Chatbot de football auto-optimisant guidé par des experts du domaine sur Databricks
Un guide pratique pour concevoir, déployer et améliorer un assistant agentique aidant les coordinateurs défensifs à anticiper les tendances adverses et à s’optimiser en continu grâce aux retours des experts du domaine.
par Wesley Pasfield et Nick Ragonese
- Objectif : Créer un assistant agentique destiné aux entraîneurs qui répond à des questions comme « Que fera cette attaque ? » en utilisant des outils régis et de qualité production sur les données action par action, de participation et de composition d'équipe.
- Approche : Créer un agent d'appel d'outils avec les fonctions Unity Catalog (analytique SQL sur Delta) et le déployer via l'Agent Framework avec MLflow Tracing. Implémenter une boucle d'auto-optimisation où les retours des SME capturés dans les sessions d'étiquetage MLflow entraînent des juges alignés (align()) qui pilotent l'amélioration automatique des invites (optimize_prompts()), encodant les connaissances expertes du football américain directement dans le système.
- Résultat : Les coordinateurs obtiennent des tendances contextuelles (tentative et distance, formation/joueurs, tactique des deux dernières minutes, taux de passes écran) avec une itération rapide et des contrôles qualité prêts pour les préparations de la semaine de match. Les développeurs obtiennent une architecture réutilisable pour n'importe quel domaine : capturez les retours d'experts, alignez les juges sur ce que « bon » signifie pour votre cas d'utilisation, et laissez le système s'améliorer en continu grâce à l'optimisation des prompts guidée par les juges alignés.
Les juges LLM génériques et les prompts statiques ne parviennent pas à saisir les nuances spécifiques au domaine. Déterminer ce qui rend une analyse défensive de football « bonne » nécessite une connaissance approfondie du football : schémas de couverture, tendances de formation, contexte situationnel. Les évaluateurs généralistes passent à côté de cela. Il en va de même pour l'examen juridique, le triage médical, la due diligence financière ou tout autre domaine où le jugement d'un expert est important.
Cet article présente une architecture pour des agents auto-optimisants basée sur Databricks Agent Framework, où l'expertise humaine spécifique à l'entreprise améliore continuellement la qualité de l'IA à l'aide de MLflow et où les développeurs contrôlent l'ensemble de l'expérience. Dans cet article, nous utiliserons comme exemple fil rouge un assistant pour coordinateur défensif (DC) de football américain : un agent d'appel d'outils capable de répondre à des questions telles que "Qui reçoit le ballon en formation 11 sur une 3e et 6 ?" ou "Que fait l'adversaire dans les 2 dernières minutes des mi-temps ?" L'exemple suivant montre cet agent interagissant avec un utilisateur via les Databricks Apps.

De l'agent au système auto-optimisant
La solution se déroule en deux phases : construire l'agent, puis l'optimiser en continu grâce aux retours d'experts.
Concevoir
- Ingérer les données : Chargez les données du domaine (action par action, participation, effectifs) dans des tables Delta gouvernées dans Unity Catalog.
- Nous avons ingéré deux ans (2023-2024) de données de participation et de play-by-play de football depuis
nflreadpycomme données pour cet agent.
- Nous avons ingéré deux ans (2023-2024) de données de participation et de play-by-play de football depuis
- Créer des outils : Définissez des fonctions SQL comme des outils Unity Catalog que l'agent peut appeler, en exploitant les données extraites.
- Définir et déployer l'agent : Connecter les outils à un
ResponsesAgent, enregistrer une invite système de référence dans le registre d'invites et le déployer sur Model Serving. - Évaluation initiale : Exécutez une évaluation automatisée avec des juges LLM et enregistrez les logs à l'aide des versions de base des juges personnalisés.
Optimiser
- Recueillir les retours d'experts : Les experts du domaine examinent les résultats de l'agent et fournissent des retours structurés par le biais de sessions d'étiquetage MLflow.
- Aligner les juges : Utilisez la fonction
align()de MLflow pour calibrer le juge LLM de référence afin qu'il corresponde aux préférences des SME, lui apprenant ce qui est considéré comme « bon » dans ce domaine. - Optimiser les prompts :
optimize_prompts()de MLflow utilise un optimiseur GEPA guidé par le juge aligné pour améliorer de manière itérative le prompt système d'origine. - Répéter : Chaque session d'étiquetage MLflow est utilisée pour améliorer le juge, qui à son tour est utilisé pour optimiser l'invite système. Ce processus complet peut être automatisé pour promouvoir automatiquement les nouvelles versions d'invites qui dépassent les critères de performance, ou il peut éclairer les mises à jour manuelles de l'agent, telles que l'ajout d'outils ou de données supplémentaires, en fonction des modes de défaillance observés.
La phase de construction vous mène à un prototype initial et la phase d'optimisation accélère la mise en production, optimisant continuellement votre agent grâce aux retours d'experts du domaine.
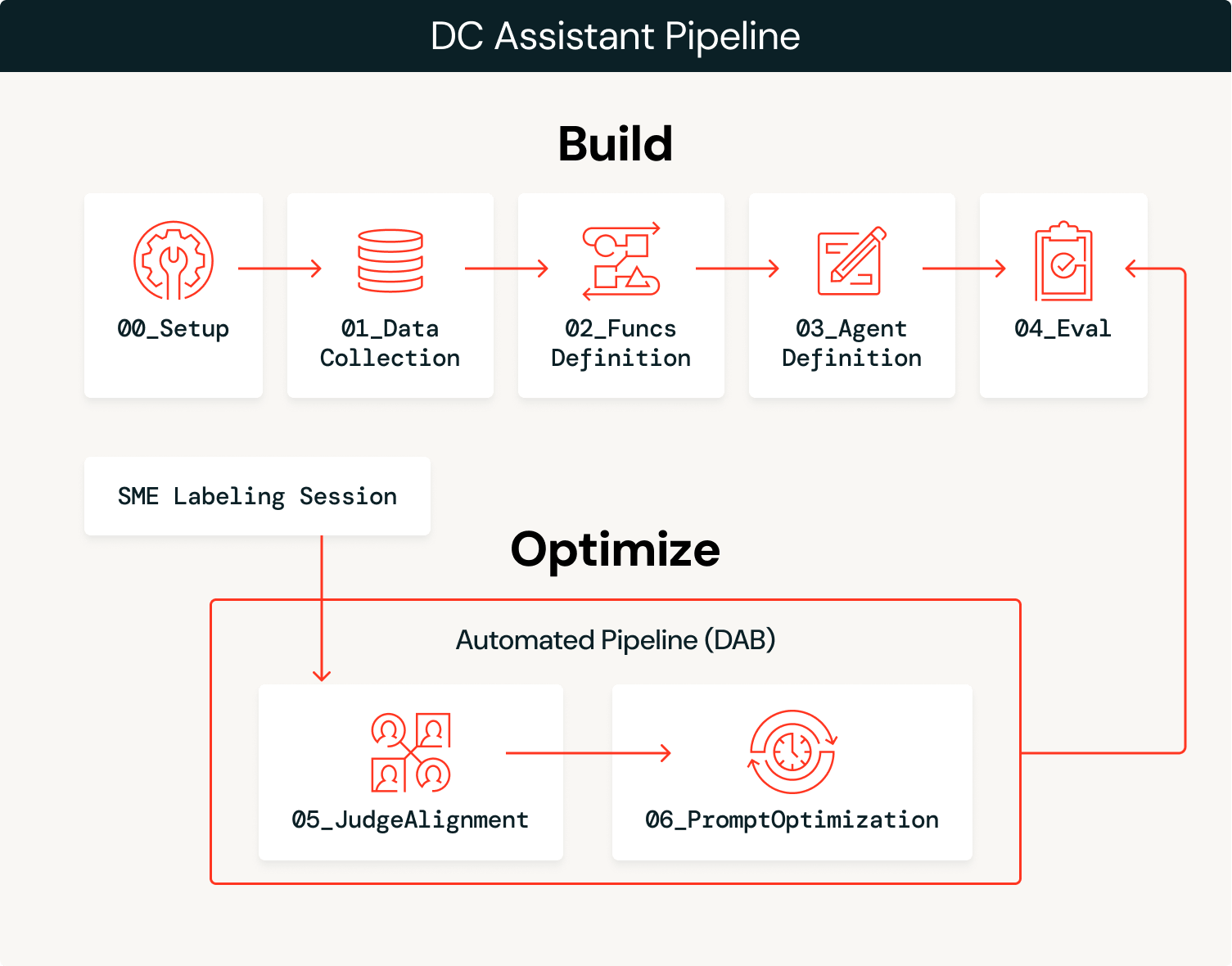
Aperçu de l'architecture
L'agent équilibre le probabilisme et le déterminisme : un LLM interprète l'intention sémantique des requêtes de l'utilisateur et sélectionne les bons outils, tandis que les fonctions SQL déterministes extraient les données avec une précision de 100 %. Par exemple, lorsqu'un entraîneur demande « Comment notre adversaire attaque-t-il le Blitz ? », le LLM interprète cela comme une demande d'analyse de la pression sur le passeur et de la couverture (pass-rush/coverage), et sélectionne success_by_pass_rush_and_coverage(). La fonction SQL renvoie des statistiques exactes à partir des données sous-jacentes. En utilisant les fonctions de Unity Catalog, nous garantissons que les statistiques sont exactes à 100 %, tandis que le LLM gère le contexte conversationnel.
| Étape | Technologie |
|---|---|
| Ingérer des données | Delta Lake + Unity Catalog |
| Créer des outils | Fonctions Unity Catalog |
| Déployer l'agent | ResponsesAgent + Model Serving via agents.deploy() |
| Évaluer avec un LLM en tant que juge | MLflow GenAI evaluate() avec des juges intégrés et personnalisés |
| Recueillir les retours | MLflow sessions d'étiquetage pour les retours des experts du domaine |
| Aligner les juges | MLflow align() à l'aide d'un optimiseur SIMBA personnalisé |
| Optimiser les prompts | MLflow optimize_prompts() à l'aide d'un optimiseur GEPA |
Parcourons chaque étape avec le code et les sorties de l'implémentation de DC Assistant.
Concevoir
1. Ingérer les données.
Un notebook de configuration (00_setup.ipynb) définit toutes les variables de configuration globales utilisées tout au long du workflow : catalogue/schéma du workspace, Experimentation MLflow, Endpoints LLM, noms de modèles, datasets d'évaluation, noms d'outils Unity Catalog et paramètres d'authentification. Cette configuration est enregistrée dans config/dc_assistant.json et chargée par tous les Notebooks en aval, garantissant ainsi la cohérence sur l'ensemble du pipeline. Cette étape est facultative, mais elle contribue à l'organisation générale.
Une fois cette configuration en place, nous chargeons les données de football via nflreadpy et appliquons un traitement incrémentiel pour les préparer à la consommation par l'agent : suppression des colonnes inutilisées, standardisation des schémas et persistance des tables Delta propres dans Unity Catalog. Voici un exemple simple de chargement des données qui n'aborde pas en détail le traitement des données :
Les résultats de ce processus sont des tables Delta gouvernées dans Unity Catalog (action par action, participation, effectifs, équipes, joueurs) qui sont prêtes pour la création d'outils et la consommation par l'agent.
2. Créer des outils.
L'agent a besoin d'outils déterministes pour query les données sous-jacentes. Nous les définissons comme des fonctions SQL Unity Catalog qui calculent les tendances offensives à travers diverses dimensions situationnelles. Chaque fonction prend des paramètres tels que team et season et renvoie des statistiques agrégées que l'agent peut utiliser pour répondre aux questions du coordinateur. Pour cet exemple, nous utilisons uniquement des fonctions basées sur SQL, mais il est possible de configurer des fonctions UC basées sur Python, des index de recherche vectorielle, des outils du Model Context Protocol (MCP) et des Genie spaces comme des fonctionnalités supplémentaires qu'un agent peut exploiter pour compléter le LLM qui supervise le processus.
L'exemple suivant montre success_by_pass_rush_and_coverage(), qui calcule les répartitions passe/course, l'EPA (Expected Points Added, ou points attendus ajoutés), le taux de réussite et les yards gagnés, regroupés par nombre de joueurs de pression sur le passeur et par type de couverture défensive. La fonction inclut un COMMENT qui décrit son objectif, que le LLM utilise pour déterminer quand l'appeler.
Comme ces fonctions se trouvent dans Unity Catalog, elles héritent du modèle de gouvernance de la plateforme : contrôles d'accès basés sur les rôles, suivi de la lignée des données et découvrabilité dans l'ensemble du workspace. Les équipes peuvent trouver et réutiliser des outils sans dupliquer la logique, et les administrateurs conservent une visibilité sur les données auxquelles l'agent peut accéder.
3. Définir et déployer l'agent.
La création de l'agent peut être aussi simple que d'utiliser l'AI Playground. Sélectionnez le LLM que vous souhaitez utiliser, ajoutez vos outils Unity Catalog, définissez votre invite système et cliquez sur « Créer un notebook d'agent » pour exporter un notebook qui produit un agent au format ResponsesAgent. La capture d'écran suivante montre ce workflow en action. Le notebook exporté contient la structure de définition de l'agent, reliant vos fonctions UC à l'agent via le UCFunctionToolkit.
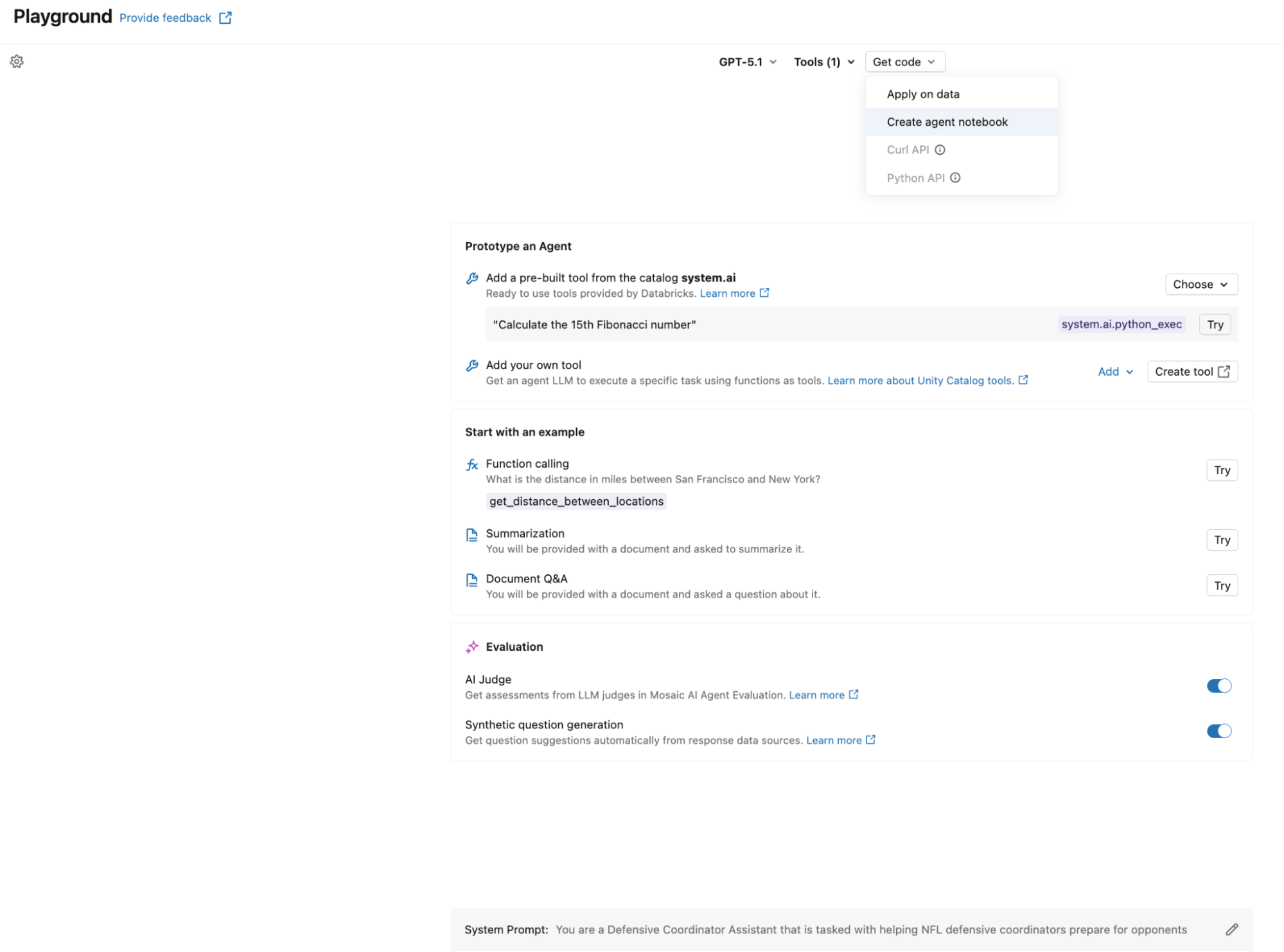
Pour activer la boucle d'auto-optimisation, nous enregistrons le prompt système dans le Prompt Registry plutôt que de le coder en dur. Cela permet à la phase d'optimisation de mettre à jour le prompt sans redéployer l'agent :
Une fois le code de l'agent testé et le modèle enregistré dans Unity Catalog, son déploiement sur un endpoint persistant est aussi simple que le code ci-dessous. Cela crée un endpoint de Model Serving avec le MLflow Tracing activé, des tables d'inférence pour la journalisation des requêtes/réponses et une mise à l'échelle automatique :
Pour l'accès des utilisateurs finaux, l'agent peut également être déployé en tant qu'application Databricks, fournissant une interface de discussion que les coordinateurs et les analystes peuvent utiliser directement sans avoir besoin d'un accès à un notebook ou à une API. La capture d'écran de l'introduction montre ce déploiement basé sur une application en action.
4. Évaluation initiale.
Une fois l'agent déployé, nous exécutons une évaluation automatisée à l'aide de juges LLM pour établir une mesure de qualité de référence. MLflow prend en charge plusieurs types de juges, et nous en utilisons trois en combinaison.
Les évaluateurs intégrés gèrent nativement les critères d'évaluation courants. RelevanceToQuery() vérifie si la réponse correspond à la question de l'utilisateur. Les évaluateurs basés sur des consignes effectuent une évaluation par rapport à des règles textuelles spécifiques de manière binaire (réussite/échec). Nous définissons une consigne garantissant que les réponses utilisent la terminologie appropriée du football professionnel :
Les juges personnalisés utilisent make_judge() pour une évaluation spécifique au domaine avec un contrôle total sur les critères de notation. Voici le juge que nous alignerons sur les commentaires de l'expert du domaine lors de la phase d'optimisation :
Une fois tous les juges définis, nous pouvons exécuter une évaluation sur l'ensemble de données :
Le juge personnalisé football_analysis_base fournit un score de référence, mais il s'agit simplement d'une tentative de créer à partir de zéro une grille d'évaluation que le LLM peut utiliser pour ses jugements, et non le reflet d'une véritable expertise du domaine. L'interface utilisateur des expérimentations MLflow nous montre les performances de l'agent sur ce juge de référence, ainsi qu'une justification du score dans chaque exemple.
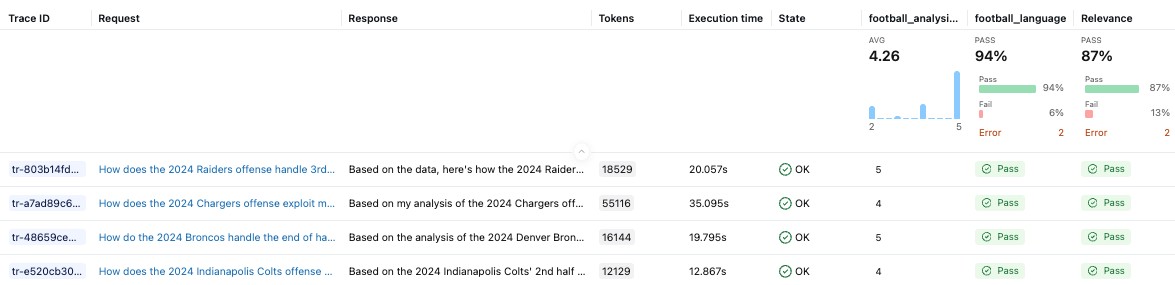

Dans la phase d'optimisation, nous alignerons le juge d'analyse du football sur les préférences des experts du domaine, en lui apprenant ce que « bon » signifie réellement pour l'analyse du coordinateur défensif.
Optimiser
5. Recueillir les commentaires d'experts.
Une fois l'agent déployé et l'évaluation de base terminée, nous entrons dans la boucle d'optimisation. C'est là que l'expertise du domaine est encodée dans le système, d'abord par le biais de juges LLM alignés, puis directement dans l'agent par l'optimisation de l'invite système guidée par notre juge aligné.
Nous commençons par créer un schéma d'étiquettes qui utilise les mêmes instructions et critères d'évaluation que le juge d'analyse du football que nous avons créé avec make_judge(). Ensuite, nous créons une session d'étiquetage qui permet à notre expert du domaine d'examiner les réponses pour les mêmes traces que celles utilisées dans le evaluate() job et de fournir ses notes et ses commentaires via l'application de révision (illustrée ci-dessous).
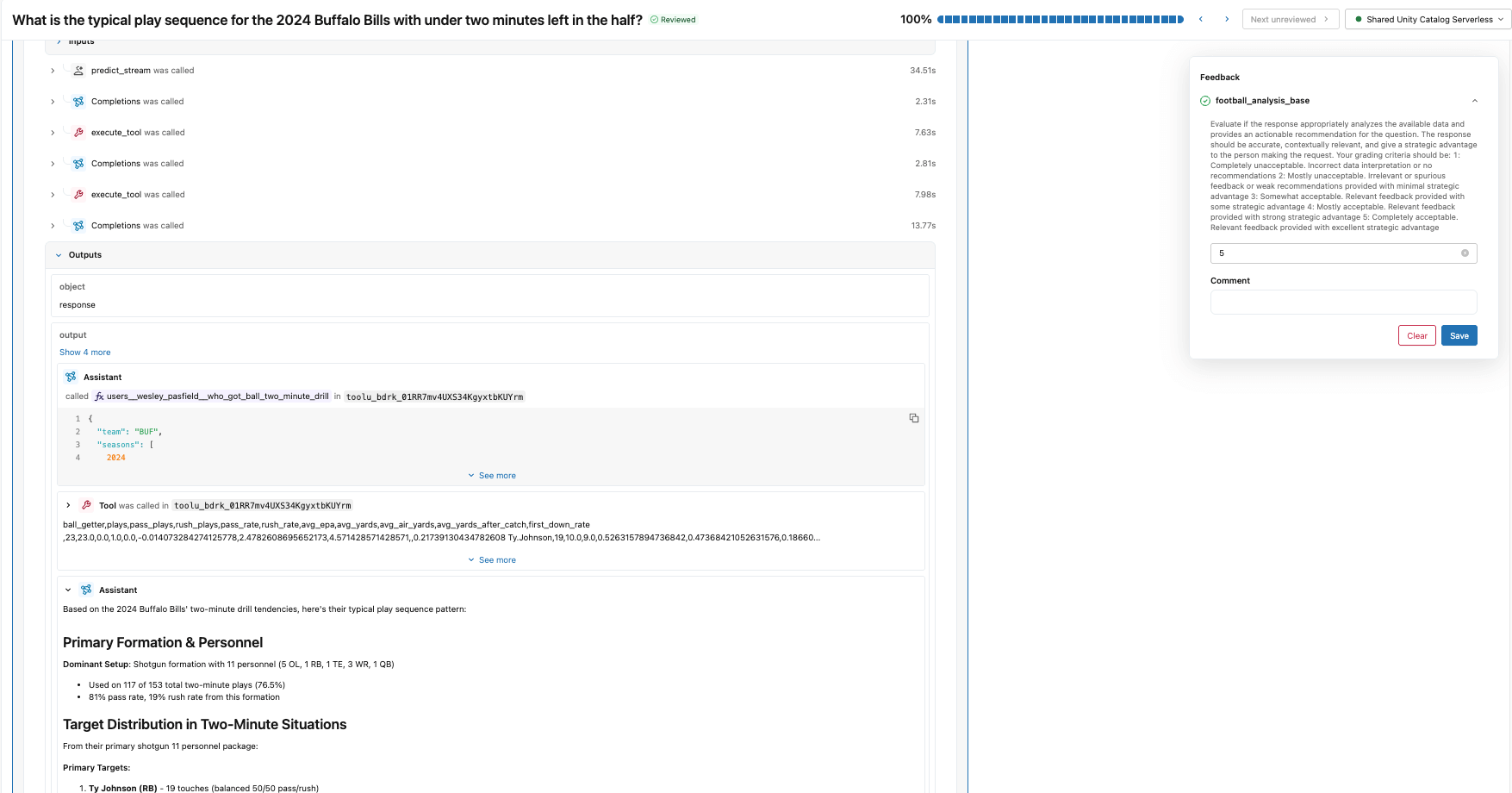
Ces retours deviennent la vérité terrain pour l'alignement du juge. En observant les points de divergence entre les scores du juge de référence et ceux des experts du domaine, nous identifions les erreurs du juge concernant ce domaine spécifique.
6. Aligner les juges.
Maintenant que nous avons des traces qui incluent à la fois les retours des experts du domaine et ceux du juge LLM, nous pouvons tirer parti de la fonctionnalité align() de MLflow pour aligner notre juge LLM sur les retours de nos experts du domaine. Un juge aligné reflète la perspective de vos experts du domaine et les données uniques de votre organisation. L'alignement intègre les experts du domaine dans le processus de développement d'une manière qui n'était pas possible auparavant : les retours du domaine façonnent directement la manière dont le système mesure la qualité, rendant les métriques de performance des agents à la fois fiables et évolutives.
align() vous permet d'utiliser votre propre optimiseur ou l'optimiseur binaire SIMBA (Simplified Multi-Bootstrap Aggregation) par défaut. Dans ce cas, nous utilisons un optimiseur SIMBA personnalisé pour calibrer un juge à échelle de Likert :
Ensuite, nous récupérons les traces qui ont à la fois des scores d'évaluateur LLM et des commentaires de SME que nous avons tagués tout au long du processus. Ces scores appariés sont ce que SIMBA utilise pour apprendre l'écart entre le jugement générique et celui des experts.
La capture d'écran suivante montre le processus d'alignement en cours. Le modèle identifie les écarts entre les juges LLM et les retours des SME, propose de nouvelles règles et de nouveaux détails à intégrer au juge pour combler ces écarts, puis évalue les nouveaux juges candidats pour voir s'ils dépassent les performances du juge de référence.

Le résultat final de ce processus est un juge aligné qui reflète directement les commentaires des experts du domaine avec des instructions détaillées.

Conseils pour un alignement efficace :
- L'objectif de l'alignement est de vous donner l'impression que des experts du domaine sont à vos côtés pendant le développement. Ce processus peut entraîner une baisse des scores de performance pour votre agent de référence, ce qui signifie que votre évaluateur de référence n'était pas assez spécifié. Maintenant que vous disposez d'un évaluateur qui critique l'agent de la même manière que le feraient vos SME, vous pouvez apporter des améliorations manuelles ou automatisées pour améliorer les performances.
- La qualité du processus d'alignement dépend de celle des retours fournis. Privilégiez la qualité à la quantité. Des retours détaillés et cohérents sur un nombre réduit d'exemples (10 au minimum) produisent de meilleurs résultats que des retours incohérents sur un grand nombre d'exemples.
La définition de la qualité est souvent le principal obstacle à l'amélioration des performances de l'agent. Quelle que soit la technique d'optimisation, s'il n'y a pas de définition claire de la qualité, les performances de l'agent seront décevantes. Databricks propose un atelier qui aide les clients à définir la qualité par le biais d'un exercice itératif et interfonctionnel. Pour en savoir plus, veuillez contacter votre équipe de compte Databricks ou remplir ce formulaire.
7. Optimiser les prompts.
Avec un juge aligné qui reflète les préférences de l'expert du domaine, nous pouvons désormais améliorer automatiquement le prompt système de l'agent. La fonction optimize_prompts() de MLflow utilise GEPA pour affiner de manière itérative le prompt en fonction de la notation du juge aligné. GEPA (Genetic-Pareto), co-créé par Matei Zaharia, le CTO de Databricks, est un algorithme de prompt génétique évolutif qui s'appuie sur de grands modèles linguistiques pour effectuer des mutations réflexives sur les prompts, lui permettant d'affiner les instructions de manière itérative et de surpasser les techniques traditionnelles d'apprentissage par renforcement dans l'optimisation des performances du modèle.
Au lieu qu'un développeur devine quels adjectifs ajouter à l'invite système, l'optimiseur GEPA fait évoluer mathématiquement l'invite pour maximiser le score spécifique défini par l'expert. Le processus d'optimisation nécessite un dataset avec les réponses attendues qui guident l'optimiseur vers les comportements souhaités, comme ceci :
L'optimiseur GEPA prend le prompt système actuel et propose des améliorations de manière itérative, en évaluant chaque candidat par rapport au juge aligné. Ici, nous récupérons le prompt initial, le dataset d'optimisation que nous avons créé et le juge aligné pour exploiter la fonction optimize_prompts() de MLflow. Nous utilisons ensuite l'optimiseur GEPA pour créer une nouvelle invite système guidée par notre juge aligné :
La capture d'écran suivante montre le changement dans le prompt système : l'ancien est à gauche et le nouveau est à droite. Le prompt final choisi est celui qui obtient le score le plus élevé, mesuré par notre juge aligné. Le nouveau prompt a été tronqué par manque de place, mais il est clair d'après cet exemple que nous avons pu intégrer les réponses des experts du domaine pour créer un prompt ancré dans un langage spécifique au domaine, avec des instructions explicites sur la manière de traiter certaines requêtes.

La capacité de générer automatiquement ce type de directives à l'aide des retours des SME permet essentiellement à vos SME de fournir indirectement des instructions à un agent, simplement en donnant leur avis sur les traces de l'agent.
Dans ce cas, le nouveau prompt a généré de meilleures performances sur notre dataset d'optimisation selon notre juge aligné. Nous avons donc attribué l'alias de production au prompt nouvellement enregistré, nous permettant de redéployer notre agent avec ce prompt amélioré.
Conseils pour l'optimisation des prompts :
- Le dataset d'optimisation doit couvrir la diversité des queries que votre agent traitera. Incluez les cas limites, les requêtes ambiguës et les scénarios où la sélection de l'outil est importante.
- Les réponses attendues doivent décrire ce que l'agent doit faire (quels outils appeler, quelles informations inclure) plutôt que le texte de sortie exact.
- Commencez avec
max_metric_callsdéfini entre50et100. Des valeurs plus élevées explorent plus de candidats, mais augmentent le coût et le temps d'exécution. - L'optimiseur GEPA apprend des modes de défaillance. Si le juge aligné pénalise les benchmarks manquants ou les mises en garde concernant les petits échantillons, GEPA injectera ces exigences dans le prompt optimisé.
8. Boucler la boucle : automatisation et amélioration continue.
Les étapes individuelles que nous avons parcourues peuvent être orchestrées dans un pipeline d'optimisation continue où l'étiquetage par l'expert du domaine devient le déclencheur de la boucle d'optimisation, et tout peut être englobé dans un job Databricks à l'aide des Asset Bundles :
- Les experts du domaine étiquettent les résultats de l'agent via l'interface utilisateur des sessions d'étiquetage MLflow, en fournissant des scores et des commentaires sur des traces de production réelles.
- Le pipeline détecte les nouvelles étiquettes et extrait les traces contenant à la fois les retours des experts du domaine et les scores de référence des juges LLM.
- Évaluer les exécutions d'alignement, produisant une nouvelle version du juge calibrée en fonction des dernières préférences du SME.
- Les exécutions d'optimisation de prompt utilisent le juge aligné pour améliorer de manière itérative le prompt système.
- La promotion conditionnelle pousse le nouveau prompt en production s'il dépasse les seuils de performance. Cela pourrait impliquer le déclenchement d'un autre job d'évaluation pour s'assurer que le nouveau prompt se généralise à d'autres exemples.
- L'agent s'améliore automatiquement, car le prompt registry sert la version optimisée.
Lorsque des experts du domaine terminent une session d'étiquetage, un job evaluate() est déclenché pour générer des scores de juge LLM sur les mêmes traces. Lorsque le job evaluate() se termine, un job align() s'exécute pour aligner le juge LLM sur les commentaires de l'expert du domaine. Lorsque ce job se termine, un job optimize_prompts() s'exécute pour générer un nouveau prompt système amélioré qui peut être immédiatement testé sur un nouveau dataset et, le cas échéant, mis en production.
L'ensemble de ce processus peut être entièrement automatisé, mais une révision manuelle peut également être ajoutée à n'importe quelle étape, donnant aux développeurs un contrôle total sur le niveau d'automatisation impliqué. Le processus se répète à mesure que les SME continuent l'étiquetage, ce qui permet des tests de performance rapides sur les nouvelles versions de l'agent, et des gains de performance cumulatifs auxquels les développeurs peuvent réellement se fier.
Conclusion
Cette architecture transforme la façon dont les agents s'améliorent au fil du temps, à l'aide du Databricks Agent Framework et de MLflow. Au lieu que les développeurs devinent ce qui constitue une bonne réponse, les experts du domaine façonnent directement le comportement de l'agent grâce aux commentaires d'experts. Les processus d'alignement et d'optimisation du juge traduisent l'expertise du domaine en changements concrets du système, tandis que les développeurs gardent le contrôle sur l'ensemble du système, y compris les parties à automatiser et où autoriser une intervention manuelle.
Dans cet article, nous avons illustré comment personnaliser un agent pour refléter le langage et les détails spécifiques qui sont importants pour les experts du domaine du football professionnel. L'assistant DC illustre ce modèle, mais l'approche fonctionne pour n'importe quel domaine où le jugement d'un expert est important : l'examen de documents juridiques, la préparation au passage au bâton dans le baseball professionnel, le triage médical, l'analyse des coups de golf, la transmission au niveau supérieur du support client, ou toute autre application où il est difficile pour les développeurs de définir ce qui est « bon » sans le soutien d'experts du domaine.
Essayez-le sur votre propre problème spécifique à un domaine et découvrez comment il peut générer une amélioration automatisée et continue basée sur les commentaires des experts du domaine !
En savoir plus sur Databricks Sports et Agent Bricks, ou demandez une démo pour découvrir comment votre organisation peut obtenir des insights concurrentiels.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.