Ingénierie des données agentive avec Genie Code et Lakeflow
Genie Code rationalise le développement, l'orchestration et le déploiement de pipelines de données
par Gal Oshri, Camiel Steenstra, Lennart Kats et Joanna Zouhour
- Genie Code est un partenaire IA autonome conçu spécifiquement pour les données
- Les ingénieurs de données peuvent utiliser Genie Code directement dans Lakeflow, de la construction de pipelines dans l'éditeur de pipelines à l'orchestration des flux de travail dans les jobs Lakeflow
- Genie Code prend en charge le cycle de vie complet de l'ingénierie des données - du développement et de l'orchestration à la surveillance et au débogage - au sein d'une seule expérience d'agent
Avec Genie Code, les ingénieurs de données peuvent utiliser le langage naturel pour générer des pipelines de données prêts pour la production, les orchestrer avec des jobs, et déboguer les échecs. Les tâches qui prenaient des semaines - trouver des données, construire des transformations, assembler des jobs, et corriger les échecs - peuvent maintenant être faites en quelques heures, tout en restant alignées avec les normes de gouvernance et opérationnelles.
Ci-dessous, nous allons expliquer comment cela fonctionne en pratique : découverte des données, construction des pipelines, orchestration des jobs, et débogage des échecs, le tout à partir d'une seule conversation.
Construisez et orchestrez des pipelines et des jobs complets, prêts pour la production, en utilisant le langage naturel
Genie Code peut maintenant vous emmener de l'exploration aux pipelines et jobs planifiés en un seul fil, vous aidant à les créer et à les exploiter de bout en bout.
Il accélère le développement des pipelines déclaratifs Spark Lakeflow et simplifie la manière dont les pipelines et les notebooks sont orchestrés et exécutés via les jobs Lakeflow. Genie Code comprend le contexte de votre pipeline et de vos jobs, accédant au code, à la configuration et aux résultats d'exécution.
Genie Code aide à travers les étapes clés du cycle de vie de l'ingénierie des données :
- Recherchez parmi les actifs de données, pas seulement le code : Genie Code utilise la popularité, la lignée, les exemples de code et les métadonnées d'Unity Catalog pour identifier les jeux de données les plus pertinents pour votre tâche. Par exemple, vous pouvez demander à Genie Code d'expliquer comment les tables sont liées ou de retracer le flux des données à travers un pipeline. Chez SiriusXM, les équipes utilisent Genie Code pour comprendre plus rapidement les relations entre les tables.
- Construisez et modifiez des pipelines : Commencez par décrire le pipeline que vous souhaitez en langage naturel, comme un pipeline de détection de fraude construit sur une architecture médaillon. Genie Code génère un pipeline déclaratif Spark avec des couches Bronze, Silver et Gold, y compris les sources, les transformations, les attentes de qualité des données et les sorties. À partir de là, vous pouvez demander des modifications, examiner les différences proposées, et exécuter et tester le pipeline.
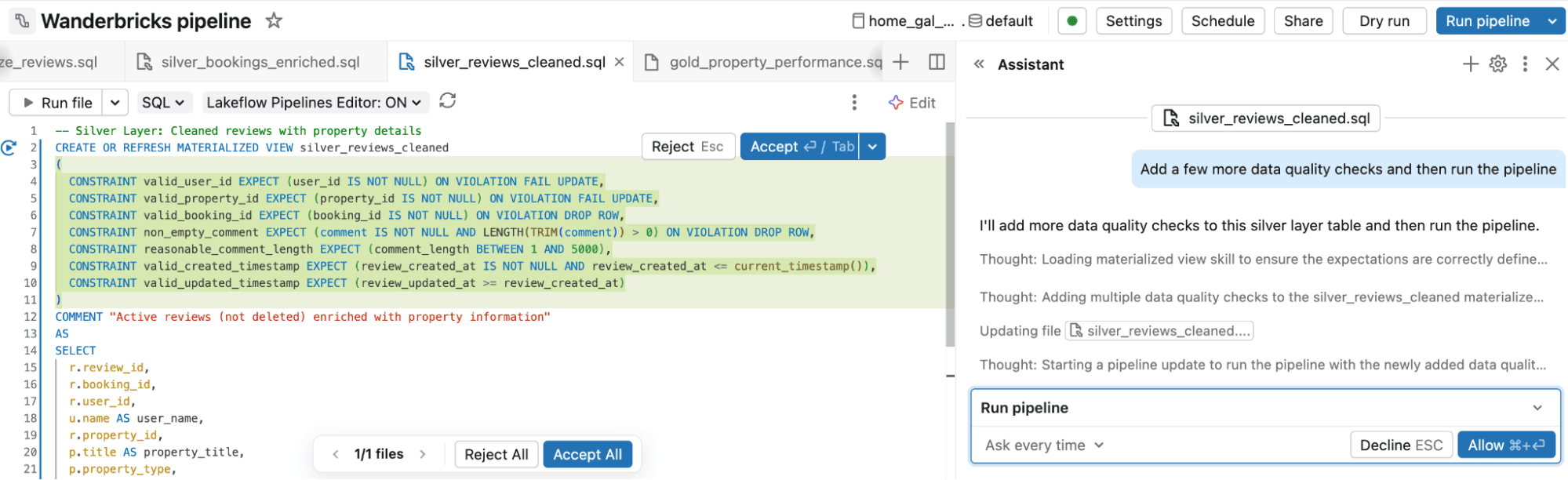
- Définissez et orchestrez des jobs : Pas besoin de définir et de maintenir manuellement la logique d'orchestration. Vous décrivez le job que vous souhaitez, y compris les tâches, les dépendances et le calendrier. Genie Code le configure pour vous, puis vous aide à modifier, déboguer et corriger les problèmes d'orchestration en langage naturel.
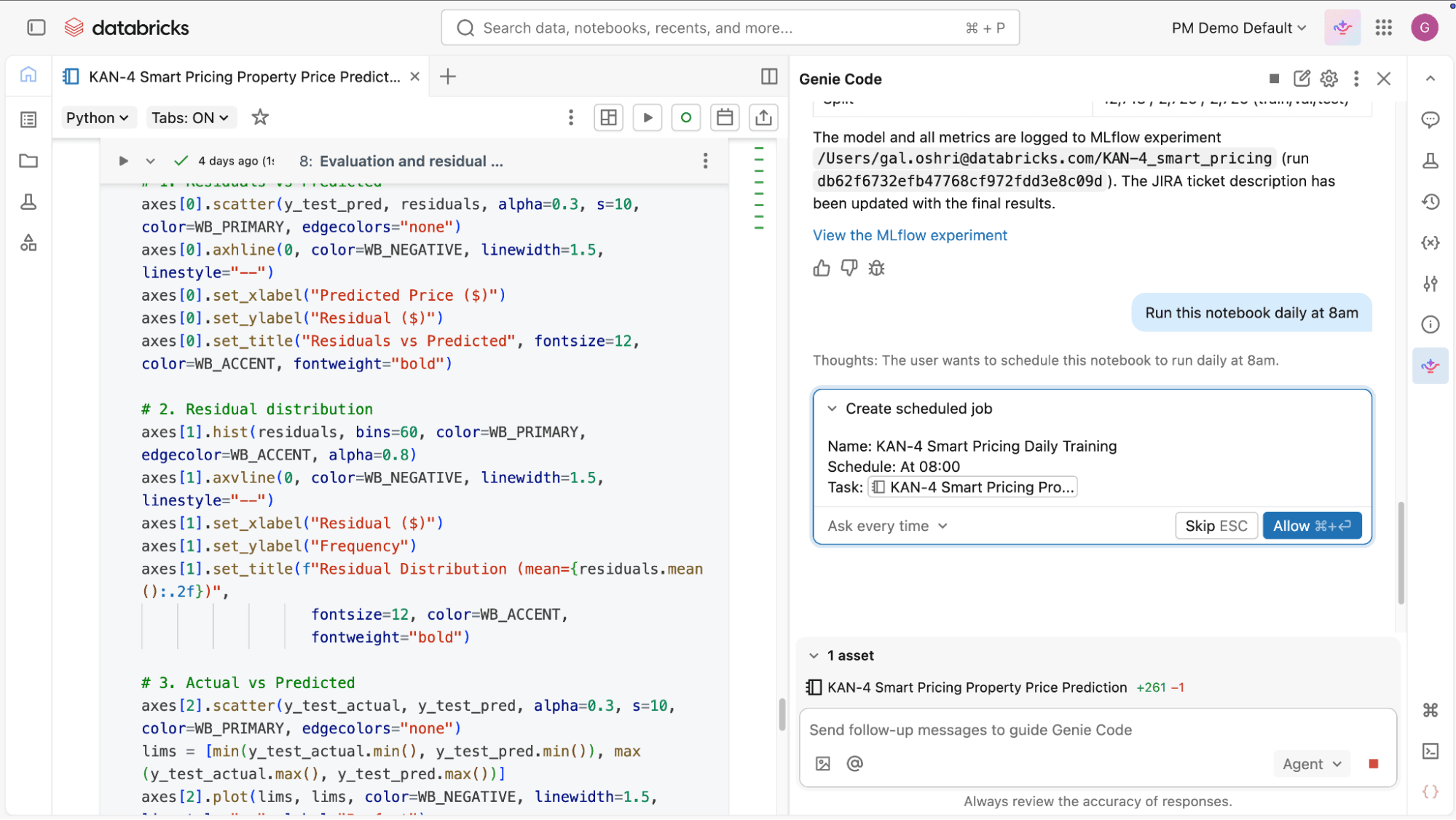
- Étendez et faites évoluer les flux de travail existants : À mesure que les exigences changent, Genie Code vous aide à mettre à jour les pipelines et les jobs avec de nouveaux jeux de données et transformations. Il comprend la structure actuelle et les résultats de vos pipelines, et peut les étendre en écrivant des flux AutoCDC pour la capture des données modifiées, en configurant Auto Loader, en appliquant des attentes de qualité des données, et en suivant l'architecture médaillon.
- Adoptez les meilleures pratiques avec les Declarative Automation Bundles (DABs) : Genie Code peut travailler directement dans vos projets DABs existants : ajout de ressources, mise à jour de configurations, validation de bundles, et déploiement vers vos cibles. Ainsi, vous pouvez adopter les meilleures pratiques d'ingénierie logicielle comme le contrôle de source, les tests, et le CI/CD pour vos projets de données sans écrire manuellement du YAML.
- Travaillez plus vite sans baisser les standards : Ces capacités réduisent l'effort manuel tout en maintenant les flux de travail alignés avec les exigences de l'entreprise. Les pipelines restent gouvernés par Unity Catalog et suivent les modèles établis pour la performance et la qualité des données, tandis que les jobs héritent d'une configuration cohérente pour la planification, les nouvelles tentatives et les dépendances. Les ingénieurs de données gardent le contrôle, mais passent moins de temps sur le travail répétitif.
Surveillez, diagnostiquez et déboguez les pipelines et les jobs
- Comprendre et améliorer le comportement des pipelines : Genie Code peut inspecter les jeux de données et les sorties des pipelines pour vous aider à comprendre un pipeline de bout en bout. Par exemple, il peut résumer les transformations, retracer comment les données affluent vers les tables en aval, et mettre en évidence les changements inattendus dans les nombres de lignes ou les schémas.
- Débogage et diagnostic des échecs de jobs et de pipelines : Lorsqu'un pipeline ou un job échoue, Genie Code vous aide à résoudre le problème. Il analyse les erreurs, propose des mises à jour dans les fichiers pertinents, et vous montre les différences avant d'appliquer des changements. Vous pouvez examiner chaque mise à jour et décider de ce qui doit avancer. Cela transforme de longs cycles de débogage manuels en itérations guidées plus rapides.
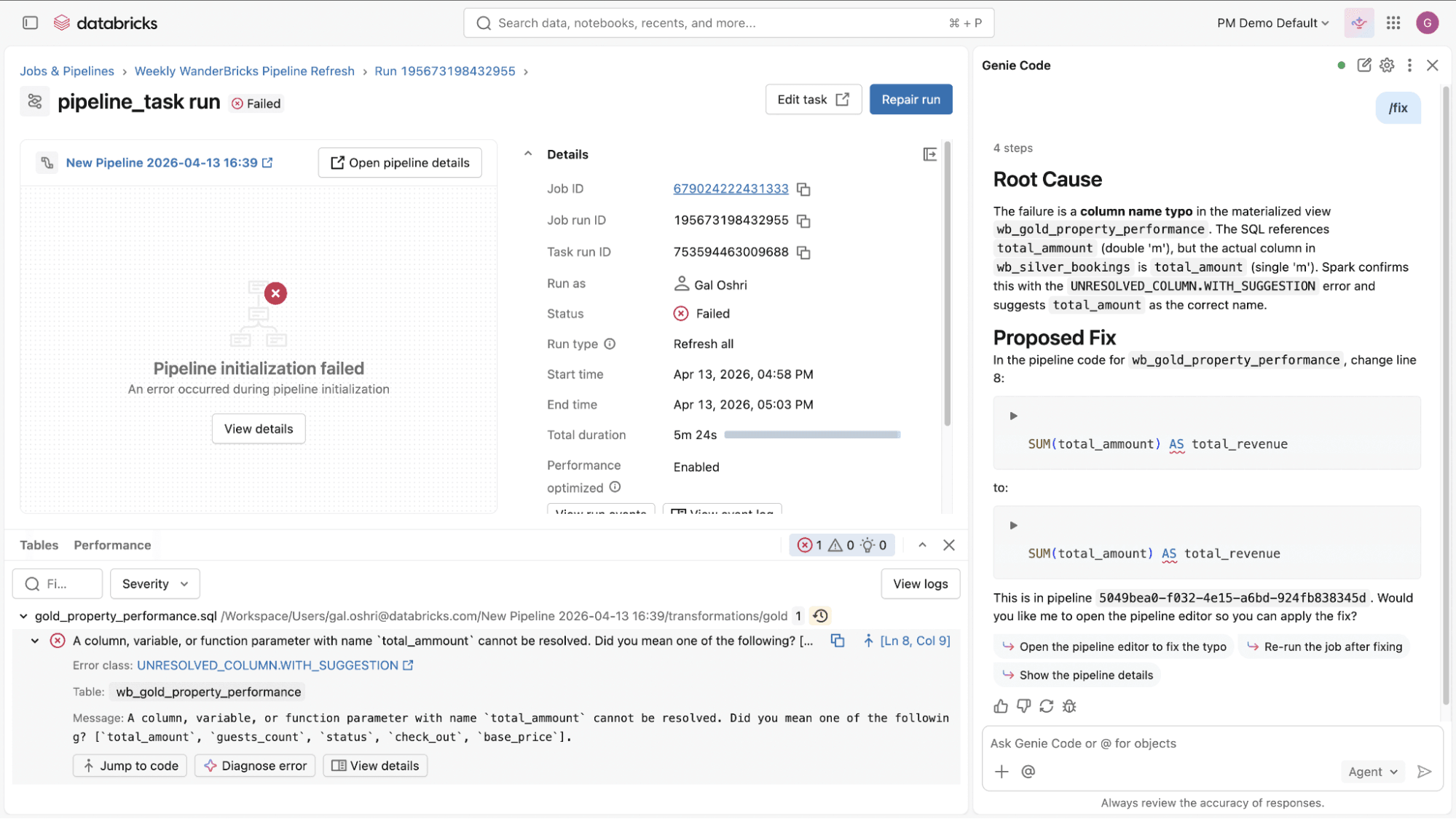
- Étendez et personnalisez Genie Code : Genie Code n'est pas limité aux capacités intégrées. Les équipes peuvent l'étendre avec des instructions personnalisées, des compétences d'agent et intégrer des systèmes externes via des serveurs MCP, permettant à Genie Code d'opérer sur une logique spécifique au domaine, des outils internes et des flux de travail personnalisés. Cela garantit que Genie Code s'adapte à votre environnement et à vos connaissances du domaine.
Prochaines étapes
D'autres capacités arrivent pour étendre Genie Code à travers les pipelines, les jobs, et la plateforme plus large. Une fonctionnalité passionnante à l'horizon est les charges de travail optimisées par l'IA. À l'avenir, vous pourrez également laisser Genie Code s'exécuter en arrière-plan pour maintenir votre plateforme en fonctionnement efficace, afin que vous puissiez déléguer ces tâches répétitives et chronophages. Cela inclut la réponse aux échecs de jobs et la gestion des mises à niveau de routine, mais aussi l'ajustement automatique de l'utilisation des clusters.
Curieux d'en savoir plus sur ces mises à jour et les meilleures pratiques ? Assurez-vous de vous inscrire au Data+AI Summit où nous avons des centaines de sessions couvrant Genie Code, Lakeflow et bien plus encore !
Essayez les capacités d'ingénierie des données de Genie Code
Ouvrez Genie Code en mode agent et demandez-lui de vous aider à construire ou mettre à jour vos pipelines et jobs. Consultez la démonstration pour plus de détails.
Consultez la documentation pour en savoir plus.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.