Was ist Datenherkunft?
Metadaten verfolgen die Ursprünge, Transformationen und Abhängigkeiten von Daten von der Quelle über Pipelines bis hin zur Nutzung und ermöglichen so Debugging und Compliance.
- Die technische Datenherkunft verfolgt Datenflüsse auf technischer Ebene und zeigt Quelltabellen, Transformationslogik, Zwischendatensätze und Zieltabelle mit Spaltenabhängigkeiten an. Dies ermöglicht eine Folgenabschätzung bei Schemaänderungen.
- Die Geschäftsdatenherkunft bietet eine semantische Sicht, die Daten mit Geschäftskonzepten, Metrikdefinitionen, Berichten und Dashboards verknüpft. So verstehen Anwender die Bedeutung der Daten und die Auswirkungen von Änderungen auf nachgelagerte Systeme.
- Zu den Vorteilen gehören die Ursachenanalyse bei Datenqualitätsproblemen, die Dokumentation der Einhaltung gesetzlicher Vorschriften für Audit-Trails, die Folgenabschätzung vor Systemänderungen und eine verbesserte Zusammenarbeit durch ein gemeinsames Verständnis der Datenflüsse.
Was ist Datenherkunft?
Datenherkunft ist der Prozess, bei dem Daten und AI über die Zeit erfasst, nachverfolgt und visualisiert werden – vom Ursprung bis zur Nutzung. Effektive Datenherkunft gibt Datenteams einen durchgängigen Überblick darüber, wie Daten transformiert werden und durch ihre Datenlandschaft fließen.
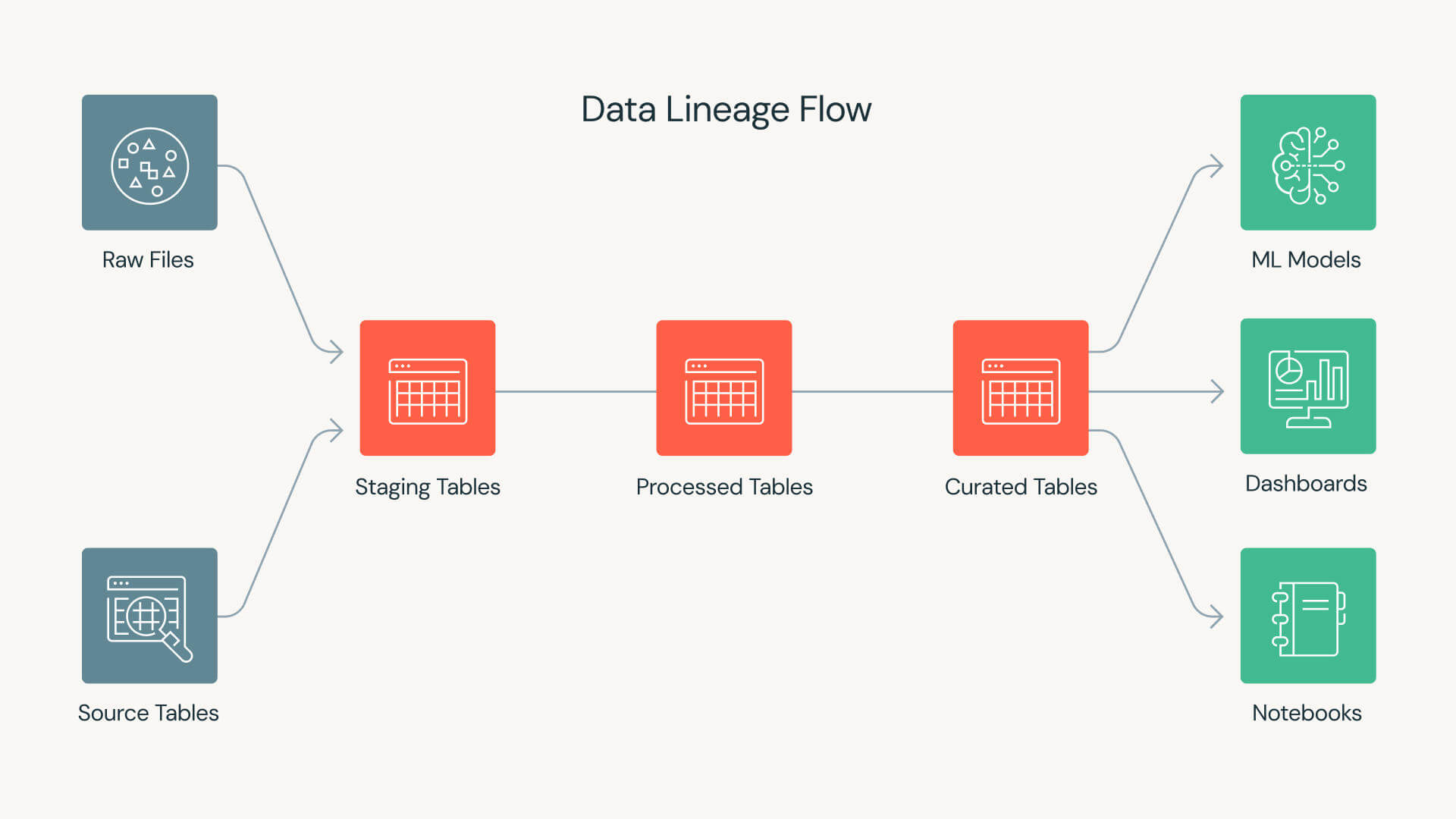
Datenherkunft erfasst die relevanten Informationen und Ereignisse rund um Daten über ihren Lebenszyklus hinweg, darunter:
- Die Quelle der Daten
- Welche weiteren Datensätze wurden dafür verwendet?
- Wer die Daten erstellt hat und wann
- So wurde es umgewandelt
- Welche anderen Datensätze verwenden es?
- Wie die Daten genutzt werden können
- Wer ist für die Nutzung und Änderung der Daten verantwortlich
Wenn Unternehmen eine datengetriebene Kultur leben und Daten und AI demokratisieren und skalieren möchten, ist Datenherkunft eine zentrale Säule einer Strategie für Datenmanagement und Data Governance.
Warum ist die Datenherkunft wichtig?
Datenherkunft zeigt Unternehmen, woher Daten stammen, wie sie sich im Zeitverlauf verändern und wo sie gespeichert und genutzt werden – das schafft Transparenz und Vertrauen. Sie ist ein zentraler Baustein für Datenverständnis und -integrität und hilft Organisationen, fundierte Entscheidungen zu treffen, Compliance zu erfüllen und das Risikomanagement zu verbessern.
Datenherkunft ist zentral für die Data Governance – die Grundsätze, Praktiken und Tools, mit denen eine Organisation ihre Datenbestände verwaltet. Datenherkunft liefert die nötige Transparenz, um sicherzustellen, dass Daten gemäß dem Data‑Governance‑Rahmen der Organisation verwaltet werden, sichert die Datenqualität und legt die Basis für wertvolle Dateneinblicke.
Data Lineage ermöglicht Organisationen, die Genauigkeit und Konsistenz ihrer Daten zu prüfen und so die Datenqualität sicherzustellen. Die von Data Lineage bereitgestellte detaillierte Nachverfolgung ist entscheidend, um Datenfehler in einer Pipeline schnell zu erkennen und zu beheben.
Sorgfältige Verfahren zur Nachverfolgung der Datenherkunft sind entscheidend für die Einhaltung gesetzlicher Vorgaben und ermöglichen es Organisationen, nachzuweisen, woher Daten stammen und wie sie verarbeitet wurden. Die Datenherkunft hilft Unternehmen außerdem, den Fluss sensibler Daten nachzuverfolgen, sorgt für die Einhaltung von Richtlinien und Kontrollen und hilft, mögliche Risiken zu erkennen.
Welche Anwendungsfälle gibt es für Datenherkunft?
Die Datenherkunft ist ein wesentlicher Bestandteil einer wirksamen Strategie für Datenmanagement und Governance, da Organisationen Daten und AI demokratisieren und skalieren wollen. Typische Anwendungsfälle sind:
Auswirkungsanalyse und Risikomanagement: Wenn Daten im Verlauf ihres Lebenszyklus transformiert werden, ist es wichtig, die Auswirkungen dieser Änderungen auf nachgelagerte Anwender zu analysieren und potenzielle Risiken zu bewerten. Die Datenherkunft ermöglicht Datenteams, alle nachgelagerten Abnehmer – etwa Anwendungen, Dashboards und Machine-Learning-Modelle – zu sehen, die Auswirkungen von Änderungen zu verstehen und Beteiligte zu informieren.
Datenverständnis und Transparenz: Ein besseres Verständnis des Kontexts rund um Daten ist entscheidend, um ihre Vertrauenswürdigkeit zu sichern – besonders, wenn Unternehmen mit ständig wachsenden Datenmengen aus vielen Quellen arbeiten. Datenherkunft hilft Datennutzern, den Kontext bei der Analyse zu verstehen – das führt zu besseren Ergebnissen.
Fehlersuche und Diagnose: Datenherkunft hilft Teams, die Ursache von Fehlern in Datenpipelines zu finden, indem sich Fehler bis zu ihrer Quelle nachverfolgen lassen. Das verkürzt die Zeit für die Fehlersuche deutlich und steigert die Effizienz.
Compliance und Audit-Bereitschaft: Die Nachvollziehbarkeit von Daten ist entscheidend für Compliance. Viele Compliance-Vorschriften, etwa die General Data Protection Regulation (GDPR), der California Consumer Privacy Act (CCPA), der Health Insurance Portability and Accountability Act (HIPAA), BCBS 239 (Basel Committee on Banking Supervision) und der Sarbanes-Oxley Act (SOX), verlangen von Organisationen ein klares Verständnis und Sichtbarkeit der Datenflüsse. Mit wirksamen Praktiken zur Datenherkunft haben Organisationen diese Informationen parat und sind für Audits bereit.
Datenmodellierung: Datenherkunft ist hilfreich für die Datenmodellierung – den Prozess, der zeigt, wie Daten organisiert sind und wie auf sie zugegriffen wird. Datenherkunft kann helfen, Datenmodelle zu aktualisieren und zu verfeinern, indem sie Beziehungen zwischen Datenbeständen sichtbar macht und Kontext zu aktuellen Datenflüssen liefert.
Datenmigration: Datenherkunft liefert Informationen zum Speicherort und Lebenszyklus von Daten – wichtig für Datenmigrationen, also das Verschieben von Daten in neue Softwaresysteme oder Speicher. Organisationen nutzen Informationen zur Datenherkunft, um Migrationen zu planen und Risiken zu senken. Datenherkunft kann Teams auch helfen, aufzuräumen und die zu migrierende Datenmenge zu reduzieren.
Das Playbook für agentenbasierte KI für Unternehmen

Best Practices für die Implementierung von Datenherkunft
Für eine wirksame Datenherkunft braucht es einen strategischen Ansatz mit klar definierten Prozessen. Das sind die wichtigsten Best Practices, denen Unternehmen folgen sollten:
- Vereinheitlichter Daten- und AI-Katalog – Richten Sie einen zentralen Katalog ein, der Daten- und AI-Ressourcen integriert und nahtlose Transparenz und Governance ermöglicht
- Robuste Data Governance – Definieren Sie klare Strategien, Prozesse und Tools, um Daten wirksam zu steuern und Qualität, Sicherheit und Compliance sicherzustellen
- Umfassende Dokumentation – Führen Sie detaillierte Aufzeichnungen über Datenquellen, Umwandlungen und Änderungen, um einen vollständigen und genauen Verlauf sicherzustellen
- Automatisierung – Nutzen Sie automatisierte Tools zur Nachverfolgung der Datenherkunft, um die Genauigkeit zu erhöhen, die Effizienz zu verbessern und den manuellen Aufwand bei der Überwachung von Datenflüssen bis auf Spaltenebene zu reduzieren
- Klare Datenverantwortung – Weisen Sie für Datenressourcen Verantwortliche zu, um Verantwortlichkeit zu schaffen, die Problemlösung zu vereinfachen und die Zusammenarbeit zu fördern
- Fortlaufende Prüfung – Überprüfen und aktualisieren Sie regelmäßig die Aufzeichnungen zur Datenherkunft, um Genauigkeit, Vollständigkeit und die Einhaltung der Governance-Richtlinien sicherzustellen.
Automatisieren Sie die Datenherkunft für Daten und AI mit Databricks Unity Catalog
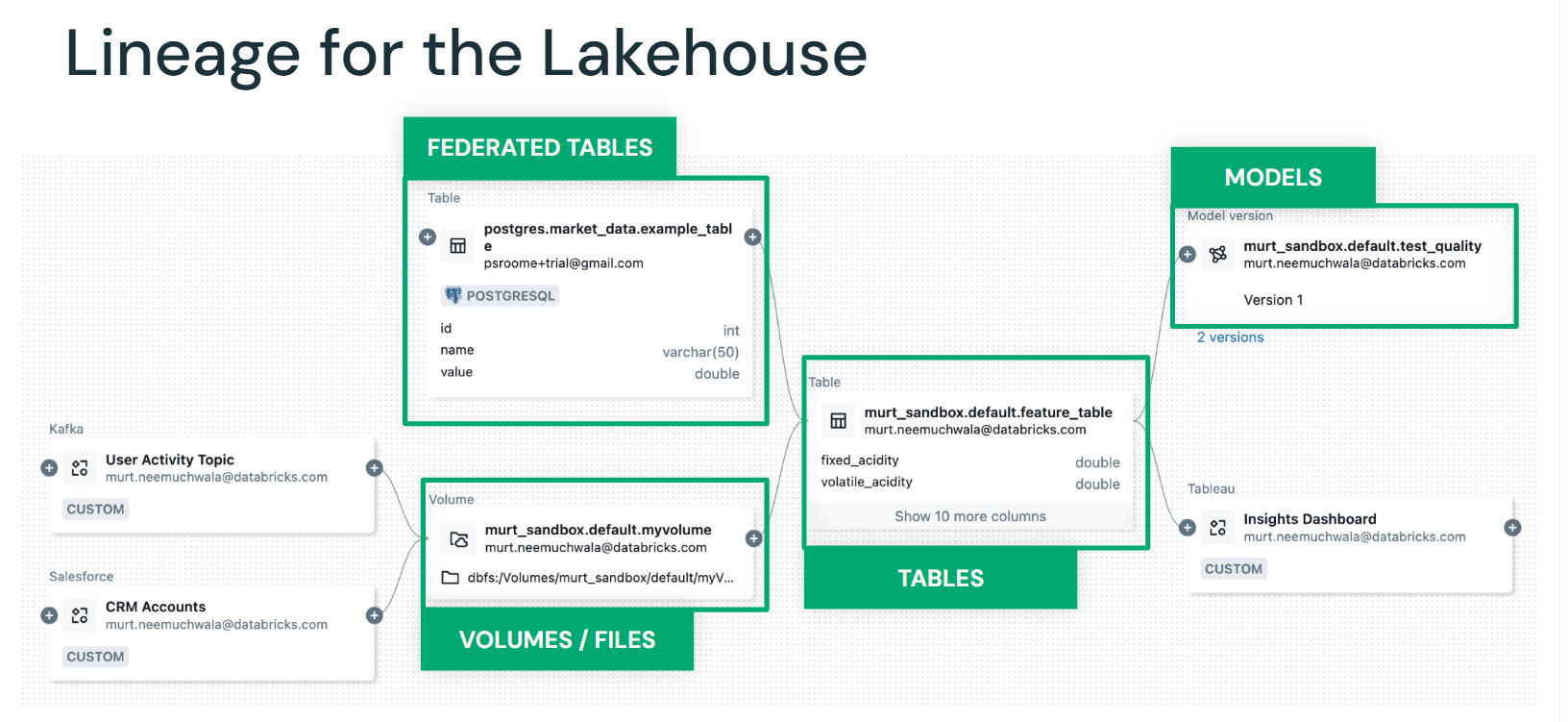
Unity Catalog bietet eine einheitliche Governance-Lösung für Daten, Analysen und AI, die Datenteams befähigt, all ihre Daten- und AI-Assets zu katalogisieren, detaillierte Zugriffsrechte festzulegen, Datenzugriffe zu prüfen und Daten über Clouds, Regionen und Datenplattformen hinweg zu teilen. Mit der automatisierten Datenherkunft in Unity Catalog können Datenteams sensible Daten bis auf Spaltenebene nachverfolgen – für Compliance-Anforderungen und Prüfberichte –, die Datenqualität in allen Arbeitsabläufen sicherstellen, Auswirkungen von Änderungen im gesamten Lakehouse bewerten bzw. Änderungen steuern und die Ursachen von Fehlern in ihren Datenpipelines ermitteln.
Zusätzliche Ressourcen
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.