Annonce de la disponibilité générale de Databricks Lakeflow
L'approche unifiée de l'ingénierie des données pour l'ingestion, la transformation et l'orchestration
par Bilal Aslam et Michael Armbrust
- Databricks Lakeflow résout les défis d'ingénierie des données posés par des piles fragmentées en offrant une solution unifiée pour l'ingestion, la transformation et l'orchestration sur la plateforme d'intelligence des données.
- Lakeflow Connect ajoute plus de connecteurs aux bases de données, aux sources de fichiers, aux applications d'entreprise et aux entrepôts de données. Zerobus introduit des écritures directes à haut débit avec une faible latence.
- Lakeflow Declarative Pipelines, construit sur la nouvelle norme ouverte Spark Declarative Pipelines, propose un nouvel IDE pour les ingénieurs de données afin d'améliorer le développement de pipelines ETL.
Nous sommes ravis d'annoncer que Lakeflow, la solution unifiée d'ingénierie des données de Databricks, est maintenant disponible en général. Elle comprend des connecteurs d'ingestion étendus pour les sources de données populaires, un nouveau « IDE pour l'ingénierie des données » qui facilite la création et le débogage des pipelines de données, ainsi que des capacités étendues pour l'opérationnalisation et la surveillance de l'ETL.
Lors du Data + AI Summit de l'année dernière, nous avons présenté Lakeflow – notre vision de l'avenir de l'ingénierie des données – une solution de bout en bout qui comprend trois composants principaux :
- Lakeflow Connect : Ingestion fiable et gérée à partir d'applications d'entreprise, de bases de données, de systèmes de fichiers et de flux en temps réel, sans la surcharge des connecteurs personnalisés ou des services externes.
- Lakeflow Declarative Pipelines : Pipelines ETL évolutifs construits sur la norme ouverte Spark Declarative Pipelines, intégrés à la gouvernance et à l'observabilité, et offrant une expérience de développement rationalisée grâce à un « IDE moderne pour l'ingénierie des données ».
- Lakeflow Jobs : Orchestration native pour la Data Intelligence Platform, prenant en charge le flux de contrôle avancé, les déclencheurs de données en temps réel et la surveillance compl�ète.
En unifiant l'ingénierie des données, Lakeflow élimine la complexité et le coût de l'assemblage de différents outils, permettant aux équipes de données de se concentrer sur la création de valeur pour l'entreprise. Lakeflow Designer, le nouveau constructeur visuel de pipelines alimenté par l'IA, permet à tout utilisateur de créer des pipelines de données de qualité production sans écrire de code.
Ce fut une année chargée, et nous sommes très heureux de partager les nouveautés à l'occasion de la disponibilité générale de Lakeflow.
Les équipes d'ingénierie des données peinent à suivre les besoins en données de leur organisation
Dans tous les secteurs, la capacité d'une entreprise à extraire de la valeur de ses données grâce à l'analyse et à l'IA constitue son avantage concurrentiel. Les données sont utilisées dans toutes les facettes de l'organisation – pour créer des vues Client 360° et de nouvelles expériences client, pour permettre de nouvelles sources de revenus, pour optimiser les opérations et pour responsabiliser les employés. Lorsque les organisations cherchent à utiliser leurs propres données, elles se retrouvent avec un patchwork d'outils. Les ingénieurs de données ont du mal à s'attaquer à la complexité des tâches d'ingénierie des données tout en naviguant dans des piles d'outils fragmentées qui sont pénibles à intégrer et coûteuses à maintenir.
Un défi clé est la gouvernance des données – les outils fragmentés rendent difficile l'application des normes, entraînant des lacunes dans la découverte, la lignée et l'observabilité. Une récente étude de The Economist a révélé que « la moitié des ingénieurs de données déclarent que la gouvernance prend plus de temps que tout le reste ». La même enquête a demandé aux ingénieurs de données quelles seraient les interventions les plus bénéfiques pour leur productivité, et ils ont identifié « simplifier les connexions aux sources de données pour l'ingestion des données », « utiliser une solution unifiée unique au lieu de plusieurs outils » et « une meilleure visibilité des pipelines de données pour trouver et corriger les problèmes » parmi les principales interventions.
Une solution unifiée d'ingénierie des données intégrée à la Data Intelligence Platform
Lakeflow aide les équipes de données à relever ces défis en fournissant une solution d'ingénierie des données de bout en bout sur la Data Intelligence Platform. Les clients Databricks peuvent utiliser Lakeflow pour tous les aspects de l'ingénierie des données – ingestion, transformation et orchestration. Comme toutes ces capacités sont disponibles dans le cadre d'une solution unique, il n'y a pas de temps perdu sur des intégrations d'outils complexes ni de coûts supplémentaires pour licencier des outils externes.
De plus, Lakeflow est intégré à la Data Intelligence Platform, ce qui permet des méthodes cohérentes pour déployer, gouverner et observer tous les cas d'utilisation des données et de l'IA. Par exemple, pour la gouvernance, Lakeflow s'intègre à Unity Catalog, la solution de gouvernance unifiée pour la Data Intelligence Platform. Grâce à Unity Catalog, les ingénieurs de données obtiennent une visibilité et un contrôle complets sur chaque partie du pipeline de données, ce qui leur permet de comprendre facilement où les données sont utilisées et de trouver la cause première des problèmes lorsqu'ils surviennent.
Qu'il s'agisse de versionner du code, de déployer des pipelines CI/CD, de sécuriser des données ou d'observer des métriques opérationnelles en temps réel, Lakeflow exploite la Data Intelligence Platform pour fournir un lieu unique et cohérent afin de gérer les besoins d'ingénierie des données de bout en bout.
Lakeflow Connect : Plus de connecteurs et des écritures directes rapides vers Unity Catalog
Au cours de la dernière année, nous avons constaté une forte adoption de Lakeflow Connect, avec plus de 2 000 clients utilisant nos connecteurs d'ingestion pour débloquer la valeur de leurs données. Un exemple est Porsche Holding Salzburg qui constate déjà les avantages de l'utilisation de Lakeflow Connect pour unifier ses données CRM avec l'analyse afin d'améliorer l'expérience client.
« L'utilisation du connecteur Salesforce de Lakeflow Connect nous aide à combler une lacune critique pour Porsche du côté commercial en termes de facilité d'utilisation et de prix. Du côté client, nous sommes en mesure de créer une expérience client entièrement nouvelle qui renforce le lien entre Porsche et le client avec un parcours client unifié et non fragmenté. » —Lucas Salzburger, chef de projet, Porsche Holding Salzburg
Aujourd'hui, nous élargissons la gamme de sources de données prises en charge avec davantage de connecteurs intégrés pour une ingestion simple et fiable. Les connecteurs de Lakeflow sont optimisés pour une extraction de données efficace, y compris l'utilisation de méthodes de capture de données modifiées (CDC) personnalisées pour chaque source de données respective.
Ces connecteurs gérés couvrent désormais les applications d'entreprise, les sources de fichiers, les bases de données et les entrepôts de données, et sont déployés dans différents états de publication :
- Applications d'entreprise : Salesforce, Workday, ServiceNow, Google Analytics, Microsoft Dynamics 365, Oracle NetSuite
- Sources de fichiers : SFTP, SharePoint
- Bases de données : Microsoft SQL Server, Oracle Database, MySQL, PostgreSQL
- Entrepôts de données : Snowflake, Amazon Redshift, Google BigQuery
De plus, un cas d'utilisation courant que nous constatons chez les clients est l'ingestion de données d'événements en temps réel, généralement avec une infrastructure de bus de messages hébergée en dehors de leur plateforme de données. Pour simplifier ce cas d'utilisation sur Databricks, nous annonçons Zerobus, une API Lakeflow Connect qui permet aux développeurs d'écrire des données d'événements directement dans leur lakehouse à très haut débit (100 Mo/s) avec une latence quasi en temps réel (<5 secondes). Cette infrastructure d'ingestion rationalisée offre des performances à grande échelle et est unifiée avec la Databricks Platform afin que vous puissiez immédiatement tirer parti d'outils d'analyse et d'IA plus larges.
« Joby est en mesure d'utiliser nos agents de fabrication avec Zerobus pour envoyer des gigaoctets de données de télémétrie par minute directement dans notre lakehouse, accélérant ainsi le temps de compréhension – le tout avec Databricks Lakeflow et la Data Intelligence Platform. » —Dominik Müller, responsable des systèmes d'usine, Joby Aviation Inc.
Lakeflow Declarative Pipelines : Développement ETL accéléré basé sur des normes ouvertes
Après des années d'exploitation et d'évolution de DLT avec des milliers de clients sur des pétaoctets de données, nous avons tiré parti de tout ce que nous avons appris pour créer une nouvelle norme ouverte : Spark Declarative Pipelines. C'est la prochaine évolution du développement de pipelines – déclaratif, évolutif et ouvert.
Et aujourd'hui, nous sommes ravis d'annoncer la disponibilité générale de Lakeflow Declarative Pipelines, apportant la puissance de Spark Declarative Pipelines à la Databricks Data Intelligence Platform. Il est 100 % compatible source avec la norme ouverte, vous pouvez donc développer des pipelines une fois et les exécuter n'importe où. Il est également 100 % rétrocompatible avec les pipelines DLT, de sorte que les utilisateurs existants peuvent adopter les nouvelles fonctionnalités sans réécrire quoi que ce soit. Lakeflow Declarative Pipelines est une expérience entièrement gérée sur Databricks : une informatique sans serveur sans intervention, une intégration approfondie avec Unity Catalog pour une gouvernance unifiée et un **IDE pour l'ingénierie des données** spécialement conçu.
Le nouvel IDE pour l'ingénierie des données est un environnement moderne et intégré conçu pour rationaliser l'expérience de développement de pipelines. Il comprend :
- Code et DAG côte à côte, avec visualisation des dépendances et aperçus de données instantanés
- Débogage contextuel qui affiche les problèmes en ligne
- Intégration Git intégrée pour un développement rapide
- Création et configuration assistées par IA
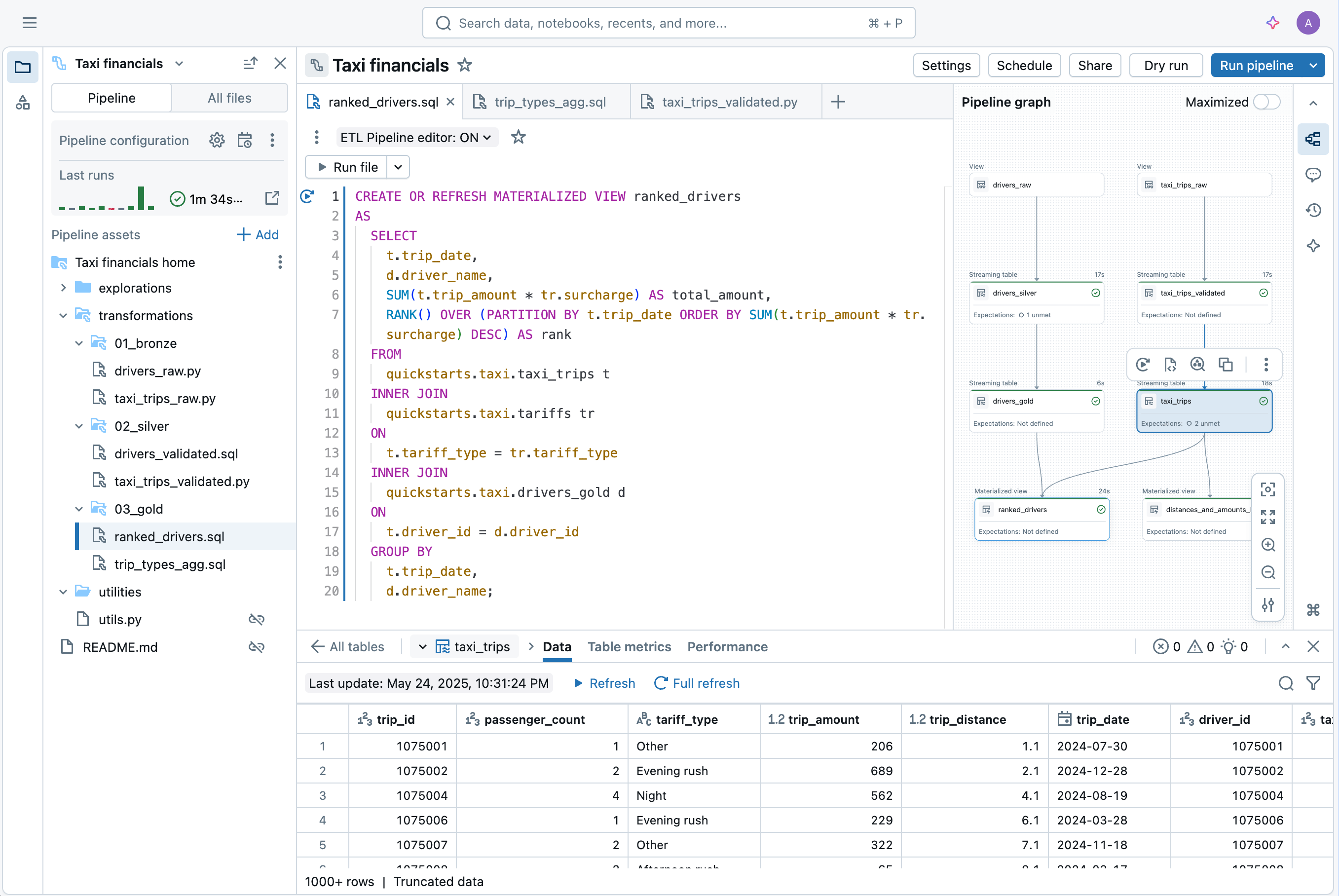
“Le nouvel éditeur rassemble tout en un seul endroit : le code, le graphe du pipeline, les résultats, la configuration et le dépannage. Fini le jonglage entre les onglets du navigateur ou la perte de contexte. Le développement semble plus ciblé et efficace. Je peux voir directement l'impact de chaque modification de code. Un clic me mène à la ligne d'erreur exacte, ce qui accélère le débogage. Tout est connecté : le code aux données ; les tables au code. Changer de pipeline est facile, et des fonctionnalités comme les dossiers utilitaires auto-configurés éliminent la complexité. C'est comme ça que le développement de pipeline devrait fonctionner.” —Chris Sharratt, Ingénieur de données, Rolls-Royce
Les pipelines déclaratifs Lakeflow sont désormais la manière unifiée de construire des pipelines évolutifs, gouvernés et continuellement optimisés sur Databricks - que vous travailliez dans le code ou visuellement via le Lakeflow Designer, une nouvelle expérience sans code qui permet aux praticiens de données de tout niveau technique de construire des pipelines de données fiables.
Jobs Lakeflow : Orchestration fiable pour toutes les charges de travail avec une observabilité unifiée
Databricks Workflows est depuis longtemps un outil de confiance pour orchestrer des flux de travail critiques, avec des milliers de clients qui s'appuient sur notre plateforme pour exécuter plus de 110 millions de jobs chaque semaine. Avec la disponibilité générale de Lakeflow, nous faisons évoluer Workflows vers Jobs Lakeflow, unifiant cet orchestrateur natif mature avec le reste de la pile d'ingénierie de données.
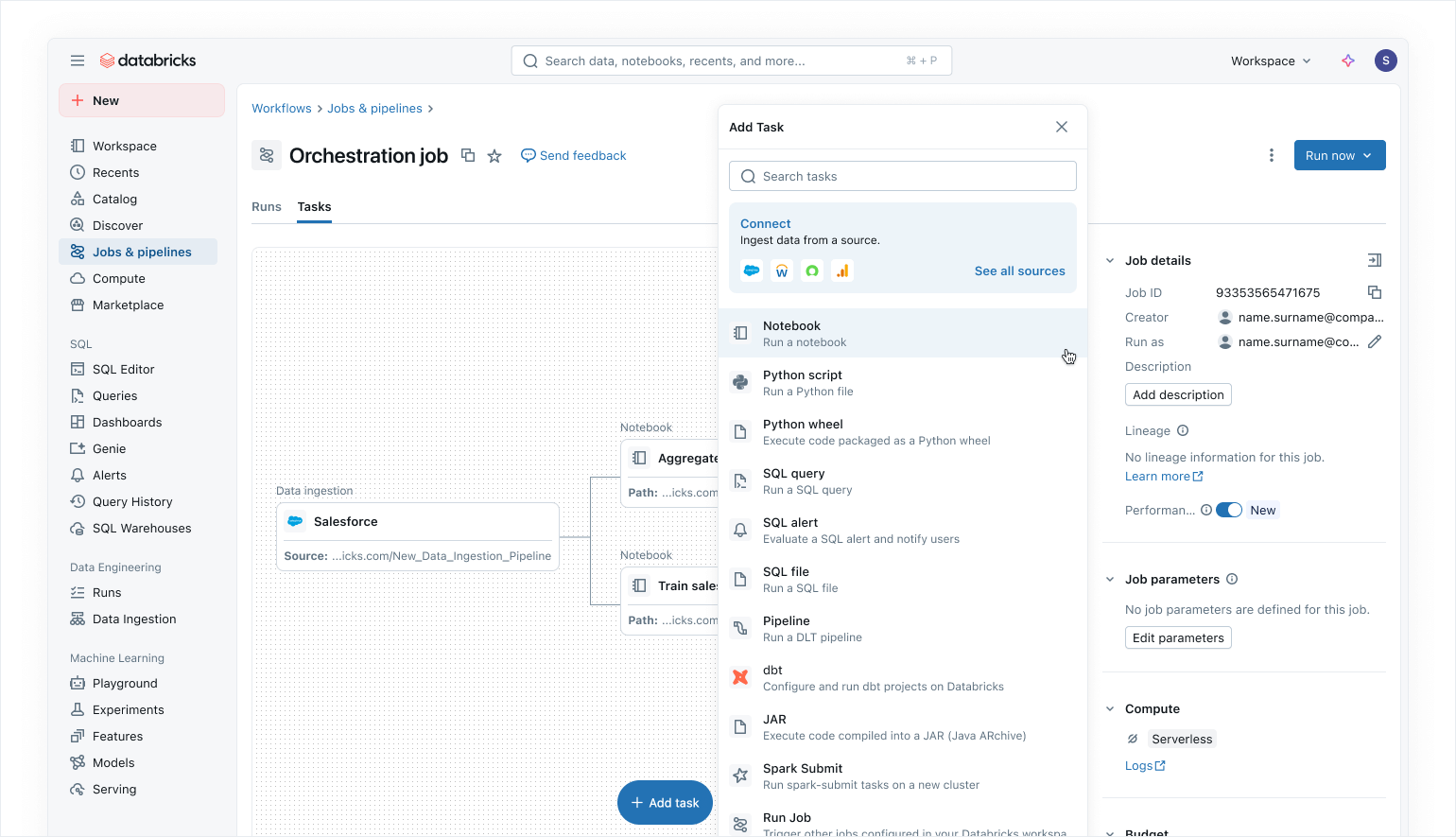
Jobs Lakeflow vous permet d'orchestrer n'importe quel processus sur la Plateforme Intelligente de Données avec un ensemble croissant de capacités, notamment :
- Prise en charge d'une collection complète de types de tâches pour orchestrer des flux incluant des Pipelines Déclaratifs, des notebooks, des requêtes SQL, des transformations dbt et même la publication de tableaux de bord IA/BI ou vers Power BI.
- Fonctionnalités de contrôle de flux telles que l'exécution conditionnelle, les boucles et la définition de paramètres au niveau de la tâche ou du job.
- Déclencheurs pour les exécutions de jobs au-delà de la simple planification, avec des déclencheurs d'arrivée de fichiers et les nouveaux déclencheurs de mise à jour de table, qui garantissent que les jobs ne s'exécutent que lorsque de nouvelles données sont disponibles.
- Jobs sans serveur qui offrent des optimisations automatiques pour de meilleures performances et des coûts réduits.
“Avec les Jobs Lakeflow sans serveur, nous avons obtenu une amélioration de la latence de 3 à 5 fois. Ce qui prenait 10 minutes prend maintenant seulement 2 à 3 minutes, réduisant considérablement les temps de traitement. Cela nous a permis de fournir des boucles de rétroaction plus rapides aux joueurs et aux entraîneurs, en veillant à ce qu'ils obtiennent les informations dont ils ont besoin en temps quasi réel pour prendre des décisions exploitables.” —Bryce Dugar, Responsable de l'ingénierie de données, Cincinnati Reds
Dans le cadre de l'unification de Lakeflow, Jobs Lakeflow apporte une observabilité de bout en bout dans chaque couche du cycle de vie des données, de l'ingestion des données à la transformation et à l'orchestration complexe. Une boîte à outils diversifiée s'adapte à tous les besoins de surveillance : des outils de surveillance visuelle offrent une recherche, un statut et un suivi en un coup d'œil, des outils de débogage comme les profils de requêtes aident à optimiser les performances, des alertes et des tables système aident à faire remonter les problèmes et offrent des aperçus historiques, et les attentes en matière de qualité des données appliquent des règles et garantissent des normes élevées pour vos besoins en pipelines de données.
Commencez avec Lakeflow
Lakeflow Connect, Lakeflow Declarative Pipelines et Lakeflow Jobs sont tous disponibles en disponibilité générale pour tous les clients Databricks dès aujourd'hui. Apprenez-en davantage sur Lakeflow ici et visitez la documentation officielle pour commencer avec Lakeflow pour votre prochain projet d'ingénierie de données.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.