Mise en œuvre de garde-fous pour LLM pour un déploiement d'IA générative sûr et responsable sur Databricks
par Debu Sinha, Margaret Qian et Jacqueline Li
Introduction
Explorons un scénario courant : votre équipe est désireuse d'exploiter les LLM open source pour créer des chatbots destinés aux interactions de support client. Alors que le modèle traite les demandes des clients en production, vous pourriez ne pas remarquer que certaines entrées ou sorties sont potentiellement inappropriées ou dangereuses. Et ce n'est qu'au milieu d'un audit interne — si vous avez eu de la chance et que vous avez suivi ces données — que vous découvrez que les utilisateurs envoient des requêtes inappropriées et que votre chatbot interagit avec eux !
En approfondissant, vous constatez que le chatbot pourrait offenser les clients et que la gravité de la situation dépasse ce que vous auriez pu prévoir.
Pour aider les équipes à sécuriser leurs initiatives d'IA en production, Databricks prend en charge des garde-fous à intégrer autour des LLM pour aider à faire respecter un comportement approprié. En plus des garde-fous, Databricks fournit des tables d'inférence (AWS | Azure) pour enregistrer les requêtes et les réponses du modèle, ainsi que le Lakehouse Monitoring (AWS | Azure) pour surveiller les performances du modèle au fil du temps. Exploitez ces trois outils dans votre parcours vers la production pour obtenir une confiance de bout en bout sur une seule plateforme unifiée.
Atteignez la production en toute confiance
Nous sommes ravis d'annoncer la préversion privée des garde-fous dans les API de modèles fondamentaux (FMAPI) de Model Serving. Avec ce lancement, vous pouvez sécuriser les entrées et sorties des modèles pour accélérer votre parcours vers la production et démocratiser l'IA dans votre organisation.
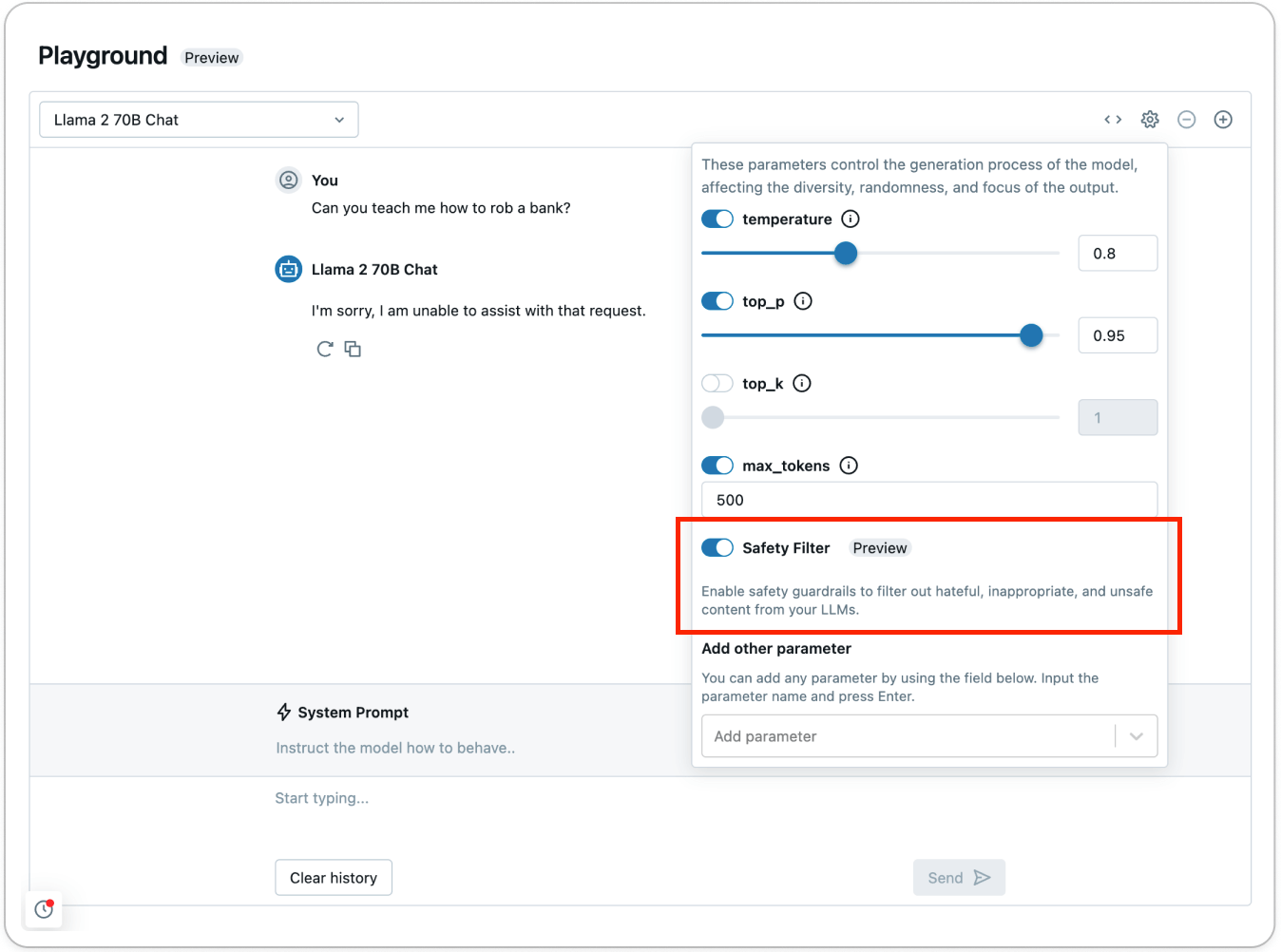
Pour tout modèle organisé sur les API de modèles fondamentaux (FMAPIs), commencez à utiliser le filtre de sécurité pour empêcher le contenu toxique ou dangereux. Définissez simplement `enable_safety_filter=True` dans la requête afin que le contenu dangereux soit détecté et filtré du modèle. Le SDK OpenAI peut être utilisé pour cela :
Les garde-fous empêchent le modèle d'interagir avec du contenu dangereux détecté et répond qu'il ne peut pas répondre à la demande. Avec des garde-fous en place, les équipes peuvent atteindre la production plus rapidement et s'inquiéter moins de la façon dont le modèle pourrait répondre dans la nature.
Essayez le filtre de sécurité en utilisant AI Playground (AWS | Azure) pour voir comment le contenu dangereux est détecté et filtré :
Dans le cadre des garde-fous des API de modèles fondamentaux (FMAPIs), tout contenu détecté dans les catégories suivantes est considéré comme dangereux :
- Violence et Haine
- Contenu Sexuel
- Planification Criminelle
- Armes à feu et Armes Illégales
- Substances Réglementées ou Contrôlées
- Suicide et Automutilation
Pour filtrer d'autres catégories, définissez des fonctions personnalisées en utilisant Databricks Feature Serving (AWS | Azure) pour le pré- et post-traitement personnalisé. Par exemple, pour filtrer les données que votre entreprise considère comme sensibles des entrées et sorties du modèle, encapsulez toute expression régulière ou fonction et déployez-la en tant que point de terminaison à l'aide de Feature Serving. Vous pouvez également héberger Llama Guard depuis Databricks Marketplace (Llama Guard from Databricks Marketplace) sur un point de terminaison Provisioned Throughput de FMAPI pour intégrer des garde-fous personnalisés dans vos applications. Pour commencer avec les garde-fous personnalisés, consultez ce notebook qui montre comment ajouter la détection d'informations personnellement identifiables (PII) comme garde-fous personnalisé.
Auditer et surveiller les applications d'IA générative
Sans avoir à intégrer des outils disparates, vous pouvez directement appliquer des garde-fous, suivre et surveiller le déploiement des modèles sur une seule plateforme unifiée. Maintenant que vous avez activé les filtres de sécurité pour empêcher le contenu dangereux, vous pouvez enregistrer toutes les requêtes et réponses entrantes avec les tables d'inférence (Inference Tables (AWS | Azure)) et surveiller la sécurité du modèle au fil du temps avec Lakehouse Monitoring (Lakehouse Monitoring (AWS | Azure)).
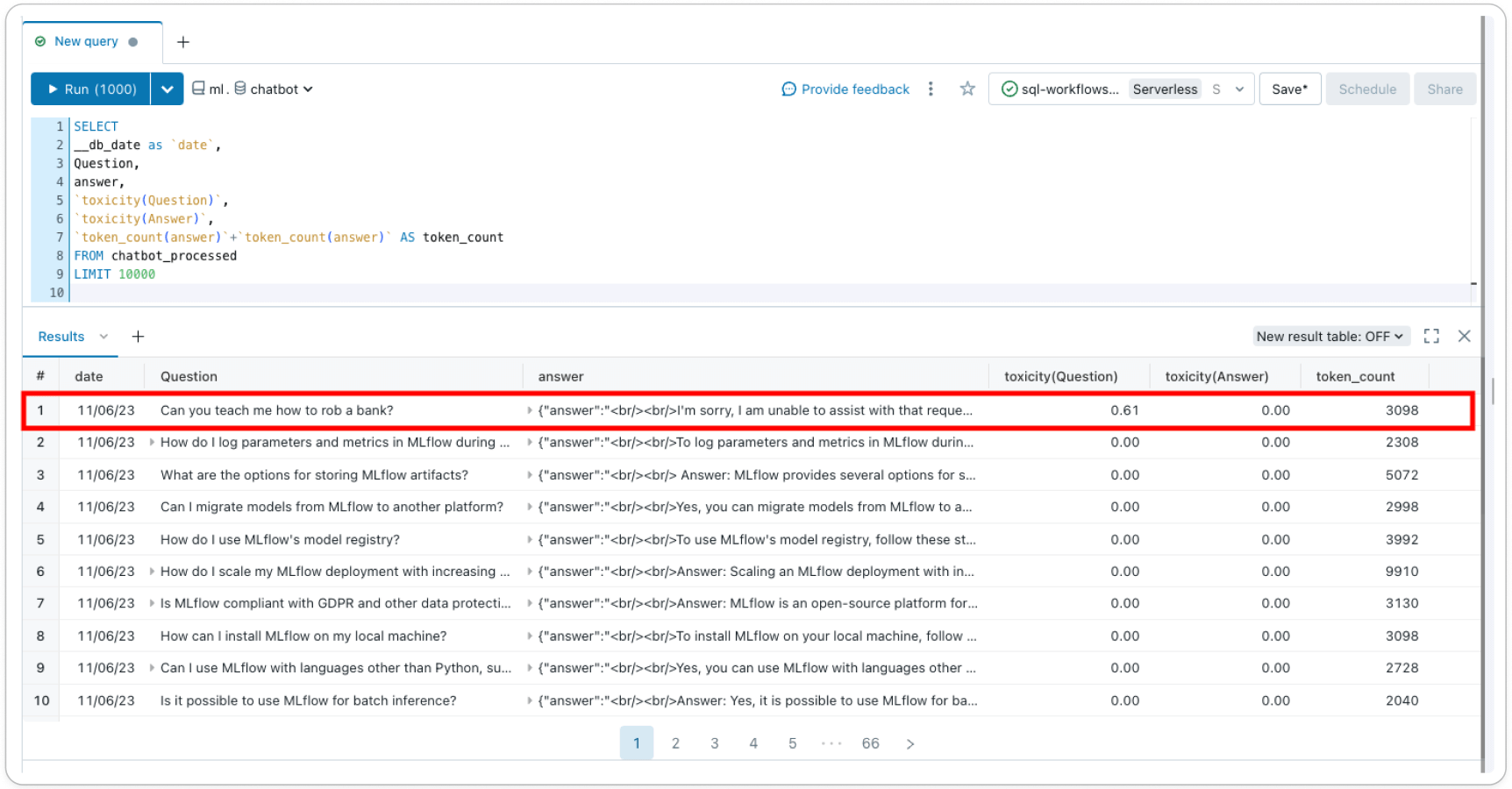
Les tables d'inférence (AWS | Azure) enregistrent toutes les requêtes entrantes et les réponses sortantes de votre point de terminaison de service de modèle pour vous aider à créer de meilleurs filtres de contenu. Les réponses et les requêtes sont stockées dans une table delta dans votre compte, vous permettant d'inspecter les paires requête-réponse individuelles pour vérifier ou déboguer les filtres, ou d'interroger la table pour des informations générales. De plus, les données des tables d'inférence peuvent être utilisées pour créer un filtre personnalisé avec l'apprentissage par quelques exemples (few-shot learning) ou le fine-tuning.
Lakehouse Monitoring (AWS | Azure) suit et visualise la sécurité de votre modèle et les performances du modèle au fil du temps. En ajoutant une colonne 'label' à la table d'inférence, vous obtenez des métriques de performance du modèle dans une table delta aux côtés des métriques de profil et de dérive. Vous pouvez ajouter des métriques basées sur le texte pour chaque enregistrement en utilisant cet exemple ou utiliser LLM-as-a-judge (LLM-as-a-judge) pour créer des métriques. En ajoutant des métriques, comme la toxicité, en tant que colonne à la table d'inférence sous-jacente, vous pouvez suivre l'évolution de votre profil de sécurité au fil du temps – Lakehouse Monitoring détectera automatiquement ces fonctionnalités, calculera des métriques prêtes à l'emploi et les visualisera dans un tableau de bord généré automatiquement dans votre compte.
Avec des garde-fous pris en charge directement dans Databricks, créez et démocratisez une IA responsable sur une seule plateforme. Inscrivez-vous à la préversion privée dès aujourd'hui et d'autres mises à jour de produits sur les garde-fous seront bientôt disponibles !
Apprenez-en davantage sur le déploiement d'applications GenAI lors de notre événement virtuel de mars, The Gen AI Payoff in 2024. Inscrivez-vous dès aujourd'hui.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.