Du chaos à Monter en charge : créer des modèles de pipelines déclaratifs Spark avec DLT-META
Un framework de métadonnées pour créer des pipelines cohérents, automatisés et régis à grande échelle
par Ravi Gawai et Phoebe Weiser
- La mise à l'échelle des pipelines de données entraîne une surcharge, un drift et une logique incohérente entre les équipes.
- Ces lacunes ralentissent la livraison, augmentent les coûts de maintenance et rendent difficile l'application de normes communes.
- Ce blog montre comment la métaprogrammation basée sur les métadonnées supprime la duplication et crée des pipelines de données automatisés et cohérents à grande échelle.
Les pipelines déclaratifs offrent aux équipes une approche basée sur l'intention pour créer des workflows batch et streaming. Vous définissez ce qui doit se passer et laissez le système gérer l'exécution. Cela réduit le code personnalisé et favorise des modèles de Data Engineering reproductibles.
À mesure que l'utilisation des données par les entreprises augmente, les pipelines se multiplient. Les normes évoluent, de nouvelles sources sont ajoutées et de plus en plus d'équipes participent au développement. Même les petites mises à jour de schémas se répercutent sur des dizaines de Notebooks et de configurations. La métaprogrammation basée sur les métadonnées résout ces problèmes en déplaçant la logique du pipeline dans des Templates structurés qui sont générés au moment de l'exécution.
Cette approche assure la cohérence du développement, réduit la maintenance et monte en charge avec un effort d'ingénierie limité.
Dans cet article de blog, vous apprendrez à créer des pipelines basés sur les métadonnées pour les pipelines déclaratifs Spark à l'aide de DLT-META, un projet de Databricks Labs, qui applique des modèles de métadonnées pour automatiser la création de pipelines.
Aussi utiles que soient les pipelines déclaratifs, le travail nécessaire pour les prendre en charge augmente rapidement lorsque les équipes ajoutent de nouvelles sources et étendent leur utilisation à l'échelle de l'entreprise.
Pourquoi les pipelines manuels sont difficiles à maintenir à grande échelle
Les pipelines manuels fonctionnent à petite échelle, mais l'effort de maintenance augmente plus rapidement que les données elles-mêmes. Chaque nouvelle source ajoute de la complexité, ce qui entraîne un drift de la logique et des remaniements. Les équipes finissent par corriger les pipelines au lieu de les améliorer. Les data engineers sont constamment confrontés à ces défis de mise à l'échelle :
- Trop d'artefacts par source : Chaque dataset nécessite de nouveaux notebooks, configurations et scripts. La charge opérationnelle augmente rapidement avec chaque flux intégré.
- Les mises à jour de la logique ne se propagent pas : Les modifications des règles métier ne sont pas appliquées aux pipelines, ce qui entraîne une drift de la configuration et des sorties incohérentes entre les pipelines.
- Qualité et gouvernance incohérentes : Les équipes créent des vérifications et une traçabilité personnalisées, ce qui rend les normes à l'échelle de l'organisation difficiles à appliquer et les résultats très variables.
- Contribution limitée et sécurisée des équipes de domaine : les analystes et les équipes métier souhaitent ajouter des données, mais l'ingénierie des données examine ou réécrit toujours la logique, ce qui ralentit la livraison.
- La maintenance se multiplie à chaque changement : de simples ajustements ou mises à jour de schémas créent un énorme arriéré de travail manuel sur tous les pipelines dépendants, ce qui paralyse l'agilité de la plateforme.
Ces problèmes montrent pourquoi une approche axée sur les métadonnées est importante. Elle réduit l'effort manuel et maintient la cohérence des pipelines lors de leur montée en charge.
Comment DLT-META gère Monter en charge et la cohérence
DLT-META résout les problèmes de montée en charge et de cohérence des pipelines. Il s'agit d'un framework de métaprogrammation basé sur les métadonnées pour les pipelines déclaratifs Spark. Les équipes de données l'utilisent pour automatiser la création de pipelines, standardiser la logique et monter en charge le développement avec un minimum de code.
Avec la métaprogrammation, le comportement du pipeline est dérivé de la configuration, plutôt que de Notebooks répétés. Cela offre des avantages évidents aux équipes.
- Moins de code à écrire et à maintenir
- Intégration plus rapide des nouvelles sources de données
- Des pipelines prêts pour la production dès le départ
- Des modèles cohérents sur l'ensemble de la plateforme
- Des bonnes pratiques évolutives avec des équipes réduites
Les pipelines déclaratifs Spark et DLT-META fonctionnent ensemble. Les pipelines déclaratifs Spark définissent l'intention et gèrent l'exécution. DLT-META ajoute une couche de configuration qui génère et met à l'échelle la logique du pipeline. Combinés, ils remplacent le codage manuel par des modèles reproductibles qui favorisent la gouvernance, l'efficacité et la croissance à l'échelle de la montée en charge.
Comment DLT-META répond aux besoins réels de l'ingénierie des données
1. Configuration centralisée et basée sur des modèles
DLT-META centralise la logique des pipelines dans des Templates partagés pour supprimer la duplication et la maintenance manuelle. Les équipes définissent les règles d'ingestion, de transformation, de qualité et de gouvernance dans des métadonnées partagées à l'aide de JSON ou de YAML. Lorsqu'une nouvelle source est ajoutée ou qu'une règle change, les équipes mettent à jour la configuration une seule fois. La logique se propage automatiquement dans les pipelines.
2. Évolutivité instantanée et intégration plus rapide
Les mises à jour basées sur les métadonnées facilitent le Monter en charge des pipelines et l'intégration de nouvelles sources. Les équipes ajoutent des sources ou ajustent les règles métier en modifiant les fichiers de métadonnées. Les modifications s'appliquent à toutes les charges de travail en aval sans intervention manuelle. Les nouvelles sources passent en production en quelques minutes au lieu de plusieurs semaines.
3. Contribution de l'équipe du domaine avec des normes appliquées
DLT-META permet aux équipes de domaine de contribuer en toute sécurité par le biais de la configuration. Les analystes et les experts du domaine mettent à jour les métadonnées pour accélérer la livraison. Les équipes de plateforme et de Data Engineering gardent le contrôle sur la validation, la qualité des données, les Transformations et les règles de conformité.
4. Cohérence et gouvernance à l'échelle de l'entreprise
Les normes à l'échelle de l'organisation s'appliquent automatiquement à tous les pipelines et consommateurs. La configuration centrale applique une logique cohérente pour chaque nouvelle source. Les règles intégrées d'audit, de lignage et de qualité des données répondent aux exigences réglementaires et opérationnelles à grande échelle.
Comment les équipes utilisent DLT-META en pratique
Les clients utilisent DLT-META pour définir l'ingestion et les transformations une seule fois et les appliquer via la configuration. Cela réduit le code personnalisé et accélère l'intégration.
Cineplex a constaté un impact immédiat.
Nous utilisons DLT-META pour minimiser le code personnalisé. Les ingénieurs n'ont plus à écrire de pipelines différemment pour des tâches simples. Les fichiers JSON d'intégration appliquent un cadre cohérent et s'occupent du reste.—Aditya Singh, data engineer, Cineplex
PsiQuantum montre comment les petites équipes peuvent monter en charge efficacement.
DLT-META nous aide à gérer les charges de travail bronze et silver avec une maintenance réduite. Il prend en charge de grands volumes de données sans dupliquer les Notebooks ou le code source.—Arthur Valadares, Principal data engineer, PsiQuantum
Dans tous les Secteurs d'activité, les équipes appliquent le même modèle.
- Vente au détail centralise les données des magasins et de la chaîne d'approvisionnement provenant de centaines de sources
- Logistique : normalise l'ingestion par lots et en streaming pour les données IoT et de flotte
- Services financiers : applique l'audit et la conformité tout en intégrant plus rapidement les flux
- Soins de santé maintient la qualité et l'auditabilité sur des datasets complexes
- Industrie et télécommunications : montent en charge l'ingestion à l'aide de métadonnées réutilisables et gouvernées de manière centralisée
Cette approche permet aux équipes d'augmenter le nombre de pipelines sans en accroître la complexité.
Comment démarrer avec DLT-META en 5 étapes simples
Vous n'avez pas besoin de reconcevoir votre plateforme pour essayer DLT-META. Commencez petit. Utilisez quelques sources. Laissez les métadonnées s'occuper du reste.
1. Obtenir le framework
Commencez par cloner le repository DLT-META. Vous obtiendrez ainsi les Templates, les exemples et les outils nécessaires pour définir des pipelines à l'aide de métadonnées.
2. Définissez vos pipelines avec des métadonnées
Ensuite, définissez ce que vos pipelines doivent faire. Pour ce faire, modifiez un petit ensemble de fichiers de configuration.
- Utilisez conf/onboarding.json pour décrire les tables d'entrée brutes.
- Utilisez conf/silver_transformations.json pour définir les transformations.
- Facultativement, ajoutez conf/dq_rules.json si vous souhaitez appliquer des règles de qualité des données.
À ce stade, vous décrivez une intention. Vous n'écrivez pas de code de pipeline.
3. Intégrer les métadonnées dans la plateforme
Avant que les pipelines puissent s'exécuter, DLT-META doit enregistrer vos métadonnées. Cette étape d'intégration convertit vos configurations en tables delta Dataflowspec que les pipelines lisent au moment de l'exécution.
Vous pouvez exécuter l'intégration à partir d'un Notebook, d'un Lakeflow Job ou de la CLI DLT-META.
a. Intégration manuelle via un notebook, p. ex. ici
Utilisez le notebook d'intégration fourni pour traiter vos métadonnées et provisionner les artefacts de votre pipeline :
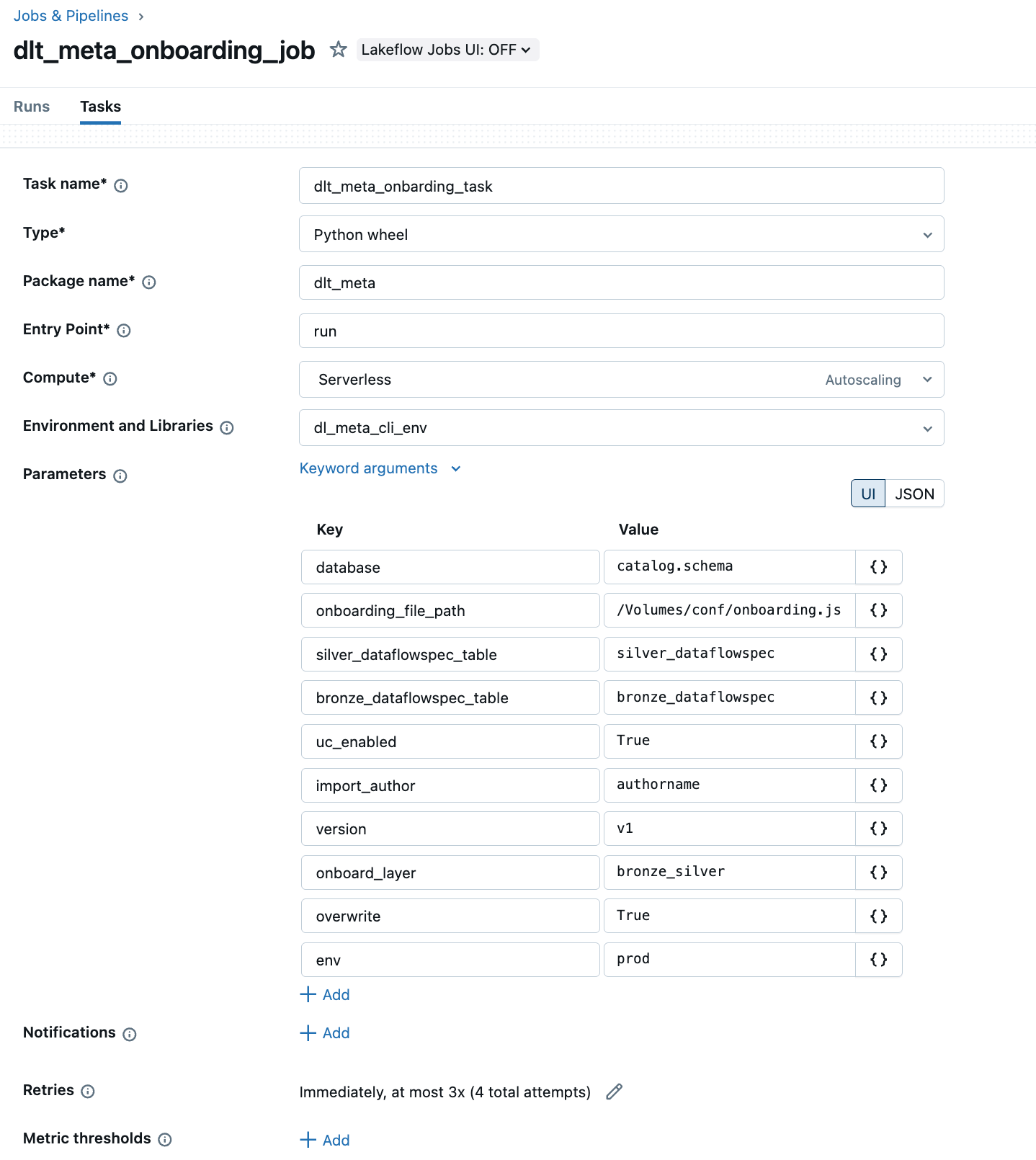
b. Automatiser l'intégration via Lakeflow Jobs avec un Python wheel.
L'exemple ci-dessous montre l'interface utilisateur de Lakeflow Jobs pour créer et automatiser un pipeline DLT-META
c. Intégrez à l'aide des commandes CLI DLT-META indiquées dans le dépôt : ici.
L'interface CLI de DLT-META vous permet d'exécuter l'intégration et le déploiement dans un terminal Python interactif
4. Créez un pipeline générique
Une fois les métadonnées en place, vous créez un pipeline générique unique. Ce pipeline lit les tables Dataflowspec et génère la logique de manière dynamique.
Utilisez pipelines/dlt_meta_pipeline.py comme point d'entrée et configurez-le pour référencer vos spécifications bronze et silver.
Ce pipeline reste inchangé lorsque vous ajoutez des sources. Les métadonnées contrôlent le comportement.

5. Trigger et exécuter
Vous êtes maintenant prêt à exécuter le pipeline. Déclenchez-le comme n'importe quel autre pipeline déclaratif Spark.
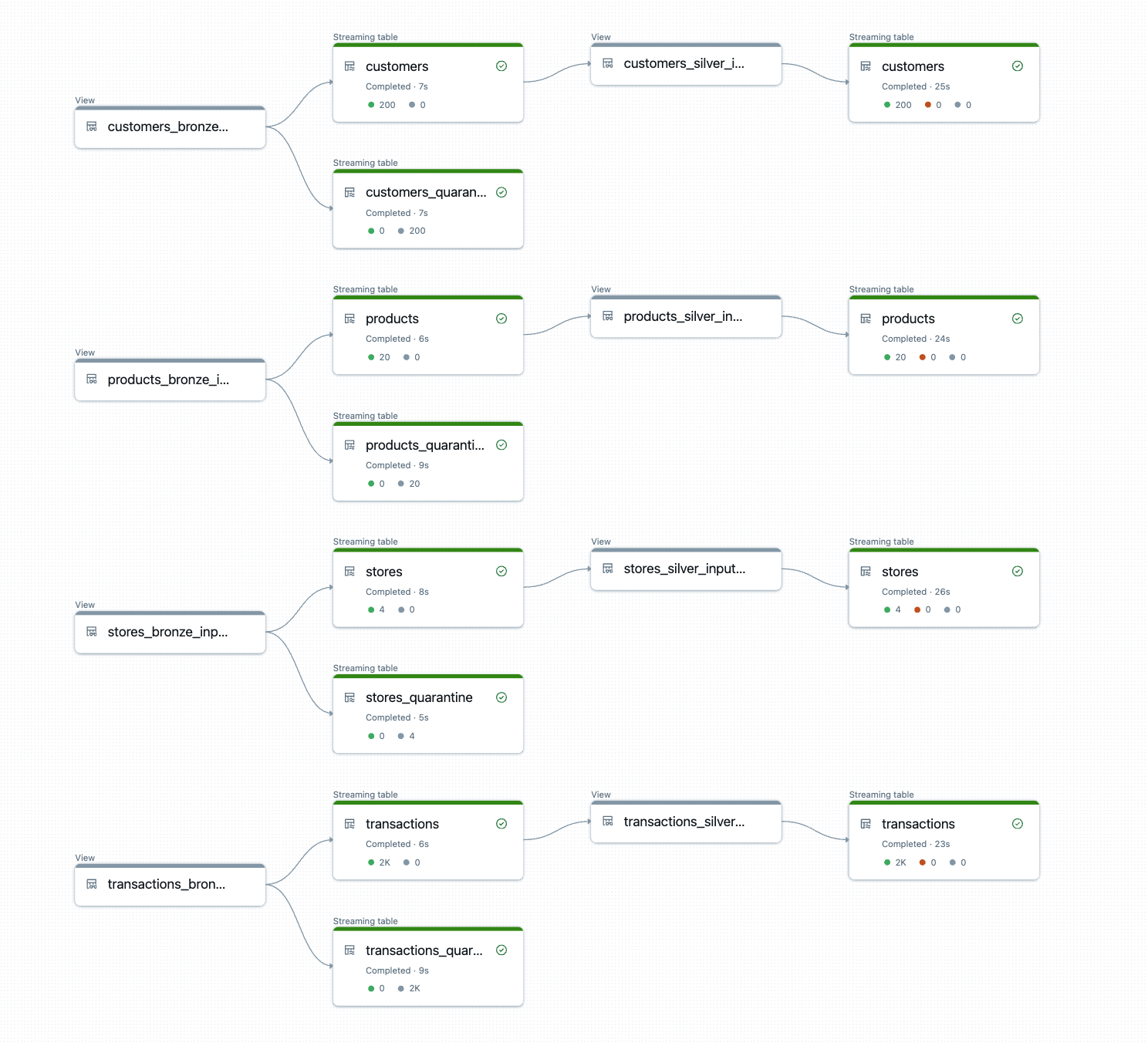
DLT-META crée et exécute la logique du pipeline au moment de l'exécution.
Le résultat est constitué de tables bronze et silver prêtes pour la production, avec des transformations cohérentes, des règles de qualité et un lignage appliqués automatiquement.
{kind=link}
Essayez-le dès aujourd'hui
Pour commencer, nous vous recommandons de lancer une preuve de concept en utilisant vos pipelines déclaratifs Spark existants avec une poignée de sources, en migrant la logique du pipeline vers les métadonnées et en laissant DLT-META orchestrer à grande échelle. Start par une petite preuve de concept et observez comment la métaprogrammation basée sur les métadonnées fait monter en charge vos capacités de Data Engineering au-delà de ce que vous pensiez possible.
Ressources Databricks
- Démarrage : https://github.com/databrickslabs/DLT-META#getting-started
- GitHub : github.com/databrickslabs/DLT-META
- Documentation GitHub : databrickslabs.github.io/DLT-META
- Documentation Databricks : https://docs.databricks.com/aws/en/dlt-ref/DLT-META
- Démos : databrickslabs.github.io/DLT-META/demo
- Dernière version : https://github.com/databrickslabs/DLT-META/releases
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.