La prochaine ère du Lakehouse ouvert : Apache Iceberg™ v3 en aperçu public sur Databricks
Performance complète. Interopérabilité complète. Sans compromis.
par Ryan Blue, Daniel Weeks, Jason Reid, Benjamin Mathew et Hao Jiang
• Unity Catalog est le hub central de votre écosystème Iceberg - peu importe les moteurs ou les catalogues que votre équipe utilise, tous les outils lisent les mêmes données avec une gouvernance cohérente et détaillée
• Iceberg v3 introduit la lignée des lignes (Row Lineage), les vecteurs de suppression (Deletion Vectors) et VARIANT, permettant un traitement incrémental haute performance et des charges de travail de données semi-structurées
• Iceberg v3 met fin au compromis performance vs interopérabilité : les vecteurs de suppression, la lignée des lignes et VARIANT font partie de la spécification ouverte, ainsi les équipes de données obtiennent ces gains de performance sans sacrifier la compatibilité inter-moteurs
Aujourd'hui, la prise en charge par Databricks d'Iceberg v3 entre en aperçu public, débloquant les dernières innovations de la communauté Iceberg nativement sur le lakehouse ouvert.
Iceberg v3 marque une étape majeure pour les formats de table ouverts, débloquant des cas d'utilisation pour le traitement incrémental des données et l'analyse des données semi-structurées qui nécessitaient auparavant des solutions de contournement fragiles. Au-delà de cela, Iceberg v3 représente une innovation technologique significative en unifiant davantage la couche de données d'Iceberg et de Delta Lake, éliminant le besoin de réécrire les données lors de la construction de pipelines interopérables.
Voici les nouveautés d'Iceberg v3, pourquoi c'est important et pourquoi Databricks est le meilleur endroit pour exécuter votre lakehouse.
Quoi de neuf dans Iceberg v3 ?
Les tables Iceberg gérées par Unity Catalog v3 prennent en charge la lignée des lignes (Row Lineage), les vecteurs de suppression (Deletion Vectors) et VARIANT, débloquant de nouveaux cas d'utilisation et des avantages de performance significatifs. Databricks peut également interagir avec ces fonctionnalités sur des tables Iceberg étrangères (tables Iceberg enregistrées dans d'autres catalogues), permettant aux clients de créer des agents et des applications d'IA sur leurs données, où qu'elles se trouvent.
Traitement incrémental à grande échelle : lignée des lignes et vecteurs de suppression
La plupart des données arrivent sous forme de flux de modifications (INSERTs, UPDATEs, MERGEs, DELETEs) plutôt qu'en lots, généralement provenant de bases de données opérationnelles, de flux d'événements et d'API tierces. Historiquement, le traitement de ces modifications nécessitait de résoudre deux problèmes difficiles :
- Identifier quelles lignes ont changé dans les jeux de données bronze
- Appliquer ces modifications efficacement aux jeux de données argent/or
Les équipes avaient l'habitude de recourir à des scans de table complets ou à des systèmes CDC externes pour détecter les modifications, et à des réécritures de fichiers coûteuses pour les appliquer. Il en résultait des pipelines lents, coûteux à maintenir, sujets à la dérive et aux silos de données.
Désormais, la lignée des lignes permet aux équipes d'identifier rapidement les lignes modifiées. Chaque ligne d'une table Iceberg v3 porte un ID de ligne permanent et un numéro de séquence reflétant la dernière modification de la ligne.
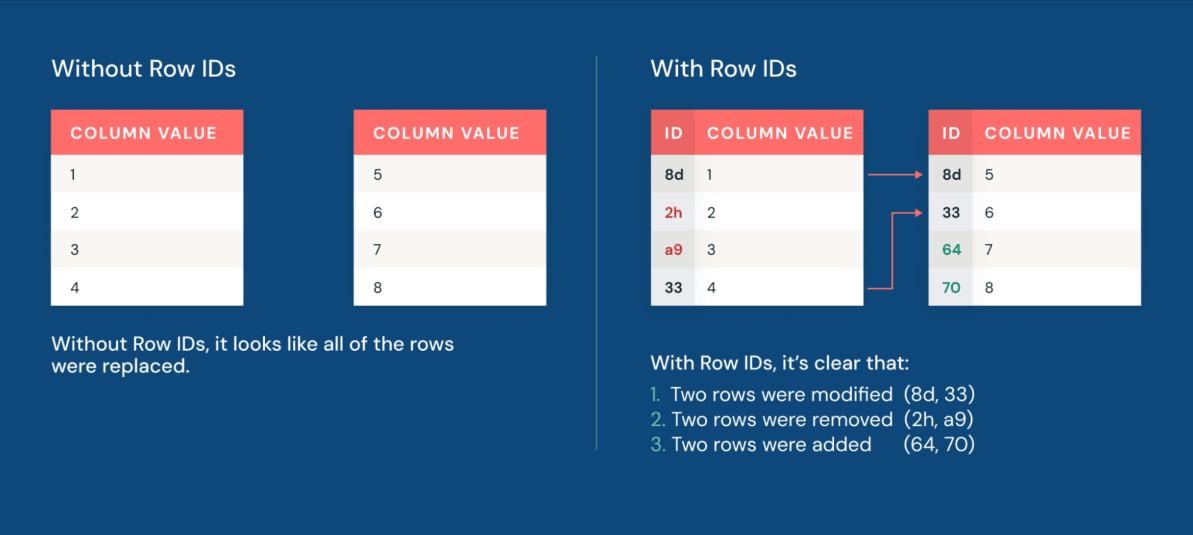
De plus, les vecteurs de suppression rendent l'application des modifications aux jeux de données plus performante que jamais. Les vecteurs de suppression permettent à Iceberg de suivre les lignes qui ont été logiquement supprimées sans réécrire immédiatement les fichiers de données sous-jacents. Au lieu de supprimer physiquement les lignes en réécrivant de gros fichiers Parquet, le moteur écrit un fichier de suppression léger à côté des données. Le résultat est une performance de manipulation des données jusqu'à 10 fois plus rapide que l'approche traditionnelle de copie sur écriture (copy-on-write).

Avec les vecteurs de suppression désormais natifs à Iceberg, Geodis peut construire son Lakehouse Iceberg sur Databricks sans compromettre les performances ou le choix du moteur.
« Maintenant que les vecteurs de suppression sont intégrés à Iceberg, nous pouvons centraliser notre parc de données Iceberg dans Unity Catalog, tout en exploitant le moteur de notre choix et en maintenant des performances de pointe. » —Delio Amato, Architecte en chef et Data Officer, Geodis
Ensemble, la lignée des lignes et les vecteurs de suppression font de la CDC une propriété native de la table elle-même. Les équipes peuvent construire des pipelines qui se concentrent sur le traitement incrémental de uniquement ce qui a réellement changé, réduisant les coûts et accélérant le délai de compréhension pour chaque analyste et scientifique des données en aval.

Données semi-structurées comme citoyen de première classe via VARIANT
Les journaux, les réponses d'API, les flux de clics et les charges utiles IoT sont des sources de données semi-structurées très précieuses. À mesure qu'ils évoluent, les modèles d'IA peuvent s'adapter avec eux, en apprenant directement des signaux changeants du monde réel.
Cependant, historiquement, les équipes de données étaient confrontées à un compromis douloureux lorsqu'elles travaillaient avec des données semi-structurées. Une approche standard consistait à imposer des schémas rigides, mais cela entraînait des pipelines fragiles qui cassaient chaque fois que les données en amont évoluaient. Une autre solution de contournement canonique consistait à stocker les données sous forme de dumps de chaînes de caractères brutes, mais cela rendait les requêtes très complexes et lentes. Aucune des deux approches n'était évolutive.
Le type VARIANT d'Iceberg v3 résout ce compromis. VARIANT est un type de colonne natif qui stocke des charges utiles semi-structurées aux côtés de colonnes relationnelles dans la même table Iceberg. Cela ne nécessite aucune mise à plat, aucun stockage dans un système séparé, ni aucun pipeline ETL pour la normalisation. Les équipes de données peuvent plutôt ingérer des données semi-structurées brutes telles quelles et les interroger avec SQL standard.

Panther utilise VARIANT pour alimenter l'ingestion et l'analyse à grande échelle sur des journaux de sécurité semi-structurés.
« Unity Catalog et Iceberg v3 libèrent la puissance des données semi-structurées grâce à VARIANT. Cela permet l'interopérabilité et la collecte de journaux à l'échelle du pétaoctet, rentable. » —Russell Leighton, Architecte en chef, Panther
Avec VARIANT, vos modèles d'IA et vos pipelines d'analyse fonctionnent directement sur des données vivantes et évolutives dans une seule table gouvernée. Lorsque de nouveaux champs apparaissent dans les réponses d'API ou que de nouveaux types d'événements entrent dans les flux de clics, ils sont immédiatement interrogeables sans migration de schéma. Grâce à des optimisations de performance comme le déchiquetage (shredding), les clients peuvent bénéficier de performances de type colonne sur leurs données semi-structurées, débloquant des pipelines de BI, de tableaux de bord et d'alerte à faible latence.
Unity Catalog offre l'interopérabilité et la performance pour les entreprises multi-moteurs et multi-catalogues
Les entreprises modernes s'appuient sur plusieurs moteurs et catalogues pour prendre en charge divers cas d'utilisation dans les unités commerciales et les systèmes existants. Unity Catalog a été conçu pour permettre l'interopérabilité et la gouvernance entre les catalogues, tout en optimisant les dispositions des données en fonction des modèles de requête.
Gouvernance unifiée sur les catalogues et les moteurs
Les API ouvertes d'Unity Catalog permettent aux clients d'écrire une fois et de lire n'importe où - plus de duplication de données ou de contrôles d'accès cloisonnés. UC peut fédérer vers d'autres catalogues Iceberg, permettant une interopérabilité bidirectionnelle. Toutes les données Iceberg dans Snowflake, AWS Glue, Salesforce et d'autres catalogues majeurs peuvent être lues par Unity Catalog, et toutes les données dans UC peuvent être accessibles par ces mêmes plateformes tierces via des API ouvertes.
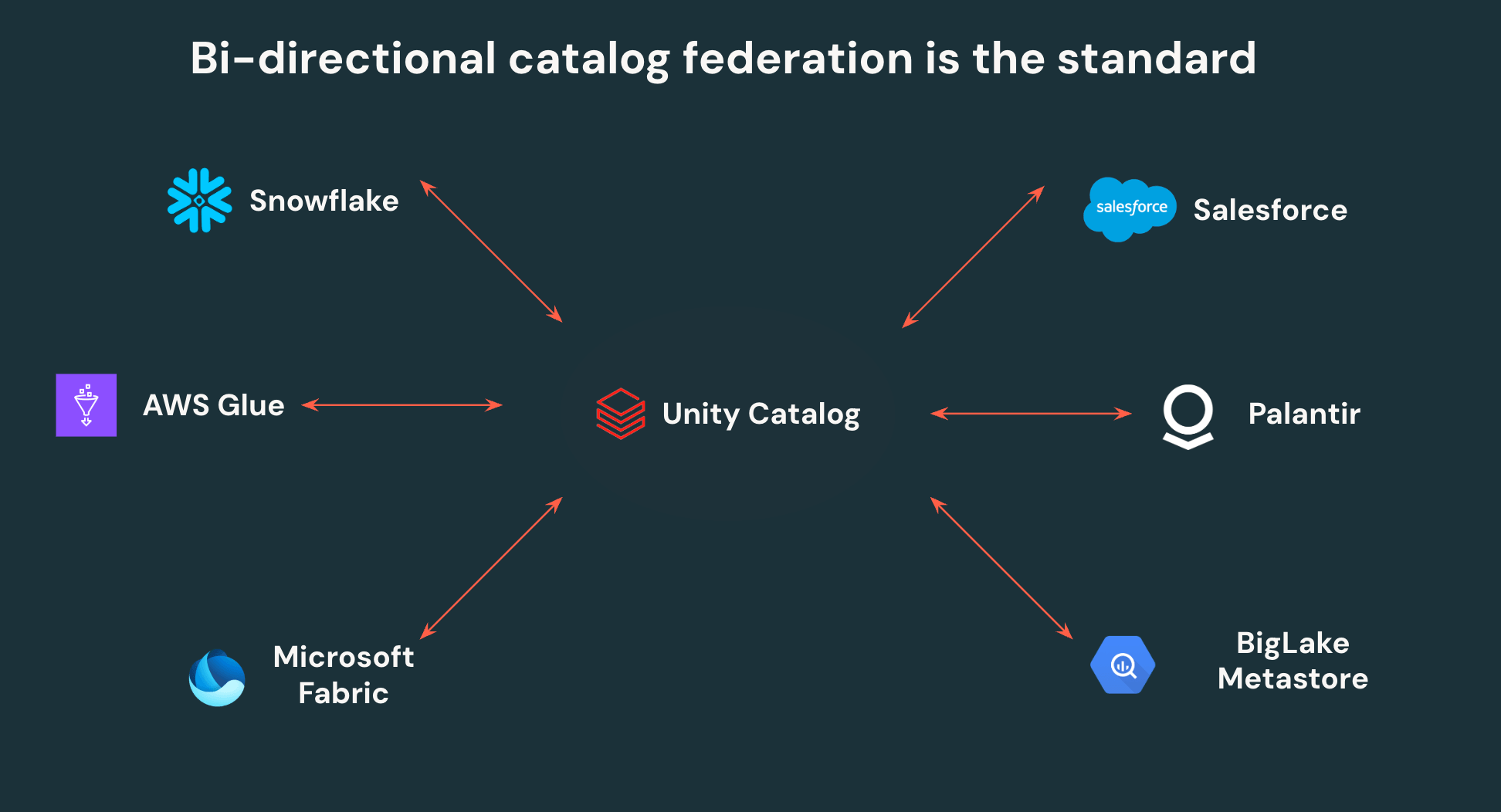
Au-delà de cela, Unity Catalog est le premier catalogue à prendre en charge le contrôle d'accès granulaire sur les moteurs externes, permettant aux équipes de définir des filtres de lignes et des masques de colonnes une seule fois et de les faire appliquer partout où les données sont accessibles. La centralisation de la gouvernance sur Unity Catalog permet aux équipes de sécurité de gouverner et de surveiller leur lakehouse beaucoup plus facilement, tout en donnant aux équipes de données l'autonomie de pointer n'importe quel outil vers leur lakehouse.

Interopérabilité Delta et Iceberg
Delta Lake avec UniForm débloque l'interopérabilité entre les écosystèmes Delta Lake et Iceberg des clients : écrivez une fois sur Delta Lake, et lisez en tant qu'Iceberg depuis Snowflake, BigQuery, Redshift, Athena, Trino, ou tout autre moteur Iceberg. Avec Iceberg v3 adoptant nativement les vecteurs de suppression, la lignée des lignes et VARIANT, les clients ne sont plus confrontés à un compromis entre les fonctionnalités de performance de Delta Lake et la compatibilité Iceberg. Le résultat est une seule copie des données qui dessert tous les moteurs de votre pile, sans pipelines de réplication à maintenir ni risque de dérive. Un fournisseur de services financiers de premier plan a remplacé un service coûteux de réplication de table complète par UniForm, permettant à Snowflake de lire directement à partir des tables gérées par Unity Catalog.
Performance et optimisation automatisées
Au-delà de l'interopérabilité, Databricks réunit performance, optimisation de la disposition et gouvernance au sein d'un système unique afin que les équipes n'aient pas à assembler ces capacités elles-mêmes. Databricks combine la maintenance intelligente (Optimisation prédictive), les optimisations de la disposition physique basées sur les modèles de requêtes (Clustering liquide automatique) et la gouvernance inter-moteurs (Unity Catalog) en une seule couche, sans configuration manuelle requise.
D'autres offres gérées d'Iceberg exigent que les équipes gèrent indépendamment la maintenance des tables, la disposition des fichiers et l'application des politiques d'accès. Sur Databricks, ces capacités sont unifiées et automatiques, éliminant ainsi une catégorie entière de surcharge opérationnelle tout en préservant la portabilité complète des données.
Commencez avec Apache Iceberg v3 sur Databricks
Iceberg v3 sur Databricks est en aperçu public dès aujourd'hui ! Les équipes peuvent désormais tirer parti des meilleures fonctionnalités de Delta et d'Iceberg sans compromis entre performance et interopérabilité.
Iceberg v3 est disponible sur Databricks Runtime 18.0+ avec Unity Catalog activé.
La création d'une table Iceberg gérée par Unity Catalog avec v3 activé est facile :
La création d'une table Delta gérée par Unity Catalog avec UniForm et v3 activé est tout aussi simple :
Perspectives : Iceberg v4
Iceberg v3 unifie la couche de données entre Delta et Iceberg sur une base performante et interopérable – la prochaine frontière est la couche de métadonnées. Les ingénieurs Databricks pilotent activement plusieurs propositions clés pour Iceberg v4 au sein de la communauté Apache afin de rendre les métadonnées plus simples, plus rapides et plus évolutives. Celles-ci incluent l'arbre de métadonnées adaptatif, qui simplifie la structure des métadonnées de sorte que la plupart des opérations nécessitent l'écriture d'un seul fichier au lieu de plusieurs. Les propositions supplémentaires incluent la prise en charge des chemins relatifs pour un déplacement transparent des tables entre les environnements et un modèle de statistiques modernisé qui s'étend aux types de données plus récents comme VARIANT et GEOMETRY. Ensemble, ces avancées signifieront une ingestion plus rapide, une planification de requêtes plus efficace et une gestion des tables plus simple à l'échelle de l'entreprise. Nous sommes ravis de continuer à faire progresser la spécification Iceberg avec la communauté.
En savoir plus au Data and AI Summit
Commencez avec Iceberg v3 et rejoignez-nous au prochain Data and AI Summit à San Francisco, du 15 au 18 juin 2026, pour en savoir plus sur notre feuille de route Iceberg et notre travail dans l'écosystème.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.