Obtenir une vue d'ensemble : unifier les coûts de Databricks et de l'infrastructure cloud
Apprenez à automatiser des tableaux de bord de coûts unifiés que les équipes FinOps et Plateforme veulent réellement utiliser.
par Steven Muschler, Daniel Martinez Arevalo et Sadhana Bala
- La nouvelle solution Cloud Infra Cost Field (disponible pour AWS et Azure) montre comment ingérer, enrichir, joindre et visualiser les données de Databricks et les données de coût cloud associées pour afficher les coûts totaux au niveau du compte, du cluster et même du tag.
- La mise en œuvre de la solution Field offre aux équipes FinOps et Plateforme une vue TCO unique et fiable, leur permettant d'analyser les coûts complets par workspace, charge de travail et unité commerciale pour aligner l'utilisation sur les budgets, en éliminant la réconciliation manuelle et en transformant le reporting des coûts en une capacité opérationnelle permanente.
- Des entreprises comme General Motors ont adopté cette approche pour développer une compréhension globale de leurs coûts Databricks, en s'assurant qu'ils sont visibles et bien compris.
Comprendre le TCO sur Databricks
Il est crucial de comprendre la valeur de vos investissements en IA et en données — pourtant, plus de 52 % des entreprises ne parviennent pas à mesurer rigoureusement le retour sur investissement (ROI) [Futurum]. Une visibilité complète du retour sur investissement nécessite de relier l'utilisation de la plateforme et l'infrastructure cloud afin d'obtenir une vue d'ensemble financière claire. Souvent, les données sont disponibles mais fragmentées, car les plateformes de données actuelles doivent prendre en charge un éventail croissant d'architectures de stockage et de compute.
Sur Databricks, les clients gèrent des environnements multi-cloud, multi-charges de travail et multi-équipes. Dans ces environnements, disposer d'une vue cohérente et complète des coûts est essentiel pour prendre des décisions éclairées.
Au cœur de la visibilité des coûts sur des plateformes comme Databricks se trouve le concept de coût total de possession (TCO).
Sur les plateformes de données multi-cloud, comme Databricks, le TCO se compose de deux composants principaux :
- Les coûts de la plateforme, tels que le compute et le stockage géré, sont des coûts engendrés par l'utilisation directe des produits Databricks.
- Les coûts de l'infrastructure cloud, tels que les machines virtuelles, le stockage et les frais de réseau, sont des coûts engendrés par l'utilisation sous-jacente des services cloud nécessaires pour prendre en charge Databricks.
La compréhension du TCO est simplifiée lors de l'utilisation de produits serverless. Comme le compute est géré par Databricks, les coûts de l'infrastructure cloud sont inclus dans les coûts de Databricks, vous offrant une visibilité centralisée des coûts directement dans les tables système de Databricks (bien que les coûts de stockage resteront imputés au fournisseur de cloud).
La compréhension du TCO pour les produits de compute classiques est cependant plus complexe. Ici, les clients gèrent le compute directement avec le fournisseur de cloud, ce qui signifie que les coûts de la plateforme Databricks et les coûts de l'infrastructure cloud doivent être rapprochés. Dans ces cas, il y a deux sources de données distinctes à résoudre :
- Les tables système (AWS | AZURE | GCP) dans Databricks fourniront des métadonnées opérationnelles au niveau de la charge de travail et sur l'utilisation de Databricks.
- Les rapports de coûts du fournisseur de cloud détailleront les coûts de l'infrastructure cloud, y compris les remises.
Ensemble, ces sources forment la vue complète du TCO. À mesure que votre environnement se développe sur de nombreux clusters, Jobs et comptes cloud, la compréhension de ces datasets devient un élément essentiel de l'observabilité des coûts et de la gouvernance financière.
La complexité du TCO
La complexité du calcul de votre TCO Databricks est accentuée par les différentes manières dont les fournisseurs de cloud présentent et communiquent les données de coût. Comprendre comment joindre ces jeux de données aux tables système pour produire des KPI de coûts précis nécessite une connaissance approfondie des mécanismes de facturation cloud, une connaissance que de nombreux administrateurs de plateforme spécialisés dans Databricks n'ont peut-être pas. Ici, nous examinons en détail la mesure de votre TCO pour Azure Databricks et Databricks sur AWS.
Azure Databricks : exploitation des données de facturation internes
Azure Databricks étant un service de première partie au sein de l'écosystème Microsoft Azure, les frais liés à Databricks apparaissent directement dans Azure Cost Management aux côtés d'autres services Azure, y compris les balises spécifiques à Databricks. Les coûts de Databricks apparaissent dans l'interface utilisateur d'analyse des coûts Azure et en tant que données de gestion des coûts.
Cependant, les données d'Azure Cost Management ne contiendront pas les métadonnées plus détaillées au niveau de la charge de travail ni les métriques de performance présentes dans les tables système de Databricks. Ainsi, de nombreuses organisations cherchent à importer les exports de facturation Azure dans Databricks.
Pourtant, joindre entièrement ces deux sources de données prend du temps et nécessite une connaissance approfondie du domaine, un effort que la plupart des clients n'ont tout simplement pas le temps de définir, de maintenir et de répliquer. Plusieurs défis y contribuent :
- L'infrastructure doit être configurée pour les exportations automatisées des coûts vers ADLS, qui peuvent ensuite être référencées et interrogées directement dans Databricks.
- Les données de coût Azure sont agrégées et actualisées quotidiennement, contrairement aux tables système, dont la mise à jour se compte en heures. Les données doivent donc être soigneusement dédupliquées et les horodatages mis en correspondance.
- La jonction des deux sources nécessite l'analyse des données de balise Azure à haute cardinalité et l'identification de la bonne clé de jointure (par exemple, ClusterId).
Databricks sur AWS : Aligner les coûts de la Marketplace et de l'infrastructure
Sur AWS, bien que les coûts Databricks apparaissent dans le Cost and Usage Report (CUR) et dans AWS Cost Explorer, ils sont représentés à un niveau SKU plus agrégé, contrairement à Azure. De plus, les coûts de Databricks n'apparaissent dans le CUR que lorsque Databricks est acheté via la Marketplace AWS ; dans le cas contraire, le CUR ne reflétera que les coûts d'infrastructure AWS.
Dans ce cas, comprendre comment co-analyser l'AWS CUR avec les tables système est encore plus critique pour les clients disposant d'environnements AWS. Cela permet aux équipes d'analyser les dépenses d'infrastructure, l'utilisation des DBU et les remises, ainsi que le contexte au niveau du cluster et de la charge de travail, créant ainsi une vue plus complète du TCO sur les comptes et régions AWS.
Cependant, la jonction d'AWS CUR avec les tables système peut également s'avérer complexe. Les difficultés courantes sont les suivantes :
- L'infrastructure doit prendre en charge le retraitement récurrent du CUR, car AWS actualise et remplace les données de coût plusieurs fois par jour (sans clé primaire) pour le mois en cours et toute période de facturation antérieure comportant des modifications.
- Les données de coûts AWS couvrent plusieurs types de postes et champs de coûts, ce qui exige de l'attention pour sélectionner le coût effectif correct par type d'utilisation (à la demande, Savings Plan, instances réservées) avant l'agrégation.
- La jointure des données CUR avec les métadonnées de Databricks nécessite une attribution minutieuse, car la cardinalité peut être différente. Par exemple, les clusters partagés polyvalents sont représentés comme une seule ligne d'utilisation AWS, mais peuvent correspondre à plusieurs Jobs dans les tables système.
Simplification des calculs du TCO de Databricks
Dans les environnements Databricks à l'échelle de la production, les questions de coût dépassent rapidement le cadre des dépenses globales. Les équipes veulent comprendre les coûts dans leur contexte : comment l'infrastructure et l'utilisation de la plateforme sont liées aux charges de travail et aux décisions réelles. Les questions courantes sont les suivantes :
- Comment le coût total d'un job serverless se compare-t-il à celui d'un job classique ?
- Quels clusters, jobs et entrepôts sont les plus grands consommateurs de VM gérées dans le cloud ?
- Comment les tendances des coûts montent-elles en charge, se déplacent ou se consolident ?
Répondre à ces questions nécessite de rassembler les données financières des fournisseurs de cloud et les métadonnées opérationnelles de Databricks. Pourtant, comme décrit ci-dessus, les équipes doivent maintenir des pipelines personnalisés et une base de connaissances détaillée sur la facturation cloud et Databricks pour y parvenir.
Pour répondre à ce besoin, Databricks présente la Cloud Infra Cost Field Solution — une solution open source qui automatise l'ingestion et l'analyse unifiée des données d'infrastructure cloud et d'utilisation de Databricks, au sein de la plateforme Databricks.
En fournissant une base unifiée pour l'analyse du TCO sur les environnements de calcul serverless et classiques de Databricks, la solution Field aide les organisations à obtenir une meilleure visibilité des coûts et à comprendre les compromis architecturaux. Les équipes d'ingénierie peuvent suivre les dépenses cloud et les remises, tandis que les équipes financières peuvent identifier le contexte commercial et les responsables des principaux postes de dépenses.
Dans la section suivante, nous vous expliquerons le fonctionnement de la solution et comment démarrer.
Analyse de la solution technique
Bien que les composants puissent avoir des noms différents, la solution Cloud Infra Cost Field pour les clients Azure et AWS partage les mêmes principes et peut être décomposée en plusieurs composants :
- Exporter les données de coût et d'utilisation vers le stockage cloud
- Ingérer et modéliser des données dans Databricks à l'aide de Lakeflow Spark Declarative Pipelines
- Visualisez le TCO complet (coûts de Databricks et des fournisseurs de cloud associés) avec les tableaux de bord d'IA/BI
Les solutions Field pour AWS et Azure sont excellentes pour les organisations qui opèrent au sein d'un seul cloud, mais elles peuvent également être combinées pour les clients Databricks multi-cloud à l'aide de Delta Sharing.
Solution de terrain Azure Databricks
La solution Cloud Infra Cost Field Solution pour Azure Databricks se compose des composants d'architecture suivants :
Architecture de la solution Azure Databricks
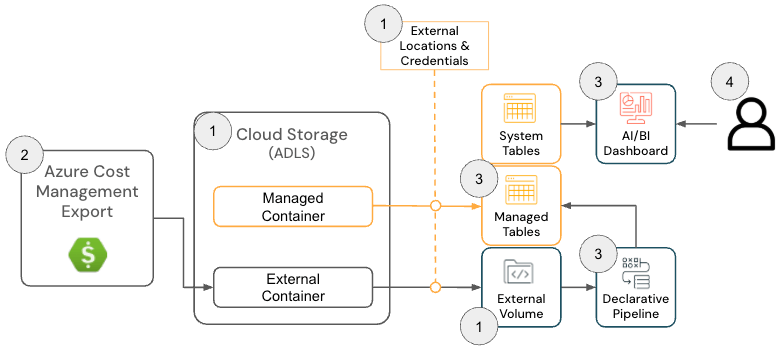
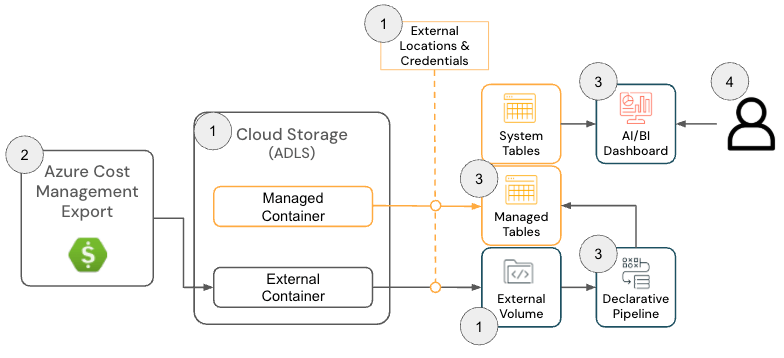{kind=link}
Pour déployer cette solution, les administrateurs doivent disposer des autorisations suivantes sur Azure et Databricks :
- Azure
- Autorisations pour créer une exportation des coûts Azure
- Autorisations de création des ressources suivantes au sein d'un groupe de ressources :
- Databricks
- Autorisation de créer les ressources suivantes :
- Identifiant de stockage
- Emplacement externe
- Autorisation de créer les ressources suivantes :
Le GitHub repository fournit des instructions de configuration plus détaillées ; cependant, à un niveau général, la solution pour Azure Databricks comprend les étapes suivantes :
- [Terraform] Déployer Terraform pour configurer les composants dépendants, notamment un compte de stockage, un emplacement externe et un volume
- L'objectif de cette étape est de configurer un emplacement où les données de facturation Azure sont exportées afin qu'elles puissent être lues par Databricks. Cette étape est facultative s'il existe un Volume préexistant, car l'emplacement d'exportation Azure Cost Management peut être configuré à l'étape suivante.
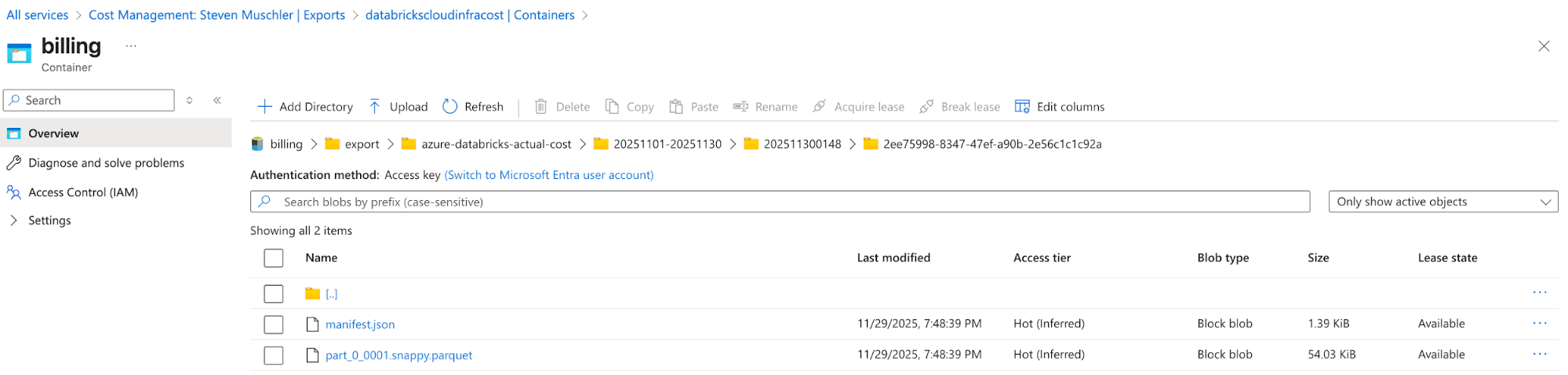
[Azure] Configurez Azure Cost Management Export pour exporter les données de facturation Azure vers le compte de stockage et confirmez que les données s'exportent correctement.
- L'objectif de cette étape est d'utiliser la fonctionnalité d'exportation d'Azure Cost Management pour rendre les données de facturation Azure disponibles dans un format facile à consommer (par ex., Parquet).
Compte de stockage avec l'exportation Azure Cost Management configurée
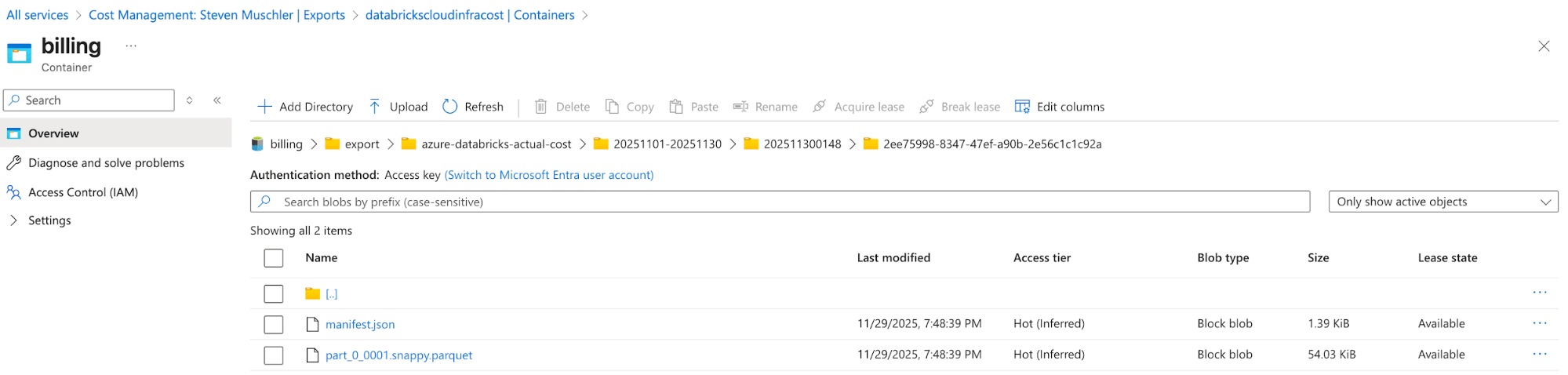
Azure Cost Management Export automatically delivers cost files to this location - [Databricks] Configuration du Databricks Asset Bundle (DAB) pour déployer un Lakeflow Job, un pipeline déclaratif Spark et un tableau de bord IA/BI
- L'objectif de cette étape est d'ingérer et de modéliser les données de facturation Azure pour la visualisation à l'aide d'un tableau de bord d'IA/BI.
- [Databricks] Valider les données dans le tableau de bord AI/BI et valider la tâche Lakeflow
- C'est à cette dernière étape que la valeur se concrétise. Les clients disposent désormais d'un processus automatisé qui leur permet de visualiser le TCO de leur architecture Lakehouse !
{kind=link}
Tableau de bord d'IA/BI affichant le TCO d'Azure Databricks
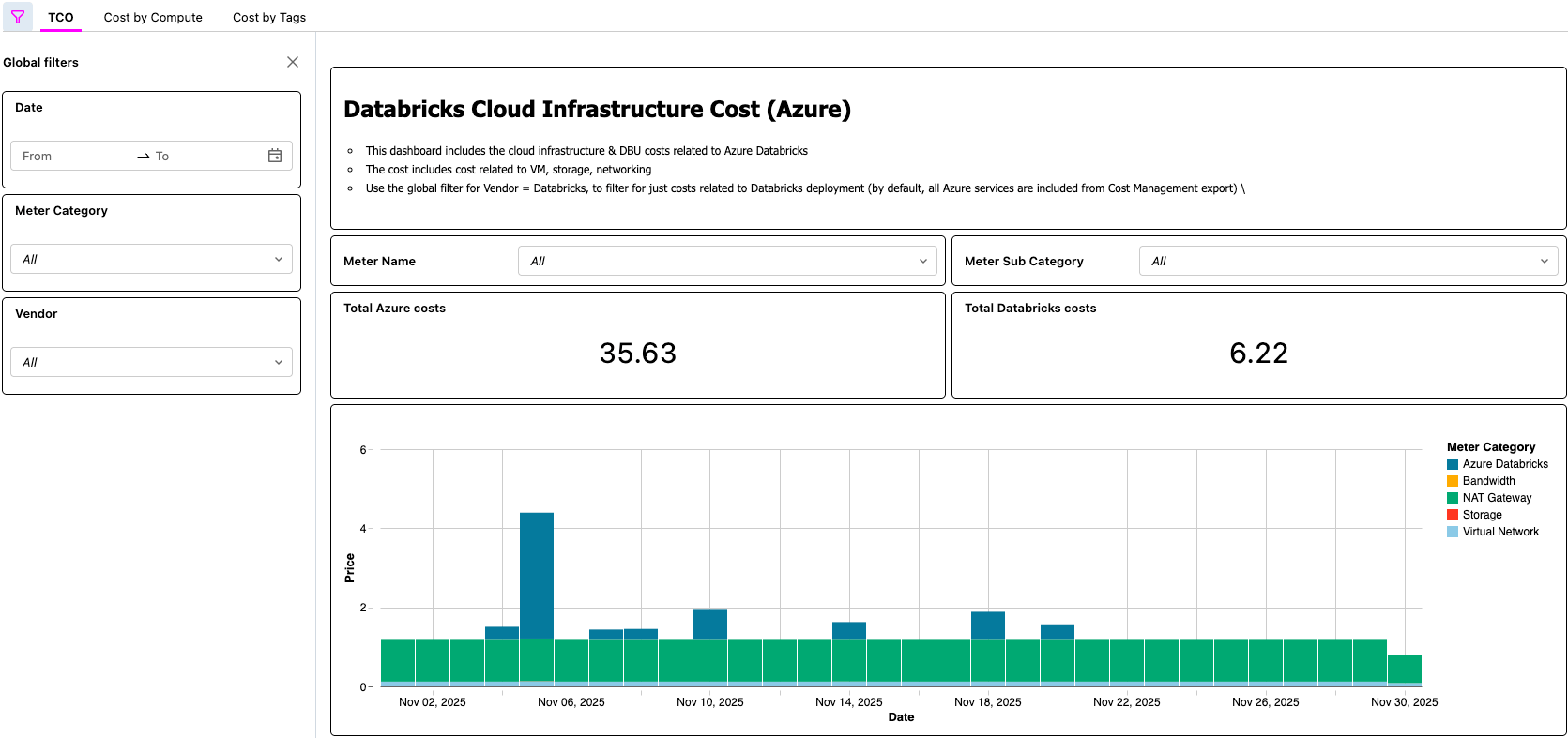
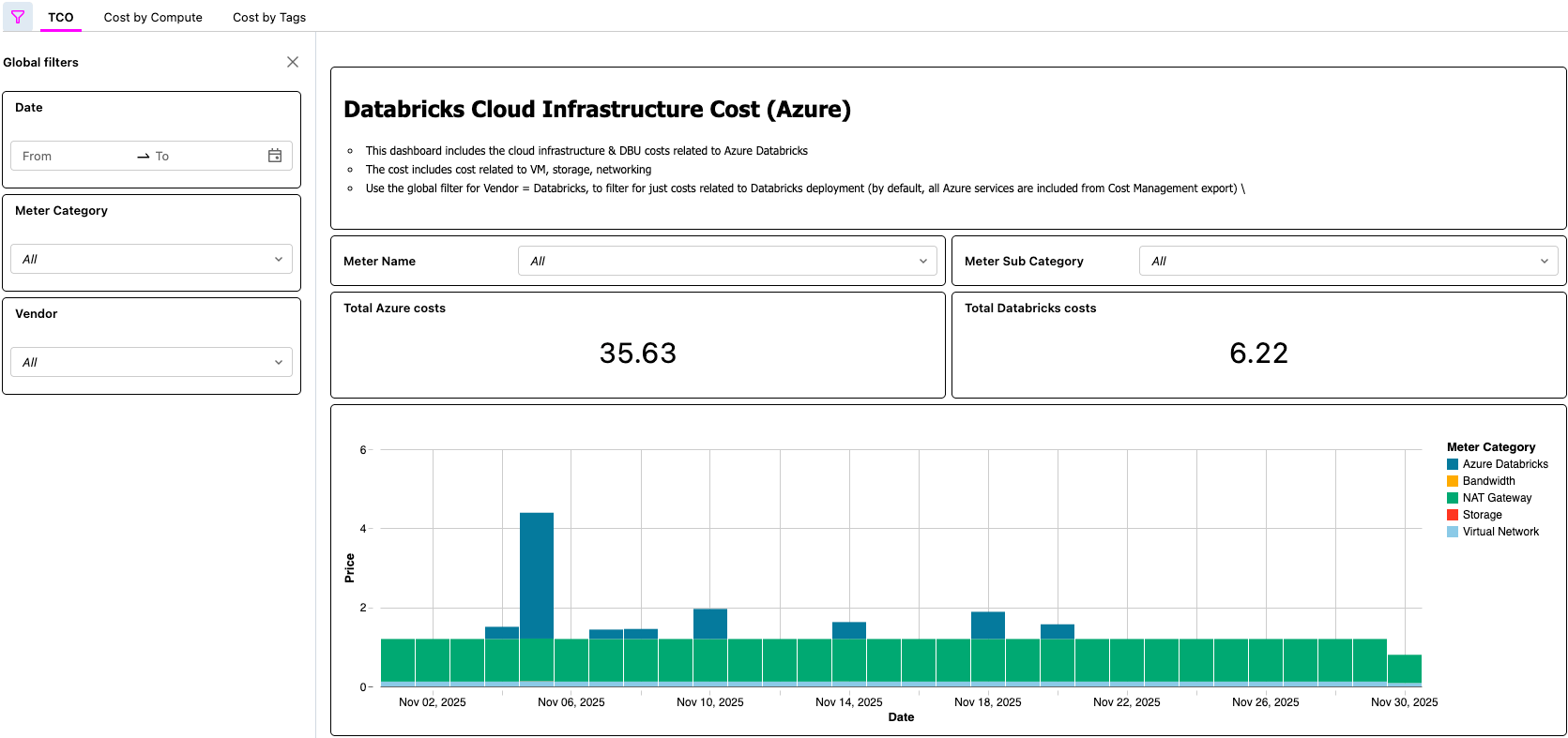{kind=link}
Solution Databricks sur AWS
La solution pour Databricks sur AWS se compose de plusieurs composants d'architecture qui fonctionnent ensemble pour ingérer les données du Cost & Usage Report (CUR) 2.0 d'AWS et les persister dans Databricks à l'aide de l'architecture médaillon.
Pour déployer cette solution, les autorisations et configurations suivantes doivent être en place sur AWS et Databricks :
- AWS
- Autorisations pour créer un CUR
- Autorisations de création d'un bucket Amazon S3 (ou autorisations de déployer le CUR dans un bucket existant)
- Remarque : la solution nécessite AWS CUR 2.0. Si vous avez encore un export CUR 1.0, la documentation AWS fournit les étapes requises pour la mise à niveau.
- Databricks
- Autorisation de créer les ressources suivantes :
- Identifiant de stockage
- Emplacement externe
- Autorisation de créer les ressources suivantes :
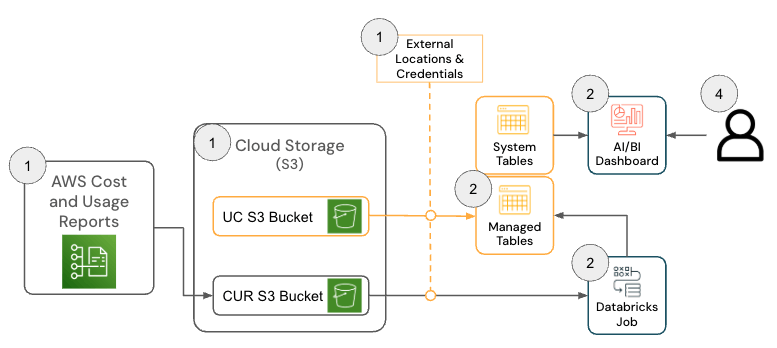
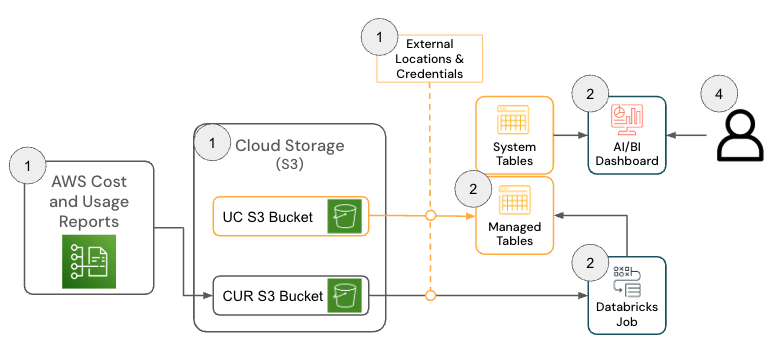{kind=link}
Le repository GitHub fournit des instructions de configuration plus détaillées ; cependant, dans les grandes lignes, la solution pour AWS Databricks comprend les étapes suivantes.
- [AWS] Configuration du rapport AWS Cost & Usage Report (CUR) 2.0
- L'objectif de cette étape est d'exploiter la fonctionnalité AWS CUR afin que les données de facturation AWS soient disponibles dans un format facile à utiliser.
- [Databricks] Configuration du Databricks Asset Bundle (DAB)
- L'objectif de cette étape est d'ingérer et de modéliser les données de facturation AWS afin qu'elles puissent être visualisées à l'aide d'un AI/BI dashboard.
- [Databricks] Examiner le tableau de bord et valider la tâche Lakeflow
- C'est à cette dernière étape que la valeur se concrétise. Les clients disposent désormais d'un processus automatisé qui met à leur disposition le TCO de leur architecture lakehouse !
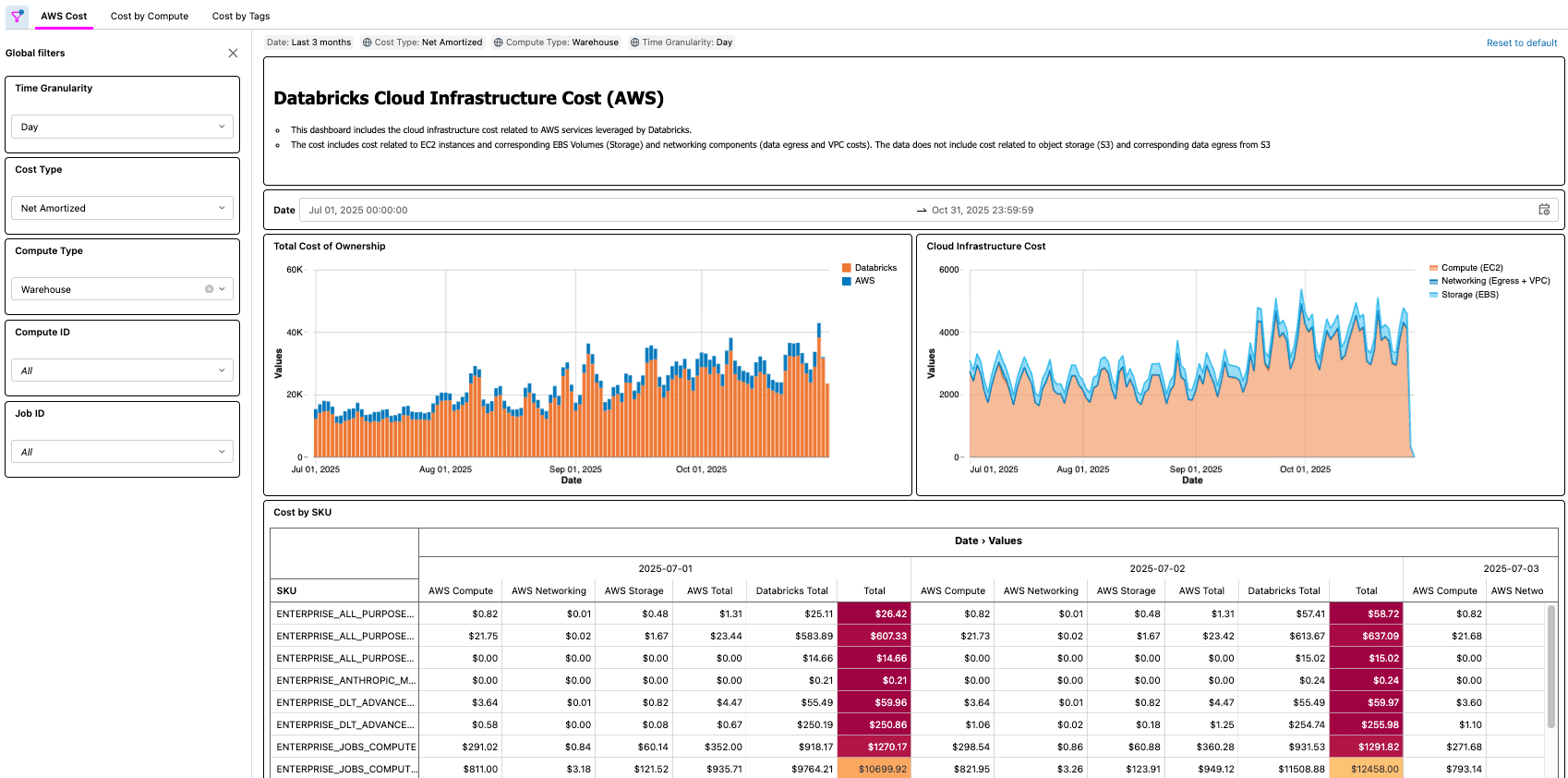
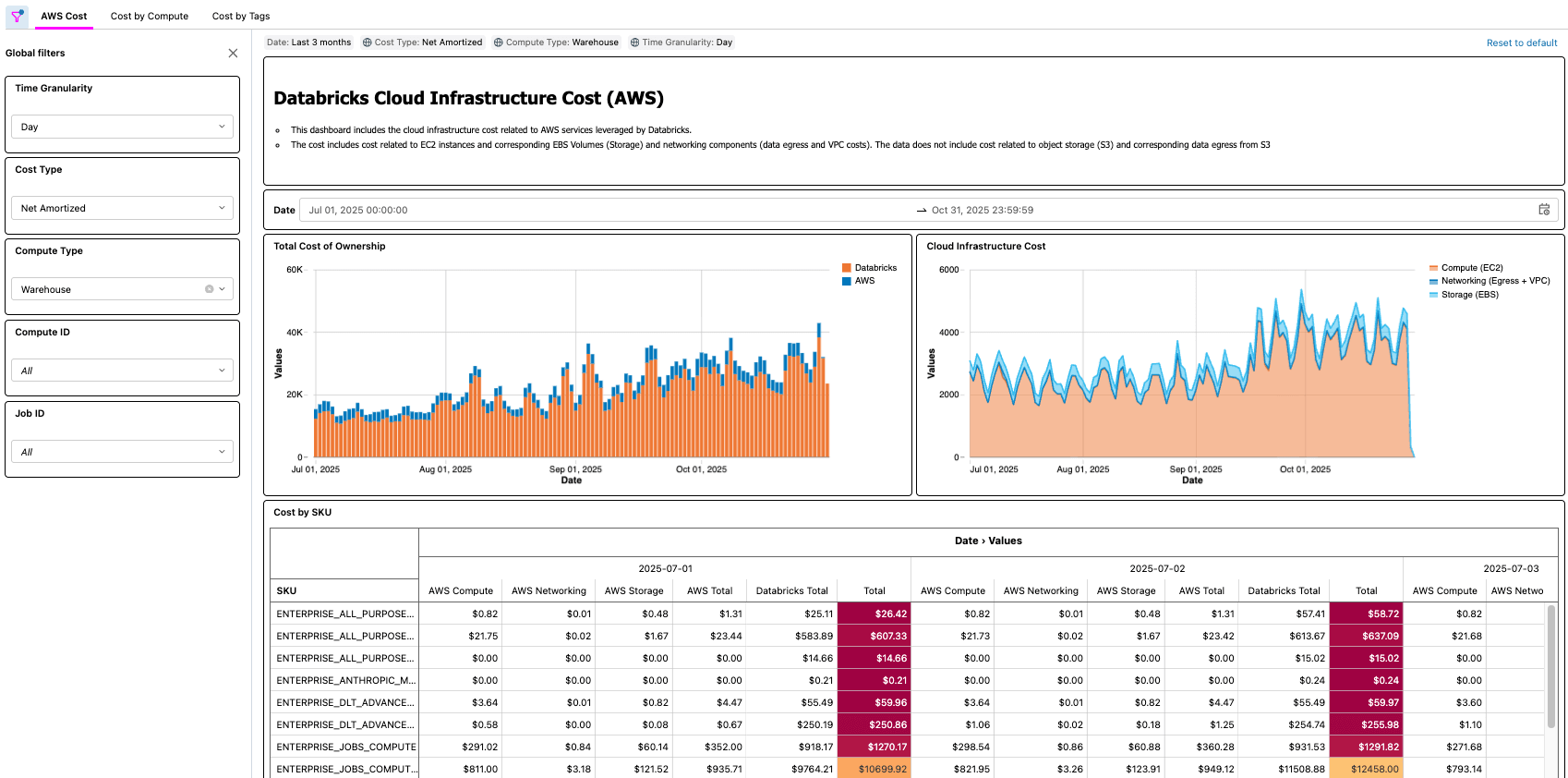{kind=link}
Scénarios réels
Comme le démontrent les solutions Azure et AWS, il existe de nombreux exemples concrets qu'une solution comme celle-ci permet, tels que :
- Identification et calcul des économies totales après l'optimisation d'un job à faible utilisation du processeur et/ou de la mémoire
- Identifier les charges de travail s'exécutant sur des types de VM qui n'ont pas de réservation
- Identification des charges de travail avec des coûts de réseau et/ou de stockage local anormalement élevés
À titre d'exemple pratique, un praticien FinOps dans une grande organisation gérant des milliers de charges de travail peut être chargé de trouver les opportunités d'optimisation les plus évidentes en recherchant des charges de travail qui coûtent un certain montant, mais qui ont également une faible utilisation du processeur et/ou de la mémoire. Étant donné que les informations sur le TCO de l'organisation sont désormais exposées via la solution Cloud Infra Cost Field, le praticien peut alors joindre ces données à la table système Node Timeline (AWS, AZURE, GCP) pour faire apparaître ces informations et quantifier avec précision les économies de coûts une fois les optimisations terminées. Les questions les plus importantes dépendront des besoins métier de chaque client. Par exemple, General Motors utilise ce type de solution pour répondre à bon nombre des questions ci-dessus et plus encore, afin de s'assurer qu'ils tirent le meilleur parti de leur architecture lakehouse.
Points clés
Après avoir mis en œuvre la solution Cloud Infra Cost Field, les organisations obtiennent une vue unique et fiable du TCO qui combine les dépenses de Databricks et de l'infrastructure cloud associée, éliminant le besoin de rapprochement manuel des coûts entre les plateformes. Voici des exemples de questions auxquelles vous pouvez répondre à l'aide de la solution :
- Quelle est la répartition des coûts de mon utilisation de Databricks entre le fournisseur de cloud et Databricks ?
- Quel est le coût total de l'exécution d'une charge de travail, incluant les coûts de VM, de stockage local et de réseau ?
- Quelle est la différence de coût total d'une charge de travail entre une exécution serverless et une exécution sur un compute classique ?
Les équipes de plateforme et FinOps peuvent analyser en détail les coûts complets par workspace, charge de travail et unité commerciale directement dans Databricks, ce qui facilite grandement l'alignement de l'utilisation sur les budgets, les modèles de responsabilité et les pratiques FinOps. Comme toutes les données sous-jacentes sont disponibles sous forme de tables gouvernées, les équipes peuvent créer leurs propres applications de gestion des coûts — des tableaux de bord, des applications internes ou utiliser des assistants IA intégrés comme Databricks Genie— accélérant ainsi la génération d'insight et transformant le FinOps d'un exercice de reporting périodique en une capacité opérationnelle permanente.
Prochaines étapes et ressources
Déployez la solution Cloud Infra Cost Field dès aujourd'hui depuis GitHub (link ici, disponible sur AWS et Azure) et obtenez une visibilité complète sur vos dépenses Databricks totales. Une fois la visibilité complète en place, vous pouvez optimiser vos coûts Databricks, y compris en envisageant le serverless pour la gestion automatisée de l'infrastructure.
Le tableau de bord et le pipeline créés dans le cadre de cette solution offrent un moyen rapide et efficace de commencer à analyser les dépenses Databricks ainsi que le reste de vos coûts d'infrastructure. Cependant, chaque organisation alloue et interprète les frais différemment, vous pouvez donc choisir de personnaliser davantage les modèles et les transformations en fonction de vos besoins. Les extensions courantes incluent la jonction des données sur les coûts d'infrastructure avec des tables système Databricks supplémentaires (AWS | AZURE | GCP) pour améliorer la précision de l'attribution, la création d'une logique pour séparer ou réallouer les coûts de machines virtuelles partagées lors de l'utilisation de pools d'instances, la modélisation différente des réservations de machines virtuelles ou l'incorporation de remplissages historiques pour prendre en charge l'analyse des tendances des coûts à long terme. Comme pour tout modèle de coût d'hyperscaler, il existe une marge de manœuvre considérable pour personnaliser les pipelines au-delà de l'implémentation par défaut afin de les aligner sur les rapports internes, les stratégies de tagging et les exigences FinOps.
Les Delivery Solutions Architects (DSA) de Databricks accélèrent les initiatives de données et d'IA au sein des organisations. Ils assurent le leadership architectural, optimisent les plateformes en termes de coût et de performance, améliorent l'expérience des développeurs et assurent la réussite de l'exécution des projets. Les DSA font le lien entre le déploiement initial et les solutions prêtes pour la production, en travaillant en étroite collaboration avec diverses équipes, notamment l'ingénierie des données, les responsables techniques, les dirigeants et d'autres parties prenantes, afin de garantir des solutions sur mesure et un délai de rentabilisation plus rapide. Pour bénéficier d'un plan d'exécution personnalisé, de conseils stratégiques et d'un soutien de la part d'un DSA tout au long de votre parcours de données et d'IA, veuillez contacter votre équipe de compte Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.