Intégration des données SAP et Salesforce pour l'analytique des fournisseurs sur Databricks
Utilisez SAP Business Data Cloud Connect et Lakeflow Connect pour unifier les données CRM et ERP pour l'analytique des fournisseurs.
- Connectez les données SAP S/4HANA et Salesforce directement dans Databricks
- Utilisez Lakeflow Connect et SAP BDC pour un accès incrémentiel sans copie
- Créez une couche Gold gouvernée pour l'analytique et les insights conversationnels
Comment créer de l'analytique sur les fournisseurs avec l'intégration de Salesforce et SAP sur Databricks
Les données fournisseurs concernent presque tous les services d'une organisation, de l'approvisionnement et de la gestion de la chaîne d'approvisionnement à la finance et à l'analytique. Pourtant, elles sont souvent réparties entre des systèmes qui ne communiquent pas entre eux. Par exemple, Salesforce contient les profils des fournisseurs, les contacts et les détails des comptes, et SAP S/4HANA gère les factures, les paiements et les écritures du grand livre. Comme ces systèmes fonctionnent indépendamment, les équipes n'ont pas de vue d'ensemble des relations avec les fournisseurs. Il en résulte un rapprochement lent, des enregistrements en double et des opportunités manquées pour optimiser les dépenses.
Databricks résout ce problème en connectant les deux systèmes sur une seule plateforme de données et d'IA gouvernée. En utilisant Lakeflow Connect for Salesforce pour l'ingestion de données et SAP Business Data Cloud (BDC) Connect, les équipes peuvent unifier les données CRM et ERP sans duplication. Le résultat est une vue unique et fiable des fournisseurs, des paiements et des métriques de performance qui prend en charge les cas d'usage des achats et de la finance, ainsi que l'analytique.
Dans ce tutoriel, vous apprendrez à connecter les deux sources de données, à créer un pipeline de données mixtes et à créer une couche Gold qui alimente les analyses et les insights conversationnels via les tableaux de bord d'IA/BI et Genie.
Pourquoi l'intégration de données SAP Salesforce zéro copie fonctionne
La plupart des entreprises tentent de connecter SAP et Salesforce via des outils ETL traditionnels ou des outils tiers. Ces méthodes créent plusieurs copies de données, introduisent de la latence et rendent la gouvernance difficile. Databricks adopte une approche différente.
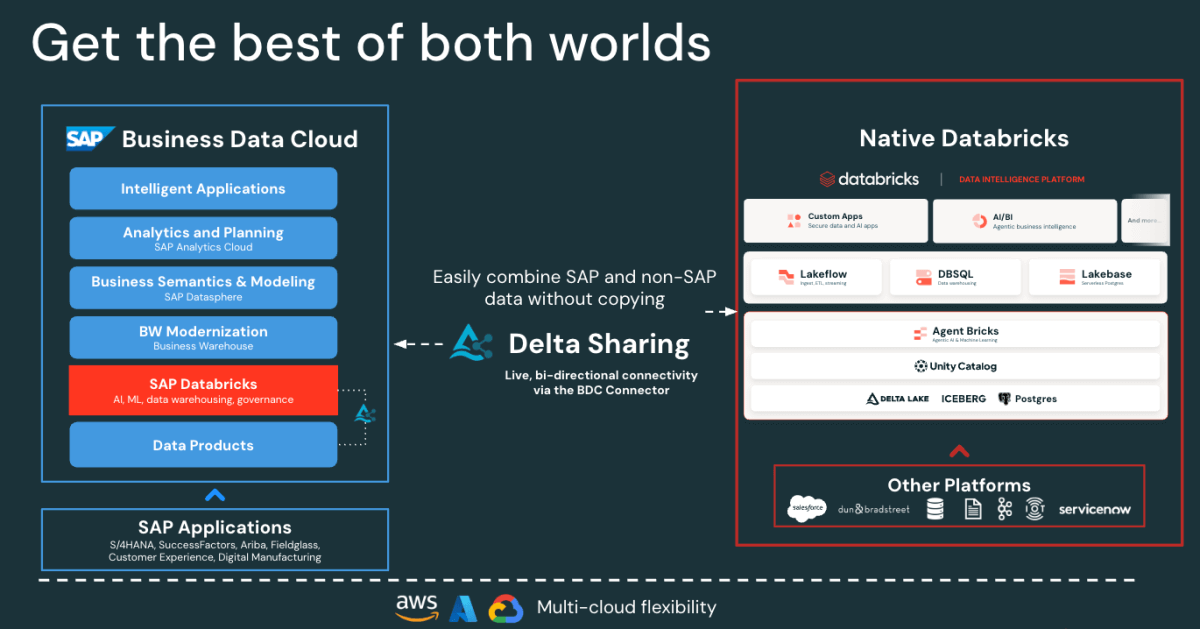
Accès SAP sans copie : Le connecteur SAP BDC pour Databricks vous donne un accès gouverné et en temps réel aux produits de données SAP S/4HANA via Delta Sharing. Aucune exportation ni duplication.
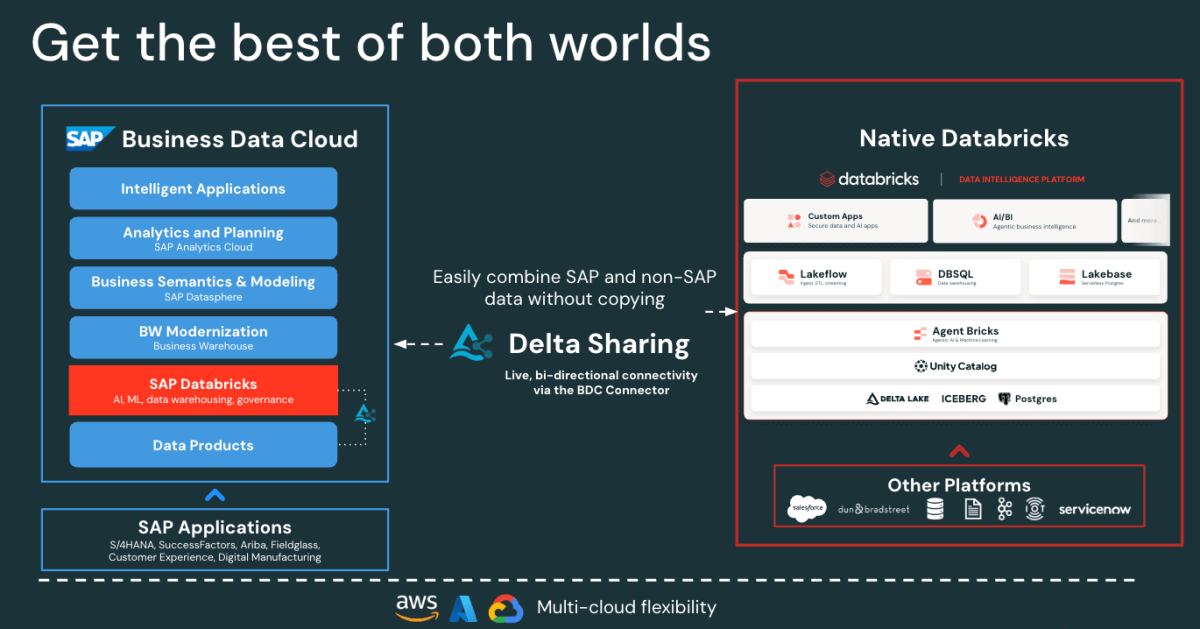
Figure: SAP BDC Connector to Native Databricks(Bi-directional) - Ingestion incrémentielle rapide des données Salesforce : Lakeflow connecte et ingère les données Salesforce en continu, afin de maintenir vos jeux de données à jour et cohérents.
- Gouvernance unifiée : Unity Catalog applique les autorisations, le lignage et l'audit sur les sources SAP et Salesforce.
- Pipelines déclaratifs : Lakeflow Spark Declarative Pipelines simplifient la conception et l'orchestration ETL avec des optimisations automatiques pour de meilleures performances.
{kind=link}
Ensemble, ces fonctionnalités permettent aux data engineers de mixer les données SAP et Salesforce sur une seule et même plateforme, ce qui réduit la complexité tout en maintenant une gouvernance de niveau entreprise.
Architecture d'intégration des données SAP et Salesforce sur Databricks
Avant de construire le pipeline, il est utile de comprendre comment ces composants s'articulent dans Databricks.
Globalement, SAP S/4HANA publie des données métier en tant que produits de données organisés, prêts à l'emploi et gérés par SAP dans SAP Business Data Cloud (BDC). SAP BDC Connect for Databricks permet un accès sécurisé et sans copie à ces produits de données à l'aide de Delta Sharing. Parallèlement, Lakeflow Connect gère l'ingestion des données Salesforce, en capturant les données sur les comptes, les contacts et les opportunités via des pipelines incrémentiels.
Toutes les données entrantes, qu'elles proviennent de SAP ou de Salesforce, sont régies dans Unity Catalog pour la gouvernance, le lignage et les autorisations. Les data engineers utilisent ensuite les pipelines déclaratifs Lakeflow pour joindre et transformer ces jeux de données en une architecture medallion (niveaux bronze, silver et gold). Enfin, la couche Gold sert de base pour l'analytique et l'exploration dans les tableaux de bord d'AI/BI et Genie.
Cette architecture garantit que les données des deux systèmes restent synchronisées, régies et prêtes pour l'analytique et l'IA, sans la surcharge de la réplication ou des outils ETL externes.
Comment créer une analytique unifiée sur les fournisseurs
Les étapes suivantes décrivent comment connecter, combiner et analyser les données SAP et Salesforce sur Databricks.
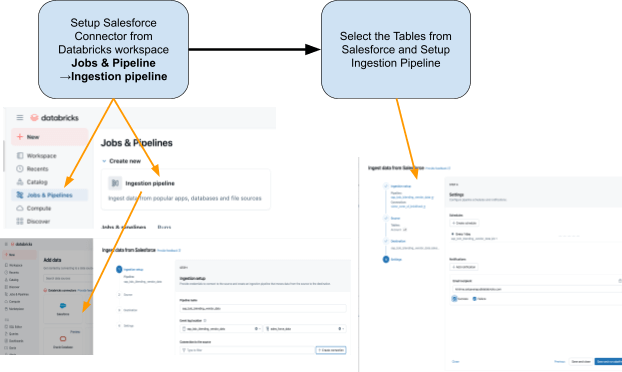
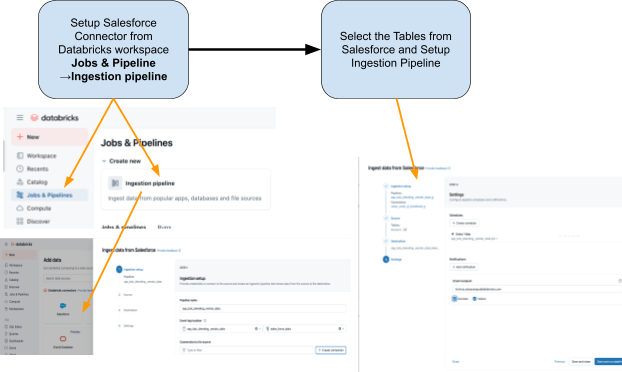
Étape 1 : Ingestion des données Salesforce avec Lakeflow Connect
Utilisez Lakeflow Connect pour importer les données Salesforce dans Databricks. Vous pouvez configurer les pipelines via l'interface utilisateur ou l'API. Ces pipelines gèrent automatiquement les mises à jour incrémentielles, garantissant que les données restent à jour sans refresh manuel.
{kind=link}
Le connecteur est entièrement intégré à la gouvernance Unity Catalog, aux pipelines déclaratifs Spark de Lakeflow pour l'ETL et aux tâches Lakeflow pour l'orchestration.
Voici les tables que nous prévoyons d'ingérer depuis Salesforce :
- Compte: Détails du vendeur/fournisseur (les champs incluent : AccountId, Name, Industry, Type, BillingAddress)
- Contact: Contacts fournisseurs (les champs incluent : ContactId, AccountId, FirstName, LastName, e-mail)
Étape 2 : Accéder aux données SAP S/4HANA avec le connecteur SAP BDC
SAP BDC Connect fournit un accès en direct et gouverné aux données de paiement des fournisseurs de SAP S/4HANA directement sur Databricks, en éliminant l'ETL traditionnel, en tirant parti du produit de données SAP BDC sap_bdc_working_capital.entryviewjournalentry.operationalacctgdocitem, la vue des postes du Journal Universel.
Ce produit de données BDC correspond directement à la vue CDS de SAP S/4HANA I_JournalEntryItem (Poste de document comptable opérationnel) sur ACDOCA.
Pour le contexte ECC, les structures physiques les plus proches étaient BSEG (postes individuels FI) avec des en-têtes dans BKPF, des écritures CO dans COEP, et des index ouverts/compensés BSIK/BSAK (fournisseurs) et BSID/BSAD (clients). Dans SAP S/4HANA, ces objets BS** font partie du modèle de données simplifié, où les postes individuels fournisseurs et de grand livre sont centralisés dans le journal universel (ACDOCA), remplaçant l'approche ECC qui nécessitait souvent de joindre plusieurs tables financières distinctes.
Voici les étapes à effectuer dans le cockpit SAP BDC.
1 : Connectez-vous au cockpit SAP BDC et consultez la formation SAP BDC dans le System Landscape. Connectez-vous à Databricks natif via le connecteur delta sharing de SAP BDC. Pour plus d'informations sur la façon de connecter Databricks natif au SAP BDC afin qu'il fasse partie de sa formation.
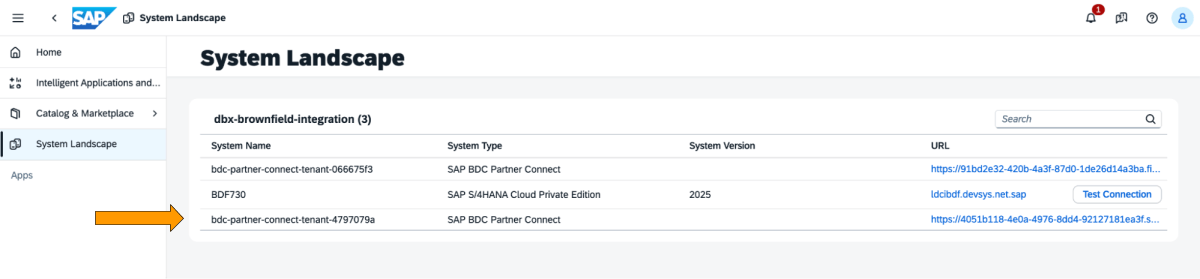
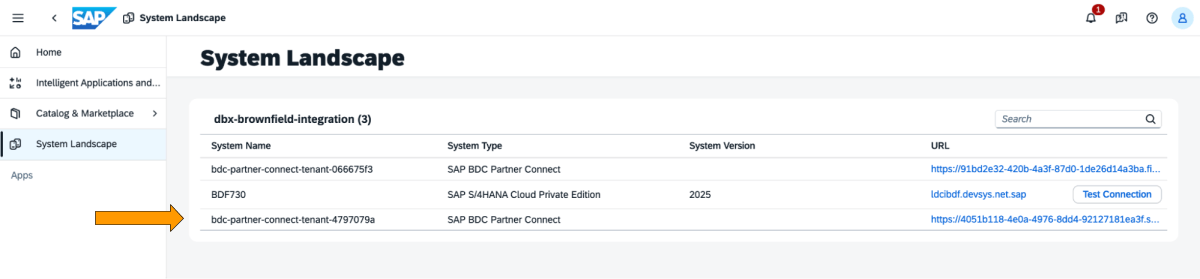{kind=link}
2 : Allez dans le Catalogue et recherchez « Data produit Entry View Journal Entry », comme indiqué ci-dessous.
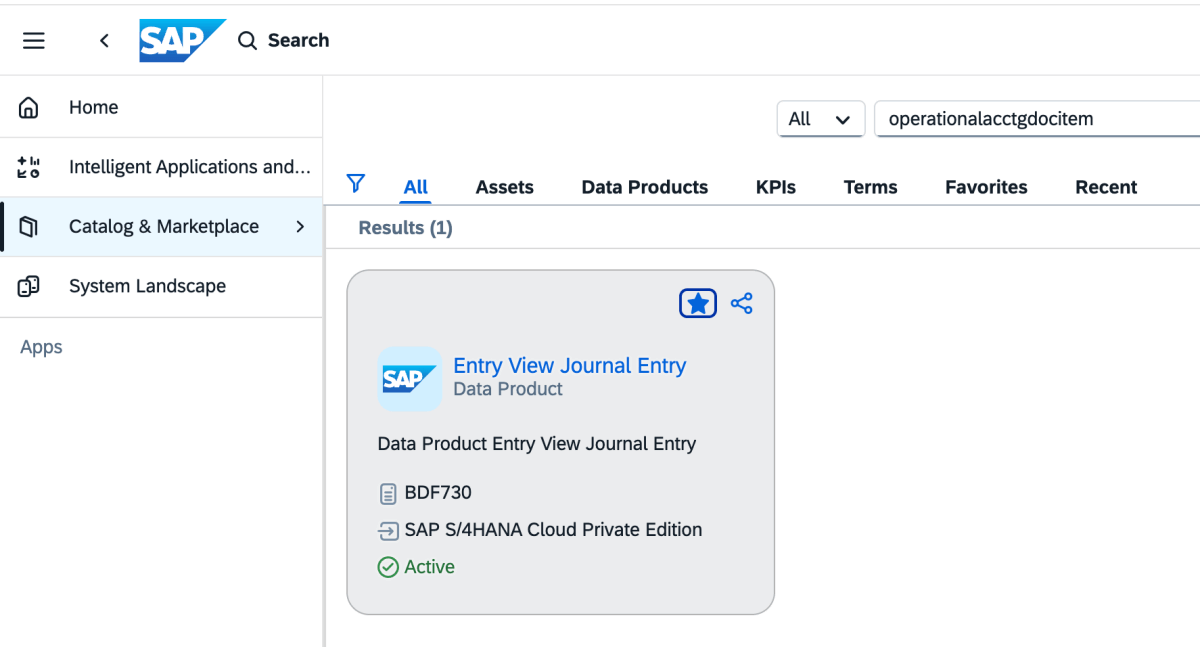
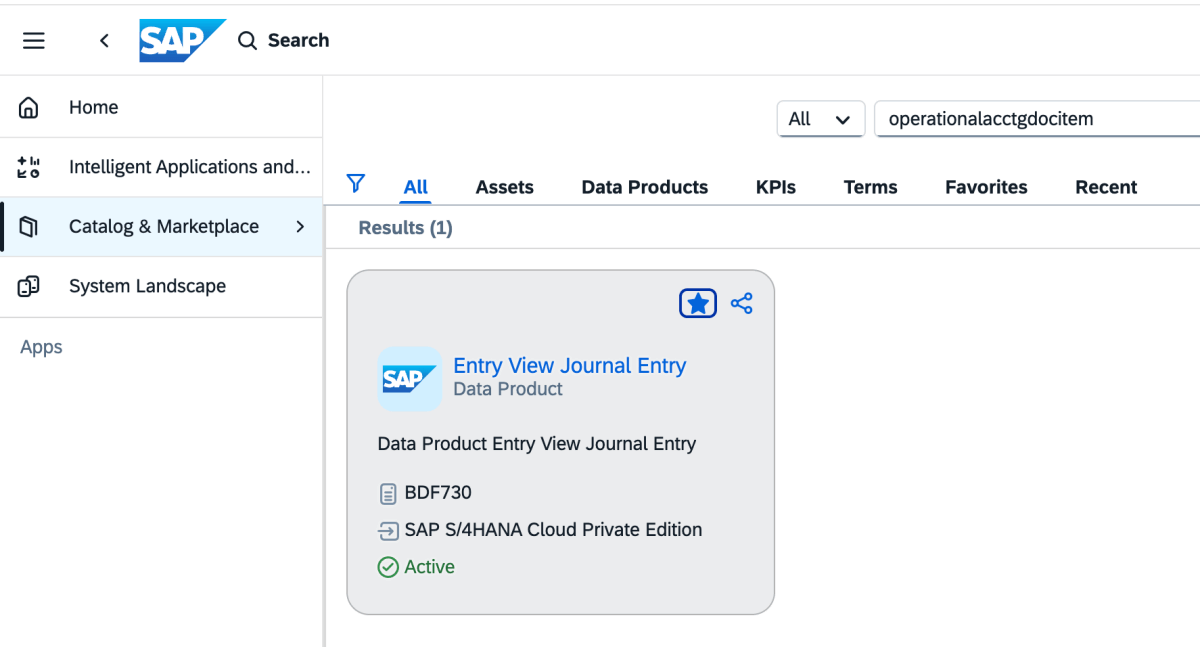{kind=link}
3 : Sur le produit de données, sélectionnez Partager, puis sélectionnez le système cible, comme illustré dans l'image ci-dessous.
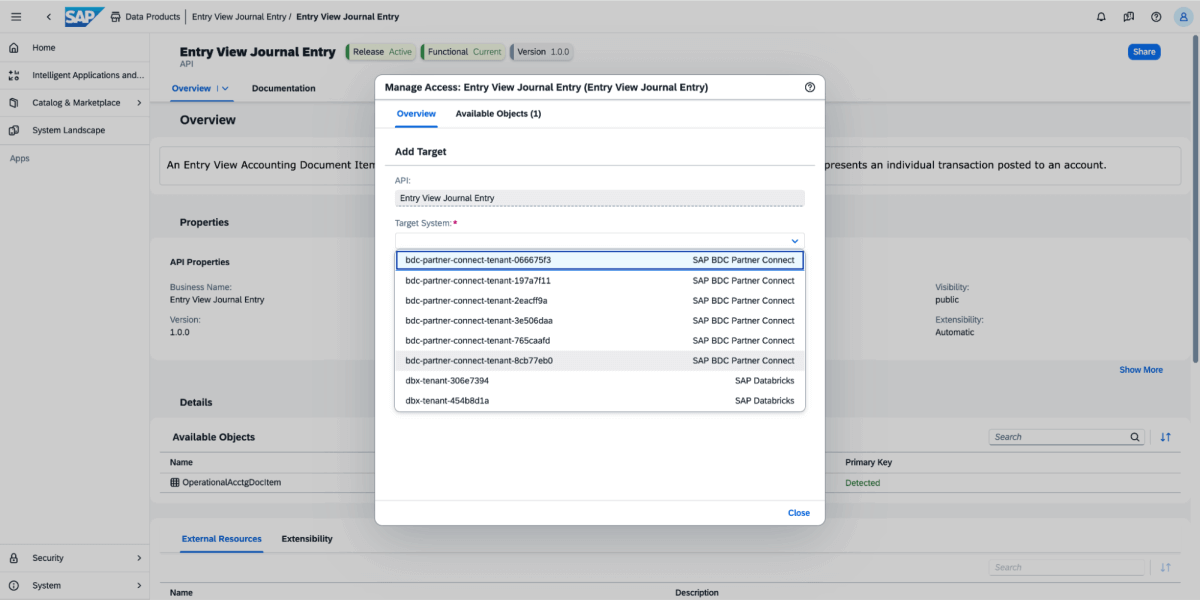
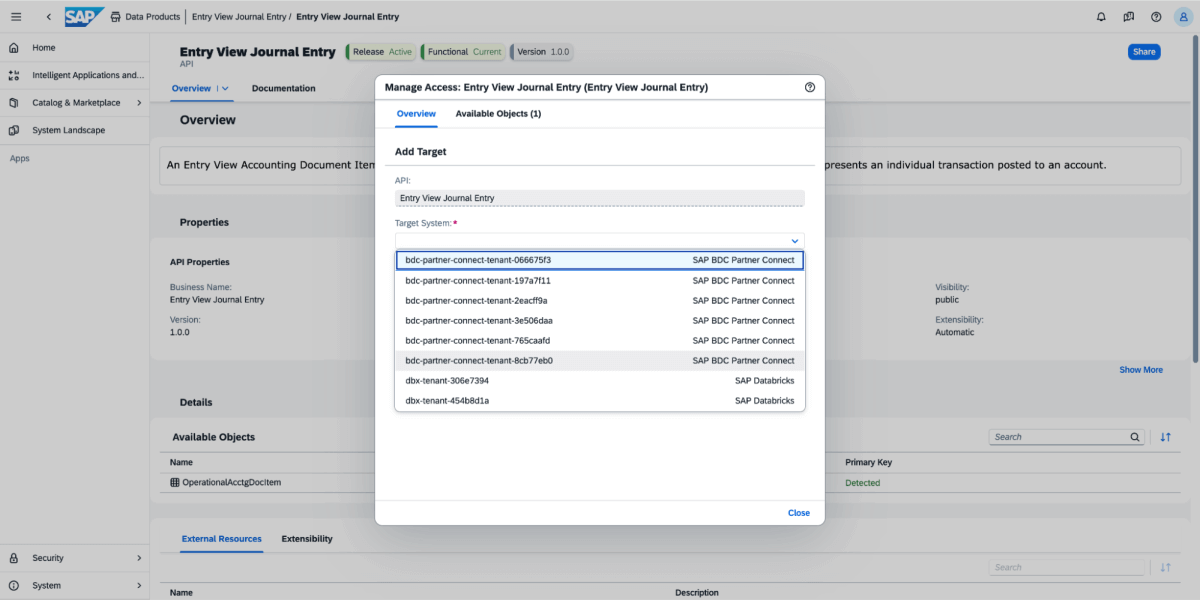{kind=link}
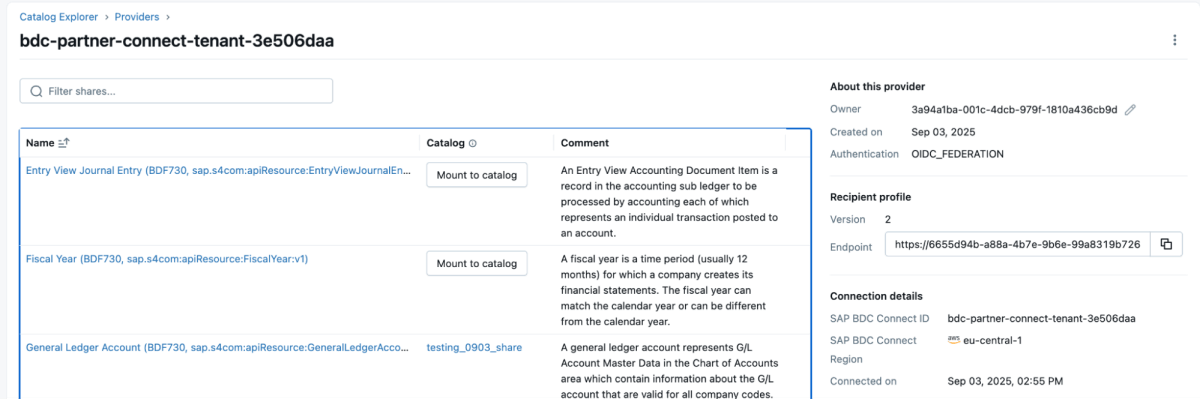
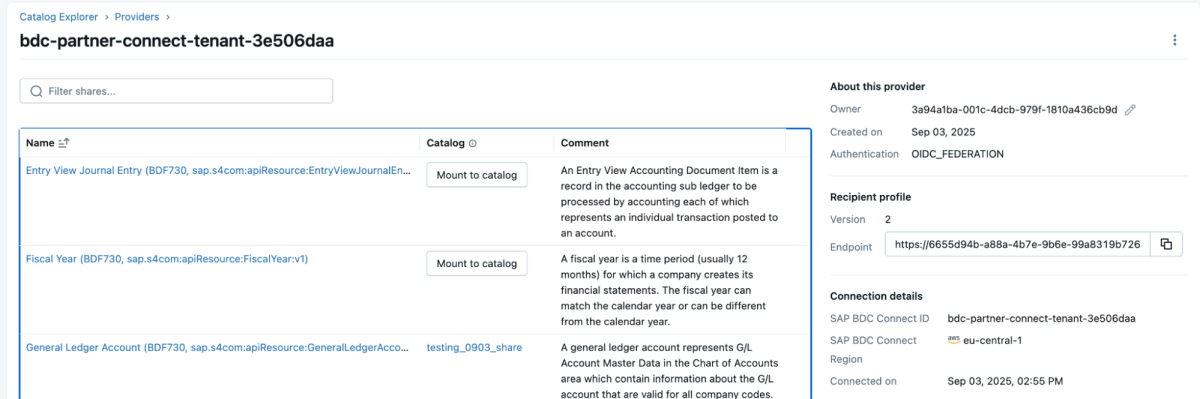
4 : Une fois le produit de données partagé, il apparaîtra comme un partage delta (delta share) dans l'espace de travail Databricks, comme indiqué ci-dessous. Assurez-vous d'avoir l'accès « Use Provider » pour voir ces fournisseurs.
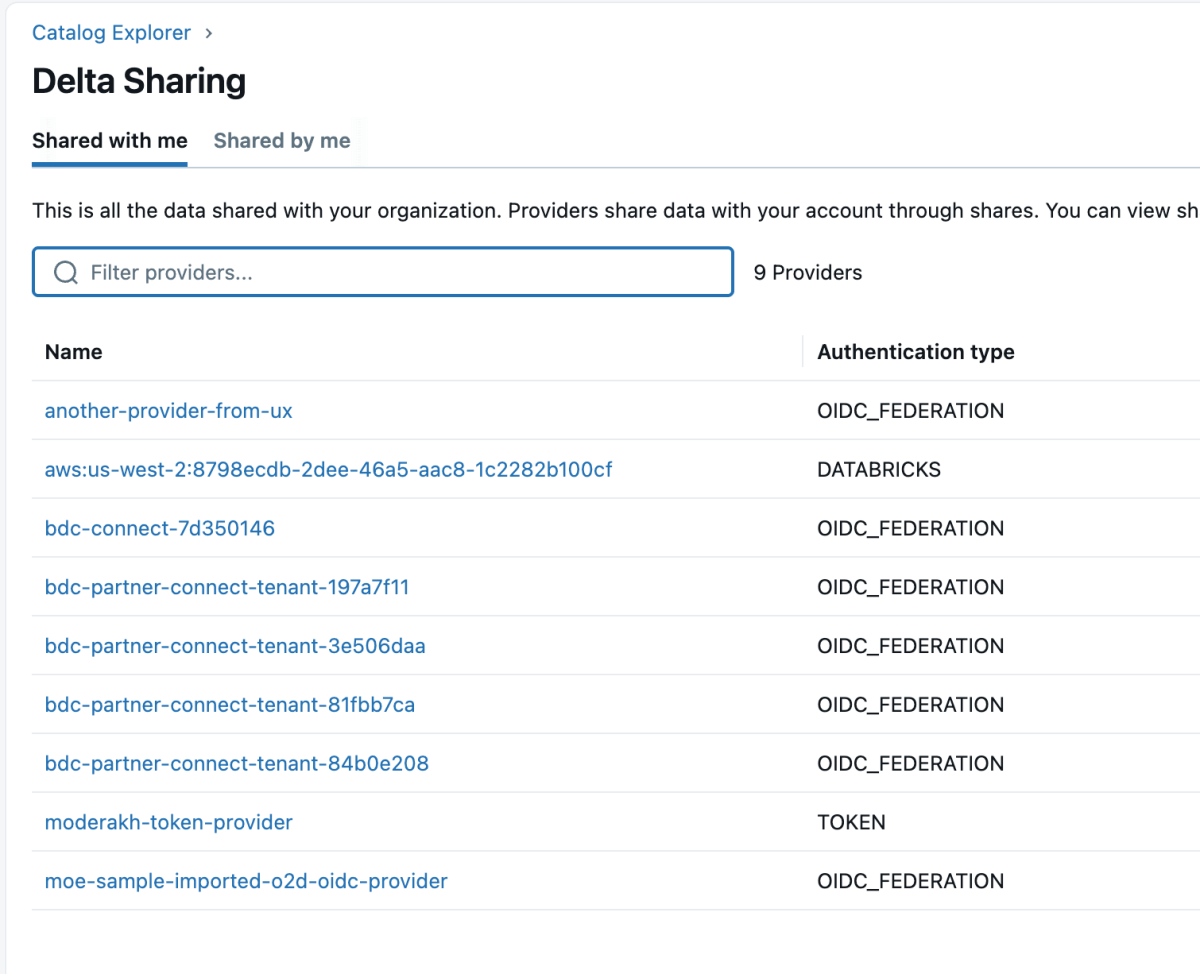
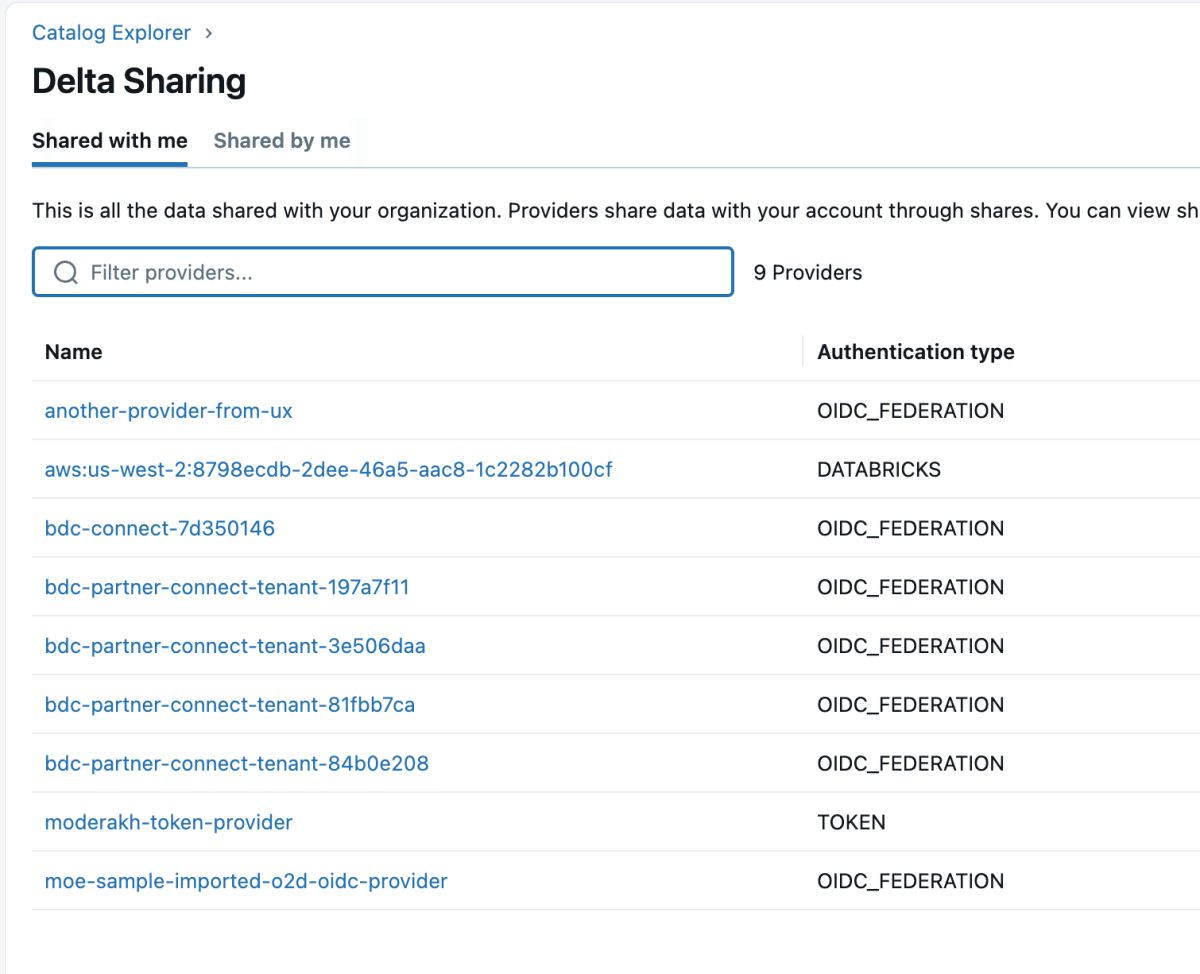{kind=link}
{kind=link}
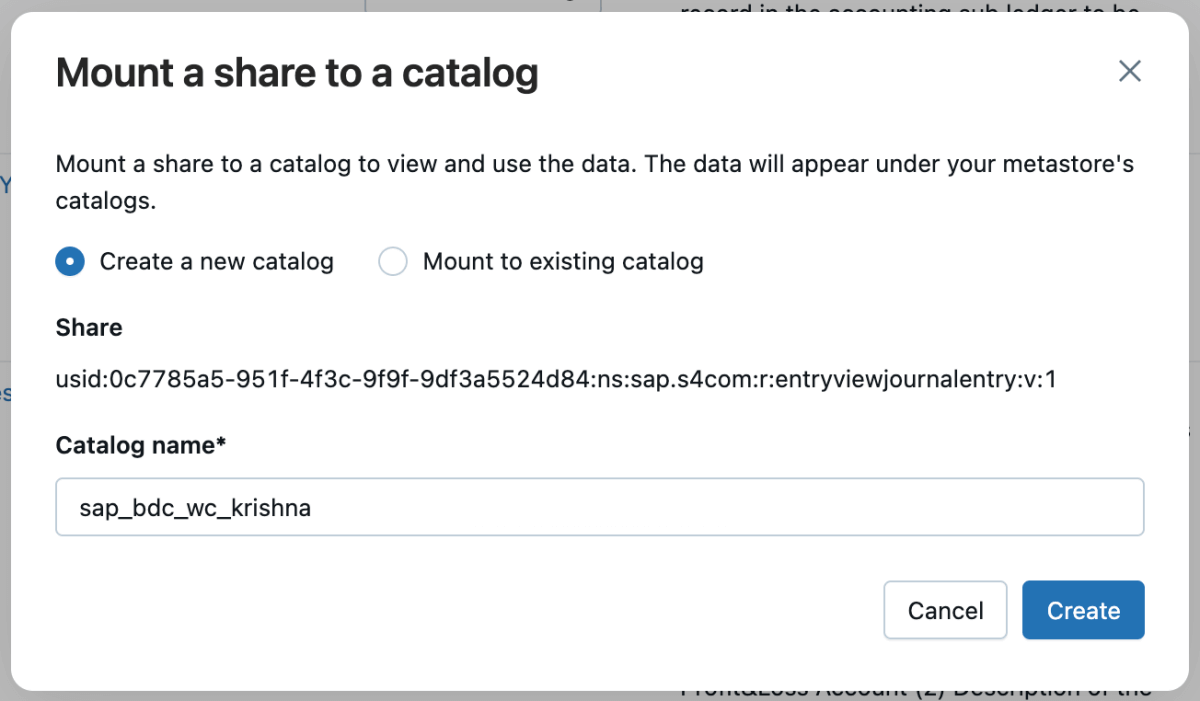
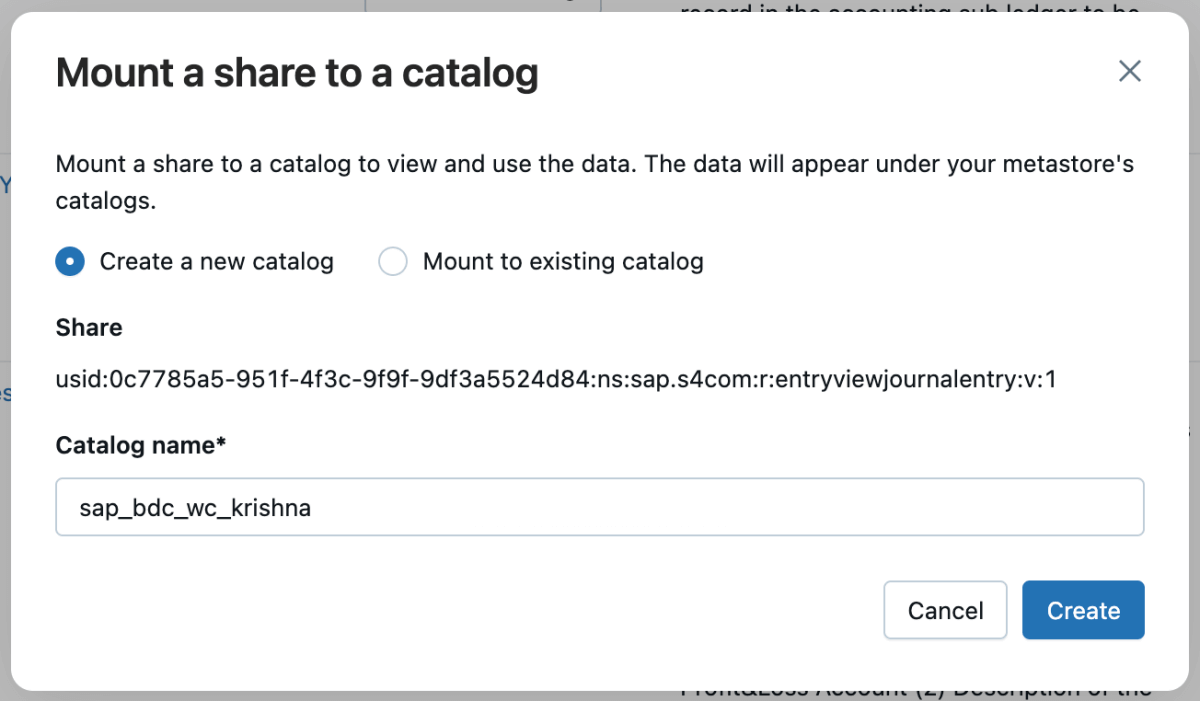
5 : Vous pouvez ensuite monter ce partage dans le catalogue et créer un nouveau catalogue ou le monter dans un catalogue existant.
{kind=link}
6 : Une fois le partage monté, il apparaîtra dans le catalogue.
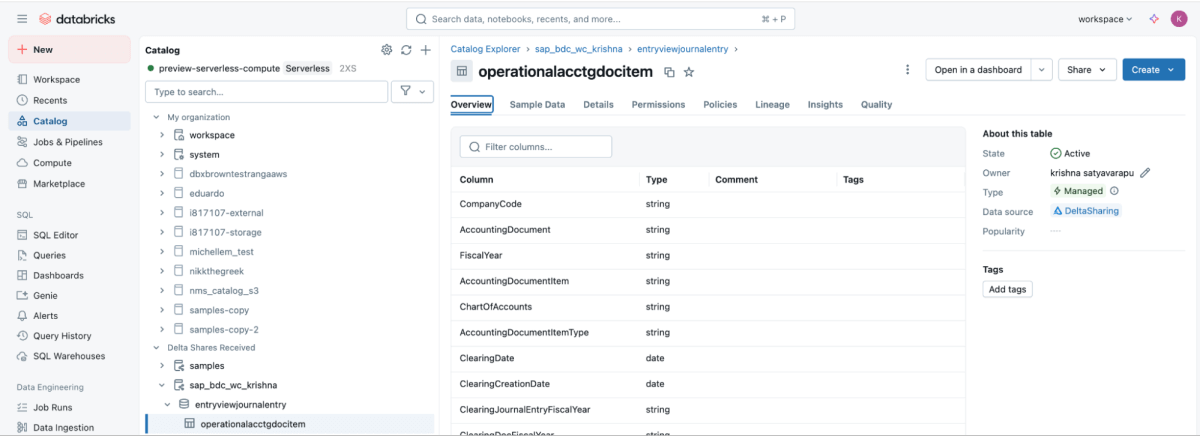
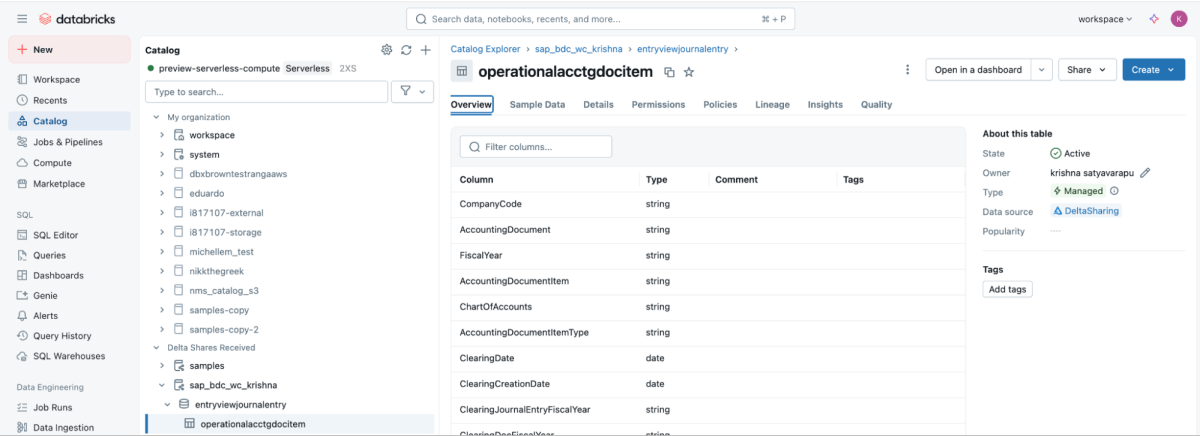{kind=link}
Étape 3 : Fusion du pipeline ETL dans Databricks à l'aide des pipelines déclaratifs Lakeflow
Une fois les deux sources disponibles, utilisez Lakeflow Declarative Pipelines pour créer un pipeline ETL avec les données Salesforce et SAP.
La table Account de Salesforce inclut généralement le champ SAP_ExternalVendorId__c, qui correspond à l'ID de fournisseur dans SAP. Cela devient la clé de jointure principale pour votre niveau silver.
Les Lakeflow Spark Declarative Pipelines vous permettent de définir la logique de transformation en SQL, tandis que Databricks gère automatiquement l'optimisation et orchestre les pipelines.
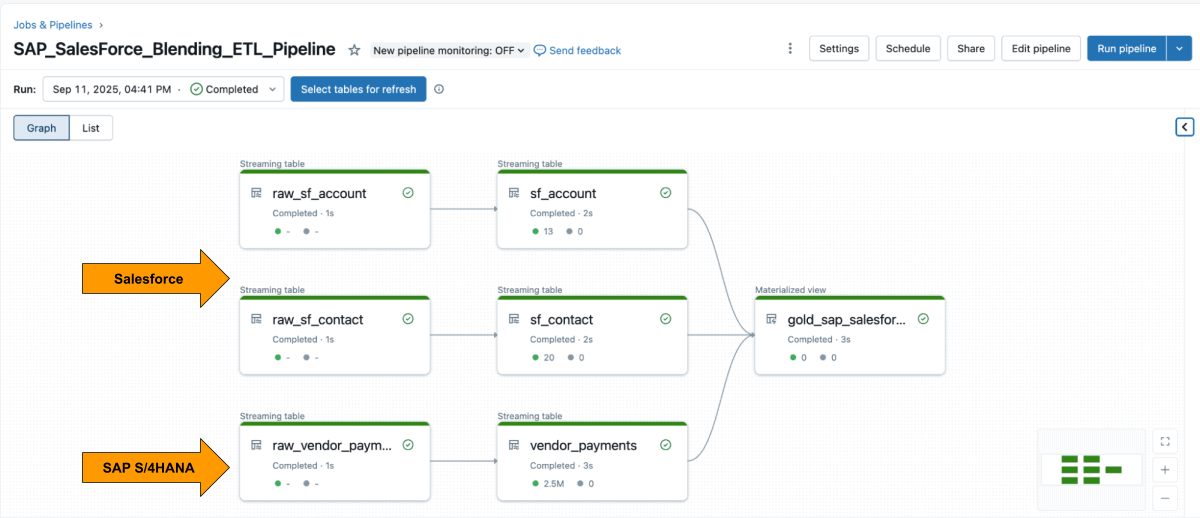
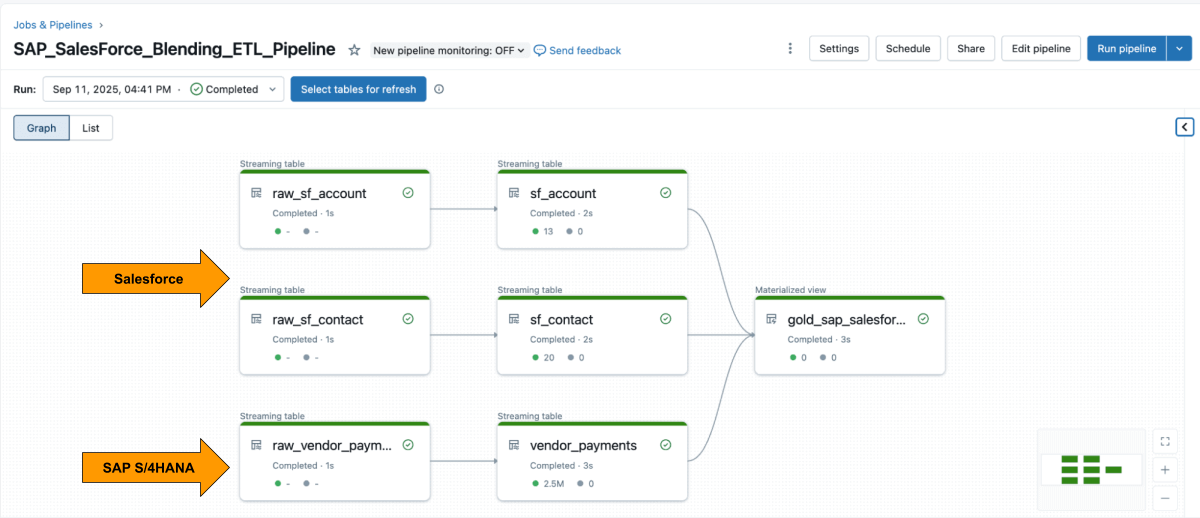{kind=link}
Exemple : Créer des tables de niveau métier organisées
Cette query crée une vue matérialisée organisée de niveau métier qui unifie les enregistrements de paiement des fournisseurs de SAP avec les informations détaillées sur les fournisseurs de Salesforce, prête pour l'analytique et le reporting.
Étape 4 : Analyser avec les tableaux de bord d'IA/BI et Genie
Une fois la vue matérialisée créée, vous pouvez l'explorer directement dans les tableaux de bord d'AI/BI, qui permettent aux équipes de visualiser les paiements des fournisseurs, les soldes impayés et les dépenses par région. Ils prennent en charge le filtrage dynamique, la recherche et la collaboration, le tout gouverné par Unity Catalog. Genie permet l'exploration en langage naturel des mêmes données.
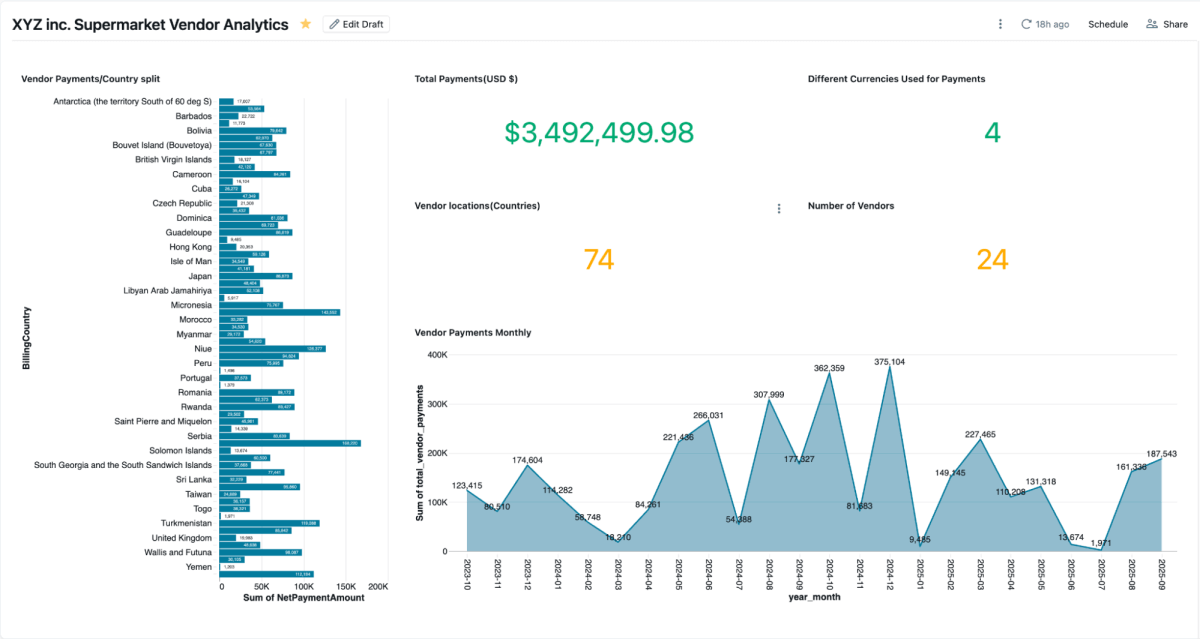
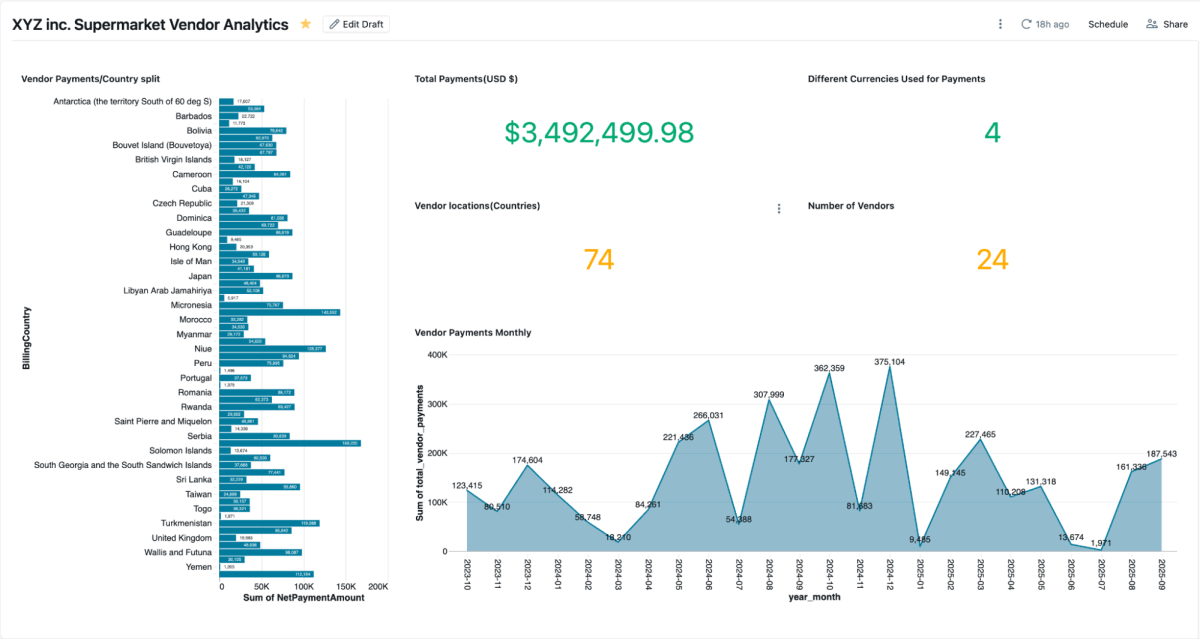{kind=link}
Vous pouvez créer des espaces Genie sur ces données mixtes et poser des questions, ce qui ne pourrait pas être fait si les données étaient cloisonnées dans Salesforce et SAP.
- « Quels sont mes 3 principaux fournisseurs que je paie le plus, et je souhaite également obtenir leurs coordonnées ? »
- « Quelles sont les adresses de facturation des 3 principaux fournisseurs ? »
- « Lesquels de mes 5 principaux fournisseurs ne viennent pas des États-Unis ? »

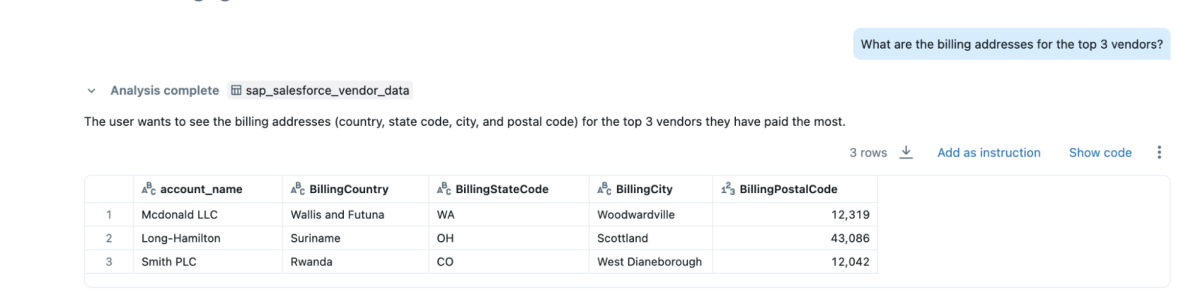
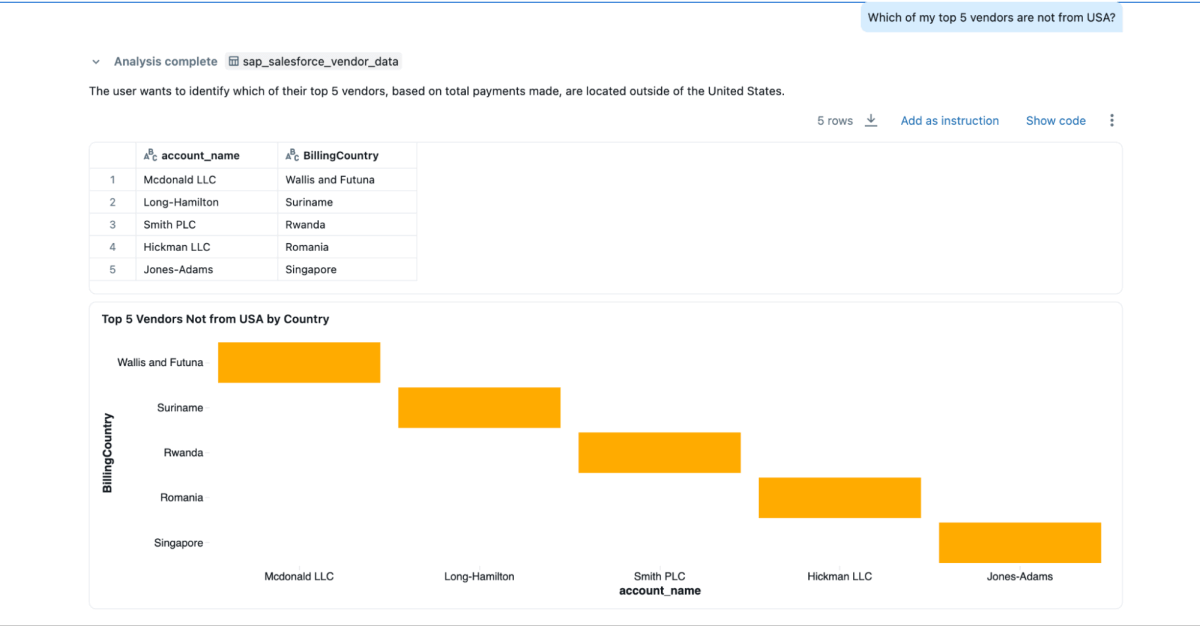
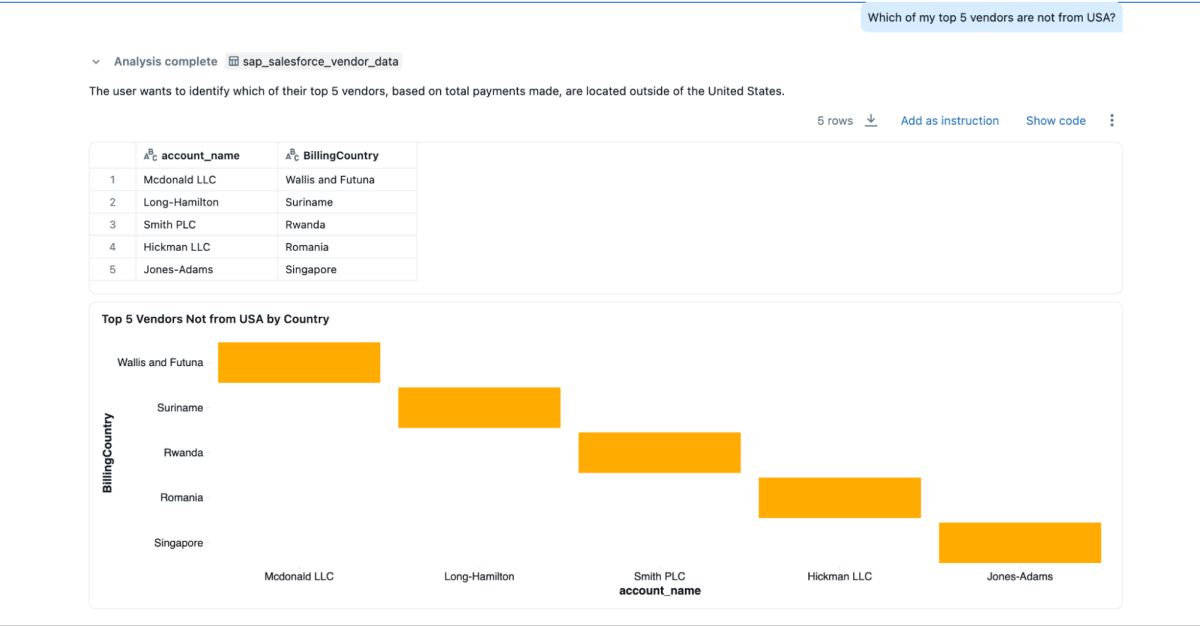{kind=link}
Résultats métier
En combinant les données SAP et Salesforce sur Databricks, les organisations obtiennent une vue complète et fiable des performances des fournisseurs, des paiements et des relations. Cette approche unifiée offre des avantages à la fois opérationnels et stratégiques :
- Résolution plus rapide des litiges : les équipes peuvent consulter les détails des paiements et les coordonnées des fournisseurs côte à côte, ce qui facilite l'examen des problèmes et leur résolution rapide.
- Économies sur les paiements anticipés : Avec les conditions de paiement, les dates de compensation et les montants nets en un seul endroit, les équipes financières peuvent facilement identifier les opportunités de remises pour paiement anticipé.
- Fichier maître des fournisseurs plus propre : La jointure sur le champ
SAP_ExternalVendorId__caide à identifier et à résoudre les enregistrements de fournisseurs en double ou incohérents, maintenant ainsi des données fournisseurs précises et cohérentes à travers les systèmes. - Gouvernance prête pour l'audit : Unity Catalog garantit que toutes les données sont gouvernées avec une traçabilité, des autorisations et un audit cohérents, de sorte que l'analytique, les modèles d'IA et les rapports s'appuient sur la même source fiable.
Ensemble, ces résultats aident les organisations à rationaliser la gestion des fournisseurs et à améliorer l'efficacité financière, tout en maintenant la gouvernance et la sécurité requises pour les systèmes d'entreprise.
Conclusion
L'unification des données fournisseurs entre SAP et Salesforce ne signifie pas nécessairement reconstruire des pipelines ou gérer des systèmes en double.
Avec Databricks, les équipes peuvent travailler à partir d'une base unique et gouvernée qui intègre de manière transparente les données ERP et CRM en temps réel. La combinaison de l'accès sans copie à SAP BDC, de l'ingestion incrémentielle des données Salesforce, de la gouvernance unifiée et des pipelines déclaratifs remplace la surcharge de travail liée à l'intégration par des insights.
Le résultat va au-delà d'un reporting plus rapide. Cela fournit une vue connectée de la performance des fournisseurs qui améliore les décisions d'achat, renforce les relations avec les fournisseurs et génère des économies mesurables. Et comme cette solution repose sur la plateforme Databricks Data Intelligence, les mêmes données SAP qui alimentent les paiements et les factures peuvent également alimenter des dashboards, des modèles d'IA et des analyses conversationnelles, le tout à partir d'une source unique et fiable.
Les données SAP constituent souvent l'épine dorsale des opérations de l'entreprise. En intégrant le SAP Business Data cloud, Delta Sharing et Unity Catalog, les organisations peuvent étendre cette architecture au-delà de l'analytique des fournisseurs, à l'optimisation du fonds de roulement, à la gestion des stocks et à la Prévision de la demande.
Cette approche transforme les données SAP d'un système d'enregistrement en un système d'intelligence, où chaque dataset est en direct, gouverné et prêt à être utilisé dans toute l'entreprise.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.