Apache Spark und Hadoop: Zusammenarbeit
von Ion Stoica
Wir werden oft gefragt, wie Apache Spark in das Hadoop-Ökosystem passt und wie man Spark in einem bestehenden Hadoop-Cluster ausführen kann. Dieser Blog soll diese Fragen beantworten.
Zunächst einmal soll Spark den Hadoop-Stack ergänzen und nicht ersetzen. Von Anfang an wurde Spark so konzipiert, dass es Daten aus und in HDFS sowie in andere Speichersysteme wie HBase und Amazon S3 lesen und schreiben kann. Hadoop-Nutzer können ihre Verarbeitungsmöglichkeiten erweitern, indem sie Spark mit Hadoop- MapReduce, HBase und anderen Big Data Frameworks kombinieren.
Zweitens haben wir uns ständig darauf konzentriert, es jedem Hadoop-Nutzer so einfach wie möglich zu machen, die Funktionen von Spark zu nutzen. Egal, ob Sie Hadoop 1.x oder Hadoop 2.0 (YARN) ausführen und ob Sie über Administratorrechte zum Konfigurieren des Hadoop-Clusters verfügen oder nicht, es gibt eine Möglichkeit für Sie, Spark auszuführen! Insbesondere gibt es drei Möglichkeiten, Spark in einem Hadoop-Cluster bereitzustellen: Standalone, YARN und SIMR.
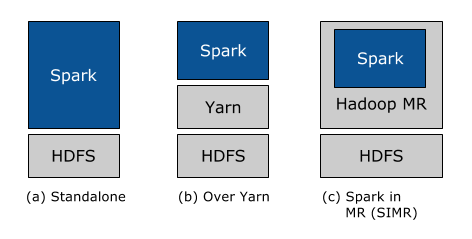
Eigenständige Bereitstellung: Bei der eigenständigen Bereitstellung kann man Ressourcen auf allen oder einem Teil der Maschinen in einem Hadoop-Cluster statisch zuweisen und Spark parallel zu Hadoop MR ausführen. Der Benutzer kann dann beliebige Spark-Jobs auf seinen HDFS-Daten ausführen. Seine Einfachheit macht dies zum Deployment der Wahl für viele Hadoop 1.x-Benutzer.
Hadoop Yarn -Bereitstellung: Hadoop-Nutzer, die Hadoop Yarn bereits bereitgestellt haben oder dies planen, können Spark einfach auf YARN ausführen, ohne dass eine Vorinstallation oder ein administrativer Zugriff erforderlich ist. Dies ermöglicht es Nutzern, Spark einfach in ihren Hadoop-Stack zu integrieren und die volle Leistung von Spark sowie anderer auf Spark laufender Komponenten zu nutzen.
Spark in MapReduce (SIMR): Für Hadoop-Benutzer, die YARN noch nicht verwenden, besteht neben der eigenständigen Bereitstellung eine weitere Option darin, SIMR zum Starten von Spark-Jobs in MapReduce zu verwenden. Mit SIMR können Nutzer schon wenige Minuten nach dem Herunterladen mit Spark experimentieren und dessen Shell nutzen! Dies senkt die Einstiegshürde enorm und ermöglicht es praktisch jedem, mit Spark zu experimentieren.
Interoperabilität mit anderen Systemen
Spark ist nicht nur mit Hadoop interoperabel, sondern auch mit anderen beliebten Big-Data-Technologien.
- Apache Hive: Durch Shark ermöglicht Spark den Benutzern von Apache Hive, ihre unveränderten Abfragen viel schneller auszuführen. Hive ist eine beliebte Data Warehouse -Lösung, die auf Hadoop ausgeführt wird, während Shark ein System ist, das es dem Hive-Framework ermöglicht, auf Spark anstelle von Hadoop ausgeführt zu werden. Daher kann Shark Hive-Abfragen um das bis zu 100-Fache beschleunigen, wenn die Eingabedaten in den Arbeitsspeicher passen, und um das bis zu 10-Fache, wenn die Eingabedaten auf der Festplatte gespeichert sind.
- AWS EC2: Benutzer können Spark (und Shark) ganz einfach auf Amazon EC2 ausführen, indem sie entweder die Skripte, die mit Spark mitgeliefert werden, oder die gehosteten Versionen von Spark und Shark auf Amazon Elastic MapReduce verwenden.
- Apache Mesos: Spark läuft auf Mesos, einem Cluster-Manager-System, das eine effiziente Ressourcenisolierung für verteilte Anwendungen, einschließlich MPI und Hadoop, bietet. Mesos ermöglicht ein feingranulares Das Teilen, wodurch ein Spark-Job die inaktiven Ressourcen im Cluster während seiner Ausführung dynamisch nutzen kann. Dies führt zu erheblichen Performance-Verbesserungen, insbesondere bei langlaufenden Spark-Jobs.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.