Comment créer une détection de fraude en temps réel à l'aide du mode temps réel Spark et de Lakebase
Modernisation des écosystèmes financiers avec une latence inférieure à la seconde et une intelligence de données évolutive
par Sixuan He et Navneeth Nair
- Les systèmes traditionnels de détection de fraude peinent à réduire les délais de détection, s'appuyant sur un traitement par lots lent ou des moteurs de streaming complexes et ajoutés qui ne parviennent pas à bloquer les menaces en temps réel.
- Le mode temps réel de Spark et Lakebase permettent aux équipes de données de construire et d'automatiser facilement un flux de travail de détection de fraude de bout en bout : traitement de flux de données à haut débit, exécution de modèles ML à faible latence et fourniture de scores de fraude explicables, le tout au sein d'une plateforme unifiée.
- Les organisations peuvent intervenir en moins d'une seconde sur les transactions frauduleuses, réduisant la complexité opérationnelle tout en protégeant les revenus et en maintenant la confiance des clients sans nécessiter d'infrastructure externe.
La fraude par carte bancaire se produit en quelques secondes. Un numéro de carte de crédit volé peut financer des dizaines d'achats en quelques minutes, et une fois qu'une transaction est réglée, il devient exponentiellement plus difficile de récupérer ces fonds. Selon le Nilson Report, les institutions financières perdent environ 33 milliards de dollars par an à cause des transactions frauduleuses par carte, et ce chiffre ne fera qu'augmenter avec l'accélération du volume des transactions numériques.
Le défi n'est pas de détecter la fraude. La plupart des organisations disposent déjà de modèles de fraude performants et de règles bien ajustées. Le défi est de la détecter assez rapidement pour bloquer une transaction suspecte avant qu'elle ne soit validée, dans la fenêtre de moins d'une seconde entre l'autorisation et le règlement, et ce, sans ajouter un moteur de streaming séparé et spécialisé qui double votre complexité opérationnelle.
Dans ce blog, nous présentons un nouvel accélérateur de solution : une implémentation de référence open source que vous pouvez cloner et déployer directement dans votre environnement Databricks. Il démontre comment construire un système complet de détection de fraude de bout en bout, de l'ingestion des transactions brutes et du scoring ML en temps réel à un tableau de bord de surveillance en direct construit avec Databricks Apps, entièrement sur la plateforme Databricks. À son cœur se trouvent deux technologies : le mode temps réel (RTM) pour Apache Spark Structured Streaming sur Databricks qui offre un traitement de flux inférieur à 300 ms, et Lakebase, une base de données Postgres entièrement gérée et sans serveur, intégrée à la plateforme Databricks.
Vitesse vs Simplicité : Le compromis temps réel pour la détection de fraude
La détection de fraude se situe à l'intersection de deux exigences contradictoires.
D'un côté, il y a la vitesse. Une transaction frauduleuse doit être identifiée et bloquée en quelques centaines de millisecondes avant d'être réglée. Les réseaux de fraude sophistiqués testent les cartes volées avec des micro-achats rapides, exploitent les anomalies géographiques et adaptent leurs modèles plus rapidement que les règles statiques ne peuvent suivre.
De l'autre côté, il y a la simplicité. Les équipes de données souhaitent construire, entraîner et déployer des modèles de fraude sur une seule plateforme, avec une gouvernance unifiée, des données partagées et un ensemble d'outils. Elles ne veulent pas maintenir une pile de streaming séparée juste pour la "dernière étape" du scoring en temps réel.
Jusqu'à présent, les équipes ont été obligées de choisir. Historiquement, répondre à ces exigences de latence ultra-faible signifiait introduire un moteur spécialisé à côté de Spark, tel qu'Apache Flink. Le résultat est un schéma familier : deux systèmes parallèles, des données dupliquées, une gouvernance divisée, et des équipes d'ingénierie passant plus de temps à gérer les pipelines au lieu d'améliorer les modèles de fraude. Avec l'introduction du RTM dans Spark Structured Streaming, ce compromis n'est plus nécessaire.
RTM : Traitement en moins d'une seconde sans la surcharge opérationnelle de plusieurs systèmes
RTM est une évolution du moteur Spark Structured Streaming qui permet le traitement des données en moins d'une seconde pour les applications opérationnelles sensibles à la latence telles que l'ingénierie des caractéristiques.
Côté vitesse, RTM traite les événements en millisecondes et est jusqu'à 92 % plus rapide qu'Apache Flink pour les transformations sans état, l'enrichissement basé sur les jointures et les charges de travail d'agrégation. Des clients tels que Coinbase utilisent déjà RTM pour calculer plus de 250 caractéristiques ML, et ont atteint des latences de traitement P99 inférieures à 100 ms.
Côté simplicité, RTM réside à l'intérieur du moteur Spark que vous exécutez déjà, pas à côté. Par conséquent, vous bénéficierez immédiatement de :
- Aucune dérive logique. Vos règles de scoring de fraude, votre ingénierie des caractéristiques et votre prétraitement ML n'existent qu'une seule fois. Le même code qui s'exécute dans votre pipeline d'entraînement hors ligne s'exécute dans votre environnement de scoring en temps réel. Cela vous permet de mettre en production des caractéristiques plus rapidement et avec une plus grande précision.
- Une seule surface opérationnelle. Spark UI, surveillance des clusters, jobs, alertes, etc. Tous les outils que vous utilisez déjà s'appliquent. Il n'y a pas de deuxième rotation sur appel pour le moteur de streaming.
- Flexibilité sur le coût vs la fraîcheur. Lorsque la fraîcheur en moins d'une seconde ne vaut pas le coût, revenir à un déclencheur plus lent est le même changement de code en une ligne dans l'autre sens. Pas besoin de passer du temps à ajuster manuellement le parallélisme ou à orchestrer l'arrêt et le redémarrage des ressources de calcul.
En conséquence, l'équipe n'a plus besoin de choisir ; vous bénéficiez à la fois de la vitesse et de la simplicité, et les heures d'ingénierie sont consacrées à l'ajustement des signaux de fraude plutôt qu'à la gestion de l'infrastructure.
Exemple de scénario : Blocage de la fraude dans les transactions par carte de crédit
Pour rendre cela concret, notre accélérateur de solution met en œuvre un système de détection de fraude en temps réel pour les transactions par carte de crédit. Voici le scénario :
Les transactions arrivent en flux d'un système de messagerie (Kafka, Kinesis, etc.). Chaque transaction contient un identifiant de carte, un montant, une catégorie de marchand, des coordonnées géographiques et un canal (en ligne ou point de vente). Le système doit évaluer chaque transaction par rapport à plusieurs signaux de fraude, attribuer un score de risque et la router vers le résultat approprié — approuvé, signalé pour examen, ou bloqué — le tout en moins de 300 ms.
L'architecture reflète l'apparence des systèmes de fraude en production dans les grandes institutions financières, avec un suivi d'état, un enrichissement des caractéristiques à partir de Lakebase en tant que couche de service en ligne, un scoring ML, et une application Databricks Apps en direct pour la surveillance des analystes de fraude. La différence est qu'elle s'exécute entièrement sur une seule plateforme.
Comment nous l'avons construit
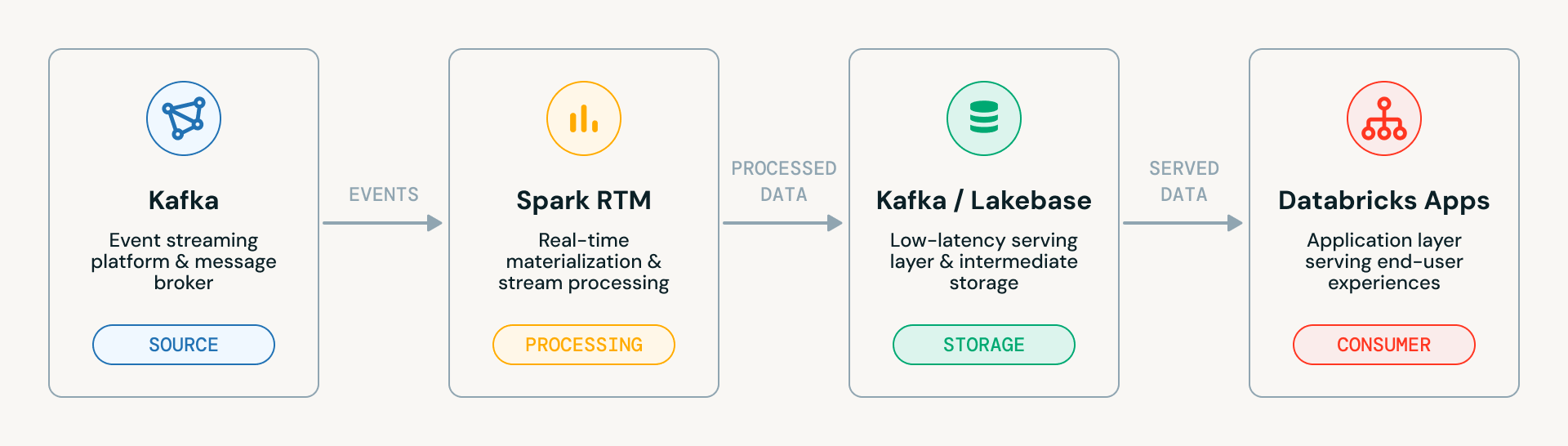
L'accélérateur passe par quatre étapes progressives, chacune s'appuyant sur la précédente. Voici le diagramme d'architecture système de haut niveau. Il montre le flux de données propre à travers les quatre composants principaux :
- Kafka (Source) : La plateforme de streaming d'événements qui ingère les événements bruts
- Spark RTM : Le moteur de matérialisation en temps réel qui traite les données en streaming
- Kafka / Lakebase : La couche intermédiaire où les données traitées atterrissent, soit de retour dans Kafka, soit dans Lakebase (la couche de service à faible latence de Databricks)
- Databricks Apps : La couche applicative qui sert les données finales aux utilisateurs finaux
Découvrez la vidéo de démonstration complète de bout en bout ci-dessous, ou continuez à lire étape par étape pour savoir exactement comment nous l'avons construite. Commencez par le démarrage rapide ci-dessous (sans dépendances externes) et ajoutez de la complexité au fur et à mesure.
Étape 1 : Voir le mode temps réel en action
Pour les institutions financières évaluant l'infrastructure de détection de fraude en temps réel, le temps de mise en valeur rapide est essentiel. Le notebook de démarrage rapide permet à votre équipe de découvrir immédiatement le mode temps réel, et de valider les benchmarks de latence de base et l'adéquation de la plateforme en moins de cinq minutes, avant tout engagement de production. Aucune connexion à Kafka ni configuration externe n'est nécessaire. Il génère des transactions synthétiques à l'aide de la source de taux intégrée de Spark, applique la logique de scoring de fraude et affiche les résultats en direct dans le notebook. C'est votre "hello world" pour le mode temps réel. Exécutez-le, regardez les chiffres de latence et validez que votre cluster est correctement configuré.
Étape 2 : Construire le pipeline de détection de fraude
Une fois le mode temps réel validé, le notebook suivant construit un pipeline de détection de fraude de qualité production qui reflète la manière dont les principales institutions financières (FSIs) opérationnalisent la prise de décision en temps réel pour la fraude. Il traite les transactions de bout en bout, fournissant le scoring explicable requis par les équipes d'opérations de fraude et de conformité. Les transactions circulent de Kafka à travers cinq étapes, chacune fonctionnant en continu, chacune ajoutant de l'intelligence :
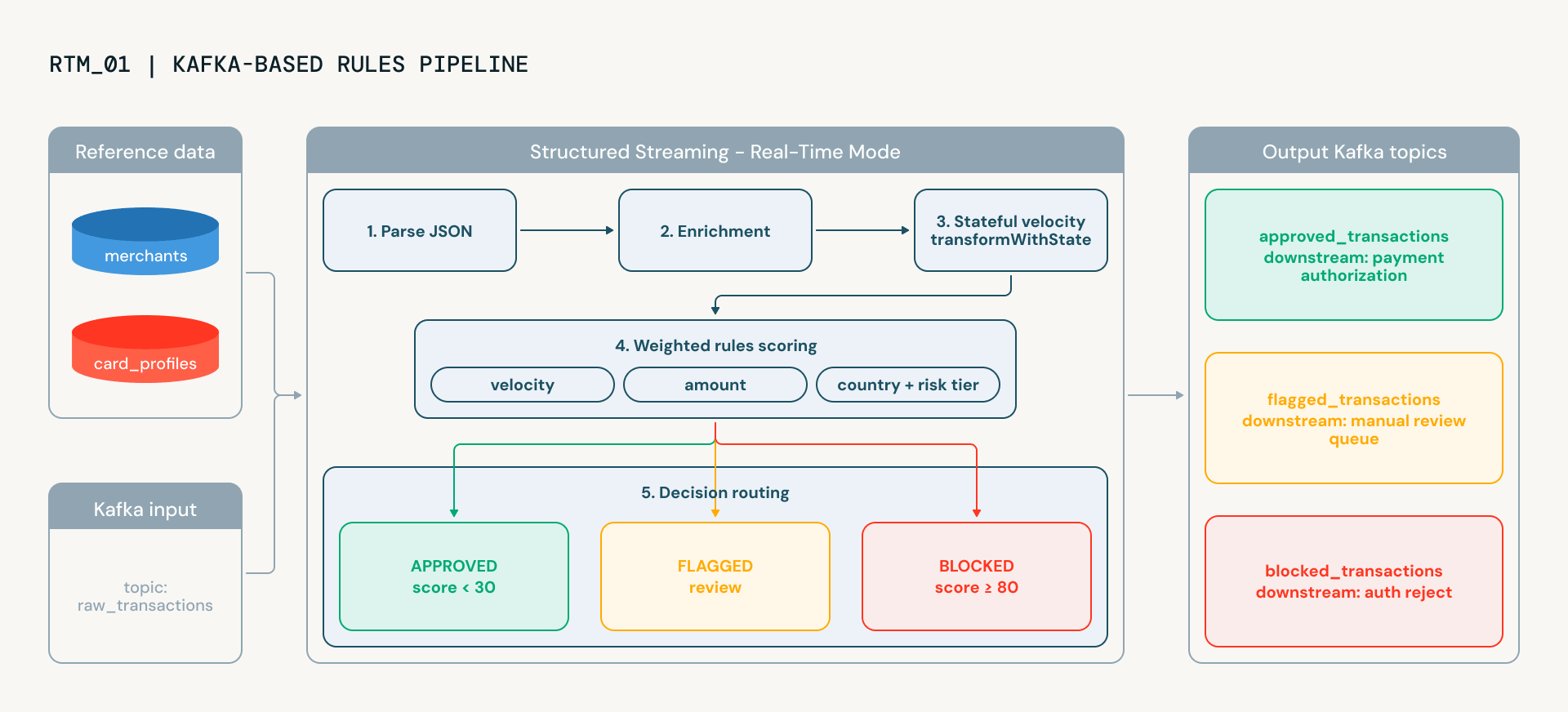
- Analyse du format : prend les données JSON brutes de Kafka et les structure en colonnes typées
- Suivi de la vélocité : c'est là que les choses deviennent intéressantes. En utilisant transformWithState (l'opérateur puissant de Spark pour construire des transformations d'état arbitraires ou personnalisées), le pipeline maintient l'état par carte à travers le flux : combien de transactions cette carte a-t-elle effectuées au cours des 60 dernières secondes ? Une carte qui effectue soudainement cinq transactions en une minute présente un comportement classique de test de carte. L'état expire automatiquement via TTL, il n'y a donc pas de croissance de mémoire illimitée ni de nettoyage manuel.
- Enrichissement : ajoute du contexte à partir des profils de risque des commerçants et des données des titulaires de carte. S'agit-il d'une catégorie de commerçant à haut risque (cartes cadeaux, bijoux) ? Le titulaire de la carte dépense-t-il normalement 50 $ ou 5 000 $ ? Ces recherches utilisent des dictionnaires Python plutôt que des jointures de diffusion, évitant ainsi la surcharge BroadcastExchange qui peut ajouter de la latence dans les pipelines de streaming.
- Notation : combine cinq signaux de fraude pondérés : vélocité, anomalie géographique, écart de montant, risque de catégorie de commerçant et risque de pays, en un seul score de 0 à 100. Chaque signal est calculé par une UDF dédiée, et les poids sont configurables. Le résultat est un score explicable : vous pouvez voir exactement quels signaux ont contribué et dans quelle mesure.
- Routage : prend la décision finale. Les transactions sont classées comme approuvées, signalées pour examen manuel ou automatiquement bloquées, et écrites dans le sujet Kafka de sortie approprié.
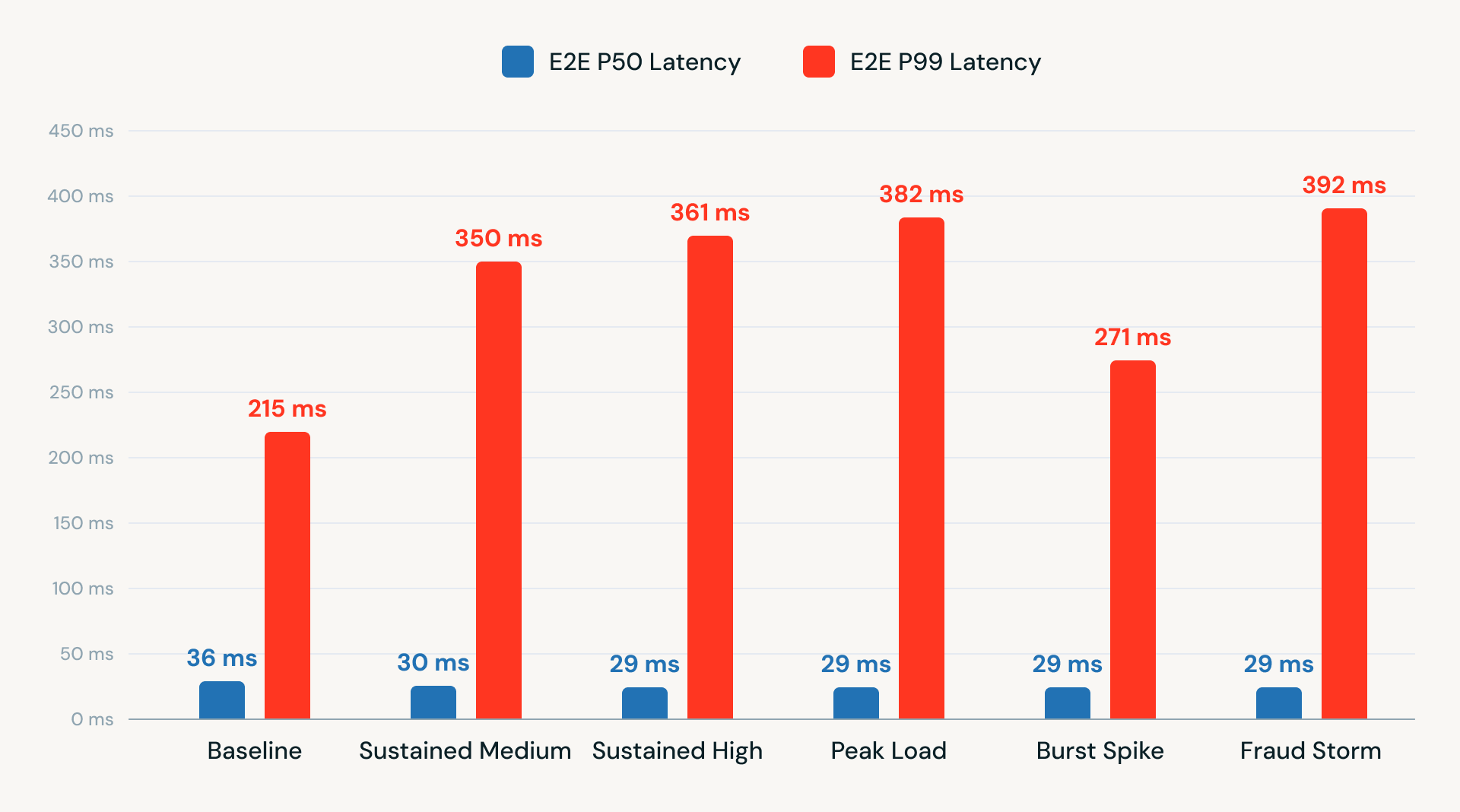
Nous avons également effectué des tests de latence de bout en bout sur différents niveaux de TPS. Les résultats ont montré des performances constantes, avec une latence P50 inférieure à 40 ms et une latence P99 comprise entre 215 et 392 ms. Ces résultats démontrent qu'une architecture Kafka entrante, Kafka sortante utilisant RTM sur la plateforme Databricks peut offrir des performances à faible latence et prêtes pour la production sans dépendre d'API externes ni d'infrastructure supplémentaire.
Étape 3 : Mise à niveau vers le Machine Learning
La détection de fraude basée sur des règles statiques crée des systèmes auditables mais fragiles. Les seuils sont arbitraires : pourquoi cinq transactions en 60 secondes sont-elles « suspectes » ? Pourquoi pas quatre ou six ? Et comme il n'y a pas d'apprentissage, le système ne s'améliore jamais à partir des décisions passées.
Le notebook avancé met à niveau cette logique vers un modèle de machine learning gouverné. Cette transition permet aux équipes de gestion des risques de réduire les faux positifs, de s'adapter aux modèles de fraude émergents et de démontrer la lignée des modèles aux régulateurs grâce au suivi des expériences et au versionnement intégrés de MLflow. Cela introduit deux nouvelles capacités de plateforme :
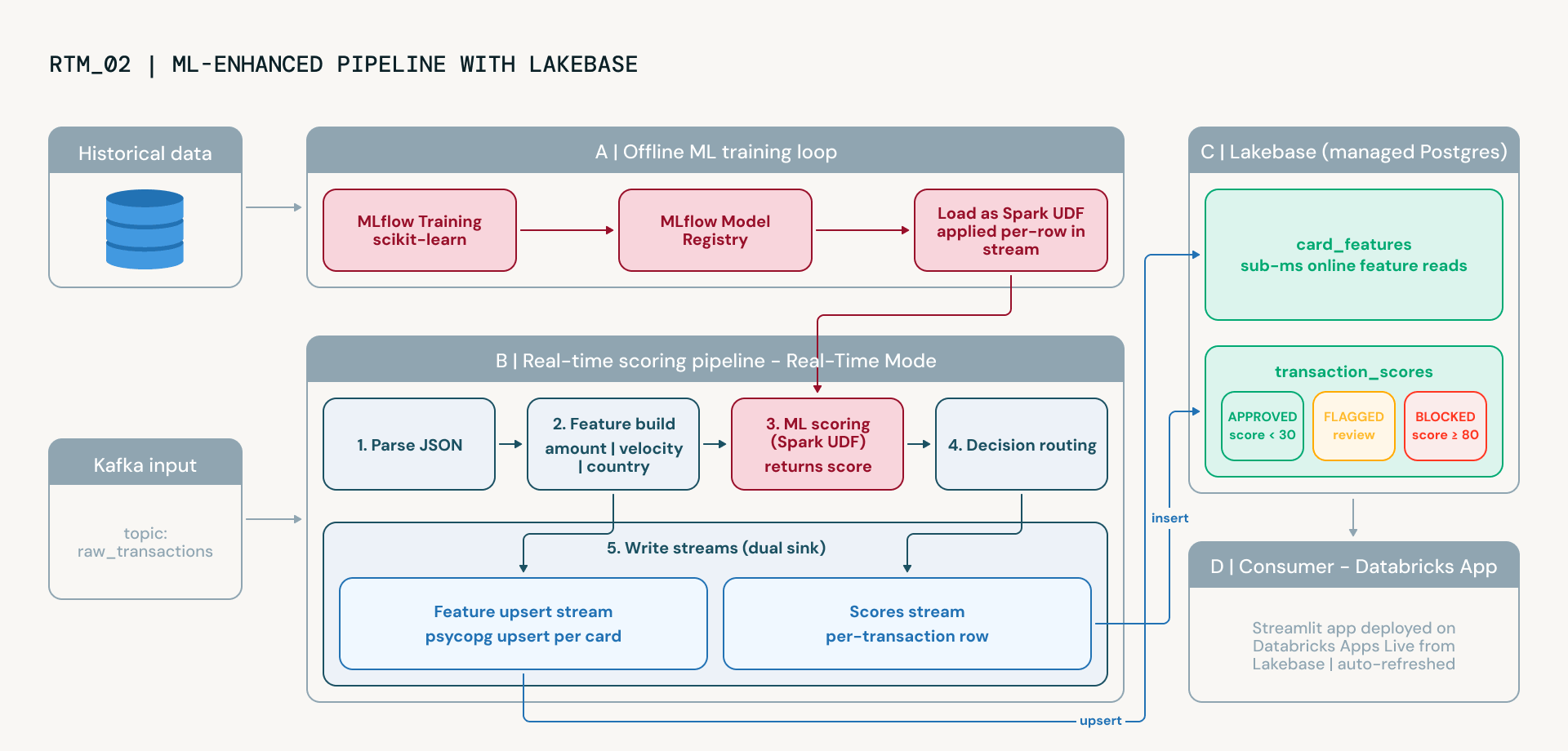
- Lakebase comme couche de service en ligne.Lakebase est le service PostgreSQL géré de Databricks. En utilisant le sink foreach de Spark Structured Streaming avec un LakebaseFeatureWriter personnalisé, le pipeline transmet en continu les caractéristiques par carte, les modèles de vélocité, les montants moyens des transactions, la répartition géographique, le tout directement dans les tables Lakebase avec sémantique d'insertion/mise à jour. Lakebase fournit des lectures sub-milliseconde, ce qui le rend idéal pour le service de caractéristiques en temps réel sans gérer d'infrastructure externe.
- MLflow pour l'entraînement et le service de modèles. Un classificateur RandomForest est entraîné sur des données historiques étiquetées à l'aide de MLflow pour le suivi des expériences et le versionnement des modèles. Le modèle entraîné est chargé en tant qu'UDF Spark et appliqué à chaque transaction dans le pipeline de streaming. Combiné avec des caractéristiques en direct de Lakebase, le modèle apprend des relations non linéaires entre les signaux que les règles statiques manquent, et s'améliore au fil du temps à mesure que de nouvelles données étiquetées deviennent disponibles.
Étape 4 : Surveillance de tout en temps réel
La visibilité opérationnelle est non négociable pour les équipes de fraude soumises à des obligations de reporting réglementaire en temps réel. Pour rendre le système observable, l'accélérateur comprend une application Databricks basée sur Streamlit qui lit directement à partir de Lakebase pour fournir un tableau de bord de surveillance de la fraude en direct. Cela donne aux analystes de fraude et aux gestionnaires de risques une vue en direct et auditable de chaque décision prise par le système, sans nécessiter de support d'ingénierie pour y accéder. Les utilisateurs peuvent suivre le total des transactions notées, les répartitions des décisions (approuvées, signalées, bloquées), les scores de fraude récents avec des détails au niveau de la carte et les distributions de probabilité de fraude, le tout se rafraîchissant automatiquement toutes les 10 secondes. C'est la couche opérationnelle qui rend le système utilisable en pratique, pas seulement techniquement fonctionnel.
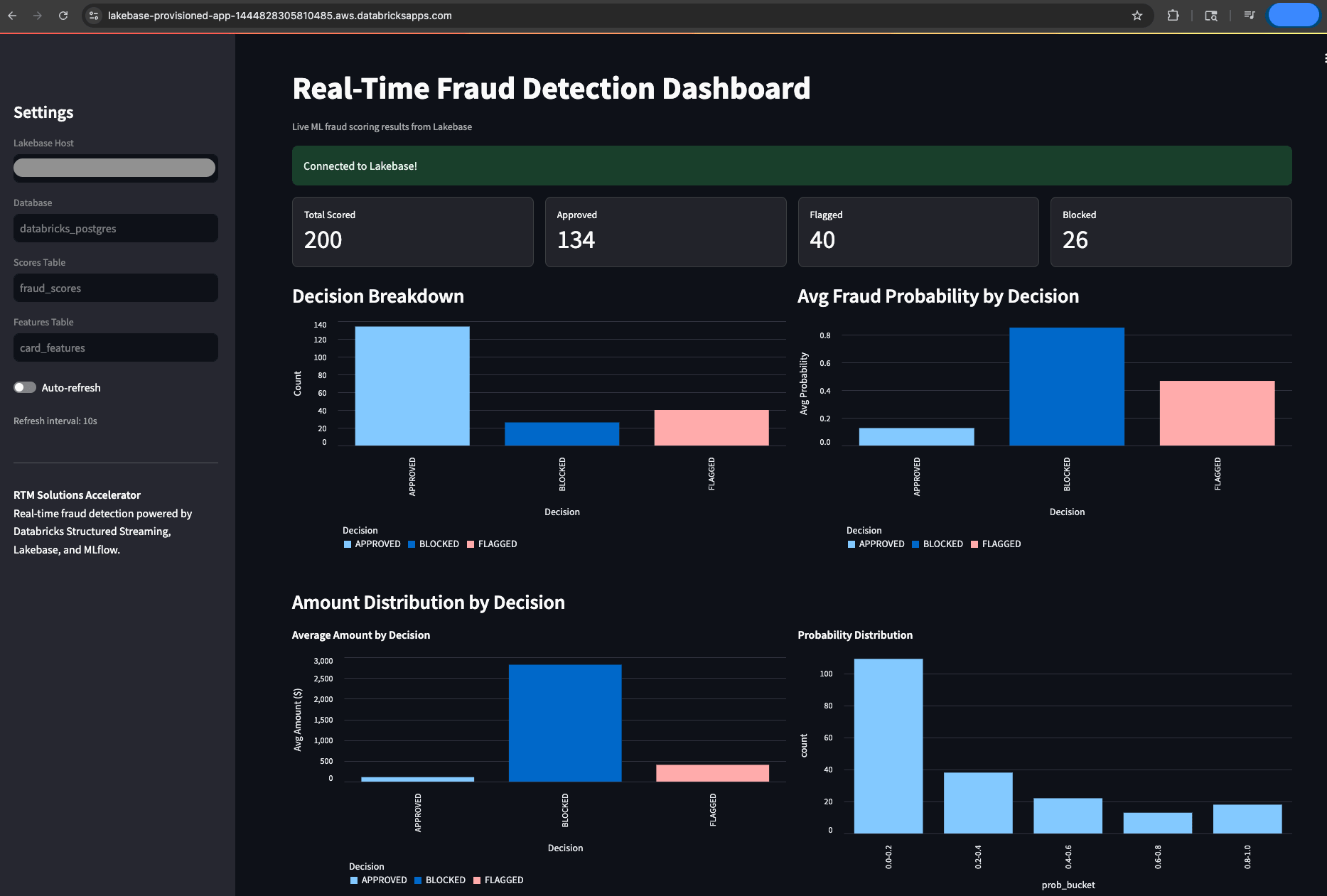
L'idée clé est que tout s'exécute sur une seule plateforme. Le même moteur Spark qui alimente votre ETL batch et votre entraînement ML gère désormais le streaming sub-300 ms. Unity Catalog gouverne désormais vos tables de streaming et vos données d'entraînement. MLflow suit désormais vos modèles de fraude, qu'ils soient utilisés dans l'inférence batch ou la notation en temps réel. Il n'y a pas de lacune d'intégration, pas de division de la gouvernance et pas de deuxième pile à maintenir car tout est sur la même plateforme.
Démarrage
Cet accélérateur de solution est conçu pour être progressivement adaptable : commencez simplement et ajoutez de la complexité si nécessaire.
- Démarrage rapide : Clonez le dépôt, ouvrez `notebooks/RTM_00_Quick_Start.py` et exécutez-le sur un cluster configuré pour fonctionner en mode temps réel. Vous verrez RTM traiter des transactions synthétiques avec une latence inférieure à 300 ms — pas de Kafka, pas de configuration externe requise.
- Pipeline complet : Configurez un périmètre de secrets Kafka avec les adresses de votre broker, puis exécutez `notebooks/RTM_01_Introduction_fraud_detection.py`. Cela vous donne le pipeline complet d'analyse-enrichissement-notation-routage lisant et écrivant dans Kafka. Lors de l'exécution, vous verrez les transactions passer par les cinq étapes et les décisions atterrir dans le sujet de sortie approuvé, signalé et bloqué. Cela vous donne le pipeline complet d'analyse-enrichissement-notation-routage lisant et écrivant dans Kafka.
- Notation basée sur le ML : Créez une instance Lakebase, puis exécutez `notebooks/RTM_02_Advanced_fraud_detection_ml.py`. Cela ajoute le streaming de caractéristiques à Lakebase, l'entraînement de modèles avec MLflow et la notation basée sur le ML dans le pipeline. Une fois terminé, MLflow enregistrera le modèle entraîné et le pipeline commencera à émettre des scores de fraude dérivés du ML à la place des poids basés sur des règles.
- Application de surveillance en direct : Déployez l'application Streamlit à partir de `apps/` en tant qu'applications Databricks avec une liaison de ressources Lakebase. L'application se connecte automatiquement et commence à afficher les scores de fraude en direct.
Le chemin le plus rapide est avec Databricks Asset Bundles — clonez, déployez et exécutez simplement :
Le bundle provisionne automatiquement un cluster correctement configuré et exécute tous les notebooks en séquence.
En savoir plus sur le mode temps réel
Le mode temps réel est disponible en disponibilité générale sur Databricks sur AWS, Azure et GCP. L'accélérateur de solution de détection de fraude est open-source et prêt à être déployé.
- Obtenez l'accélérateur de solution sur GitHub
- Documentation du mode temps réel
- Annonce de la disponibilité générale du mode temps réel
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.