Conseils et perspectives pour la mise en œuvre d'un modèle de data vault sur la plateforme lakehouse Databricks
par Soham Bhatt, Tanveer Shaikh et Glenn Wiebe
Il existe de nombreux modèles de données que vous pouvez utiliser lors de la conception d'un système analytique, tels que les modèles de domaine spécifiques à un secteur d'activité et les méthodologies Kimball, Inmon et Data Vault. En fonction de vos besoins spécifiques, vous pouvez utiliser ces différentes techniques de modélisation lors de la conception d'un lakehouse. Ils ont tous leurs points forts, et chacun peut être adapté à différents cas d'usage.
Finalement, un modèle de données n'est rien de plus qu'une construction définissant différentes tables avec des relations un-à-un, un-à-plusieurs et plusieurs-à-plusieurs définies. Les plateformes de données doivent fournir les meilleures pratiques pour physicaliser le modèle de données, afin de faciliter la récupération des informations et d'améliorer les performances.
Dans un article précédent, nous avons abordé cinq étapes simples pour mettre en œuvre un schéma en étoile dans Databricks avec Delta Lake. Dans cet article, nous allons expliquer ce qu'est un Data Vault, comment l'implémenter au sein de la couche Bronze/Silver/Gold et comment obtenir les meilleures performances de Data Vault avec la plateforme Databricks Lakehouse.
Modélisation de la voûte de données, définie
L'objectif de la modélisation Data Vault est de s'adapter aux exigences métier qui évoluent rapidement et de prendre en charge par conception un développement plus rapide et agile des data warehouses. Un Data Vault est bien adapté à la méthodologie lakehouse, car le modèle de données est facilement extensible et granulaire grâce à sa conception en hub, lien et satellite, ce qui facilite la mise en œuvre des changements de conception et d'ETL.
Comprenons quelques éléments de base d'un Data Vault. En général, un modèle Data Vault comporte trois types d'entités :
- Hubs — Un hub représente une entité commerciale principale, telle que les clients, les produits, les commandes, etc. Les analystes utiliseront les clés naturelles/métier pour obtenir des informations sur un Hub. La clé primaire des tables Hub est généralement dérivée d'une combinaison de l'ID du concept métier, de la date de chargement et d'autres métadonnées.
- Liens : les liens représentent les relations entre les centres. Il ne contient que les clés de jointure. C'est comme une table de faits sans faits dans le modèle dimensionnel. Aucun attribut - uniquement des clés de jointure.
- Satellites — Les tables Satellite contiennent les attributs des entités du Hub ou des Links. Elles contiennent des informations descriptives sur les entités métier principales. Elles sont similaires à une version normalisée d'une table de dimension. Par exemple, un hub client peut avoir de nombreuses tables satellites telles que les attributs géographiques du client, le score de crédit du client, les niveaux de fidélité du client, etc.
L'un des principaux avantages de la méthodologie Data Vault est que les Jobs ETL existants nécessitent beaucoup moins de refactorisation lorsque le modèle de données change. Data Vault est un style de modélisation « optimisé pour l'écriture » qui prend en charge les approches de développement agiles et convient parfaitement à l'approche des data lakes et des lakehouses.
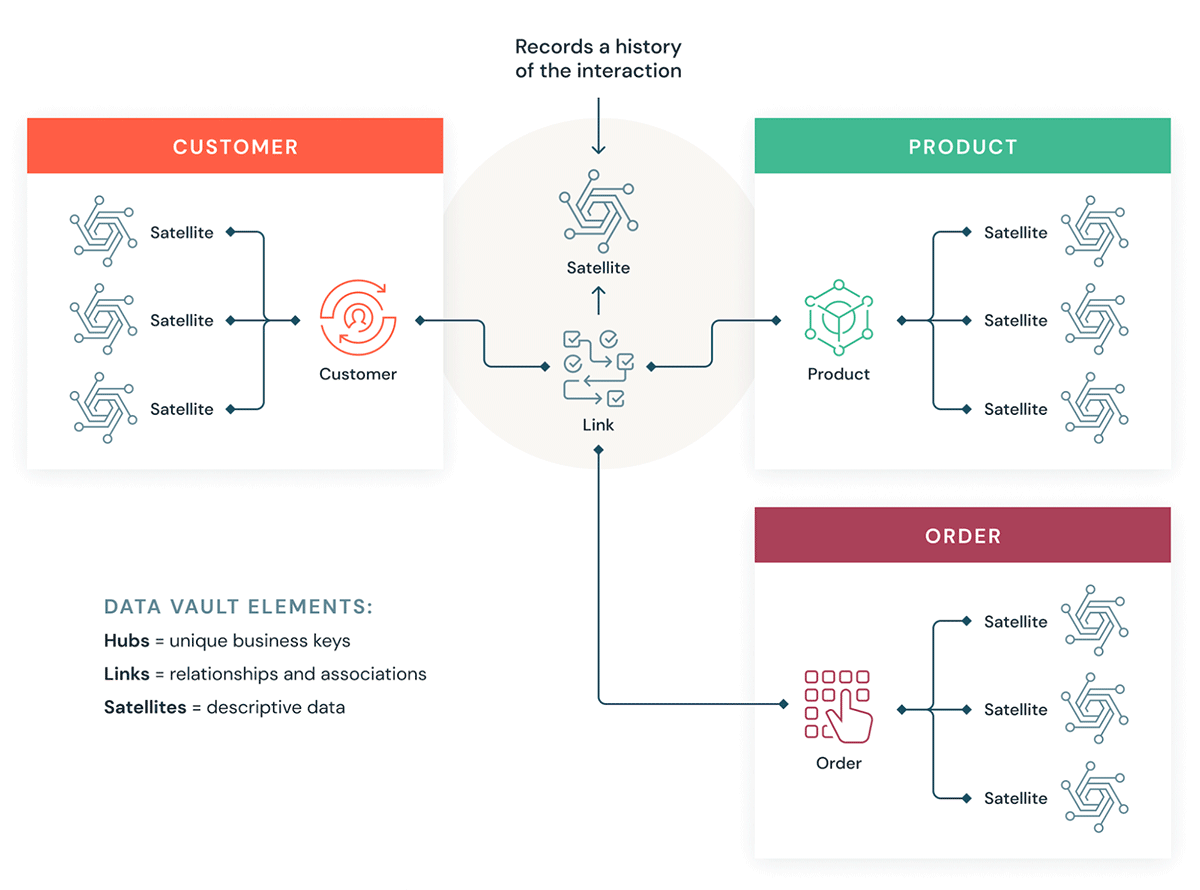
Comment Data Vault s'intègre dans un Lakehouse
Voyons comment certains de nos clients utilisent la modélisation Data Vault dans une architecture Databricks Lakehouse :
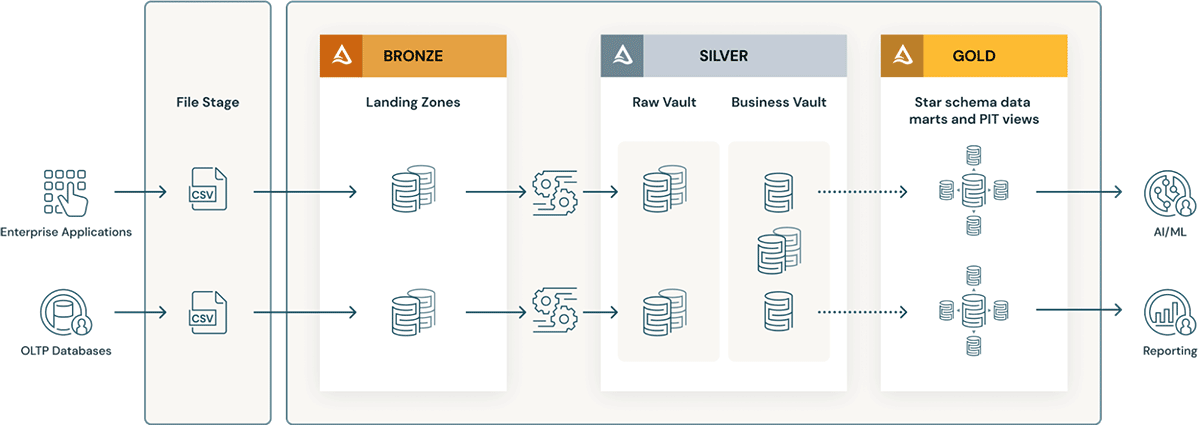
Considérations pour implémenter un modèle Data Vault dans le Lakehouse Databricks
- La modélisation Data Vault recommande d'utiliser un hachage des clés métier comme clés primaires. Databricks prend en charge nativement les fonctions hash, md5 et SHA pour les clés métier.
- Les couches Data Vault intègrent le concept de landing zone (et parfois de staging zone). Ces deux couches physiques s'intègrent naturellement dans la couche Bronze du data lakehouse. Si les données de la landing zone arrivent dans des formats tels qu'Avro, CSV, Parquet, XML, JSON, elles sont converties en tables au format Delta dans la zone de staging, afin que l'ETL ultérieur puisse être très performant.
- Le Raw Vault est créé à partir de la zone d'atterrissage ou de transit. Les données sont modélisées sous forme de tables Hub, Link et Satellite dans le Raw Data Vault. Des règles ETL "métier" supplémentaires ne sont généralement pas appliquées lors du chargement du Vault de données brutes.
- Toutes les règles commerciales ETL, les règles de qualité des données, les règles de nettoyage et de conformité sont appliquées entre Raw et Business Vault. Les tables de Business Vault peuvent être organisées par domaines de données - qui servent de repository central à l'entreprise "" de données normalisées et nettoyées. Les data stewards et les PME sont responsables de la gouvernance, de la qualité des données et des règles de gestion concernant leurs domaines du Business Vault.
- Des tables d'aide à la query telles que les tables Point-in-Time (PIT) et les tables Bridge sont créées pour la couche de présentation par-dessus le business vault. Les tables PIT amélioreront les performances des requêtes, car certains satellites et hubs sont pré-joints et fournissent des conditions WHERE avec un filtrage "point in time". Les tables de pont pré-joignent les hubs ou les entités pour fournir une table dimensionnelle aplatie "" comme les vues pour les entités. Les Delta Live Tables sont exactement comme des vues matérialisées et peuvent être utilisées pour créer des tables Point-in-Time ainsi que des tables de pont dans la couche Gold/de présentation par-dessus le Business Data Vault.
- Au fur et à mesure que les processus commerciaux changent et s'adaptent, le modèle Data Vault peut être facilement étendu sans remaniement massif comme les modèles dimensionnels. Des hubs supplémentaires (domaines) peuvent être facilement ajoutés aux Links (tables de jointure pures) et des satellites supplémentaires (par ex. segmentations de clients) peuvent être ajoutées à un Hub (client) avec des changements minimes.
- De plus, le chargement d'un data warehouse de modèle dimensionnel dans la couche Gold devient plus facile pour les raisons suivantes :
- Les hubs facilitent la gestion des clés (les clés naturelles des hubs peuvent être converties en clés de substitution via des colonnes d'identité).
- Les satellites facilitent le chargement des dimensions, car ils contiennent tous les attributs.
- Les tables Link simplifient considérablement le chargement des tables de faits, car elles contiennent toutes les relations.
Conseils pour obtenir les meilleures performances d'un modèle Data Vault dans le Lakehouse Databricks
- Utilisez des tables au format Delta pour les tables Raw Vault, Business Vault et de la couche Gold.
- Assurez-vous d'utiliser des index OPTIMIZE et Z-order sur toutes les clés de jointure des tables Hub, Link et Satellite.
- Ne sur-partitionnez pas les tables, en particulier les tables satellites plus petites. Utilisez l'indexation par filtre de Bloom sur les colonnes de date, d'indicateur actuel et de prédicat qui sont généralement filtrées pour garantir des performances optimales, en particulier si vous devez créer des index supplémentaires en dehors de l'ordre Z.
- Delta Live Tables (vues matérialisées) facilite grandement la création et la gestion des tables PIT.
- Réduisez la valeur de
optimize.maxFileSizeà un nombre inférieur, par exemple 32-64 Mo au lieu de la valeur par défaut de 1 Go. En créant des fichiers plus petits, vous pouvez bénéficier de l'élagage des fichiers et minimiser les I/O pour récupérer les données que vous devez joindre. - Le modèle Data Vault comporte comparativement plus de jointures. Utilisez donc la dernière version de DBR, qui garantit que l'exécution adaptative des requêtes (Adaptive Query Execution) est activée par défaut afin que la meilleure stratégie de jointure soit automatiquement utilisée. Utilisez les indications de jointure uniquement si nécessaire. (pour l'optimisation avancée des performances).
En savoir plus sur la modélisation Data Vault sur le site de Data Vault Alliance.
Commencez à créer votre Data Vault dans le Lakehouse
Essayez gratuitement Databricks pendant 14 jours
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.