Utilisation de MemAlign pour améliorer l'évaluation du machine learning traditionnel dans le code Genie
Combler l'écart entre les juges LLM et les experts humains grâce à MemAlign et MLflow.
par Stepan Nosov, Pavle Martinović, Tejas Sundaresan, Alkis Polyzotis et Nemanja Petrovic
- Genie Code génère des notebooks ML complets à partir de prompts en langage naturel — nous avons conçu neuf juges LLM pour évaluer leur qualité sur des aspects tels que l'entraînement de modèles, l'imputation de données et l'ingénierie des caractéristiques.
- L'annotation humaine a révélé que les juges divergeaient des experts jusqu'à 0,68 MAE sur une échelle de 3 points. MemAlign, un framework d'alignement open-source dans MLflow, a comblé cet écart en utilisant seulement environ 50 exemples étiquetés.
- Sur les trois dimensions les moins bien alignées, MemAlign a réduit l'erreur des juges de 74 à 89 %, et une étude complémentaire a montré que les mémoires sémantique et épisodique sont toutes deux essentielles à ce résultat.
Annoncé en mars, Genie Code est le partenaire d'IA autonome de Databricks, conçu spécialement pour la science des données et le machine learning. Il aide les équipes de données à réaliser des analyses exploratoires de données, à créer et valider des features, à entraîner et évaluer des modèles, et à gérer et optimiser les déploiements de modèles.
Ce qui distingue Genie Code, c'est son intégration profonde avec Databricks. Genie Code comprend vos données dans Unity Catalog, votre contexte métier et votre infrastructure ML comme Model Serving. Grâce à ce contexte, il peut fournir des suggestions plus précises, entreprendre des actions plus pertinentes et générer des workflows mieux adaptés à votre entreprise.
Cela soulève une question importante : comment s'assurer que Genie Code utilise efficacement tout ce contexte et génère des résultats conformes aux meilleures pratiques de ML ? Par exemple, il doit savoir quand et comment utiliser des outils comme MLflow pour suivre la qualité des modèles. Comme le code généré dépend grandement du problème que le client cherche à résoudre, évaluer la qualité de ce code est loin d'être simple.
Dans cet article, nous verrons comment nous avons construit un pipeline d'évaluation pour les capacités de ML traditionnel de Genie Code, et comment nous avons utilisé MemAlign, un nouveau framework d'alignement open source dans MLflow, pour combler un écart important entre les juges LLM et les experts humains. Les juges améliorés nous ont permis d'identifier et de corriger des lacunes dans les recommandations de ML de Genie Code que nous aurions autrement manquées.
Construire le framework d'évaluation
Un framework d'évaluation robuste est nécessaire pour :
- Le hillclimbing : quantifier l'impact des changements de prompts, d'outils, de compétences et d'architecture sur les résultats.
- La protection contre les régressions : s'assurer que l'amélioration de l'« entraînement des modèles » ne dégrade pas accidentellement l'« exploration des données ».
- Le benchmarking : mesurer l'impact des différents modèles de fondation (backends LLM) sur la qualité des notebooks.
- La CI : surveiller comment les modifications de la boucle d'agents sous-jacente se répercutent sur les tâches de ML finales.
L'évaluation des notebooks de ML traditionnel est l'une des tâches d'évaluation les plus complexes, car elle englobe l'évaluation de la qualité du code, des meilleures pratiques de ML et des adaptations basées sur les données. Pour gérer une tâche aussi vaste et complexe que l'évaluation de notebooks de ML, nous utilisons un LLM-as-a-judge - un LLM « expert » auquel des humains ont appris à quoi ressemble exactement un bon notebook. Nous avons créé neuf juges qui sont invités à évaluer les notebooks de ML selon neuf dimensions présentes dans la plupart des workflows de ML :
| Dimensions | Ce que nous évaluons |
|---|---|
| Installation des bibliothèques | Installe et importe les bonnes dépendances |
| Analyse exploratoire des données | Explore le jeu de données pour comprendre les distributions, les valeurs manquantes, le comportement de la cible et les problèmes susceptibles d'affecter le modèle |
| Imputation des données | Gère les valeurs manquantes de manière appropriée sans introduire de fuite de données (data leakage). |
| Feature engineering | Sélectionne, transforme et encode les features de manière appropriée pour la tâche. |
| Entraînement du modèle | Entraîne des modèles adaptés en utilisant des pratiques fiables telles que la validation croisée et le réglage des hyperparamètres |
| Utilisation du modèle | Réutilise correctement le modèle entraîné pour générer des prédictions ou effectuer des inférences. |
| Évaluation des métriques | Évalue les performances du modèle à l'aide de métriques utiles pour la tâche de ML. |
| Journalisation MLflow | Suit les expériences, les métriques et les artefacts avec MLflow. |
| Organisation des cellules | Structure le notebook en cellules claires, lisibles et bien documentées. |
Pour chaque dimension, nous avons rédigé des grilles d'évaluation (partagées entre les évaluateurs humains et les juges LLM) qui attribuent une note de 1 à 3, et 0 pour « non applicable » :
- 3 (Bon) : Le notebook répond à des exigences élevées pour une dimension donnée. Il démontre les meilleures pratiques, couvre le périmètre attendu et gère correctement les cas limites.
- 2 (Moyen) : Acceptable mais présente des lacunes. Les bases sont là, mais le notebook manque de raffinements qu'un praticien expérimenté attendrait.
- 1 (Mauvais) : Problèmes fondamentaux. Des étapes clés sont manquantes, incorrectes ou appliquées d'une manière qui mènerait à des conclusions erronées.
- N/A (Non applicable) : Cette dimension ne s'applique pas à ce prompt (par exemple, la dimension d'imputation des données ne peut pas être appliquée si le jeu de données ne contient aucune valeur manquante).
Pour donner une idée de la granularité, voici la grille d'évaluation spécifique que nous utilisons pour la dimension « imputation des données » :
Parallèlement aux juges, nous maintenons un ensemble de cas de test d'évaluation qui couvrent un éventail de tâches de ML (classification, régression, prévision), sur différentes tailles de jeux de données, domaines et niveaux de complexité. Chaque cas de test comprend un prompt utilisateur qui indique à Genie Code la tâche de ML qu'il est censé résoudre sur le jeu de données spécifié (« J'ai des données de vols d'avions dans les tables flight_delays_prediction and flight_deplays_actual. Pouvez-vous prédire quels avions seront en retard demain ? »). La boucle d'évaluation consiste à utiliser Genie Code pour générer un notebook (ou plusieurs) pour chaque cas de test, puis à noter chaque notebook selon toutes les dimensions applicables.
Évaluer le système d'évaluation
En utilisant des juges LLM plutôt que des humains pour évaluer les artefacts de Genie Code, nous avons essentiellement remplacé un problème difficile par un autre : le juge prêt à l'emploi n'est pas qualifié pour la tâche à accomplir et n'est pas aligné avec les évaluations humaines. Notre objectif est de faire en sorte que les scores des juges LLM s'alignent sur ceux des évaluateurs humains.
L'ensemble d'évaluation pour l'estimation du juge LLM contient 50 notebooks générés par Genie Code (« cas de test ») pour lesquels des experts humains ont noté chaque dimension applicable, fournissant à la fois un score et une courte justification pour servir de vérité de terrain (ground truth). Dans les zones grises entre deux scores, les évaluateurs étaient autorisés à exprimer leur propre jugement, mais les schémas ont été rédigés de manière à ce que ce soit rarement le cas.
La mesure de l'alignement homme-machine est l'erreur absolue moyenne (MAE) entre les scores de chaque dimension. Les résultats ont été mitigés, certaines dimensions montrant un alignement fort (4 dimensions avaient une MAE de = 0,10), tandis que d'autres ont révélé un désaccord important :
- Entraînement du modèle : MAE de 0,680
- Utilisation du modèle : MAE de 0,562
- Imputation des données : MAE de 0,474
- Exploration des données : MAE de 0,407
Cet écart existe parce que les humains et les LLM n'interprètent pas la même grille d'évaluation de la même manière. Alors qu'un évaluateur humain peut repérer une stratégie d'imputation subtilement défectueuse ou une boucle d'entraînement qui « fonctionne » mais qui est logiquement incorrecte, un juge LLM passe souvent à côté de cette nuance technique. Nous avons également constaté que le juge souffrait d'un biais de positivité classique : il était tout simplement trop « poli », ce qui l'empêchait d'obtenir des résultats objectifs.
Il est devenu tout à fait clair qu'avec la même grille d'évaluation, les juges LLM et les humains ne produiraient pas les mêmes résultats : un désalignement. C'est précisément le scénario que MemAlign a été conçu pour résoudre.
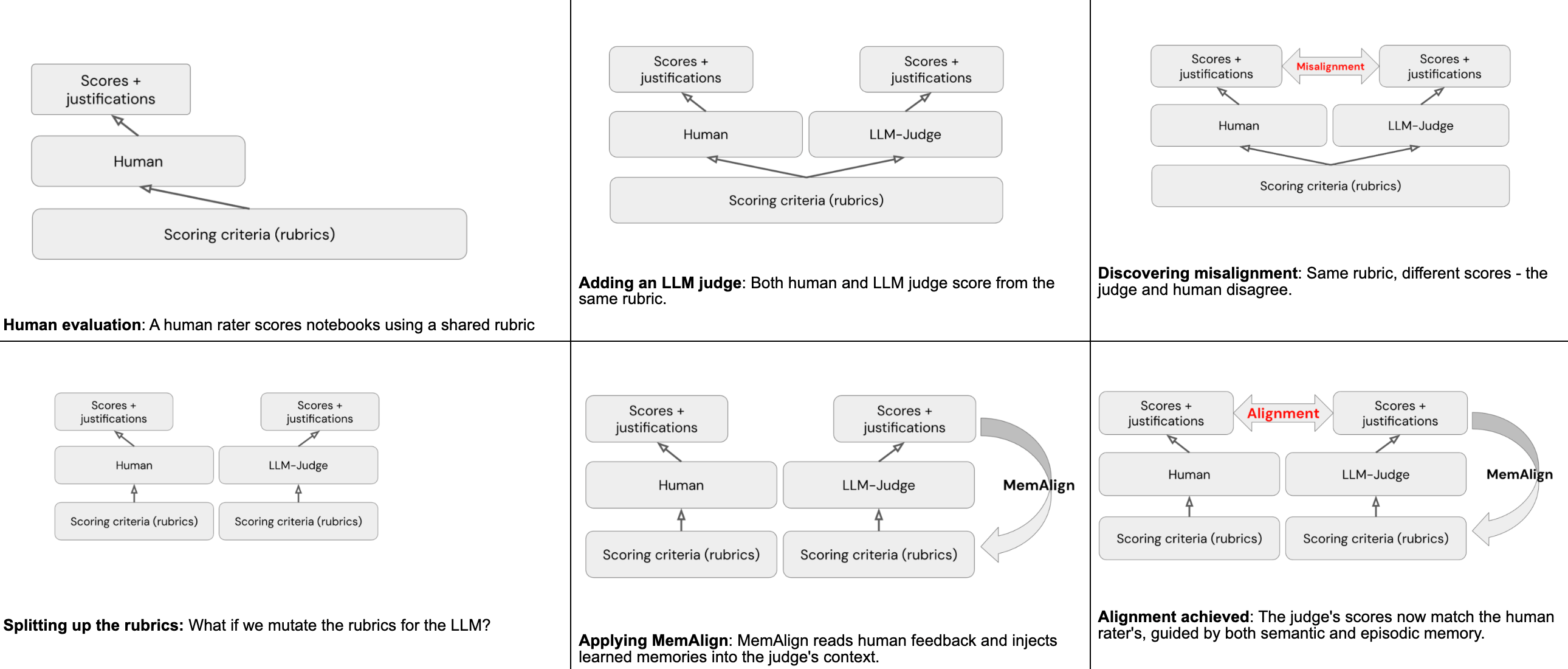
Utiliser MemAlign pour l'alignement
MemAlign est un framework au sein de MLflow qui peut, à partir d'une très petite quantité de retours humains en langage naturel, réaliser l'alignement entre les évaluateurs humains et les juges LLM. Ceci est rendu possible grâce à deux types de « mémoires » formées à partir de la lecture des retours humains :
- La mémoire sémantique stocke des directives généralisées : des règles tirées des retours qui s'appliquent de manière générale
- La mémoire épisodique stocke des exemples spécifiques : des cas où le juge s'est trompé, conservés comme points d'ancrage pour les décisions futures
Au moment de l'inférence, MemAlign construit un contexte de travail en extrayant toutes les directives sémantiques et en récupérant les exemples épisodiques les plus pertinents pour l'entrée actuelle. Le juge charge tous ces éléments dans son contexte, ainsi que la grille d'évaluation d'origine, et utilise les connaissances accumulées pour attribuer un score plus précis à tous les futurs notebooks.
La propriété clé qui a permis à MemAlign de se démarquer est sa haute performance avec seulement un petit nombre d'exemples. En effet, MemAlign distille efficacement l'apprentissage à partir de signaux d'apprentissage riches dans les retours en langage naturel, et les intègre dans le système de double mémoire.
Voici un exemple de quelques extraits de mémoire sémantique générés pour la dimension « imputation des données », comblant les lacunes de la grille d'évaluation que nous avons définie précédemment en fournissant généralement des points d'ancrage, des exemples et des contre-exemples :
De plus, comme mentionné précédemment, la mémoire sémantique reflétée dans le prompt est complétée par des exemples pertinents de la mémoire épisodique du juge au moment de l'évaluation, donnant ainsi au juge encore plus de contexte pour interpréter les instructions optimisées.
Conception de l'expérience
Validation croisée K-Fold
Suivant le paradigme d'entraînement-test du ML, nous avons appliqué une validation croisée K-fold (K=4) sur 50 cas de test (notebooks), évitant ainsi la fuite de données et la nécessité de labelliser un ensemble de test distinct. Pour chaque pli, nous avons procédé comme suit :
- Phase d'entraînement : MemAlign a aligné le juge en utilisant les traces des autres plis pour obtenir le juge.
- Phase d'évaluation : Évaluation des notebooks dans le pli i avec le juge.
Bootstrapping des intervalles de confiance
Pour calculer les intervalles de confiance sans données labellisées supplémentaires, nous avons généré 100 échantillons bootstrappés avec remplacement à partir des 50 d'origine. En répétant cette opération 10 000 fois et en suivant la MAE entre les scores humains et machine, nous avons calculé les intervalles de confiance pour l'alignement homme-machine avec un CI à 95 % définissant un changement statistiquement significatif.
Implémentation
Le pipeline d'évaluation est implémenté sous la forme d'un unique extrait MLflow qui orchestre l'ensemble du processus :
L'optimiseur MemAlign est capable d'aligner les juges LLM en se basant sur les traces des cas de test en seulement quelques lignes de code. Nous avons utilisé ce nouveau juge « aligné » pour calculer la nouvelle MAE. L'alignement d'un juge sur une seule dimension prend environ 25 secondes par pli, de sorte que l'alignement lui-même ne constitue pas un goulot d'étranglement.
Résultats
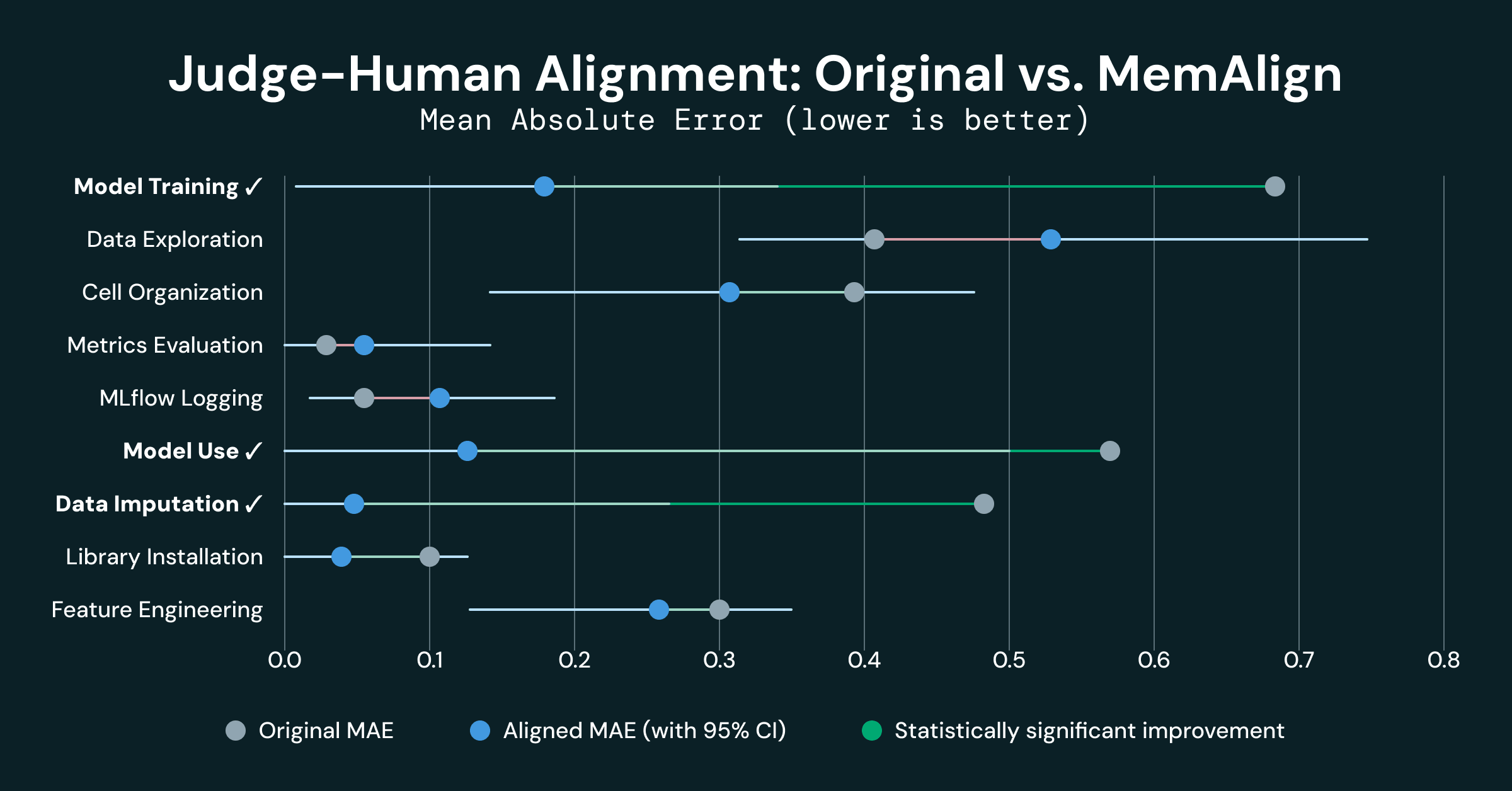
Trois des 9 dimensions ont montré une amélioration statistiquement significative :
- L'entraînement du modèle s'est amélioré de 0,500 MAE (0,680 → 0,180), soit une réduction de 74 %
- L'utilisation du modèle s'est améliorée de 0,438 MAE (0,562 → 0,125), soit une réduction de 78 %
- L'imputation des données s'est améliorée de 0,421 MAE (0,474 → 0,053), soit une réduction de 89 %
Ces 3 dimensions font partie des 4 dimensions initiales qui étaient fortement désalignées. Un faible alignement initial indique que les LLM et les humains ont une compréhension fondamentalement différente des grilles d'évaluation partagées, et la mémoire injectée par MemAlign semble fournir suffisamment de contexte pour les mettre « sur la même longueur d'onde ».
- L'évaluation des métriques et la journalisation MLflow étaient déjà bien alignées (MAE 0,10 à l'origine), et leur dégradation n'est pas statistiquement significative (bruit de l'expérience)
- L'exploration des données a montré une légère régression (-0,130), mais non statistiquement significative compte tenu de son intervalle de confiance [-0,33, +0,09]. Cette dimension présentait la variance inter-évaluateurs la plus élevée, et ce bruit a empêché MemAlign de s'améliorer (et l'a peut-être même entravé).
Expérience avec mémoire sémantique uniquement
La structure à double mémoire de MemAlign nous a amenés à nous demander si toutes deux contribuent réellement à l'alignement du juge. En particulier, la mémoire épisodique est censée aider le juge en lui fournissant un ensemble de notebooks annotés les plus similaires comme point de référence (en utilisant la recherche des plus proches voisins). Mais que se passe-t-il si les notebooks récupérés (les plus proches voisins) ne sont pas réellement similaires au notebook actuel, mais simplement les moins dissemblables ? Charger ces éléments dans le contexte du juge pourrait compliquer les choses plutôt que de les aider. L'espace de problème que nous évaluons (les notebooks de ML) est très large, et nous avions initialement émis l'hypothèse qu'un ensemble de 50 notebooks ne suffirait tout simplement pas à obtenir un ensemble de souvenirs suffisamment dense pour que le juge puisse s'en souvenir.
Sans mémoire épisodique, le tableau se dégrade considérablement :
- L'entraînement du modèle s'améliore toujours (+0,420), mais le gain est plus faible que les +0,500 obtenus avec le MemAlign complet, et la MAE alignée est de 0,260 contre 0,180.
- L'utilisation du modèle perd totalement sa signification statistique : l'amélioration passe de +0,438 à +0,294, l'intervalle de confiance franchissant désormais le zéro.
- L'imputation des données passe d'une réduction d'erreur de 89 % à une amélioration nulle : la MAE alignée est égale à la MAE d'origine (0,455).
- La journalisation MLflow et l'évaluation des métriques régressent en réalité de manière significative. Sans exemples épisodiques pour ancrer le juge, les directives distillées seules introduisent du bruit dans des dimensions qui étaient déjà bien calibrées, faisant passer la journalisation MLflow de 0,062 à 0,396 MAE.
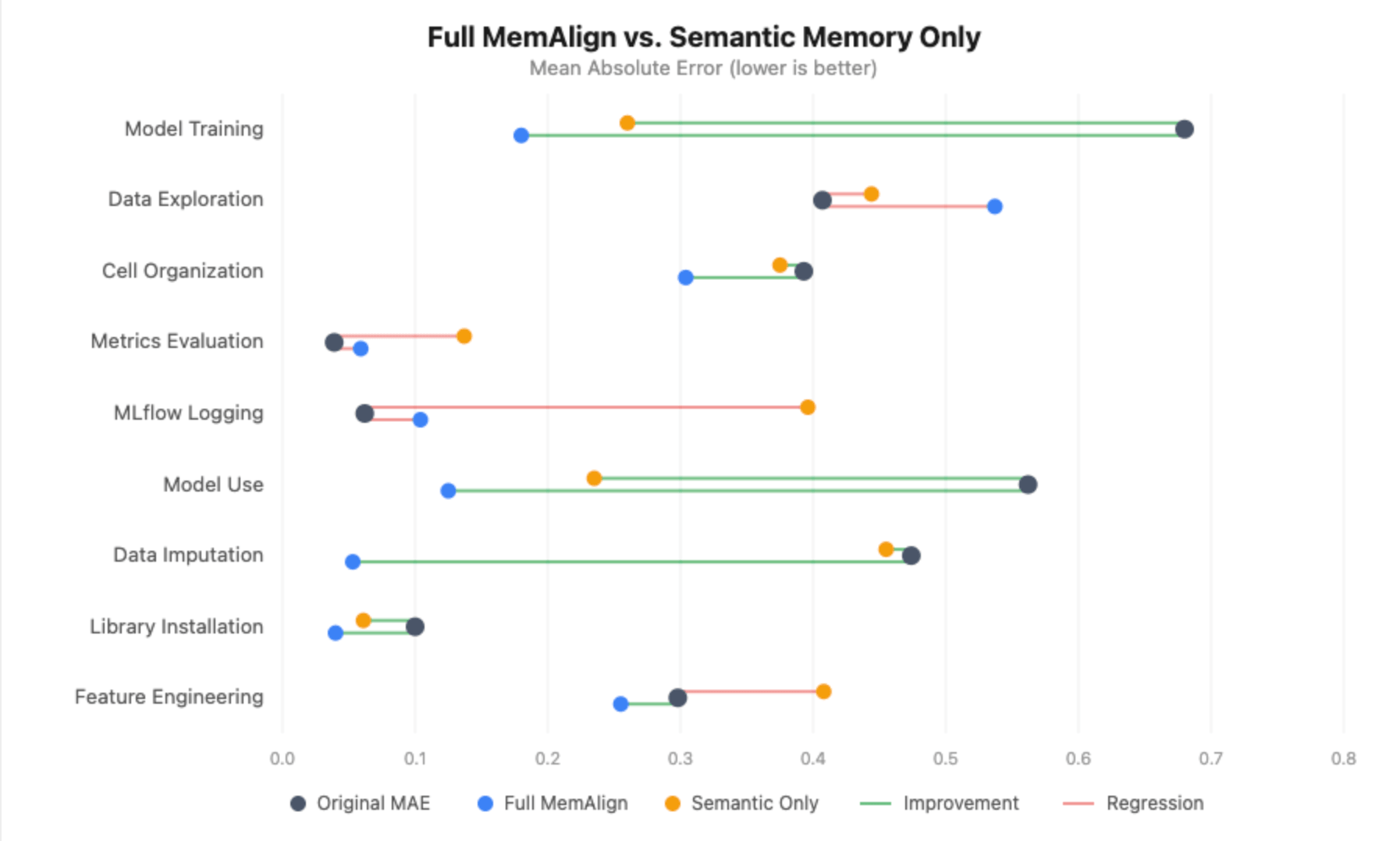
C'était le contraire de ce à quoi nous nous attendions. Nous avions initialement émis l'hypothèse que notre ensemble annoté clairsemé finirait par dérouter le juge, mais presque toutes les dimensions se sont dégradées sans mémoire épisodique. La seule exception a été l'exploration des données, où la suppression des exemples épisodiques a peut-être réellement aidé : sans les notebooks spécifiques sur lesquels nos annotateurs n'étaient pas d'accord, le juge ne disposait que des directives distillées et d'un signal moins bruité avec lequel travailler.
Ce qu'il faut retenir : même lorsque vos entrées sont volumineuses et désordonnées, la mémoire épisodique améliore encore considérablement les performances du juge. Les mémoires sémantique et épisodique font toutes deux partie intégrante du fonctionnement de MemAlign.
Conclusion : Combler l'écart d'expertise
Juger si un agent de codage fait son travail est déjà assez difficile, tandis qu'évaluer un partenaire d'IA autonome sur la construction et l'exécution de workflows de ML traditionnels se situe à un tout autre niveau de complexité. En raison de l'itération rapide sur les produits d'IA, il n'y a tout simplement pas assez de temps pour que des experts surveillent l'« intégration continue » de l'agent. La seule solution évolutive viable réside dans les juges LLM, mais nous avons toujours besoin d'un jury d'humains pour garder le contrôle sur le juge LLM.
En appliquant MemAlign, nous avons réduit l'erreur du juge de 74 à 89 % sur les dimensions où cela importait le plus. Mais, comme pour tout travail sur le ML/LLM, le résultat dépend de la qualité des informations que vous y introduisez, assurez-vous donc que la labellisation soit compétente.
Points à retenir :
- Mesurez votre système de mesure : Un système bruité n'est pas adapté à l'évaluation, et tant que nous n'avions pas investi le temps et les ressources nécessaires pour valider et améliorer réellement les juges, nous ne pouvions pas faire confiance à notre système d'évaluation.
- Les grilles d'évaluation ne suffisent pas à elles seules : Il existe des différences subtiles entre la façon dont un humain perçoit les instructions et la façon dont un LLM les perçoit. Ces différences doivent être prises en compte, et un outil d'alignement comme MemAlign est un moyen efficace de combler ce fossé.
- La qualité de l'étiquetage > la quantité : Lorsque les annotateurs humains ne sont pas d'accord entre eux (comme nous l'avons constaté dans notre régression d'exploration de données), l'alignement ne dispose d'aucun signal cohérent pour apprendre.
MemAlign est intégré à MLflow et a fonctionné pour nous avec seulement environ 50 exemples étiquetés. Si vos juges LLM ne correspondent pas à vos experts, cela vaut la peine d'y consacrer une après-midi.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.