PySpark Native Plotting
Erstellen Sie ganz einfach Visualisierungen direkt aus PySpark DataFrames
von Xinrong Meng und Ruifeng Zheng
- Einführung in PySpark Native Plotting: Dieser Blog erklärt die Notwendigkeit integrierter Visualisierungsfunktionen in PySpark, die mit der Funktionalität übereinstimmen, die Benutzer von Pandas API on Spark und nativen Pandas DataFrames erwarten.
- Hauptmerkmale und Fähigkeiten: Wir erklären verschiedene unterstützte Diagrammtypen, wie PySpark Plotting effiziente Datenverarbeitungsstrategien nutzt (z. B. Sampling, globale Metriken) und die Integration mit Plotly für Visualisierungen.
- Praktisches Beispiel: Wir demonstrieren PySpark Plotting mit einem praktischen Beispiel, führen die Leser durch die Erstellung und Anpassung von Visualisierungen und heben umsetzbare Erkenntnisse hervor, die aus den Diagrammen gewonnen wurden.
Einleitung
Wir freuen uns, Ihnen das native Plotting in PySpark mit dem Databricks Runtime 17.0 (Release Notes) vorzustellen – ein aufregender Fortschritt für die Datenvisualisierung. Sie müssen nicht mehr zwischen verschiedenen Tools wechseln, nur um Ihre Daten zu visualisieren; jetzt können Sie direkt aus Ihren PySpark DataFrames ansprechende, intuitive Diagramme erstellen. Es ist schnell, nahtlos und direkt integriert. Diese lang erwartete Funktion macht die Datenexploration einfacher und leistungsfähiger als je zuvor.
Die Arbeit mit Big Data in PySpark war schon immer leistungsstark, insbesondere wenn es um die Transformation und Analyse großer Datensätze geht. Während PySpark DataFrames für Skalierbarkeit und Leistung konzipiert sind, mussten Benutzer sie bisher in Pandas API on Apache Spark™ DataFrames konvertieren, um Diagramme zu erstellen. Aber dieser zusätzliche Schritt machte Visualisierungs-Workflows komplizierter als nötig. Der Unterschied in der Struktur zwischen PySpark und Pandas-Style DataFrames führte oft zu Reibungsverlusten und verlangsamte den Prozess der visuellen Datenexploration.
Beispiel
Hier ist ein Beispiel für die Verwendung von PySpark Plotting zur Analyse von Umsatz, Gewinn und Gewinnmargen über verschiedene Produktkategorien hinweg.
Wir beginnen mit einem DataFrame, der Umsatz- und Gewinndaten für verschiedene Produktkategorien enthält, wie unten gezeigt:
Unser Ziel ist es, die Beziehung zwischen Umsatz und Gewinn zu visualisieren und gleichzeitig die Gewinnmarge als zusätzliche visuelle Dimension einzubeziehen, um die Analyse aussagekräftiger zu gestalten. Hier ist der Code zum Erstellen des Diagramms:
Beachten Sie, dass „fig“ vom Typ „plotly.graph_objs._figure.Figure“ ist. Wir können sein Aussehen verbessern, indem wir das Layout mit vorhandenen Plotly-Funktionalitäten aktualisieren. Die angepasste Abbildung sieht wie folgt aus:
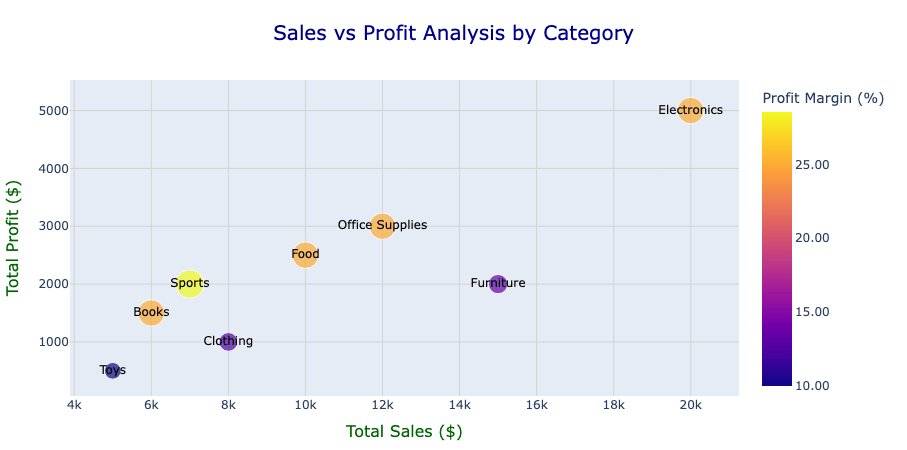
Aus der Abbildung können wir klare Beziehungen zwischen Umsatz und Gewinn in verschiedenen Kategorien erkennen. Zum Beispiel zeigt Electronics hohe Umsätze und Gewinne bei einer relativ moderaten Gewinnmarge, was auf eine starke Umsatzgenerierung, aber Raum für verbesserte Effizienz hindeutet.
Funktionen von PySpark Plotting
Benutzeroberfläche
Der Benutzer interagiert mit PySpark Plotting, indem er die `plot`-Eigenschaft eines PySpark DataFrames aufruft und den gewünschten Diagrammtyp entweder als Unter-Methode angibt oder den Parameter „kind“ setzt. Zum Beispiel:
oder äquivalent:
Dieses Design orientiert sich an den Schnittstellen der Pandas API on Apache Spark und des nativen Pandas und bietet eine konsistente und intuitive Erfahrung für Benutzer, die bereits mit Pandas Plotting vertraut sind.
Unterstützte Diagrammtypen
PySpark Plotting unterstützt eine Vielzahl gängiger Diagrammtypen wie Linien-, Balken- (einschließlich horizontaler), Flächen-, Streu-, Kreis-, Box-, Histogramm- und Dichte-/KDE-Diagramme. Dies ermöglicht es Benutzern, Trends, Verteilungen, Vergleiche und Beziehungen direkt aus PySpark DataFrames zu visualisieren.
Interna
Die Funktion wird von Plotly (Version 4.8 oder höher) als Standard-Visualisierungs-Backend angetrieben und bietet reichhaltige, interaktive Plotting-Funktionen, während natives pandas intern zur Datenverarbeitung für die meisten Diagramme verwendet wird.
Abhängig vom Diagrammtyp wird die Datenverarbeitung in PySpark Plotting über eine von drei Strategien gehandhabt:
- Top N Zeilen: Der Plotting-Prozess verwendet eine begrenzte Anzahl von Zeilen aus dem DataFrame (Standard: 1000). Dies kann mit der Option „spark.sql.pyspark.plotting.max_rows“ konfiguriert werden und ist somit effizient für schnelle Einblicke. Dies gilt für Balkendiagramme, horizontale Balkendiagramme und Kreisdiagramme.
- Sampling: Zufälliges Sampling repräsentiert effektiv die Gesamtverteilung, ohne den gesamten Datensatz zu verarbeiten. Dies gewährleistet Skalierbarkeit bei gleichzeitiger Beibehaltung der Repräsentativität. Dies gilt für Flächendiagramme, Liniendiagramme und Streudiagramme.
- Globale Metriken: Für Boxplots, Histogramme und Dichte-/KDE-Diagramme werden Berechnungen über den gesamten Datensatz durchgeführt. Dies ermöglicht eine genaue Darstellung der Datenverteilungen und gewährleistet statistische Korrektheit.
Dieser Ansatz respektiert die Plotting-Strategien der Pandas API on Apache Spark für jeden Diagrammtyp, mit zusätzlichen Leistungsverbesserungen:
- Sampling: Zuvor waren zwei Durchläufe über den gesamten Datensatz erforderlich – einer zur Berechnung des Sampling-Verhältnisses und ein weiterer zur Durchführung des eigentlichen Samplings. Wir haben eine neue Methode basierend auf Reservoir-Sampling implementiert, die dies auf einen einzigen Durchlauf reduziert.
- Subplots: Für Fälle, in denen jede Spalte einem Subplot entspricht, berechnen wir nun Metriken für alle Spalten gemeinsam, was die Effizienz verbessert.
- ML-basierte Plots: Wir haben dedizierte interne SQL-Ausdrücke für diese Plots eingeführt, die SQL-seitige Optimierungen wie Code-Generierung ermöglichen.
Fazit
PySpark Native Plotting schließt die Lücke zwischen PySpark und intuitiver Datenvisualisierung. Diese Funktion ermöglicht es PySpark-Benutzern, hochwertige Diagramme direkt aus ihren PySpark DataFrames zu erstellen, wodurch die Datenanalyse schneller und zugänglicher als je zuvor wird. Probieren Sie diese Funktion gerne auf Databricks Runtime 17.0 aus, um Ihre Datenvisualisierungserfahrung zu verbessern!
Bereit, mehr zu entdecken? Schauen Sie sich die PySpark API-Dokumentation für detaillierte Anleitungen und Beispiele an.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.