Un Lakehouse Ouvert en Temps Réel avec Redpanda et Databricks
Les investissements de Redpanda dans l'intégration des premiers principes avec Iceberg et Unity Catalog créent une architecture durable pour offrir l'agilité du stream-to-table et alimenter un lakehouse ouvert en temps réel.
par Matt Schumpert et Jason Reid
- Transformez vos flux Kafka en tables Iceberg entièrement gérées par Unity Catalog en une seule étape, offrant une analyse de lakehouse en temps réel sans connecteurs lourds ni jobs ETL personnalisés.
- Exécutez des flux inférieurs à 10 ms et une ingestion Apache Iceberg™ à haut débit sur le même cluster Redpanda avec les sujets Iceberg qui gèrent le batching parquet, les commits exactly-once et les optimisations prédictives d'Unity, réduisant considérablement les coûts et les efforts opérationnels.
- Déployez n'importe où (SaaS, BYOC ou auto-géré) et construisez sur des standards ouverts avec les API Kafka, Iceberg V2 et REST Catalog ; des configurations déclaratives simples vous offrent un partitionnement personnalisé, une évolution de schéma et des DLQ intégrées dès le départ.
Chaque lakehouse devrait être « alimenté par flux »
Le concept de « lakehouse ouvert » lancé par Databricks il y a des années a été plus largement réalisé grâce à l'essor récent d'Apache Iceberg™, stimulé par les investissements des principaux fournisseurs dans l'intégration de frameworks, les outils, le support de catalogue et l'interopérabilité des données, s'engageant à utiliser Iceberg comme substrat commun pour un lakehouse ouvert. Les avancées telles que la capacité d' exposer les tables Delta Lake à l'écosystème Iceberg croissant via UniForm, le support de Unity Catalog pour les fonctionnalités avancées telles que l'optimisation prédictive et Iceberg REST avec les tables Iceberg gérées, et la récente unification de la couche de données Delta/Iceberg dans Iceberg V3 signifient désormais que les organisations peuvent adopter une stratégie de données « orientée Iceberg » en toute confiance, et sans compromettre l'utilisation des riches ensembles de fonctionnalités des produits lakehouse matures comme Databricks.
L'un des principaux acteurs manquants dans cette histoire d'accès universel aux données résidant dans le cloud via la langue commune d'Iceberg était les flux, notamment les sujets Kafka. Aujourd'hui, toute donnée structurée au repos peut être facilement intégrée nativement ou « décorée » en tant qu'Iceberg. Par contraste, les données de haute valeur en mouvement circulant via une plateforme de streaming qui alimente des applications en temps réel doivent encore être « ETLées » dans le lakehouse cible via un travail d'intégration de données point à point, par flux, ou en exécutant une infrastructure coûteuse de connecteur sur son propre cluster. Les deux approches utilisent un consommateur Kafka lourd, mettant la pression sur vos pipelines de livraison de données en temps réel, et créent un composant d'infrastructure intermédiaire à mettre à l'échelle, gérer et observer avec des compétences Kafka spécialisées. Les deux approches reviennent à insérer un péage très coûteux entre vos domaines de données en temps réel et d'analyse, un péage qui n'a vraiment pas lieu d'exister.
Alors que l'utilisation des stockages d'objets cloud pour sauvegarder les flux a mûri (Redpanda a ouvert la voie il y a plusieurs années) et que les formats de table ouverts ont pris le devant de la scène dans les lakehouses, ce mariage du flux vers la table est à la fois pratique et « destiné à être ». Databricks et Redpanda fournissent deux plateformes de données de classe mondiale qui font briller cette approche et font tourner les têtes. Ensemble, elles créent un substrat de données couvrant la prise de décision en temps réel, l'analyse et l'IA qui est difficile à battre. Concrètement, cette approche fusionne les flux avec les tables avec la facilité d'un indicateur de configuration. Elle agit comme un barrage à plusieurs chambres, acheminant des flux sélectionnables vers un lac de données unifié à la demande, fournissant des informations à la minute et débloquant la même inclusion arbitraire de données dans de nouveaux pipelines d'analyse que l'architecture lakehouse nous a apportée pour les tables, et maintenant grâce à l'ouverture élargie que l'écosystème Iceberg offre.
Fusionner de manière transparente l'infrastructure de données en temps réel et d'analyse pour faire d'un « lakehouse alimenté par flux » une affaire simple, non seulement débloque une valeur massive, mais résout également un problème d'ingénierie complexe qui exige une approche réfléchie pour être correctement abordé dans le cas général. Comme nous espérons l'illustrer ci-dessous, nous n'avons pas lésiné sur les moyens pour commercialiser cette capacité rapidement. En travaillant avec des dizaines de partenaires de conception (et Databricks) pendant plus d'un an, nous avons étendu la base de code unique de Redpanda d'une manière qui préserve les options de déploiement préférées de nos clients (y compris BYOC sur plusieurs clouds), maintient une compatibilité Kafka complète (ne laissez aucun workload derrière), et évite la duplication d'artefacts et d'étapes pour les utilisateurs autant que possible. Nous espérons que cette vision complète transparaîtra alors que nous exposons les principes directeurs pour la construction de Redpanda Iceberg Topics, qui sont maintenant disponibles avec Databricks Unity Catalog sur AWS et GCP !
Exécutez votre plateforme de flux vers lakehouse partout
Notre premier principe était de maintenir le choix et de rencontrer les utilisateurs là où ils se trouvent. Redpanda propose déjà des offres matures multi-cloud SaaS, BYOC et auto-gérées, des options de réseau privé souverain comme BYOVPC, et ne force généralement pas ses clients à changer de cloud, de réseau, de stockage objet, d'IdP, ou quoi que ce soit d'autre qui pourrait freiner l'adoption ou empêcher les propriétaires de plateforme de positionner leur déploiement de plateforme de streaming (y compris les plans de données et de contrôle), là où cela a le plus de sens pour eux. Indépendamment de ce choix, les utilisateurs bénéficient de toutes les fonctionnalités de la plateforme et d'une expérience utilisateur cohérente pour les développeurs et les administrateurs. Cette stratégie de produit à plateforme unique nous permet d'annoncer que les Iceberg Topics pour Databricks sont généralement disponibles aujourd'hui dans les clouds AWS, GCP et Azure, et que les organisations peuvent déployer en sachant qu'elles déploient le même produit avec le même moteur sous-jacent, la même compatibilité Kafka, le même modèle de sécurité, les mêmes caractéristiques de performance et les mêmes outils de gestion, si et quand elles changent de cloud ou de facteur de forme. Cette flexibilité et cette cohérence contrastent fortement avec les autres options du marché.
Unity Catalog, rencontrez la plateforme de streaming la plus unifiée
Deuxièmement, nous tenions à construire ceci comme un système unique, et qui en donne l'impression. Vous ne pouvez tout simplement pas fusionner deux concepts de manière efficace en assemblant deux architectures logicielles complètement différentes. Vous pouvez masquer certaines choses avec une façade SaaS, mais les architectures gonflées transparaissent dans les modèles de tarification, les performances et le coût total de possession au minimum, et dans le pire des cas, dans l'expérience utilisateur. Nous avons fait de notre mieux pour éviter cela.
Pour les développeurs, le « ressenti » d'un système unique signifie un cycle de vie CRUD unique et une expérience utilisateur cohérente pour les sujets sous forme de tables, et pour les éléments nécessaires à leur fonctionnement (à savoir, les schémas). Avec Iceberg Topics, vous ne copiez jamais d'entrées ou de configurations, ni ne les créez deux fois en utilisant une interface utilisateur distincte. Vous gérez une seule entité comme source de vérité pour les données et le schéma, en utilisant toujours les mêmes outils. Pour nous, cela signifie que vous effectuez des opérations CRUD via les outils que vous utilisez déjà : tout outil de l'écosystème Kafka, notre CLI rpk, les API REST de Cloud ou tout outil d'automatisation de déploiement Redpanda comme nos CRs K8s ou notre provider Terraform. Pour les schémas, c'est notre Schema Registry intégré avec son API standard largement accepté, qui définit implicitement le schéma de la table Iceberg, ou explicitement, selon votre préférence. Tout est piloté par la configuration et convivial pour DevOps. Et avec les nouvelles tables Iceberg gérées d'Unity Catalog, tous vos flux sont découvrables via les outils Databricks en tant que tables Iceberg et Delta Lake par défaut.
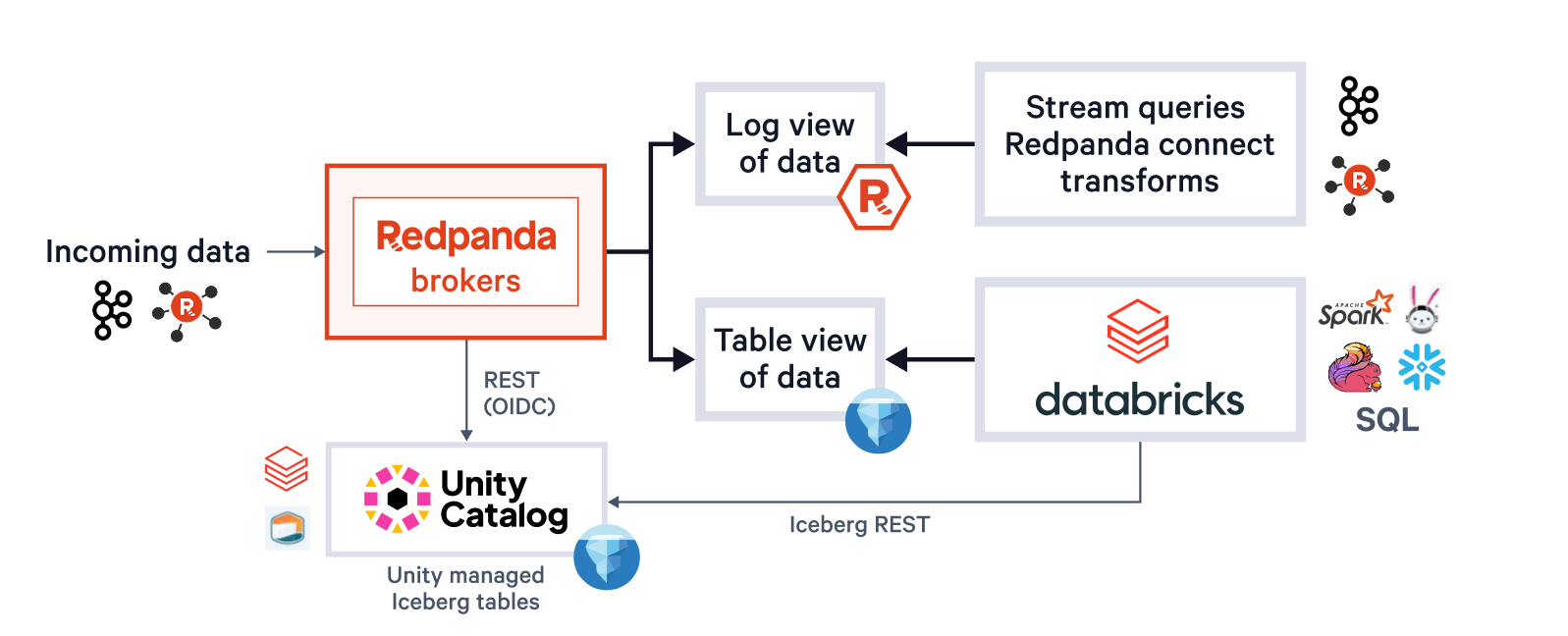
Un système unique concerne également l'opérateur de plateforme, qui ne devrait pas avoir à se soucier de gérer plusieurs buckets ou catalogues, d'optimiser la taille des fichiers Parquet, de tables en retard sur les flux lorsque les clusters sont limités en ressources, ou de défaillances de nœuds compromettant la livraison exactement une fois. Avec Redpanda Iceberg Topics, tout cela est autonome. Les opérateurs bénéficient d'écritures Parquet groupées dynamiquement et de commits Iceberg transactionnels qui s'ajustent à vos SLA d'arrivée de données, d'une surveillance automatique du retard qui génère une pression de retour sur le producteur Kafka lorsque nécessaire, et d'une livraison exactement une fois via le marquage d'instantané Iceberg (évitant les lacunes ou les doublons après des défaillances d'infrastructure).
Redpanda gère toutes vos données dans un seul bucket/conteneur, utilise un seul catalogue Iceberg dans Unity Catalog (que Redpanda surveille pour une récupération gracieuse), et rend les tables facilement découvrables en affichant le point de terminaison REST Iceberg d'Unity Catalog directement dans l'interface utilisateur de Redpanda Cloud. Et maintenant, avec les tables Iceberg gérées d'Unity Catalog, les opérations de maintenance des tables comme la compaction, l'expiration des données et l'optimisation prédictive sont intégrées et exécutées automatiquement par Unity Catalog en arrière-plan, tandis que Redpanda prend en charge les opérations de maintenance minimales appropriées à son rôle (actuellement le nettoyage des instantanés Iceberg et la création/suppression de tables). Les administrateurs Databricks peuvent ensuite sécuriser et gouverner ces tables en utilisant tous les privilèges Unity Catalog habituels.
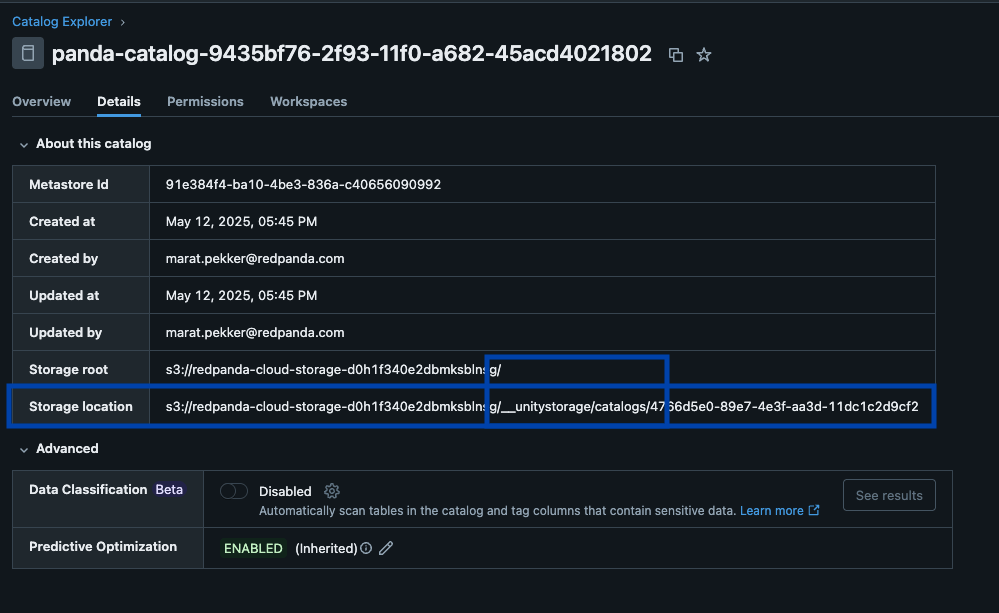
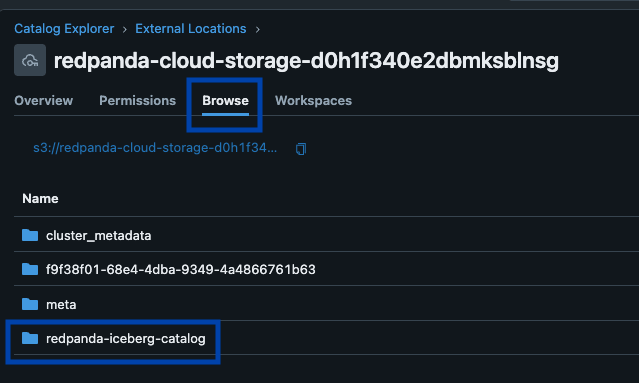
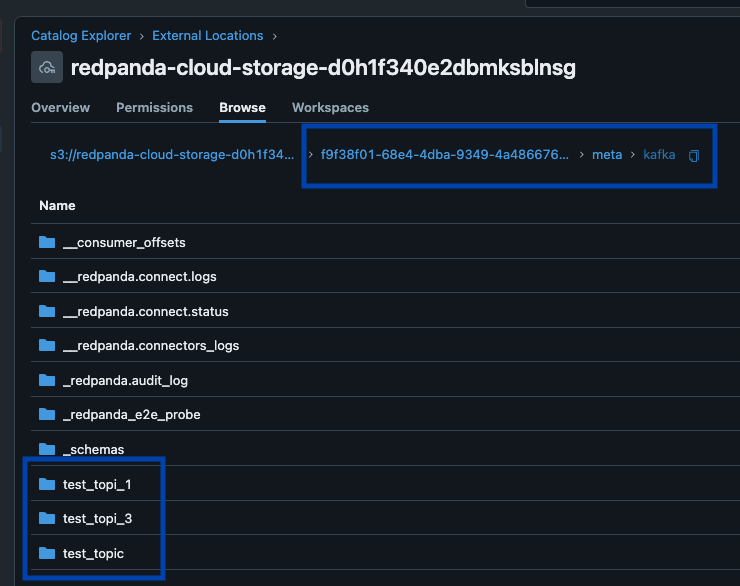
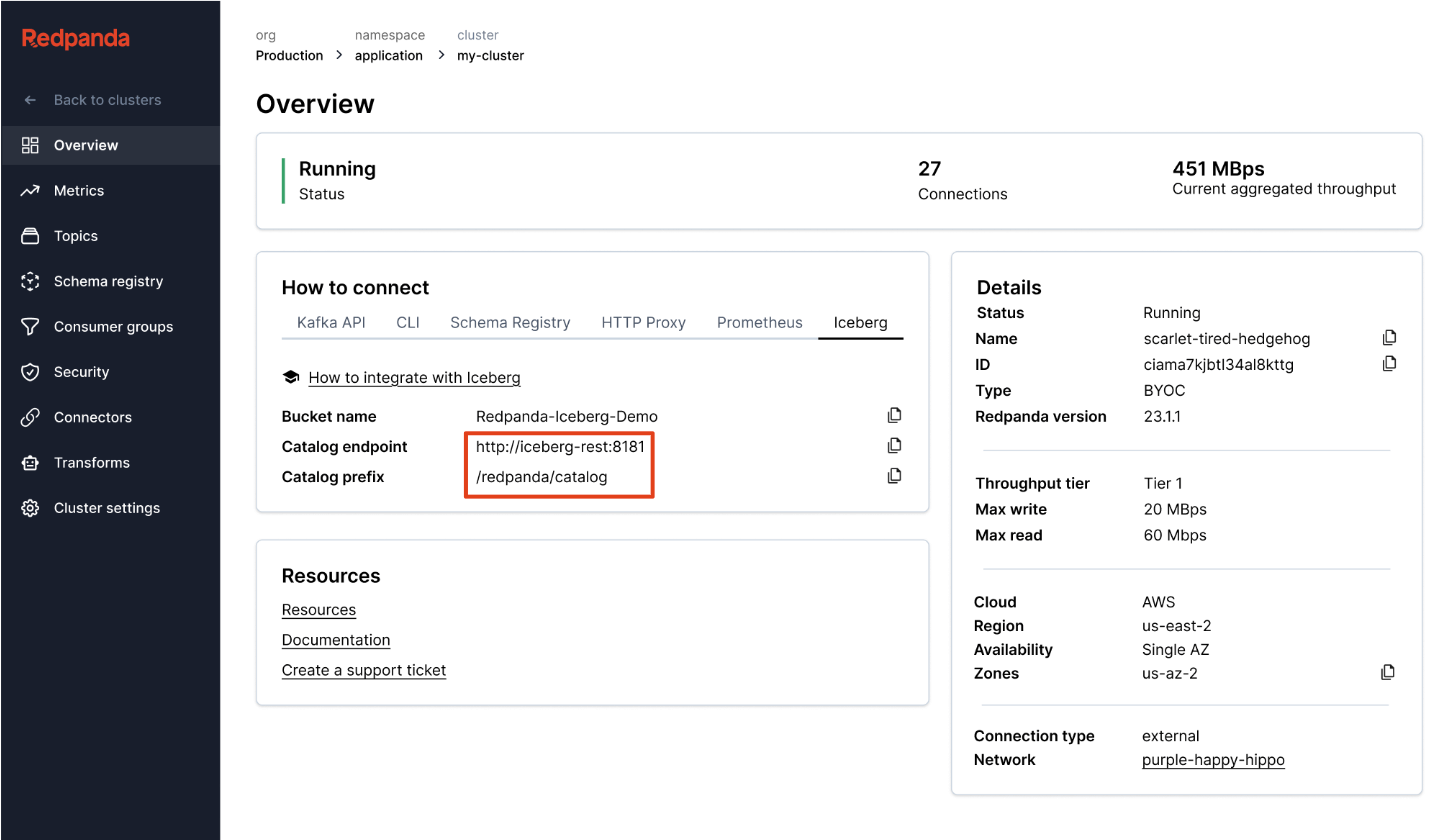
Un seul cluster pour tous les gouverner
Plus important encore, grâce à notre moteur de streaming multimodal R1 qui utilise une architecture thread par cœur et intègre des fonctionnalités comme la mise en cache en écriture et l'équilibrage multi-niveaux des données et des charges de travail, les administrateurs peuvent exécuter cette ingestion Iceberg à haut débit dans le même cluster, et avec les mêmes sujets qui alimentent les charges de travail Kafka existantes à faible latence avec des SLA inférieurs à 10 ms. En utilisant des opérations asynchrones et pipelinées verrouillées sur les mêmes cœurs de processeur qui gèrent les requêtes de production/consommation, nous gérons les deux charges de travail avec une efficacité maximale dans un seul processus. Plus important encore, Iceberg Topics peut tirer parti de l'ensemble complet des sémantiques Kafka, y compris les transactions Kafka et les sujets compactés, où la couche Iceberg ne reçoit que les enregistrements des transactions validées. Cette combinaison d'une architecture fondamentalement efficace qui résout les problèmes difficiles des sémantiques sophistiquées rapporte d'énormes dividendes en réduisant vos coûts d'exploitation car, eh bien, un seul cluster pour tous les gouverner. Aucun produit supplémentaire. Aucun cluster séparé. Pas de surveillance de pipelines. Déployez n'importe où. Gardez votre calme et continuez, administrateurs de plateformes de streaming.
Rendez-le simple
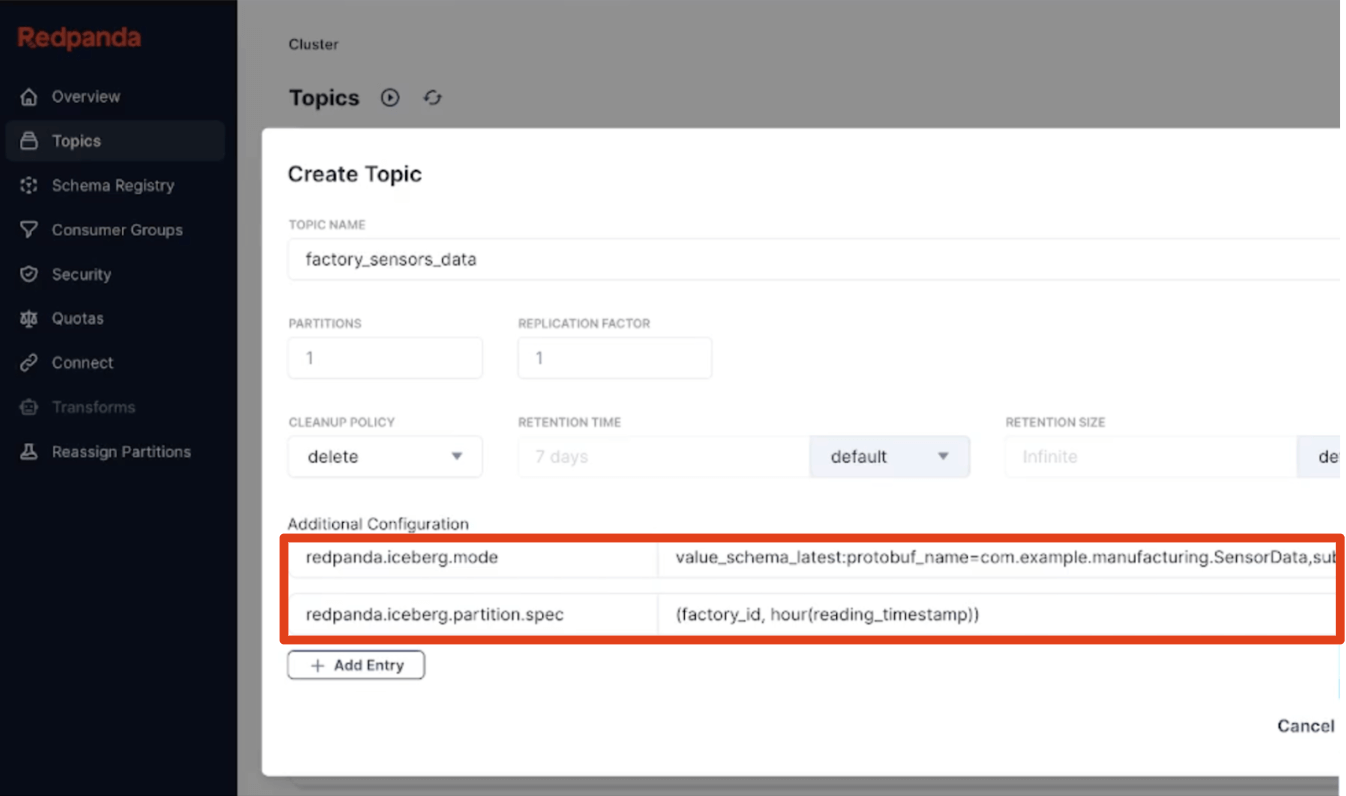
Notre troisième principe était de faire des choix opinionnés sur les comportements par défaut, permettant aux utilisateurs d'apprendre le système progressivement avec une configuration mains libres la plus intelligente possible qui fonctionne pour la plupart des cas d'utilisation. Cela signifie un partitionnement horaire intégré des tables (complètement dissocié des schémas de partitionnement des topics Kafka), des files d'attente de messages non distribués toujours actives pour capturer les données invalides, et des conventions simples et canoniques comme « dernière version » ou « TopicNameStrategy » pour l'inférence de schéma facilitent l'adoption. Nous apportons également les métadonnées Kafka comme les partitions de messages, les offsets et les clés dans le trajet sous forme de struct Iceberg, afin que les développeurs aient toute la provenance pour valider rapidement la correction de leurs pipelines de streaming en SQL Iceberg.

Le simple doit être simple, bien sûr, mais le sophistiqué doit aussi être simple. Ainsi, la définition de partitionnement personnalisé hiérarchique avec l'ensemble complet des transformations de partition Iceberg ou l'extraction d'un type de message Protobuf spécifique d'un sujet pour devenir votre schéma de table Iceberg sont, encore une fois, juste des propriétés de topic déclaratives en une seule ligne. Les schémas peuvent évoluer gracieusement car Redpanda applique l'évolution de table sur place. Et si vous en avez besoin, exécutez un SMT simple dans votre langue préférée qui diffuse des messages complexes d'un topic brut vers des tables de faits Iceberg plus simples en utilisant les transformations de données intégrées alimentées par WebAssembly. L'objectif ultime est d'atterrir prêt pour l'analyse en une seule passe. Boom, bonjour la couche Bronze.
La toile de fond de toutes ces innovations est, bien sûr, le projet Apache Iceberg en évolution rapide et ses spécifications, ainsi que l'engagement plus général de Redpanda envers les normes ouvertes. Cet engagement a commencé par son support précoce du protocole Kafka, du registre de schéma et des API de proxy HTTP, et même d'autres détails comme la configuration standard des topics qui permet aux organisations de migrer en toute transparence un parc entier d'applications Kafka sans modification. Dans le domaine Iceberg, Redpanda s'est imposé comme un pionnier engagé dans la communauté, implémentant un client Iceberg C++ complet à partir de zéro (quelque chose qui n'est pas disponible en open source). Ce client prend en charge la spécification complète des tables Iceberg V2, toutes les règles d'évolution de schéma et les transformations de partition. Du côté du catalogue Iceberg, Redpanda expédie un catalogue basé sur des fichiers et parle REST Iceberg pour les opérations comme la création, la validation, la mise à jour et la suppression dans des catalogues distants comme Unity Catalog, et prend en charge l'authentification OIDC, gérant vos identifiants Unity Catalog judicieusement comme un secret chiffré de manière transparente dans le gestionnaire de secrets de votre fournisseur de cloud. Redpanda a également travaillé en étroite collaboration avec Databricks et d'autres leaders d'Iceberg pour explorer comment la spécification peut être étendue pour prendre en charge les données de flux semi-structurées via le type Variant, et pour rendre la gestion des RBAC de table plus transparente en synchronisant les politiques entre les deux plateformes. Cette standardisation et cette implémentation toujours conforme aux spécifications signifient également un verrouillage minimal du fournisseur. Les organisations sont toujours libres de remplacer n'importe quelle pièce du système si elles trouvent une meilleure option : la plateforme de streaming, le catalogue Iceberg ou le lakehouse interrogeant/traitant les tables.
Si vous êtes arrivé jusqu'ici, nous espérons sincèrement que vous avez eu un aperçu de la rigueur réfléchie de l'approche de Redpanda face à cette opportunité de marché brûlante, qui découle d'une solide culture d'ingénierie et d'une passion pour la construction de produits solides comme le roc. En tant que technologues dans l'âme avec de solides antécédents, et en particulier avec notre concentration sur le facteur de forme BYOC, Redpanda et Databricks sont parfaitement alignés pour fournir deux plateformes de premier ordre qui agissent et se sentent comme une seule, et qui, pour vous, résolvent le problème du flux vers la table.
Essayez les topics Iceberg avec Unity Catalog en utilisant l'offre unique Bring-Your-Own-Cloud de Redpanda dès aujourd'hui. Ou, commencez par un essai gratuit de notre version auto-gérée, Redpanda Enterprise ! : https://cloud.redpanda.com/try-enterprise.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.