Was ist operationelles maschinelles Lernen?
Die Bereitstellung von ML-Modellen in der Produktion für Echtzeitvorhersagen auf Basis von Live-Daten erfordert eine Infrastruktur für Bereitstellung, Überwachung, Nachtraining und Integration.
- Die Bereitstellungsmuster umfassen REST-APIs für synchrone Vorhersagen, Batch-Scoring für Offline-Inferenz, Edge-Bereitstellung auf Endgeräten und eingebettete Modelle in Anwendungen, die Latenz, Durchsatz und Ressourcenbeschränkungen ausbalancieren.
- Das Monitoring erfasst die Vorhersagegenauigkeit, Leistungskennzahlen des Modells, Datendrift zur Erkennung von Verteilungsänderungen, Konzeptdrift zur Identifizierung von Beziehungsänderungen, Ressourcennutzung und geschäftliche KPIs zur Messung der Modellauswirkungen.
- Die MLOps-Praktiken umfassen CI/CD-Pipelines für die Modellbereitstellung, automatisierte Retraining-Trigger, A/B-Testing-Frameworks, Canary-Deployments zur Risikominimierung, Rollback-Funktionen und Verfahren zur Reaktion auf Modellfehler.
Autor: Kevin Stumpf, Mitgründer und CTO
Als wir 2015 mit der Einführung von Ubers Machine-Learning-Plattform Michelangelo begannen, fiel uns ein interessantes Muster auf: 80 % der auf der Plattform gestarteten ML-Modelle unterstützten Anwendungsfälle des Operational Machine Learning, die sich direkt auf das Endnutzererlebnis (Uber-Fahrgäste und -Fahrer) auswirken. Nur 20 % waren Anwendungsfälle des analytischen maschinellen Lernens, die die analytische Entscheidungsfindung unterstützen.
Das von uns beobachtete Verhältnis von Operational ML zu Analytical ML war das genaue Gegenteil dessen, was wir bei den meisten anderen Unternehmen in der Praxis beobachten – dort dominierte Analytical ML. Rückblickend ist Ubers massive Einführung von Operational ML keine große Überraschung: Michelangelo machte es extrem einfach, operationales ML umzusetzen, und das Unternehmen verfügte über eine lange Reihe von Use Cases mit hohem Impact. Heute, sieben Jahre später, ist der Stellenwert von operationalem ML bei Uber weiter gestiegen: Ohne die entsprechenden Systeme wären die Fahrpreise unwirtschaftlich und es käme zu schlechten ETA-Prognosen und Verlusten in dreistelliger Millionenhöhe durch Betrug. Kurz gesagt: Ohne operationales ML käme Uber zum Stillstand.
Operational ML war ein zentraler Erfolgsfaktor für Uber, und lange Zeit schien es so, als könnten das nur Tech-Giganten es umsetzen. Die gute Nachricht: In den letzten sieben Jahren hat sich viel verändert. Neue Technologien und Trends ermöglichen es heute praktisch jedem Unternehmen, den Schritt von überwiegend analytischem ML hin zu operationalem ML zu machen. Und wir haben ein paar Tipps für alle, die genau das vorhaben. Legen wir los.
Operational ML vs. Analytical ML
Operational Machine Learning bedeutet, dass eine Anwendung ein ML-Modell nutzt, um autonom und kontinuierlich Entscheidungen zu treffen, die sich in Echtzeit auf das Geschäft auswirken. Solche Anwendungen sind geschäftskritisch und laufen „online“ in der Produktion auf dem operativen Stack eines Unternehmens.
Typische Beispiele sind Empfehlungssysteme, Such-Rankings, dynamische Preisgestaltung, Betrugserkennung und die automatisierte Entscheidung über Kreditanträge.
Der „ältere Bruder“ des operationalen ML in der „Offline“-Welt ist das Analytical Machine Learning. Dabei handelt es sich um Anwendungen, die Business-User dabei unterstützen, mit Hilfe von ML bessere Entscheidungen zu treffen. Analytische ML-Anwendungen sind im Analytics-Stack des Unternehmens verankert und fließen typischerweise direkt in Reports, Dashboards und Business-Intelligence-Tools ein.
Gängige Beispiele sind Abatzprognosen, Abwanderungsprognosen und Kundensegmentierung.
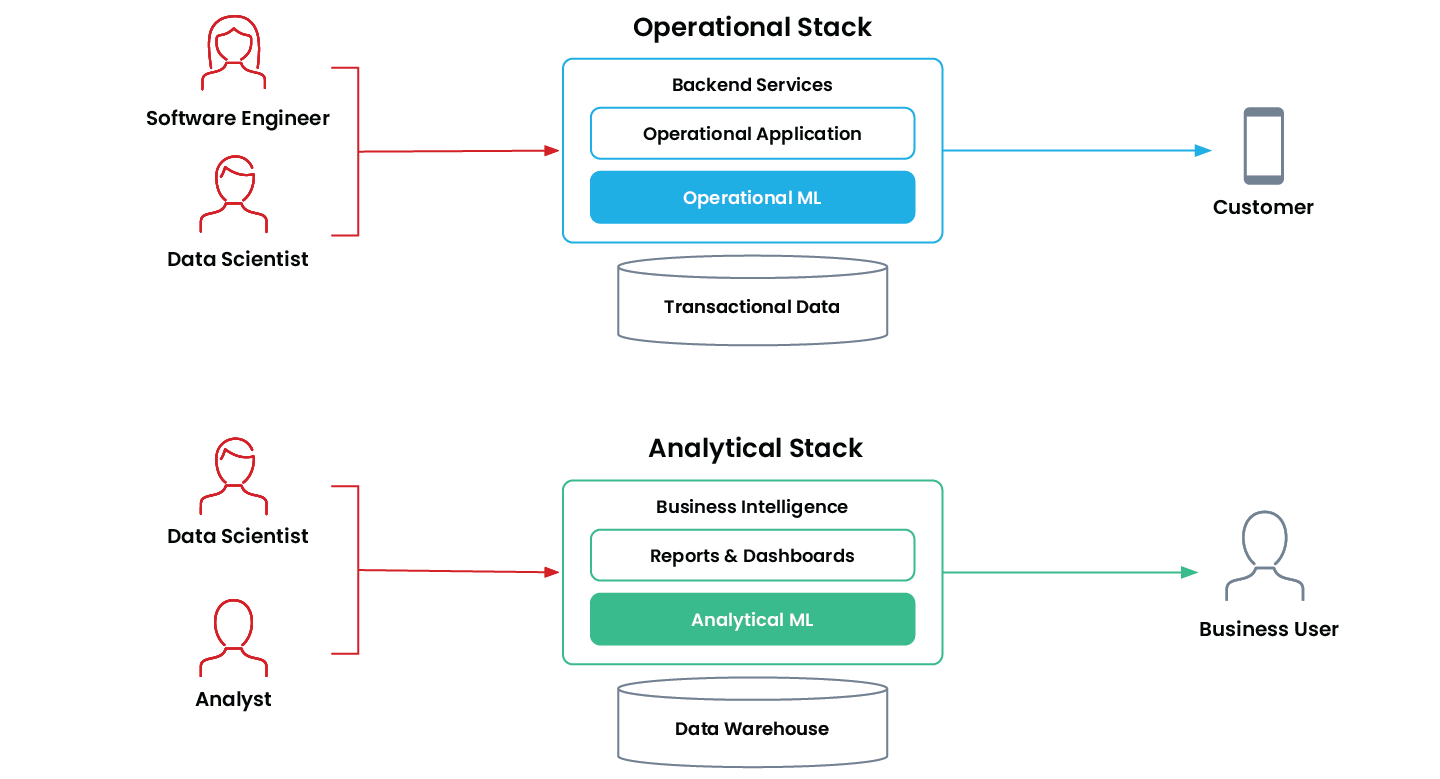
Unternehmen setzen operationales ML und analytisches ML für unterschiedliche Zwecke ein – und beide stellen jeweils eigene technische Anforderungen.
| Analytisches ML | Operational ML | |
|---|---|---|
| Automatisierung von Entscheidungen | Human-in-the-Loop | Vollständig autonom |
| Entscheidungstempo | Menschliche Geschwindigkeit | Echtzeit |
| Optimiert für | Groß angelegte Batch-Verarbeitung | Geringe Latenz und hohe Verfügbarkeit |
| Hauptzielgruppe | Interner Geschäftsanwender | Kunde |
| Unterstützt | Berichte & Dashboards | Produktionsanwendungen |
| Beispiele | Absatzprognose Lead-Scoring Kundensegmentierung Abwanderungsprognosen | Produktempfehlungen Betrugserkennung Traffic-Vorhersage Echtzeit-Preisgestaltung |
Merkmale von Analytical ML im Vergleich zu Operational ML
Operational Machine Learning in der Praxis
Schauen wir uns ein konkretes Beispiel für Operational Machine Learning aus der Praxis von Uber Eats an. Wenn Sie die App öffnen, empfiehlt sie eine Liste von Restaurants und gibt eine Prognose dazu, wie lange Sie warten müssen, bis die Bestellung an Ihrer Haustür ankommt. Was in der App einfach aussieht, ist hinter den Kulissen eigentlich ziemlich komplex:
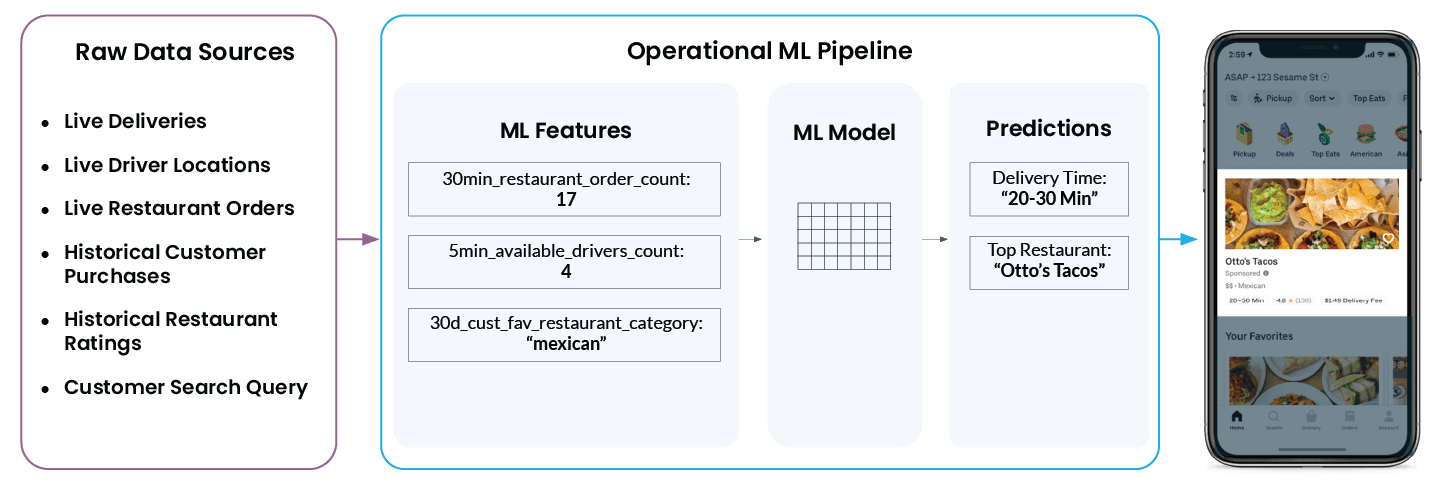
Damit in der App schließlich „Otto’s Tacos“ und „20–30 Min.“ angezeigt werden, muss die ML-Plattform von Uber eine Vielzahl von Daten aus den verschiedensten Rohdatenquellen analysieren:
- Wie viele Fahrer befinden sich jetzt in der Nähe des Restaurants? Liefern sie gerade eine Bestellung aus oder sind sie für den nächsten Auftrag verfügbar?
- Wie ausgelastet ist die Küche des Restaurants gerade? Je mehr Bestellungen ein Restaurant gerade bearbeitet, desto länger wird es dauern, bis es mit der Bearbeitung einer neuen Bestellung starten kann.
- Welche Restaurants hat der Kunde in der Vergangenheit gut und schlecht bewertet?
- Nach welcher Art von Küche sucht der Nutzer gerade aktiv?
- Und ... was ist der aktuelle Standort des Benutzers?
Michelangelos Feature-Plattform wandelt diese Daten in ML-Features um, d. h., in modellrelevante Merkmale. Das sind die Signale, mit denen ein Modell trainiert wird und die es verwendet, um in Echtzeit Vorhersagen zu treffen. Beispielsweise wird ‘num_orders_last_30_min’ als Eingabe-Feature verwendet, um die Lieferzeit vorherzusagen, die schließlich in Ihrer mobilen App angezeigt wird.
Die oben skizzierten Schritte, die Rohdaten aus einer Vielzahl unterschiedlicher Quellen in Features überführen und aus Features Vorhersagen ableiten, sind typisch für Operational Machine Learning. Ob ein System Kreditkartenbetrug erkennt, den Zinssatz für einen Autokredit prognostiziert, einen Zeitungsartikel aus dem Ressort Außenpolitik empfiehlt oder das passende Spielzeug für ein zweijähriges Kind vorschlägt: Die technischen Herausforderungen sind identisch. Und genau diese grundlegende technische Gemeinsamkeit hat es uns ermöglicht, eine zentrale Plattform für alle Use Cases zu schaffen, in denen Operational ML zum Einsatz kommen.
Das Playbook für agentenbasierte KI für Unternehmen

Trends, die Operational Machine Learning ermöglichen
Uber war bestens aufgestellt, um die Vorteile von operationalem ML zu nutzen, da es seinen gesamten Tech-Stack auf einer modernen Datenarchitektur und modernen Prinzipien aufbaute. In den letzten Jahren haben wir eine ähnliche Modernisierung weit außerhalb des Silicon Valley beobachtet:
Historische Daten werden nahezu unbegrenzt aufbewahrt.
Die Kosten für die Datenspeicherung sind in den letzten Jahren drastisch gesunken. Daher konnten Unternehmen Informationen über jeden Touchpoint mit Kunden sammeln, kaufen und speichern. Dies ist für ML von entscheidender Bedeutung – das Training eines guten Modells erfordert eine große Menge an historischen Daten. Und ohne Daten gibt es kein maschinelles Lernen.
Datensilos werden aufgebrochen
Vom ersten Tag an zentralisierte Uber so gut wie alle seine Daten in seinem Hive-basierten verteilten Dateisystem. Zentralisierte Datenspeicherung (oder alternativ zentralisierter Zugriff auf dezentrale Datenspeicher) ist wichtig, da sie es Data Scientists, die ML-Modelle trainieren, ermöglicht, zu wissen, welche Daten verfügbar sind, wo sie zu finden sind und wie sie darauf zugreifen können. Die meisten Unternehmen haben alle ihre Daten (Zugriff) noch nicht vollständig zentralisiert. Architektonische Trends wie The Modern Data Stack haben den Traum des Datenwissenschaftlers vom demokratisierten Datenzugriff jedoch viel näher ins Rampenlicht der Realität gerückt.
Echtzeitdaten werden durch Streaming verfügbar gemacht.
Bei Uber hatten wir das Glück, ein „zentrales Nervensystem“ für Datenströme zu haben: Kafka. Viele Echtzeitsignale von Diensten und mobilen Apps werden über Kafka gestreamt. Für Operational ML ist das entscheidend.
Man kann Betrug nicht erkennen, wenn man nur weiß, was gestern passiert ist. Man muss wissen, was in den letzten 30 Sekunden passiert ist. Data Warehouses und Data Lakes sind für die langfristige Speicherung historischer Daten ausgelegt. Und in den letzten Jahren haben wir eine massive Verbreitung von Streaming-Infrastrukturen wie Kafka oder Kinesis erlebt, um Anwendungen mit Echtzeitsignalen zu versorgen.
MLOps ermöglicht schnelle Iterationen.
Bei Uber konnten einzelne Engineers täglich Änderungen am Produktionssystem vornehmen. Möglich wurde das, weil DevOps-Prinzipien konsequent umgesetzt und automatisiert wurden. Mit Michelangelo haben wir diese Prinzipien auf das Operational ML übertragen – noch bevor der Prozess MLOps genannt wurde 🙂. Es war uns wichtig, dass Data Scientist in der Lage sind, Modelle zu trainieren und sie buchstäblich innerhalb eines Tages sicher in der Produktion bereitzustellen.
Außerhalb von Uber und weit außerhalb des Silicon Valley beobachten wir, wie eine wachsende Zahl von Early Adopters DevOps-Prinzipien und Automatisierung nicht nur in ihre Softwareentwicklung, sondern über MLOps auch in ihre Data-Science-Teams einbringt. Natürlich ist ML für die meisten Unternehmen immer noch viel mühsamer als Software, aus Gründen, die ich in diesem Blog dargelegt habe. Aber ich bin überzeugt, dass die Branche stetig auf eine Zukunft zusteuert, in der der typische Data Scientist in einem typischen Fortune-500-Unternehmen mehrmals täglich an einem operationalen ML-Modell iterieren kann.
So sieht eine moderne Datenarchitektur aus, die Operational ML ermöglicht:
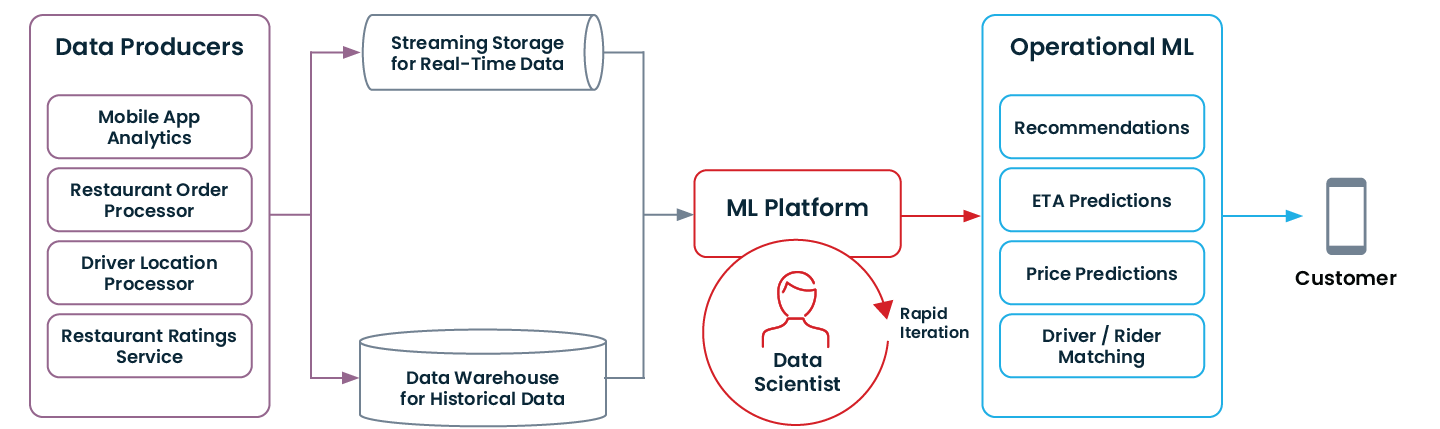
Wenn Ihre Organisation einige der oben genannten Modernisierungen durchlaufen hat (oder von Grund auf damit begonnen hat!), sind Sie möglicherweise bereit, mit operationalem ML zu beginnen.
Erste Schritte mit Operational Machine Leanring
2013 hat Uber noch kein maschinelles Lernen in der Produktion eingesetzt. Heute laufen Zehntausende von Modellen in der Produktion. Diese Veränderung geschah nicht über Nacht.
Wenn Sie die Vorteile von operationalem ML in Ihrem Unternehmen nutzen möchten, empfehle ich die folgenden Schritte:
Wählen Sie einen Anwendungsfall, der für maschinelles Lernen geeignet ist
Nicht alle Probleme können mit ML gelöst werden. Merkmale eines Problems, das sich gut für ML eignen könnte:
- Ihr System trifft viele sehr ähnliche und wiederholte Entscheidungen (mindestens Zehntausende)
- Die richtige Entscheidung zu treffen ist nicht trivial
- Einige Zeit, nachdem die Entscheidung getroffen wurde, gibt es eine Möglichkeit festzustellen, ob es eine gute oder eine schlechte Entscheidung war.
Wenn diese Elemente zutreffen, kann eine Anwendung für maschinelles Lernen Entscheidungen treffen, aus diesen Entscheidungen lernen und sich kontinuierlich verbessern.
Wählen Sie einen Anwendungsfall, der wirklich wichtig ist.
Wie bereits erwähnt, ist der Weg, das erste Modell in die Produktion zu bringen, schwierig. Wenn der zukünftige Nutzen Ihrer ersten Machine-Learning-Anwendung nicht sehr vielversprechend ist, wird es zu einfach sein, aufzugeben, wenn es schwierig wird. Prioritäten werden sich ändern, die Führungsebene wird vielleicht ungeduldig, und die Bemühungen werden nicht von Dauer sein. Wählen Sie einen Anwendungsfall mit hohem Potenzial.
Befähigen Sie ein kleines Team und minimieren Sie die Anzahl der Stakeholder für Ihr erstes Modell.
Die Wahrscheinlichkeit des Scheiterns eines Projekts steigt mit der Anzahl der Übergaben, die beim Training und Anwenden eines Modells erforderlich sind. Im Idealfall starten Sie mit einem sehr kleinen Team von 2–3 Personen, die Zugriff auf alle erforderlichen Daten haben, ein einfaches Modell trainieren können und mit Ihrem Produktions-Stack ausreichend vertraut sind, um eine Anwendung in die Produktion zu überführen.
ML-Ingenieure sind am besten geeignet, den Weg zu ebnen, da sie typischerweise über eine seltene Kombination von Fähigkeiten in den Bereichen Data Engineering, Software Engineering und Data Science verfügen. Dies ist auch die Art und Weise, wie Sie Machine-Learning-Teams skalieren sollten, mit kleinen Gruppen von ML-Experten, die in Produktteams eingebettet sind.
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.