Referenzarchitektur für die versicherungsmathematische Modellierung in der Versicherungsbranche
Diese Architektur zeigt, wie Versicherer eine 360-Grad-Sicht auf Daten für effektive Analysen und Szenariotests erstellen können, was zu genauen Modellen für den Einsatz in Geschäftsfunktionen, insbesondere im Underwriting, führt.
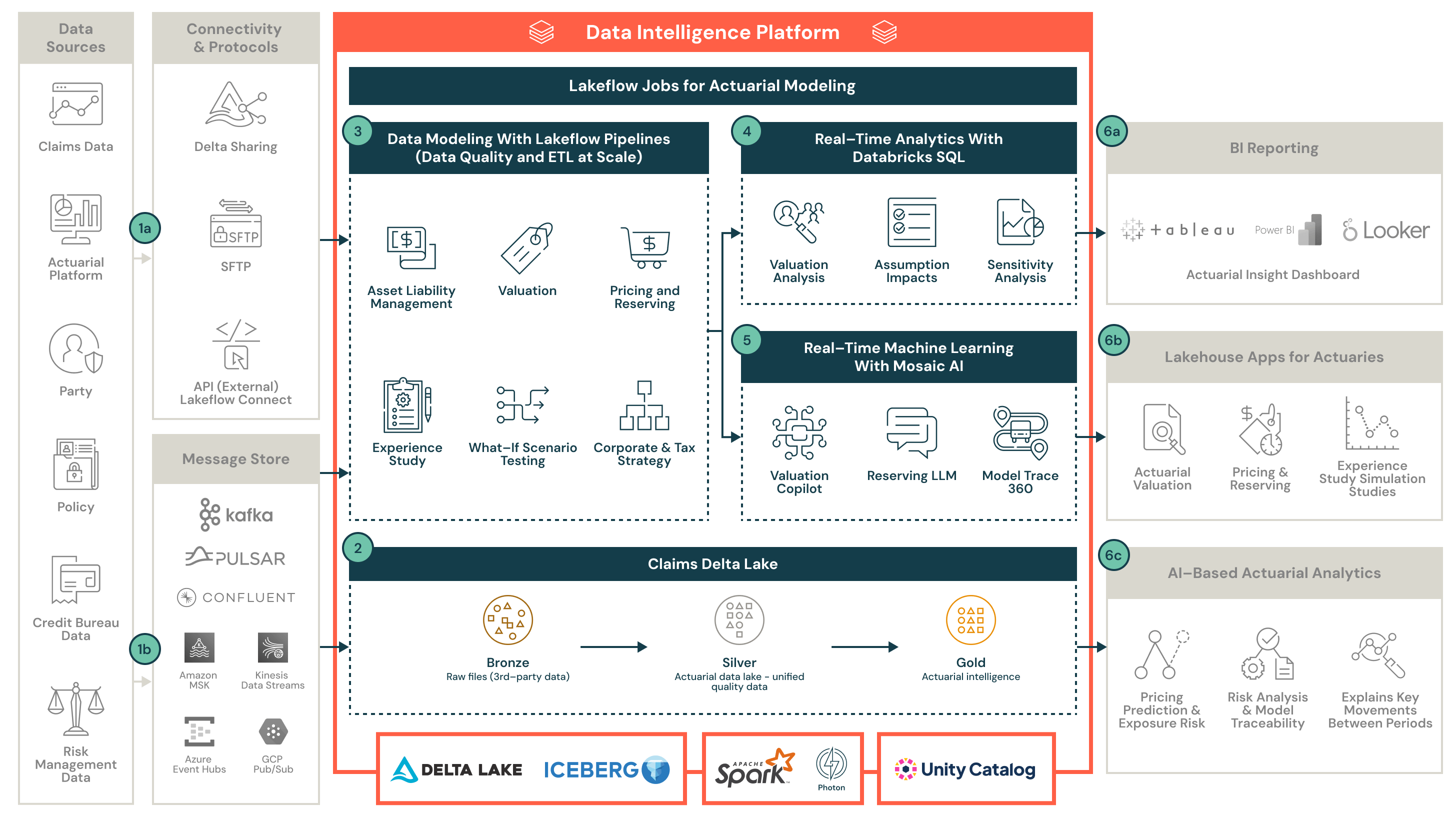
Datenflüsse
Nachfolgend werden die Datenflüsse beschrieben, die im Architekturdiagramm für die versicherungsmathematische Modellierung dargestellt sind:
- Erfassen Sie mithilfe von Lakeflow Connect und Auto Loader Daten zu Verträgen, Schadenfällen, versicherungsmathematischen Prognosen und Szenarien als Rohdaten (Bronze Layer).
- Triggern Sie automatisch Lakeflow Jobs mit Transformationspipelines — gewinnen Sie durch Datenanreicherung in Spark analytische Einblicke, um die Silver- und Gold-Layers zu befüllen.
- Analysieren Sie Einblicke interaktiv in AI/BI-Dashboards oder durch Interaktion in natürlicher Sprache in einem Genie Raum. Klären Sie etwaige Diskrepanzen durch die Nachverfolgung der Datenherkunft (Lineage) in Unity Catalog.
- Wenden Sie notwendige Überschreibungen mit einer Task-spezifischen, benutzerdefinierten UI an, die in Databricks Apps erstellt wurde.
- Stellen Sie analytische Artefakte und Ergebnisse über Databricks SQL für Berichtssysteme, einschließlich des Hauptbuchs, bereit.
- Optional: Teilen Sie Ergebnisse sicher mit externen Parteien wie Rückversicherern oder Muttergesellschaften.
Vorteile
Die Verwendung der Databricks Platform für die Referenzarchitektur zur versicherungsmathematischen Modellierung bietet folgende Vorteile:
- Etablierung einer Best-Practice-Architektur für Anwendungsfälle in der versicherungsmathematischen Modellierung
- Erkenntnisse über KI-Lösungen für 360-Grad-Kundendaten und wie diese Databricks als Branchenführer differenzieren

