Créer un copilote de risque réglementaire avec Databricks Agent Bricks (Partie 1 : Extraction d'informations)
Découvrez comment transformer des lettres de refus non structurées de la FDA en insights exploitables à l'aide des fonctions d'IA de Databricks et d'Agent Bricks.
par Guanyu Chen et Diego Malaver
- Analyser des PDF complexes : Contrairement aux approches traditionnelles qui nécessitent des équipes et des milliers de lignes de code, utilisez simplement la fonction ai_parse_document() pour analyser de manière fiable le texte et les images provenant de documents PDF complexes tels que les lettres de réponse complète (CRL) de la FDA.
- Extraction collaborative d'insights : Découvrez comment utiliser les Bricks de l'agent d'extraction d'informations pour permettre aux experts métier et aux ingénieurs en IA de définir, tester et perfectionner de manière collaborative l'extraction de données structurées en temps réel.
- Mise en production avec SQL : Déployez en un seul clic votre agent perfectionné en tant que point de terminaison serverless et utilisez la fonction ai_query() pour créer un pipeline évolutif et prêt pour la production afin de traiter de nouveaux documents directement dans votre Lakehouse.
En juillet 2025, la FDA américaine a rendu public un premier batch de plus de 200 lettres de réponse complète (CRL), des lettres de décision expliquant pourquoi les demandes d'autorisation de médicaments et de produits biologiques n'ont pas été approuvées lors de la première évaluation, ce qui marque un tournant majeur en matière de transparence. Pour la première fois, les sponsors, les cliniciens et les équipes de données peuvent analyser le secteur d'activité à travers le langage même de l'agence concernant les lacunes cliniques, CMC, de sécurité, d'étiquetage et de bioéquivalence, via des PDF open FDA centralisés et téléchargeables.
Alors que la FDA continue de publier de nouvelles CRL, la capacité à générer rapidement des insight à partir de ces données et d'autres données non structurées, et à les ajouter à leurs renseignements/données internes, devient un avantage concurrentiel majeur. Les organisations qui peuvent exploiter efficacement les insights de données non structurées (sous forme de PDF, de documents, d'images, etc.) peuvent réduire les risques liés à leurs propres soumissions, identifier les pièges courants et, au final, accélérer leur mise sur le marché. Le problème est que ces données, comme de nombreuses autres données réglementaires, sont verrouillées dans des PDF, qui sont notoirement difficiles à traiter quand on monte en charge.
C'est précisément le type de défi que Databricks a été conçu pour résoudre. Cet article de blog montre comment utiliser les derniers outils d'IA de Databricks pour accélérer l'extraction d'informations clés piégées dans des PDF, transformant ces lettres critiques en une source de renseignements exploitables.
Les clés pour réussir avec l'IA
Compte tenu de la profondeur technique requise, les ingénieurs mènent souvent le développement en silo, créant un grand écart entre le développement de l'IA et les exigences métier. Au moment où un expert du domaine (SME) voit le résultat, celui-ci ne correspond souvent pas à ce dont il avait besoin. La boucle de feedback est trop lente et le projet perd de son élan.
Pendant les phases de test initiales, il est crucial d'établir une base de référence. Dans de nombreux cas, les approches alternatives impliquent de perdre des mois sans vérités terrain, en se fiant plutôt à l'observation subjective et à l'intuition. Ce manque de preuves empiriques freine les progrès. À l'inverse, les outils Databricks fournissent des fonctionnalités d'évaluation prêtes à l'emploi et permettent aux clients de mettre immédiatement l'accent sur la qualité, en utilisant un cadre itératif pour obtenir une confiance mathématique dans l'extraction. La réussite de l'IA nécessite une nouvelle approche fondée sur une itération rapide et collaborative.
Databricks fournit une plateforme unifiée où les experts métier et les ingénieurs en IA peuvent collaborer en temps réel pour créer, tester et déployer des agents de qualité production. Ce framework repose sur trois principes clés :
- Alignement métier-technique étroit : les PME et les responsables techniques collaborent dans la même interface utilisateur pour un retour d'information instantané, remplaçant ainsi les lents échanges d'e-mails.
- Évaluation de la vérité terrain : les étiquettes de "vérité terrain" définies par l'entreprise sont directement intégrées dans le flux de travail pour une notation formelle.
- Une approche de plateforme complète : Il ne s'agit pas d'un sandbox ou d'une solution ponctuelle ; elle est entièrement intégrée à des pipelines automatisés, à l'évaluation LLM-as-a-Judge, à un throughput GPU fiable en production et à la gouvernance de bout en bout d'Unity Catalog.
Cette approche de plateforme unifiée est ce qui transforme un prototype en un système d'IA de confiance, prêt pour la production. Parcourons les quatre étapes pour le construire.
Du PDF à la production : un guide en quatre étapes
La création d'un système d'IA de qualité production sur des données non structurées nécessite plus qu'un simple bon modèle ; elle exige un flux de travail transparent, itératif et collaboratif. La brique Information Extraction Agent, associée aux fonctions d'IA intégrées de Databricks, facilite l'analyse des documents, l'extraction des informations clés et l'opérationnalisation de l'ensemble du processus. Cette approche permet aux équipes d'aller plus vite et de fournir des résultats de meilleure qualité. Décomposons ci-dessous les quatre étapes clés de la construction.
Étape 1 : Analyse de PDF non structurés en texte avec ai_parse_document()
Le premier obstacle consiste à extraire du texte propre des PDF. Les CRL peuvent avoir des Layouts complexes avec des en-têtes, des pieds de page, des tableaux, des graphiques, sur plusieurs pages et sur plusieurs colonnes. Une simple extraction de texte échouera souvent, produisant des résultats inexacts et inutilisables.
Contrairement aux solutions ponctuelles fragiles qui ont des difficultés avec le layout, ai_parse_document() exploite une IA multimodale de pointe pour comprendre la structure des documents - en extrayant avec précision le texte dans l'ordre de lecture, en préservant les hiérarchies de tableaux irrégulières et en générant des légendes pour les figures.
De plus, Databricks offre un avantage en matière d'intelligence documentaire en assurant une mise à l'échelle fiable pour traiter des volumes de PDF complexes de niveau entreprise, pour un coût 3 à 5 fois inférieur à celui des principaux concurrents. Les équipes n'ont pas à se soucier des limites de taille de fichier, et les technologies OCR et VLM sous-jacentes garantissent une analyse précise des PDF historiquement problématiques contenant des figures denses et irrégulières ainsi que d'autres structures complexes.
Ce qui nécessitait autrefois l'intervention de nombreux data scientists pour configurer et maintenir des stacks d'analyse personnalisés auprès de multiples fournisseurs peut désormais être accompli avec une seule fonction SQL native, permettant aux équipes de traiter des millions de documents en parallèle sans les modes de défaillance qui affectent les analyseurs moins évolutifs.
Pour commencer, faites pointer un volume UC vers votre stockage cloud contenant vos PDF. Dans notre exemple, nous allons faire pointer la fonction SQL vers les PDF CRL gérés par un volume :
Cette seule commande traite tous vos PDF et crée une table structurée avec le contenu analysé et le texte combiné, la préparant ainsi pour l'étape suivante.
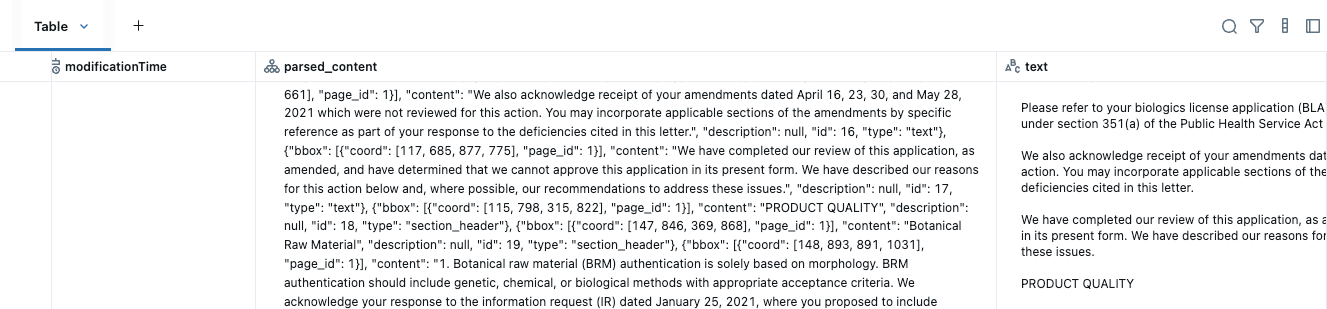
Remarque : nous n'avons eu besoin de configurer aucune infrastructure, aucun réseau ni aucun appel externe de LLM ou de GPU. Databricks héberge les GPU et le backend du modèle, offrant un throughput fiable et évolutif sans configuration supplémentaire. Contrairement aux plateformes qui facturent des frais de licence, Databricks utilise un modèle de Tarifs basé sur le compute, ce qui signifie que vous ne payez que pour les Ressources que vous utilisez. Cela permet de puissantes optimisations des coûts grâce à la parallélisation et à la personnalisation au niveau des fonctions dans vos pipelines de production.
Étape 2 : Extraction itérative d'informations avec les Agent Bricks
Une fois que vous avez le texte, l'objectif suivant est d'extraire des champs spécifiques et structurés. Par exemple : Quelle était la non-conformité ? Quel était l'ID de la NDA ? Quelle était la citation de rejet ? C'est là que les ingénieurs en IA et les experts métier doivent collaborer étroitement. L'expert métier sait ce qu'il faut rechercher et peut travailler avec l'ingénieur pour indiquer rapidement au modèle comment le trouver.
Agent Bricks : Extraction d'informations fournit une interface utilisateur collaborative en temps réel pour ce workflow précis.
Comme illustré ci-dessous, l'interface permet à un responsable technique et à un expert métier de travailler ensemble :
- L'expert métier fournit des champs spécifiques qui doivent être extraits (par ex.,
deficiency_summary_paragraphs, NDA_ID, FDA_Rejection_Citing). - L'agent d'extraction d'informations traduira ces exigences en prompts efficaces. Ces directives modifiables se trouvent dans le panneau de droite.
- Le Tech Lead et le SME métier peuvent tous deux voir immédiatement la sortie JSON dans le panneau central et valider si le modèle extrait correctement les informations du document sur la gauche. À partir de là, l'un ou l'autre peut reformuler un prompt pour garantir des extractions précises.
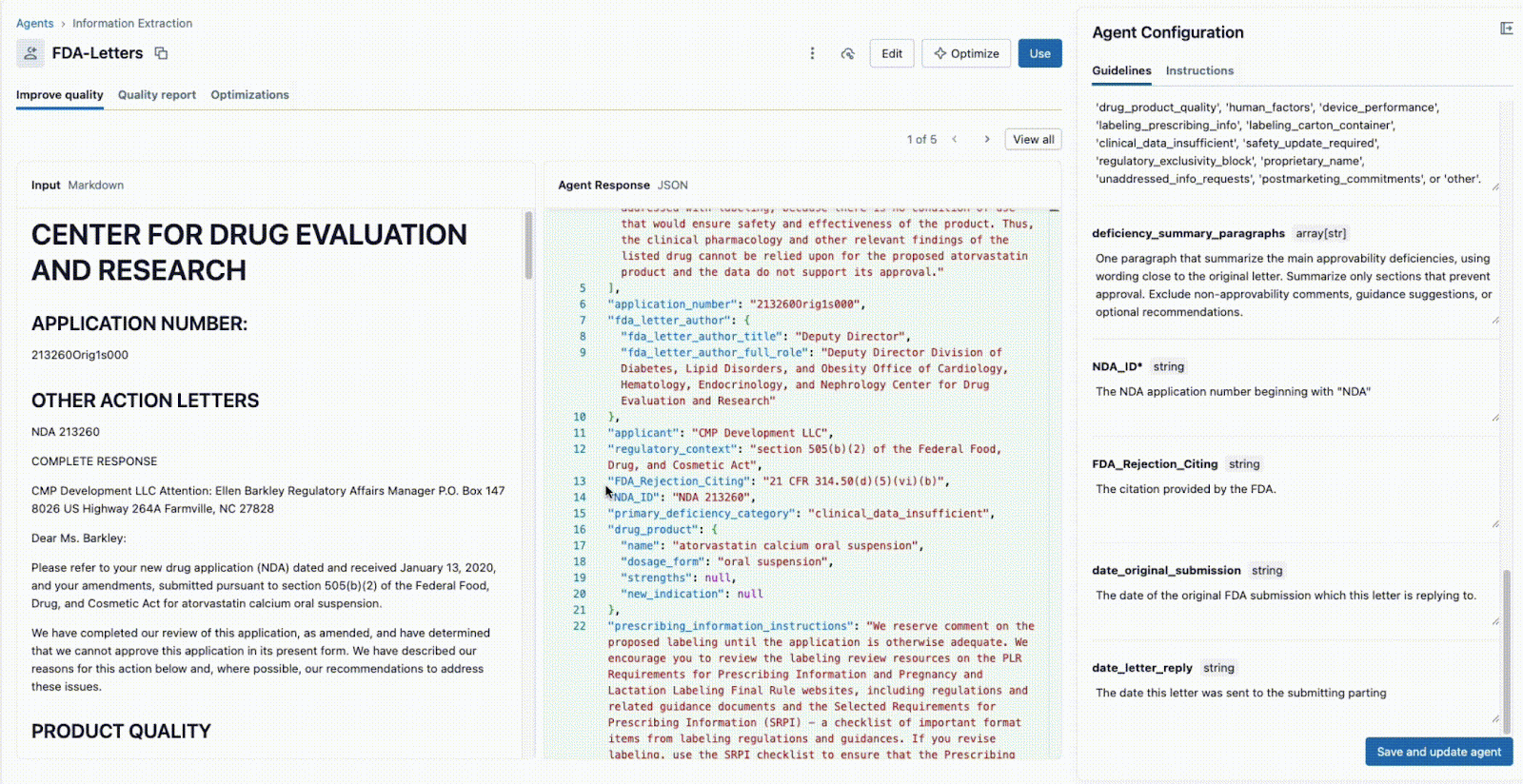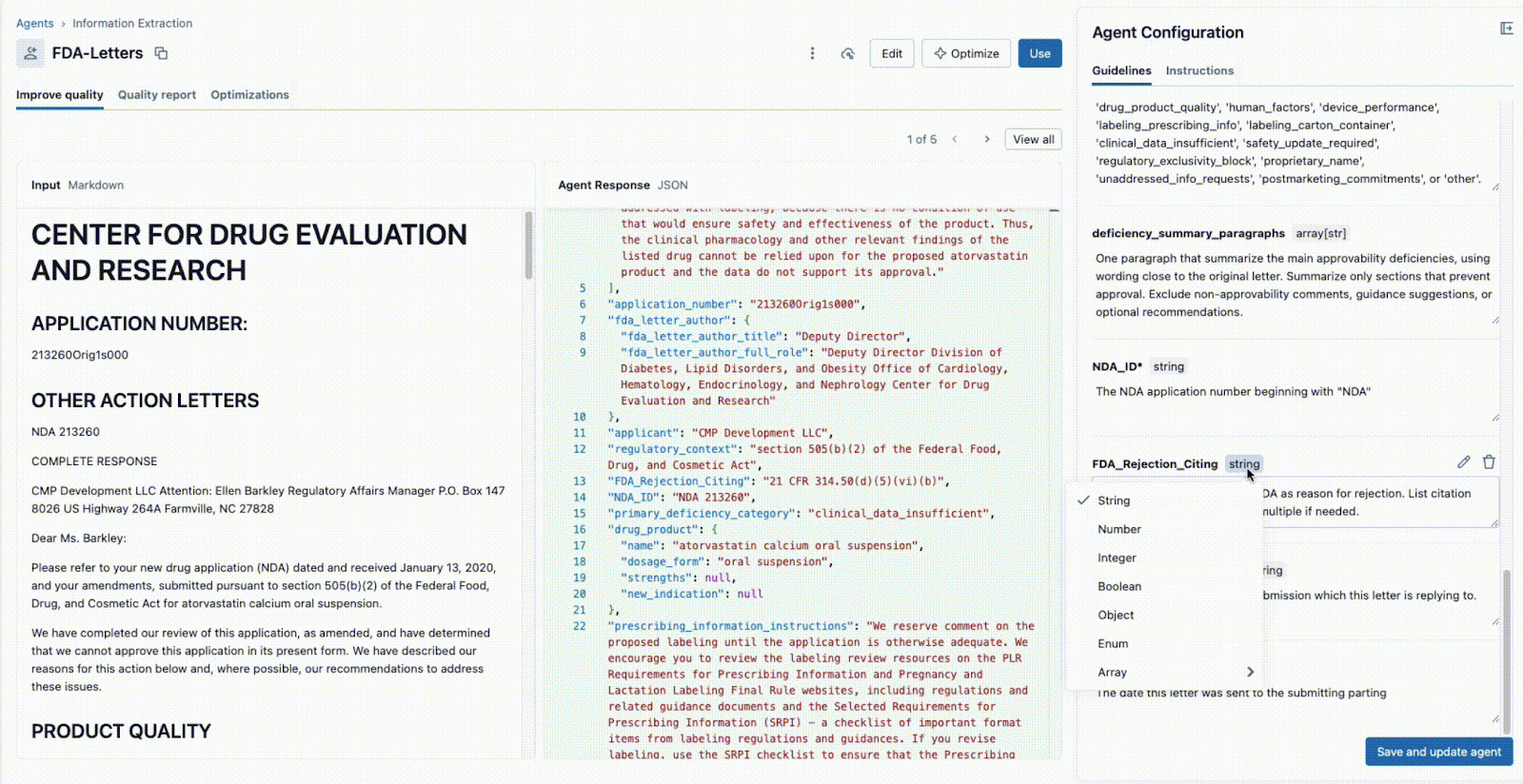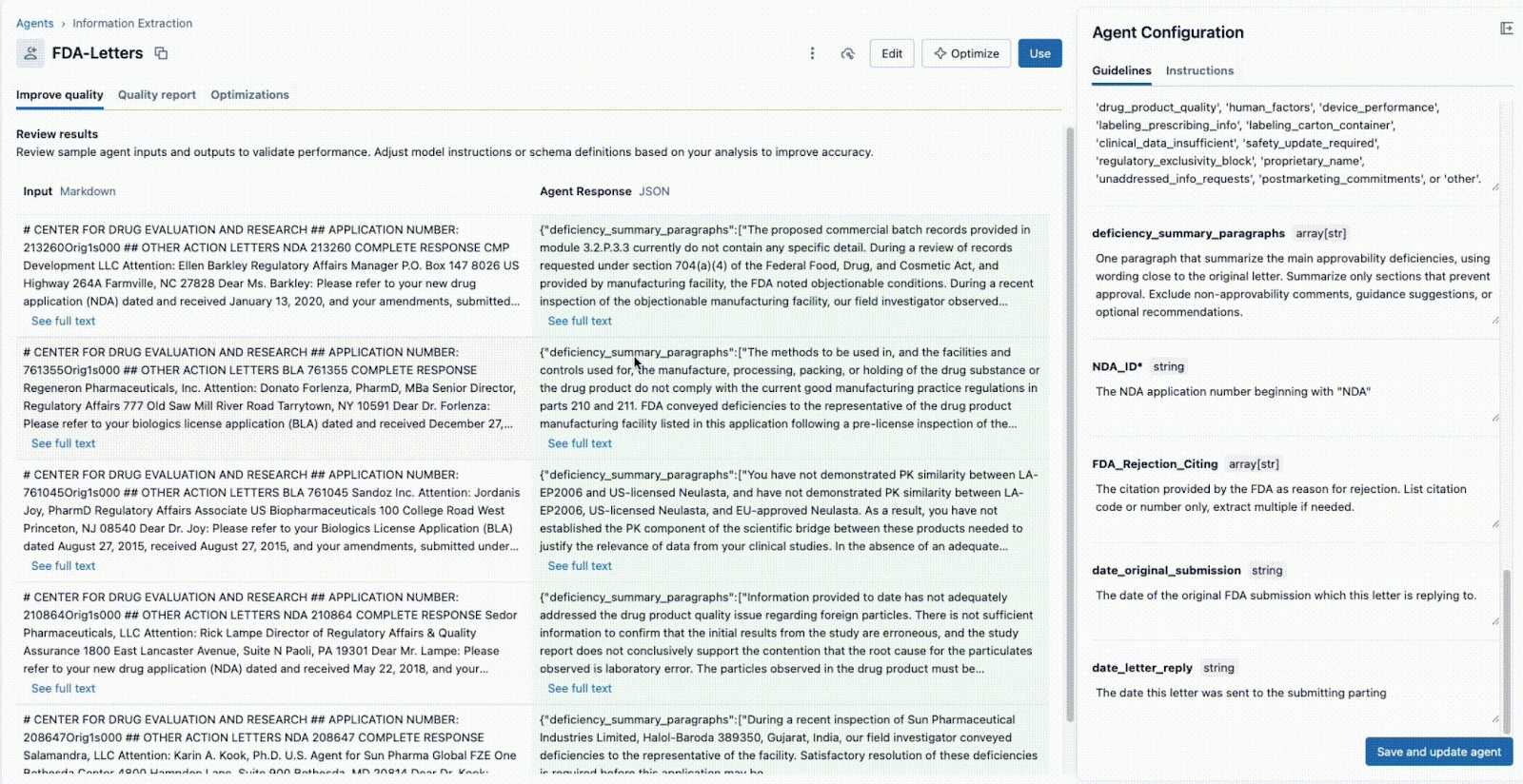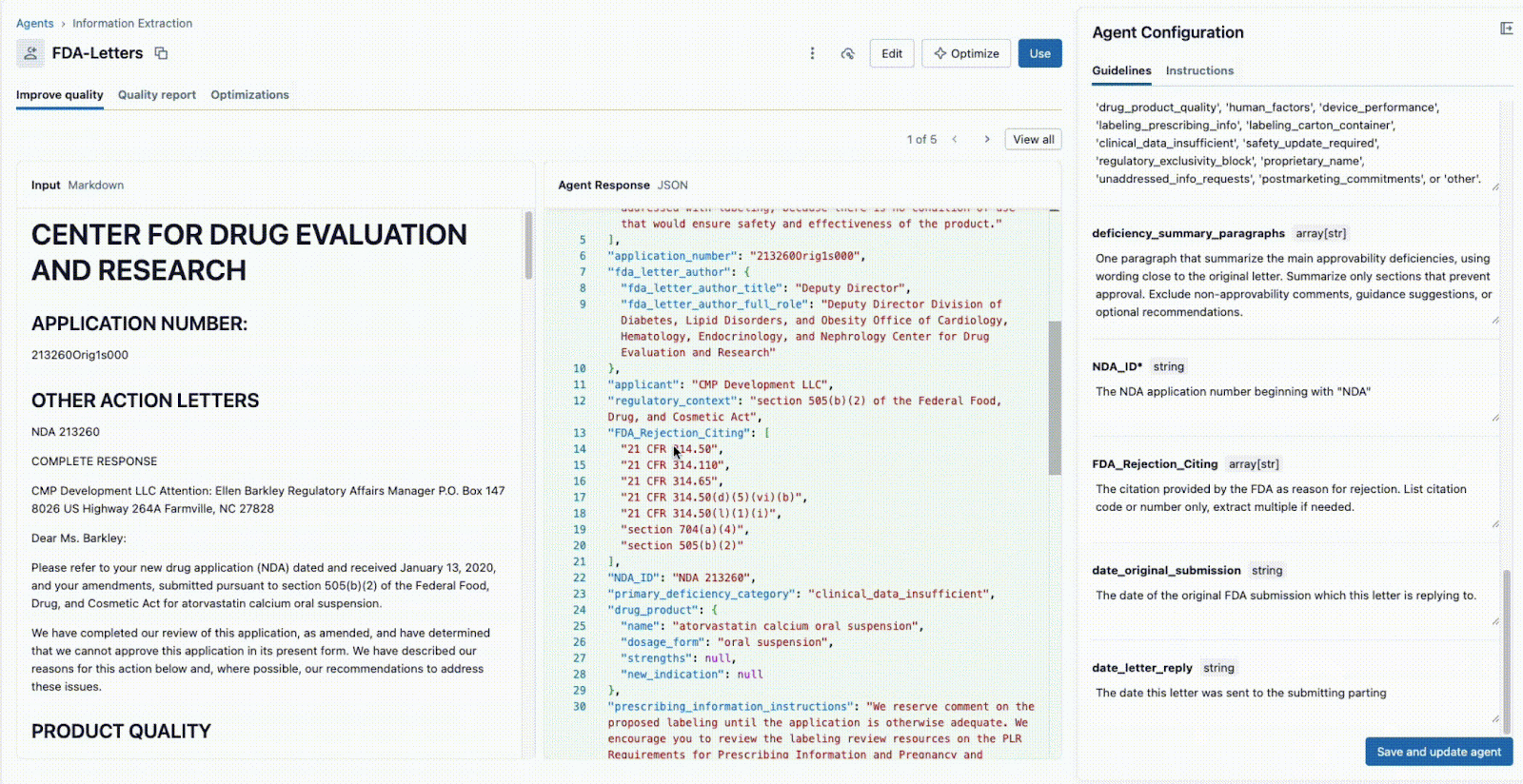
Cette boucle de rétroaction instantanée est la clé du succès. Si un champ n'est pas extrait correctement, l'équipe peut ajuster le prompt, ajouter un nouveau champ ou affiner les instructions et voir le résultat en quelques secondes. Ce processus itératif, où plusieurs experts collaborent au sein d'une interface unique, est ce qui distingue les projets d'IA réussis de ceux qui échouent en silos.
Étape 3 : Évaluer et valider l'agent
À l'étape 2, nous avons créé un agent qui, d'après une « évaluation intuitive », semblait correct pendant le développement itératif. Mais comment garantir une précision et une scalabilité élevées lors de la présentation de nouvelles données ? Une modification du prompt qui corrige un document pourrait en compromettre dix autres. C'est là qu'intervient l'évaluation formelle, un élément essentiel et intégré du workflow d'Agent Bricks.
Cette étape est votre porte de qualité, et elle fournit deux méthodes de validation puissantes :
Méthode A : Évaluer avec des étiquettes de vérité terrain (l'étalon-or)
L'IA, comme tout projet de Data Science, échoue dans un vacuum sans une expertise métier adéquate. Un investissement de la part des experts métier pour fournir un "golden set" (également appelé vérité terrain ou datasets étiquetés) d'informations correctes et pertinentes, extraites manuellement et validées par l'homme, contribue grandement à garantir la généralisation de cette solution à de nouveaux fichiers et formats. En effet, les paires clé-valeur étiquetées aident rapidement l'agent à affiner des prompts de haute qualité, ce qui permet d'obtenir des extractions précises et pertinentes pour l'entreprise. Voyons en détail comment Agent Bricks utilise ces étiquettes pour évaluer formellement votre agent.
Dans l'interface utilisateur d'Agent Bricks, fournissez le jeu de données de test de référence et, en arrière-plan, Agent Bricks s'exécute sur les documents de test. L'interface utilisateur fournira une comparaison côte à côte de la sortie extraite par votre agent par rapport à la réponse étiquetée "correcte".
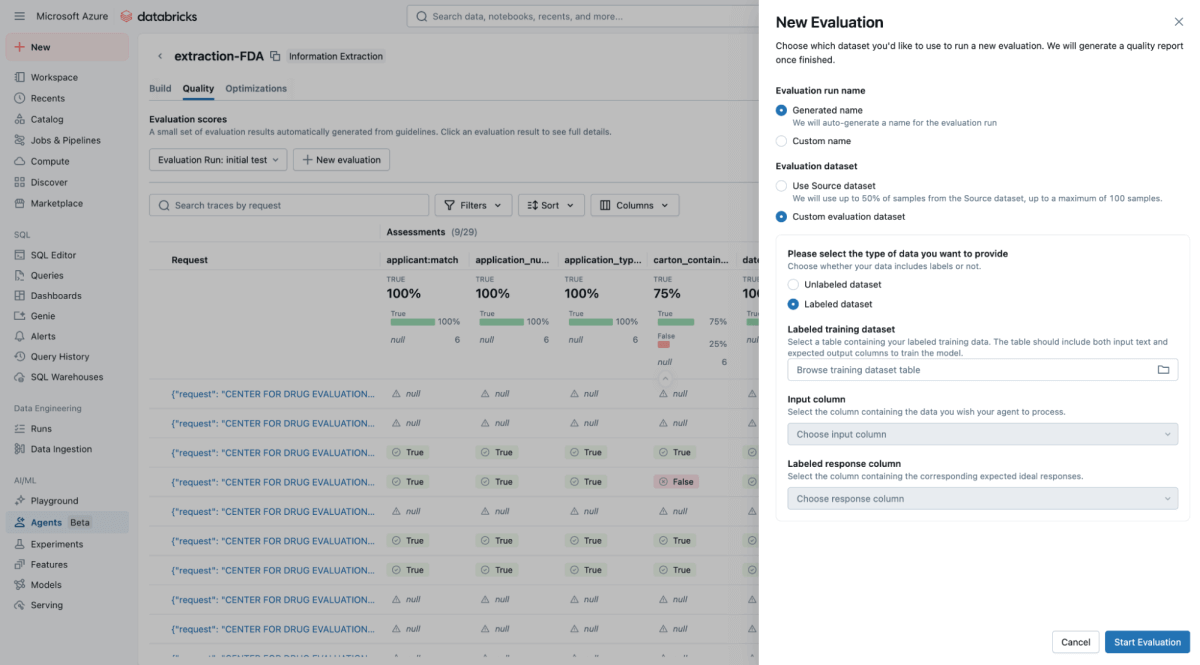
L'interface utilisateur fournit un score de précision clair pour chaque champ d'extraction, ce qui vous permet de repérer instantanément les régressions lorsque vous modifiez un prompt. Avec Agent Bricks, vous obtenez un niveau de confiance métier indiquant que l'agent atteint une précision égale ou supérieure à celle d'un humain.
Méthode B : Pas d'étiquettes ? Utiliser LLM-as-a-Judge
Mais que se passe-t-il si vous partez de zéro et que vous n'avez aucune étiquette de vérité terrain ? C'est un problème courant de "démarrage à froid".
La suite d'évaluation d'Agent Bricks fournit une solution puissante : LLM-as-a-Judge. Databricks fournit une suite de frameworks d'évaluation, et Agent Bricks s'appuiera sur des modèles d'évaluation pour jouer le rôle d'évaluateur impartial. Le modèle « Juge » se voit présenter le texte du document original et un ensemble de prompts de champ pour chaque document. Le rôle du « Juge » est de générer une réponse « attendue », puis de l'évaluer par rapport à la sortie extraite par l'agent.
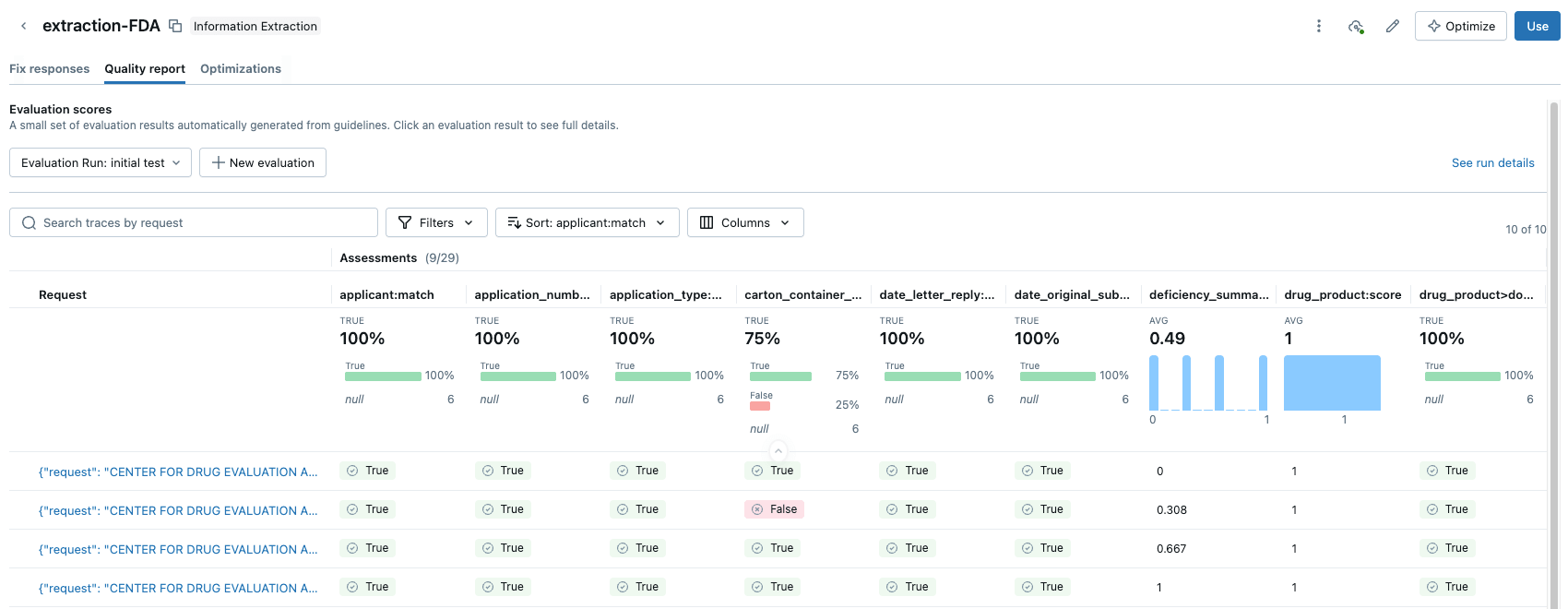
LLM-as-a-Judge vous permet d'obtenir un score d'évaluation évolutif et de haute qualité et, à noter, peut également être utilisé en production pour garantir que les agents restent fiables et généralisables à la variabilité et à la mise à l'échelle de la production. Plus d'informations à ce sujet dans un futur article de blog.
Étape 4 : Intégration de l'agent avec ai_query() dans votre pipeline ETL
À ce stade, vous avez créé votre agent à l'étape 2 et validé son exactitude à l'étape 3, et vous avez maintenant la confiance nécessaire pour intégrer l'extraction dans votre flux de travail. D'un simple clic, vous pouvez déployer votre agent en tant qu'endpoint de modèle serverless - immédiatement, votre logique d'extraction est disponible en tant que fonction simple et évolutive.
Pour ce faire, utilisez la fonction ai_query() en SQL afin d'appliquer cette logique aux nouveaux documents à mesure qu'ils arrivent. La fonction ai_query() vous permet d'appeler n'importe quel endpoint de service de modèle directement et en toute transparence dans votre pipeline de données ETL de bout en bout.
Avec cela, Databricks Lakeflow Jobs garantissent que vous disposez d'un pipeline ETL entièrement automatisé et de qualité production. Votre Job Databricks prend les PDF bruts arrivant dans votre stockage cloud, les analyse, en extrait des insights structurés à l'aide de votre agent de haute qualité, et les place dans une table prête pour l'analyse, le reporting ou pour être référencée dans la recherche d'une application d'agent en aval.
Databricks est la plateforme d'IA de nouvelle génération, celle qui fait tomber les barrières entre les équipes très techniques et les experts du domaine qui détiennent le contexte nécessaire pour créer une IA pertinente. La réussite en matière d'IA ne repose pas uniquement sur les modèles ou l'infrastructure ; elle réside dans la collaboration étroite et itérative entre les ingénieurs et les experts métier, où chacun affine la pensée de l'autre. Databricks offre aux équipes un environnement unique pour co-développer, expérimenter rapidement, gouverner de manière responsable et remettre la science au cœur de la Data Science.
Agent Bricks est l'incarnation de cette vision. Avec ai_parse_document() pour analyser le contenu non structuré, l'interface de conception collaborative d'Agent Bricks: Information Extraction pour accélérer les extractions de haute qualité, et ai_query() pour appliquer la solution dans des pipelines de production, les équipes peuvent passer de millions de PDF désordonnés à des insights validés plus rapidement que jamais.
Dans notre prochain blog, nous montrerons comment utiliser ces insights extraits et créer un agent conversationnel de qualité production capable de répondre à des questions en langage naturel comme : « Quels sont les problèmes de préparation à la fabrication les plus courants pour les médicaments oncologiques ? »
- En savoir plus : consultez la documentation officielle de ai_parse_document(), Agent Bricks : Extraction d'informations et ai_query().
- Pour commencer : Inscrivez-vous pour un essai gratuit de Databricks afin de créer vos propres solutions basées sur l'IA dès aujourd'hui.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.