Echtzeit-Entscheidungsfindung für KI-Agenten: Warum Sie zuerst eine Customer Context Layer benötigen
Eine Snowplow-Perspektive auf Scott Brinkers „The New Martech Stack for the AI Age“
von Alex Dean
- Scott Brinker hat kürzlich einen Forschungsbericht mit Databricks veröffentlicht, „The New Martech “Stack” for the AI Age“, der einen Wandel von starren Stacks hin zu einer flexiblen, komponierbaren Leinwand für Marketingarchitektur in den nächsten 3-5 Jahren beschreibt.
- Alex Dean, Mitbegründer und CEO von Snowplow, teilt seine Perspektive darauf, wie die Kundens kontextschicht Echtzeit-Verhaltensdaten erfasst, die KI-Agenten für sofortige Entscheidungen nutzen.
- Die agentische Feedbackschleife macht Marketing zu einem Schwungrad: Erfassen und vereinheitlichen Sie menschliches und KI-Verhalten in Echtzeit, aktivieren Sie es für Entscheidungen und schließen Sie dann die Schleife, damit Agenten kontinuierlich aus Ergebnissen lernen und sich verbessern.
Scott Brinker's neuer Bericht mit Databricks formuliert etwas, das ich seit Jahren Gestalt annehmen sehe: Der Martech-"Stack", die bekannte Tetris-Anordnung von Kästen, beginnt sich aufzulösen. An seine Stelle tritt, was Scott eine komponierbare Leinwand nennt: eine flüssige, datenzentrierte Architektur, in der KI-Agenten und benutzerdefinierte Software auf gemeinsamen Daten operieren, anstatt sich durch Integrationspipelines zu kämpfen.
Beim Lesen nickte ich mehr als einmal zustimmend. Nicht, weil es eine einfache These ist (es ist tatsächlich eine ziemlich radikale Neuausrichtung, wie Unternehmen über Marketingtechnologie denken), sondern weil sie eine architektonische Richtung beschreibt, der wir uns bei Snowplow vor langer Zeit verschrieben haben, oft schon bevor es dafür eine gemeinsame Terminologie gab.
Ich wollte ein paar Reaktionen teilen: Wo der Bericht stark Anklang findet, wie wir denken, dass Snowplow in die beschriebene Architektur passt, und eine Dimension, die ich dem Modell hinzufügen würde und die meiner Meinung nach wichtiger wird, wenn KI-Agenten eine größere Rolle bei Kundeninteraktionen übernehmen.
Die Datenplattform ist jetzt der Schwerpunkt für Echtzeit-Entscheidungen
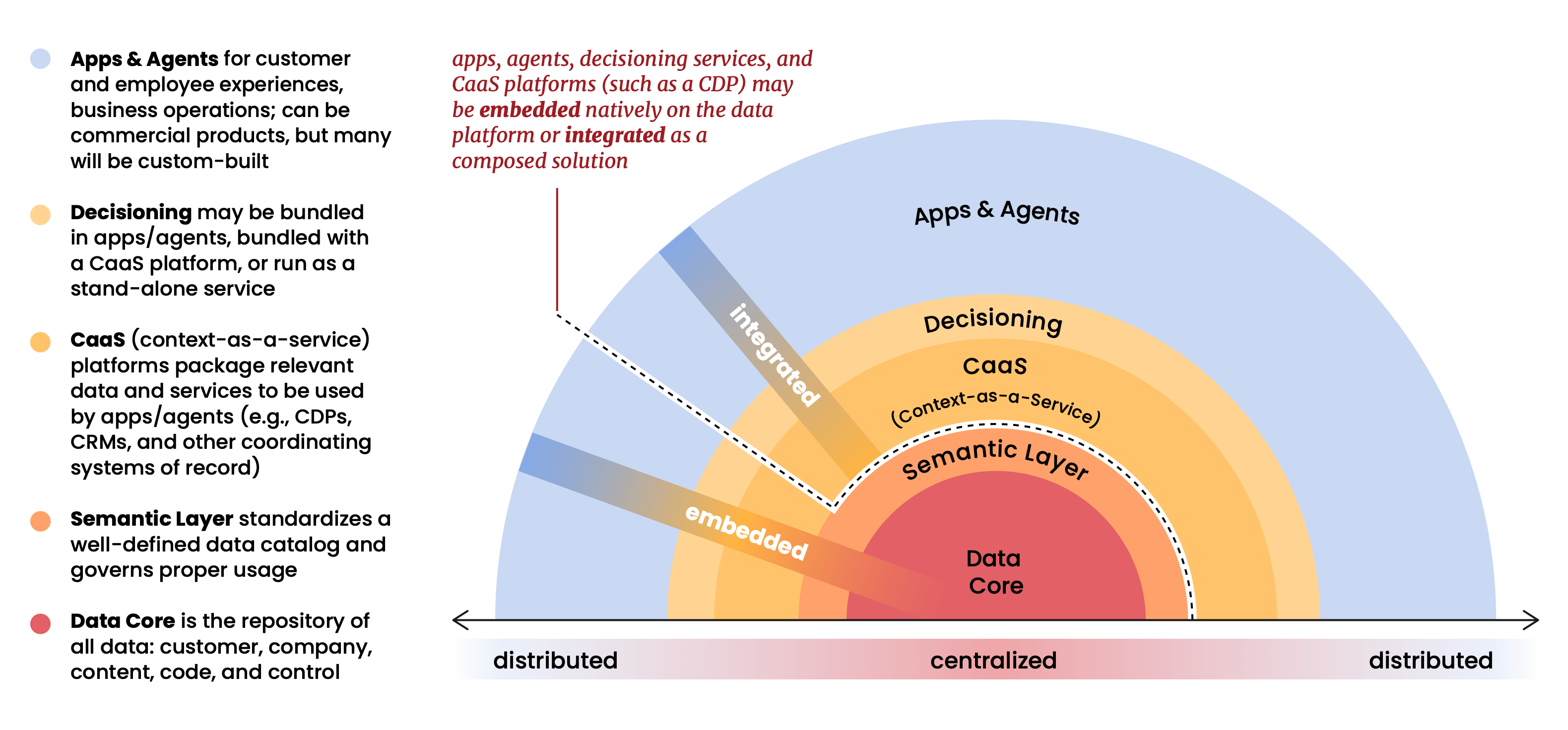
Das zentrale strukturelle Argument des Berichts ist, dass die Datenplattform (Databricks, Snowflake, BigQuery usw.) zum Gravitationszentrum des gesamten Martech-Stacks geworden ist. Anwendungen, Agenten und Analysen sitzen nicht mehr auf den Daten; sie operieren darin. Die Datenplattform ist nicht mehr nur ein Repository am unteren Ende des Stacks. Sie ist der Stack.
Dies ist eine Ansicht, die wir bei Snowplow seit langem vertreten, und sie hat viele frühe Entscheidungen über die Produktentwicklung geprägt. Als wir Snowplow 2012 entwickelten, war das vorherrschende Modell, Kundendaten in Anbietersystemen zu sammeln und darauf verwalteten Zugriff zu gewähren. Wir verfolgten den entgegengesetzten Ansatz: Ihre Daten gehören in Ihre Infrastruktur, unterliegen Ihren Regeln und sind mit jedem von Ihnen gewählten Tool abfragbar. Damals erschien uns das wie eine prinzipientreue architektonische Haltung, vielleicht sogar eine leicht konträre. Wie dieser Bericht deutlich macht, ist es jetzt die einzige Architektur, die in großem Maßstab sinnvoll ist.
Was ist die Customer Context Layer? Und warum Echtzeit-Entscheidungen davon abhängen
Was ist die Customer Context Layer? Die Customer Context Layer ist die Echtzeit-Verhaltensinfrastruktur, die zwischen Ihrer Datenbasis und Ihren kundenorientierten Systemen liegt. Sie ist direkt mit digitalen Erlebnissen verbunden, damit KI-Agenten verstehen können, was ein Kunde gerade tut, zusätzlich zu seiner gesamten historischen Reise.
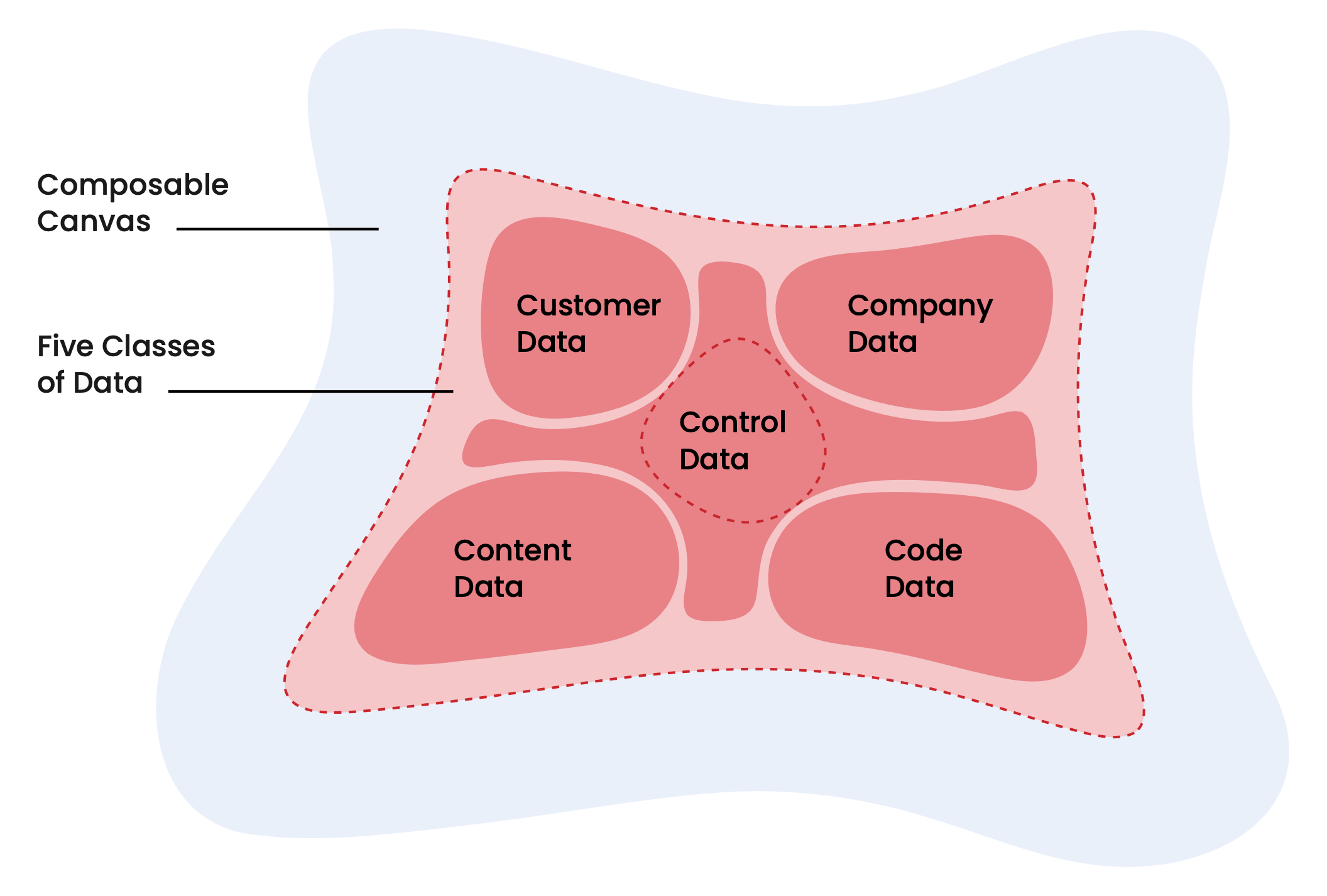
Der Bericht beschreibt fünf Datenklassen, die auf der einheitlichen Grundlage zusammenlaufen: Kundendaten, Unternehmensdaten, Inhaltsdaten, Code-Daten und Steuerungsdaten. Kundendaten: "Einzel- und Kontoprofile, Transaktionshistorien, Verhaltenssignale (Webbesuche, Produktnutzung)" stehen im Mittelpunkt von allem.
Hier operiert Snowplow. Aber ich würde die Darstellung etwas weiter treiben als der Bericht.
Es gibt einen bedeutsamen Unterschied zwischen Kundenprofilen und Kundenkontext. CRMs und CDPs haben lange Zeit erstere gut verwaltet: wer der Kunde ist, welche Deals er hat, zu welchen Segmenten er gehört. Was durchweg schwieriger zu liefern war, ist letzteres, d. h.: Was tut er gerade, und was sagt dieses Verhalten über seine Absicht aus?
Verhaltensereignisströme, die kontinuierliche, granulare Aufzeichnung, wie Kunden mit Ihrem Produkt, Ihrer Website, Ihrer App interagieren, sind das reichhaltigste Echtzeitsignal, das jedem KI-Agenten zur Verfügung steht, der eine Entscheidung treffen möchte. Und sie sind notorisch schwer richtig hinzubekommen. Ereignisse müssen zum Zeitpunkt der Erfassung strukturiert, anhand eines Schemas validiert und angereichert werden, bevor sie in die Datenbasis gelangen. Wenn die Verhaltensdaten, die in Ihre einheitliche Plattform gelangen, fehlerhaft, inkonsistent oder schlecht modelliert sind, werden die KI-Agenten, die damit arbeiten, diese Fehler im großen Stil verstärken.
Snowplow ist die Customer Context Layer. Wir sitzen zwischen dem Moment, in dem ein Kunde etwas tut (ein Klick, ein Produkterereignis, eine Suche, ein Scrollen) und der Datenplattform, die darauf reagieren muss. Unsere Aufgabe ist es sicherzustellen, dass Verhaltensdaten von dem Moment an, in dem sie erstellt werden, strukturiert, gut verwaltet und semantisch kohärent sind.
Und Kontext ohne Identität ist Rauschen. Ein reichhaltiger Verhaltensstrom ist nur so nützlich wie Ihre Fähigkeit, ihn über Touchpoints, Geräte und Sitzungen hinweg mit einer bekannten, aufgelösten Person zu verknüpfen, einschließlich der Übergänge zwischen anonymen und authentifizierten Zuständen. Snowplow's Identities erledigt diese Arbeit auf der Erfassungsebene, bevor Daten in der Plattform landen. Das Ergebnis ist nicht nur ein Strom von Ereignissen. Es ist ein aufgelöstes, kontinuierliches Bild der Reise jedes Kunden, mit dem Ihre Datenplattform, Ihre Analysten und Ihre KI-Agenten alle vertrauensvoll arbeiten können.
Komponierbarkeit war immer die Architektur, nicht das Feature
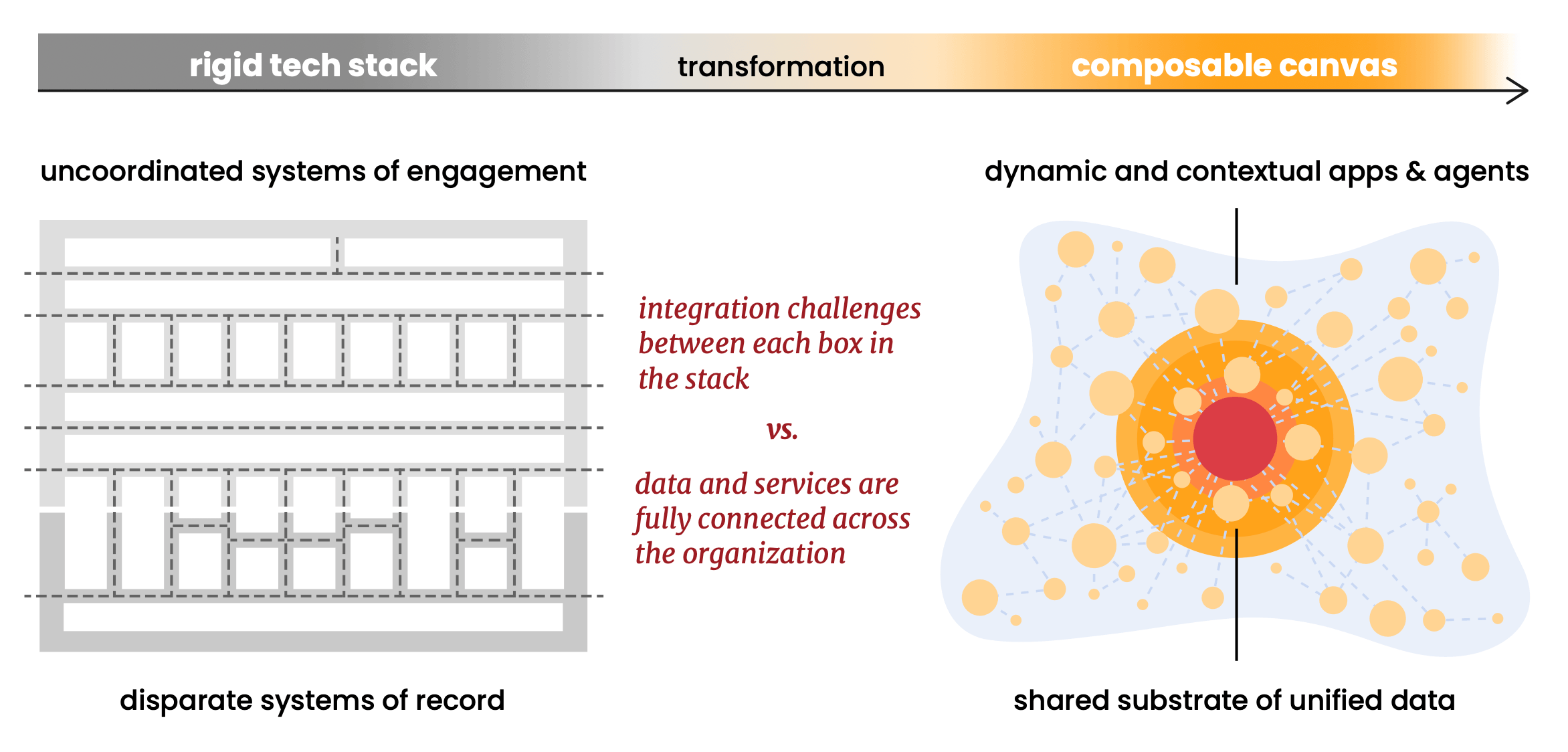
Das Komponierbarkeitsargument des Berichts ist eines seiner stärksten. Er plädiert für offene Datenformate (Linux Foundation Delta Lake, Apache Iceberg), offene Protokolle (MCP für Agenten) und offene Standards als Voraussetzung für eine wirklich komponierbare Leinwand. Das Prinzip: Standardisiere die Grundlage, damit du alles diversifizieren kannst, was darauf läuft.
Wir glauben zutiefst daran und haben Snowplow von Anfang an darauf aufgebaut. Wir glauben an offene Kernstandards. Unsere Datenstrukturen laufen nativ auf Apache Iceberg und Linux Foundation Delta Lake. Wir laufen in Ihrem Cloud-Konto (in Scott's Artikel als Hyperscaler bezeichnet: AWS, GCP oder Azure), was bedeutet, dass Ihre Verhaltensdaten Ihre Umgebung nie verlassen. Es gibt keinen proprietären Snowplow-Datenspeicher, der zu einer Abhängigkeit oder einem Migrationsrisiko wird. Wenn Sie einen Teil des Stacks ersetzen oder erweitern möchten, sind die Verhaltensdaten bereits dort, wo sie sein müssen: in Ihrer Plattform, in offenen Formaten, bereit zur Komposition.
Der Bericht stellt fest, dass "komponierbare CDPs" das traditionelle Modell "umkehren", indem sie CDP-Funktionen zu den Daten bringen, anstatt Daten in das CDP zu ziehen. Snowplow tat dies, bevor die Kategorie einen Namen hatte, denn für uns war Komponierbarkeit nie ein Feature, das wir hinzugefügt haben. Es war das Gründungsprinzip, auf dem das Produkt aufgebaut wurde.
Die semantische Schicht beginnt vor der Plattform
Eine der wichtigsten Ideen, die der Bericht entwickelt, ist die Rolle der semantischen Schicht, insbesondere dessen, was er als "Hüter der Kohärenz" bezeichnet. Dies ist das gemeinsame Vokabular, das Daten für jeden Agenten und jede Anwendung, die damit in Berührung kommen, aussagekräftig und konsistent macht. Was "Kunde" über Teams hinweg bedeutet. Wie "Konversion" berechnet wird. Was einen "qualifizierten Lead" darstellt.
Aus unserer Sicht möchte ich eine praktische Beobachtung hinzufügen: Die meisten dieser Fragen müssen bevor die Daten in die Plattform gelangen, nicht danach beantwortet werden. Insbesondere Verhaltensdaten sind bemerkenswert einfach schlecht zu erfassen. Ereignisse kommen mit inkonsistenten Benennungen, fehlenden Eigenschaften und undefinierten Schemata an. Bis die Daten die Plattform erreichen, sind sie bereits inkohärent. Sie können eine semantische Schicht auf schlechten Daten aufbauen, aber Sie überdecken ein strukturelles Problem, anstatt es zu lösen.
Die Schema-Registry von Snowplow und die Ereignisvalidierung über unser Event Studio erzwingen die semantische Kohärenz zum Zeitpunkt der Erfassung. Wir lehnen Ereignisse ab oder kennzeichnen sie, die nicht den definierten Strukturen entsprechen, bevor sie in der Datenplattform landen. Auf der komponierbaren Leinwand, die der Bericht beschreibt – wo Dutzende von Agenten und Anwendungen alle auf denselben Verhaltensdaten zugreifen – bestimmt die Qualität dieser Daten an der Quelle, ob Sie allem vertrauen können, was darauf aufgebaut ist.
Die agentenbasierte Feedbackschleife: Wie Echtzeit-Entscheidungen tatsächlich abgeschlossen werden
Der Bericht macht einen Punkt, der meiner Meinung nach noch mehr Betonung verdient: KI-Agenten sind "hungrig nach Kontext". Sie brauchen nicht nur Kundenprofile; sie müssen verstehen, was gerade passiert, d. h. die Verhaltenssignale, die Absicht, Dringlichkeit und Gelegenheit anzeigen.
Ich würde dem von Scott hier dargelegten Modell etwas hinzufügen. Der Bericht stellt Daten als Fluss zu den Agenten dar – eine Grundlage, auf die Agenten zurückgreifen, um Entscheidungen zu treffen. Was er nicht vollständig entwickelt, ist die Schleife, die nachdem der Agent handelt, stattfindet und warum das Schließen dieser Schleife zunehmend das strategisch wichtigste Datenproblem im Martech ist. Dies ist etwas, über das wir bei Snowplow sehr nachdenken und das zentral dafür ist, wie die komponierbare Leinwand in der Praxis tatsächlich funktioniert.
Die Schleife hat vier Phasen:
- Die Collect-Phase erfasst Verhaltensereignisse von menschlichen und KI-gesteuerten Interaktionen als strukturierte, schema-validierte Daten, die kontinuierlich in die Datenplattform fließen. Aber die Definition von „Verhaltensdaten“ muss erweitert werden, um eine zweite Klasse von Aktivitäten einzuschließen, die die meisten Architekturen noch nicht gut erfassen. Diese zweite Klasse hat zwei unterschiedliche Gesichter. Das erste ist AI Agent Analytics: Wenn ein Kunde mit einem Konversationsagenten interagiert, eine personalisierte Empfehlung erhält oder eine Reise durch ein automatisiertes Entscheidungsfindungssystem gestaltet wird – diese agentengesteuerten Interaktionen sind selbst Ereignisse, die mit der gleichen Sorgfalt wie jedes menschliche Verhalten erfasst werden müssen. Das zweite ist Agentic Analytics: KI-Agenten, die im Auftrag eines Benutzers recherchieren. Wenn eine KI Ihre Produktseiten durchsucht, Ihre Dokumentation liest oder Optionen als Stellvertreter eines Kunden vergleicht, ist dieser Traffic Intent, der nur durch einen nicht-menschlichen Akteur ausgedrückt wird. Ihn als Bot-Rauschen zu behandeln, das herausgefiltert werden muss, bedeutet, ein Signal zu verwerfen, das Ihnen etwas Reales darüber sagt, was ein Kunde evaluiert. Snowplow unterscheidet und erfasst beides als strukturierte Verhaltensereignisse, getrennt von direkter menschlicher Interaktion, aber gleichermaßen bedeutsam für das Verständnis von Intent und die Information von Entscheidungen.
- Die Resolve and Enrich-Phase wandelt Rohdatenströme durch Identitätsauflösung, das Zusammenfügen von Sitzungen, Geräten und Touchpoints zu einem bekannten Individuum in ein kohärentes Kundenbild um. Hier wird der Verhaltensstrom zu einem kohärenten Bild: nicht „ein Benutzer hat drei Seiten besucht“, sondern „dieses Konto, das sich derzeit in der späten Bewertungsphase befindet, hat in den letzten 48 Stunden drei Führungskräfte bei der Preisforschung beobachtet.“
- Die Serve-Phase liefert angereicherte Verhaltenstrends in zwei gleichzeitigen Modi: Echtzeit für In-Session-Personalisierung und eine Kombination aus Echtzeit und historisch für die Entscheidungsfindung von KI-Agenten. Für die In-Session-Personalisierung ist es Echtzeit: Die Datenplattform liefert Verhaltenssignale schnell genug, dass die Erfahrung, die diesem Kunden *jetzt* präsentiert wird, das widerspiegelt, was er in *dieser Sitzung* getan hat. Für die Entscheidungsfindung von KI-Agenten ist es sowohl Echtzeit als auch historisch: Ein Agent, der die nächste beste Aktion für ein Konto koordiniert, greift auf den Live-Verhaltensstrom *und* den vollständigen historischen Kundenbericht zu. Die Frage ist nicht nur „*Was tut dieser Kunde?*“, sondern „*Was bedeutet dieses Verhalten angesichts allem, was wir über ähnliche Kunden wissen?*“
- Die Learn-Phase schließt den Regelkreis, indem sie die Ergebnisse jeder Agentenentscheidung als erstklassige Verhaltensereignisse zurück in die Datenbasis leitet. Das Ergebnis jeder Agentenentscheidung, jeder personalisierten Erfahrung, jeder automatisierten Aktion ist selbst ein Verhaltensereignis. Wurde das empfohlene Produkt in den Warenkorb gelegt? Wurde die personalisierte E-Mail geöffnet? Hat die In-Session-Intervention den Verlauf der Sitzung verändert? Hat die Browsing-Sitzung des KI-Rechercheagenten letztendlich zu einer Konversion geführt? Diese Ergebnisse müssen in dieselbe Datenbasis zurückfließen, die die ursprüngliche Entscheidung ermöglicht hat. Ohne dieses Feedback arbeiten KI-Agenten mit historischen Daten, die jeden Tag veralteter werden. Mit diesem Feedback wird das System wirklich selbstverbessernd.
- Strukturierte Erfassung mit Schema-Validierung von Tag eins an
- Identitätsauflösung auf der Erfassungsebene, nicht nachträglich hinzugefügt
- Eine Pipeline, die für Echtzeit-Entscheidungen und historische Analysen auf denselben Daten aufgebaut ist
- Die Disziplin, die Ausgaben von KI-Agenten-Interaktionen als erstklassige Verhaltensereignisse zu erfassen, damit der Regelkreis von Anfang an geschlossen wird
Hier schließen AI Agent Analytics und Agentic Analytics den Kreis. Sie haben KI-Agenten-Verhaltensereignisse als erstklassige Daten gesammelt; jetzt können Sie sie mit der gleichen Sorgfalt analysieren, die Sie auf menschliches Verhalten anwenden würden. Welche Agenten erzielen gute Ergebnisse? Welche Entscheidungsmodelle verschlechtern sich? Wo konvertiert KI-generierter Rechercheverkehr und wo bricht er ab? Diese Fragen können nur beantwortet werden, wenn die Erfassung von Anfang an korrekt war. KI-Agenten- und Agentic-Analysen sind keine Berichterstattungsschicht, die Sie später hinzufügen. Sie sind eine Folge davon, wie Sie die Daten überhaupt erfasst haben.
Dies ist der Regelkreis, der für die richtige Verhaltensdateninfrastruktur einzigartig ist. Es ist keine Pipeline. Es ist ein Schwungrad.
Von Analysen zur Entscheidungsfindung: die richtigen Werkzeuge für Echtzeit-Entscheidungen
Etwas, das der Bericht andeutet und das meiner Meinung nach mehr Raum verdient, insbesondere für Marketing- und Datenleiter, die darüber nachdenken, was KI tatsächlich von ihrem Stack verlangt: Der Übergang von der Nutzung von Verhaltensdaten *für Analysen* zur Nutzung *für Entscheidungen* ist eine bedeutsame architektonische Änderung, nicht einfach eine Erweiterung des Anwendungsfalls.
Analysen blicken zurück. Sie sammeln Ereignisse, modellieren sie und fragen die Ergebnisse ab. Latenzen von Minuten oder Stunden sind akzeptabel. Die Daten informieren einen Menschen, der eine Entscheidung trifft.
Entscheidungsfindung blickt nach vorne und ist in Echtzeit. Ein KI-Agent benötigt Verhaltenskontext innerhalb von Millisekunden, um zu bestimmen, welche Erfahrung er diesem Kunden in dieser Sitzung, genau jetzt, anbieten soll. Die Infrastrukturanforderungen sind unterschiedlich. Die Datenqualitätsanforderungen sind höher, da Fehler nicht als Dashboard-Anomalie auftreten, die jemand nächste Woche entdeckt; sie treten als schlechte Kundenerfahrung auf, die sofort und in großem Umfang geliefert wird.
Leider erzwingen die meisten Datenpipelines einen Kompromiss. Einige optimieren für Geschwindigkeit, führen aber dazu, dass Sie die historische Tiefe verlieren. Andere optimieren für Reichhaltigkeit, führen aber dazu, dass Sie den Latenz-Spielraum verlieren, den Echtzeit-Entscheidungen benötigen.
Die komponierbare Leinwand verlangt beides gleichzeitig, auf denselben Daten. Das ist ein schwierigeres Infrastrukturproblem, als es klingt, und eines, das es wert ist, auf der Grundlage gelöst zu werden, anstatt später zu versuchen, es zu beheben, wenn ein Agent mit Millisekunden-Geschwindigkeit Entscheidungen trifft und Sie feststellen, dass Ihr historischer Kontext in einem separaten Speicher liegt.
Über Kontextgraphen und Verhaltensdaten
Der Bericht führt ein Konzept ein, das ich wirklich interessant fand: den Kontextgraphen – eine lebendige Aufzeichnung von Entscheidungsspuren, die nicht nur erfasst, *was* passiert ist, sondern auch, *warum* es passieren durfte. Entscheidungsbegründungen, Ausnahmegenehmigungen, Genehmigungsketten. Die Art von institutionellem Gedächtnis, die derzeit in Slack-Threads und Köpfen von Menschen lebt.
Ich würde argumentieren, dass Verhaltensereignisströme das natürliche Rohmaterial für Kontextgraphen auf der Kundenseite sind. Jede Agentenaktion, die einen Kunden betrifft (eine Empfehlung, ein ausgelöster Segment, eine gesendete Nachricht), sollte auf die Verhaltenssignale zurückführbar sein, die sie ausgelöst haben. Snowplows Ereignismodell ist so strukturiert, dass genau diese Kausalität erfasst wird: welches Signal ausgelöst wurde, welche Daten beobachtet wurden, welcher Schwellenwert überschritten wurde.
Wenn Kontextgraphen als Architekturmuster reifen, wird die Verhaltensdaten-Schicht die Grundlage dafür bilden. Das „*Was ist passiert?*“ und das „*Warum ist es passiert?*“ sind beide im Ereignisstrom kodiert, wenn Sie ihn von Anfang an richtig erfassen.
So bauen Sie eine skalierbare Echtzeit-Entscheidungsfindungsgrundlage
Für jede Organisation, die auf die im Bericht beschriebene komponierbare Leinwand hinarbeitet, ist die richtige Verhaltensdateninfrastruktur die erste und am höchsten wirksame Investition: nicht, weil sie die aufregendste ist, sondern weil alles andere darauf aufbaut.
Das bedeutet, von Anfang an vier Dinge richtig zu machen:
Die komponierbare Architektur bedeutet auch, dass die von Ihnen heute getroffenen Anbieterentscheidungen umkehrbar sein sollten. Wenn Ihre Verhaltensdatenpipeline in offene Formate in Ihrer eigenen Cloud-Infrastruktur schreibt, behalten Sie die Optionsvielfalt. Wenn sie in einen proprietären Speicher schreibt, haben Sie eine Abhängigkeit geschaffen, die jede zukünftige Entscheidung über den Stack einschränken wird.
Das 3. Zeitalter ist bereits da für diejenigen, die früh investiert haben
Der Bericht stellt das 3. Zeitalter von Martech als einen Horizont von 3-5 Jahren dar. Für Snowplow-Kunden, die bereits die hier beschriebenen architektonischen Investitionen getätigt haben, d. h. Datenplattformen als operativen Kern, Verhaltensdaten, die Echtzeit-Agenten speisen, der vollständige Entscheidungs-zu-Analyse-Regelkreis auf einer komponierbaren Grundlage, ist dies kein zukünftiger Zustand. So arbeiten sie heute bereits.
Das ist keine Behauptung über Snowplow im Speziellen. Es ist ein Beweis dafür, dass die Architektur jetzt erreichbar ist, für Organisationen, die bereit sind, ihr Priorität einzuräumen. Die komponierbare Leinwand wartet nicht auf neue Technologie. Sie wartet auf architektonische Entscheidungen und die Überzeugung, diese zu treffen.
Scotts Bericht ist eine klare und großzügige Formulierung dessen, wie diese Entscheidungen aussehen sollten. Wir freuen uns, dass diese Diskussion auf dieser tiefen Ebene stattfindet – und freuen uns, daran teilzunehmen!

Lesen Sie Scott Brinkers vollständigen Forschungsbericht hier: Der neue Martech „Stack“ für das KI-Zeitalter
Live-Webinar mit Scott Brinker, Samsaras CMO und HPs VP of Marketing Data Science darüber, wie sich Martech für KI entwickelt: Registrieren Sie sich für das Webinar
Wenn Sie tiefer eintauchen möchten, was die Datenbasis für Agentic Analytics tatsächlich leisten muss, hat das Team von Snowplow dies hier im Detail behandelt: Was ist Agentic Analytics? Ein Leitfaden für Datenleiter
FAQ:
Wie unterscheidet sich Echtzeit-Entscheidungsfindung von Batch-Verarbeitung? Die Batch-Verarbeitung sammelt und analysiert Daten in geplanten Intervallen, oft Stunden nachdem eine Interaktion stattgefunden hat. Die Echtzeit-Entscheidungsfindung verarbeitet Verhaltenssignale in dem Moment, in dem sie generiert werden, und löst eine Aktion innerhalb derselben Sitzung aus, oft innerhalb von Millisekunden. Die Infrastrukturanforderungen, die Datenqualitätsstandards und die Latenztoleranzen unterscheiden sich grundlegend zwischen den beiden Ansätzen.
Warum benötigen KI-Agenten eine Customer Context Layer? KI-Agenten, die In-Session-Entscheidungen treffen, benötigen einen Verhaltenskontext, der widerspiegelt, was ein Kunde gerade tut, nicht was er gestern getan hat. Die Customer Context Layer stellt strukturierte, identitätsaufgelöste Verhaltensereignisströme bereit, die KI-Agenten in Echtzeit abfragen können. Ohne sie arbeiten Agenten mit veralteten Daten, was die Entscheidungsqualität in großem Maßstab verschlechtert.
Was ist der Unterschied zwischen Kundenprofilen und Kundenkontext? Kundenprofile beschreiben, wer ein Kunde ist: sein Profil, seine Kaufhistorie, sein Kontostatus und seine Segmentzugehörigkeit. Der Kundenkontext beschreibt, was er im gegenwärtigen Moment tut: welche Seiten er besucht hat, wonach er gesucht hat, wie lange er sich beschäftigt hat und was dieses Verhalten über seine Absicht aussagt. Echtzeit-Entscheidungsfindung erfordert beides, aber die meisten Datenstapel sind besser für das erstere als für das letztere geeignet.
Was sind die vier Phasen der agentischen Feedbackschleife? Die agentische Feedbackschleife durchläuft vier Phasen: (1) Sammeln – Erfassen von Verhaltensereignissen aus menschlichen und KI-gesteuerten Interaktionen als strukturierte Daten; (2) Auflösen und Anreichern – Verknüpfen von Ereignissen mit einer bekannten Identität und Aufbau eines kohärenten Kundenbildes; (3) Bereitstellen – Bereitstellen von angereichertem Kontext für KI-Agenten und Personalisierungssysteme in Echtzeit; (4) Lernen – Einspeisen der Ergebnisse jeder Agentenentscheidung zurück in die Datenbasis, damit sich das System kontinuierlich verbessert.
Welche Dateninfrastruktur wird für die Echtzeit-Entscheidungsfindung benötigt? Die Echtzeit-Entscheidungsfindung erfordert vier grundlegende Fähigkeiten: strukturierte Erfassung von Ereignissen mit Schemavalidierung am Erfassungspunkt; Identitätsauflösung auf der Erfassungsebene anstatt nachträglicher Anpassung; eine Datenpipeline, die sowohl Echtzeit- als auch historischen Kontext gleichzeitig bereitstellen kann; und die Disziplin, die Ausgaben von KI-Agenteninteraktionen als erstklassige Verhaltensereignisse zu behandeln, die wieder in das System eingespeist werden.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.