Feature Flagging à haute disponibilité chez Databricks
Comment nous avons construit un système de feature flags sans interruption pour l'infrastructure mondiale de Databricks
par Benjamin Congdon
- SAFE est la plateforme interne de feature flagging de Databricks qui permet aux ingénieurs de découpler le déploiement de code de l'activation des fonctionnalités, permettant des déploiements plus sûrs et une atténuation plus rapide des incidents sur des centaines de services
- Cet article décrit l'architecture de SAFE, qui gère plus de 25 000 flags actifs et plus de 300 millions d'évaluations par seconde avec une latence de l'ordre de la microseconde grâce à des techniques comme la pré-évaluation de dimension statique et la livraison mondiale à plusieurs niveaux.
- Le système atteint une haute fiabilité grâce à des mécanismes de résilience à plusieurs couches, y compris un comportement de type fail-static, des chemins de livraison hors bande et des paquets de configuration pour le démarrage à froid qui garantissent que les services continuent de fonctionner même pendant les pannes du pipeline de livraison.
Livrer rapidement des solutions tout en maintenant leur fiabilité est une tension constante. À mesure que Databricks s'est développée, la complexité du déploiement sécurisé des changements sur des centaines de services, plusieurs clouds et des milliers de charges de travail client a également augmenté. Les feature flags nous aident à gérer cette complexité en séparant la décision de déployer le code de celle de l'activer. Cette séparation permet aux ingénieurs d'isoler les défaillances et d'atténuer les incidents plus rapidement, sans sacrifier la vitesse de déploiement.
L'un des composants clés du dispositif de stabilité de Databricks est notre plateforme interne de feature flagging et d'expérimentation, appelée "SAFE". Les ingénieurs de Databricks utilisent SAFE au quotidien pour déployer des fonctionnalités, contrôler dynamiquement le comportement des services et mesurer l'efficacité de leurs fonctionnalités avec des expérimentations A/B.
Arrière-plan
SAFE a été lancé avec l'objectif principal de découpler entièrement les publications de binaires de service de l'activation des fonctionnalités, permettant aux équipes de déployer des fonctionnalités indépendamment du déploiement de leurs binaires. Cela offre de nombreux avantages secondaires, comme la possibilité de déployer progressivement une fonctionnalité de manière fiable auprès de populations d'utilisateurs de plus en plus importantes, et d'atténuer rapidement les incidents provoqués par un déploiement.
À l'échelle de Databricks, qui sert des milliers de clients professionnels sur plusieurs clouds avec un périmètre produit en croissance rapide, nous avions besoin d'un système de feature flagging capable de répondre à nos exigences uniques :
- Normes élevées en matière de sécurité et de gestion du changement. La principale proposition de valeur de SAFE était d'améliorer la stabilité et la posture opérationnelle de Databricks, de sorte que presque toutes les autres exigences en ont découlé.
- Multi-cloud, prestation mondiale transparente sur Azure, AWS et GCP, avec une latence d'évaluation de flag inférieure à la milliseconde pour prendre en charge les services de production à haut throughput et sensibles à la latence.
- Un support transparent pour tous les endroits où les ingénieurs de Databricks écrivent du code, y compris notre plan de contrôle, l'interface utilisateur de Databricks, Databricks Runtime, et le plan de données Serverless de Databricks.
- Une interface suffisamment prescriptive sur les pratiques de publication de Databricks pour rendre les publications de flags courantes "sûres par défaut", mais suffisamment flexible pour prendre en charge un large éventail de cas d'utilisation plus ésotériques.
- Exigences de disponibilité extrêmement rigoureuses, car les services ne peuvent pas être lancés en toute sécurité sans que les définitions de flag soient chargées.
Après un examen attentif de ces exigences, nous avons finalement choisi de construire un système de feature flagging personnalisé et interne. Nous avions besoin d'une solution qui pourrait évoluer en même temps que notre architecture, et qui fournirait les contrôles de gouvernance nécessaires pour gérer les flags en toute sécurité sur des centaines de services et des milliers d'ingénieurs. Atteindre nos objectifs de mise à l'échelle et de sécurité a nécessité une intégration profonde avec notre modèle de données d'infrastructure, nos frameworks de service et nos systèmes de CI.
Fin 2025, SAFE compte environ 25 000 indicateurs actifs, avec 4 000 basculements d'indicateurs par semaine. En période de pointe, SAFE exécute plus de 300 millions d'évaluations par seconde, tout en maintenant une latence p95 d'environ 10 μs pour les évaluations de flags.
Cet article explore la manière dont nous avons conçu SAFE pour répondre à ces exigences et les enseignements que nous en avons tirés.
Les Feature Flags en action
Pour commencer, nous allons discuter d'un parcours utilisateur typique pour un indicateur SAFE. Essentiellement, un feature flag est une variable accessible dans le flux de contrôle d'un service, qui peut prendre différentes valeurs en fonction de conditions contrôlées depuis une configuration externe. Un cas d'usage extrêmement courant pour les feature flags est d'activer progressivement un nouveau chemin de code de manière contrôlée, en commençant d'abord par une petite partie du trafic, puis en l'activant progressivement à l'échelle mondiale.
Les utilisateurs de SAFE commencent par définir leur flag dans le code de leur service et l'utilisent comme une condition d'accès à la logique de la nouvelle fonctionnalité :
L'utilisateur se rend ensuite sur l'interface utilisateur interne de SAFE, enregistre ce flag et sélectionne un modèle pour le déployer. Ce modèle définit un plan de déploiement progressif composé d'une liste d'étapes ordonnées. Chaque étape est progressivement déployée par pourcentages. Une fois le flag créé, l'utilisateur voit une interface utilisateur qui ressemble à ceci :
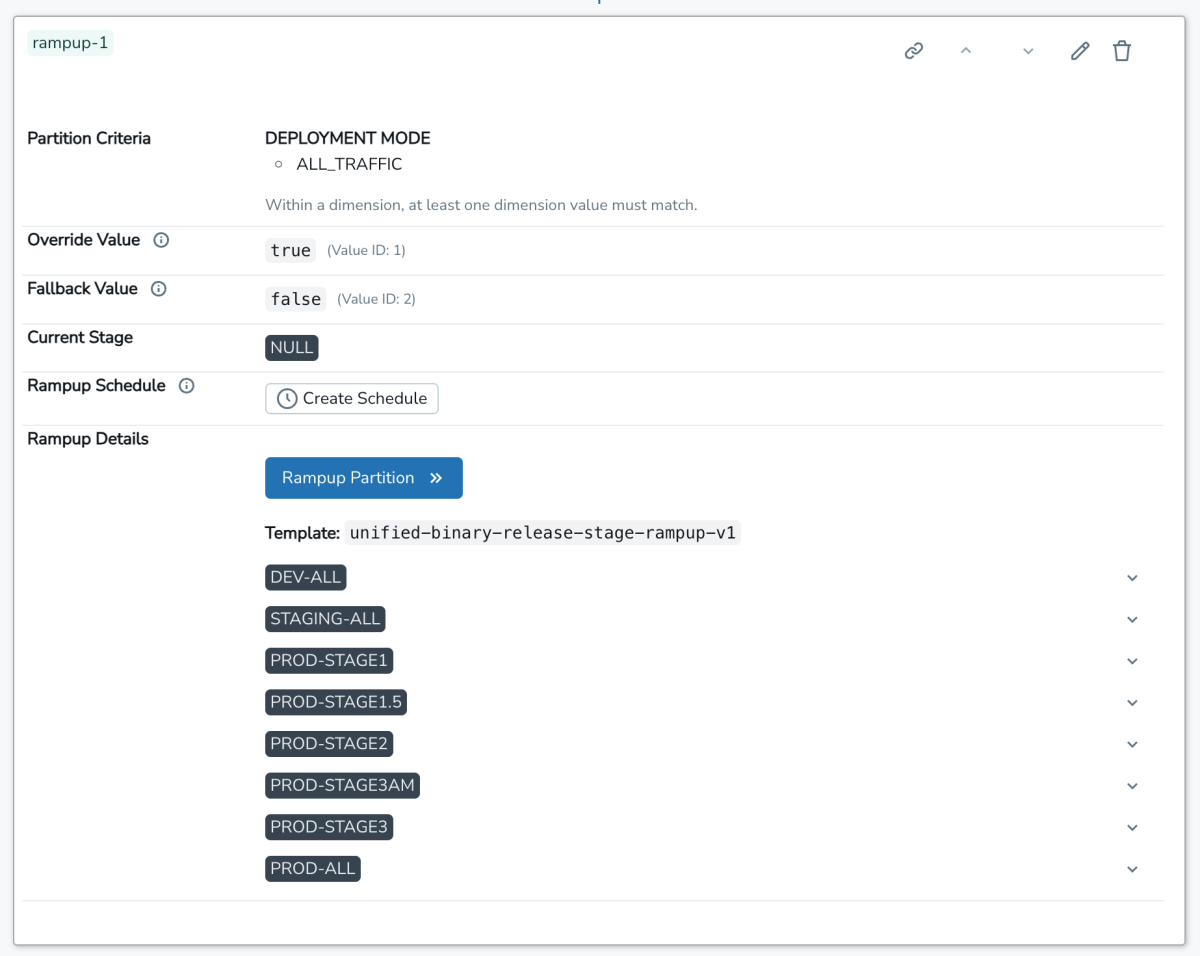
À partir de là, l'utilisateur peut soit déployer manuellement son flag une étape à la fois, soit définir un calendrier pour que les basculements de flag soient créés pour lui. En interne, la source de vérité pour la configuration du flag est un fichier jsonnet archivé dans le monorepo Databricks, qui utilise un langage dédié (DSL) léger pour gérer la configuration du flag :
Lorsque les utilisateurs modifient un flag depuis l'interface utilisateur, le résultat de cette modification est une Pull Request qui doit être examinée par au moins un autre ingénieur. SAFE exécute également diverses vérifications de pré-merge pour se prémunir contre les modifications dangereuses ou non intentionnelles. Une fois la modification mergée, le service de l'utilisateur prendra en compte la modification et commencera à émettre la nouvelle valeur dans les 2 à 5 minutes suivant le Merge de la PR.
Cas d’utilisation
Outre le cas d'usage décrit ci-dessus pour le déploiement de fonctionnalités, SAFE est également utilisé pour d'autres aspects de la configuration dynamique de services, tels que : les configurations dynamiques à longue durée de vie (par ex. timeouts ou limites de débit), le contrôle de machines à états pour les migrations d'infrastructure, ou pour fournir de petits blobs de configuration (par ex. politiques de journalisation ciblées).
Architecture
Bibliothèques client
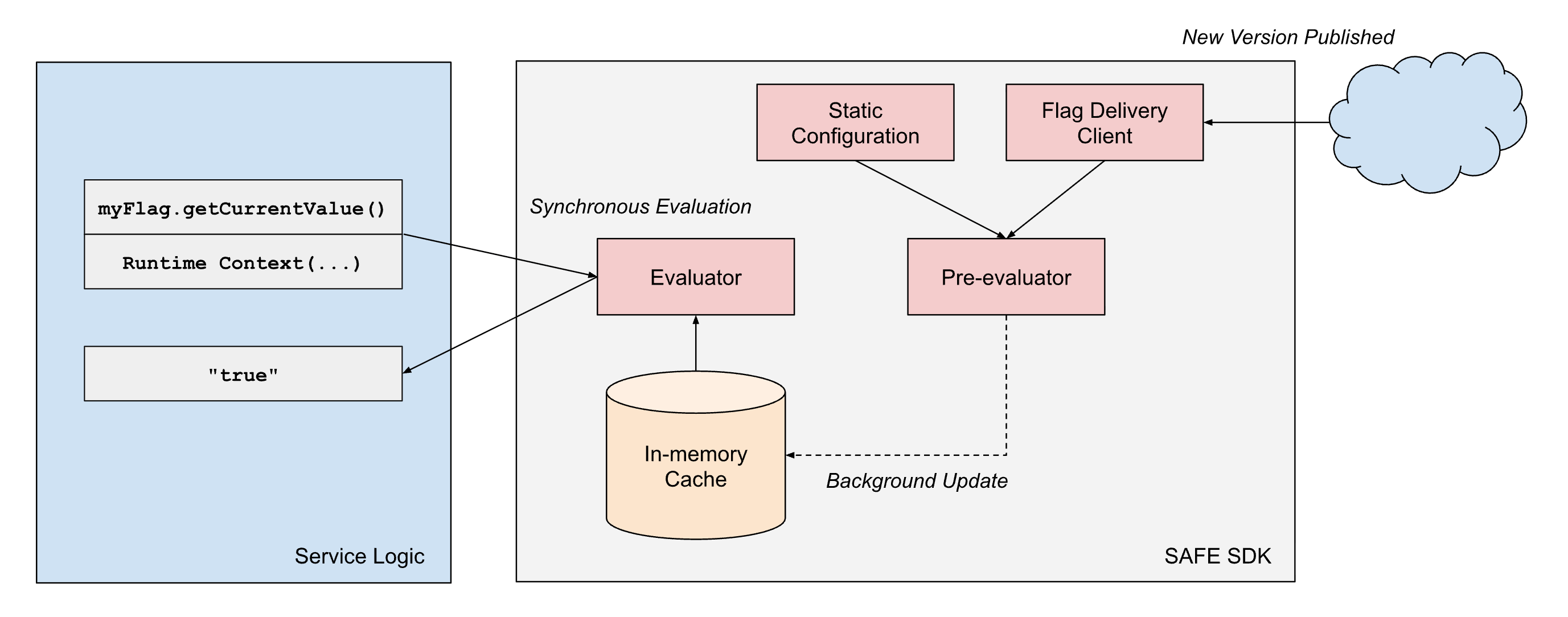
SAFE fournit des « SDK » clients dans plusieurs langages pris en charge en interne, le SDK Scala étant le plus mature et le plus largement adopté. Le SDK est essentiellement une bibliothèque d'évaluation de critères, combinée à un composant de chargement de configuration. Pour chaque flag, il existe un ensemble de critères qui contrôlent la valeur que le SDK doit retourner lors de l'exécution. Le SDK gère le chargement du dernier ensemble de configurations et doit renvoyer rapidement le résultat de l'évaluation de ces critères lors de l'exécution.
En pseudo-code, les critères se présentent en interne comme suit :
Les critères peuvent être modélisés comme une séquence d'arbres d'expressions booléennes. Chaque expression conditionnelle doit être évaluée efficacement pour renvoyer un résultat rapide.
Pour répondre à nos exigences de performance, la conception du SDK SAFE repose sur quelques principes architecturaux : (1) la séparation de la livraison de la configuration de l'évaluation, et (2) la séparation des dimensions d'évaluation statiques et d'exécution.
- Séparation de la livraison et de l'évaluation : les bibliothèques clientes SAFE traitent toujours la livraison comme un processus asynchrone et ne bloquent jamais le « hot path » de l'évaluation du drapeau sur la livraison de la configuration. Une fois que le client dispose d'un instantané d'une configuration de flag, il continuera à renvoyer des résultats basés sur cet instantané jusqu'à ce qu'un processus asynchrone en arrière-plan effectue une mise à jour atomique de cet instantané vers un instantané plus récent.
- Séparation des types de dimension : l'évaluation des flags dans SAFE fonctionne avec deux types de dimensions :
- Les dimensions statiques représentent des caractéristiques propres au binaire en cours d'exécution, telles que le fournisseur de cloud, la région de cloud et l'environnement (développement/préproduction/production). Ces valeurs restent constantes pendant toute la durée de vie d'un processus.
- Les dimensions de Runtime capturent le contexte spécifique à la requête, comme les ID de workspace, les ID de compte, les valeurs fournies par l'application et d'autres attributs par requête qui varient à chaque évaluation.
Pour atteindre de manière fiable une latence d'évaluation inférieure à la milliseconde lorsque l'on monte en charge, SAFE utilise la pré-évaluation des parties de l'arbre d'expression booléenne qui sont statiques. Lorsqu'un bundle de configuration SAFE est fourni à un service, le SDK évalue immédiatement toutes les dimensions statiques par rapport à la représentation en mémoire de la configuration des flags. Cela produit un arbre de configuration simplifié qui ne contient que la logique pertinente pour cette instance de service spécifique.
Lorsqu'une évaluation de drapeau est demandée pendant le traitement de la requête, le SDK n'a qu'à évaluer les dimensions d'exécution restantes par rapport à cette configuration précompilée. Cela réduit considérablement le coût de calcul de chaque évaluation. Étant donné que de nombreux flags n'utilisent que des dimensions statiques dans leurs arbres d'expressions booléennes, beaucoup d'entre eux peuvent en fait être entièrement pré-évalués.
Distribution des flags
Pour fournir de manière fiable la configuration à tous les services chez Databricks, SAFE fonctionne en étroite collaboration avec Zippy, notre plateforme interne de livraison de configuration dynamique. Une description détaillée de l'architecture Zippy fera l'objet d'un autre article, mais en bref, Zippy utilise une architecture multiniveau mondiale/régionale et un stockage d'objets blob par cloud pour transporter des blobs de configuration arbitraires d'une source centrale vers (entre autres surfaces) tous les pods Kubernetes s'exécutant dans le plan de contrôle Databricks.
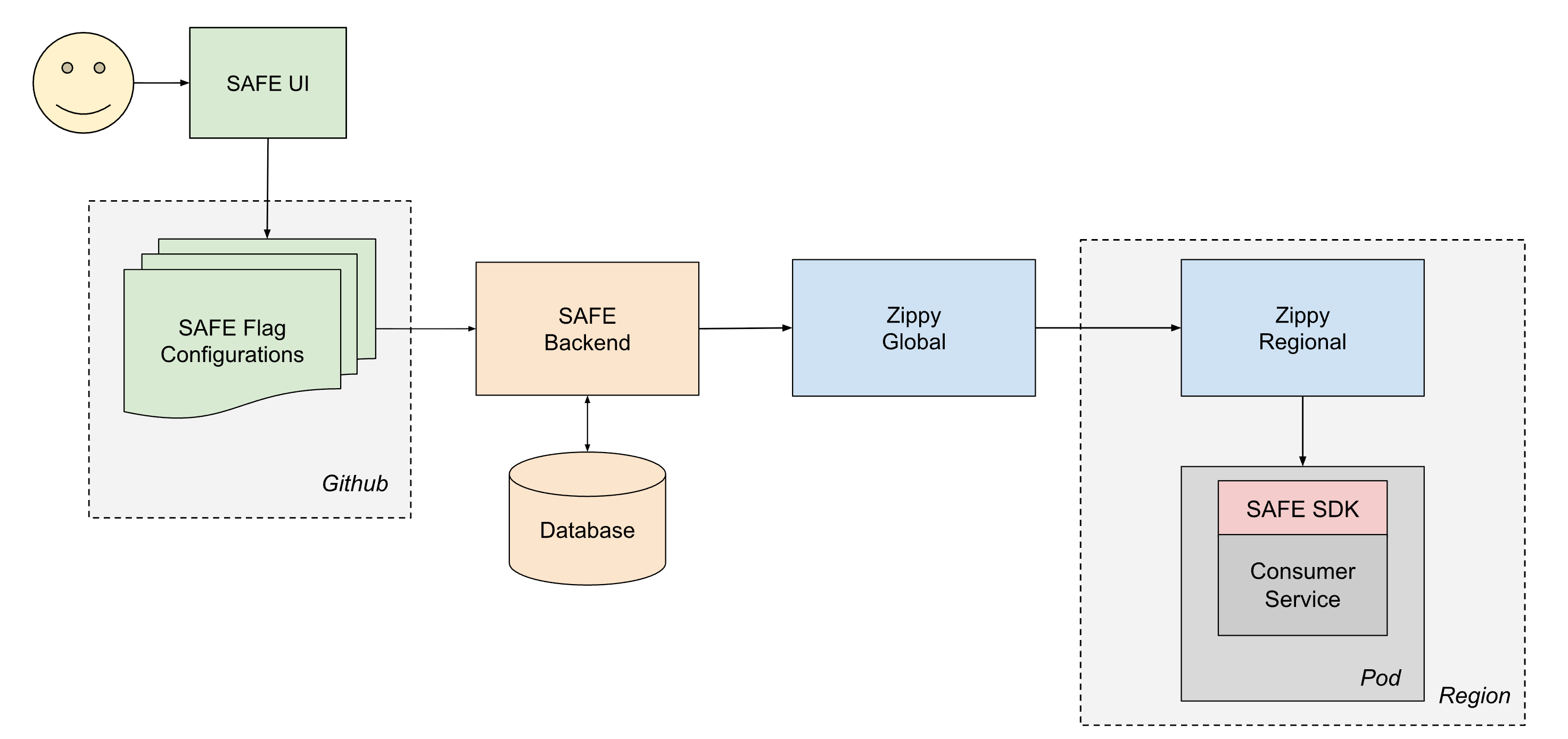
Le cycle de vie d'un flag livré est le suivant :
- Un utilisateur crée et fusionne une PR dans l'un de ses fichiers jsonnet de configuration de flag, qui est ensuite fusionnée dans le monorepo Databricks sur Github.
- En environ 1 minute, un job d'intégration continue post-merge récupère le fichier modifié et l'envoie au backend SAFE, qui stocke ensuite une copie de la nouvelle configuration dans une base de données.
- Périodiquement (à des intervalles d'environ 1 minute), le backend SAFE regroupe toutes les configurations de drapeaux SAFE et les envoie au backend Zippy Global.
- Zippy Global distribue ces configurations à chacune de ses instances Zippy Regional, en environ 30 secondes.
- Le SDK SAFE, qui s'exécute dans chaque pod de service, reçoit périodiquement les nouveaux lots de versions via une combinaison de livraison basée sur les modes push et pull.
- Une fois livrée, le SDK SAFE peut utiliser la nouvelle configuration pendant l'évaluation.
De bout en bout, une modification de flag se propage généralement à tous les services dans les 3 à 5 minutes qui suivent le Merge d'une PR.
Pipeline de configuration des indicateurs
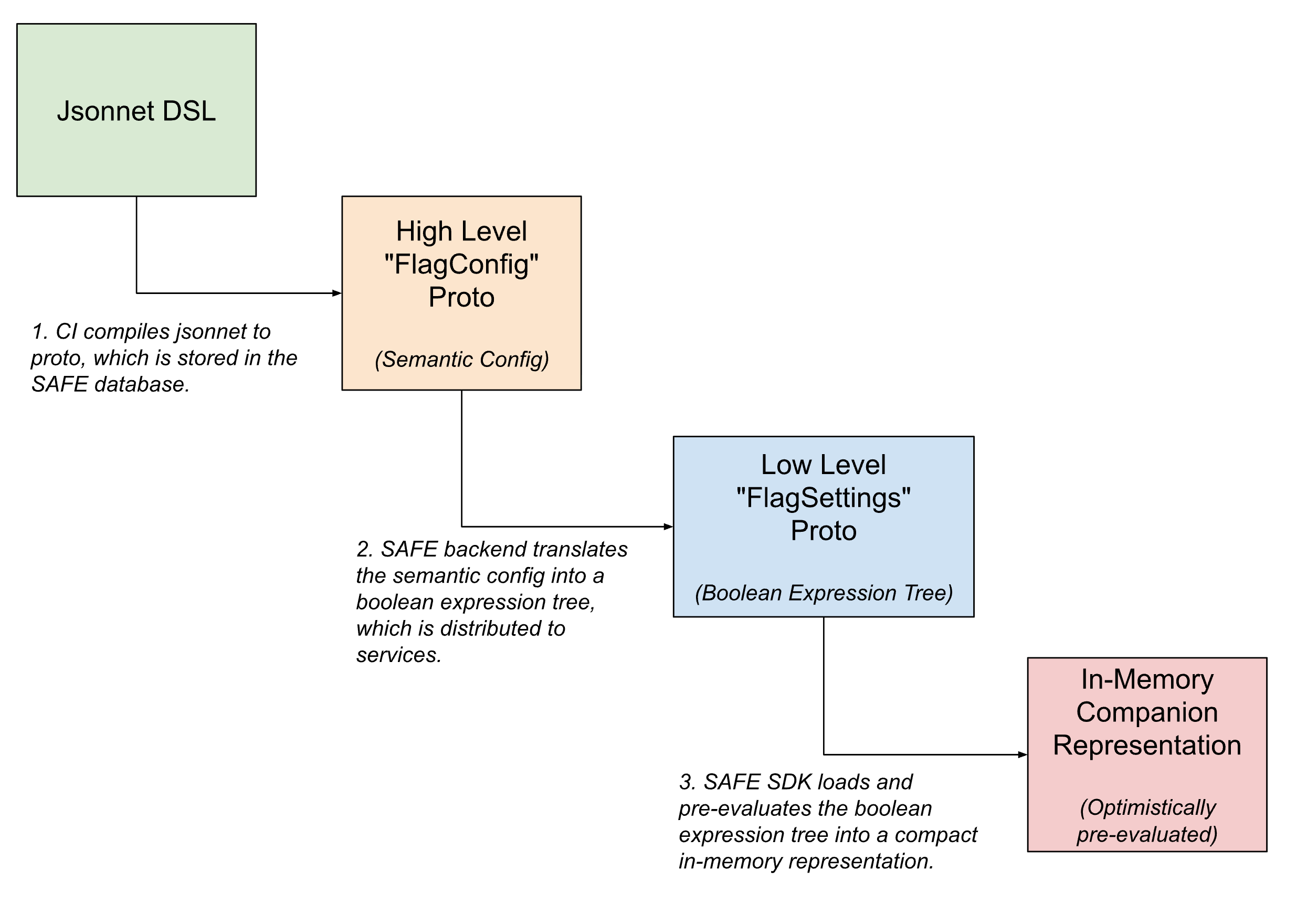
Au sein du pipeline de livraison des flags, les configurations de flags prennent plusieurs formes, étant progressivement traduites de configurations sémantiques de haut niveau lisibles par l'homme en versions compactes lisibles par machine à mesure que le flag se rapproche de son évaluation.
Dans l'interface utilisateur, les flags sont définis à l'aide de Jsonnet avec un DSL personnalisé pour permettre des configurations de flags arbitrairement complexes. Ce DSL facilite les cas d'utilisation courants, comme la configuration du déploiement d'un flag à l'aide d'un template prédéfini, ou la définition de surcharges spécifiques sur des tranches de trafic.
Une fois enregistré, ce DSL est traduit en un équivalent protobuf interne, qui capture l'intention sémantique de la configuration. Le backend de SAFE traduit ensuite cette configuration sémantique en un arbre d'expressions booléennes. Une description protobuf de cet arbre d'expressions booléennes est fournie au SDK de SAFE, qui la charge dans une représentation en mémoire encore plus compacte de la configuration.
Interface utilisateur
La plupart des basculements de flags sont initiés depuis une UI interne pour la gestion des flags SAFE. Cette UI permet aux utilisateurs de créer, modifier et retirer des flags via un workflow qui abstrait une grande partie de la complexité de Jsonnet pour les modifications simples, tout en conservant l'accès à la majeure partie de la pleine puissance du DSL pour les cas d'utilisation avancés.
Une interface utilisateur riche nous a également permis de proposer des fonctionnalités de confort supplémentaires, telles que la possibilité de programmer le basculement des flags, la prise en charge des contrôles de santé post-fusion et des outils de debugging pour déterminer les basculements de flags récents qui ont affecté une région ou un service particulier.
Examen de la configuration des flags
Toutes les modifications de flags SAFE sont créées sous la forme de PR Github normales et sont validées à l'aide d'un vaste ensemble de validateurs de pré-merge. Cet ensemble de validateurs s'est étoffé pour inclure des dizaines de vérifications individuelles, à mesure que nous en avons appris davantage sur la meilleure façon de se prémunir contre les modifications de flag potentiellement dangereuses. Lors de l'introduction initiale de SAFE, les analyses post-mortem d'incidents causés ou atténués par un basculement de flag SAFE ont inspiré nombre de ces vérifications. Nous disposons désormais de vérifications qui, par exemple, exigent un examen spécialisé pour les modifications à large rayon d'impact, exigent qu'une version binaire de service particulière soit déployée avant qu'un flag puisse être activé, empêchent les schémas de mauvaise configuration courants et subtils, et ainsi de suite.
Les équipes peuvent également définir leurs propres vérifications de pré-merge spécifiques aux indicateurs ou à l'équipe, afin d'appliquer des invariants pour leurs configurations.
Gestion des modes de défaillance
Compte tenu du rôle essentiel de SAFE dans la stabilité du service, le système est conçu avec plusieurs couches de résilience pour garantir un fonctionnement continu, même en cas de défaillance de certaines parties du pipeline de livraison.
Le scénario de défaillance le plus courant implique des disruptions du chemin de livraison de la configuration. Si un élément du chemin de livraison entraîne un échec de la mise à jour des configurations, les services continuent simplement d'utiliser leur dernière configuration connue jusqu'à ce que le chemin de livraison soit restauré. Cette approche "fail static" garantit que le comportement du service existant reste stable, même pendant les pannes en amont.
Pour les scénarios plus graves, nous disposons de plusieurs mécanismes fallback :
- Livraison hors bande: si un élément du chemin d'intégration continue ou de push Github est indisponible, les opérateurs peuvent pousser les configurations directement vers le backend SAFE à l'aide d'outils d'urgence.
- Basculement régional: si le backend SAFE ou Zippy Global sont en panne, les opérateurs peuvent temporairement pousser les configurations directement vers les instances Zippy Regional. Les services peuvent également effectuer des interrogations interrégionales pour atténuer l'impact d'une seule panne régionale Zippy.
- Lots de démarrage à froid: Pour gérer les cas où Zippy lui-même n'est pas disponible lors du startup du service, SAFE distribue périodiquement des lots de configuration aux services via un registre d'artefacts. Bien que ces lots puissent dater de quelques heures, ils fournissent une sauvegarde suffisante pour que les services démarrent en toute sécurité plutôt que de bloquer en attente d'une livraison en direct.
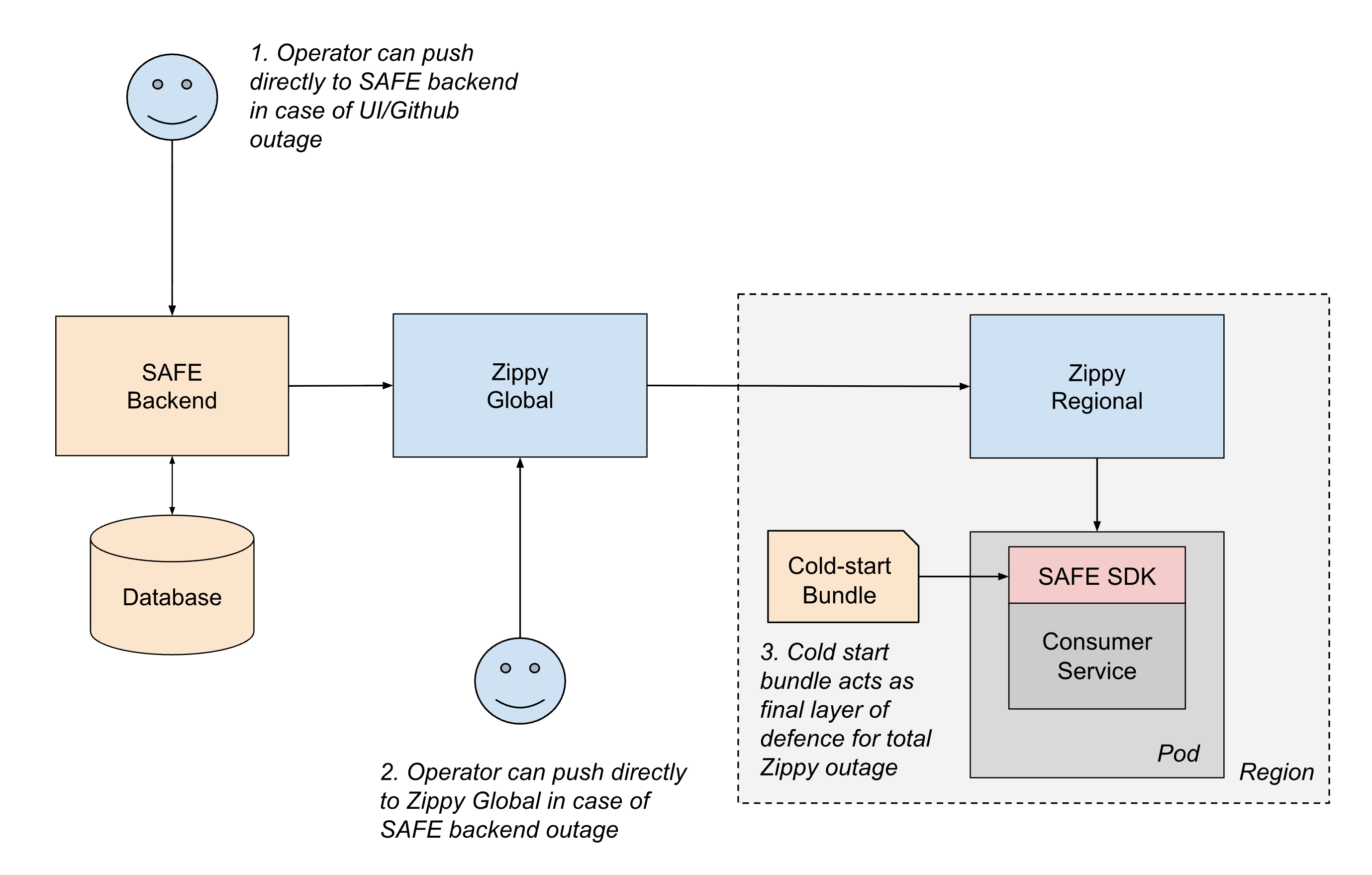
Au sein même du SDK SAFE, la conception défensive garantit que les erreurs de configuration ont un rayon d'impact limité. Si la configuration d'un indicateur particulier est malformée, seul cet indicateur est affecté. Le SDK respecte également le contrat de ne jamais lever d'exceptions et utilise toujours la valeur par défaut du code en cas d'échec. Ainsi, les développeurs d'applications n'ont pas à considérer l'évaluation des indicateurs comme une opération faillible. Le SDK alerte également immédiatement les ingénieurs d'astreinte lorsque des erreurs d'analyse de la configuration ou d'évaluation surviennent. Grâce à la maturité de SAFE et à une validation approfondie avant merge, de telles défaillances sont désormais extrêmement rares en production.
Cette approche de la résilience par couches garantit que SAFE se dégrade progressivement et minimise le risque qu'il devienne un point de défaillance unique.
Enseignements tirés
La minimisation des dépendances et les fallback redondants et superposés réduisent la charge opérationnelle. Bien qu'il soit déployé et largement utilisé sur la quasi-totalité des surfaces de compute de Databricks, la charge opérationnelle de maintenance de SAFE est restée tout à fait gérable. L'ajout de redondances superposées, telles que l'ensemble de démarrage à froid et le comportement « fail static » du SDK, a rendu une grande partie de l'architecture SAFE auto-réparatrice.
L'expérience des développeurs est primordiale. La mise à l'échelle de l'« aspect humain » d'un système de flagging robuste a nécessité une forte concentration sur l'UX. SAFE est un système critique, souvent utilisé pour atténuer les incidents. Par conséquent, la création d'une UX conviviale pour basculer les flags pendant les urgences avait un fort impact. L'adoption d'une mentalité axée sur le produit a permis de réduire les petits désagréments, de diminuer la confusion et, au final, d'abaisser le temps moyen de rétablissement (MTTR) à l'échelle de l'entreprise pour les incidents.
Faire des "bonnes pratiques" la voie la plus simple. L'un de nos plus grands apprentissages a été que l'on ne peut pas se contenter de documenter les bonnes pratiques et s'attendre à ce que les ingénieurs les suivent. Les ingénieurs ont de nombreuses priorités concurrentes lorsqu'ils livrent des fonctionnalités. SAFE fait de la voie sûre la voie la plus simple : les déploiements progressifs demandent moins d'efforts et disposent de plus de fonctionnalités de confort que les modèles d'activation plus risqués. Lorsque le système encourage un comportement plus sûr, la plateforme peut inciter les ingénieurs à adopter une culture de gestion responsable des changements.
État actuel et travaux futurs
SAFE est aujourd'hui une plateforme interne mature au sein de Databricks, et elle est largement utilisée. Les investissements réalisés dans la disponibilité et l'expérience des développeurs portent leurs fruits, car nous constatons une réduction continue du temps moyen de résolution et du rayon d'impact des incidents de production grâce à l'utilisation des SAFE flags.
À mesure que la gamme de produits de Databricks s'élargit, les primitives d'infrastructure sous-jacentes à ces produits gagnent en portée et en complexité. Par conséquent, un investissement important et continu a été réalisé pour garantir que SAFE prenne en charge tous les environnements où les ingénieurs de Databricks écrivent et déploient du code.
Si la mise à l'échelle d'infrastructures critiques comme celle-ci vous intéresse, consultez les postes à pourvoir chez Databricks!
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.