Arrêtez de coder manuellement les pipelines de capture de données modifiées
Comment AutoCDC automatise la CDC et les dimensions à variation lente
par Matt Jones, Zoé Durand, Phoebe Weiser, Bilal Aslam et Ray Zhu
- Pourquoi les pipelines CDC et SCD codés manuellement sont fragiles, complexes et coûteux à exploiter à grande échelle
- Comment AutoCDC automatise de manière déclarative les modèles CDC basés sur SCD Type 1, SCD Type 2 et les instantanés
- Gains réels en matière de correction, de performance et de coût grâce aux charges de travail AutoCDC en production
J'ai essayé AutoCDC à partir d'instantanés en Python et j'ai été stupéfait de voir comment 4 lignes de code pouvaient remplacer ce que je faisais auparavant en 1 500 lignes de code. —Ingénieur de données principal, entreprise aérospatiale et de défense du Fortune 500
La capture des données de modification (CDC) et les dimensions à évolution lente (SCD) sont fondamentales pour les charges de travail analytiques et d'IA modernes. Les équipes s'appuient sur elles pour maintenir l'exactitude des tables en aval à mesure que les données opérationnelles changent, qu'il s'agisse de maintenir une vue actuelle de l'activité ou de préserver le contexte historique complet.
Pourtant, en pratique, les pipelines CDC sont souvent parmi les pipelines les plus pénibles à construire et à exploiter. Les équipes créent manuellement une logique MERGE complexe pour gérer les mises à jour, les suppressions et les données arrivant tardivement : en superposant des tables intermédiaires, des fonctions de fenêtre et des hypothèses de séquencement qui sont difficiles à comprendre, et encore plus difficiles à maintenir à mesure que les pipelines évoluent.
Dans cet article, nous allons passer en revue les modèles CDC et SCD que les ingénieurs de données et les praticiens SQL rencontrent chaque jour, pourquoi ces modèles sont difficiles à implémenter manuellement, et comment AutoCDC dans les pipelines déclaratifs Spark de Lakeflow les automatise de manière déclarative, tout en apportant des améliorations significatives en termes de prix et de performances.
La CDC et la SCD sont toujours difficiles pour les ingénieurs de données
Même pour les équipes qui comprennent bien ces modèles, les mettre en œuvre correctement et les maintenir corrects au fil du temps est là où les choses se compliquent. À mesure que les volumes de données augmentent et que les cas d'utilisation se développent, les pipelines deviennent fragiles ; les problèmes de correction apparaissent tardivement ; et même de petits changements nécessitent des réécritures prudentes pour éviter de corrompre les tables en aval.
Maintenance des tables SCD Type 1
Les tables SCD Type 1 écrasent les lignes existantes pour refléter le dernier état. Même ce cas « simple » pose rapidement des défis :
- Les mises à jour arrivent dans le désordre
- Les événements en double doivent être dédupliqués de manière cohérente
- Les suppressions doivent être appliquées correctement
- La logique doit rester idempotente lors des nouvelles tentatives et du retraitement
Ce qui commence souvent comme un simple MERGE INTO évolue vers une logique profondément imbriquée avec des tables intermédiaires, des fonctions de fenêtre et des hypothèses de séquencement difficiles à comprendre (ou à modifier en toute sécurité). Au fil du temps, les équipes deviennent réticentes à toucher ces pipelines.
Maintenance de l'historique SCD Type 2
La SCD Type 2 introduit une complexité supplémentaire :
- Suivi des versions de lignes et des fenêtres de validité
- Gestion des mises à jour arrivant tardivement sans corrompre l'historique
- Garantir qu'il n'existe qu'une seule version « actuelle » à tout moment
Les erreurs ici ne se manifestent pas toujours bruyamment. Elles apparaissent souvent des semaines plus tard sous forme de dérives subtiles des métriques, ou de la nécessité de reconstruire entièrement les tables historiques.
Extraction des données de modification à partir de différentes sources
Tous les systèmes n'émettent pas de journaux CDC propres. Certains systèmes émettent des flux de données de modification natifs, tandis que d'autres non, souvent parce que l'équipe qui consomme les données ne contrôle pas la base de données en amont, obligeant les équipes à reconstruire les modifications en comparant des instantanés successifs d'une table source.
La prise en charge des deux implique généralement une logique d'ingestion et de traitement distincte ; des hypothèses de correction différentes ; et plus de chemins de code à maintenir et à déboguer.
Exploitation des pipelines CDC dans le temps
Même une fois qu'un pipeline CDC est correct, il doit toujours survivre au retraitement et aux remplissages, à l'évolution du schéma, aux échecs et aux redémarrages. La logique CDC écrite manuellement a tendance à devenir de plus en plus fragile avec le temps à mesure que ces réalités s'accumulent, augmentant le risque opérationnel et le coût de maintenance.
Automatisation des modèles CDC complexes avec l'ingénierie déclarative des données
AutoCDC a été conçu pour standardiser ces modèles CDC et SCD courants derrière une abstraction déclarative. Au lieu de coder manuellement *comment* les modifications doivent être appliquées, les équipes déclarent *quelles sémantiques* elles souhaitent, et la plateforme gère l'ordre, l'état et le traitement incrémentiel.
| Charge de travail CDC | AutoCDC | Logique MERGE / Instantané écrite manuellement |
|---|---|---|
| Maintien des tables d'état actuel (SCD Type 1) | La définition déclarative du pipeline gère automatiquement le séquencement, la déduplication et les suppressions | Logique MERGE personnalisée avec fonctions de fenêtre et règles de séquencement |
| Maintien des tables historiques (SCD Type 2) | Gestion automatique des versions avec suivi de l'historique intégré | Logique MERGE en plusieurs étapes pour fermer et insérer les versions d'enregistrement |
| Inférence des modifications à partir de sources d'instantanés | Prise en charge intégrée de la CDC par instantané | Pipelines de comparaison d'instantanés manuels avec jointures et comparaisons |
| Exploitation fiable des pipelines dans le temps (données tardives, nouvelles tentatives, retraitement) | Ordre automatique et exécution idempotente | Nécessite des protections personnalisées et une logique supplémentaire |
| Empreinte de code et complexité opérationnelle | ~6 à 10 lignes de définition de pipeline déclaratif | 40 à 200+ lignes de logique de pipeline personnalisée |
Cela offre aux équipes une manière cohérente et répétable d'implémenter la CDC et la SCD dans les pipelines, plutôt que de réinventer le modèle à chaque fois (ce qui est vraiment la valeur fondamentale de la programmation déclarative en général, et des pipelines déclaratifs Spark spécifiquement).
Lors du traitement des enregistrements de modification à partir d'un flux de données de modification (CDF), AutoCDC gère automatiquement les enregistrements hors séquence et applique correctement les mises à jour en fonction d'une colonne de séquencement déclarée. Pour montrer comment cela fonctionne en pratique, considérons le flux CDC d'exemple ci-dessous :
| userId | name | city | operation | sequenceNum |
|---|---|---|---|---|
| 124 | Raul | Oaxaca | INSERT | 1 |
| 123 | Isabel | Monterrey | INSERT | 1 |
| 125 | Mercedes | Tijuana | INSERT | 2 |
| 126 | Lily | Cancun | INSERT | 2 |
| 123 | null | null | DELETE | 6 |
| 125 | Mercedes | Guadalajara | UPDATE | 6 |
| 125 | Mercedes | Mexicali | UPDATE | 5 |
| 123 | Isabel | Chihuahua | UPDATE | 5 |
Rappelez-vous, vous devez choisir SCD Type 1 pour conserver uniquement les dernières données, ou choisir SCD Type 2 pour conserver les données historiques. Commençons par le Type 1.
Automatisation de la maintenance SCD Type 1 (sources de flux de données de modification)
Dans cet exemple, un flux de données de modification contient des insertions, des mises à jour et des suppressions pour une table utilisateur. L'objectif est de maintenir une vue actuelle de chaque enregistrement, où les nouvelles mises à jour écrasent les anciennes valeurs.
Table de sortie pour SCD Type 1
| id | name | city |
|---|---|---|
| 124 | Raul | Oaxaca |
| 125 | Mercedes | Guadalajara |
| 126 | Lily | Cancun |
L'utilisateur 123 (Isabel) a été supprimé, il n'apparaît donc pas dans la sortie. L'utilisateur 125 (Mercedes) affiche uniquement la dernière ville (Guadalajara) car SCD Type 1 écrase les valeurs précédentes.
Avec une approche traditionnelle, cela nécessite une logique MERGE personnalisée pour dédupliquer les événements, appliquer le séquencement, appliquer les suppressions et garantir que le pipeline reste correct lors des nouvelles tentatives ou de l'arrivée tardive de données. AutoCDC remplace cette logique fragile par une définition de pipeline déclarative qui gère automatiquement le séquencement, la déduplication, les données arrivant tardivement et le traitement incrémentiel, éliminant des dizaines de lignes de logique de fusion personnalisée.
Voir l'exemple de code complet dans l'annexe
Automatisation de l'historique SCD Type 2 (sources de flux de données de modification)
Dans de nombreux systèmes analytiques, conserver uniquement le dernier état ne suffit pas : les équipes ont besoin d'un historique complet de l'évolution des enregistrements au fil du temps. C'est le modèle SCD Type 2, où chaque version d'un enregistrement est stockée avec des fenêtres de validité indiquant quand elle était active.
Table de sortie pour SCD type 2 :
| id | name | city | __START_AT | __END_AT |
|---|---|---|---|---|
| 123 | Isabel | Monterrey | 1 | 5 |
| 123 | Isabel | Chihuahua | 5 | 6 |
| 124 | Raul | Oaxaca | 1 | NULL |
| 125 | Mercedes | Tijuana | 2 | 5 |
| 125 | Mercedes | Mexicali | 5 | 6 |
| 125 | Mercedes | Guadalajara | 6 | NULL |
| 126 | Lily | Cancun | 2 | NULL |
La table conserve l'historique complet. L'utilisateur 123 a deux versions (terminées à la séquence 6 lors de la suppression). L'utilisateur 125 a trois versions montrant les changements de ville. Les enregistrements avec __END_AT = NULL sont actuellement actifs.
L'implémentation manuelle nécessite une logique MERGE en plusieurs étapes pour clôturer les enregistrements précédents, insérer de nouvelles versions et s'assurer qu'une seule version reste active à la fois. AutoCDC automatise ces transitions de manière déclarative, gérant les colonnes d'historique et la logique de versionnement automatiquement tout en garantissant l'exactitude, même lorsque les mises à jour arrivent dans le désordre.
Voir l'exemple de code complet dans l'annexe
Déduction du CDC à partir de sources de snapshots
Tous les systèmes sources n'émettent pas de journaux de modifications. Dans de nombreux cas, les équipes reçoivent des snapshots périodiques d'une table source et doivent en déduire ce qui a changé entre les exécutions.
Traditionnellement, cela nécessite de comparer manuellement les snapshots pour détecter les insertions, les mises à jour et les suppressions avant d'appliquer ces modifications avec une logique MERGE. AutoCDC traite le CDC basé sur les snapshots comme un modèle de première classe, détectant automatiquement les modifications au niveau des lignes entre les snapshots et les appliquant de manière incrémentielle sans nécessiter de logique de diff personnalisée ou de gestion d'état.
L'implémentation manuelle nécessite de détecter les modifications au niveau des lignes entre les snapshots, de clôturer les enregistrements précédemment actifs et d'insérer de nouvelles versions avec des fenêtres de validité mises à jour. AutoCDC dérive automatiquement ces modifications et applique la sémantique SCD Type 2, en maintenant l'historique des versions sans nécessiter de logique de fusion en plusieurs étapes ou de suivi personnalisé de l'état du snapshot.
Gestion de l'ordre, de l'état et du retraitement
Lakeflow Spark Declarative Pipelines suit automatiquement les progrès incrémentiels et gère les données hors séquence. Les pipelines peuvent récupérer après des échecs, retraiter les données historiques et évoluer au fil du temps sans appliquer en double ou perdre des modifications.
Concrètement, cela supprime la nécessité pour les équipes de gérer elles-mêmes la logique de séquençage, la comptabilisation des filigranes ou la sécurité du retraitement - la plateforme s'en charge.
Nouveautés : gains majeurs de prix et de performance
Au-delà de la simplification de la logique des pipelines, les récentes améliorations de Databricks Runtime ont apporté des gains substantiels en termes de performance et de rentabilité pour les charges de travail AutoCDC - depuis novembre 2025 seulement :
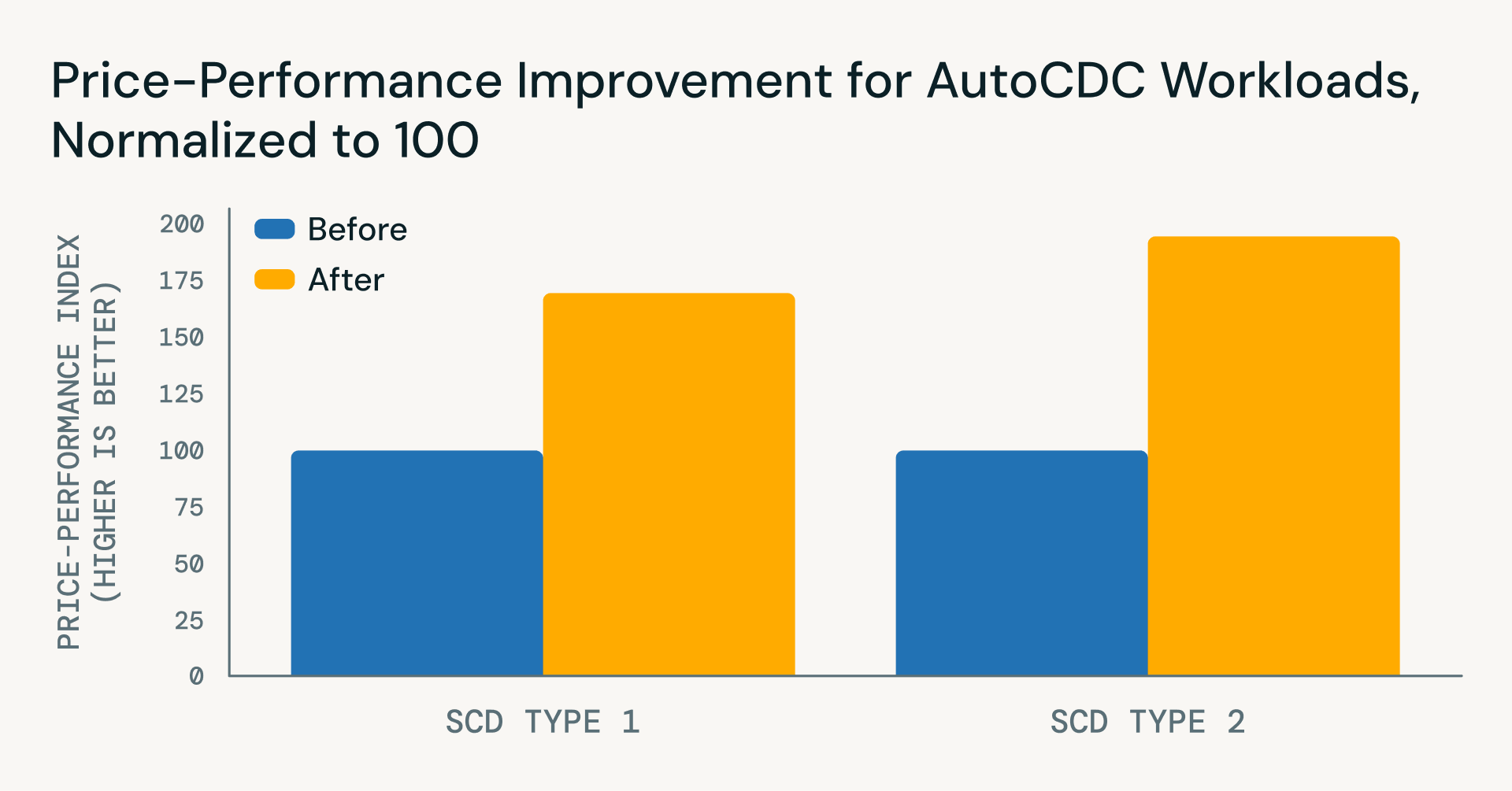
- SCD Type 1
- ~22% d'amélioration de la latence
- ~40% de réduction des coûts
- ~71% de bénéfice net prix-performance
- SCD Type 2
- ~45% de réduction de la latence
- ~35% de réduction des coûts pour les mises à jour incrémentielles
- ~96% de bénéfice net prix-performance
Ces gains sont importants pour les pipelines réels qui s'exécutent en continu à grande échelle. Bien que MERGE INTO reste une primitive fondamentale de Spark, AutoCDC s'appuie sur elle pour gérer les données hors séquence et le traitement incrémentiel plus efficacement à mesure que les volumes de données augmentent.
Succès clients avec AutoCDC
Les équipes exécutant des pipelines CDC et SCD en production ont explicitement cité AutoCDC comme apportant une valeur significative :
Navy Federal Credit Union utilise AutoCDC dans Lakeflow Spark Declarative Pipelines pour alimenter le traitement d'événements à grande échelle en temps réel, gérant des milliards d'événements d'application en continu tout en éliminant le code CDC personnalisé et la maintenance continue des pipelines.
La simplicité du modèle de programmation Spark Declarative Pipelines combinée à ses capacités de service a permis un temps de retour sur investissement incroyablement rapide. —Jian (Miracle) Zhou, Senior Engineering Manager, Navy Federal Credit Union
Block utilise AutoCDC dans Lakeflow Spark Declarative Pipelines pour simplifier la capture de données de modification et les pipelines de streaming en temps réel sur Delta Lake, remplaçant le code CDC et la logique de fusion écrits à la main par une approche déclarative rapide à implémenter et facile à exploiter.
Avec l'adoption de Spark Declarative Pipelines, le temps nécessaire pour définir et développer un pipeline de streaming est passé de jours à heures. —Yue Zhang, Staff Software Engineer, Data Foundations, Block
Valora Group, un fournisseur suisse de premier plan de « foodvenience », utilise AutoCDC dans Lakeflow Spark Declarative Pipelines pour rationaliser la capture des données de modification pour les données de référence et l'analyse en temps réel de la vente au détail, remplaçant le code CDC personnalisé par une approche déclarative facile à implémenter, à répéter et à adapter à l'échelle des équipes.
Nous avons beaucoup gagné en faisant du CDC dans SDP, car vous n'écrivez pas de code, tout est abstrait en arrière-plan. AutoCDC minimise le nombre de lignes... c'est tellement facile à faire. —Alexane Rose, Data and AI Architect, Valora Holding
Commencer
AutoCDC est disponible dans le cadre de Lakeflow Spark Declarative Pipelines sur Databricks.
Pour en savoir plus :
- Consultez la documentation AutoCDC (SQL et Python)
- Explorez des exemples pour SCD Type 1, SCD Type 2 et le CDC basé sur les snapshots
Essayez AutoCDC dans vos propres pipelines et éliminez la logique CDC écrite à la main !
Annexe
Exemple SCD Type 1
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import max_by, struct
# Deduplicate: keep latest record per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Apply SCD Type 1: upsert updates, delete deletions
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(updates.alias("s"), "s.userId = t.userId")
.whenMatchedDelete(condition="s.operation = 'DELETE'")
.whenMatchedUpdate(
condition="s.sequenceNum > t.sequenceNum",
set={"name": "s.name", "city": "s.city", "sequenceNum": "s.sequenceNum"}
)
.whenNotMatchedInsertAll(condition="s.operation != 'DELETE'")
.execute())
| from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr
@dp.view
def users():
return spark.readStream.table("cdc_data.users")
dp.create_streaming_table("target")
dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=1
)
|
Exemple SCD Type 2
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import col, lit, max_by, struct
# Deduplicate: keep latest record per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Step 1: close out active rows for records being updated or deleted
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(
updates.alias("s"),
"s.userId = t.userId AND t.__END_AT IS NULL AND s.sequenceNum > t.__START_AT"
)
.whenMatchedUpdate(set={"__END_AT": "s.sequenceNum"})
.execute())
# Step 2: insert new rows for inserts and updates (not deletes)
new_rows = (updates
.filter("operation != 'DELETE'")
.withColumn("__START_AT", col("sequenceNum"))
.withColumn("__END_AT", lit(None).cast("long"))
.drop("operation"))
new_rows.write.mode("append").saveAsTable("target")
| dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=2
)
|
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.