Vom Prüfstand zum Lakehouse: Wie AVL die Messdatenanalyse mit Impulse modernisiert
von Dr. Thomas Bonfert, Jonathan Bräuer, Fabian Ade, Maxim Hammer, Florian Gorzitzke, David Crescence, Christa Simon, Jörg Zimmermann und Hannes Schneider
- Impulse ist ein Open-Source-Framework von Databricks Labs, mit dem Fachingenieure Sensordaten auf Databricks mit einfachen Python-Ausdrücken analysieren können.
- Impulse skaliert Zeitreihenanalysen auf Hunderte Terabyte an Messdaten, während die Analysen reproduzierbar bleiben, teamübergreifend geteilt werden können und durch Unity Catalog verwaltet werden.
- AVL hat seine bestehende On-Premise-Plattform durch Impulse auf Databricks ersetzt, wodurch die Analysezeit von Tagen auf Minuten verkürzt und die Messdatenanalyse im gesamten Unternehmen standardisiert wurde.
1. Einführung – Impulse: Zeitreihenanalyse für Messdaten
Eine einzige Fahrzeug-Testkampagne erzeugt Hunderttausende von Messwertaufzeichnungen und Hunderte von Terabytes an Zeitreihen-Sensordaten. Diese Daten werden in Binärformaten wie ASAM MDF4 gespeichert und traditionell mit Desktop-Tools wie NI DIAdem oder MATLAB analysiert. Fachingenieure schätzen diese Tools aus gutem Grund. Sie können sich auf die eigentliche Analyse konzentrieren und entscheiden, welche Signale verglichen werden sollen und welche Bedingungen ein kritisches Ereignis definieren, ohne zu Experten für Big-Data-Frameworks und verteiltes Rechnen werden zu müssen. Allerdings skalieren diese Tools nicht, auf isolierten Skripten basierende Analysen sind schwer reproduzierbar und die Daten liegen außerhalb der Governance, auf die sich der Rest eines modernen Unternehmens verlässt.
Impulse ist eine Python-basierte Analysebibliothek, die als Databricks Labs-Projekt veröffentlicht wurde und diese Lücke auf der Databricks Intelligence Platform schließt. Im Kern (Abbildung 1) bietet Impulse drei Schlüsselkomponenten:
- Eine deklarative Time Series Analytics Language (TSAL), mit der Ingenieure Signalarithmetik, Ereignisbedingungen und Aggregationen in natürlichem Python ausdrücken können, ohne Spark-Expertise zu benötigen.
- Eine pluggable Query Engine, die TSAL-Ausdrücke in eine verteilte Spark-Ausführung über Tausende von Aufzeichnungen hinweg kompiliert, die in einem beliebigen Eingangsdatenlayout gespeichert sind.
- Fachbereichsspezifische Abstraktionen, die sich direkt darauf beziehen, wie Ingenieure über ihre Daten nachdenken, einschließlich Messcontainern, Sensorkanälen, Betriebsereignissen sowie dauer- und wegstreckengewichteten Aggregationen.
In diesem Blogbeitrag zeigen wir, wie Impulse das Lakehouse für Messdaten von AVL auf Databricks unterstützt. AVL ist ein weltweit führendes Mobilitätstechnologie-Unternehmen, das auf die Entwicklung, Simulation und das Testen von Fahrzeug- und Energiesystemen spezialisiert ist. Das Unternehmen arbeitet mit Mess- und Simulationsdaten, um Designs zu validieren, das Systemverhalten zu verstehen und die datengesteuerte Produktentwicklung von virtuellen Modellen bis hin zu realen Tests zu beschleunigen. Wir führen Sie durch die Lakehouse-Architektur, drei komplementäre Nutzungsmodi, die Fachingenieuren, Data Engineers und Data Scientists gleichermaßen dienen, und die Auswirkungen, die AVL in der Produktion erzielt hat. Impulse baut auf einem hierarchischen Silver-Layer-Datenmodell auf, das gemeinsam mit Mercedes-Benz entwickelt und in unserem vorherigen Blogbeitrag beschrieben wurde.

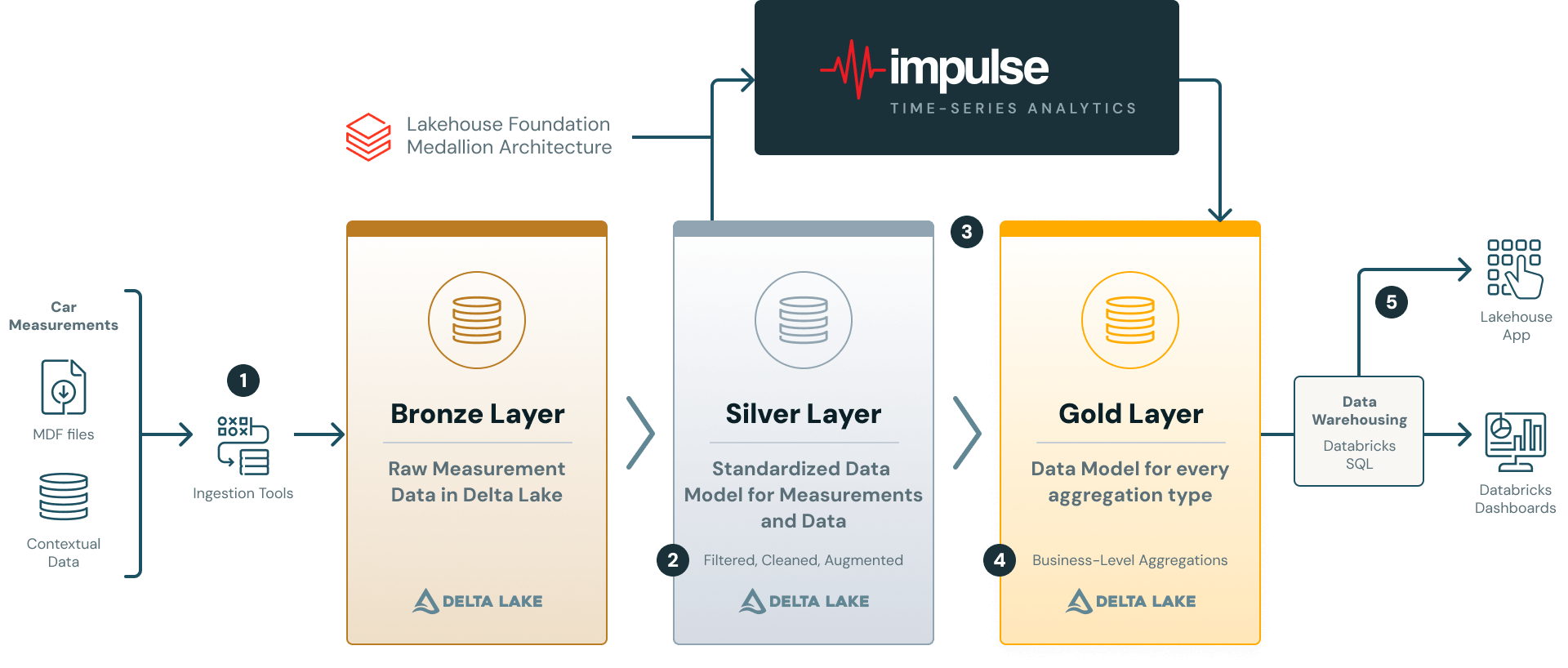
2. Die Architektur – ein Lakehouse für Messdaten
Die Plattform von AVL folgt der Medallion-Architektur, wobei Unity Catalog die Governance über alle Ebenen hinweg bereitstellt und Databricks Workflows die Pipeline orchestriert (siehe Abbildung 2).
1. Quelle und Ingestion: Unverarbeitete Messdateien (z. B. im ASAM MDF4-Format) werden mithilfe eines Databricks Solution Accelerators in den Bronze-Layer geladen. AVL hat diesen Accelerator erweitert, um mit AVL Concerto zu arbeiten, ihrem Messdaten-Managementsystem, das mehrere proprietäre Dateiformate unterstützt. Kontextuelle Metadaten (Fahrzeug-IDs, Softwareversionen, Projekt-Tags usw.) werden zusammen mit den aufgezeichneten Dateien erfasst.
2. Silver-Layer: Bronze-Daten werden in das hierarchische Datenmodell für Messdaten transformiert. Das Modell organisiert Daten um Container (d. h. einzelne Dateien) und Kanäle (Sensorsignale), die jeweils mit Attributen/Tags und Metriken auf Container- und Kanalebene angereichert sind. Der Silver-Layer speichert validierte und qualitätsgesicherte Daten, die für die analytische Verarbeitung vorbereitet sind. Regeln zur Datenqualitätssicherung werden mithilfe des Databricks DQX-Frameworks implementiert und sind vollständig konfigurierbar und anpassbar, um spezifische nachgelagerte Analyseanforderungen zu erfüllen. Weitere Details zum Silver-Layer-Datenmodell finden Sie in unserem zuvor veröffentlichten Blogbeitrag.
3. + 4. Vom Silver- zum Gold-Layer: Der Silver-Layer speist Impulse, das die deklarative Analyselogik in eine verteilte Spark-Ausführung übersetzt. Die Ausgaben können ein Sternschema im Gold-Layer für das Reporting, Ad-hoc-DataFrames für die Exploration oder Feature-Matrizen für ML sein (siehe Abschnitt 5).
5. Bereitstellung und Analyse: BI-Tools wie Databricks Dashboards oder Lakehouse Apps nutzen die Daten des Gold-Layers über SQL Warehouses, was eine interaktive Exploration ermöglicht, ohne die Compute-Pipeline zu beeinträchtigen.
3. Impulse in der Praxis: Eine vollständige Analyse in 10 Zeilen Python
Am besten versteht man Impulse, wenn man es in Aktion sieht. In diesem Abschnitt gehen wir durch ein minimales, aber realistisches Beispiel: die Auswahl von Batterietemperatursensoren, die Definition eines thermischen Durchgehens-Risikoereignisses (Thermal Runaway) basierend auf diesen Sensoren und die Berechnung eines dauergewichteten Histogramms – alles unter Verwendung der Time Series Analytics Language (TSAL).
Auswahl physischer Kanäle und Definition virtueller Kanäle
Der Ausgangspunkt für jede Analyse ist die Auswahl der relevanten physischen Sensorkanäle. Der QueryBuilder durchsucht die Metadatentabellen des Silver-Layers und gibt einen TSAL-Ausdruck zurück. Im folgenden Beispiel rufen wir die höchsten und niedrigsten Zelltemperaturen von unserer EV-Plattform ab und berechnen das Temperaturungleichgewicht (Delta):
Beachten Sie, dass die einzelne Zeile zur Definition des virtuellen Kanals eine nicht triviale Berechnung codiert. Das Framework führt automatisch eine Kanal-Alias-Auflösung und Einheitenumrechnung durch, richtet die Kanäle an einer gemeinsamen Zeitachse aus und interpoliert die Datenpunkte, bevor die Arithmetik ausgeführt wird.
Definieren eines Ereignisses
Ereignisse sind Zeitfenster, die von Signalbedingungen abgeleitet werden. Hier definieren wir ein kritisches Sicherheitsereignis, bei dem die absolute maximale Zelltemperatur einen sicheren Schwellenwert (60 °C) überschreitet ODER die Temperaturabweichung zwischen den Zellen verdächtig hoch ist (mehr als 5 °C):
TSAL-Ausdrücke sind vollständig kombinierbar: Virtuelle Kanäle, boolesche Bedingungen und Aggregationen können aufeinander verweisen.
Berechnen eines Histogramms innerhalb des Ereignisses
Schließlich definieren wir ein dauergewichtetes Histogramm der maximalen Zelltemperatur, bezogen auf das thermische Risikoereignis. Das Histogramm zählt die in jedem Temperaturbereich verbrachte Zeit und liefert unabhängig von der Sensor-Abtastrate physikalisch aussagekräftige Ergebnisse:
Ausführen der Analyse
Zwei Methodenaufrufe stoßen die verteilte Berechnung über alle übereinstimmenden Messaufzeichnungen an und speichern die Ergebnisse als Sternschema-Tabellen der Gold-Schicht in Unity Catalog. Die gesamte Analyse, von der Kanalauswahl über die Berechnung virtueller Signale, die Ereignisdefinition, die Histogramm-Aggregation bis hin zur Speicherung, umfasst gerade einmal etwa 10 Zeilen Python-Code. Der Benutzer muss dafür weder eine DataFrame-Transformation, eine benutzerdefinierte Funktion, einen Join noch eine Window-Funktion schreiben.
4. Drei Möglichkeiten zur Nutzung von Impulse – Reporting, Ad-hoc-Analyse und ML
Impulse unterstützt drei komplementäre Nutzungsmodi (Abbildung 3), die alle auf derselben TSAL-Ausdruckssprache und Query Engine basieren. Im strukturierten Reporting-Modus definieren Fachingenieure Ereignisse und Aggregationen, die parallel über alle übereinstimmenden Aufzeichnungen hinweg ausgeführt und in einem Sternschema der Gold-Schicht gespeichert werden – bereit für AI/BI-Dashboards oder Lakehouse Apps. Die Pipeline kann als Databricks-Workflow geplant werden, um sich automatisch zu aktualisieren, sobald neue Messungen eingehen. Im Ad-hoc-Modus werden TSAL-Ausdrücke direkt von der Query Engine ausgewertet und als Spark DataFrames für die interaktive Untersuchung in Notebooks zurückgegeben, ohne in die Gold-Schicht zu schreiben. Im ML-Modus werden ereignisbezogene Statistiken und Histogrammverteilungen als flache Feature-Matrizen extrahiert, die direkt an MLflow, AutoML oder benutzerdefinierte Trainings-Pipelines übergeben werden können.

Wie AVL Impulse in der Praxis einsetzt
In der Praxis nutzt AVL die Stärken des Impulse-Frameworks, indem es primär dessen strukturierten Reporting-Modus verwendet, um konfigurierbare, standardisierte Analysepakete („Toolboxen“) zu erstellen. Diese Toolboxen werden von Fachingenieuren auf eingehende Messkampagnen angewendet, je nach ihrer spezifischen technischen Aufgabe oder ihrem analytischen Fokus.
Die resultierenden Ausgaben der Gold-Schicht werden nahtlos in Databricks-Dashboards und Lakehouse Apps integriert, wo Ingenieure Ergebnisse interaktiv untersuchen und Histogramme, Heatmaps sowie andere statistische Visualisierungen erstellen können, um datengestützte technische Entscheidungen zu unterstützen.
5. Ergebnisse und Auswirkungen
Mit Hilfe des Impulse-Frameworks und der Databricks Data Intelligence Platform hat AVL eine End-to-End-Engineering-Datenplattform aufgebaut, um die datengestützte Produktentwicklung zu unterstützen. Die Plattform setzt einen neuen Standard in der Automobil-Datenanalyse und liefert Verbesserungen in verschiedener Hinsicht:
Quantitative Verbesserungen
- Erhebliche Verkürzung der Analysezeit (von Tagen auf Minuten im Vergleich zu herkömmlichen Ansätzen)
- Möglichkeit, eine große Anzahl von Messaufzeichnungen in einem einzigen Durchlauf zu verarbeiten
- Infrastrukturkosteneinsparungen im Vergleich zu On-Premise-Lösungen
Qualitative Verbesserungen
- Stärkung der Fachingenieure durch Self-Service-Analytics
- Vollständig reproduzierbare und transparente Analysen
- Teamübergreifende Standardisierung auf einer einzigen, einheitlichen Datenplattform
6. Wie geht es weiter – Open Source und der Weg in die Zukunft
Impulse wird als Databricks-Labs-Projekt veröffentlicht (siehe hier) und ist offen für Beiträge aus der Community in Form von neuen Aggregationen, Query Solvern und fachspezifischen Erweiterungen. Das Framework enthält einen öffentlichen Demo-Datensatz, eine vollständige Dokumentation und Databricks-Notebooks zur Veranschaulichung der Reporting- und ML-Nutzungsmodi.
Für AVL ist die heutige Bereitstellung erst das Fundament ihres Lakehouse für Messdaten. Die Roadmap sieht eine Erweiterung von Impulse auf ADAS und die Validierung des autonomen Fahrens, Predictive Maintenance sowie Simulationsdaten vor, um eine durchgängige, datengestützte Produktentwicklung zu realisieren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.