Fortschritte bei Apache Iceberg auf Databricks: Iceberg v3 GA, Open Sharing und Unified Governance
Der umfassendste und offenste Katalog für Apache Iceberg
von Jason Reid, Ryan Blue, Daniel Weeks und Michelle Leon
*Unity Catalog ist jetzt der umfassendste, interoperabelste und produktionsreifste Apache Iceberg-Katalog, wobei Managed Iceberg, Iceberg v3 und Foreign Iceberg in den GA überführt werden.
*Fünf Funktionen heben ihn hervor: offene APIs, Katalogföderation, bereichsübergreifende Zugriffssteuerung, Zero-Copy-sicheres Teilen und KI-gesteuerte Optimierung.
*Mit Blick auf die Zukunft werden Iceberg v4 und Delta 5.0 auf eine einheitliche Metadatenstruktur konvergieren, wodurch der Kompromiss zwischen Interoperabilität und produktionsreifer Leistung beendet wird.
Die nächste Phase des Open Lakehouse wird durch den Katalog definiert. Offene Tabellenformate ermöglichten es vielen Engines, auf denselben Daten zu arbeiten, aber der Katalog bestimmt, ob diese Daten konsistent über Systeme hinweg verwaltet, optimiert und geteilt werden können. Da immer mehr Workloads, einschließlich KI und agentenbasierter Anwendungen, auf einen verwalteten Datenzugriff über viele Systeme angewiesen sind, benötigen Unternehmen einen Iceberg-Katalog, der Interoperabilität, hohe Leistung und unternehmensreife Governance bietet.
Deshalb kündigen wir heute die umfassendsten Iceberg-Funktionen an, die für jeden Lakehouse-Katalog verfügbar sind. In diesem Blogbeitrag werden wir neue Verbesserungen für die Iceberg-Unterstützung in Unity Catalog besprechen und 5 Gründe aufzeigen, warum Unity Catalog der interoperabelste Iceberg-Katalog auf dem Markt ist.
Was ist neu: Iceberg-Funktionen im Überblick
Wir haben eine breite Palette von Iceberg-Funktionen in Databricks und Unity Catalog allgemein verfügbar gemacht und in die Vorschauversion aufgenommen, um sicherzustellen, dass jede Engine, jeder Katalog und jedes Team nahtlos zusammenarbeiten kann.
- Managed Iceberg (GA): Erstellen, Lesen, Schreiben, Optimieren, Verwalten und Teilen von Iceberg-Tabellen direkt in Unity Catalog, wobei Predictive Optimization und Liquid Clustering die manuelle Arbeit zur Leistungssteigerung von Tabellen überflüssig machen.
- Iceberg v3 (GA): Native Unterstützung für Deletion Vectors, Row Tracking und den neuen VARIANT-Datentyp für verwaltete, externe und UniForm-aktivierte Tabellen.
- Foreign Iceberg (GA) & Credential Vending für Foreign Iceberg (GA): Registrieren, Verwalten und sicheres Abfragen von Iceberg-Tabellen, die in externen Katalogen verwaltet werden.
- Externes Teilen mit Iceberg-Clients (GA): Live-Daten mit beliebigen Iceberg REST-kompatiblen Clients über das offene DeltaSharing-Protokoll teilen.
- Externes Teilen von Foreign Iceberg-Tabellen (Public Preview): Iceberg-Tabellen, die außerhalb von Databricks verwaltet werden, nativ in Databricks und im gesamten Delta Sharing-Ökosystem teilen.
- Iceberg-kompatible materialisierte Sichten (Gated Public Preview): Erstellen Sie hochperformante materialisierte Sichten in Databricks und stellen Sie sie nachgelagert als native Iceberg-Tabellen bereit.
- Cross-Engine Attribute-Based Access Control (Beta): Erzwingen Sie feingranulare Governance-Richtlinien für externe Iceberg-Engines über Iceberg REST Catalog Scan APIs.
- Neue Catalog Federation-Konnektoren (Preview): Erweiterung der Catalog Federation-Unterstützung von Unity Catalog über AWS Glue, Snowflake Horizon, Hive Metastore, und Salesforce Data Cloud hinaus auf Google Cloud Lakehouse und Palantir, wodurch Unity Catalog zu Ihrer zentralen Anlaufstelle wird.
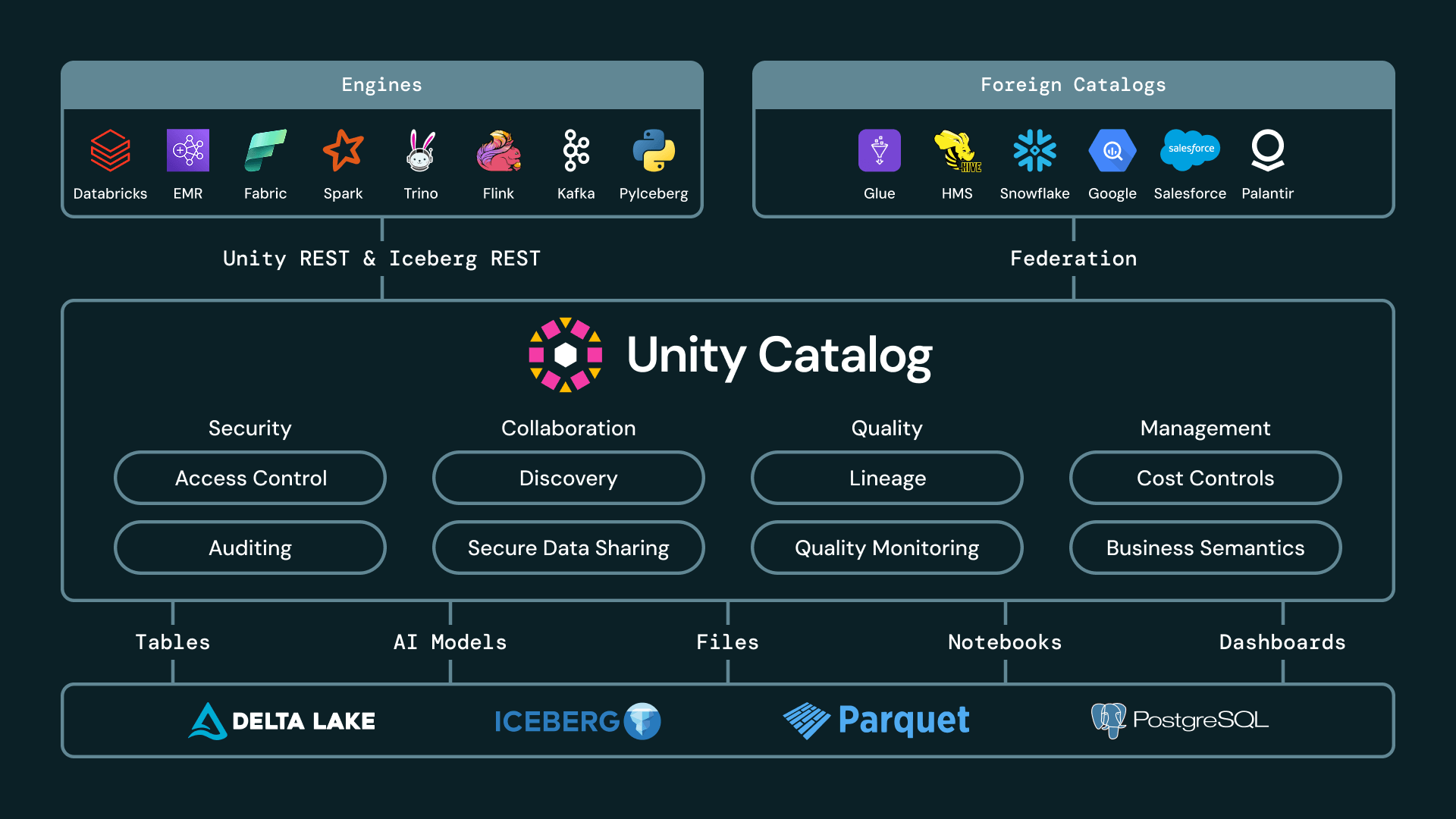
Fünf Gründe, warum Unity Catalog der interoperabelste Iceberg-Katalog ist
Um ein vollständig offenes Lakehouse bereitzustellen, muss ein Iceberg-Katalog über die einfache Metadatenverfolgung hinausgehen. Er muss Ihnen absolute Flexibilität über verschiedene Engines, Anbieter und Governance-Modelle hinweg bieten. Wir glauben, dass die Bewertung eines offenen Iceberg-Katalogs davon abhängt, wie gut er fünf grundlegende operative Anforderungen erfüllt: die Bereitstellung von offenen APIs, die Federation über externe Umgebungen, die Durchsetzung von Cross-Engine-Governance, die Ermöglichung sicherer und offener Freigaben, und kontinuierliche Leistungs- und Formatinnovation.
Unity Catalog ist der einzige Katalog, der alle fünf Anforderungen erfüllt.

1. Offene APIs und Credential Vending
Kunden sollten die Engine verwenden können, die am besten zur Workload passt, sei es Spark, Trino, Flink, Snowflake, DuckDB, pandas oder ein anderer Iceberg-kompatibler Client, ohne Daten zu kopieren oder jeder Engine weitreichende Speicherberechtigungen zu erteilen.
Mit Managed Iceberg, das jetzt allgemein auf Databricks verfügbar ist, können Kunden Iceberg-Tabellen in Unity Catalog von jeder Engine aus über die Iceberg REST Catalog APIs von UC erstellen, lesen und schreiben.
Die Iceberg REST Catalog APIs von UC erstrecken sich jetzt auch über verwaltete Iceberg-Tabellen hinaus. UC stellt auch Anmeldeinformationen für föderierte Iceberg-Tabellen bereit und bietet so sicheren Zugriff über offene APIs, selbst auf Tabellen, die in externen Katalogen verwaltet werden. Und derzeit in Gated Public Preview können Kunden materialisierte Sichten in Databricks erstellen und diese als Iceberg-Tabellen für nachgelagerte Verbraucher bereitstellen. Mit breiterer Verfügbarkeit in den kommenden Wochen können Kunden Iceberg-kompatible materialisierte Sichten direkt mit CREATE MATERIALIZED VIEW my_mv USING ICEBERG erstellen.
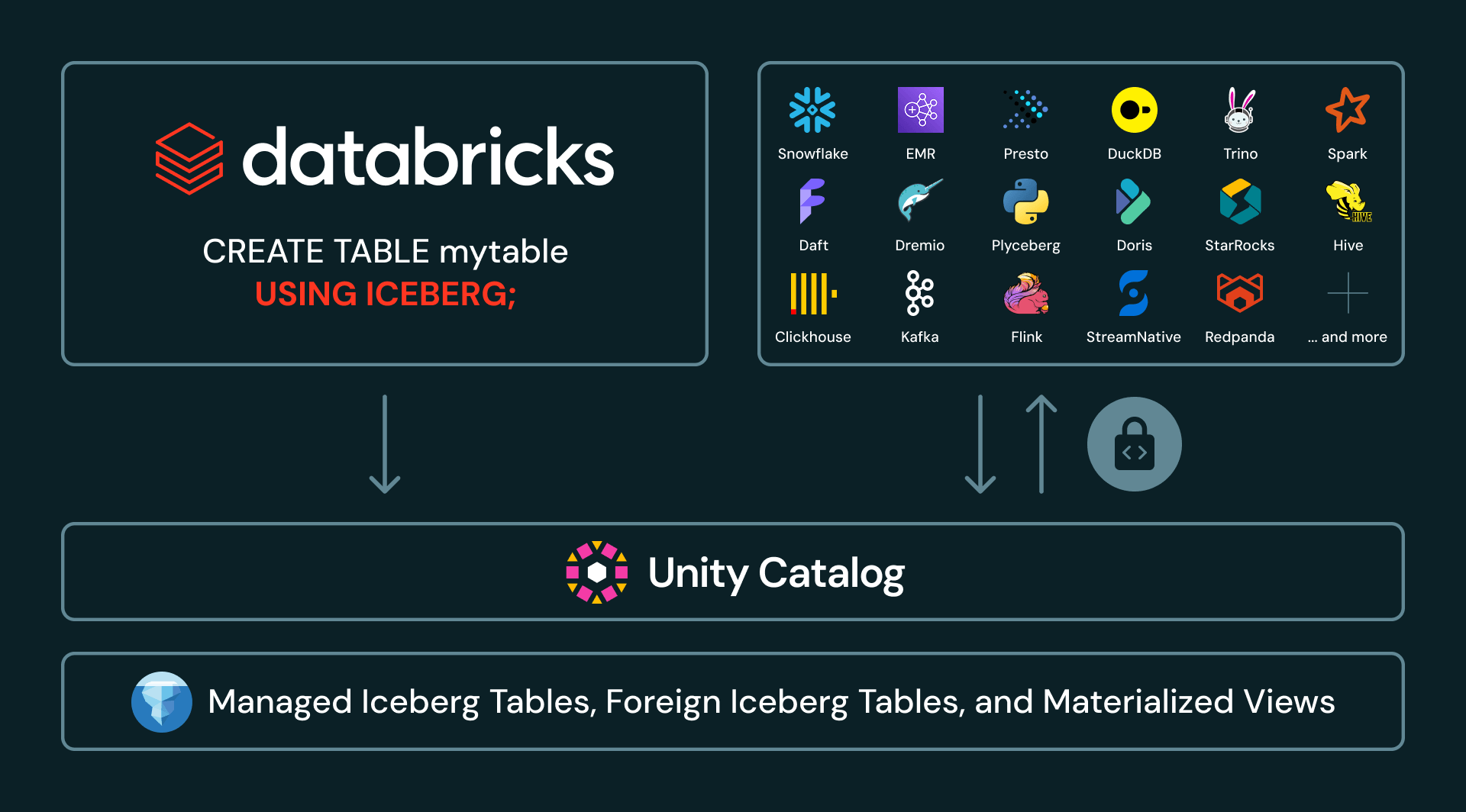
2. Catalog Federation: Ihr gesamtes Iceberg-Estate in einer Ansicht
Viele große Unternehmen verfügen über mehrere Kataloge in ihrem Lakehouse. Sie können beispielsweise Daten haben, die über Unity Catalog, AWS Glue, Snowflake Horizon und Hive Metastore verteilt sind. Mit Foreign Iceberg, das jetzt allgemein verfügbar ist, kann Unity Catalog Iceberg-Tabellen verwalten, die in anderen Katalogen verwaltet werden. Kunden können externe Iceberg-Tabellen über Databricks entdecken, sichern, abfragen und teilen, während die Daten und der Quellkatalog unverändert bleiben.
Unity Catalog unterstützt jetzt eine breite und wachsende Palette von Iceberg-Katalogintegrationen, darunter AWS Glue, Google Cloud Lakehouse Runtime Catalog, Snowflake Horizon, Palantir, Salesforce und Workday. Diese Integrationen ermöglichen es Unternehmen, Unity Catalog als zentrale Anlaufstelle für ihr Iceberg-Estate zu behandeln, auch wenn die Daten woanders produziert oder verwaltet werden.
3. Cross-Engine Attribute-Based Access Control
Historisch gesehen wurden Zeilen- und Spaltenkontrollen innerhalb einer einzelnen Engine durchgesetzt. Im Open Lakehouse kann dieselbe Tabelle von vielen Engines abgerufen werden. Dies führte zu einem schwierigen Problem: Die Governance muss überall dort funktionieren, wo auf Daten zugegriffen werden kann.
Mit Cross-Engine Attribute-Based Access Controls (ABAC), das jetzt in der Beta-Version verfügbar ist, erweitert Unity Catalog die Attributbasierte Zugriffskontrolle auf Iceberg-Clients über die Iceberg REST Catalog Scan APIs.
So funktioniert es: Administratoren definieren Richtlinien einmal in UC, einschließlich Spaltenmasken, Zeilenfilter und Tag-basierte Richtlinien. Wenn eine externe Iceberg-Engine auf Daten zugreift, wertet UC die anwendbaren Richtlinien während der serverseitigen Scan-Planung aus. UC gibt dann einen gefilterten Scan-Plan zurück, sodass die Engine beim Verarbeiten der Abfrage nur autorisierte Daten liest.
Dies bringt eine feingranulare Governance für externe Iceberg-Engines unter Verwendung offener Standards. Jede Engine, wie z. B. Apache Spark oder DuckDB, die den Iceberg REST Catalog Scan Planning Client implementiert (hinzugefügt in der Iceberg 1.11-Version), kann mit durchgesetztem ABAC auf Daten zugreifen. Kunden können die beste Engine für jede Workload verwenden und gleichzeitig ein einheitliches Governance-Modell über das Lakehouse hinweg beibehalten.
Unity Catalog und Managed Iceberg geben uns das Beste aus beiden Welten: native Performance für unsere KI- und ML-Pipelines und offene Interoperabilität für jeden nachgelagerten Consumer. Ein Schreibpfad, keine Duplizierung und eine Governance-Schicht, die jede Engine respektiert, einschließlich der KI-gesteuerten Produkte, die wir für Ripplings Data Cloud entwickeln.—Tae Lee, Staff Engineer, Data Platform bei Rippling
4. Zero-Copy-Datenaustausch für externe & domänenübergreifende Kollaborationen
Domänenübergreifende Freigaben zwingen Datenanbieter oft zu schlechten Kompromissen: Daten auf eine andere Plattform kopieren, komplexe externe Authentifizierungsmechanismen aufbauen oder verlangen, dass jeder Empfänger dasselbe Anbieter-Ökosystem verwendet. Databricks hat den sicheren Open-Data-Sharing mit Delta Sharing, dem am weitesten verbreiteten Open-Source-Protokoll für den Austausch von Daten und KI, vorangetrieben – unterstützt sowohl Databricks-zu-Databricks als auch Databricks-zu-Open-Sharing.
Wir freuen uns, Ihnen mitteilen zu können, dass Iceberg jetzt ein First-Class-Citizen in Databricks DeltaSharing ist, sowohl als Quellformat als auch als Ziel. Mit dem Teilen mit Iceberg-Clients, das jetzt allgemein verfügbar ist, können Databricks-Kunden Live-Daten extern mit jedem Empfänger teilen, der die Iceberg REST Catalog API unterstützt. Empfänger können freigegebene Daten von Iceberg-kompatiblen Clients wie Snowflake, Trino, Flink und Spark abfragen, ohne manuelle Aufnahme oder Kopien. Anbieter verwalten weiterhin den Zugriff, die Überwachung und die Governance über Unity Catalog.
Wir kündigen auch die Public Preview von Foreign Iceberg Sharing an. Kunden können Iceberg-Tabellen freigeben, die außerhalb von Databricks verwaltet oder katalogisiert, aber in Unity Catalog registriert und verwaltet werden. Das bedeutet, dass UC als Freigabeebene für verwaltete und fremde Iceberg-Tabellen dienen kann, während die Daten vor Ort bleiben und die Governance zentralisiert wird.
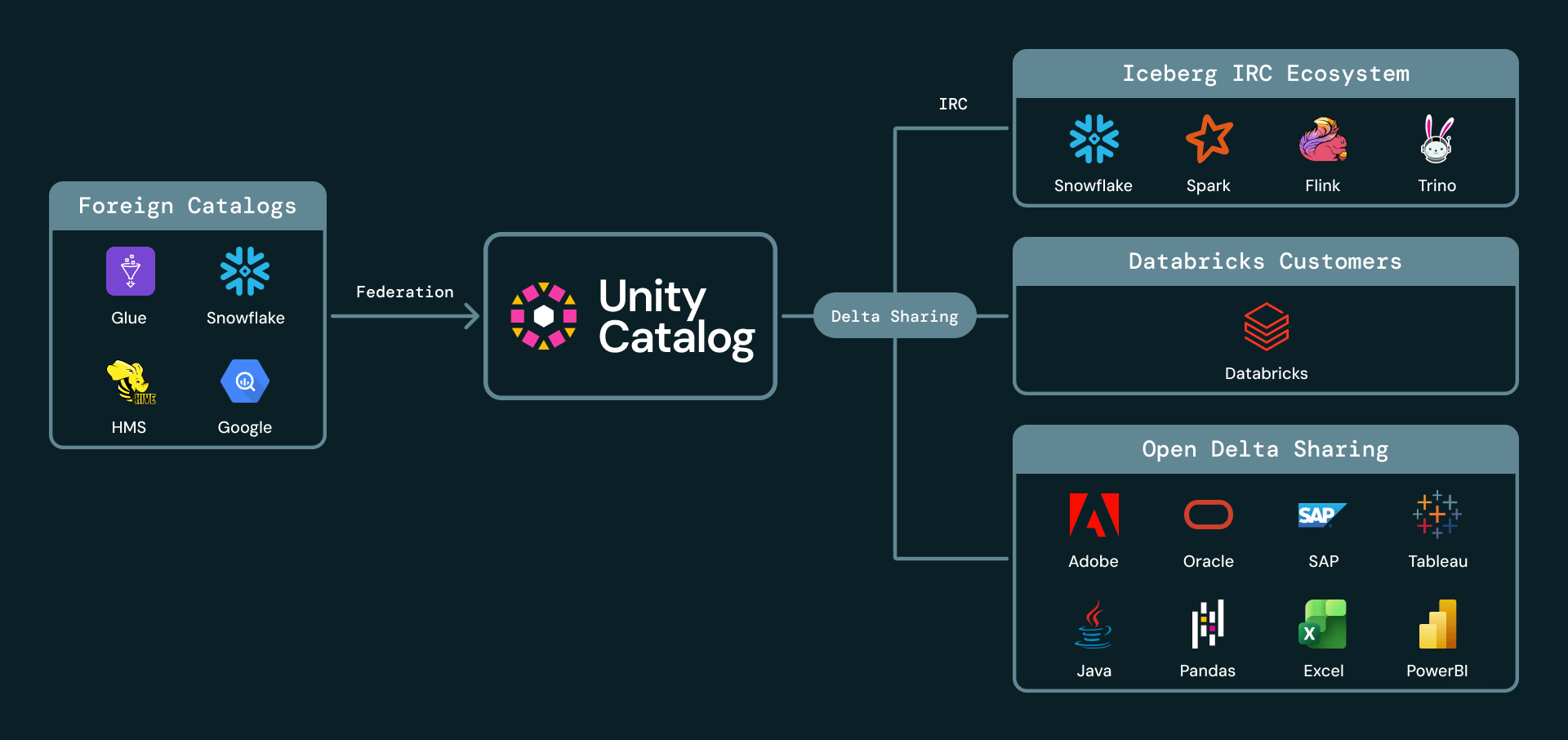
5. Performance- und Format-Innovation: schnellere Open Tables ohne manuelles Tuning
Open Interoperability funktioniert nur, wenn die Tabellen bei Produktionsskalierung performant bleiben. Unity Catalog ist der einzige Katalog, der KI verwendet, um Ihre Tabellen für schnellere Abfragen und geringeren Betriebsaufwand zu optimieren. Predictive Optimization bestimmt, welche Tabellen Wartung benötigen, welche Optimierungen ausgeführt werden sollen und wie oft sie ausgeführt werden sollen, und passt das Datenlayout Ihrer Tabelle basierend auf den Workload-Mustern an. Dies reduziert den Betriebsaufwand, der erforderlich ist, um Iceberg-Tabellen bei sich ändernder Nutzung schnell und kosteneffizient zu halten, und diese Optimierungen kommen allen Engines zugute – beispielsweise verbessern Datenlayout-Optimierungstechniken das Data Skipping für Abfragen, die außerhalb von Databricks ausgeführt werden, wie z. B. in Apache Spark. Wir innovieren ständig an der Customer Experience – und sind der einzige Katalog, der Clustering-Schlüssel intelligent für optimale Leistung auswählen oder Open Tables automatisch mit den neuesten Innovationen aktualisieren kann, basierend auf früheren Zugriffsmustern.
Databricks treibt auch den Iceberg-Standard selbst voran. Mit Iceberg v3, das jetzt allgemein auf Databricks verfügbar ist, erhalten Kunden Unterstützung für Deletion Vectors, Row Tracking und VARIANT über verwaltete Iceberg-Tabellen, fremde Iceberg-Tabellen und UniForm-aktivierte verwaltete Tabellen. Diese Funktionen schließen wichtige Lücken zwischen Performance und Interoperabilität: Deletion Vectors beschleunigen Updates, Merges und Deletes; Row Tracking unterstützt eine effizientere inkrementelle Verarbeitung; und VARIANT bietet eine Standarddarstellung für semi-strukturierte Daten. Diese Features funktionieren auch nahtlos über Delta- und Iceberg-Tabellen hinweg und ermöglichen Interoperabilität ohne Neuschreiben von Daten.
Diese Investitionen zielen auf dasselbe Ziel ab: Open Tables, die Kunden nicht zwingen, zwischen Ökosystem-Interoperabilität und den für Produktions-Workloads erforderlichen Performance-Funktionen zu wählen.
Unity Catalog gibt uns einen zentralen Ort zur Verwaltung von Daten über Teams und Systeme hinweg, während Managed Iceberg die Leistung liefert, die wir in unserem Maßstab benötigen.—Kayvon Raphael, Head of Data Engineering, Magnite
Zusammengenommen machen diese fünf Funktionen Unity Catalog zum besten Katalog für Apache Iceberg. UC bietet Kunden offenen Zugriff auf Iceberg-Tabellen, eine einheitliche Ansicht über Kataloge hinweg, feingranulare Governance über Engines hinweg, sicheres Teilen über Domänen hinweg und automatische Optimierung für Produktions-Workloads.
Die nächste Grenze: Iceberg v4
Mit Iceberg v4 überdenken wir die Kernmetadatenstruktur von Grund auf für bessere Performance, Skalierbarkeit und Interoperabilität. Unser Ziel ist es, die Messlatte für Performance und Feature-Innovation kontinuierlich höher zu legen und dies auf eine Weise zu tun, die Iceberg und Delta Lake näher zusammenbringt. Deshalb schlagen wir auch vor, dass die nächste Version von Delta, Delta 5.0, die adaptive Metadatenbaumstruktur übernimmt.
Das Ergebnis ist einfach: Alle verwalteten Tabellen werden in Unity Catalog automatisch optimiert, über offene APIs gesteuert und für jede Engine verfügbar gemacht. Während andere Plattformen Sie zwingen, zwischen Interoperabilität und fortschrittlicher Performance und Funktionen zu wählen. Mit Unity Catalog erhalten Sie beides.
Erfahren Sie mehr auf dem Data + AI Summit
Besuchen Sie uns auf dem Data + AI Summit, um mehr über Apache Iceberg, Unity Catalog, Open Sharing, Federation und die nächste Phase der Delta- und Iceberg-Formatvereinheitlichung zu erfahren.
- Format Co-Evolution: Wie Iceberg v4 und Delta 5.0 Unified Metadata teilen Tauchen Sie tiefer in den adaptiven Metadatenbaum von Iceberg v4 ein und erfahren Sie, wie Delta 5.0 dieselbe Content-Metadatenstruktur übernimmt, die bessere Performance und Interoperabilität in einem vereinheitlichten Ökosystem ermöglicht.
- Ihr Leitfaden zu Open Table Formats: Delta, Iceberg, Best Practices und Was kommt als Nächstes Erfahren Sie, was es Neues bei Delta Lake und Apache Iceberg gibt, einschließlich Best Practices für die Arbeit mit verschiedenen Formaten und ein erster Blick auf unsere kommende Roadmap zur besseren Unterstützung von KI/ML-Workloads.
- Magnites Reise der Interoperabilität auf einem Petabyte an Iceberg-Daten Erfahren Sie, wie Magnite den Zugriff mit Unity Catalog zentralisiert und gleichzeitig die Performance über Engines hinweg verbessert hat, darunter Apache Spark, DuckDB und Snowflake.
- So greifen Sie sicher auf Daten mit Lakehouse Federation über AWS Glue, Snowflake, BigQuery und Fabric zu Sehen Sie, wie Unity Catalog als Katalog der Kataloge für die Verwaltung, Sicherung und Abfrage von Daten über externe Systeme hinweg fungieren kann, ohne Daten zu kopieren.
- Apache Iceberg Interoperabilität: First-Class Open Support in Databricks Delta Sharing
Sehen Sie den First-Class-Iceberg-Support in Delta Sharing, einschließlich wie Foot Locker Databricks Open Sharing für plattformübergreifende Iceberg-Interoperabilität nutzt.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.