Announcing full Apache Iceberg™ support in Databricks
Read and write Managed Iceberg tables and use Unity Catalog to access and govern Iceberg tables in external catalogs
by Ali Ghodsi, Reynold Xin, Adam Conway, Daniel Weeks, Ryan Blue and Jason Reid
- Write open Managed Iceberg Tables using Databricks or external Apache Iceberg™ engines via Unity Catalog’s Iceberg REST Catalog API.
- Access and govern Iceberg tables managed by foreign catalogs.
- These additions advance the industry further toward a single, unified open table format.
We are excited to announce the Public Preview for Apache IcebergTM support in Databricks, unlocking the full Apache Iceberg and Delta Lake ecosystems with Unity Catalog. This Preview introduces two new features to Unity Catalog. First, you can now read and write Managed Iceberg tables using Databricks or external Iceberg engines via Unity Catalog’s Iceberg REST Catalog API. Powered by Predictive Optimization, these tables automatically run advanced table operations, including Liquid Clustering, to deliver out-of-box, fast query performance and storage efficiency. Managed Iceberg tables are also integrated with advanced features across the Databricks platform, including DBSQL, Databricks, Delta Sharing, and MVs. Second, as part of Lakehouse Federation, Unity Catalog now enables you to seamlessly access and govern Iceberg tables managed by foreign catalogs such as AWS Glue, Hive Metastores, and Snowflake Horizon Catalog.
With these new features, you can connect to Unity Catalog from any engine and access all your data, across catalogs and regardless of format, breaking data silos and resolving ecosystem incompatibilities. In this blog, we will cover:
- Identifying new data silos
- Using Unity Catalog as a fully open Iceberg catalog
- Extending UC governance to the entire Lakehouse
- Our vision for the future of open table formats
The new data silos
New data silos have emerged along two foundational components of the Lakehouse: open table formats and data catalogs. Open table formats enable ACID transactions on data stored in object storage. Delta Lake and Apache Iceberg, the two leading open table formats, developed connector ecosystems across a wide range of open source frameworks and commercial platforms. However, most popular platforms only adopted one of the two standards, forcing customers to choose engines when choosing a format.
Catalogs introduce additional challenges. A core responsibility of a catalog is managing a table’s current metadata files across writers and readers. However, some catalogs restrict what engines are allowed to write them. Even if you manage to store all your data in a format supported by all your engines, you may still not be able to use your chosen engine because it cannot connect to your catalog. This vendor lock-in forces customers to fragment data discovery and governance across disparate catalogs.
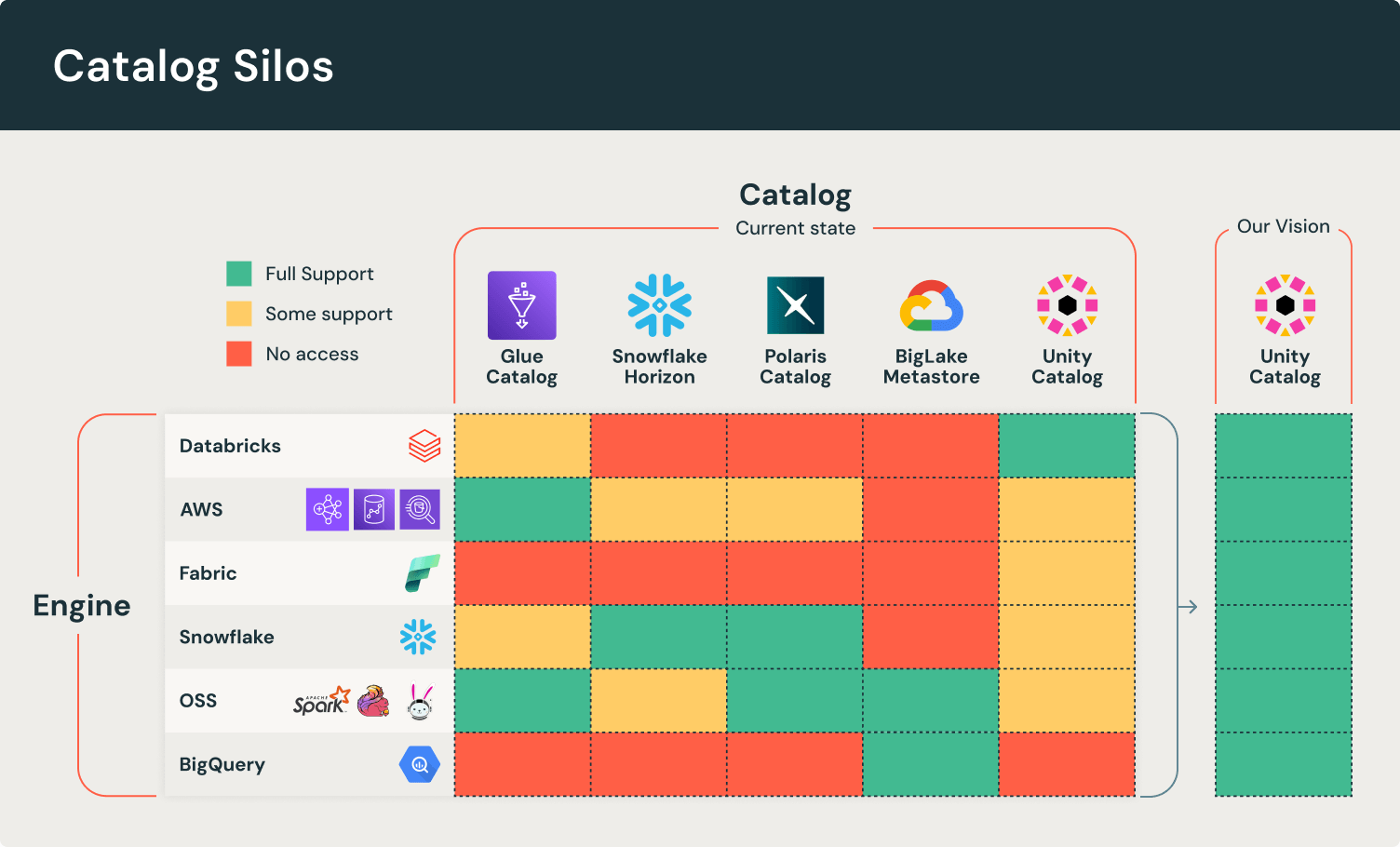
Over the next two sections, we will cover how Unity Catalog uses open standards and catalog federation to resolve format and catalog incompatibilities.
A Fully Open Iceberg Catalog
Unity Catalog breaks format silos through open standards. Now in Public Preview, you can use Databricks and external engines to write Iceberg tables managed by Unity Catalog. Managed Iceberg tables are fully open to the entire Iceberg ecosystem via Unity Catalog’s implementation of the Iceberg REST Catalog APIs. The REST Catalog is an open API specification that provides a standard interface for interacting with Iceberg tables. Unity Catalog was an early adopter of the REST Catalog, first launching support in 2023. This Preview builds on that foundation. Now, virtually any Iceberg client compatible with the REST spec, such as Apache Spark™, Apache Flink, or Trino can read and write to Unity Catalog.
We plan to store all our data in an open format and want a single catalog that can connect to all the tools we use. Unity Catalog allows us to write Iceberg tables that are fully open to any Iceberg client, unlocking the entire Lakehouse ecosystem and future proofing our architecture. —Hen Ben-Hemo, Data Platform Architect

With Managed Iceberg, you can bring Unity Catalog governance to the Iceberg ecosystem even amongst OSS tools like PyIceberg that do not natively support authorization. Unity Catalog allows you to create data pipelines that span the full Lakehouse ecosystem. For example, Apache Iceberg offers a popular sink connector for writing from Kafka to Iceberg tables. You can use Kafka Connect to write Iceberg tables to Unity Catalog and downstream use Databricks’s best-in-class price-performance for ETL, data warehousing, and machine learning capabilities.
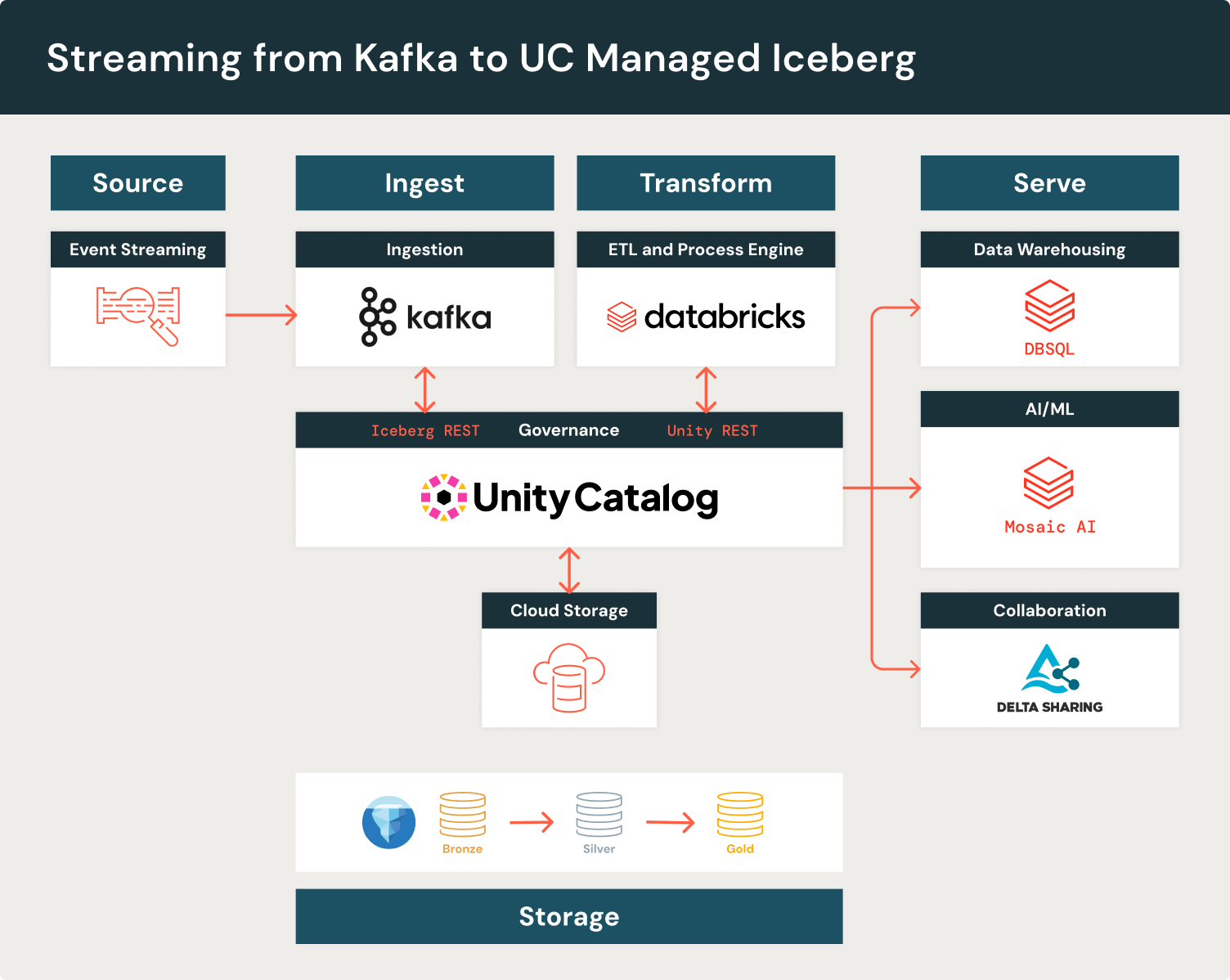
All Managed Tables automatically deliver best-in-class read performance and storage optimization using Predictive Optimization. Predictive Optimization automatically expires old snapshots, deletes unreferenced files, and incrementally clusters your data using Liquid Clustering. In our example using Kafka, this prevents performance degradation commonly caused by the proliferation of small files. You can keep your Iceberg tables healthy and performant without the hassle of manually managing your own table maintenance.
Managed Iceberg tables are integrated with the Databricks platform, allowing you to leverage these tables with advanced platform features such as DBSQL, Databricks, Delta Sharing, and MVs. Beyond Databricks, Unity Catalog supports a partner ecosystem to securely land data in Iceberg using external tools. For example, Redpanda ingests streaming data produced to Kafka topics through Unity catalog’s Iceberg REST Catalog API:
With Unity Catalog Managed Iceberg Tables and the Iceberg REST Catalog, Redpanda can now stream the largest, most demanding Kafka workloads directly into Iceberg tables that are optimized by Unity Catalog, unlocking out-of-box discoverability and fast query performance on arbitrary streams. With push-button configuration, all real-time streaming data is now fully available to the Iceberg ecosystem, so customers can have confidence that their architecture is built to last, no matter how their stack evolves. —Matthew Schumpert, Head of Product, Platform

We're excited to have the following launch partners on board: Atlan, Buf, CelerData, Clickhouse, dbt Labs, dltHub, Fivetran, Informatica, PuppyGraph, Redpanda, RisingWave, StreamNative, and more.
The Lakehouse Catalog
With Unity Catalog, you can interoperate not only across table formats, but also across catalogs. Now also in Public Preview, you can seamlessly query and govern Iceberg tables managed by external catalogs such as AWS Glue, Hive Metastores, and Snowflake Horizon Catalog. Extending Hive Metastore and AWS Glue Federation, these connectors allow you to mount entire catalogs within Unity Catalog, creating a unified interface for data discovery and governance.

Federation provides a seamless integration to leverage Unity Catalog’s advanced features on Iceberg tables managed by foreign catalogs. You can use Databricks’ fine-grained access controls, lineage, and auditing on all your data, across catalogs and regardless of format.
Unity Catalog allows Rippling ML engineers and Data Scientists to seamlessly access Iceberg tables in existing OLAP warehouses with zero copy. This helps us lower costs, create consistent sources of truth, and reduce latency of data refresh -- all while maintaining high standards on data access and privacy across the entire data lifecycle. —Albert Strasheim, Chief Technology Officer

With federation, Unity Catalog can govern the entirety of your Lakehouse – across all your tables, AI models, files, notebooks, and dashboards.
The Future of Table Formats
Unity Catalog is pushing the industry closer to realizing the simplicity, flexibility, and lower costs of the open data lakehouse. At Databricks, we believe that we can advance the industry even further - with a single, unified open table format. Delta Lake and Apache Iceberg share much of the same design, but subtle differences cause large incompatibilities for customers. To resolve these shared problems, the Delta and Apache Iceberg communities are aligning concepts and contributions, unifying the Lakehouse ecosystem.
Iceberg v3 is a major step toward this vision. Iceberg v3 includes key features like Deletion Vectors, Variant data type, Row IDs, and geospatial data types that share identical implementations in Delta Lake. These improvements enable you to move data and delete files between formats easily, without rewriting petabytes of data.
In future Delta Lake and Apache Iceberg releases, we want to build on this foundation so that Delta and Iceberg clients can use the same metadata and thus, can share tables directly. With these investments, customers can realize the original goal of an open data lakehouse – a fully integrated platform for data and AI on a single copy of data.
Managed and Foreign Iceberg tables are now available in Public Preview. Check out our documentation to get started! Replay our announcements at Data and AI Summit on June 9-12, 2025 to learn more about our newest Iceberg features and the future of open table formats.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.