Annonce des métriques LLM-as-a-judge de MLflow 2.8 et des meilleures pratiques pour l'évaluation des applications RAG par LLM, Partie 2
par Quinn Leng, Kasey Uhlenhuth, Alkis Polyzotis, Abe Omorogbe et Sunish Sheth
Aujourd'hui, nous sommes ravis d'annoncer que MLflow 2.8 prend en charge nos métriques LLM-as-a-judge, qui peuvent aider à économiser du temps et de l'argent tout en fournissant une approximation des métriques évaluées par des humains. Dans notre rapport précédent, nous avons présenté une étude de cas sur la manière dont la technique LLM-as-a-judge nous a aidés à améliorer l'efficacité, à réduire les coûts et à maintenir une cohérence de plus de 80 % avec les scores humains dans l'Assistant IA de la documentation Databricks, ce qui a entraîné des économies significatives de temps (passant de 2 semaines avec une main-d'œuvre humaine à 30 minutes avec des juges LLM) et de coûts (passant de 20 $ par tâche à 0,20 $ par tâche). Nous avons également donné suite à notre rapport précédent sur les meilleures pratiques pour l'évaluation LLM-as-a-judge des applications RAG (Retrieval Augmented Generation) avec une deuxième partie ci-dessous. Nous allons vous expliquer comment appliquer une méthodologie similaire, en combinaison avec le nettoyage des données, pour évaluer et ajuster les performances de vos propres applications RAG. Comme dans le rapport précédent, LLM-as-a-judge est un outil prometteur dans la suite des techniques d'évaluation nécessaires pour mesurer l'efficacité des applications basées sur les LLM. Dans de nombreuses situations, nous pensons que cela représente un juste milieu : il peut évaluer des sorties non structurées (comme la réponse d'un chatbot) de manière automatique, rapide et à faible coût. En ce sens, nous le considérons comme un digne complément à l'évaluation humaine, qui est plus lente et plus coûteuse, mais qui représente la référence absolue en matière d'évaluation de modèles.
Votre utilisation d'un service de LLM tiers (par ex., OpenAI) à des fins d'évaluation peut être soumise et régie par les conditions d'utilisation du service de LLM.
MLflow 2.8 : Évaluation automatisée
La communauté LLM a exploré l'utilisation des « LLM en tant que juges » pour l'évaluation automatisée et nous avons appliqué leur théorie à des projets de production. Nous avons constaté que vous pouvez économiser beaucoup de temps et d'argent si vous utilisez une évaluation automatisée avec des LLM de pointe, comme les familles de modèles GPT, MPT et Llama2, avec un seul exemple d'évaluation pour chaque critère. MLflow 2.8 introduit un framework puissant et personnalisable pour l'évaluation des LLM. Nous avons étendu l'API d'évaluation de MLflow pour prendre en charge les métriques GenAI et les exemples d'évaluation. Vous obtenez des métriques prêtes à l'emploi comme la toxicité, la latence, les jetons et plus encore, ainsi que des métriques GenAI qui utilisent GPT-4 comme juge par défaut, comme la fidélité, l'exactitude de la réponse et la similarité de la réponse. Des métriques personnalisées peuvent toujours être ajoutées dans MLflow, même pour les métriques GenAI. Voyons MLflow 2.8 en pratique avec quelques exemples !
Lorsque vous créez une métrique GenAI personnalisée avec la technique LLM-as-a-judge, vous devez choisir le LLM que vous voulez comme juge, fournir une échelle de notation et donner un exemple pour chaque note de l'échelle. Voici un exemple de la manière de définir une métrique GenAI pour le `Professionnalisme` dans MLflow 2.8 :
Comme nous l'avons vu dans notre précédent rapport, les exemples d'évaluation (la liste `examples` dans l'extrait de code ci-dessus) peuvent améliorer la précision de la métrique évaluée par le LLM. MLflow 2.8 facilite la définition d'un EvaluationExample :
Nous savons qu'il existe des métriques communes dont vous avez besoin, c'est pourquoi MLflow 2.8 prend en charge certaines métriques GenAI prêtes à l'emploi. En nous indiquant le `model_type` de votre application, p. ex. « question-answering », l'API d'évaluation de MLflow générera automatiquement des métriques GenAI communes pour vous. Vous pouvez également ajouter des métriques « supplémentaires », comme nous le faisons avec la « Pertinence de la réponse » dans l'exemple suivant :
Pour affiner davantage les performances, vous pouvez également modifier le modèle de juge et le prompt pour ces métriques GenAI prêtes à l'emploi. Vous trouverez ci-dessous une capture d'écran de l'interface utilisateur de MLflow qui vous aide à comparer rapidement visuellement les métriques GenAI dans le tab Évaluation :
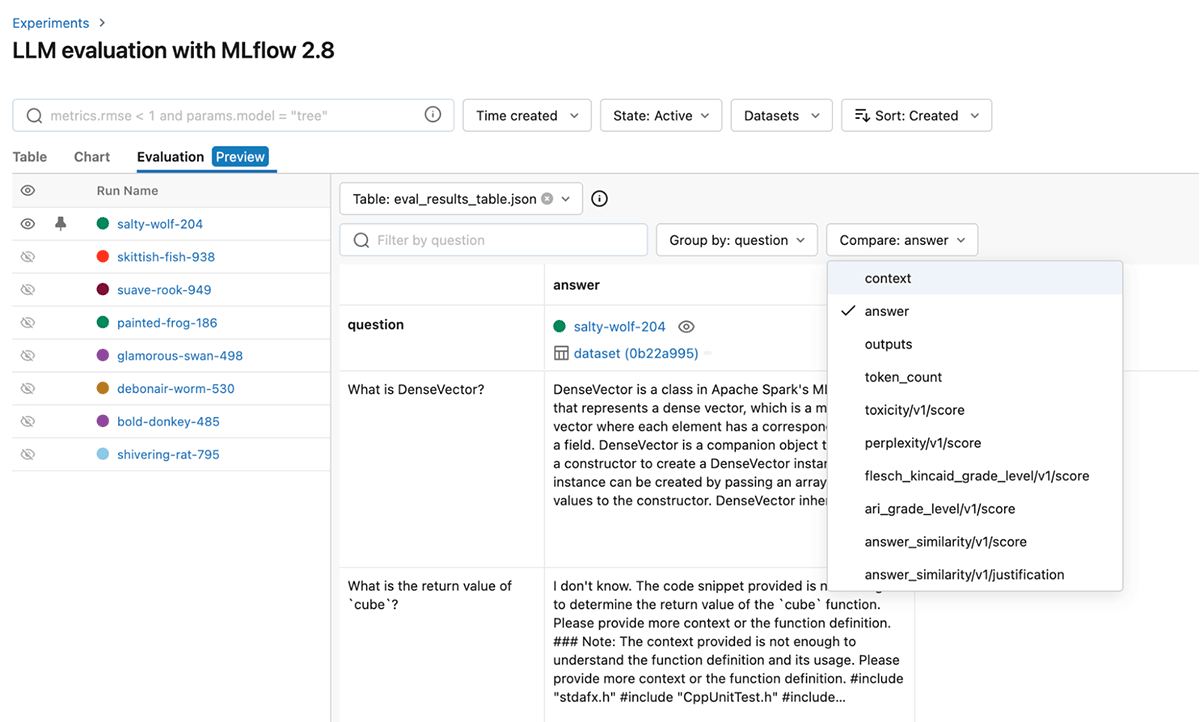
Vous pouvez également afficher les résultats dans le fichier eval_results_table.json correspondant ou les charger en tant que DataFrame Pandas pour une analyse plus approfondie.
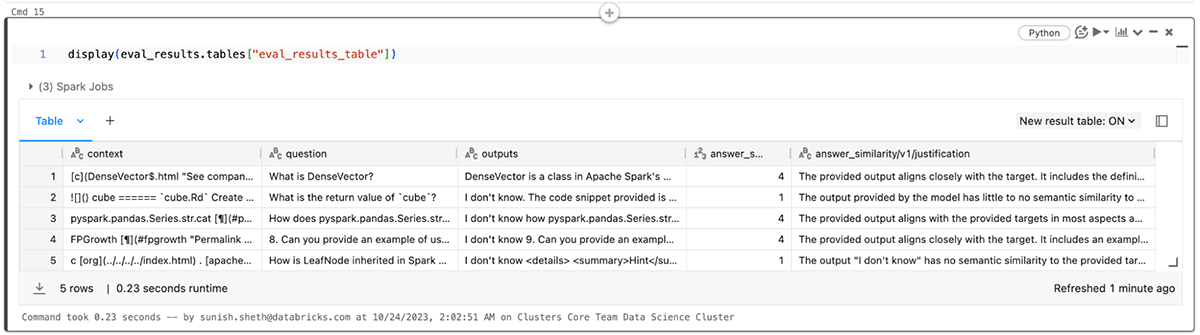
Application de l'évaluation des LLM aux applications RAG : Partie 2
Lors de la prochaine phase de nos recherches, nous avons réexaminé notre application de production de l'Assistant IA de la documentation Databricks pour voir si nous pouvions améliorer les performances en améliorant la qualité des données d'entrée. À partir de cette investigation, nous avons développé un workflow pour nettoyer automatiquement les données, ce qui a permis d'obtenir une plus grande exactitude et lisibilité des réponses du chatbot, ainsi qu'une réduction du nombre de jetons pour diminuer les coûts et améliorer la vitesse.
Nettoyage des données pour une auto-évaluation efficace des applications RAG
Nous avons exploré l'impact de la qualité des données sur la performance des réponses du chatbot, ainsi que diverses techniques de nettoyage des données pour améliorer la performance. Nous pensons que ces conclusions peuvent être généralisées et aider votre équipe à évaluer efficacement les chatbots basés sur RAG :
- Le nettoyage des données a amélioré l'exactitude des réponses générées par le LLM jusqu'à +20 % (de 3,58 à 4,59 pour une échelle de notation de 1 à 5)
- Un avantage inattendu du nettoyage des données est qu'il peut réduire les coûts en nécessitant moins de jetons. Le nettoyage des données a réduit le nombre de jetons pour le contexte jusqu'à -64 % (de 965 538 jetons dans les données indexées à 348 542 jetons après nettoyage)
- Différents LLM se comportent mieux avec différents codes de nettoyage de données
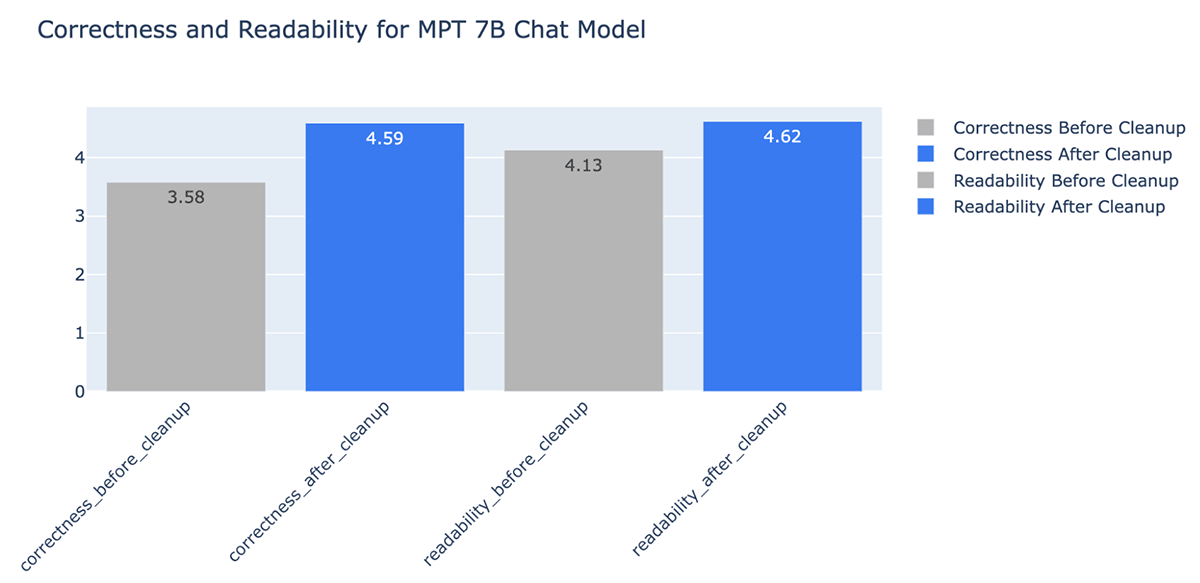
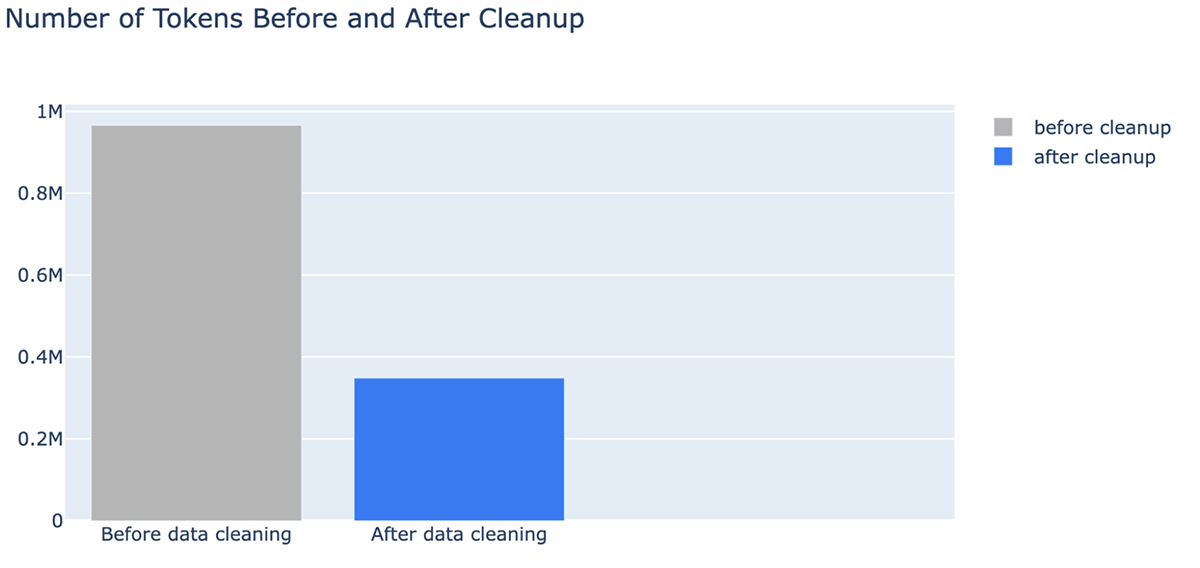
Défis liés aux données avec les applications RAG
Il existe différents types de données d'entrée pour les applications RAG : pages de sites web, PDF, Google Docs, pages Wiki, etc. Les types de données les plus fréquemment utilisés que nous avons observés dans l'industrie et chez nos clients sont les sites web et les PDF. Notre assistant Databricks Document AI utilise la documentation officielle de Databricks, la base de connaissances et les pages de documentation de Spark comme sources de données. Bien que les sites web de documentation soient lisibles par l'homme, le format peut être difficile à comprendre pour un LLM. Voici un exemple ci-dessous :
| Rendu pour l'humain | Rendu pour LLM |
|---|---|
 |  |
Ici, le format Markdown et les options de langage des extraits de code fournissent une interface utilisateur facile à comprendre pour présenter les exemples correspondants pour chaque langue. Toutefois, une fois que cette interface utilisateur est convertie uniquement au format Markdown pour un LLM, le contenu est converti en plusieurs blocs de code répétitifs, ce qui le rend difficile à comprendre. Par conséquent, lorsque nous avons posé la question à mpt-7b-chat "Comment configurer un nom de catalogue par défaut différent ?" compte tenu du contexte, il fournit comme réponse "``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ```", ce qui est la répétition du symbole de bloc de code. Dans d'autres cas, le LLM ne parvient pas à suivre les instructions et commence à répéter les questions. De même, une page web peut contenir diverses icônes, images et symboles spéciaux qui doivent être utilisés par le navigateur pour rendre une meilleure interface utilisateur, ce qui embrouille également les LLM. Notez qu'une autre approche consiste à modifier le prompt pour ignorer le balisage de formatage. Cependant, nous prévoyons d'ajuster davantage le prompt pour l'application particulière, et nous préférerions éviter de le rendre trop compliqué et d'introduire de l'instabilité.
Le nettoyage des données améliore les performances
Nous avons écrit un flux de travail rapide qui a exploité le concept LLM-as-judge et a déterminé de manière itérative le code de nettoyage pour supprimer les jetons de formatage superflus des fichiers Markdown et des pages web. Voici un exemple de ce à quoi ressemble un document unique avant et après le nettoyage, illustrant que le document conserve à la fois sa structure et sa signification :

Vous pouvez également voir clairement que le nettoyage des documents peut réduire considérablement le nombre de jetons utilisés dans une fenêtre de contexte LLM, ce qui permet d'économiser du temps et de l'argent. Après le nettoyage des données, nous avons constaté des améliorations dans la réponse de MPT-7B-Chat :
| Question | Réponse avant nettoyage | Réponse après nettoyage |
|---|---|---|
| Quelle est la syntaxe pour créer un schéma avec Spark SQL ? | ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Pour créer un schéma à l'aide de Spark SQL, vous pouvez utiliser la syntaxe suivante : CREATE SCHEMA [schema_name] Vous pouvez spécifier l'emplacement du schéma à l'aide de la clause LOCATION, et vous pouvez également fournir une de… |
| Quels sont les Résultats par Objet courants pour le stockage S3, ADLS Gen2 et GCS ? | Quels sont les résultats courants par objet pour le stockage S3, ADLS Gen2 et GCS ? ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Les Résultats par Objet courants pour le stockage S3, ADLS Gen2 et GCS sont : 1 (répertoire de base) 365 (par jour) 24 heures) 8761 Il s'agit du nombre total d'appels d'API au stockage d'objets qui seront effectués par jour, se… |
| Comment épingler un persona dans la barre latérale ? | Merci pour votre aide ! | Pour épingler un persona dans la barre latérale, vous pouvez cliquer sur l'icône du persona sous le logo Databricks, sélectionner le persona souhaité et cliquer sur le bouton « Épingler le persona ». Cela garantira que la personne sélectionnée… |
| Quelles API sont disponibles dans Databricks ? | réponse réponse : Il existe trois types de SQL warehouses disponibles dans Databricks : Serverless, Pro et Classic. Le type de SQL warehouse par default est Pro, mais il peut être défini sur Serverless ou Classic à l'aide de | Plusieurs API sont disponibles dans Databricks pour l'entreposage des données, notamment l'API SQL warehouse, l'API de requêtes, l'API de visualisations et l'API de tableaux de bord. Ces API fournissent une gamme de fonc… |
Essayez MLflow 2.8 dès aujourd'hui pour l'auto-évaluation
Dans la partie 2 de notre analyse, nous avons utilisé MLflow 2.8 pour évaluer les applications RAG avec LLM-as-a-judge. Maintenant, avec le nettoyage des données et l'auto-évaluation, vous pouvez comparer rapidement et efficacement différents LLM pour répondre aux exigences de votre application RAG. Quelques Ressources pour vous aider à démarrer :
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.