La dette technique cachée des systèmes GenAI
Les coûts cachés de l'IA générative : gérer la prolifération des outils, les pipelines opaques et les évaluations subjectives
par Jeanne Choo et Conor Murphy
- Les développeurs travaillant sur le ML classique et l'IA générative répartissent leur temps très différemment
- L'IA générative introduit de nouvelles formes de dette technique qui doivent être remboursées
- De nouvelles pratiques de développement doivent être introduites pour gérer ces nouvelles formes de dette technique
Introduction
Si l'on compare de manière générale les workflows du machine learning classique et de l'IA générative, on constate que les étapes générales du workflow restent similaires. Les deux requièrent la collecte de données, l'ingénierie des caractéristiques, l'optimisation du modèle, le déploiement, l'évaluation, etc. mais les détails d'exécution et les allocations de temps sont fondamentalement différents. Plus important encore, l'IA générative introduit des sources uniques de dette technique qui peuvent s'accumuler rapidement si elles ne sont pas gérées correctement, notamment :
- Prolifération des outils - difficulté à gérer et à sélectionner parmi la multitude d'outils d'agent
- Prompt stuffing - des prompts excessivement complexes qui deviennent impossibles à maintenir
- Pipelines opaques - le manque de traçage approprié rend le debugging difficile
- Systèmes de feedback inadéquats : ne parviennent pas à recueillir et à utiliser efficacement les retours humains
- Engagement insuffisant des parties prenantes : absence de communication régulière avec les utilisateurs finaux
Dans ce blog, nous aborderons tour à tour chaque forme de dette technique. En fin de compte, les équipes qui passent du ML classique à l'IA générative doivent être conscientes de ces nouvelles sources de dette et adapter leurs pratiques de développement en conséquence, en consacrant plus de temps à l'évaluation, à la gestion des parties prenantes, au monitoring de la qualité subjective et à l'instrumentation plutôt qu'au nettoyage des données et à l'ingénierie des caractéristiques qui dominaient les projets de ML classique.
En quoi les flux de travail du Machine Learning (ML) classique et de l'Intelligence Artificielle (IA) générative sont-ils différents ?
Pour comprendre où en est le domaine aujourd'hui, il est utile de comparer nos workflows pour l'IA générative avec ceux que nous utilisons pour les problèmes de machine learning classique. Voici une vue d'ensemble. Comme le révèle cette comparaison, les grandes étapes du workflow restent les mêmes, mais des différences dans les détails d'exécution font que l'accent est mis sur des étapes différentes. Comme nous le verrons, l'IA générative introduit également de nouvelles formes de dette technique, ce qui a des implications sur la façon dont nous maintenons nos systèmes en production.
| Étape du workflow | ML classique | IA générative |
|---|---|---|
| Collecte de données | Les données collectées représentent des événements du monde réel, tels que les ventes au détail ou les pannes d'équipement. Des formats structurés, tels que CSV et JSON, sont souvent utilisés. | Les données collectées représentent des connaissances contextuelles qui aident un modèle de langage à fournir des réponses pertinentes. Des données structurées (souvent dans des tables en temps réel) et des données non structurées (images, vidéos, fichiers texte) peuvent être utilisées. |
| Ingénierie des fonctionnalités/ Transformation des données | Les étapes de transformation des données impliquent soit la création de nouvelles caractéristiques pour mieux refléter l'espace du problème (par exemple, la création de caractéristiques de jour de semaine et de week-end à partir de données d'horodatage), soit la réalisation de transformations statistiques pour que les modèles s'ajustent mieux aux données (par exemple, la standardisation des variables continues pour le k-means clustering et l'application d'une transformation logarithmique sur des données asymétriques afin qu'elles suivent une distribution normale). | Pour les données non structurées, la transformation implique le découpage en blocs, la création de représentations d'embedding et (éventuellement) l'ajout de métadonnées telles que des en-têtes et des balises aux blocs. Pour les données structurées, elle peut impliquer la dénormalisation des tables afin que les grands modèles de langage (LLM) n'aient pas à prendre en compte les jointures de tables. L'ajout de descriptions de métadonnées de table et de colonne est également important. |
| Conception du pipeline de modèles | Généralement couvert par un pipeline de base en trois étapes :
| Implique généralement une étape de réécriture de la requête, une forme de recherche d'informations, éventuellement un appel d'outil, et des contrôles de sécurité à la fin. Les pipelines sont beaucoup plus complexes, impliquent une infrastructure plus complexe comme des bases de données et des intégrations d'API, et sont parfois gérés avec des structures de type graphe. |
| Optimisation du modèle | L'optimisation du modèle implique l'ajustement des hyperparamètres à l'aide de méthodes telles que la validation croisée, la recherche par grille et la recherche aléatoire. | Bien que certains hyperparamètres, tels que la température, top-k et top-p, puissent être modifiés, la plupart des efforts sont consacrés à l'ajustement des prompts pour guider le comportement du modèle. Puisqu'une chaîne LLM peut comporter de nombreuses étapes, un ingénieur en IA peut également expérimenter la décomposition d'une opération complexe en composants plus petits. |
| Déploiement | Les modèles sont beaucoup plus petits que les modèles de fondation tels que les LLM. Des applications de ML entières peuvent être hébergées sur un CPU sans que des GPU ne soient nécessaires. Le versionnage des modèles, le monitoring et le lignage sont des considérations importantes. Les prédictions de modèle nécessitent rarement des chaînes ou des graphes complexes, les traces ne sont donc généralement pas utilisées. | Comme les modèles de fondation sont très volumineux, ils peuvent être hébergés sur un GPU central et exposés en tant qu'API à plusieurs applications d'IA destinées aux utilisateurs. Ces applications agissent comme des « wrappers » autour de l'API du modèle de fondation et sont hébergées sur des processeurs plus petits. La gestion des versions des applications, le monitoring et la traçabilité sont des considérations importantes. De plus, comme les chaînes et les graphes de LLM peuvent être complexes, un traçage adéquat est nécessaire pour identifier les goulots d'étranglement et les bogues des requêtes. |
| Évaluation | Pour la performance du modèle, les data scientists peuvent utiliser des métriques quantitatives définies telles que le score F1 pour la classification ou l'erreur quadratique moyenne pour la régression. | La justesse d'un résultat de LLM repose sur des jugements subjectifs, par exemple sur la qualité d'un résumé ou d'une traduction. Par conséquent, la qualité de la réponse est généralement jugée selon des lignes directrices plutôt que par des métriques quantitatives. |
Comment les développeurs en Machine Learning répartissent-ils leur temps différemment dans les projets GenAI ?
D'après notre expérience directe, en équilibrant un projet de prévision des prix et un projet de création d'un agent d'appel d'outils, nous avons constaté qu'il existe des différences majeures dans les étapes de développement et de déploiement des modèles.
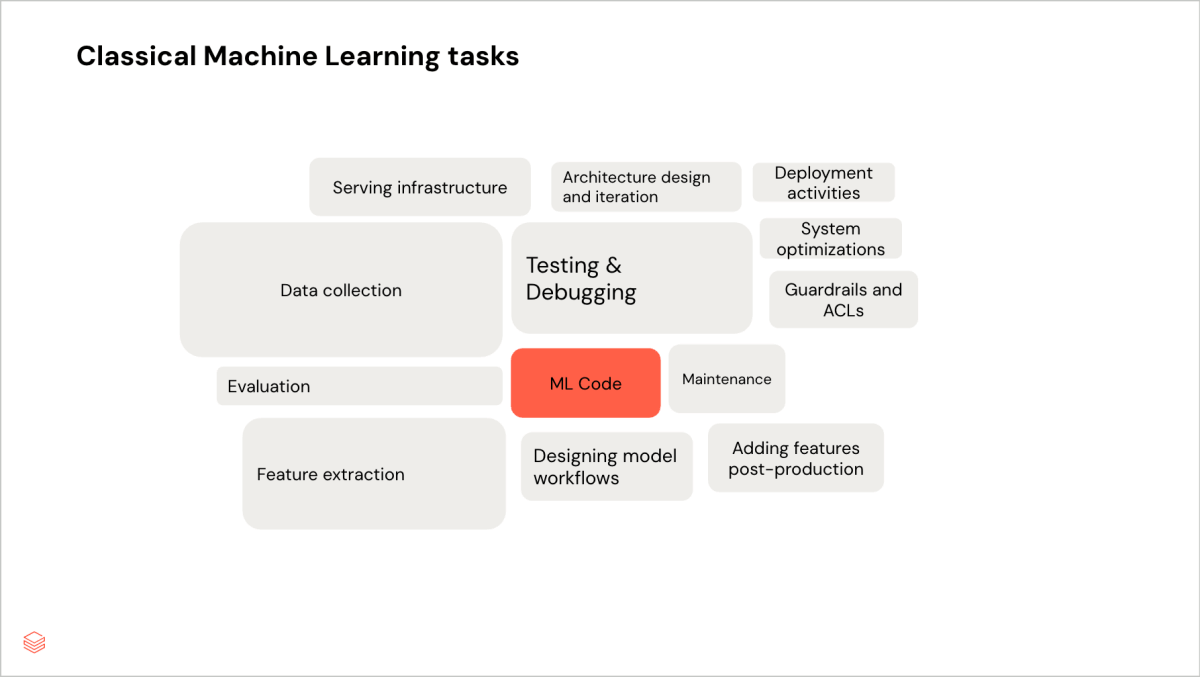
Boucle de développement de modèles
La boucle de développement interne fait généralement référence au processus itératif que les développeurs de machine learning suivent lors de la création et de l'affinage de leurs pipelines de modèles. Cela se produit généralement avant les tests en production et le déploiement du modèle.
Voici comment les professionnels du ML classique et de la GenAI passent leur temps différemment à cette étape :
Les gouffres de temps dans le développement de modèles de ML classique
- Collecte de données et affinement des caractéristiques : Dans un projet de machine learning classique, la plupart du temps est consacré à l'affinement itératif des caractéristiques et des données d'entrée. Un outil de gestion et de partage de caractéristiques, tel que Databricks Magasin de fonctionnalités, est utilisé lorsque de nombreuses équipes sont impliquées, ou lorsqu'il y a trop de caractéristiques à gérer manuellement.
En revanche, l'évaluation est simple : vous exécutez votre modèle, vérifiez l'amélioration de vos métriques quantitatives, puis vous réfléchissez à la manière dont une meilleure collecte de données et de meilleures features peuvent améliorer le modèle. Par exemple, dans le cas de notre modèle de prévision des prix, notre équipe a observé que la plupart des erreurs de prédiction résultaient de la non-prise en compte des données aberrantes. Nous avons alors dû réfléchir à la manière d'inclure des caractéristiques qui représenteraient ces données aberrantes, permettant au modèle d'identifier ces schémas.
Activités chronophages dans le développement de modèles et de pipelines d'IA générative
- Évaluation : sur un projet d'IA générative, la répartition relative du temps entre la collecte et la transformation des données et l'évaluation est inversée. La collecte de données implique généralement de rassembler un contexte suffisant pour le modèle, qui peut se présenter sous la forme de documents de base de connaissances non structurés ou de manuels. Ces données ne nécessitent pas de nettoyage approfondi. Mais l'évaluation est beaucoup plus subjective et complexe, et par conséquent plus chronophage. Vous n'itérez pas seulement sur le pipeline du modèle ; vous devez également itérer sur votre ensemble d'évaluation. Et l'on consacre plus de temps à la gestion des cas limites qu'avec le ML classique.
Par exemple, un ensemble initial de 10 questions d'évaluation peut ne pas couvrir tout l'éventail des questions qu'un utilisateur pourrait poser à un bot d'assistance. Dans ce cas, vous devrez recueillir davantage d'évaluations, ou bien les juges LLM que vous avez configurés sont peut-être trop stricts, si bien que vous devez reformuler leurs prompts pour éviter que les réponses pertinentes n'échouent aux tests. Les Evaluation Datasets de MLflow sont utiles pour le versionnage, le développement et l'audit d'un « ensemble de référence » d'exemples qui doivent toujours fonctionner correctement. - Gestion des parties prenantes : de plus, comme la qualité des réponses dépend des entrées de l'utilisateur final, les ingénieurs passent beaucoup plus de temps à rencontrer les utilisateurs finaux métier et les chefs de produit pour recueillir et hiérarchiser les exigences, ainsi qu'à itérer sur les retours des utilisateurs. Historiquement, le ML classique n'était souvent pas largement destiné aux utilisateurs finaux (par ex. prévisions de séries temporelles) ou était moins exposé aux utilisateurs non techniques, de sorte que les exigences en matière de gestion de produit de l'IA générative sont beaucoup plus élevées. La collecte de retours sur la qualité des réponses peut se faire via une interface utilisateur simple hébergée sur Databricks Apps qui appelle l'API de feedback MLflow. Les retours peuvent ensuite être ajoutés à une trace MLflow et à un dataset d'évaluation MLflow, créant un cercle vertueux entre les retours et l'amélioration du modèle.
Les diagrammes suivants comparent la répartition du temps pour le ML classique et l'IA générative dans la boucle de développement du modèle.

Boucle de déploiement de modèle
Contrairement à la boucle de développement de modèle, la boucle de déploiement de modèle ne se concentre pas sur l'optimisation des performances du modèle. Au lieu de cela, les ingénieurs se concentrent sur les tests systématiques, le déploiement et le monitoring dans les environnements de production.
Ici, les développeurs peuvent déplacer les configurations dans des fichiers YAML pour faciliter les mises à jour du projet. Ils peuvent également refactoriser les pipelines de traitement de données statiques pour qu'ils s'exécutent en streaming, en utilisant un framework plus robuste comme PySpark au lieu de Pandas. Enfin, ils doivent réfléchir à la manière de mettre en place des processus de test, de monitoring et de retour d'information pour maintenir la qualité du modèle.
À ce stade, l'automatisation est essentielle, et l'intégration et la livraison continues sont une exigence non négociable. Pour la gestion du CI/CD pour les projets de données et d'IA sur Databricks, les Databricks Asset Bundles sont généralement l'outil de prédilection. Ils permettent de décrire les Ressources Databricks (telles que les Jobs et les pipelines) en tant que fichiers source et fournissent un moyen d'inclure des métadonnées avec les fichiers source de votre projet.
Comme pour la phase de développement de modèles, les activités qui prennent le plus de temps à ce stade ne sont pas les mêmes pour les projets d'IA générative et de ML classique.
Déploiement de modèles de ML classique : les activités chronophages
- Refactorisation : dans un projet de machine learning classique, le code des Notebooks peut être assez désordonné. Différentes combinaisons de datasets, de fonctionnalités et de modèles sont continuellement testées, abandonnées et recombinées. Par conséquent, un effort important peut être nécessaire pour refactoriser le code des Notebooks afin de le rendre plus robuste. Disposer d'une structure de dossiers de dépôt de code définie (comme le modèle Databricks Asset Bundles MLOps Stacks) peut fournir la structure nécessaire à ce processus de refactorisation.
Voici quelques exemples d'activités de refactorisation :- Abstraction du code auxiliaire en fonctions
- Créer des bibliothèques d'aide pour que les fonctions utilitaires puissent être importées et réutilisées plusieurs fois
- Extraire les configurations des Notebooks dans des fichiers YAML
- Créer des implémentations de code plus performantes qui s'exécutent plus rapidement et plus efficacement (par exemple, en supprimant les boucles
forimbriquées)
- Monitoring de la qualité : le monitoring de la qualité est un autre gouffre à temps, car les erreurs de données peuvent prendre de nombreuses formes et être difficiles à détecter. En particulier, comme le notent Shreya Shankar et al. dans leur article « Operationalizing Machine Learning: An Interview Study » , « Les erreurs douces, telles que quelques caractéristiques à valeur nulle dans un point de données, sont moins pernicieuses et peuvent tout de même donner des prédictions raisonnables, ce qui les rend difficiles à attraper et à quantifier. » De plus, différents types d'erreurs nécessitent des réponses différentes, et déterminer la réponse appropriée n'est pas toujours facile.
Un défi supplémentaire est que différents types de dérive de modèle (comme la dérive des caractéristiques, la dérive des données et la dérive des étiquettes) doivent être mesurés à différentes granularités temporelles (quotidienne, hebdomadaire, mensuelle), ce qui ajoute à la complexité. Pour faciliter le processus, les développeurs peuvent utiliser Databricks Data Quality Monitoring pour suivre les métriques de qualité du modèle, la qualité des données d'entrée et le drift potentiel des entrées et des prédictions du modèle dans un cadre holistique.
Gouffres de temps dans le déploiement de modèles d'IA générative
- Monitoring de la qualité : avec l'IA générative, le monitoring prend également un temps considérable, mais pour des raisons différentes :
- Exigences en temps réel : Les projets de machine learning classiques pour des tâches telles que la prédiction de l'attrition, la prévision des prix ou la réadmission des patients peuvent fournir des prédictions en mode batch, s'exécutant peut-être une fois par jour, une fois par semaine ou une fois par mois. Cependant, de nombreux projets d'IA générative sont des applications en temps réel telles que des agents de support virtuels, des agents de transcription en direct ou des agents de codage. Par conséquent, des outils de monitoring en temps réel doivent être configurés, ce qui implique le monitoring des endpoints en temps réel, des pipelines d'analyse des inférences en temps réel et des alertes en temps réel.
La mise en place de passerelles d'API (telles que Databricks AI Gateway) pour effectuer des vérifications de garde-fous sur l'API LLM peut répondre aux exigences de sécurité et de confidentialité des données. C'est une approche différente du monitoring de modèle traditionnel, qui est effectué comme un processus hors ligne. - Évaluations subjectives : comme mentionné précédemment, les évaluations pour les applications d'IA générative sont subjectives. Les ingénieurs en déploiement de modèles doivent réfléchir à la manière d'opérationnaliser la collecte de commentaires subjectifs dans leurs pipelines d'inférence. Cela peut prendre la forme d'évaluations par juge LLM exécutées sur les réponses du modèle, ou de la sélection d'un sous-ensemble de réponses du modèle à présenter à un expert du domaine pour évaluation. Les fournisseurs de modèles propriétaires optimisent leurs modèles au fil du temps, de sorte que leurs « modèles » sont en fait des services sujets aux régressions et les critères d'évaluation doivent tenir compte du fait que les poids du modèle ne sont pas figés comme ils le sont dans les modèles auto-entraînés.
La capacité à fournir des retours libres et des évaluations subjectives occupe une place centrale. Des frameworks tels que Databricks Apps et l'API de feedback MLflow permettent des interfaces utilisateur plus simples qui peuvent capturer de tels commentaires et les lier à des appels LLM spécifiques.
- Exigences en temps réel : Les projets de machine learning classiques pour des tâches telles que la prédiction de l'attrition, la prévision des prix ou la réadmission des patients peuvent fournir des prédictions en mode batch, s'exécutant peut-être une fois par jour, une fois par semaine ou une fois par mois. Cependant, de nombreux projets d'IA générative sont des applications en temps réel telles que des agents de support virtuels, des agents de transcription en direct ou des agents de codage. Par conséquent, des outils de monitoring en temps réel doivent être configurés, ce qui implique le monitoring des endpoints en temps réel, des pipelines d'analyse des inférences en temps réel et des alertes en temps réel.
- Test : le test est souvent plus chronophage dans les applications d'IA générative, pour plusieurs raisons :
- Défis non résolus : les applications d'IA générative elles-mêmes sont de plus en plus complexes, mais les cadres d'évaluation et de test n'ont pas encore rattrapé leur retard. Certains scénarios qui rendent les tests difficiles incluent :
- Conversations longues à plusieurs tours
- Résultat SQL qui peut ou non saisir les détails importants concernant le contexte organisationnel d'une entreprise
- S'assurer que les bons outils sont utilisés dans une chaîne
- Évaluation de plusieurs agents dans une application
La première étape pour gérer cette complexité consiste généralement à capturer aussi précisément que possible une trace de la sortie de l'agent (un historique d'exécution des appels d'outils, du raisonnement et de la réponse finale). Une combinaison de capture automatique de traces et d'instrumentation manuelle peut fournir la flexibilité nécessaire pour couvrir toute la gamme des interactions des agents. Par exemple, le décorateurtracede MLflow Traces peut être utilisé sur n'importe quelle fonction pour capturer ses entrées et ses sorties. En même temps, des étendues (spans) de traces MLflow personnalisées peuvent être créées dans des blocs de code spécifiques pour enregistrer des opérations plus granulaires. Ce n'est qu'après avoir utilisé l'instrumentation pour agréger une source de vérité fiable à partir des sorties de l'agent que les développeurs peuvent commencer à identifier les modes de défaillance et à concevoir des tests en conséquence.
- Intégration du feedback humain : il est crucial de prendre en compte cette contribution lors de l'évaluation de la qualité. Mais certaines activités sont chronophages. Par exemple :
- Conception de grilles d'évaluation pour que les annotateurs aient des directives à suivre
- Concevoir différentes métriques et différents juges pour différents scénarios (par exemple, un résultat est-il sûr ou est-il utile ?)
Des discussions et des ateliers en personne sont généralement nécessaires pour créer une grille d'évaluation commune sur la manière dont un agent est censé répondre. Ce n'est qu'une fois les annotateurs humains alignés que leurs évaluations peuvent être intégrées de manière fiable dans des juges basés sur des LLM, à l'aide de fonctions comme l'APImake_judgede MLflow ou leSIMBAAlignmentOptimizer.
- Défis non résolus : les applications d'IA générative elles-mêmes sont de plus en plus complexes, mais les cadres d'évaluation et de test n'ont pas encore rattrapé leur retard. Certains scénarios qui rendent les tests difficiles incluent :
Dette technique de l'IA
La dette technique s'accumule lorsque les développeurs implémentent une solution rapide et peu rigoureuse au détriment de la maintenabilité à long terme.
Dette technique du ML classique
Dan Sculley et al. ont fourni un excellent résumé des types de dette technique que ces systèmes peuvent accumuler. Dans leur article « Machine Learning: The High-Interest Credit Card of Technical Debt », ils les répartissent en trois grands domaines :
- Dette de données Dépendances de données mal documentées, non prises en compte ou qui changent silencieusement
- Dette au niveau du système Code de liaison (glue code) étendu, « jungles » de pipelines et chemins « morts » codés en dur
- Modifications externes Modification des seuils (comme le seuil de précision-rappel) ou suppression de corrélations auparavant importantes
L'IA générative introduit de nouvelles formes de dette technique, dont beaucoup peuvent ne pas être évidentes. Cette section explore les sources de cette dette technique cachée.
Prolifération des outils
Les outils sont un moyen puissant d'étendre les capacités d'un LLM. Cependant, à mesure que le nombre d'outils utilisés augmente, ils peuvent devenir difficiles à gérer.
La prolifération des outils ne représente pas seulement un problème de découvrabilité et de réutilisation ; elle peut également affecter négativement la qualité d'un système d'IA générative. Lorsque les outils prolifèrent, deux points de défaillance clés apparaissent :
- Sélection de l'outil : Le LLM doit être capable de sélectionner correctement le bon outil à appeler parmi un large éventail d'outils. Si des outils font des choses à peu près similaires, comme appeler des APIs de données pour des statistiques de Ventes hebdomadaires par rapport aux statistiques mensuelles, il devient difficile de s'assurer que le bon outil est appelé. Les LLM commenceront à faire des erreurs.
- Paramètres de l'outil : Même après avoir sélectionné le bon outil à appeler, un LLM doit encore être capable d'analyser la question d'un utilisateur pour la convertir en l'ensemble de paramètres correct à transmettre à l'outil. C'est un autre point de défaillance à prendre en compte, et cela devient particulièrement difficile lorsque plusieurs outils ont des structures de paramètres similaires.
La solution la plus propre à la prolifération des outils est d'être stratégique et minimaliste avec les outils qu'une équipe utilise.
Cependant, la bonne stratégie de gouvernance peut aider à rendre évolutive la gestion de plusieurs outils et de leur accès, à mesure que de plus en plus d'équipes intègrent la GenAI dans leurs projets et systèmes. Les produits Databricks Unity Catalog et AI Gateway sont conçus pour ce type d'évolutivité.
Prompt stuffing
Même si les modèles de pointe peuvent gérer des pages d'instructions, les prompts trop complexes peuvent entraîner des problèmes tels que des instructions contradictoires ou des informations obsolètes. C'est particulièrement le cas lorsque les prompts ne sont pas modifiés, mais simplement complétés au fil du temps par différents experts du domaine ou développeurs.
À mesure que différents modes de défaillance apparaissent ou que de nouvelles queries sont ajoutées au périmètre, il est tentant de simplement continuer à ajouter de plus en plus d'instructions à un prompt LLM. Par exemple, un prompt peut commencer par fournir des instructions pour traiter les questions liées à la finance, puis s'étendre aux questions relatives aux produits, à Data Engineering et aux ressources humaines.
Tout comme une « classe divine » en génie logiciel n'est pas une bonne idée et devrait être décomposée, les méga-prompts devraient être séparés en plus petits. En fait, Anthropic le mentionne dans son guide d'ingénierie des prompts, et en règle générale, avoir plusieurs prompts plus petits plutôt qu'un seul long et complexe améliore la clarté, la précision et le dépannage.
Les frameworks peuvent aider à garder les prompts gérables en suivant leurs versions et en appliquant les entrées et sorties attendues. Le MLflow Prompt Registry est un exemple d'outil de gestion des versions de prompts, tandis que les optimiseurs de prompts tels que DSPy, qui peuvent être exécutés sur Databricks, permettent de décomposer un prompt en modules autonomes pouvant être optimisés individuellement ou dans leur ensemble.
Pipelines opaques
Ce n'est pas sans raison que le traçage a récemment retenu l'attention, la plupart des bibliothèques LLM et des outils de suivi offrant la possibilité de tracer les entrées et les sorties d'une chaîne LLM. Lorsqu'une réponse renvoie une erreur — le redouté « Je suis désolé, je ne peux pas répondre à votre question » — l'examen des entrées et des sorties des appels LLM intermédiaires est crucial pour identifier la cause première.
J'ai un jour travaillé sur une application pour laquelle j'avais initialement supposé que la génération SQL serait l'étape la plus problématique du workflow. Cependant, l'inspection de mes traces a révélé une tout autre histoire : la plus grande source d'erreurs était en fait une étape de réécriture de requête où nous mettions à jour les entités de la question de l'utilisateur en des entités qui correspondaient à nos valeurs de base de données. Le LLM réécrivait des requêtes qui n'avaient pas besoin de l'être, ou commençait à surcharger la requête d'origine avec toutes sortes d'informations supplémentaires. Cela finissait ensuite régulièrement par perturber le processus de génération SQL ultérieur. Le traçage a aidé ici à identifier rapidement le problème.
Le traçage des bons appels LLM peut prendre du temps. Il ne suffit pas de mettre en œuvre un traçage prêt à l'emploi. Instrumenter correctement une application avec l'observabilité, en utilisant un framework tel que MLflow Traces, est une première étape pour rendre les interactions des agents plus transparentes.
Systèmes inadéquats pour capturer et utiliser les retours humains
Les LLM sont remarquables, car il suffit de leur soumettre quelques prompts simples, d'enchaîner les résultats et d'obtenir au final quelque chose qui semble très bien comprendre les nuances et les instructions. Mais si l'on va trop loin dans cette voie sans ancrer les réponses dans les retours des utilisateurs, la dette de qualité peut s'accumuler rapidement. C'est là que la création d'un « cercle vertueux des données » dès que possible peut être utile, un processus qui se compose de trois étapes :
- Définir les métriques de succès
- Automatiser la mesure de ces métriques, peut-être via une UI que les utilisateurs peuvent utiliser pour donner leur avis sur ce qui fonctionne
- Ajuster de manière itérative les prompts ou les pipelines pour améliorer les métriques
Le développement d'une application texte-SQL pour query des statistiques sportives m'a rappelé l'importance du retour humain. L'expert du domaine a pu expliquer comment un fan de sport voudrait interagir avec les données, en clarifiant ce qui l'intéresserait et en apportant d'autres insights auxquels moi, qui regarde rarement le sport, n'aurais jamais pu penser. Sans leur contribution, l'application que j'ai créée n'aurait probablement pas répondu aux besoins des utilisateurs.
Bien que la collecte des retours humains soit inestimable, elle est généralement terriblement chronophage. Il faut d'abord planifier du temps avec les experts du domaine, puis créer des grilles d'évaluation pour concilier les différences entre eux, et enfin évaluer les commentaires pour apporter des améliorations. Si l'interface utilisateur de feedback est hébergée dans un environnement auquel les utilisateurs professionnels n'ont pas accès, la coordination avec les administrateurs IT pour fournir le bon niveau d'accès peut s'avérer être un processus interminable.
Construire sans points de contrôle réguliers avec les parties prenantes
Consulter régulièrement les utilisateurs finaux, les commanditaires et les équipes adjacentes pour s'assurer que l'on développe le bon produit est un prérequis indispensable pour tout type de projet. Cependant, avec les projets d'IA générative, la communication avec les parties prenantes est plus cruciale que jamais.
Pourquoi une communication fréquente et personnalisée est importante :
- Appropriation et contrôle : Des réunions régulières donnent aux parties prenantes le sentiment de pouvoir influencer la qualité finale d'une application. Plutôt que de simples critiques, ils peuvent devenir de véritables collaborateurs. Bien sûr, tous les retours ne se valent pas. Certaines parties prenantes commenceront inévitablement à demander des choses qu'il est prématuré d'implémenter pour un MVP, ou qui dépassent ce que les LLM peuvent gérer actuellement. Il est important de négocier et d'expliquer à tout le monde ce qui peut et ne peut pas être réalisé. Sinon, un autre risque peut apparaître : trop de demandes de fonctionnalités sans aucun frein.
- Nous ignorons ce que nous ignorons : l'IA générative est si nouvelle que la plupart des gens, techniciens comme non-techniciens, ne savent pas ce qu'un LLM peut ou ne peut pas traiter correctement. Le développement d'une application LLM est un parcours d'apprentissage pour toutes les personnes impliquées, et des points de contact réguliers permettent de tenir tout le monde informé.
Il existe de nombreuses autres formes de dette technique qui peuvent devoir être traitées dans les projets d'IA générative, notamment en appliquant des contrôles d'accès aux données appropriés, en mettant en place des garde-fous pour gérer la sécurité et empêcher les injections de prompts, en évitant que les coûts ne montent en flèche, et plus encore. Je n'ai inclus ici que celles qui semblent les plus importantes et qui pourraient être facilement négligées.
Conclusion
Le ML classique et l'IA générative sont des variantes différentes du même domaine technique. Bien qu'il soit important d'être conscient des différences entre eux et de considérer l'impact de ces différences sur la façon dont nous construisons et maintenons nos solutions, certaines vérités restent constantes : la communication comble toujours les lacunes, le monitoring prévient toujours les catastrophes, et les systèmes propres et faciles à maintenir surpassent toujours les systèmes chaotiques sur le long terme.
Vous voulez évaluer la maturité de votre organisation en matière d'IA ? Lisez notre guide : Libérer la valeur de l'IA : le guide de l'entreprise pour la préparation à l'IA.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.