Données structurées ou non structurées
- Les données structurées sont organisées en schémas prédéfinis - Stockées dans des tables à format fixe, les données structurées permettent des requêtes SQL rapides, prennent en charge les outils de Business Intelligence et sont utilisées pour l'analytique traditionnelle, comme le reporting et la prévision, mais les changements de schéma peuvent être difficiles.
- Les données non structurées représentent 80 à 90 % des données d'entreprise et nécessitent des outils avancés pour extraire des insights à partir de data lakes ou d'architectures lakehouse.
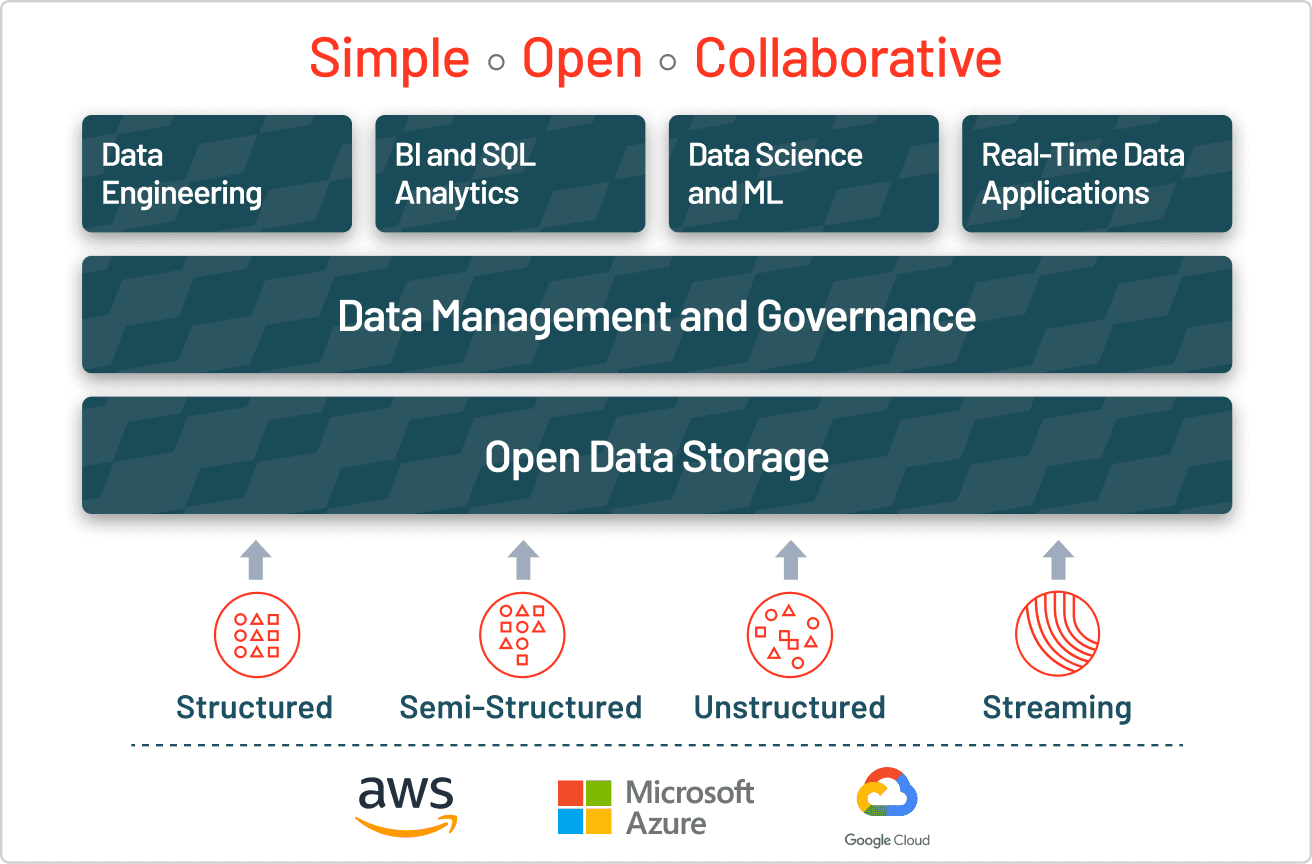
- Les entreprises modernes ont besoin d'approches hybrides combinant les deux types de données - Les architectures Lakehouse unifient la gestion de données structurées et non structurées, offrant l'ouverture des data lake et la fiabilité des data warehouse, tout en fournissant une gouvernance unifiée sur tous les types de données.
Les données structurées et non structurées sont toutes deux des assets essentiels pour les organisations modernes, mais elles sont fondamentalement différentes. Les organisations doivent comprendre ces différences et gérer chaque type efficacement pour en exploiter toute la valeur. Ce guide examine les implications pratiques, les cas d'utilisation concrets et les considérations stratégiques pour choisir le bon type de données. Il aborde également les outils répondant aux besoins courants des entreprises, allant au-delà des comparaisons génériques pour proposer des cadres décisionnels exploitables.
Données structurées : caractéristiques et applications
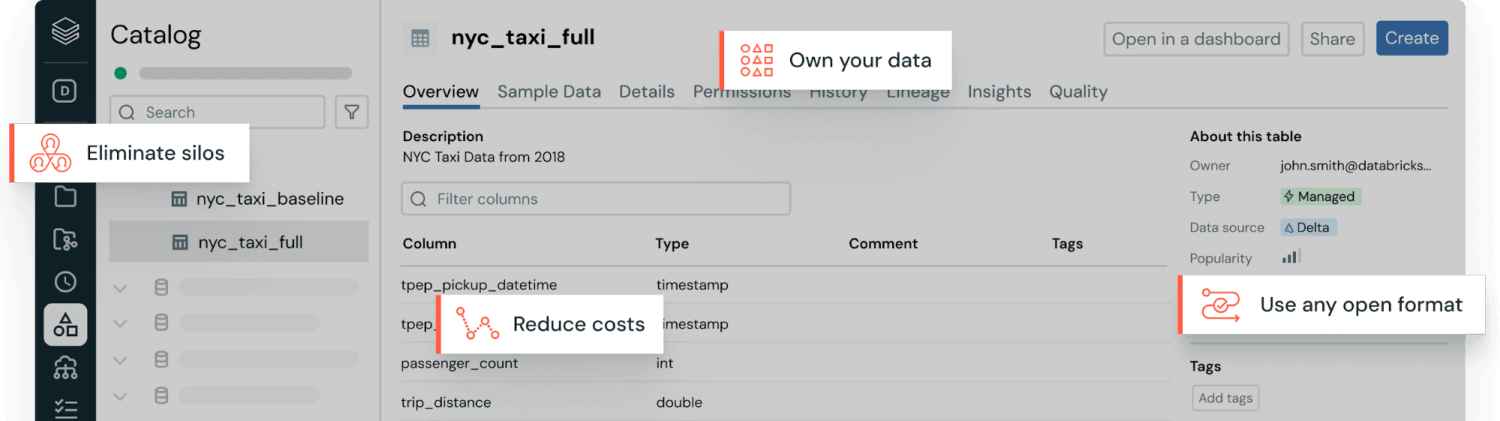
Caractéristiques principales des données structurées
Les données structurées sont des informations organisées au sein d'un modèle de données relationnel prédéfini, ce qui signifie que les données sont disposées dans des tables avec des schémas fixes. Ce modèle spécifie la structure (lignes et colonnes), les types de données et les relations entre les tables avant que toute donnée ne soit stockée afin de permettre une recherche et une analyse efficaces. Les exemples courants de données structurées incluent les transactions financières, les fichiers Excel, les enregistrements de gestion de la relation client (CRM), les niveaux de stock, les commandes de ventes, les systèmes de réservation et les relevés de capteurs.
Les données structurées sont généralement stockées dans des data warehouse. Ceux-ci sont optimisés pour des requêtes rapides et fiables via le langage SQL (Structured Query Language), utilisé pour les charges de travail sur données structurées.
Le format standardisé rend également les données structurées très accessibles. Les utilisateurs métier peuvent facilement les explorer, les analyser et en rendre compte à l'aide d'outils familiers de Business Intelligence (BI) et d'analytique pour générer des insights sans nécessiter de compétences techniques avancées.
Valeur commerciale et analyse des données structurées
Les données structurées apportent une valeur commerciale significative, car leur format cohérent et filtrable facilite l'analyse des données avec un prétraitement minimal, permettant aux organisations d'effectuer des calculs, de créer des modèles et de comparer efficacement les tendances. Les données structurées constituent la base de l'analytique d'entreprise, offrant des requêtes rapides, une intégrité des données élevée et des résultats fiables sur lesquels les organisations peuvent compter pour la planification quotidienne et stratégique. Cela inclut la BI traditionnelle, telle que le reporting de routine, les prévisions, le monitoring des KPI et les tableaux de bord interactifs qui aident les organisations à suivre les performances et à prendre des décisions pour optimiser les Opérations.
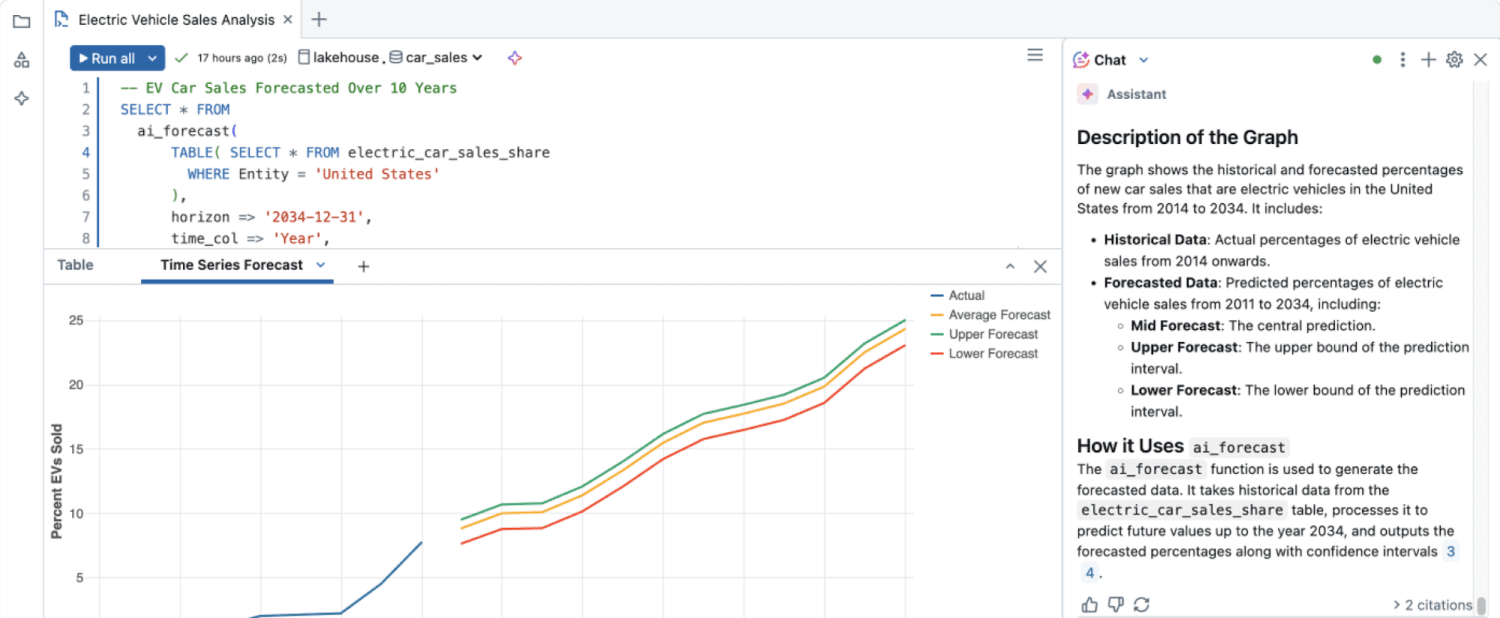
Les données structurées sont également très efficaces pour les modèles de machine learning (ML) et les systèmes automatisés générant des informations avancées telles que des résumés générés par l'IA et l'évaluation du sentiment des clients.
Stockage des données structurées et considérations de scalabilité
Un avantage majeur des datasets structurés est la grande efficacité de stockage grâce à la compression en colonnes. Comme les valeurs d'une même colonne ont tendance à être similaires, les bases de données en colonnes permettent une compression et une lecture efficaces des données, ce qui se traduit par d'importantes économies de stockage et des analytiques plus rapides.
Cependant, les modifications de schéma au sein des données structurées peuvent s'avérer difficiles. Les écosystèmes de bases de données étant fortement connectés et présentant de nombreuses dépendances, des modifications telles que l'ajout, la modification ou la suppression de champs peuvent entraîner des pertes de données, des temps d'arrêt des applications et des défaillances en cascade ailleurs dans le système si elles ne sont pas gérées correctement. Les organisations doivent planifier soigneusement les migrations pour éviter toute disruption.
Données non structurées : caractéristiques, défis et opportunités
Caractéristiques et sources des données non structurées
Les données non structurées sont des informations dans leur format natif. Contrairement aux données structurées qui sont organisées en lignes et en colonnes, les données non structurées n'ont pas de structure prédéfinie, ce qui les rend plus difficiles à explorer et à analyser.
Les données sous leur forme non structurée peuvent être générées par des machines (telles que les données GPS, les fichiers journaux et d'autres informations de télémétrie) ou par l'homme. Les exemples de données non structurées générées par l'homme incluent les publications sur les réseaux sociaux, les fichiers audio, les fichiers vidéo, les e-mails, les fichiers multimédias et les documents texte.
Les données non structurées représentent 80 % à 90 % de la croissance des données d'entreprise. Ce type de données peut offrir des insights précieux dans des domaines tels que les tendances du marché, le sentiment des clients et les problèmes opérationnels, mais l'extraction de ces insights peut être difficile par rapport au travail avec des données structurées.
Défis et solutions de l'analyse des données non structurées
Les insights sur les données non structurées sont restés largement inexploités jusqu'à la création d'analyses de données avancées telles que les algorithmes de ML, le traitement du langage naturel (NLP) et l'analyse des sentiments, qui peuvent extraire automatiquement le sens de grands volumes de données non structurées.
Généralement, les organisations ont besoin de data scientists pour gérer, traiter et extraire des modèles pertinents à partir de données non structurées à l'aide de techniques avancées. Les data lake sont couramment utilisés pour consolider les données non structurées dans leur format natif et brut, offrant un stockage flexible pour de grands volumes. Les data lakes permettent de transformer des données brutes en données structurées utilisables par vos activités d'analytique SQL, de data science et de machine learning avec une faible latence. Les lacs de données peuvent également conserver les données brutes indéfiniment à faible coût pour une utilisation future en ML et en analytique.
Cependant, les lacs de données peuvent facilement dégénérer en « marais de données » (data swamps) en raison de problèmes de fiabilité, de performance et de gouvernance. Les lacs de données traditionnels ne suffisent pas à eux seuls pour répondre aux besoins d'innovation des entreprises, c'est pourquoi elles opèrent souvent dans des architectures complexes, avec des données cloisonnées dans différents systèmes de stockage.
Le stockage Lakehouse unifie la gestion des données structurées et non structurées pour relever les défis posés par les lacs de données. Les Lakehouses implémentent des structures et des fonctionnalités de gestion similaires à celles des data warehouses directement sur le stockage de données à faible coût d'un data lake, combinant l'ouverture des data lakes avec les fonctionnalités de gestion et de fiabilité des data warehouses. Cette structure garantit que les entreprises peuvent tirer parti de différents types de données pour les projets de Data Science, de ML et d'analytique commerciale.
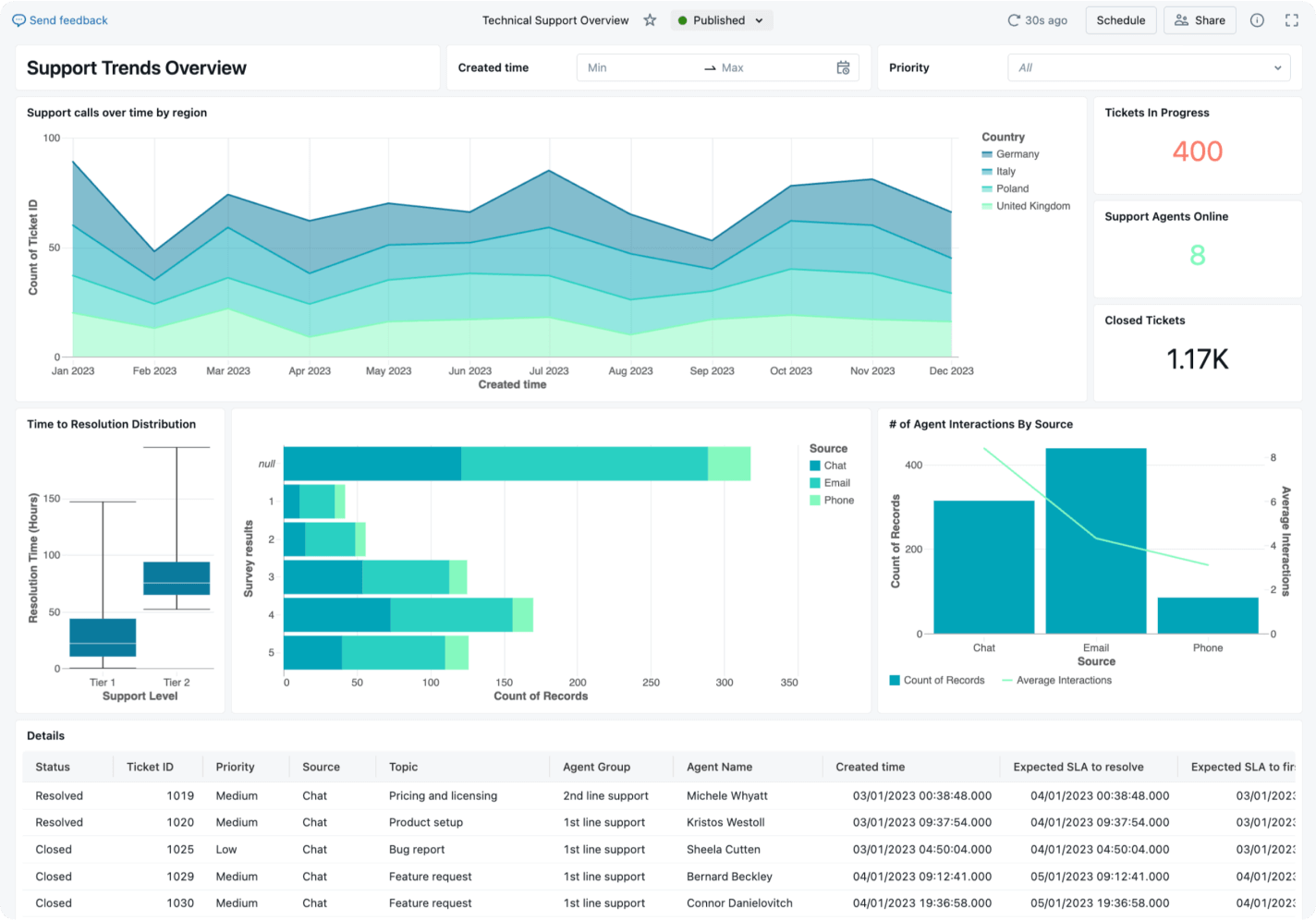
Dégager de la valeur commerciale à partir des données non structurées
Les données non structurées contiennent des informations riches que les techniques d'analyse traditionnelles ne peuvent pas facilement interpréter. Les capacités de machine learning permettent de traiter le contenu non structuré à grande échelle, en identifiant des modèles, des thèmes, des sentiments et des anomalies qui resteraient autrement cachés. En utilisant des techniques telles que le NLP et la computer vision, les organisations peuvent transformer des données qualitatives en insights exploitables pour éclairer leurs décisions.
Par exemple, pour améliorer le service client, les organisations peuvent utiliser l'IA pour analyser diverses sources, notamment les avis sur les produits, les transcriptions des centres d'appels, les mentions sur les réseaux sociaux et les conversations avec les chatbots. Les modèles identifiés peuvent être utilisés pour révéler des opportunités de résoudre des problèmes, d'accroître l'efficacité et de stimuler l'innovation afin d'améliorer l'expérience client.
Principales différences entre les données structurées et non structurées et cadre de décision
Comprendre les différences entre les données structurées et non structurées est essentiel pour concevoir des architectures de données efficaces et choisir des méthodes d'analyse appropriées. Chaque type présente des atouts et des défis uniques qui doivent être pris en compte dans la stratégie de données d'une organisation.
Axes de comparaison essentiels
- Format des données : Les données structurées sont organisées dans un format fixe et prédéfini. Chaque enregistrement utilise le même ensemble de champs et de types de données, de sorte que tout reste cohérent. Les données non structurées sont stockées dans leur format brut et natif sans structure uniforme, ce qui les rend plus flexibles, mais plus difficiles à organiser et à analyser.
- Outils d'analyse : Les données structurées peuvent facilement être interrogées à l'aide de SQL et intégrées dans des outils de Business Intelligence standard. Les données non structurées nécessitent des méthodes d'analyse plus avancées, notamment le ML, le NLP et la vision par ordinateur. Celles-ci sont généralement gérées par des data scientists ou des analystes spécialisés.
- Stockage : les données structurées s'intègrent naturellement dans les entrepôts de données (data warehouses), qui sont optimisés pour les requêtes relationnelles et les performances. Les données non structurées sont mieux adaptées aux lacs de données (data lakes), qui permettent aux organisations de stocker des données brutes à grande échelle, ou aux architectures lakehouse hybrides.
- Temps de traitement : Les données structurées étant déjà organisées, elles peuvent souvent être analysées immédiatement avec une préparation minimale. Les données non structurées nécessitent généralement un prétraitement important — comme le nettoyage, la tokenisation, l'étiquetage et l'extraction de caractéristiques — avant que des insights pertinents puissent être générés.
- Accessibilité pour les utilisateurs : les données structurées sont accessibles à un large éventail d'utilisateurs, y compris les analystes métier et les décideurs qui peuvent les explorer via des tableaux de bord et des outils de reporting. Les données non structurées requièrent généralement l'expertise de data scientists ou d'ingénieurs pour les convertir en formats utilisables et en extraire des informations exploitables.
Données semi-structurées et approches modernes
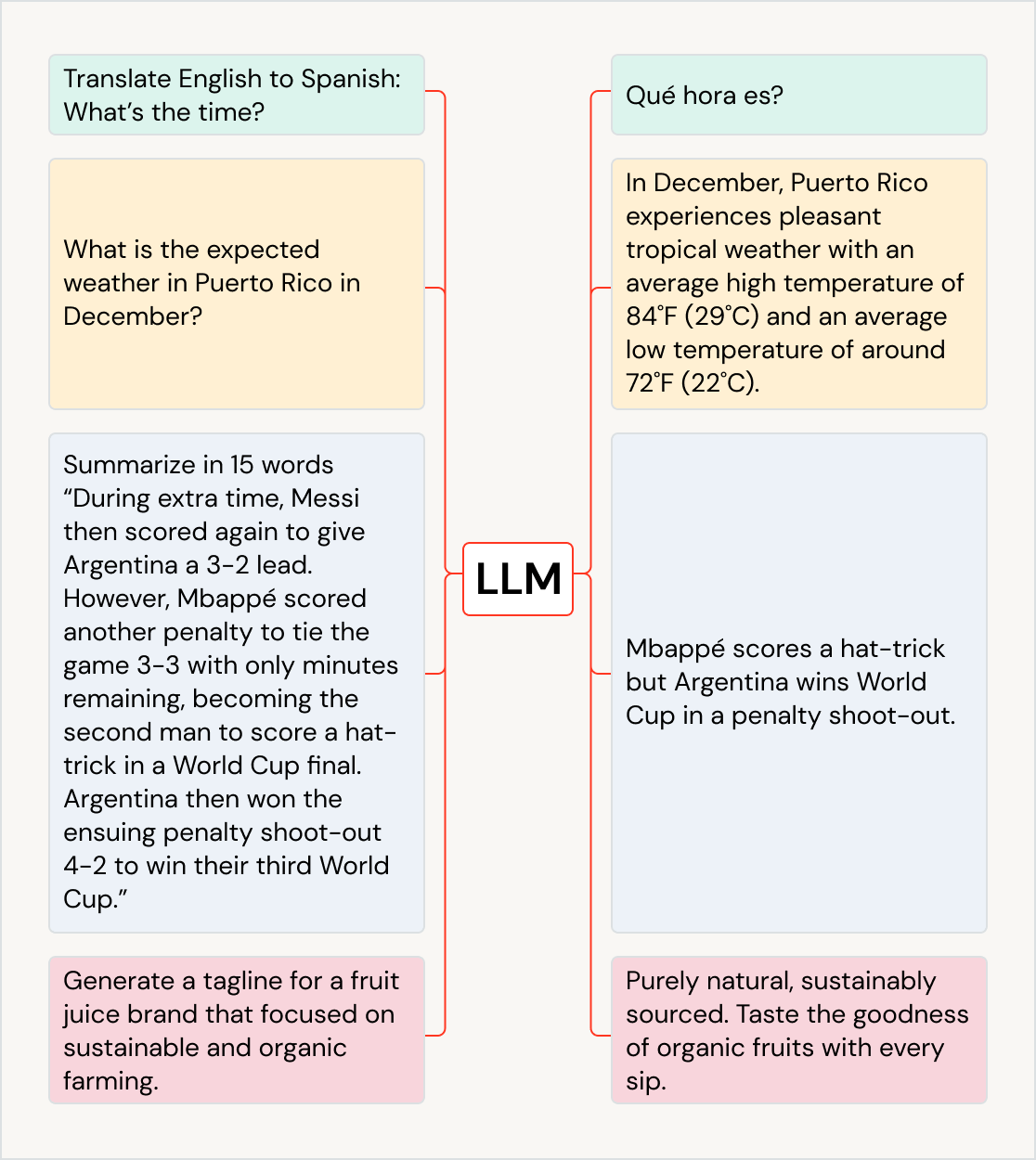
Le juste milieu hybride
Les données structurées et non structurées ne sont pas les seuls formats que les organisations doivent gérer. Les données semi-structurées comblent le fossé entre les deux, en utilisant des balises de métadonnées pour ajouter une certaine organisation tout en autorisant des champs flexibles et évolutifs. Les fichiers JSON, XML et CSV en sont des exemples courants. Les organisations utilisent souvent des bases de données NoSQL et des systèmes de fichiers modernes pour gérer ce type de données, car ils prennent en charge des schémas flexibles et s'adaptent plus facilement à l'évolution des formats de données.
La plupart des entreprises ont besoin de tous les types de données. Elles adoptent donc des stratégies de stockage hybrides qui combinent les atouts des différentes approches de données. L'architecture lakehouse moderne élimine le besoin de choisir entre les data lakes et les data warehouses en combinant leurs capacités en une seule plateforme. Unity Catalog de Databricks offre une gouvernance unifiée et ouverte pour toutes les données structurées, les données non structurées, les métriques commerciales et les modèles d'IA sur n'importe quel cloud. Cela permet aux organisations de gouverner, découvrir, surveiller et partager des données en un seul endroit, ce qui rationalise la conformité et accélère l'obtention d'insights.
Conclusion
Une stratégie de données n'est pas une solution universelle. Comprendre les différences entre les données structurées, non structurées et semi-structurées est essentiel pour mettre en place une gestion de données efficace. Les organisations ont besoin de l'expertise nécessaire pour faire correspondre les types de données à leurs besoins analytiques spécifiques et à leurs exigences métier. En alignant les choix de données sur leurs cas d'usage uniques, les entreprises peuvent obtenir des insights, améliorer la prise de décision et maximiser l'impact de leurs investissements dans les données.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.