Der Stein von Rosette für CPS: Clarotys KI-gestützte Bibliothek
Wie ein Multi-Agenten-KI-System auf Databricks die CPS-Identitätskrise löst
von Ben Hazan, Anton Berlinsky, Ohad Avni, Itay Wagner, Guy Zalcman , Dor Bdolach, Ravid Ariely und Gal Sberro
- Clarotys KI-gestützte CPS-Bibliothek löst die Krise der Asset-Identität – bei der 88 % der CPS-Geräte keinen exakten Produktcode aufweisen – durch die Automatisierung der Entitätsauflösung für über 17 Millionen industrielle und medizinische Assets.
- Ein Multi-Agenten-KI-System, das auf den Custom Agents von Databricks aufbaut, kombiniert NLP- und Reasoning-Agenten mit menschlichem Feedback, angetrieben von einer Medallion-Architektur auf Delta Lake, um fragmentierte Gerätesignale in eine deterministische einzige Quelle der Wahrheit zu verwandeln.
- Das Ergebnis: Allein im MVP haben wir eine Verbesserung der Genauigkeit der Schwachstellenattribution um über 25 % und für mehr als 56 % der analysierten Geräte neue Sicherheitsempfehlungen für zuvor unsichtbare veraltete Firmware gesehen.
Der Stein von Rosette für CPS: Clarotys revolutionäre KI-gestützte Bibliothek im Inneren
Seit Jahrzehnten leidet die Welt der Cyber-Physical Systems (CPS) – der Maschinen, die unsere Fabriken, Krankenhäuser und kritischen Infrastrukturen antreiben – unter einer stillen "Identitätskrise". Während ein IT-Administrator problemlos jeden Laptop in seinem Netzwerk identifizieren kann, kämpft ein OT (Operational Technology)-Sicherheitsteam oft damit, genau zu wissen, was in seiner Produktionshalle läuft.
Ein aktueller Bericht des Team82-Forschungsteams von Claroty enthüllte eine erschütternde Realität: 88% der CPS-Assets übertragen keinen exakten Produktcode, und 76% verwenden Produktcodes, die von den offiziellen Aufzeichnungen des Herstellers abweichen. Dieser Mangel an einem "digitalen Geburtszertifikat" macht das Schwachstellenmanagement nahezu unmöglich, da Sicherheitsteams gezwungen sind, Informationen aus inkonsistenten Quellen manuell zusammenzusetzen.
Um dies zu lösen, hat Claroty kürzlich seine KI-gestützte CPS-Bibliothek vorgestellt, eine neuartige, autoritative Mapping-Engine, die als "universeller Übersetzer" für industrielle und medizinische Hardware konzipiert ist.
Im Kern handelt es sich hierbei um eine Entity Resolution (ER)-Herausforderung, und der Zweck des Systems ist es, die Identitätskrise zu lösen, indem verrauschte reale Daten abgeglichen und in eine einzige Quelle der Wahrheit konsolidiert werden. Um eine deterministische Rückverfolgbarkeit mit hoher Genauigkeit zu erreichen, sind wir über Standard-Matching-Algorithmen hinausgegangen und haben eine hybride Architektur entwickelt, die bewährte, klassische ER-Methoden mit der kognitiven Leistung von Generative AI kombiniert.
Als Reaktion auf einen kritischen industriellen Schmerzpunkt haben wir mit Databricks im Rahmen ihres GenAI MVP-Programms zusammengearbeitet. Diese Zusammenarbeit nutzt unser spezialisiertes Angebot und die Data & AI-Fähigkeiten von Databricks, um eine definitive Lösung für das Problem zu liefern.
Wie es in der Realität aussieht
Stellen Sie sich eine typische Situation in einer Fabrik vor: Clarotys xDome findet ein Gerät mit der Modellnummer 1769-L36ERMS/B über das CIP-Protokoll. Für eine Person oder ein einfaches Sicherheitstool ist dies nur ein interner Rockwell-Automatisierungscode – er ist in keiner Schwachstellendatenbank enthalten und deutet nicht sofort auf ein Risiko hin.
Um dieses Gerät zu sichern, müssten Mitarbeiter normalerweise manuell herausfinden, um was es sich handelt, was Folgendes beinhaltet:
- Websuche: Durchsuchen von Rockwells Katalogen, um herauszufinden, dass dieser Code für einen Compact GuardLogix 5370 Controller steht.
- Überprüfung auf Schwachstellen: Suche nach CISA-Warnungen für diesen Namen, die auf CVE-2020-6998 als Risiko für "Versionen 33 und früher" hinweisen könnten.
- Bestätigung der Details: Überprüfung der NVD (National Vulnerability Database), ob die spezifische CPE (Common Platform Enumeration) übereinstimmt, nur um einen allgemeinen Eintrag für "CompactLogix 5370 L3" zu finden, der den Untertyp "GuardLogix" möglicherweise enthält oder auch nicht.
Diese manuelle "Detektivarbeit" ist oft der Punkt, an dem die Sicherheit versagt. Die KI-gestützte CPS-Bibliothek automatisiert diesen gesamten Prozess. Sie erkennt sofort den internen Code, verknüpft ihn mit dem kommerziellen Namen, identifiziert die spezifischen Teile und Firmware-Versionen und ordnet die richtigen CVEs mit eindeutiger Genauigkeit zu – und verwandelt einen verwirrenden Zeichenstring in Millisekunden in ein klares, sicheres Setup.
Die Identitätskrise mit deterministischer Sichtbarkeit lösen
Die CPS-Bibliothek ist nicht nur eine Datenbank; sie ist ein Multi-Agenten-KI-System, das eine "Last-Mile"-Behebung ermöglicht. Durch die Partnerschaft mit Branchenriesen hat Claroty einen Evidenz-Graphen aufgebaut, der verrauschte Netzwerkdaten in eine einzige Quelle der Wahrheit überführt.
Wichtige Durchbrüche umfassen:
- Deterministische Rückverfolgbarkeit: Selbst wenn ein Gerät nur minimale Daten meldet, nutzt die Bibliothek statistische Schlussfolgerungen und domänengesteuerte Logik, um seine genaue Identität zu triangulieren.
- Schwachstellen-Attribution: Durch die Identifizierung spezifischer Unterkomponenten und Firmware-Strukturen hat die Bibliothek die Genauigkeit der Schwachstellenidentifizierung um 25% verbessert.
- Handlungsrelevante Einblicke: In frühen Tests erhielten 56% der analysierten Geräte neue oder aktualisierte Sicherheitsempfehlungen für veraltete Firmware, die für Sicherheitsteams zuvor unsichtbar waren.
Unter der Haube: Die Databricks Data Intelligence Engine
Zur Verwaltung eines globalen Katalogs von über 17 Millionen Assets und ihrer komplexen Abhängigkeiten nutzt Claroty die Databricks Data Intelligence Platform als sein einheitliches Rückgrat. Durch die Einführung einer Lakehouse-Architektur eliminiert Claroty traditionelle Datensilos und ermöglicht die Aufnahme verschiedenster Datensätze – von proprietären OT-Protokollen und API-Aufrufen bis hin zu unstrukturierten PDF-Handbüchern von Herstellern – in einer einzigen, skalierbaren Umgebung. Diese Grundlage bietet die Hochleistungsberechnung, die für die Ausführung komplexer statistischer Inferenzmodelle über Millionen von Datenpunkten hinweg erforderlich ist, und stellt sicher, dass jeder CPS-ID (dem neuen Industriestandard für die Identität von Cyber-Physical Systems von Claroty) eine rigorose Datenintegrität und abteilungsübergreifende Intelligenz zugrunde liegt.
Data Engineering im großen Maßstab: Die Medallion-Pipeline
Angetrieben wird dieses Ökosystem durch eine robuste Medallion-Architektur, die auf Delta Lake basiert und im Unity Catalog verwaltet wird. Die Reise beginnt in der Bronze-Schicht, wo rohe, heterogene JSON-Payloads in nur-anhängende Delta-Tabellen aufgenommen werden. Von dort aus transformiert eine Promotion-Pipeline, die vom Delta Change Data Feed (CDF) liest, dynamisch eine Mapping-Registry, um rohe Evidenz in ein verwaltetes, kanonisches Schema umzuwandeln. Durch die Nutzung der Schema-Evolution und des Time Travel von Delta Lake behält Claroty eine unzerbrechliche Nachweiskette; jeder Asset-Datensatz ist bis zu seinem ursprünglichen Rohartefakt und der spezifischen Mapping-Version, die ihn klassifiziert hat, zurückverfolgbar, was eine vollständige Auditierbarkeit selbst in den sensibelsten Industrieumgebungen gewährleistet.
Multi-Agenten-Intelligenz über Databricks' Custom Agents
Der anspruchsvollste Teil dieser hybriden Engine ist die Nutzung der Databricks Custom Agents. Anstatt sich auf ein einziges monolithisches Modell zu verlassen, hat Claroty ein Orchestrated Multi-Agent System entwickelt, ein synchronisiertes Netzwerk, in dem spezialisierte KI-Agenten zusammenarbeiten, um komplexe Signale zu interpretieren.
Um diese Agenten mit zuverlässigem Kontext zu versorgen, kombinieren wir klassische statistische Analysen strukturierter Daten, die aus proprietären Quellen gesammelt wurden, mit fortschrittlichen NLP-Techniken, die Signale aus dem Rauschen extrahieren, das in Herstellerdokumentationen, technischen Datenblättern und offenen Webquellen inhämt. Databricks' Unity Catalog bietet die verwaltete Datenbasis, die zur Vereinheitlichung dieser vielfältigen Datensätze erforderlich ist, während Spark-basierte Pipelines Informationen im großen Maßstab verarbeiten und normalisieren. Zusammen synthetisieren diese Fähigkeiten fragmentierte, inkonsistente Informationen in die präzisen, kontextualisierten Antworten, die die Agenten benötigen, um genaue Entity-Resolution-Abgleiche zu liefern.
Das System ist um drei Kernkomponenten aufgebaut:
- NLP-Agenten: Verarbeiten komplexe, gemischte Datenformate – einschließlich protokollbasierter Namenszeichenfolgen und obskurer Software-Markierungen, die Standardmodelle oft übersehen.
- Reasoning Agents: Wenden Konfidenzbewertungen und statistische Tests an, um Evidenz zu gewichten und hochpräzise Signale vom Rauschen zu unterscheiden, um die Datenintegrität zu gewährleisten.
- Human-in-the-loop (HITL): Ein kritischer Feedback-Mechanismus, der Zuordnungen mit geringer Konfidenz zur Überprüfung durch Experten markiert. Die Ergebnisse dieser Sitzungen werden zurück in das System gespeist und trainieren die Modelle für kontinuierliche Genauigkeitssteigerungen neu.
Innovation durch Databricks-Funktionen
Der Erfolg dieser Architektur liegt nicht nur in den Agenten selbst, sondern im End-to-End-Ökosystem, das auf Databricks aufbaut und sie antreibt. Wir haben die gesamte Bandbreite der Plattform genutzt, um mit Geschwindigkeit und Zuverlässigkeit vom MVP zur Produktion zu gelangen:
1. Domänenspezifische Intelligenz durch Model Serving Um die Nuancen von Gesundheitswesen und OT zu bewältigen, reichten generische Embeddings nicht für die erforderliche Präzision aus. Wir haben festgestellt, dass generische RAG-Architekturen weiterentwickelt werden müssen, um domänenspezifische Frameworks zu werden, damit der "Universal Translator" wirklich erfolgreich ist. Derzeit überbrücken wir diese Lücke, indem wir erstklassige medizinische Embedding-Modelle als benutzerdefinierte Endpunkte mit Databricks Model Serving bereitstellen. Für die Zukunft sehen wir jedoch Fine-Tuning dieser Modelle als nächsten logischen Schritt, um sicherzustellen, dass unsere Agenten die obskursten industriellen Dialekte mit deterministischer Genauigkeit verstehen.
2. Fortgeschrittene RAG & Informationsextraktion Wir nutzten den Knowledge Assistant, um robuste RAG (Retrieval-Augmented Generation)-Systeme zu erstellen, die große Mengen proprietärer Dokumentation aufnehmen können. Durch die Verwendung eines Informationsextraktions-Agenten können wir unstrukturierte proprietäre Dokumente strukturell parsen und Rohdaten in handlungsrelevante Intelligenz für die CPS-Bibliothek umwandeln.
3. Full Lifecycle Management mit MLflow das als Rückgrat unseres ML-Entwicklungslebenszyklus dient und eine einheitliche Plattform von der anfänglichen MVP-Phase bis zur rigorosen Evaluierung und endgültigen Bereitstellung bietet.
- Kontinuierliche Evaluierung: Wir implementierten eine umfassende Evaluierungsstrategie mit "LLM als Richter" neben manuellen Labeling-Sitzungen. MLflow-Funktionen ermöglichten uns, die Modellleistung ständig zu bewerten, um Konzeptdrift zu verhindern.
- Observability & Monitoring: In der Produktion nutzen wir die Observability-Funktionen von MLflow, um die Agentengesundheit in Echtzeit zu überwachen. Dies umfasst die Verfolgung der Token-Nutzung und der Infrastrukturkosten, die Identifizierung von Latenzengpässen und die Erkennung potenzieller Fehler, bevor sie Benutzer beeinträchtigen. Ein strategischer Fokus liegt auf der Kosteneffizienz unserer Vektorsuchindizes. Während die Leistung Weltklasse ist, erfordert das derzeitige Fehlen eines "Scale-to-Zero"-Modells für Vektor-Endpunkte – eine Nuance, die besonders für die sprunghafte, ereignisgesteuerte Natur industrieller Sicherheitsdaten relevant ist – die Entwicklung spezifischer Architekturmuster, um während Leerlaufzeiten einen hohen ROI aufrechtzuerhalten.
Durch die Verschmelzung klassischer Entity-Resolution-Methoden mit einer ausgeklügelten, orchestrierten Multi-Agenten-Strategie – unterstützt durch die robuste Infrastruktur von Databricks – haben wir eine sich selbst verbessernde, kosteneffiziente und hochpräzise Intelligenzschicht geschaffen. Dieses System schließt endlich die Lücke zwischen unstrukturierten Netzwerkdaten und der einzigen Quelle der Wahrheit und löst die Identitätskrise für CPS-Sicherheit.
Automatisierung mit Jobs, Pipelines und LLM
Um die riesigen Informationsmengen aus verschiedenen Quellen zu verarbeiten, nutzt Claroty Lakeflow Jobs, um den gesamten Prozess zu orchestrieren – von Rohdaten bis zu einer gut strukturierten Tabelle.
Eine unserer Pipelines orchestriert einen ETL-Prozess, der CSAF, eine JSON-formatierte Sicherheitsberatung, in eine tabellarische Struktur parst. In diesem Prozess liest und schreibt jeder Schritt Einträge in eine dedizierte Delta-Tabelle.
In diesem ETL und in vielen weiteren Anwendungsfällen verwenden wir LLMs, um die Daten anzureichern – von Klassifizierungsaufgaben und AI Functions wie ai_query, unter Verwendung verschiedener Serving-Endpunkte und MLflow zur Bewertung der Antworten, die wir vom LLM erhalten, unter Verwendung statistischer Metriken und LLM-als-Richter, und zur Überwachung der Kosten.
Um diese Pipeline bei Skalierung zuverlässig zu halten, verwenden wir einen LLM als Richter-Ansatz, um kontinuierlich die Qualität unserer eigenen LLM-Ausgaben zu bewerten. Anstatt uns nur auf vollständig gelabelte Ground Truth zu verlassen – die bei realen CPS-Daten oft fehlt oder mehrdeutig ist –, lassen wir ein dediziertes Richtermodell die Antwort eines anderen Modells überprüfen und entscheiden, ob sie akzeptabel erscheint. Die Aufgabe des Richters ist einfach und konservativ: Markieren Sie jedes Ergebnis als bestanden, sieht korrekt aus, fehlgeschlagen, sieht falsch aus oder unbekannt, nicht genügend Informationen. Alle diese Richter werden in Delta-Tabellen gespeichert. Mit dieser Methode können unsere Teams Evaluationsstichproben laden, benutzerdefinierte MLflow GenAI-Richter starten und strukturierte Evaluierungen durchführen. MLflow GenAI Monitoring native Fähigkeiten bieten uns eine konsistente Möglichkeit, die Qualität zu überwachen, Versionen zu vergleichen und Regressionen über viele LLM-Anwendungsfälle hinweg zu erkennen – ohne für jeden neuen Workflow einen maßgeschneiderten Evaluations-Stack zu erstellen.
Transaktionale Integrität mit Lakebase
Damit die "Bibliothek" funktioniert, müssen die Daten konsistent und hochverfügbar sein. Claroty integriert Lakebase, eine vollständig verwaltete transaktionale Datenebene auf Databricks. Lakebase basiert auf Postgres und bietet die für Echtzeitabfragen erforderliche Latenz-Performance, während gleichzeitig eine nahtlose Verbindung zum breiteren Lakehouse für analytische Verarbeitung aufrechterhalten wird. Dies ermöglicht strenge Einschränkungen, um sicherzustellen, dass unsere Daten ihre hohe Qualität behalten und dass Asset-Zuordnungen auch bei sich ändernden Konfigurationen korrekt bleiben.
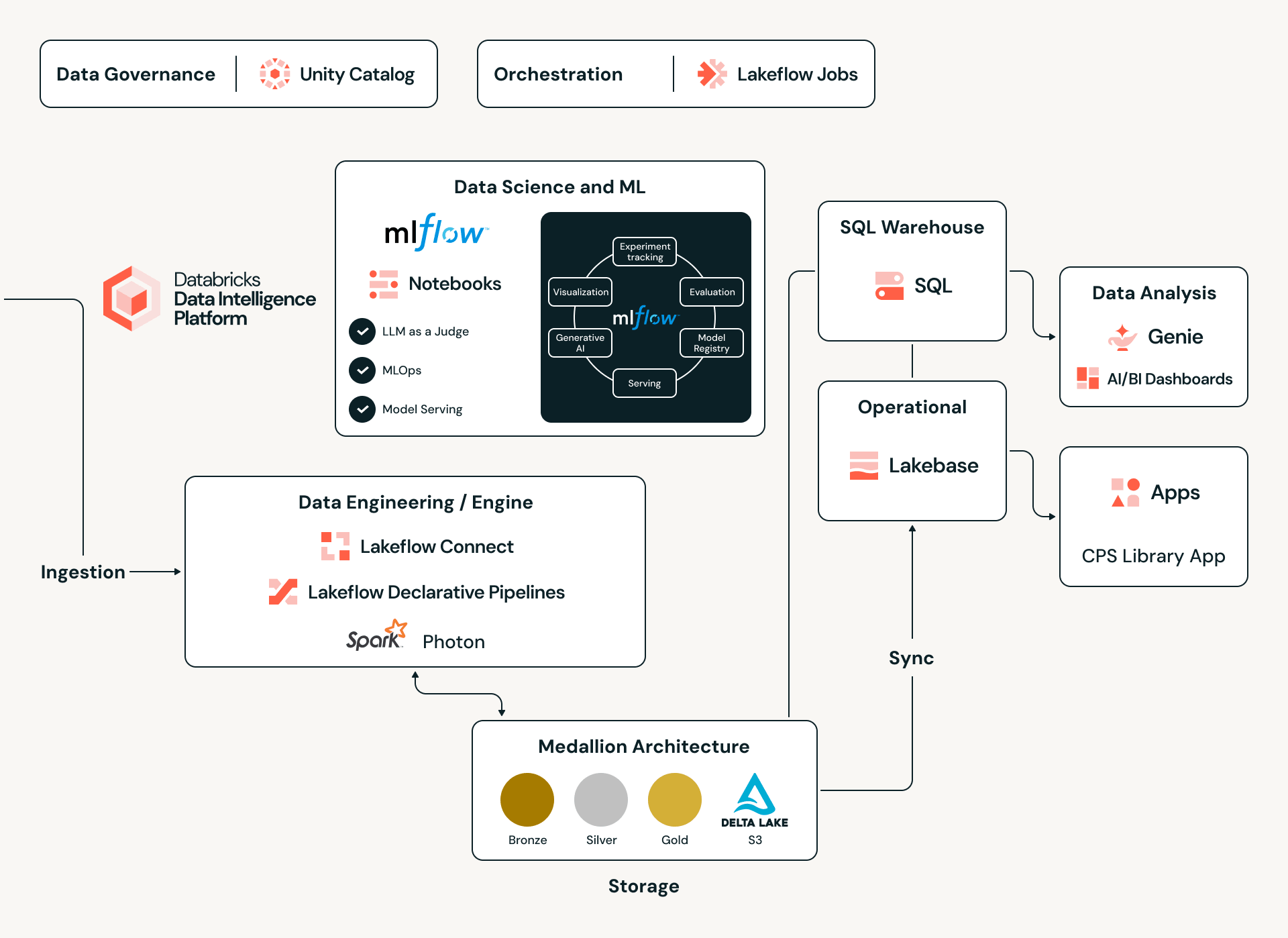
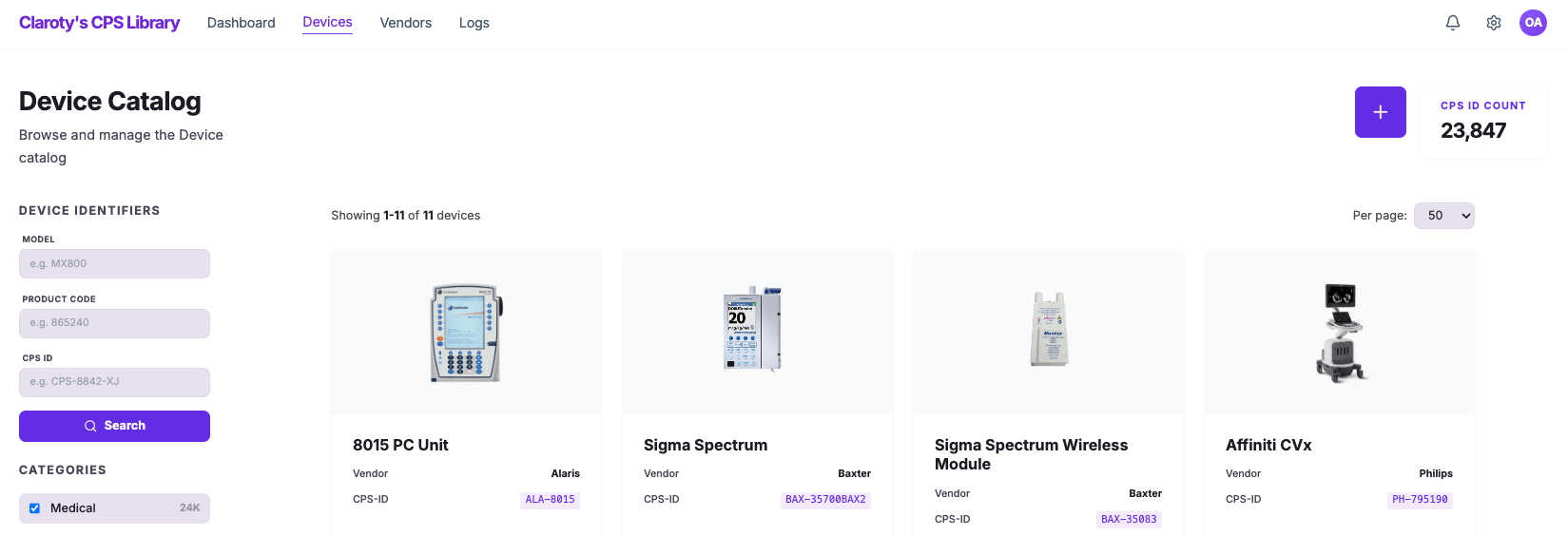
Schnelle Innovation mit Databricks Apps
Um all diese Erkenntnisse zusammenzuführen, nutzen wir Databricks Apps, eine Funktion, die es Claroty ermöglicht, Full-Stack-, datenintensive Anwendungen direkt in der Databricks-Umgebung zu erstellen und bereitzustellen. Unter Verwendung moderner UI-Frameworks (wie React oder Streamlit) für das Frontend und Lakebase, der vollständig verwalteten Postgres OLTP-Datenbank von Databricks, für transaktionale Workloads können wir sowohl Anwendungslogik als auch operative Daten auf derselben Plattform wie unser Lakehouse hosten. Dies bedeutet, dass die Anwendung die integrierte Sicherheit, Governance und Authentifizierung der Plattform (über Unity Catalog und OAuth) erbt und gleichzeitig die Notwendigkeit separater App-Server, Datenbanken und Bereitstellungspipelines eliminiert. Was traditionell das Zusammenfügen mehrerer Technologie-Stacks und Dienste erfordert hätte, wird in einer einzigen, kostengünstigen und robusten Lösung konsolidiert.
Human-in-the-Loop über Databricks Apps
Während unsere KI-Pipelines die Hauptarbeit automatisieren, ist die wichtigste Anforderung im Feld zur Schaffung von Vertrauen das Feedback von Fachexperten (SMEs) im Rahmen eines Human-in-the-Loop-Prozesses. Mit Databricks Apps und Lakebase ermöglichen wir eine transparente Ansicht und einen nahtlosen Feedback-Zyklus für den "Human-in-the-Loop". Diese intuitive Benutzeroberfläche ermöglicht es Fachexperten, Klassifizierungen zu überprüfen, Entitäten zu korrigieren und anzureichern und qualitativ hochwertige, validierte Daten zurück in unsere MLflow-Pipelines und die F&E-Migration einzuspeisen, um sicherzustellen, dass das System im Laufe der Zeit intelligenter und genauer wird.
Die Zukunft der Resilienz
Durch die Kombination von Clarotys tiefem Fachwissen in OT-Protokollen mit der Leistungsfähigkeit der Databricks-Plattform setzt die CPS-Bibliothek einen neuen Standard. Es geht nicht mehr nur darum zu sehen, dass ein Gerät existiert, sondern darum, genau zu wissen, was es ist, welche Risiken es birgt und wie man es mit absoluter Sicherheit beheben kann.
Clarotys Führung in diesem Bereich wurde kürzlich durch die Ernennung zum Leader im Gartner® Magic Quadrant™ for CPS Protection Platforms 2025 bestätigt, mit der höchsten Positionierung in Bezug auf die "Ability to Execute". Während sich die Branche weiterentwickelt, wird dieser "Identity-First"-Ansatz die Grundlage für die Förderung der Resilienz in jeder vernetzten Umgebung bilden.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.