Was ist Big-Data-Analyse?
Die Untersuchung umfangreicher, vielfältiger Datensätze von IoT-Geräten, sozialen Medien und E-Commerce-Plattformen deckt verborgene Muster, Zusammenhänge und umsetzbare Erkenntnisse auf.
- Analysiert strukturierte, semistrukturierte und unstrukturierte Daten von Terabytes bis Zettabytes mithilfe fortschrittlicher Techniken wie maschinellem Lernen, natürlicher Sprachverarbeitung und Deep Learning.
- Nutzt verteilte Frameworks wie Hadoop, Spark und Hive zur Datenverarbeitung über ganze Netzwerke hinweg und überwindet so die Einschränkungen herkömmlicher ETL-Prozesse und langsamer Stapelverarbeitung.
- Ermöglicht Kostensenkungen durch Cloud Computing, Echtzeit-Entscheidungsfindung mit In-Memory-Analysen und hilft bei der Identifizierung neuer Produkte, Markttrends und Kundenpräferenzen.

Was ist Big Data Analytics?
Als Big Data Analytics bezeichnet man den oft komplexen Prozess der Untersuchung großer und heterogener Datensets: die so genannten „Big Data“. Sie stammen aus verschiedenen Quellen wie dem E-Commerce, mobilen Geräten, den sozialen Medien und dem Internet der Dinge (IoT). Der Vorgang umfasst die Einbindung verschiedener Datenquellen, die Umwandlung unstrukturierter in strukturierte Daten und die Gewinnung von Erkenntnissen aus diesen Daten mithilfe spezialisierter Tools und Verfahren, die die Datenverarbeitung auf ein ganzes Netzwerk verteilen.
Die Menge an digitalen Daten wächst rasant und verdoppelt sich etwa alle zwei Jahre. Big Data Analytics bieten einen anderen Ansatz für die Verwaltung und Analyse all dieser Datenquellen. Zwar gelten die Prinzipien der traditionellen Datenanalyse im Allgemeinen weiterhin, doch Umfang und Komplexität von Big Data Analytics erforderten die Entwicklung neuartiger Methoden zur Speicherung und Verarbeitung strukturierter und unstrukturierter Daten im Petabyte-Bereich.
Kernprozess & Methoden
Die Nachfrage nach höheren Geschwindigkeiten und größeren Speicherkapazitäten schuf ein technologisches Vakuum, das bald durch Ansätze gefüllt wurde, darunter:
- Speichermethoden wie Data Warehousesund Data Lakes
- Nichtrelationale Datenbanken wie NoSQL
- Technologien und Frameworks für Datenverarbeitung und Datenverwaltung, wie z. B. Open Source Apache Hadoop, Spark und Hive.
Big Data Analytics nutzt fortschrittliche Verfahren zur Analyse enorm großer Datenmengen, die strukturierte, halbstrukturierte und unstrukturierte Daten aus verschiedenen Quellen und in unterschiedlichen Volumina vom Terabyte- bis zum Zettabyte-Bereich umfassen.
Traditionelle Datenanalyse vs. Big Data Analytics
Vor der Erfindung von Hadoop waren die Technologien, die den modernen Speicher- und Rechensystemen zugrunde liegen, relativ schlicht. Daher waren die Unternehmen meist auf die Analyse von „Small Data“ (also kleinen Datenbeständen) beschränkt. Auch diese Form der Analytics kann schwierig sein, insbesondere die Integration neuer Datenquellen. Bei der herkömmlichen Datenanalyse, die auf relationalen Datenbanken mit strukturierten Daten basiert, muss jedes Byte Rohdaten auf eine bestimmte Weise formatiert werden, bevor es zur Analyse in die Datenbank aufgenommen werden kann. Dieser oft langwierige Prozess, der gemeinhin als „Extract, Transform, Load“ (kurz „ETL”) bezeichnet wird, ist für jede neue Datenquelle erforderlich. Das Hauptproblem dieses dreiteiligen Prozesses und Ansatzes besteht darin, dass er äußerst zeit- und arbeitsintensiv ist und Data Scientists und Engineers manchmal bis zu 18 Monate brauchen, um ihn umzusetzen oder zu ändern.
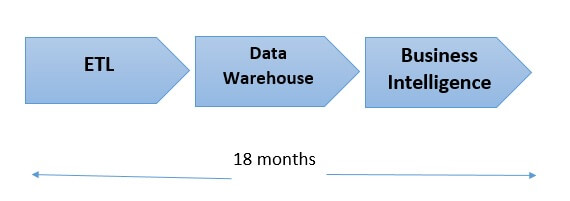
Waren die Daten jedoch erst einmal in der Datenbank, dann war es für Datenanalysten in den meisten Fällen ein Leichtes, sie abzufragen und zu analysieren. Doch dann kamen Internet, E-Commerce, soziale Medien, mobile Geräte, Marketingautomatisierung, das Internet der Dinge (IoT) usw. auf, und Größe, Volumen und Komplexität der Rohdaten wurden für alle außer eine Handvoll Institutionen einfach zu groß, um sie im Rahmen des normalen Geschäftsbetriebs zu analysieren.
Das Playbook für agentenbasierte KI für Unternehmen

Die häufigsten Datentypen in Big Data Analytics
- Webdaten. Daten zum Webverhalten von Kunden, beispielsweise Besuche, Seitenaufrufe, Suchanfragen, Käufe usw.
- Textdaten. Daten, die aus Textquellen wie E-Mails, Nachrichtenartikeln, Facebook-Feeds, Word-Dokumenten und vielem mehr generiert werden. Sie gehören zu den umfangreichsten und meistverwendeten Arten von unstrukturierten Daten.
- Zeit und Ort oder Geodaten: GPS und Mobiltelefone sowie WLAN-Verbindungen machen Zeit- und Standortinformationen zu einer wachsenden Quelle interessanter Daten. Hinzu kommen auch geografische Daten zu Straßen, Gebäuden, Gewässern, Anschriften, Personen, Arbeitsstätten und Transportwegen, die aus geografischen Informationssystemen generiert wurden.
- Echtzeitmedien. Echtzeitdatenquellen können Echtzeit-Streaming oder ereignisbasierte Daten umfassen.
- Daten aus intelligenten Stromnetzen und von Sensoren. Sensordaten von Fahrzeugen, Ölpipelines, Windkraftanlagen und weiteren Sensoren werden oft in extrem kurzen Abständen erfasst.
- Daten aus sozialen Netzwerken: Unstrukturierter Text (Kommentare, Likes usw.) von Social-Media-Websites wie Facebook, LinkedIn, Instagram usw. wächst. Es ist sogar möglich, eine Link-Analyse durchzuführen, um das Netzwerk eines bestimmten Benutzers zu entschlüsseln.
- Verknüpfte Daten: Solche Daten werden mithilfe von Standardtechnologien im Web – z. B. HTTP, RDF, SPARQL und URLs – gesammelt.
- Netzwerkdaten. Daten aus sehr großen sozialen Netzwerken wie Facebook und X oder Technologienetzwerken wie dem Internet, dem Telefon- oder einem Transportnetz.
Big Data Analytics hilft Unternehmen dabei, ihre Daten zu nutzen und fortschrittliche Data-Science-Verfahren und -Methoden wie z. B. die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), Deep Learning und maschinelles Lernen einzusetzen, um verborgene Muster, unbekannte Zusammenhänge, Markttrends und Kundenvorlieben aufzuspüren und so neue Chancen zu erkennen und fundiertere Geschäftsentscheidungen zu treffen.
Vorteile der Verwendung von Big Data Analytics sind:
- Kostensenkung. Cloud Computing und Speichertechnologien wie Amazon Web Services (AWS) und Microsoft Azure sowie Technologien wie Apache Hadoop, Spark und Hive können Unternehmen dabei helfen, ihre Ausgaben für die Speicherung und Verarbeitung großer Datenmengen zu senken.
- Verbesserte Entscheidungsfindung. Mit der Geschwindigkeit von Spark und In-Memory-Analysen in Verbindung mit der Möglichkeit zur schnellen Analyse neuer Datenquellen können Unternehmen unmittelbare und umsetzbare Erkenntnisse gewinnen, die für Entscheidungen in Echtzeit erforderlich sind.
- Neue Produkte und Dienstleistungen. Mithilfe von Tools für Big Data Analytics können Unternehmen die Bedürfnisse ihrer Kunden genauer analysieren und ihnen so leichter genau die Produkte und Dienstleistungen bieten, die sie sich wünschen.
- Betrugserkennung. Big-Data-Analysen werden auch zur Betrugsprävention herangezogen. Das gilt zwar noch vor allem für die Finanzdienstleistungsbranche, aber auch in anderen Bereichen gewinnen sie zunehmend an Bedeutung und werden immer häufiger eingesetzt.
Weitere Ressourcen
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.