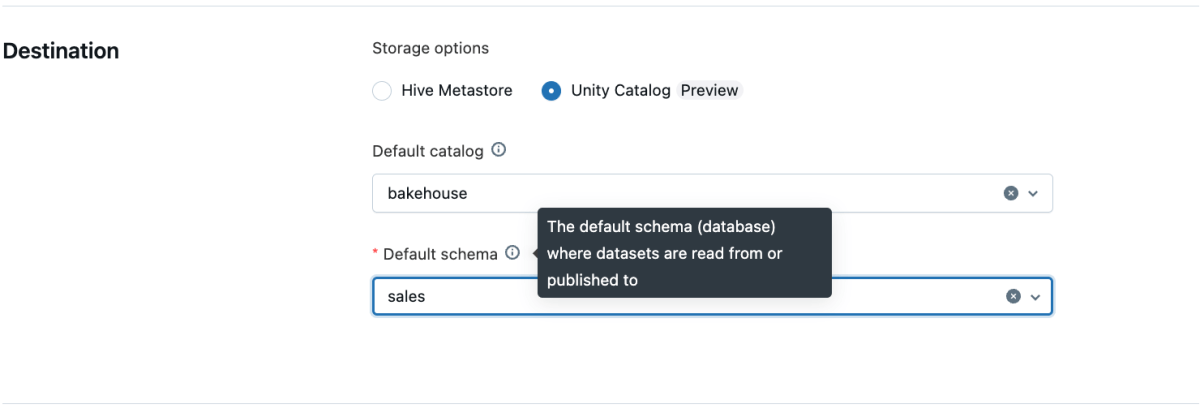
Alle Pipelines, die über die Benutzeroberfläche erstellt werden, unterstützen jetzt standardmäßig mehrere Kataloge und Schemas. Sie können einen Standardkatalog und ein Standardschema auf Pipeline-Ebene über die Benutzeroberfläche, die API oder Databricks Asset Bundles (DABs) festlegen.
Über die Benutzeroberfläche:
- Erstellen Sie wie gewohnt eine neue Pipeline.
- Legen Sie den Standardkatalog und das Standardschema in den Pipeline-Einstellungen fest.
Über die API:
Wenn Sie eine Pipeline programmgesteuert erstellen, können Sie diese Funktion aktivieren, indem Sie das Feld schema in den PipelineSettings angeben. Dies ersetzt das vorhandene Feld target und stellt sicher, dass Datasets über mehrere Kataloge und Schemas hinweg veröffentlicht werden können.
Um eine Pipeline mit dieser Funktion über die API zu erstellen, können Sie diesem Codebeispiel folgen (Hinweis: Personal Access Token-Authentifizierung muss für den Workspace aktiviert sein):
Durch Festlegen des Feldes schema unterstützt die Pipeline automatisch die Veröffentlichung von Tabellen in mehreren Katalogen und Schemas, ohne dass das Schlüsselwort LIVE erforderlich ist.
Vom DAB
- Stellen Sie sicher, dass Ihre Databricks CLI Version v0.230.0 oder höher hat. Wenn nicht, aktualisieren Sie die CLI gemäß der Dokumentation.
- Richten Sie die Databricks Asset Bundle (DAB) Umgebung ein, indem Sie der Dokumentation folgen. Wenn Sie diese Schritte befolgen, sollten Sie ein DAB-Verzeichnis haben, das von der Databricks CLI generiert wurde und alle Konfigurations- und Quellcodedateien enthält.
- Finden Sie die YAML-Datei, die die DLT-Pipeline definiert, unter:
<your dab folder>/<resource>/<pipeline_name>_pipeline.yml - Legen Sie das Feld
schemain der Pipeline-YAML fest und entfernen Sie das Feldtarget, falls es vorhanden ist. - Führen Sie „
databricks bundle validate“ aus, um zu überprüfen, ob die DAB-Konfiguration gültig ist. - Führen Sie „
databricks bundle deploy -t <environment>“ aus, um Ihre erste DPM-Pipeline bereitzustellen!
„Die Funktion funktioniert genau so, wie wir es erwarten! Ich konnte die verschiedenen Datasets innerhalb von DLT in unsere Stage-, Core- und UDM-Schemas (im Grunde ein Bronze-, Silber-, Gold-Setup) innerhalb einer einzigen Pipeline aufteilen.“ —Florian Duhme, Expert Data Software Developer, Arvato

Tabellen in mehreren Katalogen und Schemas veröffentlichen
Sobald Ihre Pipeline eingerichtet ist, können Sie Tabellen mit vollständig oder teilweise qualifizierten Namen sowohl in SQL als auch in Python definieren.
SQL-Beispiel
Python-Beispiel
Datasets lesen
Sie können Datasets mit vollständig oder teilweise qualifizierten Namen referenzieren, wobei das LIVE-Schlüsselwort aus Gründen der Abwärtskompatibilität optional ist.
SQL-Beispiel
Python-Beispiel
API-Verhaltensänderungen
Mit dieser neuen Funktion wurden wichtige API-Methoden aktualisiert, um mehrere Kataloge und Schemas nahtloser zu unterstützen:
dlt.read() und dlt.read_stream()
Früher konnten diese Methoden nur Datasets referenzieren, die innerhalb der aktuellen Pipeline definiert wurden. Jetzt können sie Datasets über mehrere Kataloge und Schemas hinweg referenzieren und dabei automatisch Abhängigkeiten verfolgen. Dies erleichtert den Aufbau von Pipelines, die Daten aus verschiedenen Quellen integrieren, ohne zusätzliche manuelle Konfiguration.
spark.read() und spark.readStream()
Früher erforderten diese Methoden explizite Referenzen auf externe Datasets, was abteilungsübergreifende Abfragen umständlicher machte. Mit dem neuen Update werden Abhängigkeiten nun automatisch verfolgt und das LIVE-Schema ist nicht mehr erforderlich. Dies vereinfacht den Prozess des Lesens von Daten aus mehreren Quellen innerhalb einer einzigen Pipeline.
USE CATALOG und USE SCHEMA verwenden
Die Databricks SQL-Syntax unterstützt jetzt das dynamische Festlegen aktiver Kataloge und Schemas, wodurch die Verwaltung von Daten an mehreren Standorten erleichtert wird.
SQL-Beispiel
Python-Beispiel
Event Logs in Unity Catalog verwalten
Diese Funktion ermöglicht es Pipeline-Besitzern auch, Event Logs im Unity Catalog Metastore zu veröffentlichen, um die Beobachtbarkeit zu verbessern. Um dies zu aktivieren, geben Sie das Feld event_log in der Pipeline-Einstellungen-JSON an. Zum Beispiel:
Damit können Sie nun GRANTS auf die Event Log-Tabelle ausstellen, genau wie bei jeder regulären Tabelle:
Sie können auch eine Ansicht über die Event Log-Tabelle erstellen:
Außerdem können Sie von der Event Log-Tabelle streamen:
Wie geht es weiter?
Zukünftig werden diese Verbesserungen zum Standard für alle neu erstellten Pipelines, egal ob über die Benutzeroberfläche, die API oder Databricks Asset Bundles erstellt. Zusätzlich wird bald ein Migrationstool verfügbar sein, das bei der Umstellung bestehender Pipelines auf das neue Publishing-Modell hilft.
Lesen Sie mehr in der Dokumentation hier.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.