Was ist eine relationale Datenbank (RDBMS)?
Strukturierte Daten in Tabellen mit definierten Beziehungen speichern und verwalten, wobei die Datenintegrität durch ACID-Eigenschaften sichergestellt wird.
- Verstehen Sie, was relationale Datenbankmanagementsysteme (RDBMS) sind und wie sie Daten in strukturierten Tabellen mit Beziehungen organisieren.
- Lernen Sie die Prinzipien relationaler Datenbanken kennen, darunter Primärschlüssel, Fremdschlüssel, Normalisierung und SQL-basierte Abfragen.
- Entdecken Sie, warum RDBMS-Lösungen für Transaktionssysteme, die Datenkonsistenz und referenzielle Integrität erfordern, weiterhin unerlässlich sind.
Was ist eine relationale Datenbank?
Eine relationale Datenbank ist ein Datenbanktyp, der Daten in Tabellen speichert und den Zugriff darauf ermöglicht. Diese Tabellen können durch gemeinsame Spalten und Zeilen, die als Relationen bezeichnet werden, miteinander verknüpft werden und verfügen über eindeutige Identifikatoren (Schlüssel), die die verschiedenen Beziehungen zwischen den Tabellen aufzeigen.
Dieses relationale Modell ähnelt einem Tabellenkalkulationsmodell darin, dass Zeilen die einzelnen Datensätze wie Kunden, Konten oder Transaktionen darstellen, während Spalten die Attribute dieser Datensätze wie Kunden-ID, Kontonummer oder Transaktionsbetrag repräsentieren. Bei diesem Modell können Zeilen in einer Tabelle über gemeinsame Schlüssel, die die Beziehungen zwischen den Tabellen herstellen, mit Zeilen in einer anderen Tabelle verknüpft werden.
Dieses Modell bietet eine standardisierte Möglichkeit, Daten darzustellen und Abfragen durchzuführen, die von einer Vielzahl von Anwendungen genutzt werden kann.
Ein relationales Datenbankmanagementsystem (RDBMS) ist ein Softwaresystem (manchmal auch als Datenbank-Engine bezeichnet), das das relationale Datenbankmodell implementiert und relationale Daten verwaltet – nicht nur Tabellen – von Schreib- und Lesezugriffen auf/von Festplatten über die Pflege von Indizes und die Ausführung von Abfragen bis hin zur Durchsetzung der Datenintegrität.
Grundkonzepte des relationalen Modells
Tabellen, Zeilen und Spalten
Die grundlegende Struktur des relationalen Modells ist die Organisation von Daten in Tabellen, Zeilen und Spalten. Tabellen sind zweidimensionale Datenstrukturen, die erstellt werden, um eine Sammlung zusammengehöriger Daten darzustellen, die logisch organisiert sind, um die Ausführung strukturierter Abfragen zu ermöglichen.
Zeilen stellen bestimmte Entitäten oder Datensätze (Tupel) in einer relationalen Datenbanktabelle dar und enthalten den Wert für jede Spalte.
Spalten stellen die Attributkategorien für jeden Datensatz in einer Zeile dar.
Im Wesentlichen definieren die Spalten die Struktur und die Zeilen liefern die tatsächlichen Daten. Eine einfache Produkttabelle könnte die folgenden Zeilen spezifischer Produkte mit Spalten zugehöriger Attribute enthalten:
| Produkt-ID | Produktname | Produkttyp | Preis ($) |
|---|---|---|---|
| PSHL16 | Chuck’s Hot Pork Sausage | Scharfe Schweinswürstchen (1lb) | 5.99 |
| PSML16 | Chucks milde Schweinswurst | Mild Pork Links (1lb) | 5.99 |
| GTS16 | Chuck’s Putenbratwurst | Seasoned Ground Turkey (1lb) | 6.59 |
| GT48 | Chuck’s Putenhackfleisch | Putenhackfleisch (3lb) | 18.59 |
Schema und strukturierte Daten
Das Schema einer relationalen Datenbank beschreibt die Struktur der Datenbank. Es definiert einen Plan dafür, wie die Daten aussehen sollen und welche Regeln sie befolgen müssen. Die strukturierten Daten werden gemäß diesem Schema in einem konsistenten und vorhersagbaren Format gespeichert (Zeilen und Spalten mit konsistenten Beziehungen, die definieren, welche Datentypen wohin gehören und wie sie dargestellt werden müssen).
Ein gutes Schema gewährleistet die Integrität und Konsistenz von Datentypen. Mit einer bekannten Struktur können Sie Speicherung und Abfragen optimieren, um die Performance aufrechtzuerhalten und das Verständnis zu verbessern, da jede Tabelle und Spalte dieselbe Bedeutung hat.
Einschränkungen und Indizes
Beim Schreiben in eine Tabelle kann es Einschränkungen und Regeln geben. Beispielsweise muss im obigen Beispiel jedes Produkt einer echten Produkt-ID zugeordnet sein, und jeder Produkttyp beschreibt auf konsistente Weise verpackte (Links) oder gemahlene Produkte und deren Gewicht. Es können außerdem Schutzmechanismen festgelegt werden, z. B. dass jede Spalte Werte (NOT NULL) ohne Duplikate (UNIQUE) enthalten muss, mit Ausnahme des Preises.
Das bedeutet, dass jede Zeile die gleichen Felder hat und jedes Feld die gleiche Bedeutung hat. Mit einem strengen Schema bleiben die Daten sauber, die Beziehungen gültig und die Abfragen vorhersagbar.
Relationale Datenbanken können auch Indizes haben, die das Auffinden von Zeilen ohne einen vollständigen Tabellenscan beschleunigen. Ein Index speichert die Spaltenwerte und stellt Zeiger auf die Zeilen in der Tabelle bereit, in denen diese Werte vorkommen. Die Performance kann sich bei der Abfrage großer Tabellen verlangsamen, und die Indizierung vermeidet das Scannen jeder einzelnen Zeile in einer Tabelle.
Datenbanken speichern Indizes in verschiedenen optimierten Strukturen, um die Geschwindigkeit des Datenabrufs zu verbessern:
- Die B-Baum-Indizierung ist eine gängige Datenstruktur, die entwickelt wurde, um große Datasets durch die Reduzierung der Baumhöhe effizient zu verarbeiten. Jeder Knoten in einem B-Baum kann mehrere Schlüssel speichern und mehrere Kinder haben, was die Anzahl der für den Datenzugriff erforderlichen Festplatten-I/O-Operationen minimiert. Indem er mehr Kinder unter einem Knoten zulässt als ein regulärer selbstausgleichender binärer Suchbaum, reduziert der B-Baum die Höhe des Baumes und legt die Daten in weniger separaten Blöcken ab.
- Hash-Tabellen sind Datenstrukturen, die Schlüssel auf Werte abbilden und eine Hash-Funktion verwenden, um einen Schlüssel in einen Index umzuwandeln, unter dem der entsprechende Wert gespeichert ist. Hash-basierte Indizes sind für exakte Übereinstimmungssuchen effektiv, werden aber nicht in allen RDBMS universell unterstützt oder als default-Indextyp verwendet und bewahren die Reihenfolge nicht wie B-Bäume.
Schlüssel und Beziehungen
Keys sind unerlässlich, um Eindeutigkeit, Integrität und einen effizienten Datenabruf zu gewährleisten. Sie identifizieren Zeilen eindeutig, stellen Beziehungen zwischen Tabellen her und verhindern Duplikate. Dadurch bilden sie das Rückgrat des relationalen Schemadesigns. Datenpunkte in Tabellen können mit gemeinsamen Schlüsseln verbunden werden, sodass Tabellen zur Erstellung von Berichten abgefragt werden können. Mithilfe gemeinsamer Schlüssel können Beziehungen Eins-zu-eins-, Eins-zu-viele- und Viele-zu-viele-Beziehungen sein.
Tabellen werden mit verschiedenen Key-Typen verbunden:
- Superschlüssel sind Sätze aus einem oder mehreren Attributen, die einen Datensatz eindeutig identifizieren können.
- Ein Kandidatenschlüssel ist eine minimale Menge von Attributen, die einen Datensatz eindeutig identifizieren kann.
- Ein Primärschlüssel ist ein eindeutiger Schlüssel, der eine Zeile in seiner Tabelle identifiziert. In einer Kundentabelle wäre beispielsweise die Kunden-ID ein Primär-Key.
- Ein alternativer Schlüssel ist ein Kandidatenschlüssel, der nicht als Primärschlüssel ausgewählt wird.
- Ein Fremdschlüssel ist eine Spalte, die auf einen Primärschlüssel in einer anderen Tabelle verweist. Beispielsweise könnte eine Transaktionstabelle mit Orders.customer_id auf die Kunden-ID aus der Kundentabelle verweisen.
- Ein zusammengesetzter Schlüssel wird benötigt, wenn eine Kombination aus zwei oder mehr Attributen erforderlich ist, um alle Datensätze einer Tabelle zu identifizieren.
Wesentliche Eigenschaften von relationalen Datenbanken
Relationale Datenbanken sind Gruppen von Operationen (Transaktionen), die zusammenarbeiten und mehrere definierende Features aufweisen, die sie zuverlässig machen. Diese Transaktionen folgen einer Reihe von Regeln, die als ACID bezeichnet werden. Dies steht für:
- Atomarität: Alle Aktualisierungen müssen vollständig abgeschlossen sein
- Konsistenz: Regeln werden immer durchgesetzt
- Isolation: Gleichzeitige Transaktionen stören sich nicht gegenseitig in ihren Zwischenzuständen.
- Dauerhaftigkeit: Sobald die Daten committet wurden, können sie Abstürze oder Ausfälle überstehen.
Diese Regeln helfen, die Datenintegrität auf Transaktionsebene zu gewährleisten und garantieren, dass Datenbankoperationen zuverlässig und korrekt abgeschlossen werden. Schemadesign, Datentypen und Einschränkungen sind dafür verantwortlich, sicherzustellen, dass Werte in Spalten atomar und in ihrer Bedeutung konsistent sind. Einschränkungen werden verwendet, um die Konsistenz über mehrere Tabellen hinweg aufrechtzuerhalten.
Eine weitere Schlüsseleigenschaft relationaler Datenbanken ist die Structure Query Language (SQL), die gebräuchlichste Sprache, um Daten zu extrahieren. Da Daten in vorhersagbaren Tabellen mit Beziehungen gespeichert werden, wird SQL verwendet, um komplexe Fragen effizient zu beantworten und die Datenanalyse zu unterstützen. Sie bietet eine Standardmethode für die Ausführung von Abfragen, den Abruf von Daten, das Einfügen/Aktualisieren/Löschen von Datensätzen, die Erstellung neuer Datenbanken oder Tabellen und die Festlegung von Berechtigungen für Tabellen, Prozeduren und Ansichten.
Relationale Datenbanken müssen auch Sicherheit/Zugriffskontrolle gewährleisten, um Daten in mehreren Dimensionen zu schützen:
- Authentifizierung – Diejenigen, die auf die Datenbank zugreifen, sind die, für die sie sich ausgeben
- Autorisierung – Sie tun das, was Sie tun dürfen
- Prüfung – Bestätigung dessen, was Sie wann getan haben
Datenbanksicherheit umfasst auch Features wie Verschlüsselung zum Schutz von Daten vor Abfangen oder Diebstahl sowie Sicherung und Wiederherstellung, um Datenverluste bei Systemausfällen zu verhindern.
Relationale Datenbanken sind aufgrund ihrer Standardisierung und Reife zu den „Systems of Record“ geworden. Standard-Features, -strukturen und -fähigkeiten sorgen dafür, dass ein RDBMS im Laufe der Zeit vorhersagbar, zuverlässig, sicher und skalierbar bleibt. Wenn beispielsweise SQL als Standard-Abfrage verwendet wird, können Kernkonzepte und Fähigkeiten von einem RDBMS auf ein anderes übertragen werden und Datenanwendungen sowie Tools können durch Migrationen gewartet werden. Die Standardisierung erhöht auch den Wettbewerb und die Auswahl unter den Anbietern.
Relationale Datenbanken gibt es schon seit langer Zeit. Diese Reife bedeutet, dass sie für reale Arbeitslasten praxiserprobt und für extrem verfeinerte Transaktionen optimiert sind.
Relationale vs. nicht relationale Datenbanken
Der offensichtlichste Unterschied zwischen relationalen und nicht-relationalen Datenbanken besteht darin, dass nicht-relationale Datenbanken keine strukturierten Daten in Tabellen speichern. Sie bieten die Flexibilität, Daten in Containern in dem Format zu speichern, das für die zu speichernden Daten am besten geeignet ist. Diese lose definierten, unstrukturierten Daten können E-Mails, Geschäftsdokumente, Videos und Bilder umfassen. Sie können aber auch eine Mischung aus strukturierten Transaktionsdaten und unstrukturierten Daten speichern.
Nicht-relationale Datenbanken werden oft als NoSQL-Datenbanken bezeichnet. Dieser Begriff bedeutete ursprünglich „nicht nur SQL“ und spiegelt wider, dass diese Systeme nicht auf SQL als primäre Schnittstelle angewiesen sind, obwohl viele von ihnen mittlerweile SQL-basierte Abfragen unterstützen.
Relationale Datenbanken verwenden ein festes Schema mit Zeilen und Spalten und Beziehungen mit Keys und SQL-Joins, während nicht-relationale Datenbanken Daten in flexiblen Strukturen speichern, die kein vordefiniertes Schema erfordern, wie Key-Value-Paare, Knoten/Kanten und Dokumente. Bei relationalen Datenbanken müssen die Daten beim Schreiben dem Schema entsprechen, während die Datenform bei nicht relationalen Datenbanken variieren kann. Dort werden die Daten beim Lesen interpretiert und Beziehungen werden in der Regel in Anwendungen und nicht in der Datenbank gehandhabt.
Relationale Datenbanken verwenden standardmäßig auch starke ACID-Transaktionen, während NoSQL-Datenbanken traditionell für eventuelle Konsistenz ausgelegt sind und Verfügbarkeit und Geschwindigkeit gegenüber Korrektheit priorisieren.
Relationale Datenbanken werden gewählt, wenn eine klare Struktur mit strengen Regeln sowie eine Vielzahl von Beziehungen zwischen Datenpunkten benötigt wird. Ein relationales Modell eignet sich am besten für Berichte und Analysen mit Transaktionen, die immer korrekt sein müssen. Relationale Datenbanken eignen sich hervorragend für Ad-hoc-Analysen sowie für komplexes Filtern und Gruppieren, während nicht-relationale Datenbanken oft für einen begrenzten Abfragesatz optimiert sind. Relationale Datenbanken skalieren typischerweise vertikal, wobei moderne Systeme die horizontale Skalierung durch Replikate, Sharding oder verteilte Ausführung unterstützen, oft mit zusätzlicher Komplexität, während nicht-relationale Datenbanken für die horizontale Skalierung ausgelegt sind und in der Regel für große, verteilte Netzwerke gewählt werden.
Nicht-relationale Datenbanken werden für flexible oder sich schnell entwickelnde Daten in großer Scale mit einfachen Abfragemustern ausgewählt.
Gängige RDBMS-Beispiele
- MySQL – Ein Open-Source-RDBMS, jetzt im Besitz der Oracle Corp., das den SQL-Standard implementiert. Es ist oft die bevorzugte Wahl für Webanwendungen, Geschäftssysteme und kritische datengesteuerte Dienste, die eine hohe Performance erfordern. Es wird häufig für Webanwendungen, Onlineshops und Kataloge, Benutzerkonten und Authentifizierungssysteme, Protokollierung und Analysen, SaaS-Apps und Dashboards verwendet.
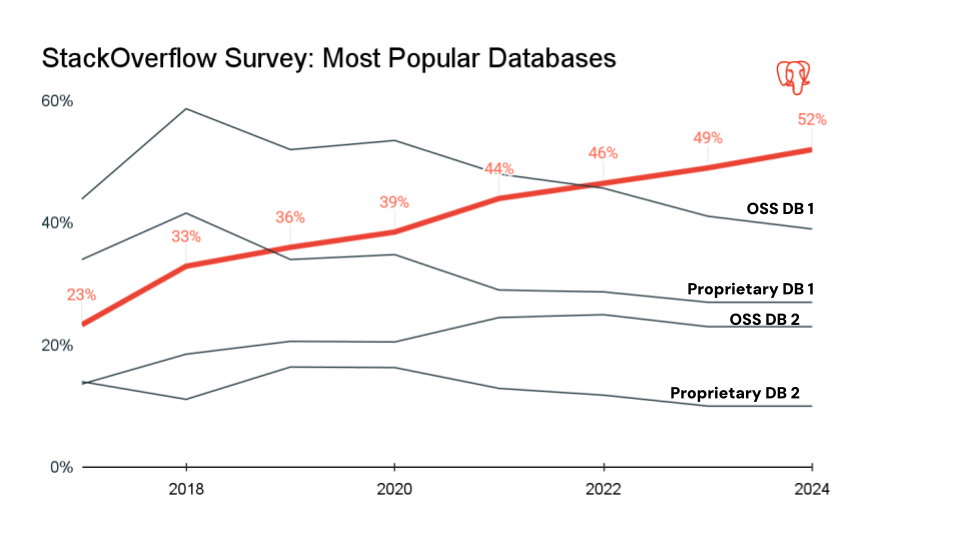
- PostgreSQL – Ein hochgradig erweiterbares Open-Source-RDBMS, das für hohe Standards und ACID-Compliance mit einer guten Balance zwischen Zuverlässigkeit und Flexibilität bekannt ist. Es unterstützt sowohl SQL als auch die Speicherung von teilstrukturiertem JSON/JSONB und verwendet Multi-Version Concurrency Control. PostgreSQL wird für Web-Apps, SaaS-Multi-Tenant-Plattformen, Finanztransaktionen, Analysen und Berichte, wissenschaftliche Daten und OLTP-Workloads verwendet. Es ist bei reinen Online-Unternehmen beliebt. In den letzten sieben Jahren hat sich Postgres zur beliebtesten Datenbank in der Entwickler-Community entwickelt und ist die De-facto-Datenbankwahl für moderne Anwendungen.
- SQLite – Eine serverlose, plattformübergreifende, relationale Open-Source-Datenbank, die SQL verwendet und über eine schlanke C-Bibliothek in einer Anwendung ausgeführt wird. Es erfordert keine Einrichtung oder Verwaltung. SQLite wird hauptsächlich für eingebettete Systeme und kleine Anwendungen auf persönlichen Geräten verwendet.
- Oracle – Ein proprietäres, unternehmenstaugliches RDBMS, das von der Oracle Corp. entwickelt wurde. Es ist bekannt für seine Skalierbarkeit, sein Clustering und seine Zuverlässigkeit und ist sowohl für transaktionale (OLTP) als auch für analytische (OLAP) Workloads optimiert. Es wird im Bankwesen, bei Fluggesellschaften, im Gesundheitswesen, in der Telekommunikation, bei Behörden und für große ERP/CRM-Systeme eingesetzt.
- Microsoft SQL Server – Microsofts proprietäres, unternehmenstaugliches RDBMS, das auf Transact-SQL (T-SQL), Microsofts SQL-Erweiterung, basiert. SQL Server ist für Windows und Linux verfügbar und für seine Management- und Administrationstools sowie seine starke Integration mit Microsoft Azure und anderen Microsoft-Technologien bekannt. Typische Anwendungsfälle sind ERP, CRM, HR, E-Commerce, Business Intelligence und Analytics. SQL Server ist stark im Finanz-, Bank- und Gesundheitswesen.
- IBM Db2 – Eine proprietäre Familie von RDBMS-Systemen, die von IBM für hohe Performance, Zuverlässigkeit und die Datenverarbeitung im Unternehmens-Scale entwickelt wurde. Db2-RDBMS-Versionen laufen auf mehreren Plattformen, darunter Linux, UNIX, Windows, IBM AS/400 und IBM-Mainframes. Es ist SQL-basiert, unterstützt in einigen Versionen aber auch JSON-Dokumente, XKL-Speicherung, Zeitreihendaten, spaltenorientierte Speicherung und Graph-Funktionen. Es wird häufig im Finanzwesen, im öffentlichen Sektor, im Gesundheits- und Versicherungswesen, im Einzelhandel, bei Fluggesellschaften und in Unternehmens-IT-Umgebungen eingesetzt.
- MariaDB – Ein Open-Source-RDBMS, das als Community-gesteuerter Drop-in-Ersatz für MySQL entwickelt wurde und von der MariaDB Foundation verwaltet wird. Es wird häufig sowohl für OLTP- als auch für OLAP-Workloads in Web-Apps, SaaS-Plattformen, Cloud-Systemen und Unternehmen eingesetzt und ist eine häufige Wahl für Linux-Systeme und Open-Source-Stacks. Gängige Anwendungsfälle sind Web-Apps und Websites, SaaS-Plattformen, Content Management, E-Commerce und Analysen.
Das Playbook für agentenbasierte KI für Unternehmen

SQL, RDBMS und zugehörige FAQs
Ist SQL eine relationale Datenbank?
Nein, SQL ist eine Abfragesprache, die zur Interaktion mit einer relationalen Datenbank verwendet wird, und kein Datenbanksystem.
Ist MySQL eine relationale Datenbank?
Ja, MySQL ist ein RDBMS mit einer tabellenbasierten Struktur, die Beziehungen zwischen Tabellen unterstützt.
Ist Excel relational?
Nein, Excel ist das Tabellenkalkulationsprogramm von Microsoft, kein RDBMS. Obwohl Excel ein Tabellenformat verwendet, gibt es kein vorgegebenes Schema mit einer konsistenten Struktur und Einschränkungen. Excel kann von sich aus keine SQL-Abfragen ausführen und es gibt keine ACID-Transaktionen.
Was ist der Unterschied zwischen der Terminologie für relationale Datenbanken und RDBMS?
Obwohl sie eng miteinander verwandt sind und oft austauschbar verwendet werden, beziehen sich relationale Datenbanken auf das Datenmodell selbst, während ein RDBMS ein Softwaresystem ist, das dieses Datenmodell verwaltet.
Vorteile und Einschränkungen
Zu den Vorteilen der Verwendung relationaler Datenbanken gehören:
- Starke Datenintegrität und -konsistenz, die durch ACID-Transaktionen durchgesetzt werden, um sicherzustellen, dass es keine teilweisen Aktualisierungen, keine beschädigten Daten und zuverlässigen Betrieb gibt. Strukturierte, gut definierte Daten gewährleisten saubere, vorhersagbare Daten.
- Standardisierte Abfragefunktionen und Tools mit SQL bieten Filterung, Gruppierung, Aggregation, Indizierung und komplexe Joins, was relationale Datenbanken ideal für Analytics, Berichterstattung und komplexe Geschäftslogik macht.
- Mit jahrzehntelanger Reife werden relationale Datenbanken gut unterstützt und bieten eine zuverlässige Performance, starke Sicherheits- und Verfügbarkeitsmodelle und ein Ökosystem von Tools zur Risikominderung.
Zu den Einschränkungen gehören:
- Das starre, feste Schema relationaler Datenbanken reduziert die Agilität und ist nicht für unstrukturierte oder semistrukturierte Daten und sich häufig ändernde Datensatzformen geeignet.
- Relationale Datenbanken eignen sich hervorragend für die vertikale Skalierung, aber die horizontale Skalierung ist komplex.
- Die Performance kann sich bei sehr großen Datensätzen und komplexen Joins verschlechtern, was verteilte Workloads verlangsamen kann.
- Kommerzielle RDBMS können teuer sein, insbesondere bei der Scale.
- OLTP ist nicht für komplexe Analysenabfragen gedacht.
- Einfache Erstellung von Datensilos, was die Speicherkosten erhöht.
- ETL-Komplexität (beim Verschieben von Daten zwischen operativen und analytischen Datenspeichern).
- Verarbeitung von semistrukturierten Daten (Delta, Iceberg, Parquet – was man im Lakehouse findet).
- Schwierigkeiten bei der Integration von nicht standardmäßigen Datentypen für ML/KI
- Nicht für die Verarbeitung von Streaming-Daten ausgelegt
- Anbieterbindung vermeiden
Evolution über traditionelle RDBMS hinaus
- Data-Warehouse-Ära: RDBMS sind für die Verwendung aktueller Daten konzipiert und für viele kleine Lese-/Schreibvorgänge für die Online-Transaktionsverarbeitung (OLTP) optimiert. Daher können sie bei Analytics im großen Scale Schwierigkeiten haben. Um diese Einschränkung zu überwinden, verwenden Data Warehouses denormalisierte Schemata, die riesige, komplexe Abfragen auf aktuellen und historischen Daten für das Online Analytical Processing (OLAP) verarbeiten können.
- Herausforderung Big Data: RDBMS haben Schwierigkeiten beim Umgang mit massiven, schnellen, vielfältigen und verteilten Daten. Ihr starres Schema, die vertikale Skalierung und der ACID-Transaktions-Overhead machten sie für umfangreiche, verteilte Analysen weniger geeignet. Herkömmliche RDBMS basieren auf Joins, die auf lokal verwaltetem Speicher ausgeführt werden, was die Skalierbarkeit in verteilten Umgebungen einschränkt.
- Cloudnative Anforderungen: Herkömmliche relationale Datenbanksysteme haben in cloudnativen Architekturen, die Objektspeicher bevorzugen, Schwierigkeiten. Sie sind für Blockspeicher mit eng gekoppelter Hardware und Festplattenzugriff mit geringer Latenz ausgelegt. In der Vergangenheit bot Objektspeicher nicht die Garantien für niedrige Latenzzeiten, die für die klassische ACID-Transaktionen Verarbeitung erforderlich sind, was eine Herausforderung für traditionelle RDBMS-Designs darstellte. Objektspeicher ist für den Durchsatz und nicht für die Latenz optimiert. Cloud-native Anwendungen skalieren ebenfalls horizontal, während herkömmliche RDBMS-Designs auf eng gekoppelten Rechen- und Speicherressourcen basieren, die oft um einen primären Server herum zentriert sind.
- Moderne Data Lakes: Lakehouse-Architekturen wurden entwickelt, um die Einschränkungen herkömmlicher Data Lakes zu überwinden, indem sie die Skalierbarkeit und die geringen Kosten von Data Lakes mit der Struktur, der Governance und den Performance-Merkmalen von Data Warehouses und relationalen Systemen kombinieren.
Ein Lakehouse verwendet cloudnativen Objektspeicher für die Datenpersistenz und führt gleichzeitig verwaltete Tabellenformate, Metadatenschichten und Transaktionsprotokolle ein, die Schemaerzwingung, SQL-Zugriff und ACID-Transaktionen direkt auf diesem Speicher ermöglichen. Dies ermöglicht, dass strukturierte, semistrukturierte und unstrukturierte Daten in einem einzigen System koexistieren.
Im Gegensatz zu frühen Data Lakes, die stark auf Schema-on-Read und externe Verarbeitungslogik angewiesen waren, unterstützen Lakehouses Schema-on-Write oder eine verwaltete Schemaentwicklung auf Tabellenebene. Dies ermöglicht konsistente Datendefinitionen, die Durchsetzung der Datenqualität und zuverlässige Analysen. Durch die Entkopplung von Speicher und Rechenleistung ermöglichen Lakehouse-Architekturen, dass mehrere Compute-Engines für Analysen, Data Engineering, Streaming und Machine Learning auf denselben Daten arbeiten können. Diese Flexibilität macht Lakehouses gut geeignet für groß angelegte Analytics, Business Intelligence und fortgeschrittene Daten-Workloads, während gleichzeitig Kosteneffizienz und Offenheit durch offene Datei- und Tabellenformate gewährleistet werden. - Lakebase-Architektur: Eine Lakebase ist eine neue Kategorie von operativen Datenbanken, die für moderne, intelligente Anwendungen entwickelt wurde. Während RDBMS sich durch Transaktionskonsistenz und strukturierte Schemata auszeichnen, sind sie von den analytischen Daten, Machine-Learning-Pipelines und der Echtzeit-Intelligenz isoliert, von denen Anwendungen zunehmend abhängen. Eine Lakebase kombiniert zentrale Datenbankfunktionen wie Transaktionen, Indizierung und Zugriff mit geringer Latenz mit nativer Integration in das Lakehouse, sodass Anwendungen direkt auf frischen, gemeinsam genutzten, analytischen und KI-fähigen Daten arbeiten können. Dies ermöglicht es einem einzigen System, sowohl operative Workloads als auch intelligentes, datengesteuertes Anwendungsverhalten zu unterstützen, ohne Daten zu duplizieren oder Architekturen aufzuteilen.
Umgang mit gängigen Mythen
- Alle Datenbanken sind relational
Es gibt viele nicht-relationale Datenbanken, die nicht dem relationalen Modell folgen (Speicherung von Daten in Tabellen und Verwendung von SQL zur Definition und Abfrage von Beziehungen). - Relationale Datenbanken verwenden nur SQL
Die meisten relationalen Datenbanken verwenden SQL als Hauptsprache. SQL wurde für das relationale Modell entwickelt, aber einige Datenbanken verwenden andere relationale Sprachen wie Quel, Tutorial D, Rel und Datalog. - Relationale Datenbanken sind veraltet
Relationale Datenbanken sind alles andere als veraltet. Sie sind für komplexe, strukturierte Daten nach wie vor unübertroffen und bilden immer noch das Rückgrat der heutigen geschäftskritischen Systeme. Und SQL ist immer noch eine der am weitesten verbreiteten Sprachen. Heute koexistieren relationale Datenbanken mit NoSQL, Data Lakes und Lakehouses, da sich die Anwendungsfälle für Daten ständig weiterentwickeln.
Fazit
Relationale Datenbanken mit strukturiertem Schema, die Daten in Tabellen, Zeilen und Spalten organisieren, mit Schlüsseln und Joins für schnellen Datenabruf und zuverlässige ACID-Transaktionen, bleiben eine grundlegende Architektur für sichere, unternehmenskritische Anwendungen. Mit einer Struktur, die für schnelle, zuverlässige Abfragen ausgelegt ist, bieten relationale Datenbanken die Integrität und Konsistenz von Datentypen, und Sie können Speicher und Abfragen optimieren, um die Performance aufrechtzuerhalten. Sie können auch mit nicht-relationalen Datenbanken in modernen verteilten Data-Lake- und Lakehouse-Umgebungen koexistieren.
Die Standardisierung und Reife von RDBMS bedeutet, dass sie für reale Lasten praxiserprobt und für extrem verfeinerte Transaktionen optimiert sind. Moderne Architekturen wie eine Lakebase erweitern diese bewährten relationalen Grundlagen in cloudnativ Umgebungen, sodass relationale Zuverlässigkeit und SQL-basierte Analysen mit skalierbarem Objektspeicher und verteiltem compute koexistieren können.
Zusätzliche Ressourcen
- Anfängerfreundliche Einführung, die Tabellen, Beziehungen und grundlegende Konzepte behandelt
- Umfassender Überblick über Architektur, Features und Unternehmensanwendungen von RDBMS
- Umfassende Erklärung der 1NF bis 5NF mit Beispielen
- Detaillierte Aufschlüsselung von Atomarität, Konsistenz, Isolation und Dauerhaftigkeit
- Umfassende Abdeckung einschließlich der Codd’schen Regeln und theoretischen Grundlagen
- Lakehouse: Eine neue Generation offener Plattformen, die Data Warehousing und Advanced Analytics zusammenführen
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.