monitoring de la qualité des données à grande échelle avec l'IA agentique
Basé sur Unity Catalog pour détecter les problèmes en amont et les résoudre rapidement
• La qualité des données manuelle et basée sur des règles ne monte pas en charge à mesure que les patrimoines de données se développent pour l'analytique et l'IA.
• L'agentic data quality monitoring apprend les modèles de données attendus et détecte les problèmes dans les datasets critiques.
• Les signaux natifs de la plateforme, tels que le lignage de Unity Catalog, aident les équipes à résoudre les problèmes plus rapidement à l'échelle de l'entreprise.
Le défi de la qualité des données à grande échelle
À mesure que les organisations développent davantage de produits de données et d'IA, le maintien de la qualité des données devient plus difficile. Les données alimentent tout, des tableaux de bord pour les dirigeants aux bots Q&A à l'échelle de l'entreprise. Une table obsolète entraîne des réponses dépassées, voire incorrectes, ce qui affecte directement les résultats de l'entreprise.
La plupart des approches en matière de qualité des données ne montent pas en charge pour cette réalité. Les équipes data s'appuient sur des règles définies manuellement et appliquées à un petit ensemble de tables. À mesure que les parcs de données se développent, ils créent des angles morts et limitent la visibilité sur leur état de santé général.
Les équipes ajoutent continuellement de nouvelles tables, chacune avec ses propres modèles de données. La maintenance de vérifications personnalisées pour chaque dataset n'est pas viable. En pratique, seule une poignée de tables critiques sont surveillées, tandis que la plupart du patrimoine de données reste non vérifié.
Par conséquent, les organisations disposent de plus de données que jamais, mais ont moins confiance pour les utiliser.
Présentation du monitoring agentique de la qualité des données
Aujourd'hui, Databricks annonce la préversion publique du monitoring de la qualité des données sur AWS, Azure Databricks et GCP.
Le monitoring de la qualité des données remplace les vérifications manuelles et fragmentées par une approche agentique conçue pour la montée en charge. Au lieu de seuils statiques, les agents d'IA apprennent les modèles de données normaux, s'adaptent au changement et surveillent le patrimoine de données en continu.
L'intégration profonde avec la plateforme Databricks permet plus que de la détection.
- La cause première est directement mise en évidence dans les Lakeflow jobs et les pipelines en amont. Les équipes peuvent passer du monitoring de la qualité des données au job concerné et exploiter les fonctionnalités d'observabilité intégrées de Lakeflow pour obtenir un contexte plus détaillé sur les défaillances et résoudre les problèmes plus rapidement.
- La priorité des problèmes est définie à l'aide du lignage Unity Catalog et des balises certifiées, ce qui garantit que les datasets à fort impact sont traités en premier.
Grâce au monitoring natif de la plateforme, les équipes détectent les problèmes plus tôt, se concentrent sur ce qui est le plus important et résolvent les problèmes plus rapidement à l'échelle de l'entreprise.
« Notre objectif a toujours été que nos données nous indiquent quand il y a un problème. La fonctionnalité Data Quality Monitoring de Databricks y parvient enfin grâce à son approche basée sur l'IA. Elle est parfaitement intégrée à l'UI, monitoring toutes nos tables avec une approche sans intervention et sans configuration, ce qui a toujours été un facteur limitant avec d'autres produits. Au lieu que ce soient les utilisateurs qui signalent les problèmes, nos données les signalent en premier, améliorant ainsi la qualité, la confiance et l'intégrité de notre plateforme. » —Jake Roussis, data engineer principal chez Alinta Energy
Comment fonctionne le monitoring de la qualité des données
Le monitoring de la qualité des données fournit des insights exploitables grâce à deux méthodes complémentaires.
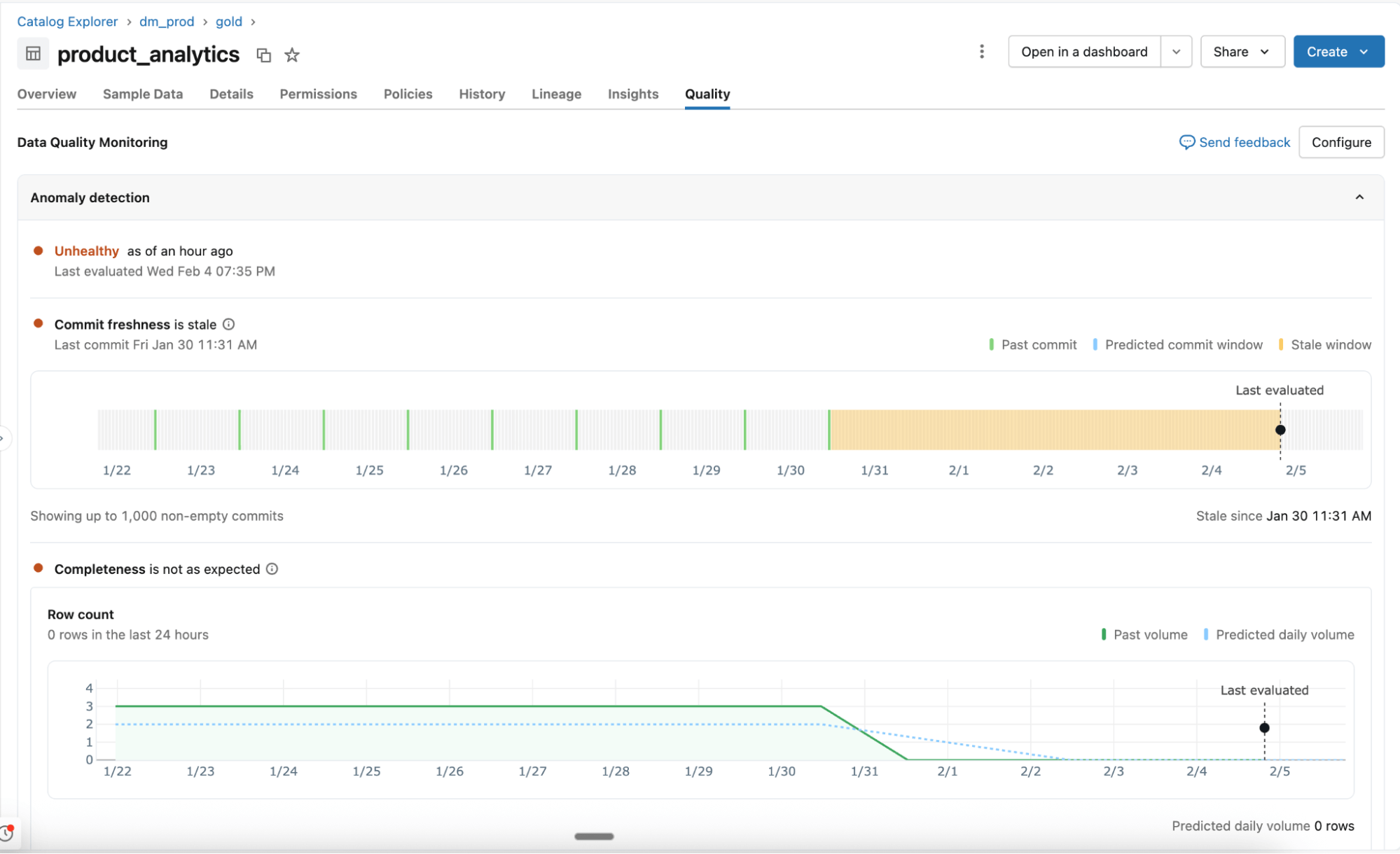
Détection d'anomalies
Activée au niveau du schéma, la détection d'anomalies surveille toutes les tables critiques sans configuration manuelle. Les agents d'IA apprennent les modèles historiques et les comportements saisonniers pour identifier les changements inattendus.
- Comportement appris, et non règles statiques : Les agents s'adaptent aux variations normales et surveillent les signaux de qualité clés tels que la fraîcheur et l'exhaustivité. La prise en charge de vérifications supplémentaires, notamment le pourcentage de valeurs nulles, l'unicité et la validité, sera bientôt disponible.
- Analyse intelligente à grande échelle : Toutes les tables d'un schéma sont analysées une fois, puis réexaminées en fonction de l'importance de la table et de la fréquence des mises à jour. Le lignage et la certification de Unity Catalog déterminent quelles tables sont les plus importantes. Les tables fréquemment utilisées sont analysées plus souvent, tandis que les tables statiques ou obsolètes sont automatiquement ignorées.
- Tables système pour la visibilité et le reporting : La santé des tables, les seuils appris et les schémas observés sont enregistrés dans les tables système. Les équipes utilisent ces données pour les alertes, le reporting et une analyse plus approfondie.
Profilage des données
Activé au niveau de la table, le profilage des données capture des statistiques récapitulatives et suit leurs évolutions au fil du temps. Ces métriques fournissent un contexte historique et seront fournies à la détection d'anomalies afin que vous puissiez détecter facilement les problèmes.
« Chez OnePay, notre mission est d'aider les gens à réaliser des progrès financiers, en leur donnant les moyens d'épargner, de dépenser, d'emprunter et de faire fructifier leur argent. Des données de haute qualité sur l'ensemble de nos datasets sont essentielles pour mener à bien cette mission. Grâce au monitoring de la qualité des données, nous pouvons détecter les problèmes à un stade précoce et prendre rapidement des mesures. Nous sommes en mesure de garantir l'exactitude de nos analytique, de nos rapports et du développement de modèles de ML robustes, ce qui contribue à mieux servir nos clients. » —Nameet Pai, responsable de la plateforme et de l'ingénierie des données chez OnePay
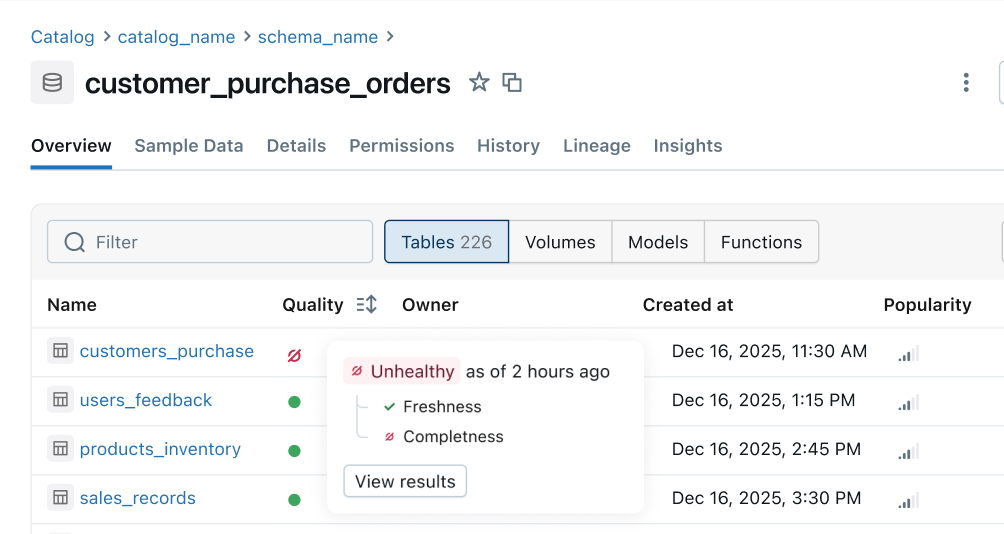
Assurez la qualité d'un patrimoine de données en constante expansion
Avec un monitoring automatisé de la qualité en place, les équipes de la plateforme de données peuvent suivre l'état de santé général de leurs données et garantir la résolution rapide de tout problème.
monitoring agentique en un clic : Surveillez des schémas entiers sans avoir à écrire de règles manuelles ni à configurer de seuils. Le suivi de la qualité des données apprend les modèles historiques et les comportements saisonniers (par ex., baisses de volume le week-end, période des impôts, etc.) pour détecter intelligemment les anomalies dans toutes vos tables.
Vue d'ensemble de l'état de santé des données : Suivez facilement l'état de santé de toutes les tables dans une vue consolidée et assurez-vous que les problèmes sont résolus.
- Problèmes priorisés en fonction de l'impact en aval : Toutes les tables sont priorisées en fonction de leur lignage en aval et du volume de requêtes. Les problèmes de qualité sur vos tables les plus importantes sont signalés en premier.
- Délai de résolution plus rapide : Dans Unity Catalog, la Data quality monitoring retrace les problèmes directement jusqu'aux Lakeflow Jobs en amont et aux Spark Declarative Pipelines. Les équipes peuvent passer du catalogue au Job concerné pour enquêter sur les défaillances spécifiques, les modifications de code et autres causes profondes.
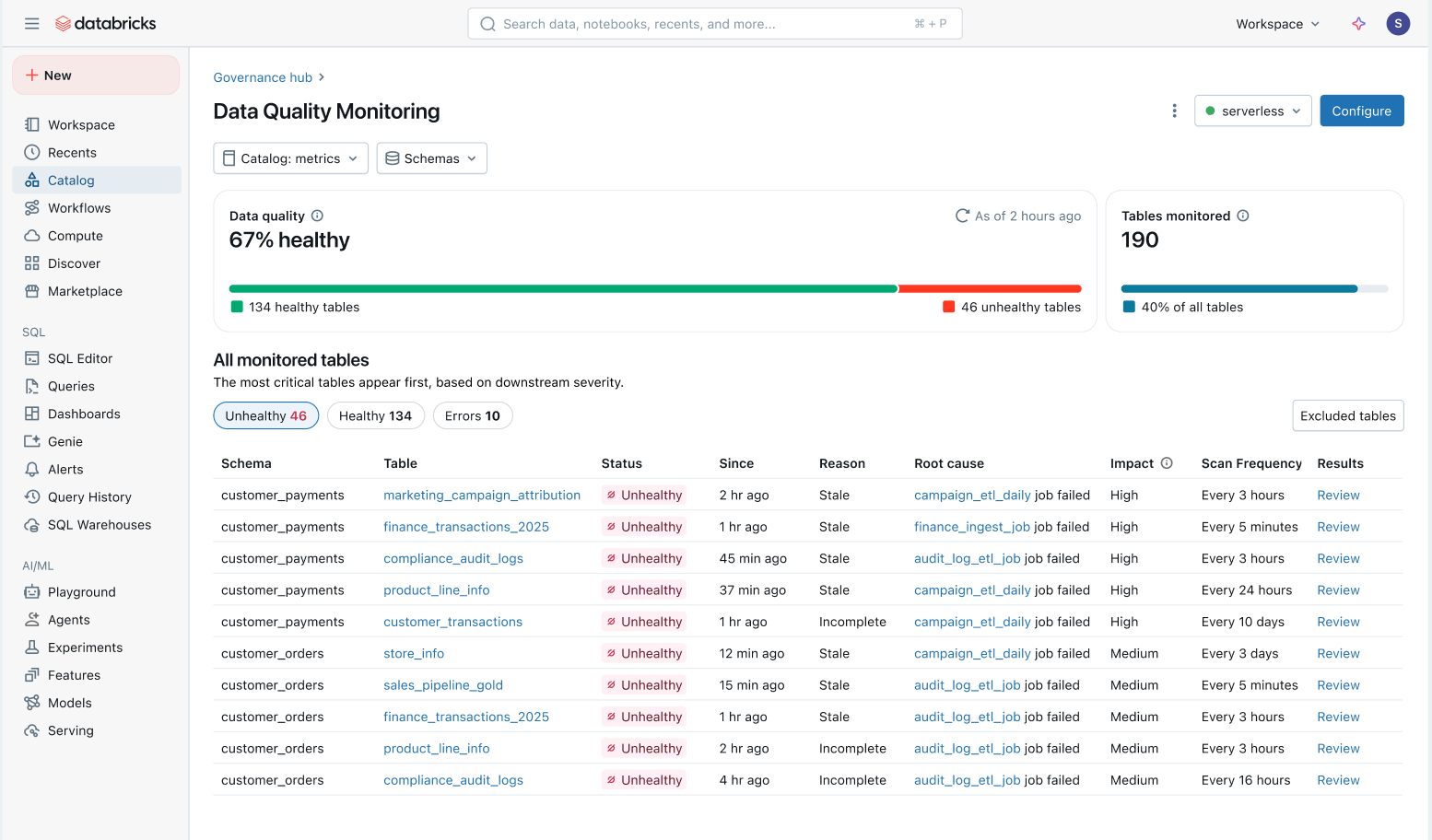
Indicateur de santé : Des signaux de qualité cohérents sont propagés depuis les pipelines en amont vers les surfaces métier en aval. Les équipes Data Engineering sont les premières informées en cas de problème et les consommateurs peuvent instantanément déterminer si les données sont fiables.
Et ensuite
Voici notre feuille de route pour les mois à venir :
- Plus de règles de qualité : Prise en charge de vérifications supplémentaires telles que le pourcentage de valeurs nulles, l'unicité et la validité.
- Alertes automatisées et analyse des causes profondes : Recevez automatiquement des alertes et résolvez rapidement les problèmes grâce à des pointeurs de cause profonde intelligents intégrés directement dans vos jobs et pipelines.
- Indicateur de santé sur l'ensemble de la plateforme: Visualisez des signaux de santé cohérents dans Unity Catalog, Lakeflow Observability, Lineage, Notebooks, Genie, etc.
- Filtrage et mise en quarantaine des données incorrectes : Identifiez de manière proactive les données incorrectes et empêchez-les d'atteindre les consommateurs.
Pour commencer : Aperçu public
Découvrez le monitoring intelligent à grande échelle et construisez une plateforme de données fiable et en libre-service. Essayez la préversion publique dès aujourd'hui :
- Activer le monitoring de la qualité des données depuis la tab Détails du schéma dans Unity Catalog
- Obtenez une vue d'ensemble de toutes les tables surveillées directement dans le produit.
- Configurez des alertes avec ce template
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.