Was ist Datenfluss?
Bewegung und Transformation von Daten von der Quelle zum Ziel mittels Streaming-Pipelines, Batch-Workflows, Echtzeit-Ereignisverarbeitung und orchestriertem ETL
- Zu den Mustern gehören ETL (Extract-Transform-Load) für die Stapelverarbeitung, ELT (Extract-Load-Transform) unter Nutzung der Rechenleistung des Zielsystems, Streaming-Architekturen für die kontinuierliche Verarbeitung und Lambda-Architekturen, die Stapel- und Echtzeitverarbeitung kombinieren.
- Die Orchestrierung verwaltet Aufgabenabhängigkeiten, plant die Ausführung, behandelt Fehler, ermöglicht Parallelverarbeitung, stellt Überwachungs-Dashboards bereit und verwaltet den Zustand verteilter Systeme zur Koordination komplexer, mehrstufiger Workflows.
- Optimierungstechniken umfassen inkrementelle Verarbeitung zur Vermeidung vollständiger Neuberechnungen, Partitionierung für Parallelität, Zwischenspeicherung von Ergebnissen, Prädikat-Pushdown zur Minimierung von Datenbewegungen und adaptive Ressourcenzuweisung basierend auf den Workload-Charakteristika.
Was ist Datenfluss?
Der Begriff „Datenfluss“ beschreibt den Weg, den Daten innerhalb der Architektur eines Systems von einem Prozess oder einer Komponente zur nächsten zurücklegen. Er skizziert, wie Daten in einem Computersystem, einer Anwendung oder einem Netzwerk eingegeben, verarbeitet, gespeichert und ausgegeben werden. Der Datenfluss hat direkte Auswirkungen auf Effizienz, Zuverlässigkeit und Sicherheit jedes IT-Systems. Daher ist es ausschlaggebend, ein System richtig zu konfigurieren, um optimale Ergebnisse zu erzielen.
Es gibt mehrere wesentliche Komponenten, die beeinflussen, wie Daten innerhalb eines Datenflusssystems übertragen und verarbeitet werden:
- Datenquelle. Der Datenfluss beginnt mit der Erfassung von Daten aus einer gegebenen Quelle. Das können strukturierte oder unstrukturierte Daten, aber auch Quellen mit Skripts oder Kundeneingaben sein. Diese Quellen stoßen den Datenfluss an und setzen das Datenflusssystem in Gang.
- Datentransformation. Nach der Aufnahme der Daten in das System können sie eine Transformation in eine Struktur oder ein Format durchlaufen, das für Analysen oder Data Science nutzbar ist. Die Datentransformation erfolgt gemäß den Transformationsregeln, die vorgeben, wie Daten in einem System verarbeitet oder geändert werden sollen. Dadurch wird sichergestellt, dass die Daten im korrekten Format für Ihre Geschäftsprozesse und -ziele vorliegen.
- Datensenke. Nach der Erfassung und Transformation werden die Daten im letzten Schritt an die Datensenke übergeben. Sie bildet den Endpunkt des Datensystems, an dem Daten genutzt werden, ohne im Datenfluss weiter übertragen zu werden. Dabei kann es sich um eine Datenbank, ein Lakehouse, Berichte oder Protokolldateien handeln, in denen Daten für Audits oder Analysen aufgezeichnet werden.
- Datenflusspfade. Datenflussdiagramme definieren die Wege oder Kanäle, über die Daten zwischen Quellen, Prozessen und Zielen übertragen werden. Zu diesen Pfaden können physische Netzwerkverbindungen genauso gehören wie logische Pfade wie API-Aufrufe. Auch Protokolle und Kanäle für eine sichere und effiziente Datenübertragung gehören dazu.
Beispiele für den Datenfluss
Je nach Organisation Ihrer Datenpipeline gibt es verschiedene bewährte Methoden zur Handhabung des Datenflusses. Beim ETL-Prozess (Extract, Transform, Load) werden Daten aus verschiedenen Quellen organisiert, aufbereitet und zentralisiert, um sie zugänglich und anschließend für Analysen, Berichterstellung und operative Entscheidungsfindung nutzbar zu machen. Durch die Steuerung des Datenflusses von Quellsystemen zu einer Zieldatenbank oder einem Data Warehouse ermöglicht der ETL-Prozess Datenintegration und -konsistenz – beides essenziell für verlässliche Erkenntnisse und die Umsetzung datengestützter Strategien.
- Echtzeitanalysen. Dieser Datenfluss kann eine unbegrenzte Anzahl von Datensätzen aus der Originalquelle verarbeiten und einen kontinuierlichen Datenstrom erfassen. Anwender erhalten so unmittelbare Analysen und Erkenntnisse, die für Anwendungen mit hohen Anforderungen an schnelle Reaktionen nützlich sind, etwa bei Überwachung, Nachverfolgung, Empfehlungssystemen oder automatisierten Aktionen.
- Operative Datenpipelines. Operative Datenpipelines sind für die Verarbeitung von Transaktions- und Betriebsdaten ausgelegt, die für die täglichen Routinefunktionen in einem Unternehmen von wesentlicher Bedeutung sind. Solche Pipelines erfassen Daten aus verschiedenen Quellen, darunter Kundeninteraktionen, Finanztransaktionen, Lagerbewegungen und Sensormesswerte. Sie sorgen dafür, dass diese Daten verarbeitet und auf dem neuesten Stand gehalten werden und systemübergreifend nahezu in Echtzeit oder mit geringer Latenz verfügbar sind. Operative Datenpipelines dienen dazu, Anwendungen und Datenbanken synchron zu halten. So gewährleisten sie reibungslose Betriebsabläufe und stellen sicher, dass alle Systeme stets den aktuellen Datenstand abbilden.
- Batch-Verarbeitung. Als Batch-Verarbeitung (oder auch „Stapelverarbeitung“) im Datenfluss bezeichnet man die Verarbeitung großer Datenmengen in festgelegten Intervallen oder nach dem Erfassen einer ausreichend großen Datenmenge, die auf einmal verarbeitet werden kann. Anders als bei der Echtzeitverarbeitung sind bei der Batch-Verarbeitung keine sofortigen Ergebnisse gefragt. Stattdessen liegt der Fokus auf Effizienz, Skalierbarkeit und einer fehlerfreien Verarbeitung. Zu diesem Zweck werden die Daten vor der Verarbeitung aggregiert. Die Batch-Verarbeitung wird häufig für Aufgaben wie Berichterstellung, Verlaufsanalysen und umfangreiche Datentransformationen eingesetzt, bei denen unmittelbare Erkenntnisse nicht zwingend erforderlich sind.
Tools und Technologien für den Datenfluss
Ein ETL-Workflow ist ein typisches Beispiel für einen Datenfluss. Bei der ETL-Verarbeitung werden Daten aus Quellsystemen erfasst und in einen Staging-Bereich geschrieben, gemäß den Anforderungen transformiert (z. B. durch Sicherstellung der Datenqualität, Deduplizierung oder Kennzeichnung fehlender Daten) und anschließend in ein Zielsystem wie ein Data Warehouse oder einen Data Lake überführt.
Robuste ETL-Systeme können Ihre Datenarchitektur deutlich verbessern, indem sie Durchsatz, Latenz, Kosten und betriebliche Effizienz optimieren. Damit erhalten Sie Zugang zu hochwertigen, aktuellen Daten, die Ihnen eine präzise Entscheidungsfindung ermöglichen.
Angesichts der schieren Menge und Vielfalt der erzeugten geschäftskritischen Daten ist es für ein angemessenes Data Engineering essenziell, den Datenfluss zu verstehen. Während sich viele Unternehmen bei der Verarbeitung ihrer Daten zwischen Batch- und Echtzeit-Streaming entscheiden müssen, stellt Databricks eine einzige API für Batch- und Streaming-Daten zur Verfügung. Tools wie Delta Live Tables helfen Anwendern, durch einfaches Wechseln der Verarbeitungsmodi einerseits die Kosten und andererseits Latenz oder Durchsatz zu optimieren. Auf diese Weise können Anwender ihre Lösungen zukunftssicher gestalten, indem sie sie einfach auf die Umstellung auf Streaming vorbereiten, wenn sich ihre geschäftlichen Anforderungen ändern.
Das Playbook für agentenbasierte KI für Unternehmen

Erstellen von Datenflussdiagrammen
Organisationen können den Datenfluss in ihrem System veranschaulichen, indem sie ein Datenflussdiagramm (DFD) erstellen. Ein DFD ist eine grafische Darstellung, die zeigt, wie Informationen erfasst, verarbeitet, gespeichert und genutzt werden. Dabei wird der Datenfluss zwischen den verschiedenen Systemkomponenten in der Ablaufrichtung dargestellt. Was für ein DFD Sie erstellen müssen, hängt von der Komplexität Ihrer Datenarchitektur ab. Es kann sich um eine einfache Übersicht über den Datenfluss handeln, aber auch um ein detailliertes DFD mit mehreren Ebenen, das die Verarbeitung der Daten in den verschiedenen Phasen ihres Lebenszyklus darstellt.
DFDs haben sich im Laufe der Zeit weiterentwickelt. Heute verwendet Delta Live Tables DAGs (Directed Acyclical Graphs) zur Darstellung der Abfolge von Datentransformationen und Abhängigkeiten zwischen Tabellen oder Ansichten innerhalb einer Pipeline. Jede Transformation oder Tabelle ist ein Knoten, und die Ränder zwischen den Knoten definieren den Datenfluss und die Abhängigkeiten. Dadurch wird sichergestellt, dass die Operationen in der vorgesehenen Reihenfolge innerhalb eines geschlossenen Kreislaufs ausgeführt werden.
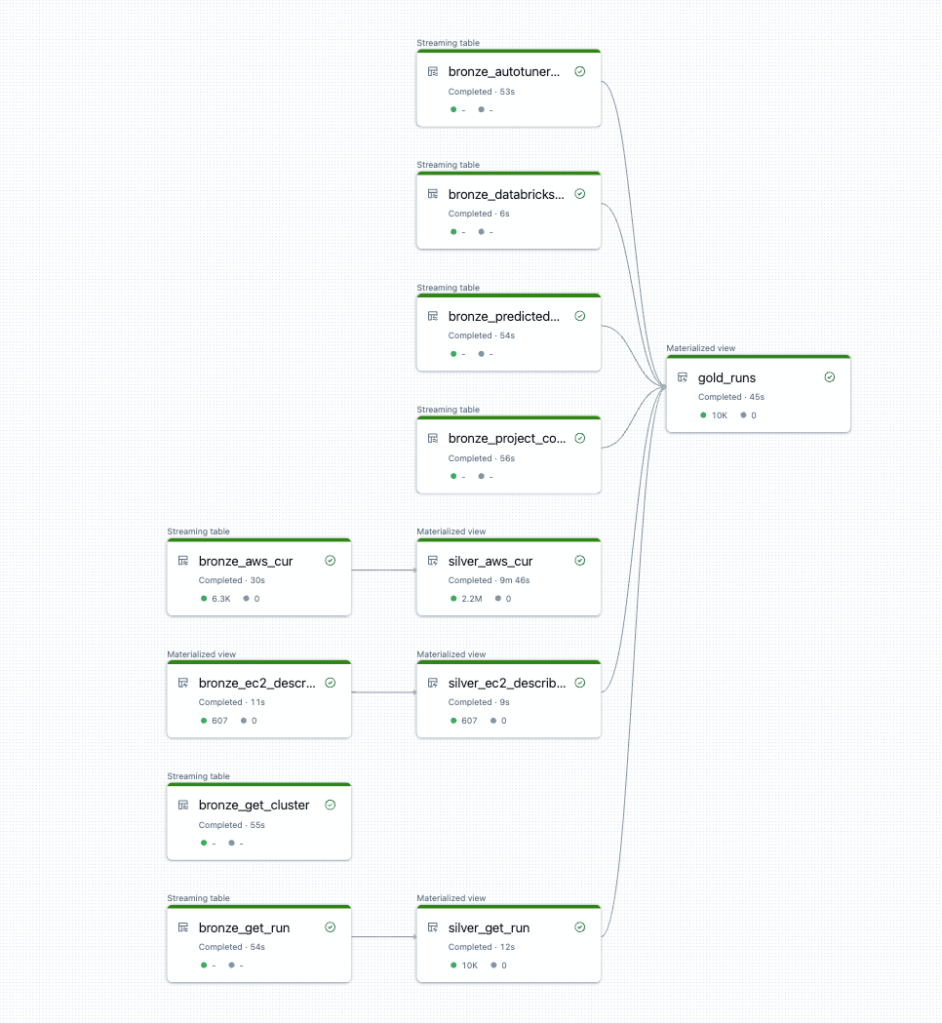
DAGs schaffen optische Klarheit, um die Beziehungen zwischen Aufgaben zu verstehen, und können auch dazu beitragen, Fehler oder Störungen im Datenflusssystem zu erkennen und zu beheben. Delta Live Tables sorgt dafür, dass der DAG effizient verwaltet wird. Zu diesem Zweck werden Vorgänge wie das Laden von Daten, Transformationen und Aktualisierungen geplant und optimiert, um Konsistenz und Leistung zu gewährleisten.
Best Practices für das Datenflussmanagement
Bestimmte Best Practices sollten eingehalten werden, um einen optimalen, effizienten und sicheren Datenfluss zu gewährleisten:
- Optimieren Sie den Datenprozess. Hierzu gehört das Rationalisieren des Datenflusses, um Engpässe zu beseitigen, Redundanzen zu verringern und eine Echtzeitverarbeitung zu ermöglichen. Regelmäßige Bewertung und Optimierung von Workflows stellt sicher, dass Daten das System ohne unnötige Komplexität durchlaufen, wodurch der Ressourcenverbrauch sinkt und die Skalierbarkeit steigt.
- Sorgen Sie für einen nahtlosen Informationsfluss. Zur Gewährleistung eines nahtlosen Informationsflusses ist es wichtig, Datensilos auf ein Minimum zu reduzieren und der Interoperabilität zwischen den Systemen Vorrang einzuräumen. Organisationen können durch die Implementierung stringenter ETL-Pipelines von konsistenten Daten profitieren – anwendungs-, abteilungs- und nutzungsübergreifend. Das erfordert auch die Einrichtung zuverlässiger Sicherungs- und Wiederherstellungsprozesse, um gegen Systemausfälle oder -unterbrechungen gewappnet zu sein.
- Sicherheitsüberlegungen. Natürlich ist es äußerst wichtig, Ihre Daten im Datenfluss zu schützen. Alle Daten, insbesondere aber sensible oder personenbezogene, sollten während der Übertragung oder Speicherung verschlüsselt werden. Die Beschränkung des Datenzugriffs kann dazu beitragen, das Risiko einer unbefugten Offenlegung zu verringern. Regelmäßige Sicherheitsprüfungen und Schwachstellenanalysen helfen, potenzielle Lücken zu identifizieren und proaktive Maßnahmen zum Schutz eines stabilen Datenflusses zu ergreifen.
- Performance-Überwachung. Durch den Einsatz von Analysetools zur Erfassung von Kennzahlen wie Latenz, Datenübertragungsraten und Fehlerquoten können Bereiche ermittelt werden, in denen der Datenfluss möglicherweise verzögert ist oder Probleme auftreten. Durch Einrichtung von automatischen Alerts und Dashboards wird sichergestellt, dass Teams über Probleme umgehend informiert werden, was schnelle Lösungen ermöglicht und Unterbrechungen minimiert. Regelmäßige Performance-Reviews können zudem aufschlussreiche Erkenntnisse liefern und unterstützen einen robusten, sicheren und effizienten Verwaltungsprozess.
Vorteile eines effizienten Datenflusses
Ein effizienter Datenfluss kann Ihre Unternehmensbilanz entscheidend verbessern. Durch die Einrichtung eines nahtlosen und schnellen Datenflusses durch Systeme und Abteilungen können Sie Workflows optimieren, die Produktivität verbessern und die Informationsverarbeitung beschleunigen.
Weitere Informationen darüber, wie Sie mit Databricks einen optimalen Datenfluss in Ihrer Organisation umsetzen, entnehmen Sie unserer Lakehouse-Referenzarchitektur. Auch möchten wir Ihnen Informationen zu unserer Medaillon-Architektur ans Herz legen. Dabei handelt es sich um ein Datendesignmuster, das zur logischen Datenorganisation in einem Lakehouse verwendet wird.
Wenn Sie mehr darüber wissen möchten, wie Delta Live Tables die Verarbeitung von Batch- und Streaming-Daten in Ihrer Organisation unterstützen kann, sprechen Sie mit einem unserer Databricks-Mitarbeiter.
Vor allem kann ein effizienter Datenfluss Ihrer Organisation dabei helfen, fundierte Entscheidungen zu treffen und so angemessener auf betriebliche oder kundenseitige Herausforderungen zu reagieren. Wenn Sie unmittelbaren Zugriff auf Ihre Daten haben, können Sie Ihre Entscheidungen in Echtzeit auf Basis aktuellster Informationen treffen. Und mit effizienten Datenflüssen können Sie sich darauf verlassen, dass die Informationen stimmig und stringent sind.
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.