L’évolution de l’ingénierie des données : comment le calcul sans serveur transforme les notebooks, les travaux Lakeflow et les pipelines déclaratifs Spark
Découvrez comment le calcul sans serveur Databricks offre une simplicité, des performances et une fiabilité inégalées pour les notebooks, les tâches Lakeflow et les pipelines déclaratifs Spark.
par Aaron Davidson, Ihor Leshko, Justin Breese, Piyush Singh, Vivek Narasimhan, Prashanth Babu Velanati Venkata, Roland Fäustlin, Hemant Saxena et Mostafa Mokhtar
- Le calcul sans serveur pour les notebooks, les tâches Lakeflow et les pipelines déclaratifs Spark élimine le besoin de gérer l’infrastructure et les mises à niveau Spark.
- Le calcul sans serveur améliore automatiquement les charges de travail et a amélioré les performances de 80 % et le rapport coût-efficacité jusqu’à 70 % au cours de la dernière année sans intervention de l’utilisateur.
- Le calcul sans serveur est désormais le produit de calcul le plus stable de Databricks, dimensionnant automatiquement les clusters pour s’adapter aux volumes de données croissants et protégeant les charges de travail contre les pannes et les ruptures de stock du cloud, ce qui se traduit par 89 % d’exécutions réussies supplémentaires.
L’ingénierie des données a atteint un point d’inflexion. Alors que les organisations s’appuient de plus en plus sur l’IA et le machine learning pour prendre des décisions commerciales, la complexité de la gestion de l’infrastructure de calcul est devenue un goulot d’étranglement critique. Les avancées en matière de calcul serverless Databricks aident les équipes à gagner jusqu’à 20 % de leur temps sur les tâches de routine telles que la mise à niveau des versions de Databricks Runtime (DBR), la gestion des paramètres de cluster et le dépannage des problèmes d’infrastructure. Aujourd’hui, nous sommes ravis de partager plusieurs lancements de fonctionnalités récentes pour le calcul serverless Databricks et la façon dont il a fondamentalement transformé le paradigme en offrant une simplicité, des performances et une fiabilité inégalées pour les Notebooks, les Lakeflow Jobs et les Spark Declarative Pipelines (SDP, anciennement appelés DLT). Par exemple, le calcul serverless offre 70 % d’économies de coûts avec le mode de performance Standard par rapport aux charges de travail optimisées pour les performances, et plus de 50 % d’économies de coûts pour les charges de travail Non-Spark. De plus, les charges de travail optimisées pour les performances démarrent en quelques secondes et s’exécutent généralement deux fois plus vite. Versionless a exécuté 25 mises à niveau de DBR sur plus de 4,5 milliards de charges de travail avec un taux de réussite extraordinaire de 99,998 % au cours de la dernière année.
Le défi de la gestion de l’infrastructure est réel
Chaque plateforme d’ingénierie des données doit gérer un large éventail de responsabilités opérationnelles pour maintenir les clusters Spark traditionnels, telles que :
- Les réseaux doivent être configurés avec des VPC, des passerelles, des plages d’adresses IP et des points de terminaison privés.
- La sécurité et la conformité nécessitent une attention particulière à la gestion des vulnérabilités, au chiffrement et à la protection contre l’exfiltration des données.
- Les considérations d’efficacité, telles que le dimensionnement des instances, l’utilisation, les pools d’instances et l’optimisation Delta, sont essentielles pour exécuter un environnement de données robuste.
- Le maintien des runtimes à jour avec toutes les dernières améliorations de performances est un autre aspect important des opérations de la plateforme. Avec deux versions de support à long terme de DBR chaque année, il est normal que les équipes évaluent les mises à niveau de manière réfléchie pour assurer la stabilité, les performances et la compatibilité avec leurs charges de travail.
Le calcul serverless offre un modèle d’exploitation différent : les tâches fondamentales, comme la mise en réseau et les plages d’adresses IP, le renforcement de la sécurité, la gestion du cycle de vie et les mises à niveau du runtime, sont toutes gérées automatiquement et continuellement optimisées. Cela permet aux équipes d’adopter plus tôt les dernières optimisations et de consacrer plus de temps à la création de produits de données et à la création de valeur commerciale plutôt qu’à la gestion de l’infrastructure.
Calcul serverless : simple, performant, sans maintenance
Le calcul serverless Databricks est un calcul automatique et optimisé géré par Databricks et relève ces défis grâce à trois principes fondamentaux :
- Simple : vous avez juste besoin de choisir si vous voulez que la charge de travail s’exécute rapidement (mode optimisé pour les performances) ou de manière rentable (mode standard). Databricks affine constamment et automatiquement pour atteindre l’objectif sélectionné. Aucun bouton, type d’instance ou sélection de facteur d’échelle n’est nécessaire.
- Performant : Soutenu par l’infrastructure optimisée de Databricks et un nouvel autoscaler, le calcul serverless démarre en quelques secondes, charge les bibliothèques dépendantes en quelques secondes à partir du cache et s’exécute généralement deux fois plus vite que les clusters classiques.
- Sans maintenance : Databricks serverless met automatiquement à l’échelle votre calcul horizontalement et verticalement pour éviter les problèmes de mémoire insuffisante, vous protège des pannes cloud et bascule vers les types d’instances disponibles, ce qui se traduit par un degré élevé de tolérance aux pannes. Il est également sans version, vous mettant automatiquement à niveau vers les dernières améliorations de performances tout en restant entièrement rétrocompatible.
Serverless est simple
Performance et efficacité prêtes à l’emploi
Avec le calcul serverless pour les Notebooks, les Spark Declarative Pipelines et les Lakeflow Jobs, Databricks sélectionne automatiquement la bonne infrastructure pour votre charge de travail, puis l’optimise en permanence en fonction des informations historiques de la charge de travail. Ainsi, les utilisateurs n’ont plus à sélectionner des types d’instances spécifiques, des paramètres d’autoscaler ou des optimisations, telles que Photon. Notre IA détecte automatiquement l’infrastructure et les paramètres qui profiteraient le plus à la charge de travail et les active automatiquement, par exemple, Photon n’est utilisé que lorsque la charge de travail spécifique bénéficie de l’accélération Photon.
Pour les charges de travail qui ne nécessitent pas Spark, notre sélection automatique de l’infrastructure garantit que lorsqu’il n’est pas nécessaire, une machine virtuelle plus petite est provisionnée à la volée. Cette approche peut offrir plus de 50 % d’économies de coûts et un démarrage plus rapide de plus de 33 % par rapport aux clusters classiques, simplement en utilisant uniquement les ressources dont vous avez réellement besoin.
L’introduction de modes de performance pour Lakeflow Jobs et Spark Declarative Pipelines représente une avancée significative dans l’optimisation du calcul, car elle permet aux utilisateurs d’exprimer ce pour quoi Databricks doit optimiser. Le mode optimisé pour les performances démarre en quelques secondes et s’exécute généralement deux fois plus vite que les clusters classiques. Ce mode exploite les pools de machines chaudes et la mise à l’échelle agressive des ressources pour minimiser le temps de traitement, ce qui le rend idéal pour les charges de travail interactives et urgentes.
Le mode Standard, qui est généralement disponible depuis juillet, adopte une approche différente. En optimisant le rapport coût-efficacité plutôt que la vitesse pure, il offre jusqu’à 70 % d’économies de coûts par rapport au mode optimisé pour les performances tout en maintenant des performances compétitives. Ce mode est parfait pour les charges de travail par lots, les tâches planifiées et les pipelines où une latence de démarrage de 4 à 6 minutes est acceptable en échange de réductions de coûts importantes.
Les modes de performance permettent aux utilisateurs de se concentrer sur les informations sur les données et les besoins de l’entreprise spécifiques à leur cas d’utilisation, plutôt que de gérer l’infrastructure. Cette simplicité permet aux utilisateurs de consacrer plus de temps à la génération d’informations à partir des données. Gardez à l’esprit que serverless dans les notebooks interactifs démarre toujours en quelques secondes et s’exécute rapidement pour tirer le meilleur parti du temps des utilisateurs.
| Mode de calcul serverless | Performance typique | Principaux avantages |
|---|---|---|
| Mode interactif pour les Notebooks Meilleure expérience serverless pour la science des données, plateforme entièrement gérée pour les Notebooks Databricks | Démarrage en < 10 secondes, mise à l’échelle rapide |
|
| Mode optimisé pour les performances pour Lakeflow Jobs et SDP Meilleure expérience serverless pour l’ingénierie des données, avec un démarrage et une exécution rapides pour les Lakeflow Jobs et SDP urgents | Démarrage en < 1 minute, mise à l’échelle rapide |
|
| Mode Standard pour Lakeflow Jobs et Pipelines Expérience serverless à moindre coût, plateforme entièrement gérée pour exécuter des Jobs et SDP | Démarrage en 4 à 6 minutes, mise à l’échelle prudente |
|
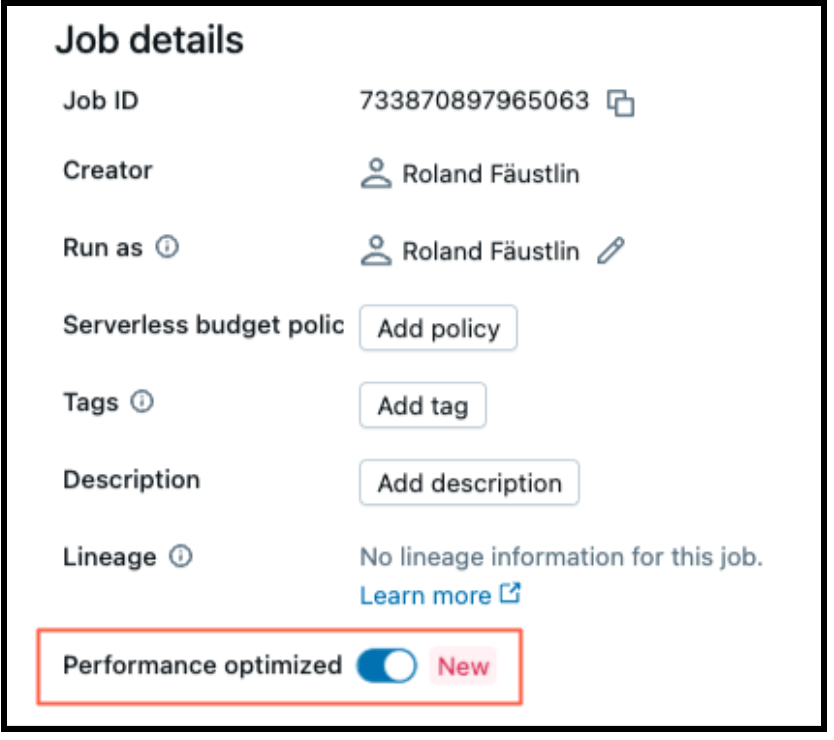
Le calcul serverless permet de régler facilement les performances ou l’efficacité en actionnant un bouton. Lorsque « Optimisé pour les performances » est activé, vos charges de travail démarrent et s’exécutent plus rapidement. Lorsqu’il est désactivé, vos charges de travail s’exécutent en mode « Standard », optimisant ainsi l’efficacité.
Gestion et gouvernance complètes des coûts
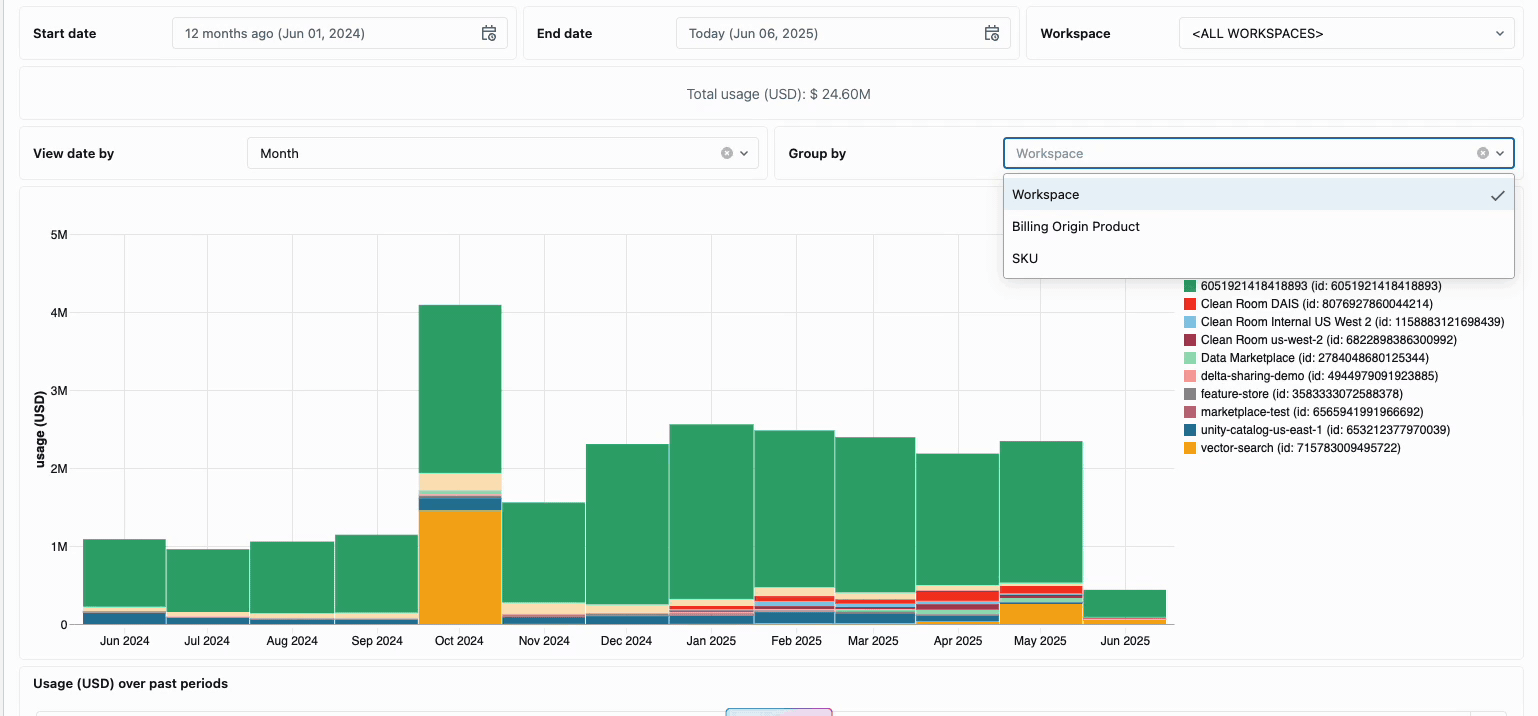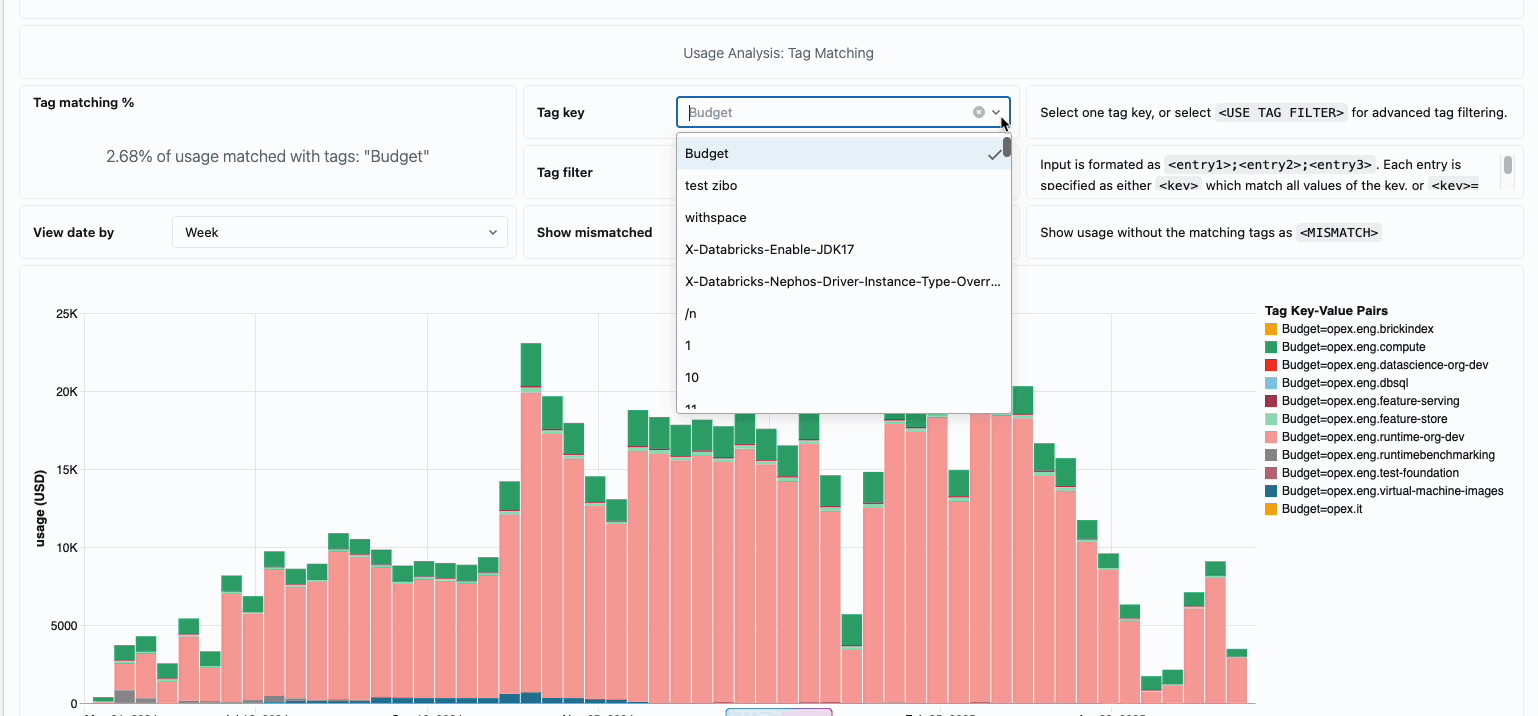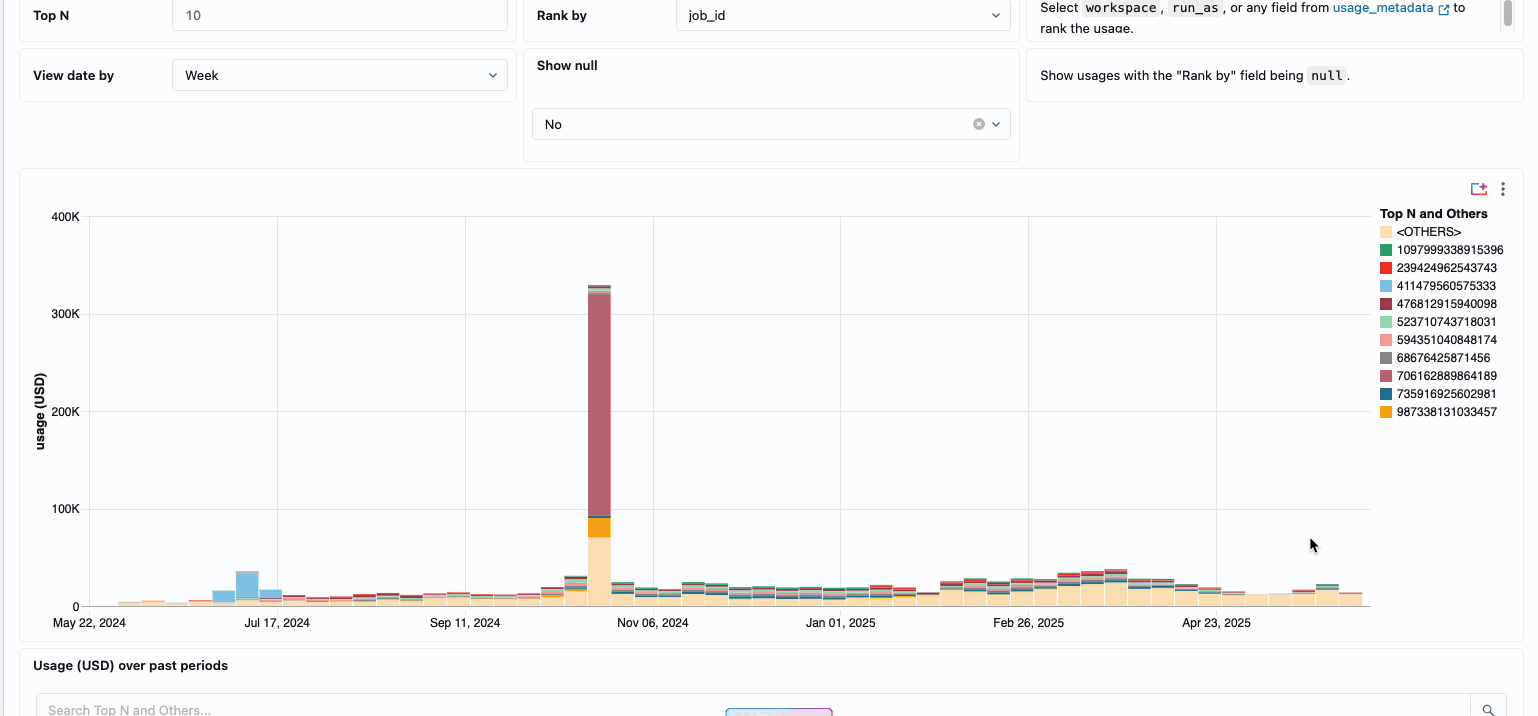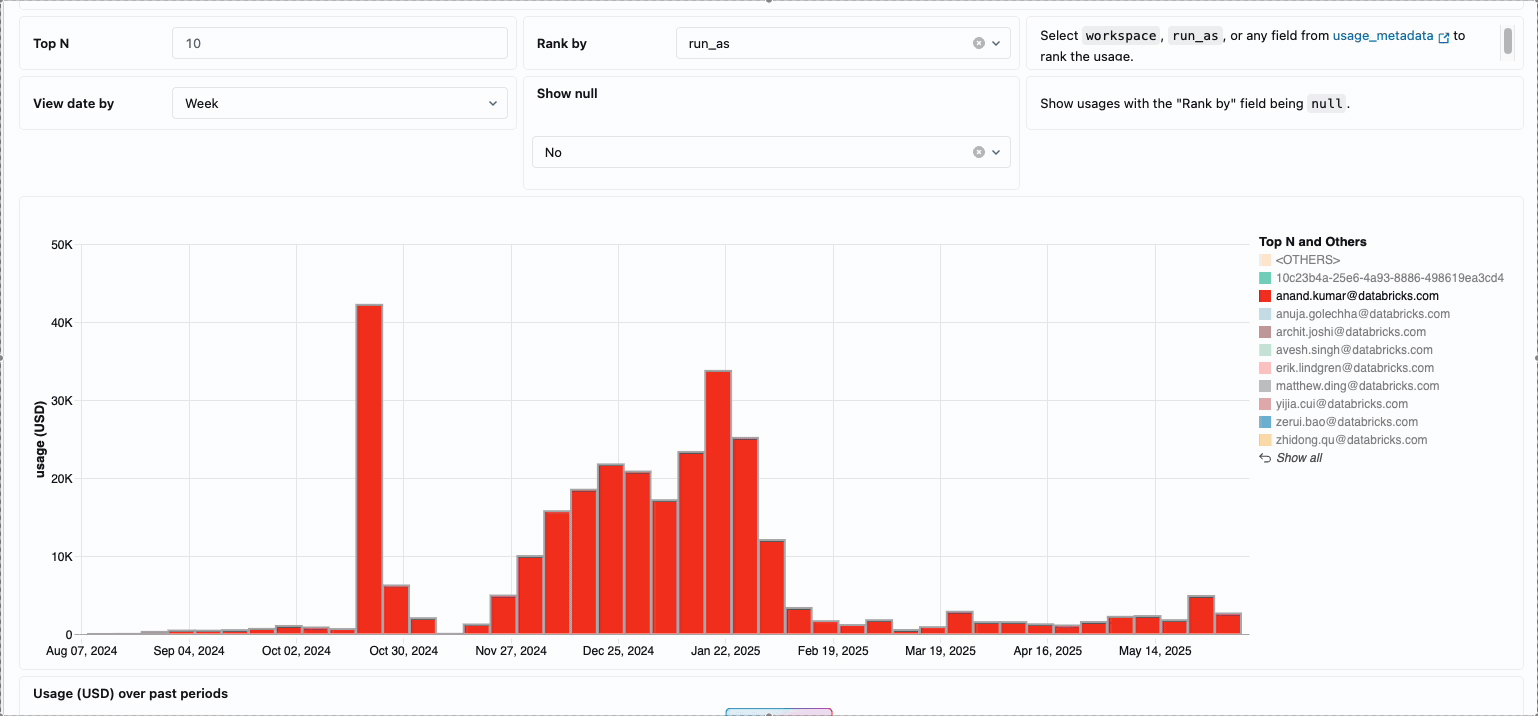
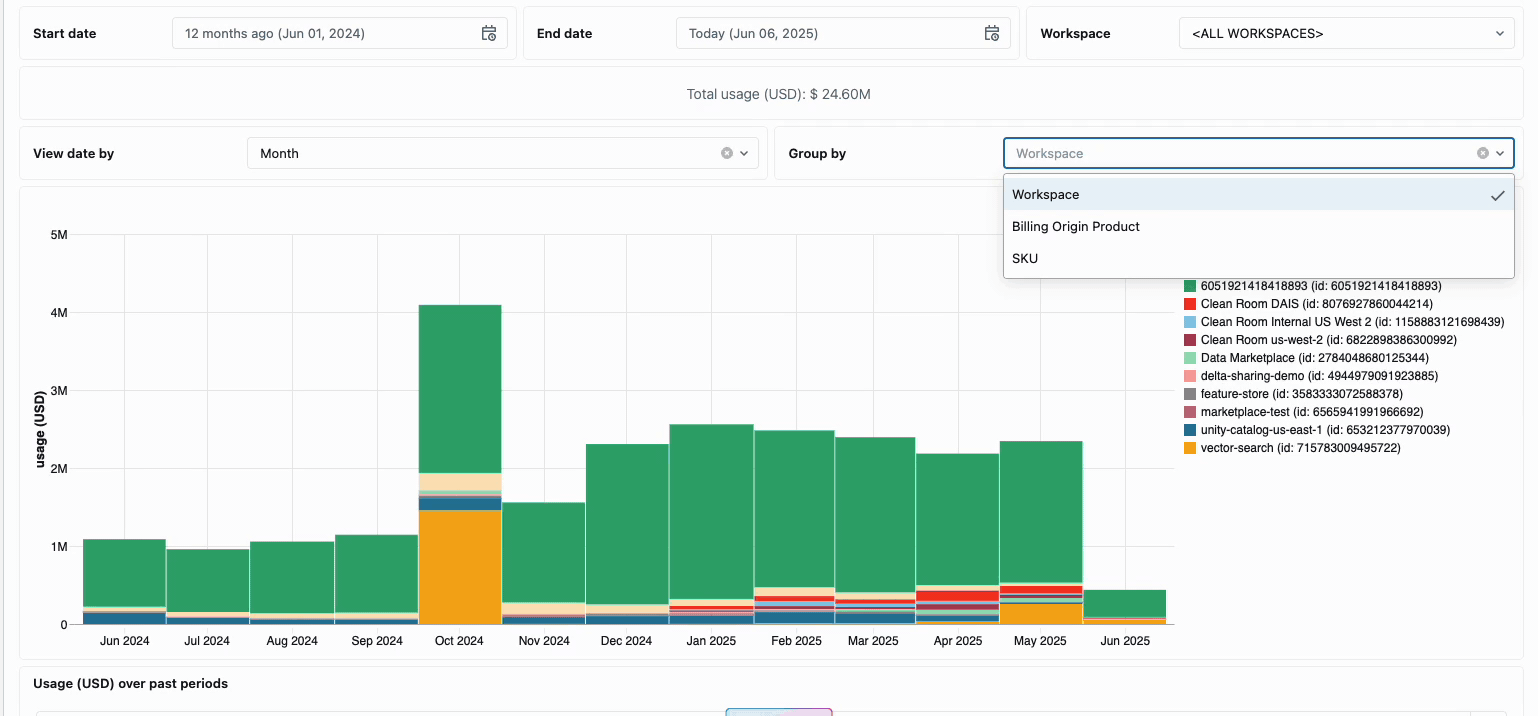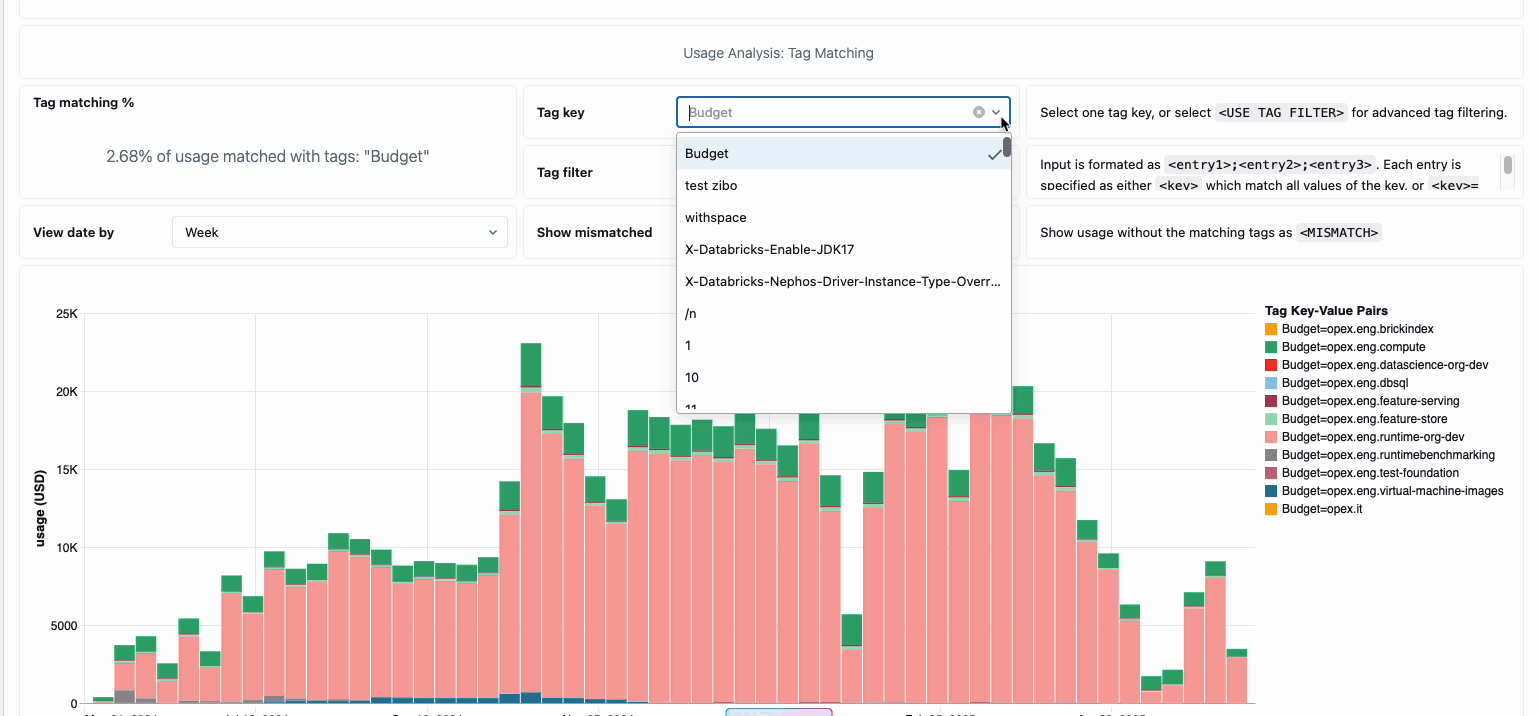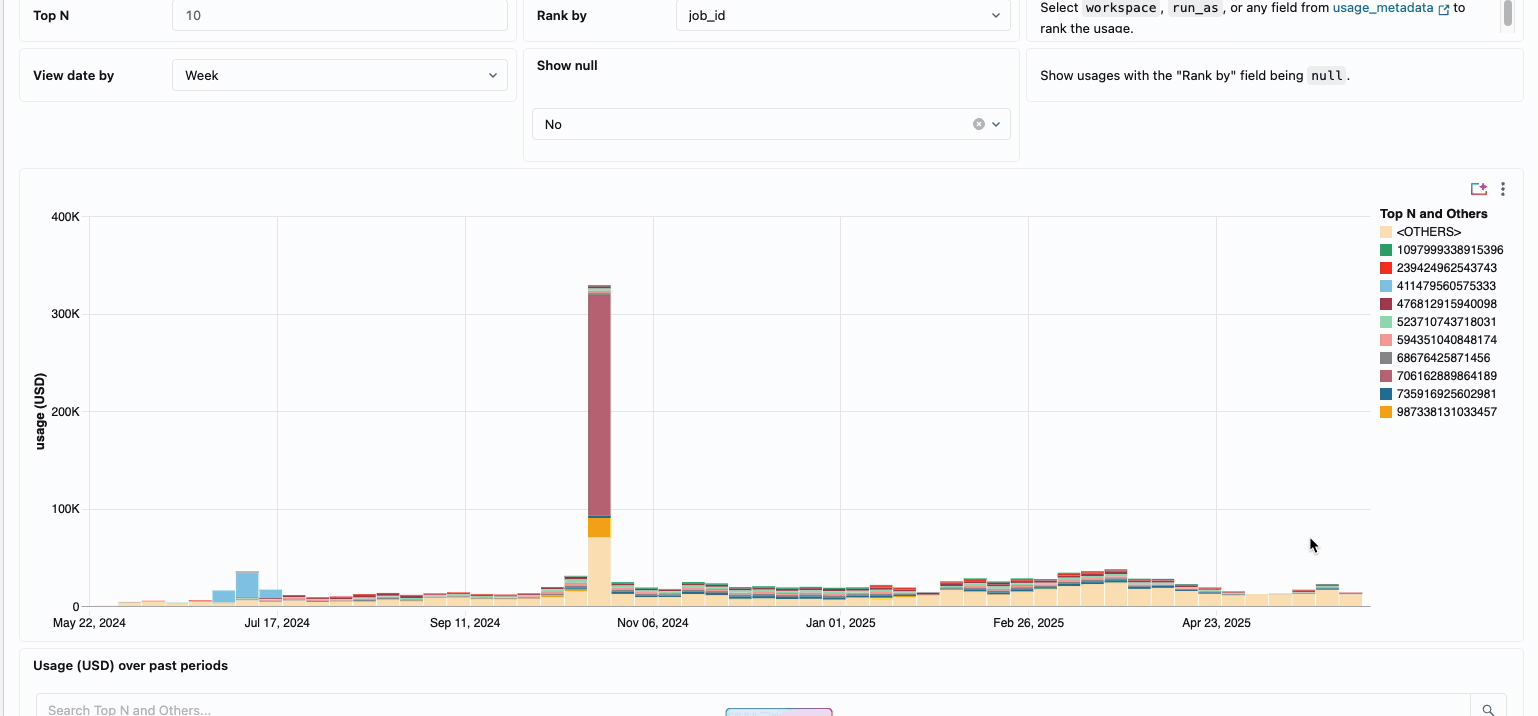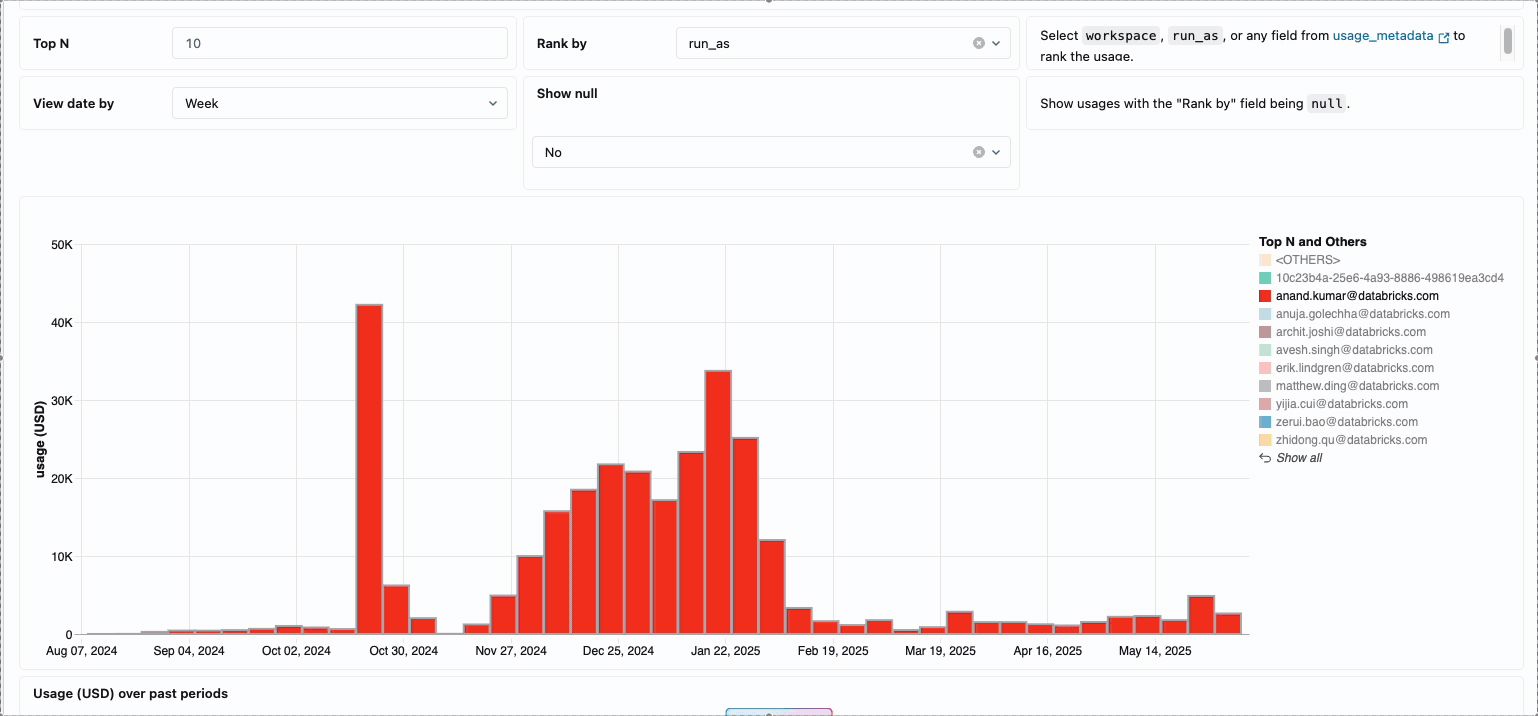
La gestion des coûts de calcul entre les équipes d’ingénierie des données distribuées a traditionnellement nécessité de rassembler des sources de données disparates et des éléments de facturation - un processus fastidieux qui obscurcit souvent le coût total réel de possession. Le calcul serverless transforme cette complexité en clarté grâce à une facturation unifiée, consolidant tous les éléments de coût en une seule vue compréhensible. Les administrateurs bénéficient d’une visibilité instantanée grâce à des tableaux de bord de budget prédéfinis et à des requêtes personnalisables basées sur des tables système, éliminant ainsi le besoin de travaux de rapprochement manuel entre différents fournisseurs de services.
Pour les organisations qui ont besoin de refacturations internes, les stratégies d’utilisation serverless permettent l’application de balises qui agrègent automatiquement les coûts par équipe ou par projet, assurant ainsi une attribution et une responsabilisation précises entre les unités commerciales. La plateforme offre également plusieurs niveaux de protection contre les dépenses accidentelles : des délais d’attente intelligents empêchent les requêtes hors de contrôle d’épuiser les budgets, tandis que des stratégies d’utilisation granulaires donnent aux administrateurs un contrôle précis sur qui peut accéder au calcul serverless et à quel rythme ils peuvent consommer des ressources, créant ainsi un cadre de gouvernance complet qui équilibre l’innovation et la responsabilité financière.
{kind=link}
Serverless : conçu pour la performance
La mise en cache de l’environnement élimine les frais généraux d’installation des dépendances
Les configurations de calcul traditionnelles reposent souvent sur des étapes d’installation pour préparer le bon environnement pour chaque exécution, en particulier lorsque les équipes ont des besoins de bibliothèque divers. Le calcul serverless change cela en utilisant la mise en cache intelligente de l’environnement. Les utilisateurs définissent leur environnement une fois, et Databricks analyse, télécharge et installe automatiquement les bibliothèques nécessaires, puis crée un instantané et le met en cache. Les exécutions futures chargent l’environnement à partir du cache en quelques secondes : aucun téléchargement ou installation n’est nécessaire. Ceci est particulièrement utile pour les petites charges de travail et est en moyenne 2 fois plus rapide. De nouveaux environnements de base par défaut permettent aux administrateurs de gérer de manière centralisée les environnements préconfigurés pour différentes équipes, simplifiant ainsi les flux de travail pour les analystes, les data scientists et les ingénieurs ML.
Le démarrage est une priorité pour nous, et les Notebooks et Workflows serverless ont fait une énorme différence. Le calcul serverless pour les notebooks le rend facile en un seul clic.—Chiranjeevi Katta, ingénieur de données chez Airbus
Les Spark Declarative Pipelines serverless divisent par deux les temps d’exécution sans compromettre les coûts, améliorent l’efficacité de l’ingénierie et rationalisent les opérations de données complexes, permettant aux équipes de se concentrer sur l’innovation plutôt que sur l’infrastructure dans les environnements de production et de développement. —Cory Perkins, ingénieur principal en données et IA chez Qorvo
En pratique, sur toutes les charges de travail sur Databricks, nous constatons que le calcul serverless est en moyenne 20 % plus rentable que les charges de travail de cluster classiques comparables, et bien que les clients paient leur fournisseur de cloud pour le démarrage des clusters classiques, Databricks ne facture pas le démarrage.
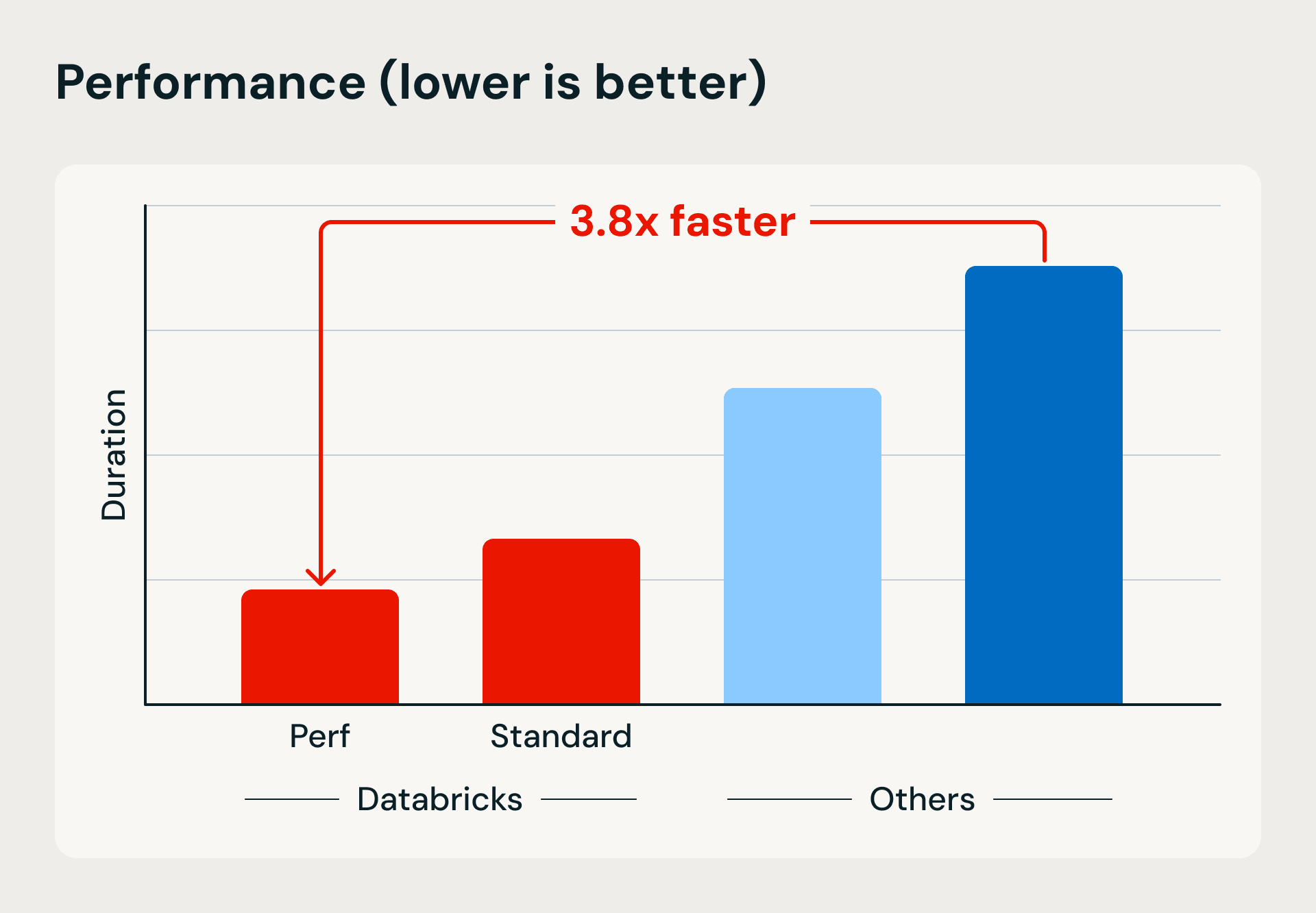
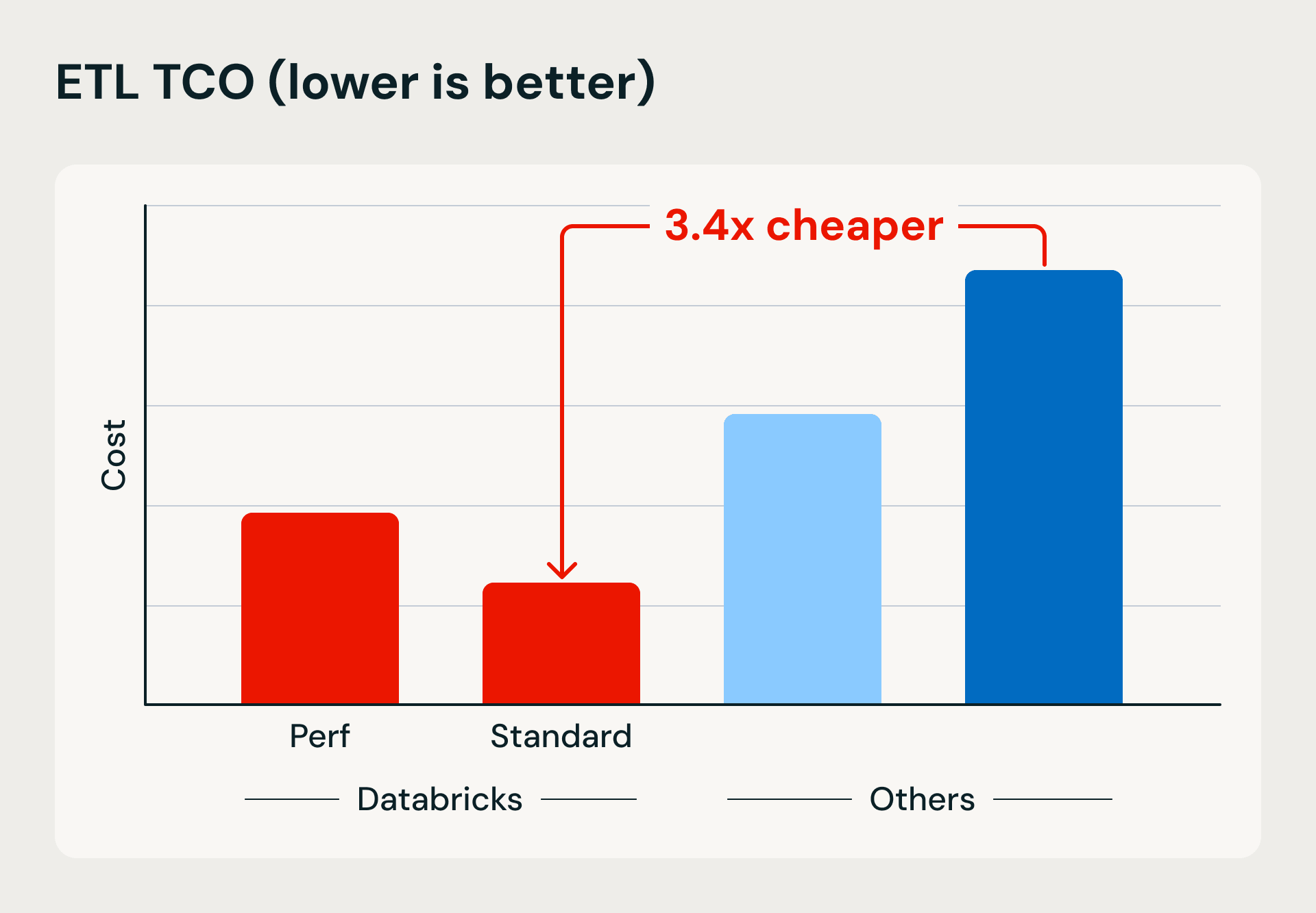
Comparaison des performances et des coûts montrant les avantages du calcul serverless de Databricks en termes de vitesse d’exécution et d’efficacité. Le benchmark charge 1 To dans Bronze à l’aide de Lakeflow Jobs et d’upserts basés sur la fusion, puis affine et déduplique les données dans les tables Silver et Gold.
Après avoir transféré nos pipelines Databricks vers le calcul « serverless », HP a réalisé des économies cloud de plus de 32 % et a diminué le temps d’exécution combiné des tâches de 36 %. La gestion de l’infrastructure sans effort fournie par « serverless » a fait de cette décision un choix évident et stratégique. —Luis Alonso, responsable de la stratégie et de l’ingénierie des données chez HP Marketing
Les Spark Declarative Pipelines serverless sur Google Cloud ont redéfini notre approche chez Uplight, nous permettant d’exécuter des charges de travail ETL plus de deux fois plus rapidement tout en réduisant les coûts. La facilité d’utilisation, l’auto-optimisation et l’efficacité du calcul serverless rendent la mise à l’échelle plus gérable et nous permettent de donner la priorité à la création de valeur pour nos clients. —Micaela Christopher, directrice de la science des données et de l’ingénierie chez Uplight
Historiquement, le passage des données brutes à la couche Silver nous prenait environ 16 minutes, mais après être passé à serverless, ce n’est qu’environ 7 minutes. —Aaron Jepsen, directeur des opérations informatiques chez Jet Linx Aviation
L’amélioration significative du temps de démarrage, combinée à la réduction de la configuration et de la maintenance de DataOps, améliore considérablement la productivité et l’efficacité. —Gal Doron, responsable des données chez AnyClip
Serverless est sans maintenance
Sélection automatique de l’infrastructure : élimination de la gestion manuelle des clusters
L’approche classique de la gestion des clusters offre aux utilisateurs la plus grande liberté dans le choix de l’une des nombreuses combinaisons de configurations possibles et dans l’ajustement de la configuration pour répondre aux exigences changeantes des données et de l’entreprise au fil du temps, y compris la prévention des erreurs de mémoire insuffisante ou des goulots d’étranglement des performances. Le calcul serverless change fondamentalement la donne grâce à la sélection de l’infrastructure par l’IA. Le système surveille en permanence les modèles de charge de travail et l’utilisation des ressources, en augmentant automatiquement la taille des instances en cas de détection de contraintes de mémoire et en basculant de manière transparente vers des types d’instances compatibles lors des pannes du fournisseur de cloud. En tirant parti de l’historique complet des charges de travail et des données de performance en temps réel, le calcul serverless prend des décisions d’infrastructure optimales sans intervention humaine, ce qui entraîne 89 % moins de pannes par rapport aux environnements de calcul classiques. Cette approche automatisée protège non seulement les utilisateurs des limitations du fournisseur de cloud, mais permet également la correction automatique des problèmes d’infrastructure courants, faisant du calcul serverless l’offre de calcul la plus stable et la plus fiable de Databricks.
Avec serverless [...], nous avons réalisé une amélioration de la latence de 3 à 5 fois. Ce qui prenait 10 minutes auparavant ne prend plus que 2 à 3 minutes. —Bryce Dugar, responsable de l’ingénierie des données chez Cincinnati Reds
La disponibilité des options serverless facilite les frais généraux liés à l’ingénierie, à la maintenance et à l’optimisation des coûts. Cette décision s’aligne parfaitement sur notre stratégie globale de migration de tous les pipelines vers des environnements serverless au sein de Databricks. —Bala Moorthy, responsable principal de l’ingénierie des données chez Compass
Mises à niveau sans version pour des améliorations automatiques des performances et de la sécurité
La capacité la plus transformatrice du calcul serverless est peut-être son architecture sans version, qui élimine le besoin de mises à niveau manuelles du runtime (DBR). Se tenir au courant du dernier runtime apporte des améliorations significatives des performances. Le calcul serverless réimagine fondamentalement ce processus grâce à une architecture révolutionnaire qui permet un échange transparent de DBR sans aucune modification destructrice. Au cours de la dernière année seulement, Databricks a effectué automatiquement 25 mises à niveau de DBR sur plus de 4,5 milliards de charges de travail avec un taux de réussite extraordinaire de 99,998 %. Même dans les rares cas où des problèmes sont détectés, les charges de travail sont automatiquement restaurées à la version stable précédente pendant que les problèmes sont résolus en arrière-plan, assurant ainsi des opérations ininterrompues. Les résultats parlent d’eux-mêmes : La combinaison des améliorations de la sélection automatique de l’infrastructure et des mises à niveau sans version a conduit à une amélioration du rapport prix/performance de plus de 80 % en moins d’un an, sans que les utilisateurs aient à toucher la charge de travail. Cette approche sans version signifie que le calcul serverless s’améliore continuellement, offrant automatiquement les dernières optimisations Spark, les correctifs de sécurité et les améliorations de performances, tandis que les équipes d’ingénierie des données se concentrent entièrement sur la création de valeur commerciale plutôt que sur la gestion des mises à niveau de l’infrastructure.
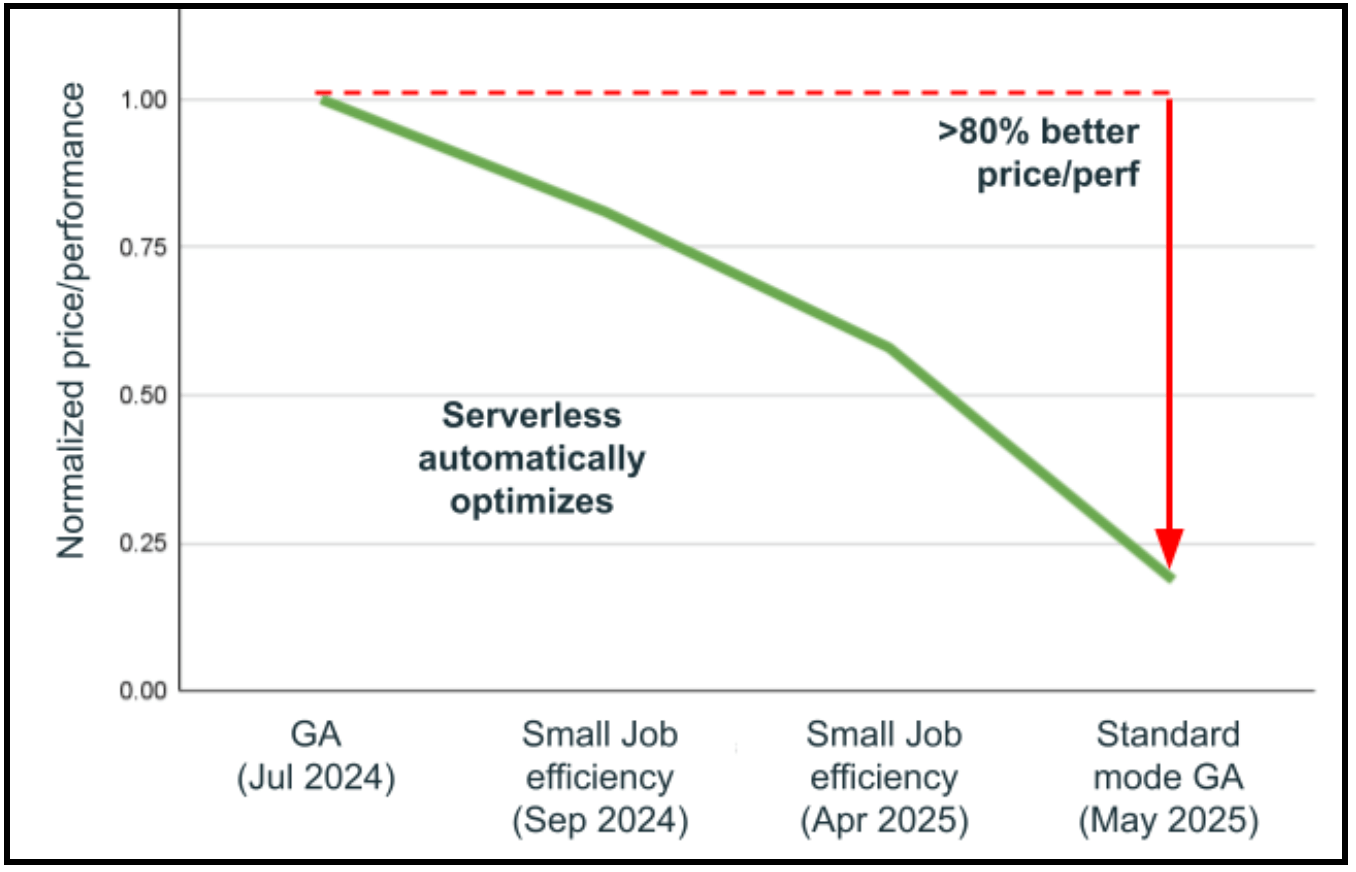
Plus de fonctionnalités serverless
Le calcul serverless offre désormais un ensemble complet de capacités avancées, notamment :
- Les environnements basés sur l’espace de travail permettent aux administrateurs de gérer de manière centralisée les environnements utilisateur avec une mise en cache automatique pour un démarrage rapide.
- La prise en charge des tâches Scala apporte un développement IDE local avec des capacités de déploiement de JAR volumineux.
- La prise en charge du GPU, y compris les A10 et H100, et la prise en charge de SparkML ouvrent serverless au machine learning et aux charges de travail GenAI.
- La suspension et la reprise facilitent grandement le développement et le débogage en permettant de prendre des instantanés des états de calcul actuels et de reprendre le travail plus tard sans perdre de travail et sans avoir à payer pour les clusters.
- Les fonctionnalités améliorées de gestion des coûts comprennent les limites de débit (à venir), la durée de requête prévue avec des avertissements et les tables système étendues pour une analyse détaillée des coûts.
Ces ajouts renforcent la position du calcul serverless en tant que plateforme de calcul la plus performante et la plus intelligente pour l’ingénierie des données - et nous ne faisons que commencer.
Commencez votre parcours serverless dès aujourd’hui
Les preuves sont convaincantes : le calcul serverless représente l’évolution définitive de l’infrastructure de données, offrant une simplicité, une fiabilité et une optimisation des performances sans précédent. Avec le mode Standard généralement disponible et offrant jusqu’à 70 % d’économies de coûts, il n’y a jamais eu de meilleur moment pour passer de la gestion complexe des clusters au calcul intelligent et automatisé. Que vous ayez besoin de l’exécution ultra-rapide du mode optimisé pour les performances ou du rapport coût-efficacité du mode Standard, le calcul serverless élimine la complexité de l’infrastructure tout en améliorant continuellement vos charges de travail grâce à des mises à niveau automatiques de DBR et à des améliorations des performances.
- Inscrivez-vous à un compte Databricks Serverless
- Calcul serverless pour les Notebooks, Lakeflow Jobs et Spark Declarative Pipelines
- Guide du praticien du calcul serverless
- Introduction au SDP
- Démo SDP
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.