Transformation von Solar- und Wind-Wartungsberichten mit Genie und AI-Agenten
Wie Plenitude Databricks Genie und Agent Bricks nutzt, um unstrukturierte Wartungs-PDFs in eine durchsuchbare Datenebene und Analysen in natürlicher Sprache für Solar- und Windkraftanlagen zu verwandeln.
von Maria Vallarelli
- Plenitude hat auf Databricks Genie ein agentenbasiertes System entwickelt, das unstrukturierte PDFs zur Solar- und Windkraftwartung in ein einheitliches, abfragbares Datenmodell umwandelt.
- Die Lösung nutzt Genie in Kombination mit semantischen Metadaten aus Unity Catalog und AI Functions, sodass Benutzer Fragen in natürlicher Sprache stellen und Visualisierungen über verschiedene Anlagen und Zeiträume hinweg erstellen können.
- Zu den ersten Ergebnissen gehören schnellere anlagenübergreifende Analysen, kontrollierter Self-Service-Zugriff mit Row-Level Security und eine Grundlage für Predictive Maintenance bei kritischen Komponenten wie Wechselrichtern.
Von Wartungs-PDFs zu umsetzbaren Erkenntnissen mit AI-Agenten
Betriebs- und Wartungsdienstleister für Solar- und Windkraftanlagen liefern Berichte in der Regel als PDFs, wobei die wichtigsten Informationen über Freitexte, Tabellen und Bilder verteilt sind. Dieses Format ist zwar zugänglich, aber nicht skalierbar: Teams müssen jedes Dokument manuell lesen, um Fehler, Trends oder wiederkehrende Probleme zu verstehen. Dadurch werden anlagenübergreifende Vergleiche mit zunehmender Anzahl von Anlagen langsam und inkonsistent.
Plenitude und Databricks haben ein agentenbasiertes System entwickelt, das diese PDF-Wartungsberichte in strukturierte Daten umwandelt. Die Grundidee ist einfach: Dokumente in Daten umwandeln und dann einen AI-Agenten nutzen, um aus diesen Daten umsetzbare Erkenntnisse zu gewinnen. Benutzer können nun Fragen in natürlicher Sprache stellen, Trends im Zeitverlauf analysieren, Anlagen vergleichen und strukturierte Ergebnisse exportieren, anstatt Berichte einzeln durchzugehen.
Agentenbasierte Architektur für die Datenanalyse von PDFs
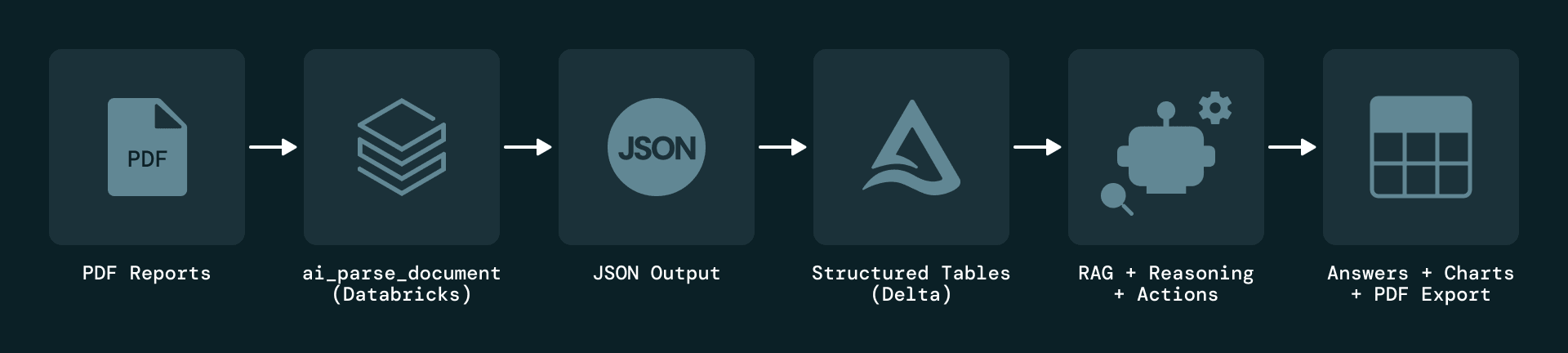
Die Lösung beginnt mit der ereignisgesteuerten Erfassung von PDF-Berichten auf Anlagenebene. Jeder neue Bericht löst einen Databricks-Job aus, der das Dokument parst und eine LLM-basierte Extraktion anwendet. Die extrahierten Elemente werden als JSON serialisiert und in Delta Lake gespeichert, das eine vollständige Versionshistorie für Audits und Replays bereithält.
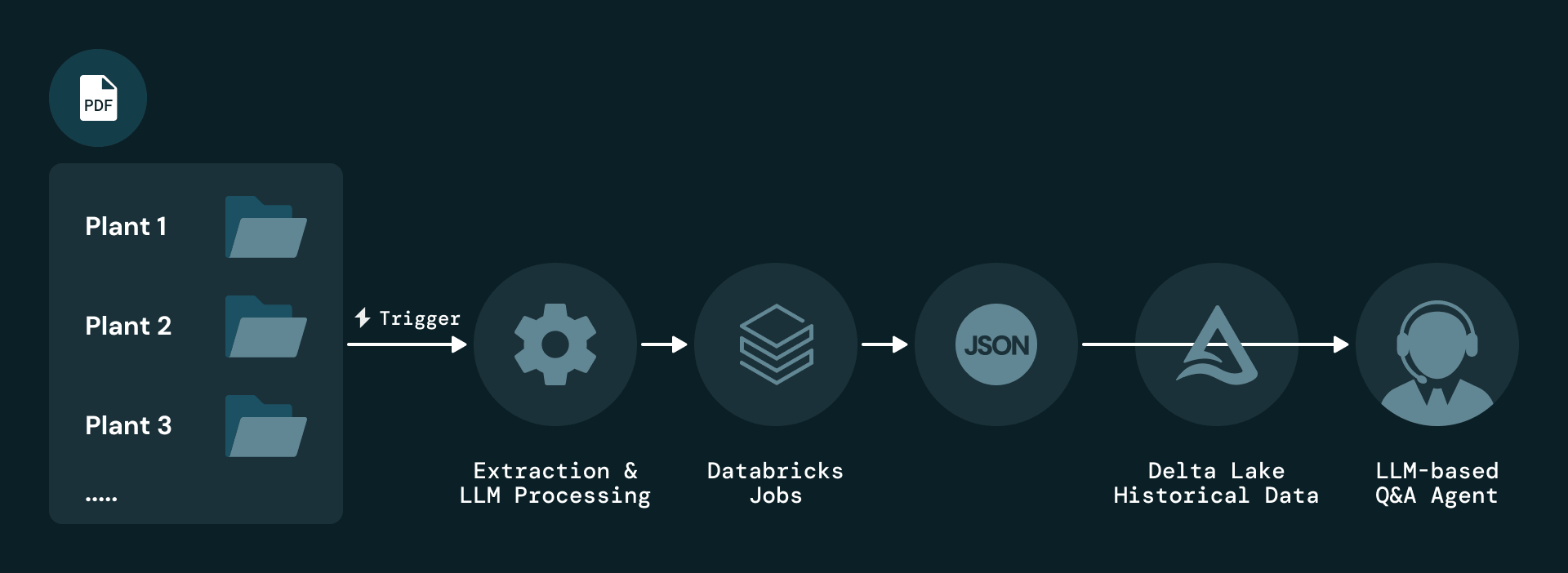
Um das grundlegende Problem zu lösen, dass Wartungsinformationen fast ausschließlich in unstrukturierten PDFs vorliegen, nutzt Plenitude Databricks Document Intelligence AI Functions – insbesondere ai_parse_document, um verschiedene Arten von Elementen aus jeder Seite zu extrahieren, darunter Textblöcke, Tabellen, Abbildungen und Metadaten. Jedes Element wird mit Attributen wie Anlage, Berichtszeitraum, Seitenzahl und Inhaltstyp angereichert, und jeder Datensatz behält eine direkte Verknüpfung zum Originalbericht für eine lückenlose Rückverfolgbarkeit.
Diese Struktur eröffnet leistungsstarke Möglichkeiten:
- Filtern nach Zeit, Kategorie und Region.
- Identifizieren von Inhaltstypen und Verwenden von räumlichen Koordinaten.
- Rückverfolgung jeder Erkenntnis bis zum ursprünglichen PDF.
- Integration mit BI-Tools und digitalen Agenten, ohne die zugrunde liegenden Dokumente zu ändern.
Anstelle von statischen Dateien werden Wartungsberichte zu einer persistenten Datenebene, die für erweiterte Analysen und agentenbasierte Logik bereitsteht.
Datenverarbeitung auf Databricks: vom PDF zu Delta Lake
Die Architektur ist in drei Hauptschichten unterteilt: Erfassung und Parsing, Datenstrukturierung und agentenbasierte Interaktion.
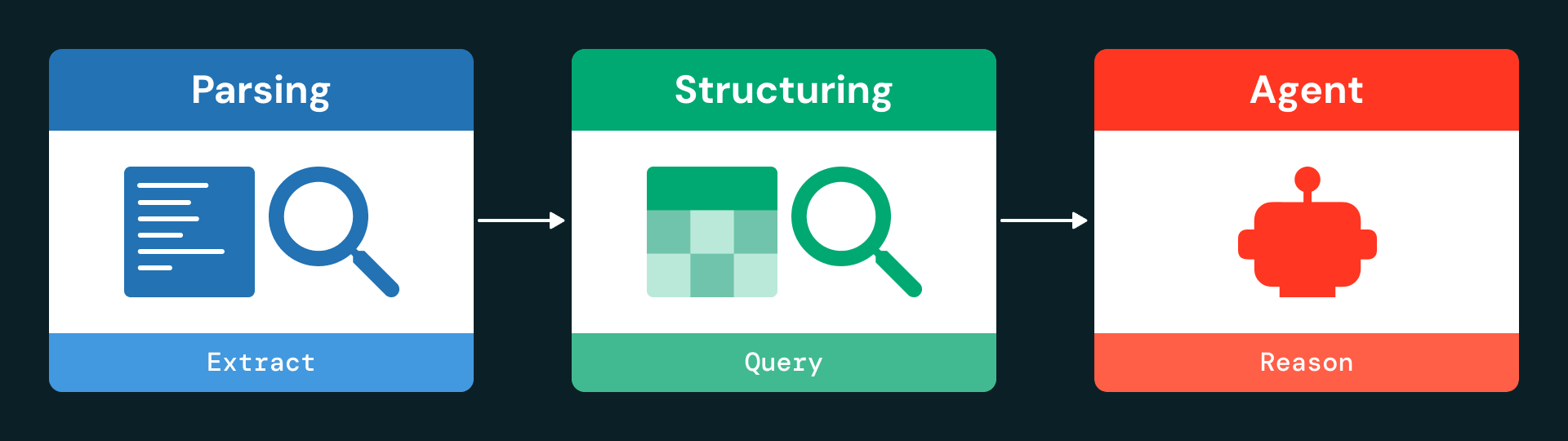
Schritt 1: Parsing
Mithilfe von ai_parse_document extrahiert die Pipeline Text, Tabellen und Metadaten von jeder Seite und serialisiert sie als strukturierte JSON-Objekte. Selbst komplexe Tabellen werden mit vollem Kontext erfasst, einschließlich ihrer Position auf der Seite und ihrer HTML-Darstellung.
Schritt 2: Normalisierung und Speicherung
Für jede Seite (page_id) und jedes Objekt (id) erstellt das System eine Zeile in einer Delta Lake-Tabelle. Jede Zeile enthält:
- Den extrahierten JSON-Inhalt.
- Seiten- und Objekt-IDs.
- Koordinaten (coords), die den Begrenzungsrahmen (Bounding Box) auf der Seite darstellen.
- Den Inhaltstyp (z. B. Text oder Tabelle).
- Hochwertige Metadaten wie Monat, Jahr, Dateiname, Kategorie und Land.
Dieses normalisierte Modell verwandelt PDFs in einen einheitlichen, abfragbaren Datensatz, der transparent ist und sich leicht mit anderen Quellen verknüpfen lässt, während die vollständige Rückverfolgbarkeit zu den Originaldokumenten erhalten bleibt.
Schritt 3: Genie-Space und Agent-Modus
Auf dieser kuratierten Datenebene baut Plenitude einen dedizierten Genie-Space auf und nutzt dann den Agent-Modus von Genie, um Deep Research auf den Daten durchzuführen. Genie nutzt die strukturierten Delta Lake-Tabellen als primären Kontext und ermöglicht es Benutzern, in natürlicher Sprache mit den Wartungsdaten zu interagieren.
Wenn ein Benutzer eine Frage stellt, führt Genie folgende Schritte aus:
- Verwendet semantische Metadaten in Unity Catalog, um verfügbare Tabellen und Spalten zu identifizieren.
- Nutzt detaillierte Spaltenbeschreibungen, einen kuratierten Knowledge Store und SQL-Beispiele, um die Abfragegenerierung zu steuern.
- Generiert und führt SQL-Abfragen auf der strukturierten Ebene aus.
- Gibt Antworten, Visualisierungen und optional exportierbare Ergebnisse zurück.
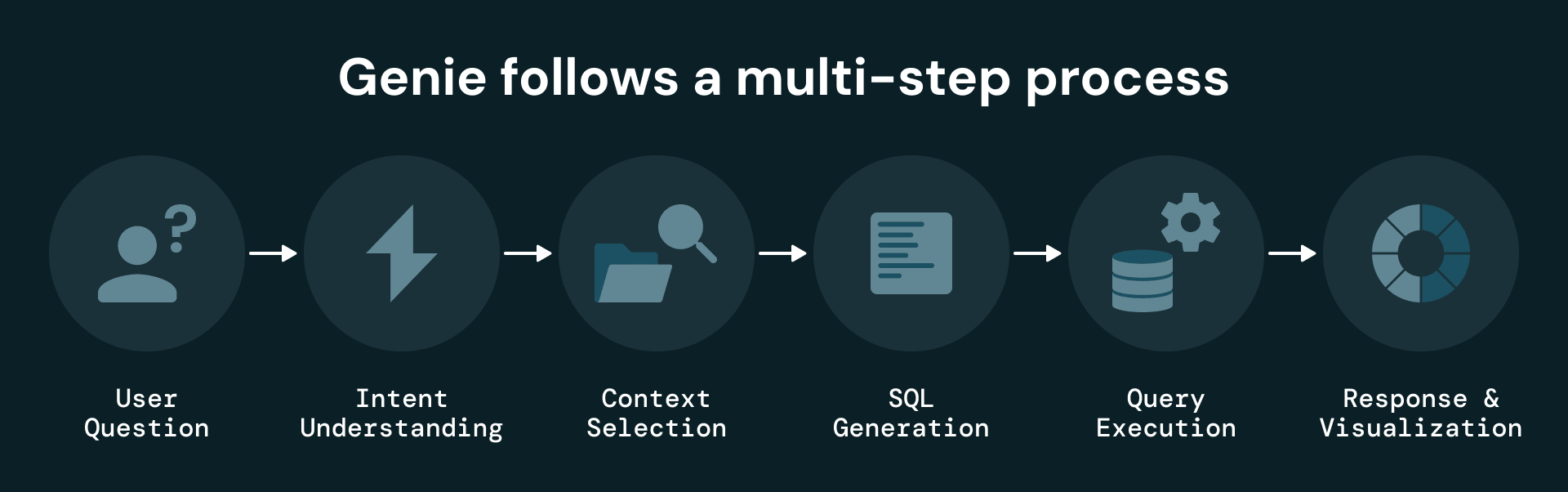
Dieses Design ermöglicht es Genie, sowohl die geschäftliche Semantik der Wartungsdaten als auch deren zugrunde liegende Struktur zu verstehen, was zu präzisen, kontextbezogenen Antworten führt.
Warum Metadaten und Anweisungen für Genie wichtig sind
Um verlässliche Ergebnisse aus komplexen, aus PDFs abgeleiteten Datensätzen zu erhalten, reicht der Kontext allein nicht aus. Plenitude hat festgestellt, dass zwei Designmuster entscheidend sind: reichhaltige Metadaten und explizite Anweisungen für den Genie-Space.
Metadaten als Vertrag mit dem Agenten
Gut definierte Tabellen- und Spaltenbeschreibungen teilen Genie mit, was jedes Feld bedeutet und wie es verwendet werden soll. Beispielsweise identifiziert page_id die Quellseite im Originalbericht, type gibt an, ob es sich bei dem Element um Text oder eine Tabelle handelt, coords kodiert die räumliche Position und content enthält den extrahierten Text oder die Tabellendarstellung. Diese Metadaten verwandeln rohes JSON in verständliches Wissen, über das Genie logische Schlüsse ziehen kann.
Allgemeine Anweisungen als operative Grundlage
Wenn Daten fragmentiert sind oder sich über mehrere Seiten erstrecken, sind domänenspezifische Anweisungen im lokalen Knowledge Store des Genie-Space unerlässlich. Plenitude kodiert Regeln für den Umgang mit mehrseitigen Tabellen, das Ignorieren von HTML-Artefakten, das Ausschließen von Kopfzeilen und das Anwenden anlagenspezifischer Filter.
Ein praktisches Beispiel: Selbst mit vollständigen Metadaten könnte Genie eine falsche Quartalssumme berechnen, wenn es YTD-Spalten summiert oder fehlende Monate ignoriert. Durch das Hinzufügen klarer Anweisungen wie „Nur Spalten auf Monatsebene verwenden, niemals YTD-Felder“ und „Vor dem Summieren überprüfen, ob alle erforderlichen Monate vorhanden sind“, bietet das Team Genie operative Leitplanken, die konsistente Ergebnisse gewährleisten.
Diese Genie-Space-spezifischen Anweisungen helfen Genie in Kombination mit Metadaten aus Unity Catalog, die richtige Logik anzuwenden, um Daten korrekt zu interpretieren.
Nutzung von Genie und Agent Bricks für skalierbare Agent-Workflows
Während Genie eine leistungsstarke Research-Agent-Erfahrung auf der strukturierten Wartungsebene bietet, benötigt Plenitude auch wiederholbare Workflows und Orchestrierung, um eine wachsende Anzahl von Anwendungsfällen zu unterstützen. Agent Bricks ist der nächste Schritt in dieser Entwicklung.
Mit Agent Bricks kann Plenitude von „LLM plus Prompt“-Mustern zu agentischen Workflows übergehen, die im Auftrag von Wartungsanalysten und -ingenieuren Aktionssequenzen ausführen. Dieselben kuratierten Delta Lake-Tabellen, Metadaten und Anweisungen, die Genie antreiben, können von Agenten im Supervisor-Stil wiederverwendet werden, die mit Agent Bricks erstellt wurden, um:
- Komplexe Fragen in kleinere analytische Aufgaben zu zerlegen.
- Die Tool-Flows von Genie aufzurufen, um SQL-Abfragen zu generieren und auszuführen.
- Nachgelagerte Aktionen wie die Berichterstellung oder die Erstellung von Warnmeldungen auszulösen.
Was früher eine manuelle Verknüpfung von Prompts, Tools und Validierungslogik erforderte, kann jetzt in Agent Bricks zentralisiert werden – auf derselben Databricks-Plattform, die auch die Daten verwaltet.
Optimierung der Performance mit automatischem Liquid Clustering
Da Agenten-gesteuerte Abfragen explorativ und dynamisch sind, ist das traditionelle Z-ORDER-basierte Tuning nicht immer ideal. Plenitude hat festgestellt, dass sich Zugriffsmuster mit dem Erscheinen neuer Berichte, Benutzer und Fragen weiterentwickeln, was eine manuelle Clusterung schwer zu pflegen macht.
Automatisches Liquid Clustering hingegen lernt, wie Tabellen tatsächlich genutzt werden, und passt das Layout entsprechend an. Dies reduziert den Bedarf an anfänglichem Indexdesign und fortlaufendem Tuning, was besonders in der Proof-of-Concept-Phase und der frühen Go-Live-Phase wichtig ist. In diesem Zusammenhang ist Auto-Clustering die bevorzugte Wahl für Agenten- und LLM-gesteuerte Workloads auf Delta-Tabellen.
Sicherung des Datenzugriffs für Genie Rooms
Wartungsdaten unterliegen oft länder- oder regionsspezifischen Zugriffsanforderungen. Um diese Regeln konsistent durchzusetzen, nutzt Plenitude eine Sicherheit auf Zeilenebene in Kombination mit Unity Catalog und Tabellen.
Eine Unity Catalog-Funktion ermittelt, auf welche Länder der aktuelle Benutzer zugreifen kann, und gibt eine Liste oder das Schlüsselwort ALL zurück, wenn er vollen Zugriff hat. Eine Tabelle filtert dann die Zeilen basierend auf dieser Funktion, sodass jeder Benutzer nur die Daten für seine autorisierten Länder sieht.
Wenn Benutzer über den Genie Room interagieren, werden alle Abfragen auf der gefilterten Tabelle ausgeführt, sodass die Sicherheit auf Zeilenebene automatisch angewendet wird. Das bedeutet, dass Benutzer Fragen in natürlicher Sprache stellen können, aber nur Ergebnisse aus den Daten erhalten, die sie sehen dürfen. Derselbe Datensatz unterstützt Genie, Agenten und BI-Tools, während sich die Sichtbarkeit je nach Benutzer anpasst.
Zukünftige Verbesserungen: Auf dem Weg zur vorausschauenden Wartung
Da Wartungsberichte offene Vorfälle und Fehlerdetails enthalten, ist das strukturierte Datenmodell eine solide Grundlage für die vorausschauende Wartung. Wechselrichter sind ein gutes Beispiel: Ausfälle können zum Verlust mehrerer Megawattstunden pro Einheit führen, und wiederkehrende Probleme tauchen oft zuerst in den Wartungsnotizen auf.
Durch die Analyse von Fehlermustern im Zeitverlauf kann Plenitude:
- Potenzielle Erfassungsprobleme identifizieren.
- Frühwarnsignale erkennen.
- Anlagen priorisieren, die eine genauere Untersuchung erfordern.
- Prädiktive Modelle mit qualitativ hochwertigeren Vorfallshistorien speisen.
Das agentenbasierte System verwandelt diese Signale in zugängliche Analysen, Trends und Visualisierungen, sodass Teams Probleme vorhersehen können, anstatt nur darauf zu reagieren.
Wichtigste Vorteile und Funktionen
Beim bisherigen Ansatz beschränkte sich die Analyse auf das einzelne Lesen von Berichten, was es schwierig machte, historische Trends zu erstellen, Anlagen zu vergleichen oder strukturierte Ergebnisse zu generieren. Das Erstellen von Diagrammen, das Exportieren von Ergebnissen oder das Kombinieren von Erkenntnissen aus mehreren Berichten war bestenfalls manuell und oft gar nicht machbar.
Mit dem Genie Agent Mode auf Databricks und einem agentenfreundlichen Datenmodell kann Plenitude:
- Wartungsdaten über Zeiträume und Anlagen hinweg untersuchen.
- Visualisierungen erstellen und Ergebnisse exportieren, einschließlich PDF-Ausgaben.
- Frühzeitige Signale und wiederkehrende Muster erkennen.
- Analysen skalieren, ohne den manuellen Aufwand zu erhöhen.
Durch die Kombination von strukturierten Daten, Business-Metadaten und KI-Schlussfolgerungen generiert das System Analysen, Trends und Visualisierungen, die eine frühzeitige Erkennung und Vorhersage von Problemen unterstützen, anstatt nur rückblickend zu berichten.
Erfahren Sie mehr über Databricks Genie und Agent Bricks.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.