Was ist ein Hadoop Distributed File System (HDFS)?
Verteilte Speicherung, die Dateien in replizierte Blöcke über Clusterknoten aufteilt und Fehlertoleranz, skalierbare Kapazität und Hochdurchsatzzugriff bietet
- Das Hadoop Distributed File System (HDFS) ist ein Speichersystem, das Dateien in Blöcke aufteilt und sie zur Skalierbarkeit und Fehlertoleranz auf viele Maschinen verteilt.
- HDFS wurde entwickelt, um sehr große Datensätze auf Clustern von Standardhardware zu speichern und die Daten auch dann verfügbar zu halten, wenn einzelne Knoten ausfallen.
- Obwohl viele Organisationen heute Cloud-Objektspeicher mit Lakehouse-Architekturen verwenden, hilft das Verständnis von HDFS, die Grundlage früher Big-Data-Systeme zu erklären.
HDFS
HDFS (Hadoop Distributed File System) ist das primäre Speichersystem, das von Hadoop-Anwendungen verwendet wird. Dieses Open-Source-Framework überträgt Daten schnell zwischen Knoten. Es wird häufig von Unternehmen verwendet, die Big Data verarbeiten und speichern müssen. HDFS ist eine Schlüsselkomponente vieler Hadoop-Systeme, da es eine Möglichkeit zur Verwaltung von Big Data bietet und Big-Data-Analysen unterstützt.
Es gibt viele Unternehmen auf der ganzen Welt, die HDFS nutzen. Was genau ist es und warum wird es benötigt? Tauchen wir tief in das ein, was HDFS ist und warum es für Unternehmen nützlich sein kann.
Was ist HDFS?
HDFS steht für Hadoop Distributed File System. HDFS fungiert als verteiltes Dateisystem, das auf handelsüblicher Hardware läuft.
HDFS ist fehlertolerant und für den Einsatz auf kostengünstiger, handelsüblicher Hardware konzipiert. HDFS bietet einen hohen Datendurchsatz für Anwendungsdaten und eignet sich für Anwendungen mit großen Datensätzen. Es ermöglicht den Streaming-Zugriff auf Dateisystemdaten in Apache Hadoop.
Also, was ist Hadoop? Und wie unterscheidet es sich von HDFS? Ein Kernunterschied zwischen Hadoop und HDFS besteht darin, dass Hadoop das Open-Source-Framework ist, das Daten speichern, verarbeiten und analysieren kann, während HDFS das Dateisystem von Hadoop ist, das den Datenzugriff ermöglicht. Das bedeutet im Wesentlichen, dass HDFS ein Modul von Hadoop ist.
Werfen wir einen Blick auf die HDFS-Architektur:
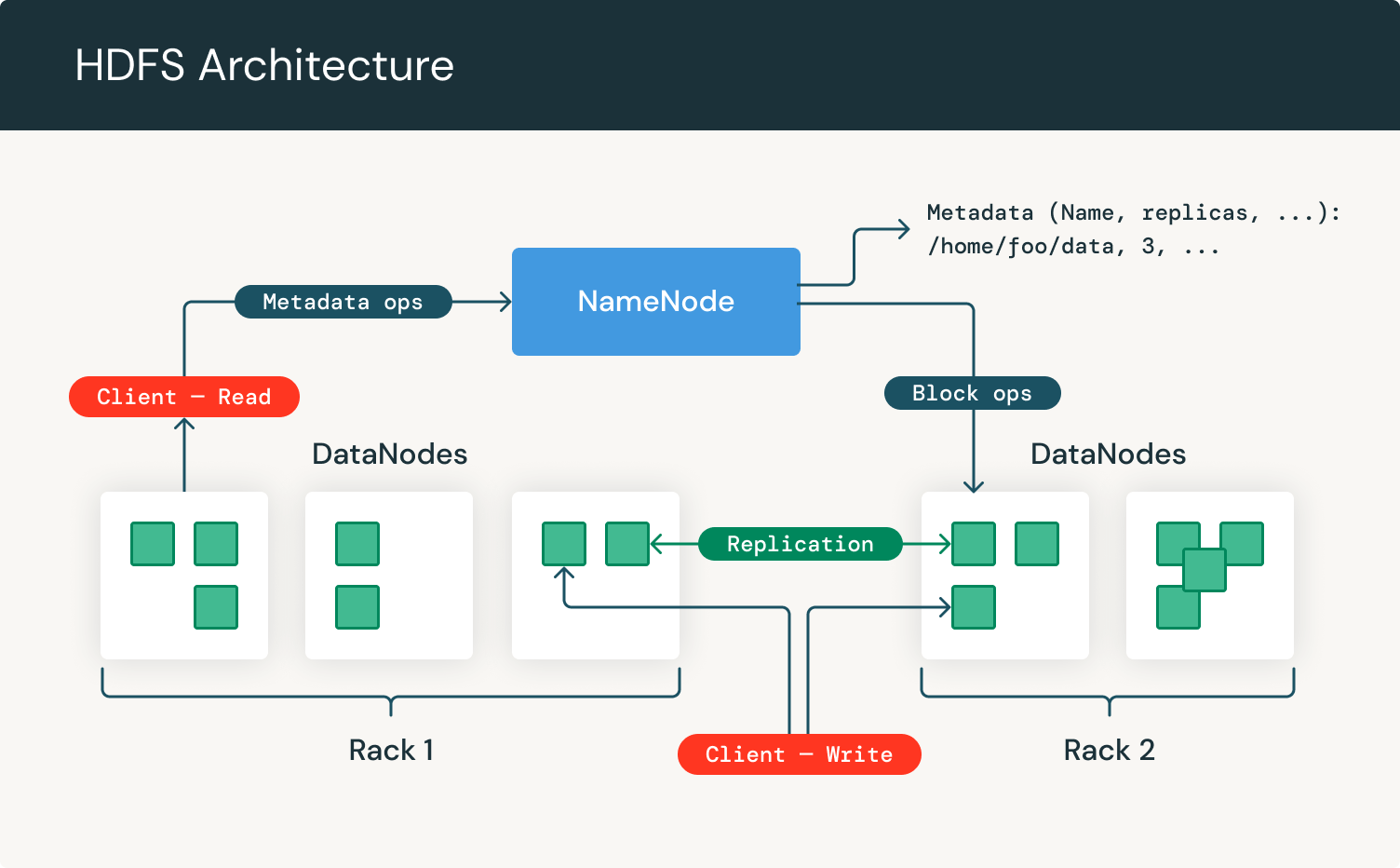
Wie wir sehen, konzentriert es sich auf NameNodes und DataNodes. Der NameNode ist die Hardware, die das GNU/Linux-Betriebssystem und die Software enthält. Das verteilte Dateisystem von Hadoop fungiert als Master-Server und kann die Dateien verwalten, den Zugriff eines Clients auf Dateien steuern und Dateibetriebsprozesse wie Umbenennen, Öffnen und Schließen von Dateien überwachen.
Ein DataNode ist eine Hardware mit dem GNU/Linux-Betriebssystem und der DataNode-Software. Für jeden Knoten in einem HDFS-Cluster finden Sie einen DataNode. Diese Knoten helfen bei der Steuerung der Datenspeicherung ihres Systems, da sie Operationen auf den Dateisystemen durchführen können, wenn der Client dies anfordert, und auch Dateien erstellen, replizieren und blockieren, wenn der NameNode dies anweist.
Die Bedeutung und der Zweck von HDFS sind die Erreichung der folgenden Ziele:
- Verwaltung großer Datensätze - Das Organisieren und Speichern von Datensätzen kann eine schwierige Aufgabe sein. HDFS wird verwendet, um Anwendungen zu verwalten, die mit riesigen Datensätzen umgehen müssen. Dazu sollte HDFS Hunderte von Knoten pro Cluster haben.
- Fehlererkennung - HDFS sollte über Technologie verfügen, um Fehler schnell und effektiv zu scannen und zu erkennen, da es eine große Anzahl von handelsüblicher Hardware umfasst. Der Ausfall von Komponenten ist ein häufiges Problem.
- Hardwareeffizienz - Wenn große Datensätze beteiligt sind, kann dies den Netzwerkverkehr reduzieren und die Verarbeitungsgeschwindigkeit erhöhen.
Die Geschichte von HDFS
Was sind die Ursprünge von Hadoop? Das Design von HDFS basierte auf dem Google File System. Es wurde ursprünglich als Infrastruktur für das Apache Nutch Web-Suchmaschinenprojekt entwickelt, ist aber seitdem ein Mitglied des Hadoop-Ökosystems geworden.
In den früheren Jahren des Internets tauchten Web-Crawler als Mittel für Menschen auf, um Informationen auf Webseiten zu suchen. Dies führte zur Entstehung verschiedener Suchmaschinen wie Yahoo und Google.
Es entstand auch eine weitere Suchmaschine namens Nutch, die Daten und Berechnungen gleichzeitig auf mehreren Computern verteilen wollte. Nutch wechselte dann zu Yahoo und wurde in zwei Teile geteilt. Apache Spark und Hadoop sind nun eigenständige Einheiten. Während Hadoop für die Stapelverarbeitung konzipiert ist, ist Spark für die effiziente Verarbeitung von Echtzeitdaten ausgelegt.
Heutzutage werden die Struktur und das Framework von Hadoop von der Apache Software Foundation verwaltet, einer globalen Gemeinschaft von Softwareentwicklern und Mitwirkenden.
HDFS entstand daraus und wurde entwickelt, um Hardware-Speicherlösungen durch eine bessere, effizientere Methode zu ersetzen – ein virtuelles Dateisystem. Als es auf den Markt kam, war MapReduce die einzige verteilte Verarbeitungs-Engine, die HDFS nutzen konnte. In jüngerer Zeit nutzen alternative Hadoop-Datenservicekomponenten wie HBase und Solr ebenfalls HDFS zum Speichern von Daten.
Was ist HDFS in der Welt von Big Data?
Was ist also Big Data und wie passt HDFS dazu? Der Begriff „Big Data“ bezieht sich auf alle Daten, die schwer zu speichern, zu verarbeiten und zu analysieren sind. HDFS Big Data sind Daten, die im HDFS-Dateisystem organisiert sind.
Wie wir jetzt wissen, ist Hadoop ein Framework, das durch parallele Verarbeitung und verteilte Speicherung arbeitet. Dies kann zum Sortieren und Speichern von Big Data verwendet werden, da es nicht auf herkömmliche Weise gespeichert werden kann.
Tatsächlich ist es die am häufigsten verwendete Software zur Verarbeitung von Big Data und wird von Unternehmen wie Netflix, Expedia und British Airways verwendet, die eine positive Beziehung zu Hadoop für die Datenspeicherung pflegen. HDFS ist im Bereich Big Data von entscheidender Bedeutung, da viele Unternehmen heute ihre Daten darauf speichern.
Es gibt fünf Kernelemente von Big Data, die von HDFS-Diensten organisiert werden:
- Geschwindigkeit (Velocity) - Wie schnell Daten generiert, gesammelt und analysiert werden.
- Datenmenge (Volume) - Die Menge der generierten Daten.
- Vielfalt (Variety) - Die Art der Daten, dies können strukturierte, unstrukturierte usw. Daten sein.
- Wahrhaftigkeit (Veracity) - Die Qualität und Genauigkeit der Daten.
- Wert (Value) - Wie Sie diese Daten nutzen können, um Einblicke in Ihre Geschäftsprozesse zu gewinnen.
Vorteile des Hadoop Distributed File System
Als Open-Source-Subprojekt innerhalb von Hadoop bietet HDFS fünf Kernvorteile bei der Arbeit mit Big Data:
- Fehlertoleranz. HDFS wurde entwickelt, um Fehler zu erkennen und automatisch schnell wiederherzustellen, um Kontinuität und Zuverlässigkeit zu gewährleisten.
- Geschwindigkeit, aufgrund seiner Cluster-Architektur kann es 2 GB Daten pro Sekunde verarbeiten.
- Zugriff auf mehr Datentypen, insbesondere Streaming-Daten. Aufgrund seines Designs zur Verarbeitung großer Datenmengen für die Stapelverarbeitung ermöglicht es hohe Datendurchsatzraten, was es ideal für die Unterstützung von Streaming-Daten macht.
Kompatibilität und Portabilität. HDFS ist so konzipiert, dass es über eine Vielzahl von Hardware-Konfigurationen portierbar und mit mehreren zugrunde liegenden Betriebssystemen kompatibel ist, was den Benutzern letztendlich die Möglichkeit gibt, HDFS mit ihrer eigenen maßgeschneiderten Einrichtung zu verwenden. Diese Vorteile sind besonders wichtig bei der Arbeit mit Big Data und wurden durch die spezielle Art und Weise, wie HDFS Daten verarbeitet, ermöglicht.
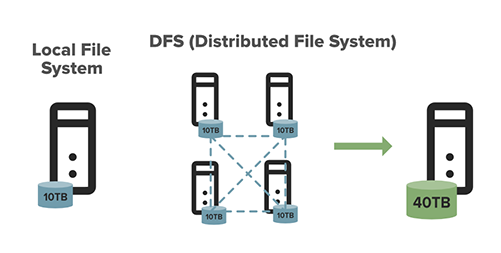
Diese Grafik zeigt den Unterschied zwischen einem lokalen Dateisystem und HDFS.
- Skalierbar. Sie können Ressourcen entsprechend der Größe Ihres Dateisystems skalieren. HDFS umfasst Mechanismen für vertikale und horizontale Skalierbarkeit.
- Datenlokalität. Beim Hadoop-Dateisystem befinden sich die Daten in den Datenknoten, anstatt dass die Daten dorthin bewegt werden, wo sich die Recheneinheit befindet. Durch die Verkürzung der Distanz zwischen Daten und Rechenprozess wird die Netzwerkauslastung reduziert und das System effektiver und effizienter gemacht.
- Kostengünstig. Anfangs denken wir bei Daten vielleicht an teure Hardware und hohen Bandbreitenverbrauch. Wenn ein Hardwarefehler auftritt, kann die Behebung sehr kostspielig sein. Bei HDFS werden die Daten kostengünstig gespeichert, da sie virtuell sind, was die Speicherkosten für Metadaten und den Namespace des Dateisystems drastisch reduzieren kann. Darüber hinaus müssen Unternehmen, da HDFS Open Source ist, keine Lizenzgebühren zahlen.
- Speichert große Datenmengen. Datenspeicherung ist das, worum es bei HDFS geht – das bedeutet Daten aller Arten und Größen – aber insbesondere große Datenmengen von Unternehmen, die Schwierigkeiten haben, sie zu speichern. Dies umfasst sowohl strukturierte als auch unstrukturierte Daten.
- Flexibel. Im Gegensatz zu einigen anderen traditionelleren Speicherdatenbanken müssen die gesammelten Daten nicht vor dem Speichern verarbeitet werden. Sie können so viele Daten speichern, wie Sie möchten, und haben die Möglichkeit zu entscheiden, was Sie damit tun und wie Sie sie später verwenden möchten. Dies schließt auch unstrukturierte Daten wie Text, Videos und Bilder ein.
Wie man HDFS benutzt
Wie benutzt man also HDFS? Nun, HDFS arbeitet mit einem Haupt-NameNode und mehreren anderen DataNodes, alle in einem Cluster handelsüblicher Hardware. Diese Knoten sind am selben Ort im Rechenzentrum organisiert. Als Nächstes wird es in Blöcke unterteilt, die zur Speicherung auf die mehreren DataNodes verteilt werden. Um die Wahrscheinlichkeit von Datenverlust zu verringern, werden Blöcke oft über Knoten hinweg repliziert. Es ist ein Backup-System für den Fall, dass Daten verloren gehen.
Lassen Sie uns die NameNodes betrachten. Der NameNode ist der Knoten im Cluster, der weiß, welche Daten er enthält, zu welchem Block er gehört, welche Blockgröße er hat und wohin er gehen soll. NameNodes werden auch zur Steuerung des Zugriffs auf Dateien verwendet, einschließlich der Frage, wann jemand Daten schreiben, lesen, erstellen, entfernen und replizieren kann, und zwar über die verschiedenen Datenknoten.
Der Cluster kann bei Bedarf auch in Echtzeit angepasst werden, abhängig von der Serverkapazität – was nützlich sein kann, wenn ein Datenanstieg auftritt. Knoten können bei Bedarf hinzugefügt oder entfernt werden.
Nun zu den DataNodes. DataNodes stehen in ständiger Kommunikation mit den NameNodes, um festzustellen, ob sie eine Aufgabe beginnen und abschließen müssen. Dieser ständige Austausch bedeutet, dass der NameNode über den Status jedes DataNodes genau informiert ist.
Wenn ein DataNode als nicht ordnungsgemäß funktionierend eingestuft wird, kann der NameNode diese Aufgabe automatisch einem anderen funktionierenden Knoten im selben Datenblock neu zuweisen. Ebenso können DataNodes auch miteinander kommunizieren, was bedeutet, dass sie bei Standard-Dateivorgängen zusammenarbeiten können. Da der NameNode über die DataNodes und ihre Leistung informiert ist, sind sie entscheidend für die Aufrechterhaltung des Systems.
Datenblöcke werden über mehrere Datenknoten repliziert und vom NameNode abgerufen.
Um HDFS zu verwenden, müssen Sie einen Hadoop-Cluster installieren und einrichten. Dies kann eine Einzelknoten-Einrichtung sein, die für Erstbenutzer besser geeignet ist, oder eine Cluster-Einrichtung für große, verteilte Cluster. Sie müssen sich dann mit den HDFS-Befehlen vertraut machen, wie den unten aufgeführten, um Ihr System zu bedienen und zu verwalten.
| Befehl | Beschreibung |
| -rm | Löscht Datei oder Verzeichnis |
| -ls | Listet Dateien mit Berechtigungen und anderen Details auf |
| -mkdir | Erstellt ein Verzeichnis mit dem Namen Pfad in HDFS |
| -cat | Zeigt den Inhalt der Datei an |
| -rmdir | Löscht ein Verzeichnis |
| -put | Lädt eine Datei oder einen Ordner von einer lokalen Festplatte nach HDFS hoch |
| -rmr | Löscht die durch Pfad identifizierte Datei oder den Ordner und Unterordner |
| -get | Verschiebt Datei oder Ordner von HDFS in eine lokale Datei |
| -count | Zählt die Anzahl der Dateien, die Anzahl der Verzeichnisse und die Dateigröße |
| -df | Zeigt freien Speicherplatz an |
| -getmerge | Führt mehrere Dateien in HDFS zusammen |
| -chmod | Ändert Dateiberechtigungen |
| -copyToLocal | Kopiert Dateien in das lokale System |
| -Stat | Gibt Statistiken über die Datei oder das Verzeichnis aus |
| -head | Zeigt das erste Kilobyte einer Datei an |
| -usage | Gibt die Hilfe für einen einzelnen Befehl zurück |
| -chown | Weist einer Datei einen neuen Besitzer und eine neue Gruppe zu |
Wie funktioniert HDFS?
Wie bereits erwähnt, verwendet HDFS NameNodes und DataNodes. HDFS ermöglicht die schnelle Übertragung von Daten zwischen Compute-Knoten. Wenn HDFS Daten aufnimmt, kann es die Informationen in Blöcke aufteilen und sie an verschiedene Knoten in einem Cluster verteilen.
Daten werden in Blöcke aufgeteilt und zur Speicherung an die DataNodes verteilt. Diese Blöcke können auch über Knoten hinweg repliziert werden, was eine effiziente parallele Verarbeitung ermöglicht. Sie können über verschiedene Befehle auf Daten zugreifen, sich darin bewegen und sie anzeigen. HDFS DFS-Optionen wie "-get" und "-put" ermöglichen es Ihnen, Daten nach Bedarf abzurufen und zu verschieben.
Darüber hinaus ist HDFS darauf ausgelegt, sehr aufmerksam zu sein und Fehler schnell zu erkennen. Das Dateisystem verwendet Datenreplikation, um sicherzustellen, dass jedes Datenelement mehrmals gespeichert wird, und weist es dann einzelnen Knoten zu, um sicherzustellen, dass mindestens eine Kopie auf einem anderen Rack liegt als die anderen Kopien.
Das bedeutet, wenn ein DataNode keine Signale mehr an den NameNode sendet, entfernt er den DataNode aus dem Cluster und arbeitet ohne ihn. Wenn dieser Datenknoten dann zurückkehrt, kann er einem neuen Cluster zugewiesen werden. Da die Datenblöcke über mehrere DataNodes repliziert werden, führt die Entfernung eines einzelnen DataNodes nicht zu Dateibeschädigungen jeglicher Art.
HDFS-Komponenten
Es ist wichtig zu wissen, dass Hadoop drei Hauptkomponenten hat: Hadoop HDFS, Hadoop MapReduce und Hadoop YARN. Werfen wir einen Blick darauf, was diese Komponenten zu Hadoop beitragen:
- Hadoop HDFS – Hadoop Distributed File System (HDFS) ist die Speichereinheit von Hadoop.
- Hadoop MapReduce – Hadoop MapReduce ist die Verarbeitungseinheit von Hadoop. Dieses Software-Framework wird verwendet, um Anwendungen zum Verarbeiten riesiger Datenmengen zu schreiben.
- Hadoop YARN – Hadoop YARN ist eine Komponente zur Ressourcenverwaltung von Hadoop. Es verarbeitet und führt Daten für Batch-, Stream-, interaktive und Graph-Verarbeitung aus – die alle in HDFS gespeichert sind.
So erstellen Sie ein HDFS-Dateisystem
Möchten Sie wissen, wie Sie ein HDFS-Dateisystem erstellen? Befolgen Sie die unten stehenden Schritte, die Sie durch die Erstellung, Bearbeitung und gegebenenfalls Entfernung des Systems führen.
Auflistung Ihres HDFS
Ihre HDFS-Liste sollte /user/yourUserName lauten. Um den Inhalt Ihres HDFS-Home-Verzeichnisses anzuzeigen, geben Sie ein:
Da Sie gerade erst anfangen, werden Sie zu diesem Zeitpunkt noch nichts sehen können. Wenn Sie den Inhalt eines nicht leeren Verzeichnisses anzeigen möchten, geben Sie ein:
Sie können dann die Namen der Home-Verzeichnisse aller anderen Hadoop-Benutzer sehen.
Erstellen eines Verzeichnisses in HDFS
Sie können jetzt ein Testverzeichnis erstellen, nennen wir es testHDFS. Es wird innerhalb Ihres HDFS angezeigt. Geben Sie einfach Folgendes ein:
Nun müssen Sie überprüfen, ob das Verzeichnis existiert, indem Sie den Befehl verwenden, den Sie beim Auflisten Ihres HDFS eingegeben haben. Sie sollten das Verzeichnis testHDFS aufgelistet sehen.
Überprüfen Sie es erneut mit dem vollständigen HDFS-Pfad zu Ihrem HDFS. Geben Sie ein:
Überprüfen Sie doppelt, ob dies funktioniert, bevor Sie die nächsten Schritte unternehmen.
Kopieren einer Datei
Um eine Datei von Ihrem lokalen Dateisystem nach HDFS zu kopieren, erstellen Sie zunächst eine Datei, die Sie kopieren möchten. Geben Sie dazu Folgendes ein:
Dadurch wird eine neue Datei namens testFile erstellt, die die Zeichen HDFS test file enthält. Um dies zu überprüfen, geben Sie ein:
ls
Und dann, um zu überprüfen, ob die Datei erstellt wurde, geben Sie ein:
Anschließend müssen Sie die Datei nach HDFS kopieren. Um Dateien von Linux nach HDFS zu kopieren, müssen Sie Folgendes verwenden:
Beachten Sie, dass Sie den Befehl "-copyFromLocal" verwenden müssen, da der Befehl "-cp" zum Kopieren von Dateien innerhalb von HDFS verwendet wird.
Jetzt müssen Sie nur noch bestätigen, dass die Datei korrekt kopiert wurde. Tun Sie dies, indem Sie Folgendes eingeben:
Verschieben und Kopieren von Dateien
Beim Kopieren der testfile wurde sie in das Basis-Home-Verzeichnis gelegt. Jetzt können Sie sie in das bereits erstellte testHDFS-Verzeichnis verschieben. Verwenden Sie Folgendes:
Der erste Teil hat Ihre testFile aus dem HDFS-Home-Verzeichnis in das von Ihnen erstellte Testverzeichnis verschoben. Der zweite Teil dieses Befehls zeigt uns dann, dass sie nicht mehr im HDFS-Home-Verzeichnis vorhanden ist, und der dritte Teil bestätigt, dass sie jetzt in das Test-HDFS-Verzeichnis verschoben wurde.
Um eine Datei zu kopieren, geben Sie ein:
Überprüfung der Festplattennutzung
Die Überprüfung des Speicherplatzes ist bei der Verwendung von HDFS nützlich. Dazu können Sie den folgenden Befehl eingeben:
Dadurch können Sie sehen, wie viel Speicherplatz Sie in Ihrem HDFS verwenden. Sie können auch sehen, wie viel Speicherplatz im HDFS über den gesamten Cluster verfügbar ist, indem Sie Folgendes eingeben:
Löschen einer Datei/eines Verzeichnisses
Es kann vorkommen, dass Sie eine Datei oder ein Verzeichnis in HDFS löschen müssen. Dies kann mit dem Befehl erreicht werden:
Sie werden sehen, dass Sie immer noch das testHDFS-Verzeichnis und die testFile2 haben, die Sie erstellt haben. Entfernen Sie das Verzeichnis, indem Sie Folgendes eingeben:
Es wird dann eine Fehlermeldung angezeigt – aber keine Panik. Sie wird etwa so lauten: "rmdir: testhdfs: Verzeichnis ist nicht leer". Das Verzeichnis muss leer sein, bevor es gelöscht werden kann. Sie können den Befehl "rm" verwenden, um dies zu umgehen und ein Verzeichnis einschließlich aller darin enthaltenen Dateien zu löschen. Geben Sie ein:
Das Playbook für agentenbasierte KI für Unternehmen

Installation von HDFS
Um Hadoop zu installieren, müssen Sie bedenken, dass es einen Singlenode und einen Multinode gibt. Je nachdem, was Sie benötigen, können Sie entweder einen Singlenode- oder einen Multinode-Cluster verwenden.
Ein Einzelknoten-Cluster bedeutet, dass nur ein DataNode ausgeführt wird. Er umfasst den NameNode, DataNode, Ressourcenmanager und NodeManager auf einer einzigen Maschine.
Für manche Branchen ist das alles, was benötigt wird. Im medizinischen Bereich zum Beispiel, wenn Sie Studien durchführen und Daten sequenziell sammeln, sortieren und verarbeiten müssen, können Sie einen Single-Node-Cluster verwenden. Dieser kann die Daten leicht im kleineren Maßstab verarbeiten, verglichen mit Daten, die über Hunderte von Maschinen verteilt sind. Um einen Single-Node-Cluster zu installieren, befolgen Sie diese Schritte:
- Laden Sie das Java 8-Paket herunter. Speichern Sie diese Datei in Ihrem Home-Verzeichnis.
- Extrahieren Sie die Java Tar-Datei.
- Laden Sie das Hadoop 2.7.3-Paket herunter.
- Extrahieren Sie die Hadoop Tar-Datei.
- Fügen Sie die Hadoop- und Java-Pfade in die Bash-Datei (.bashrc) ein.
- Bearbeiten Sie die Hadoop-Konfigurationsdateien.
- Öffnen Sie core-site.xml und bearbeiten Sie die Eigenschaft.
- Bearbeiten Sie hdfs-site.xml und bearbeiten Sie die Eigenschaft.
- Bearbeiten Sie die Datei mapred-site.xml und bearbeiten Sie die Eigenschaft.
- Bearbeiten Sie yarn-site.xml und bearbeiten Sie die Eigenschaft.
- Bearbeiten Sie hadoop-env.sh und fügen Sie den Java-Pfad hinzu.
- Wechseln Sie in das Hadoop-Home-Verzeichnis und formatieren Sie den NameNode.
- Wechseln Sie in das Verzeichnis hadoop-2.7.3/sbin und starten Sie alle Daemons.
- Überprüfen Sie, ob alle Hadoop-Dienste laufen.
Und da haben Sie es, Sie sollten jetzt ein erfolgreich installiertes HDFS haben.
So greifen Sie auf HDFS-Dateien zu
Es wird Sie nicht überraschen, dass die Sicherheit bei HDFS streng ist, da wir es mit Daten zu tun haben. Da HDFS technisch gesehen ein virtueller Speicher ist, erstreckt er sich über den gesamten Cluster, sodass Sie nur die Metadaten in Ihrem Dateisystem sehen können, aber nicht die tatsächlichen spezifischen Daten anzeigen können.
Um auf HDFS-Dateien zuzugreifen, können Sie die "jar"-Datei von HDFS auf Ihr lokales Dateisystem herunterladen. Sie können auch über die Weboberfläche auf HDFS zugreifen. Öffnen Sie einfach Ihren Browser und geben Sie "localhost:50070" in die Adressleiste ein. Von dort aus können Sie die Weboberfläche von HDFS sehen und zum Tab "Utilities" auf der rechten Seite wechseln. Klicken Sie dann auf "browse file system", dies zeigt Ihnen eine vollständige Liste der Dateien, die sich auf Ihrem HDFS befinden.
HDFS DFS Beispiele
Hier sind einige der gängigsten Hadoop-Befehlsbeispiele.
Beispiel A
Um ein Verzeichnis zu löschen, müssen Sie Folgendes anwenden (Hinweis: Dies kann nur geschehen, wenn die Dateien leer sind):
Oder
Beispiel B
Wenn Sie mehrere Dateien in einem HDFS haben, können Sie einen "-getmerge"-Befehl verwenden. Dieser fasst mehrere Dateien zu einer einzigen Datei zusammen, die Sie dann auf Ihr lokales Dateisystem herunterladen können. Sie können dies mit Folgendem tun:
Oder
Beispiel C
Wenn Sie eine Datei von HDFS auf lokal hochladen möchten, können Sie den Befehl "-put" verwenden. Sie geben an, wohin Sie kopieren möchten, und welche Datei Sie auf HDFS kopieren möchten. Verwenden Sie Folgendes:
Oder
Beispiel D
Der Befehl "count" wird verwendet, um die Anzahl der Verzeichnisse, Dateien und die Dateigröße auf HDFS zu verfolgen. Sie können Folgendes verwenden:
Oder
Beispiel E
Der Befehl "chown" kann verwendet werden, um den Besitzer und die Gruppe einer Datei zu ändern. Um dies zu aktivieren, verwenden Sie Folgendes:
Oder
Was ist HDFS-Speicher?
Wie wir jetzt wissen, werden HDFS-Daten in sogenannten Blöcken gespeichert. Diese Blöcke sind die kleinste Dateneinheit, die das Dateisystem speichern kann. Dateien werden verarbeitet und in diese Blöcke zerlegt, die dann verteilt und zur Sicherheit repliziert werden. Typischerweise kann jeder Block dreimal repliziert werden. Dieses Diagramm zeigt Big Data und wie es mit HDFS gespeichert werden kann.
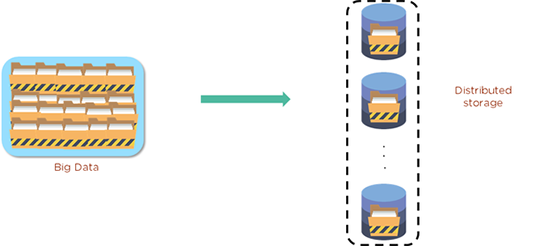
Die erste finden Sie auf dem DataNode, die zweite wird auf einem separaten DataNode innerhalb des Clusters gespeichert und die dritte wird auf einem DataNode in einem anderen Cluster gespeichert. Dies ist wie ein dreifacher Sicherheitsschritt. Wenn also das Schlimmste passiert und eine Replik ausfällt, sind die Daten nicht für immer verloren.
Der NameNode speichert wichtige Informationen, wie z. B. die Anzahl der Blöcke und wo die Replikate gespeichert sind. Im Vergleich dazu speichert ein DataNode die tatsächlichen Daten und kann Blöcke erstellen, Blöcke entfernen und Blöcke auf Befehl replizieren. Es sieht so aus:
Dies bestimmt, wo DataNodes seine Blöcke speichern sollen.
Wie speichert HDFS Daten?
Das HDFS-Dateisystem besteht aus einer Reihe von Master-Diensten (NameNode, Secondary NameNode und DataNodes). Der NameNode und der Secondary NameNode verwalten die HDFS-Metadaten. Die DataNodes hosten die zugrunde liegenden HDFS-Daten.
Der NameNode verfolgt, welche DataNodes die Inhalte einer bestimmten Datei in HDFS enthalten. HDFS teilt Dateien in Blöcke auf und speichert jeden Block auf einem DataNode. Mehrere DataNodes sind mit dem Cluster verbunden. Der NameNode verteilt dann Replikate dieser Datenblöcke über den Cluster. Er weist den Benutzer oder die Anwendung auch an, wo die gewünschten Informationen zu finden sind.
Wofür ist das Hadoop Distributed File System (HDFS) ausgelegt?
Einfach ausgedrückt, wenn Sie fragen: "Wofür ist das Hadoop Distributed File System ausgelegt?" Die Antwort ist in erster Linie - Big Data. Dies kann für große Unternehmen von unschätzbarem Wert sein, die andernfalls Schwierigkeiten hätten, Daten von ihrem Geschäft und ihren Kunden zu verwalten und zu speichern.
Mit Hadoop können Sie Daten speichern und vereinheitlichen, sei es transaktional, wissenschaftlich, Social Media, Werbung und maschinelles Lernen. Es bedeutet auch, dass Sie auf diese Daten zurückgreifen und wertvolle Einblicke in die Geschäftsleistung und Analysen gewinnen können.
Da es für die Datenspeicherung konzipiert wurde, kann HDFS auch Rohdaten verarbeiten, die häufig von Wissenschaftlern oder Personen im medizinischen Bereich verwendet werden, die solche Daten analysieren möchten. Dies werden Data Lakes genannt. Es ermöglicht ihnen, schwierigere Fragen ohne Einschränkungen zu beantworten.
Darüber hinaus kann Hadoop, da es in erster Linie für die Verarbeitung riesiger Datenmengen auf verschiedene Weise konzipiert wurde, auch zur Ausführung von Algorithmen für analytische Zwecke verwendet werden. Das bedeutet, es hilft Unternehmen, Daten effizienter zu verarbeiten und zu analysieren, sodass sie neue Trends und Anomalien entdecken können. Bestimmte Datensätze werden sogar aus Data Warehouses entfernt und nach Hadoop verschoben. Es macht es einfach, alles an einem leicht zugänglichen Ort zu speichern.
Wenn es um transaktionale Daten geht, ist Hadoop auch in der Lage, Millionen von Transaktionen zu verarbeiten. Dank seiner Speicher- und Verarbeitungsfähigkeiten kann es zur Speicherung und Analyse von Kundendaten verwendet werden. Sie können auch tief in die Daten eintauchen, um aufkommende Trends und Muster zu entdecken, die Ihnen bei Ihren Geschäftszielen helfen. Vergessen Sie nicht, Hadoop wird ständig mit neuen Daten aktualisiert, und Sie können neue und alte Daten vergleichen, um zu sehen, was sich geändert hat und warum.
Überlegungen zu HDFS
Standardmäßig ist HDFS mit 3-facher Replikation konfiguriert, was bedeutet, dass Datensätze zwei zusätzliche Kopien haben. Während dies die Wahrscheinlichkeit lokalisierter Daten während der Verarbeitung erhöht, führt es zu zusätzlichen Speicherkosten.
- HDFS funktioniert am besten, wenn es mit lokal angeschlossenem Speicher konfiguriert ist. Dies gewährleistet die beste Leistung für das Dateisystem.
- Die Erhöhung der Kapazität von HDFS erfordert die Hinzufügung neuer Server (Rechenleistung, Speicher, Festplatte), nicht nur von Speichermedien.
HDFS vs. Cloud-Objektspeicher
Wie oben erwähnt, ist die Kapazität von HDFS eng mit den Computerressourcen gekoppelt. Die Erhöhung der Speicherkapazität erfordert die Erhöhung der CPU-Ressourcen, auch wenn letztere nicht erforderlich ist. Beim Hinzufügen weiterer Datenknoten zu HDFS ist ein Rebalancierungsvorgang erforderlich, um vorhandene Daten auf die neu hinzugefügten Server zu verteilen.
Dieser Vorgang kann einige Zeit dauern. Das Skalieren eines Hadoop-Clusters in einer lokalen Umgebung kann auch aus Kosten- und Platzgründen schwierig sein. HDFS verwendet lokal angeschlossenen Speicher, der IO-Leistungsvorteile bieten kann, vorausgesetzt, YARN kann die Verarbeitung auf den Servern bereitstellen, die die zu verarbeitenden Daten speichern.
In stark ausgelasteten Umgebungen können die meisten Lese-/Schreibvorgänge über das Netzwerk und nicht lokal erfolgen. Cloud-Objektspeicher umfasst Technologien wie Azure Data Lake Storage, AWS S3 oder Google Cloud Storage. Er ist unabhängig von den Computerressourcen, die darauf zugreifen, und daher können Kunden in der Cloud weitaus größere Datenmengen speichern.
Kunden, die Petabytes an Daten speichern möchten, können dies problemlos im Cloud Object Storage tun. Alle Lese- und Schreibvorgänge gegen Cloud Storage erfolgen jedoch über das Netzwerk. Daher ist es wichtig, dass Anwendungen, die auf die Daten zugreifen, nach Möglichkeit Caching nutzen oder Logik zur Minimierung von IO-Vorgängen integrieren.
Zusätzliche Ressourcen
- Leitfaden zur Migration von Hadoop zu Lakehouse
- Migrations-Hub
- Ebook zur Cloud-Modernisierung: Ein Geschäftsleitfaden zum verborgenen Wert der Migration von Hadoop
- On-Demand-Kurzdemos der Databricks Lakehouse Platform
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.