Erweiterung der Grenzen für Datenagenten mit Genie
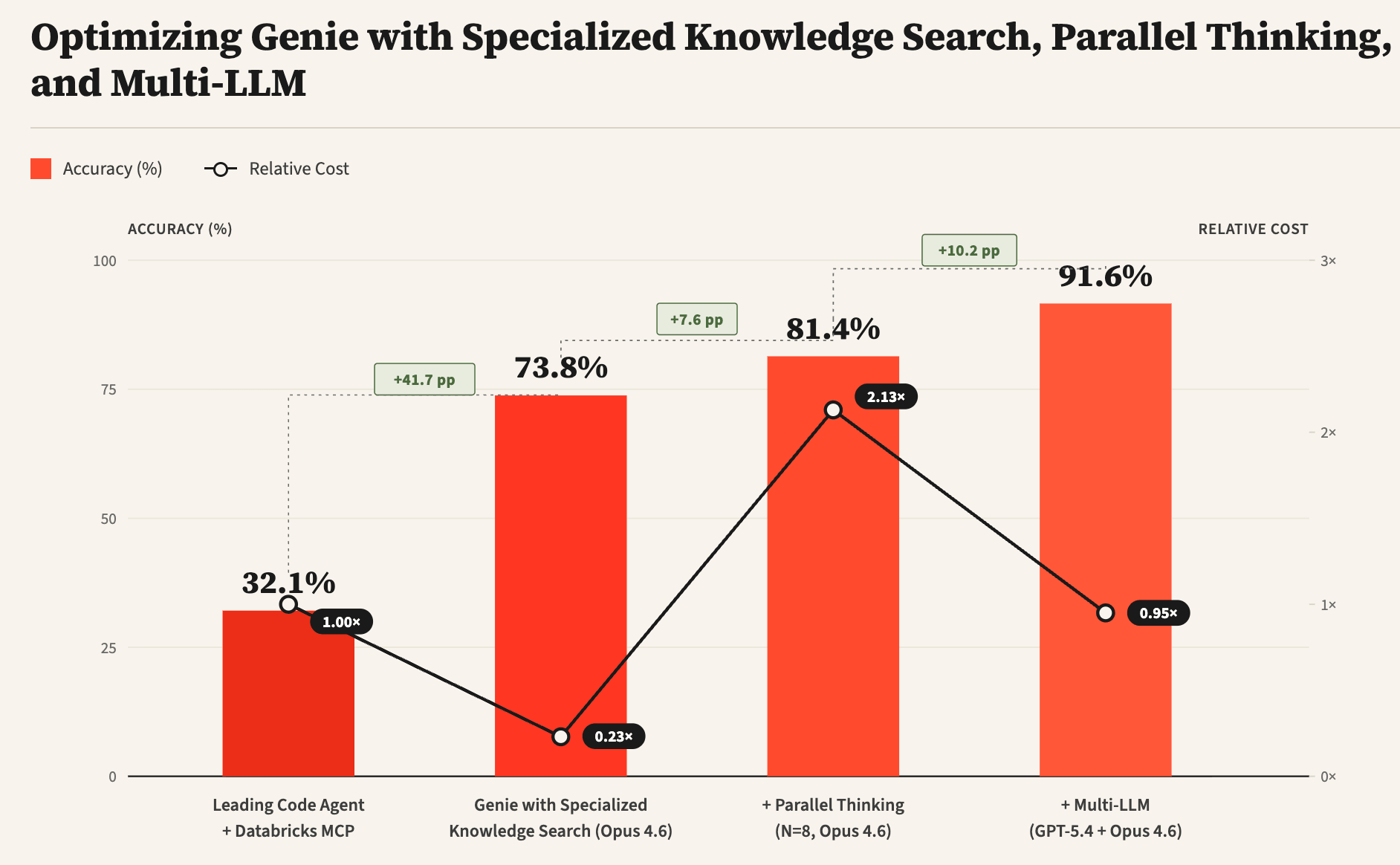
Genie ist der hochmoderne Datenagent von Databricks, der für die Beantwortung komplexer Fragen zu Unternehmensdaten entwickelt wurde und sowohl strukturierte (Tabellen, Dashboards, Notebooks usw.) als auch unstrukturierte (Arbeitsbereichsdateien, Google Drive, Sharepoint usw.) Datenquellen umfasst. Dieser Blog beschreibt einige der einzigartigen Herausforderungen, denen sich Datenagenten stellen müssen, und stellt Techniken zu ihrer Bewältigung vor, darunter spezialisierte Wissenssuche, paralleles Denken und Multi-LLM-Designs. Aus unseren Experimenten mit einem internen Benchmark von realen Datenanalysen beobachten wir, dass diese Techniken die Gesamtgenauigkeit von Genie im Vergleich zu einem führenden Coding-Agenten (von 32 % auf über 90 %) erheblich verbessern und gleichzeitig die Kosten und die Latenz deutlich reduzieren können.
Wichtige Herausforderungen für Datenagenten
Coding-Agenten haben gezeigt, dass ein leistungsstarkes LLM unglaubliche Dinge autonom leisten kann, wenn es mit Werkzeugen ausgestattet ist, die ihm helfen, den Codekontext zu verstehen. Während Coding-Agenten in statischen, deterministischen Umgebungen wie dem Dateisystem einer Festplatte effektiv arbeiten, führen Daten-Agenten ein völlig neues Paradigma ein. Datenagenten arbeiten innerhalb eines dynamischen, sich ständig weiterentwickelnden Data Lakehouse, das eine Fülle von semantischem Kontext über Hunderttausende von Tabellen, Notebooks, Dashboards und Dokumenten umfasst.
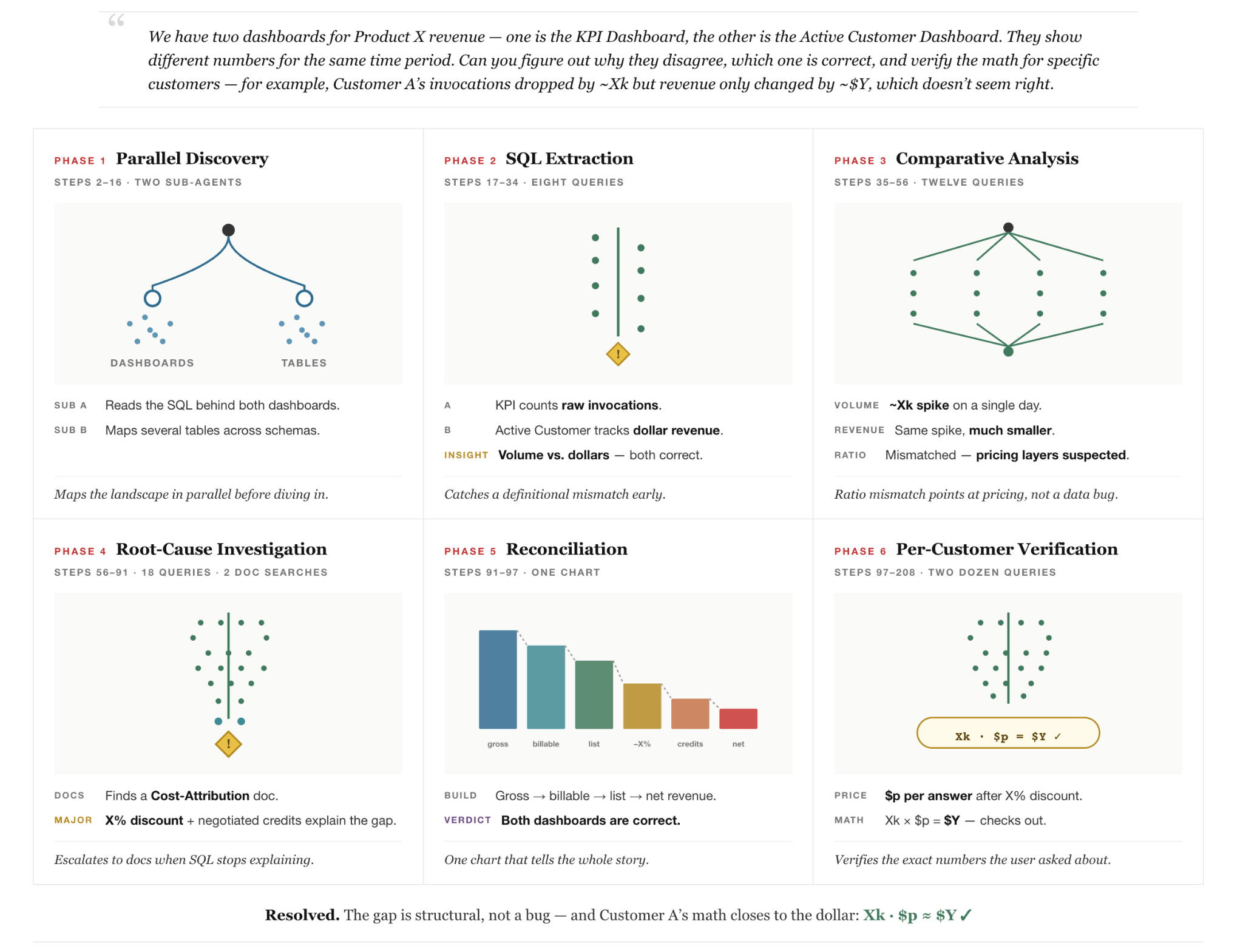
Betrachten Sie zum Beispiel eine echte (anonymisierte) Abfrage eines internen Benutzers in Abbildung 2: Der Benutzer bemerkt, dass zwei Unternehmens-Dashboards, die den Umsatz desselben Produkts melden, widersprüchliche Spitzen an verschiedenen Daten aufweisen, und bittet den Agenten, dies zu erklären. Diese vernünftige Frage ist trügerisch schwierig, da keine einzelne Datenquelle die Antwort enthält und die Beantwortung der Frage eine systemübergreifende Entdeckung über Tabellen, interne Dokumente und Dashboards hinweg erfordert und die Einrichtung von mehrtägigen Berichten verstanden werden muss. Darüber hinaus muss der Agent Unternehmenspreisdetails untersuchen, um Vertragssätze zu finden. Schließlich muss der Agent in der Lage sein, sich automatisch zu korrigieren, wenn Zwischenberechnungen anfängliche Annahmen als falsch aufzeigen. Die Abbildung zeigt, wie der Agent die Aufgabe erfolgreich lösen kann, indem er in verschiedenen Phasen vorgeht: (1) parallele Multi-Agenten-Datenerkennung, (2) Datenuntersuchung, (3) Selbstkorrekturschleife und (4) Verifizierung.
Im Vergleich zu Coding-Agenten haben Datenagenten drei wichtige, einzigartige Herausforderungen:
- Umfang der Datenerkennung: Das Finden der richtigen Datenquellen zur Beantwortung der Benutzerabfrage ist eine der größten Herausforderungen für Unternehmenskunden mit Millionen von strukturierten und unstrukturierten Quellen (wie Tabellen, Dashboards und Dokumenten), ein Umfang, der herkömmliche Suchmethoden bricht.
- Bestimmung des „Source of Truth“-Geschäftswissens: Die Beantwortung von Geschäftsfragen erfordert tiefes, spezifisches Wissen, das aus vielen Quellen (z. B. Tabellenmetadaten, Unternehmensdokumenten, internen Nachrichten) stammt, die oft veraltet, widersprüchlich oder überholt sind, was den Agenten zwingt, die maßgeblichste Information zu ermitteln.
- Mangel an verifizierbaren Tests: Im Gegensatz zu Coding-Agenten, die deterministische, verifizierbare Tests verwenden können, um Code iterativ zu verfeinern, haben Datenagenten keinen entsprechenden Test, da die „Spezifikation“ nur die High-Level-Benutzerabfrage ohne die Vorstellung einer erwarteten korrekten Antwort ist. Darüber hinaus sind die Abfragen möglicherweise nicht immer beantwortbar, da die Daten unvollständig sind, und es ist wichtig, dass Datenagenten solche Fälle identifizieren und an die Benutzer zurückmelden können.
Wichtige technische Fortschritte
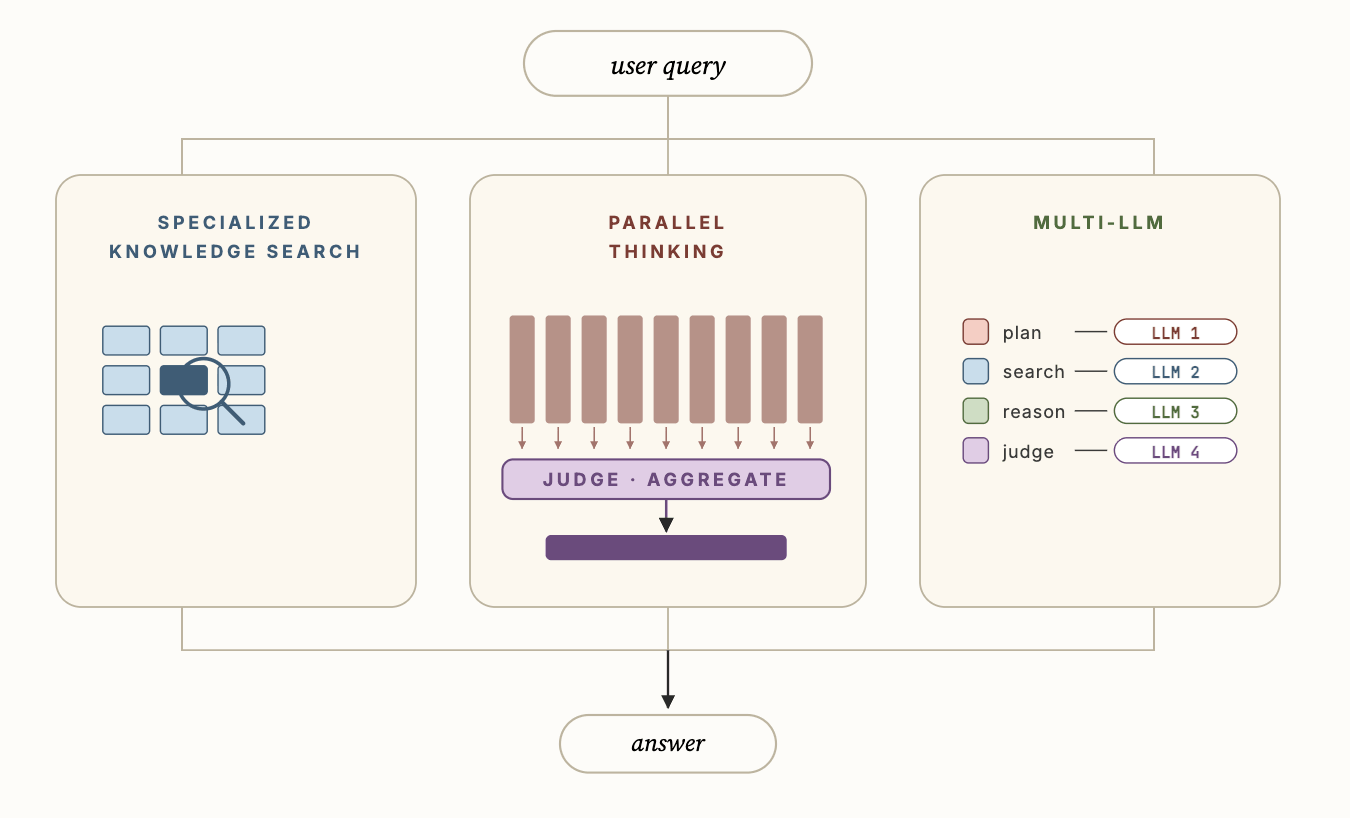
Abbildung 3 zeigt einige der wichtigsten technischen Innovationen in Genie, die es ihm ermöglichen, deutlich besser als generische Coding-Agenten zu funktionieren, nämlich: i) Spezialisierte Wissenssuche, ii) Paralleles Denken und iii) Multi-LLM. Die spezialisierte Wissenssuche nutzt semantische kontextbezogene Daten, um die Sub-Agenten für die Asset-Erkennung zu verankern und die Suchqualität erheblich zu verbessern. Paralleles Denken ermöglicht es dem Agenten, mehrere verschiedene Trajektorien zu sampeln und dann die Ergebnisse über die Trajektorien hinweg zu aggregieren, um die endgültige Antwort zu berechnen. Schließlich ermöglicht Multi-LLM dem Agenten, verschiedene LLMs für jeden der verschiedenen Sub-Agenten zusammen mit ihren optimierten Prompts zu verwenden, um die Gesamtgenauigkeit und Latenz weiter zu verbessern.
Spezialisierte Wissenssuche
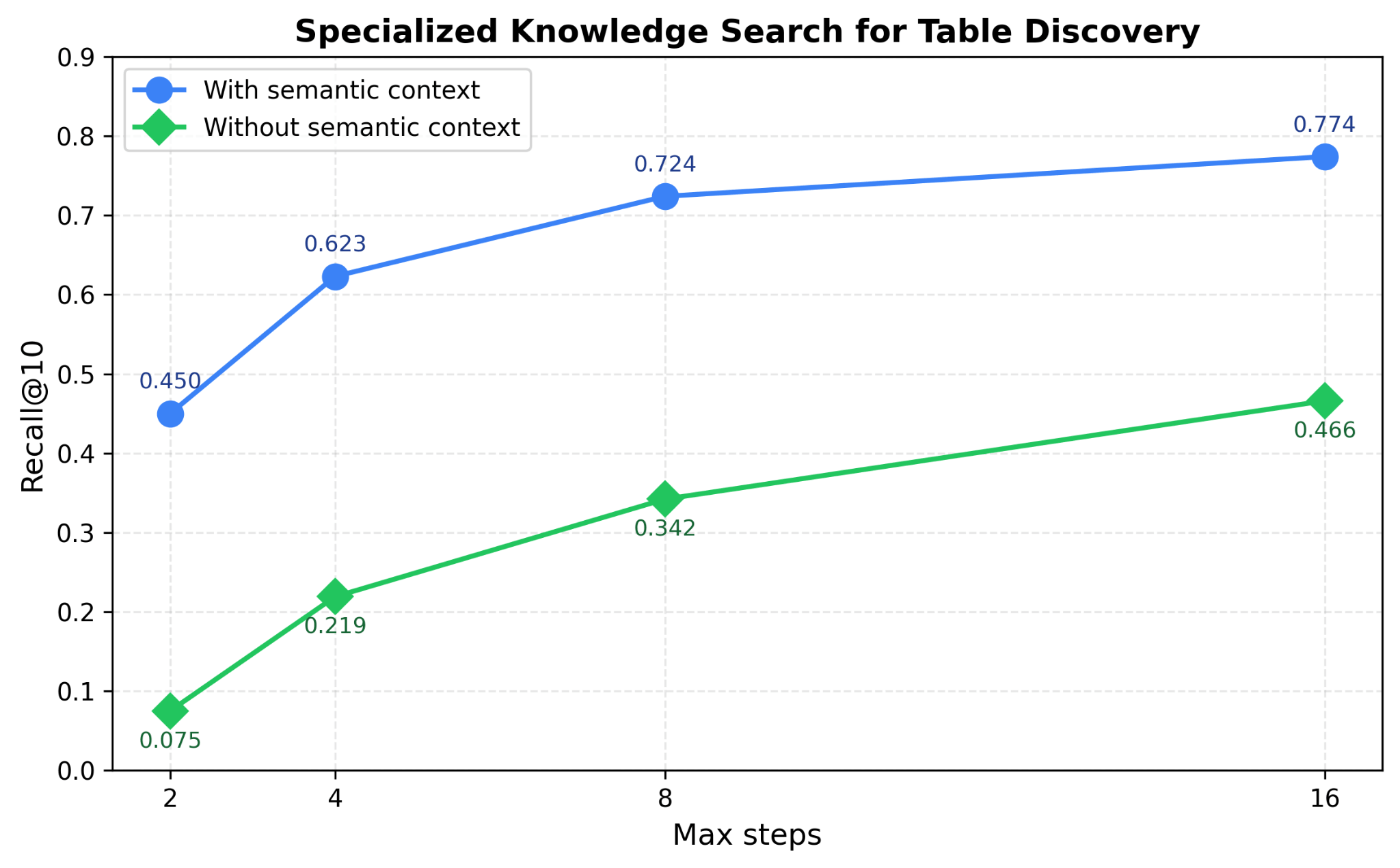
Genie nutzt bestehende Datenassets wie Tabellen, Notebooks, Dashboards, Dokumente und Dateien aus dem Arbeitsbereich, um einen reichhaltigen semantischen Unternehmenskontext abzuleiten und nutzt diesen Kontext dann, um einen Suchindex zu erstellen. Es verwendet mehrere Suchindizes parallel zusammen mit reichhaltigen Metadatensignalen, um die relevantesten Assets für eine Benutzerabfrage effizient zu entdecken. Abbildung 4 zeigt, wie die Nutzung der spezialisierten Wissenssuche Genie hilft, die Leistung der Tabellensuche in unseren Benchmarks zur Tabellenerkennung um bis zu 40 % zu verbessern.
Paralleles Denken
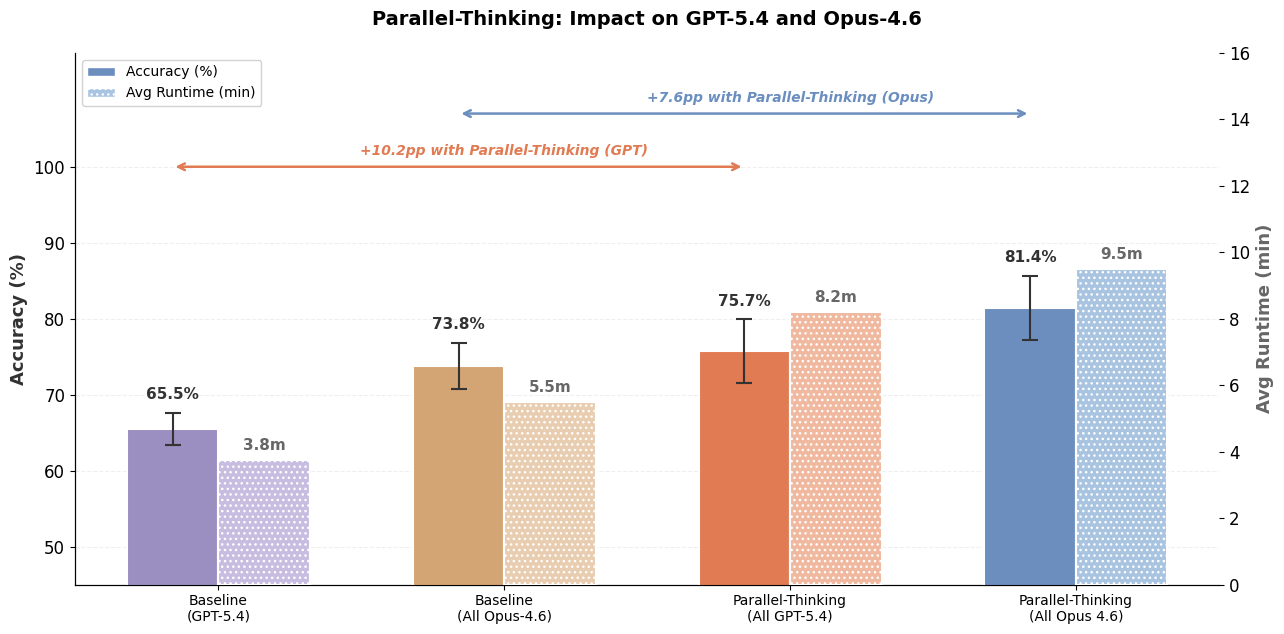
Im Gegensatz zu Softwareentwicklungsaufgaben, bei denen Coding-Agenten zuerst Tests schreiben können, um die gewünschte Funktionalität zu überprüfen, und dann die Codegenerierung iterieren, bis die Tests bestanden sind, gibt es für offene Datenabfragen keine entsprechenden Unit-Tests. In Ermangelung von Tests ist es für Datenagenten schwierig zu wissen, ob die generierte Antwort korrekt ist oder weitere Verfeinerung benötigt. Um diese Herausforderung zu bewältigen, nutzen wir paralleles Denken, indem wir mehrere Trajektorien sampeln und relevante Informationen über die Trajektorien hinweg aggregieren, um die endgültige Antwort zu berechnen. Abbildung 5 zeigt, wie paralleles Denken die Antwortgenauigkeit erheblich verbessern kann, wenn auch mit etwas zusätzlicher Latenz und Token-Kosten. Darüber hinaus kann, wie in Abbildung 1 gezeigt, die Kombination von Multi-LLM und weiteren Optimierungen die Kosten und die Latenz weiter erheblich reduzieren.
Multi-LLM
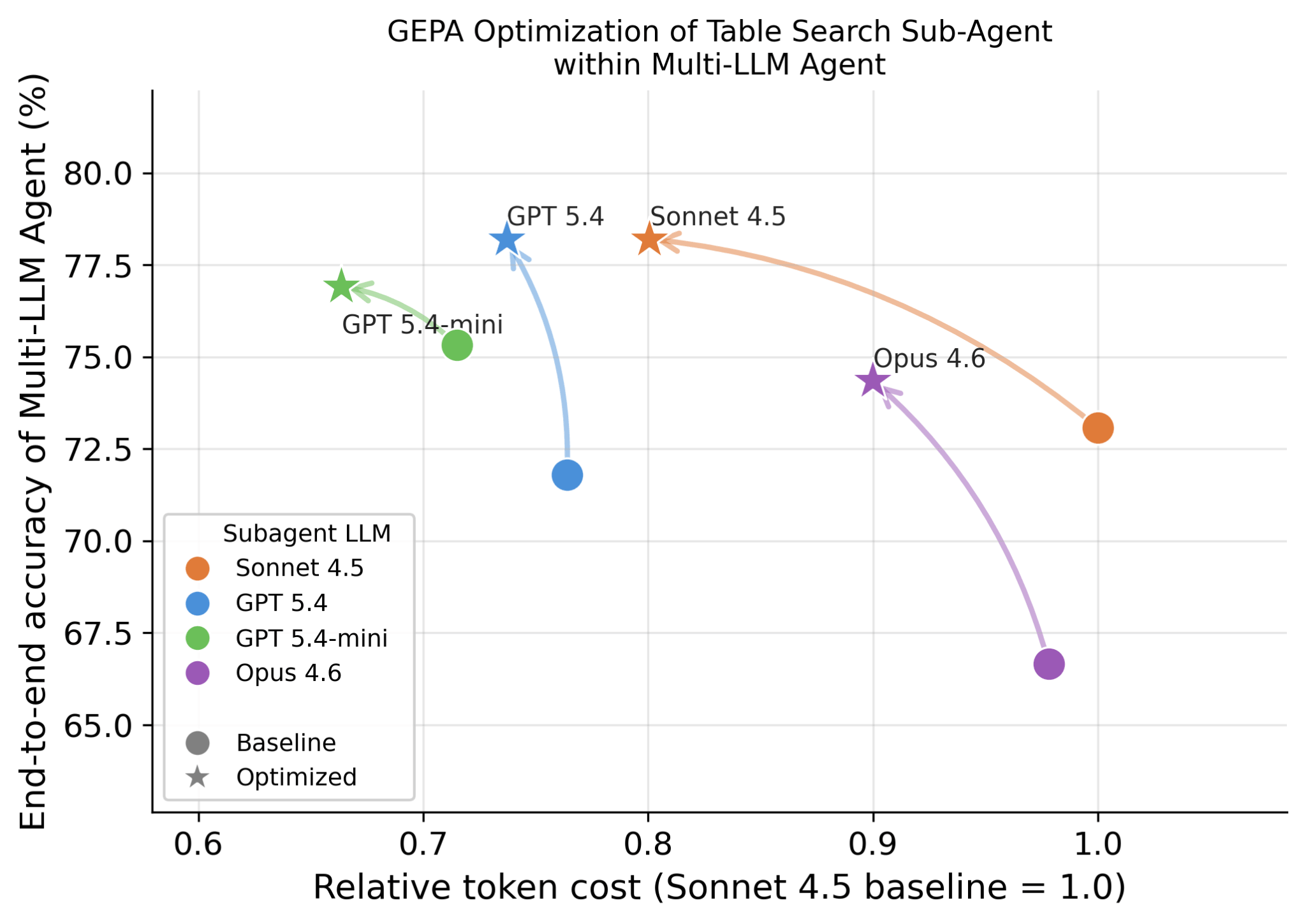
Einer der wichtigsten technischen Fortschritte in Genie ist die Fähigkeit, verschiedene LLMs für verschiedene Sub-Agenten zu nutzen, da wir feststellen, dass verschiedene LLMs gut in komplementären Fähigkeiten sind. Zum Beispiel kann es ein anderes LLM für die Planungsphase, ein anderes LLM für verschiedene Such-Sub-Agenten, ein weiteres für die Codegenerierung und Richter verwenden. Mit der Databricks-Plattform ist es nahtlos möglich, alle Spitzenmodelle (einschließlich Opus, GPT und Gemini), Open-Source-Modelle sowie benutzerdefinierte trainierte Modelle auszuprobieren. Neben der Genauigkeit stellen wir auch fest, dass verschiedene LLMs zu sehr unterschiedlichen Latenz- und Kostenmerkmalen führen. Abbildung 6 zeigt, wie verschiedene LLMs bei Tabellensuchaufgaben abschneiden und wie die entsprechende Genauigkeit und die Kosten durch Methoden wie GEPA weiter optimiert werden können.
Schlussfolgerung
Während sich Codierung und Datenanalyse konzeptionell ähneln, stellt die dynamische Natur von Enterprise-Datensystemen einige einzigartige Herausforderungen dar. Datenagenten müssen die richtigen Assets aus einem großen Unternehmenskontext effizient entdecken, „Wahrheit“ in einer mehrdeutigen Umgebung ermitteln und effizienten Code und Abfragen schreiben, um die Fragen der Benutzer korrekt zu beantworten. Wir haben mehrere neuartige Ansätze entwickelt, um diese Probleme zu lösen, wie z. B. spezialisierte Wissenssuchen, um reichhaltige semantische Informationen und mehrere Metadatensignale zu nutzen, Multi-LLM, um verschiedene LLMs mit optimierten Prompts unter Verwendung von GEPA zu nutzen, und paralleles Denken, um die Gesamtgenauigkeit weiter zu verbessern. Durch die Hinzufügung dieser Ansätze zu Genie erzielt es bei den Benchmark-Aufgaben eine deutlich bessere Leistung als führende Coding-Agenten. Es gibt noch viele herausfordernde offene Fragen zu erforschen, und es war noch nie eine aufregendere Zeit, Forschung in diesem Bereich des Aufbaus hochmoderner Datenagenten für Unternehmen zu betreiben.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.