Lancement officiel du Service de modèles Databricks
Le ML en production simplifié sur la plateforme Databricks Lakehouse
par Patrick Wendell, Aaron Davidson, Sue Ann Hong, Kasey Uhlenhuth, Ahmed Bilal et Josh Hartman
Événement virtuel du ML
Nous sommes ravis d'annoncer la disponibilité générale de Databricks Model Serving. Model Serving déploie des modèles de machine learning en tant qu'API REST, vous permettant de créer des applications de ML en temps réel telles que des recommandations personnalisées, des chatbots de service client, la détection de fraude, et plus encore, le tout sans avoir à gérer l'infrastructure de service.
Avec le lancement de Databricks Model Serving, vous pouvez désormais déployer vos modèles au sein de votre infrastructure de données et d'entraînement existante, ce qui simplifie le cycle de vie du ML et réduit les coûts opérationnels.
"En effectuant le service de modèles sur la même plateforme où se trouvent nos données et où nous entraînons les modèles, nous avons pu accélérer les déploiements et réduire la maintenance, ce qui nous a finalement permis de mieux servir nos clients et de promouvoir un mode de vie plus agréable et durable dans le monde entier."—Daniel Edsgärd, Responsable Data science, Electrolux
Défis liés à la création de systèmes de ML en temps réel
Les systèmes de machine learning en temps réel révolutionnent le mode de fonctionnement des entreprises en leur permettant d'effectuer des prédictions ou de prendre des mesures immédiates sur la base des données entrantes. Des applications telles que les chatbots, la détection des fraudes et les systèmes de personnalisation s'appuient sur des systèmes en temps réel pour fournir des réponses instantanées et précises, améliorant ainsi l'expérience client, augmentant les revenus et réduisant les risques.
Cependant, la mise en œuvre de tels systèmes reste un défi pour les entreprises. Les systèmes de ML en temps réel nécessitent une infrastructure de diffusion rapide et évolutive, dont la création et la maintenance requièrent une expertise. L'infrastructure doit non seulement prendre en charge la diffusion, mais aussi inclure la recherche de caractéristiques, le monitoring, le déploiement automatisé et le réentraînement des modèles. Cela conduit souvent les équipes à intégrer des outils disparates, ce qui augmente la complexité opérationnelle et crée une surcharge de maintenance. Les entreprises finissent souvent par consacrer plus de temps et de ressources à la maintenance de l'infrastructure au lieu d'intégrer le ML dans leurs processus.
Service de modèles en production sur le Lakehouse
Databricks Model Serving est la première solution de service en temps réel serverless développée sur une plateforme de données et d'IA unifiée. Cette solution de service unique accélère la mise en production pour les équipes de Data Science en simplifiant les déploiements et en réduisant les erreurs grâce à des outils intégrés.
Éliminez les frais généraux de gestion grâce au Model Serving en temps réel
Databricks Model Serving est un service serverless, à haute disponibilité et à faible latence, pour le déploiement de modèles derrière une API. Vous n'avez plus à vous soucier des difficultés et des contraintes liées à la gestion d'une infrastructure évolutive. Notre service entièrement managé s'occupe de toutes les tâches complexes pour vous, ce qui vous évite d'avoir à gérer les instances, à maintenir la compatibilité des versions et à appliquer des correctifs. Les Endpoints montent en charge automatiquement pour répondre aux variations de la demande, ce qui permet de réduire les coûts d'infrastructure tout en optimisant la latence.
« L'auto-scaling à grande vitesse nous permet de contrôler nos coûts tout en restant réactifs en cas de hausse de la demande. Notre équipe consacre plus de temps à créer des modèles destinés à répondre aux attentes de nos clients qu'à corriger des problèmes d'infrastructure. » —Gyuhyeon Sim, CEO, Letsur.ai
Accélérez les déploiements grâce au Model Serving unifié du lakehouse
Databricks Model Serving accélère les déploiements de modèles de ML en fournissant des intégrations natives avec divers services. Vous pouvez désormais gérer l'ensemble du processus de ML, de l'ingestion et de l'entraînement des données au déploiement et au monitoring, le tout sur une seule et même plateforme, créant ainsi une vue cohérente tout au long du cycle de vie du ML qui minimise les erreurs et accélère le debugging. Model Serving s'intègre avec divers services Lakehouse, notamment
- Intégration du Magasin de fonctionnalités: S'intègre en toute transparence avec le Magasin de fonctionnalités de Databricks et fournit des recherches en ligne automatisées pour éviter le décalage entre les données en ligne et hors ligne. Il vous suffit de définir les caractéristiques une fois pendant l'entraînement et nous les récupérerons et joindrons automatiquement pour compléter la charge utile d'inférence.
- Intégration MLflow: se connecte en mode natif au MLflow Model Registry, permettant un déploiement rapide et facile des modèles. Il vous suffit de nous fournir le modèle, et nous préparerons automatiquement un conteneur prêt pour la production et le déploierons sur un compute serverless
- Qualité et diagnostics (bientôt disponible): Capture automatiquement les requêtes et les réponses dans une table Delta pour surveiller et déboguer les modèles ou générer des datasets d'entraînement.
- Gouvernance unifiée: Gérez et gouvernez toutes les données et tous les actifs de ML, y compris ceux consommés et produits par le service de modèles, avec Unity Catalog.
« En réalisant les opérations de service de modèles sur une plateforme unifiée de données et d'IA, nous avons simplifié le cycle de vie du ML et réduit les tâches de maintenance non productives. Nous consacrons maintenant l'essentiel de nos efforts à élargir l'utilisation de l'IA à de nouveaux domaines de l'entreprise. » —Vincent Koc, Responsable des données, hipages Group
Autonomisez les équipes grâce au déploiement simplifié
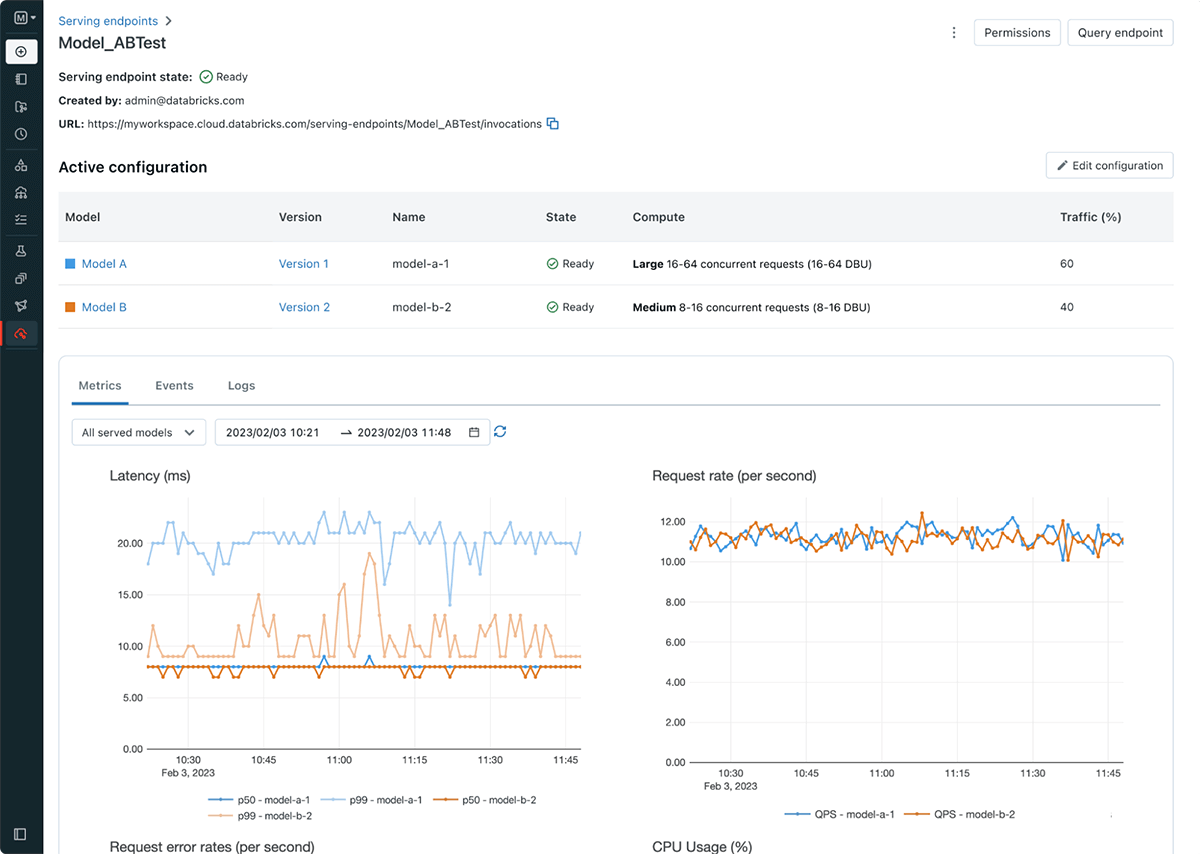
Databricks Model Serving simplifie le workflow de déploiement des modèles, permettant aux Data Scientists de déployer des modèles sans avoir besoin de connaissances ou d'expérience complexes en matière d'infrastructure. Dans le cadre de ce lancement, nous introduisons également des endpoints de service, qui découplent le registre de modèles et l'URI de scoring, ce qui se traduit par des déploiements plus efficaces, stables et flexibles. Par exemple, vous pouvez désormais déployer plusieurs modèles derrière un endpoint unique et répartir le trafic entre les modèles comme vous le souhaitez. La nouvelle interface utilisateur et les nouvelles APIs de mise en service permettent de créer et de gérer facilement les Endpoints. Les Endpoints fournissent également des métriques et des logs intégrés que vous pouvez utiliser pour la surveillance et la réception d'alertes.
Prise en main de Databricks Model Serving
- Inscrivez-vous à la prochaine conférence pour découvrir comment Databricks Model Serving peut vous aider à créer des systèmes en temps réel et à bénéficier des retours d'expérience des clients.
- Essayez-le ! Commencez à déployer des modèles de ML en tant qu'API REST
- Explorez plus en détail la documentationdu Databricks Model Serving
- Consultez le guide pour migrer de Legacy MLflow Model Serving vers Databricks Model Serving
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.