Une gouvernance unifiée et ouverte pour les données et l
Éliminez les silos, simplifiez la gouvernance et accélérez les insights à grande échelle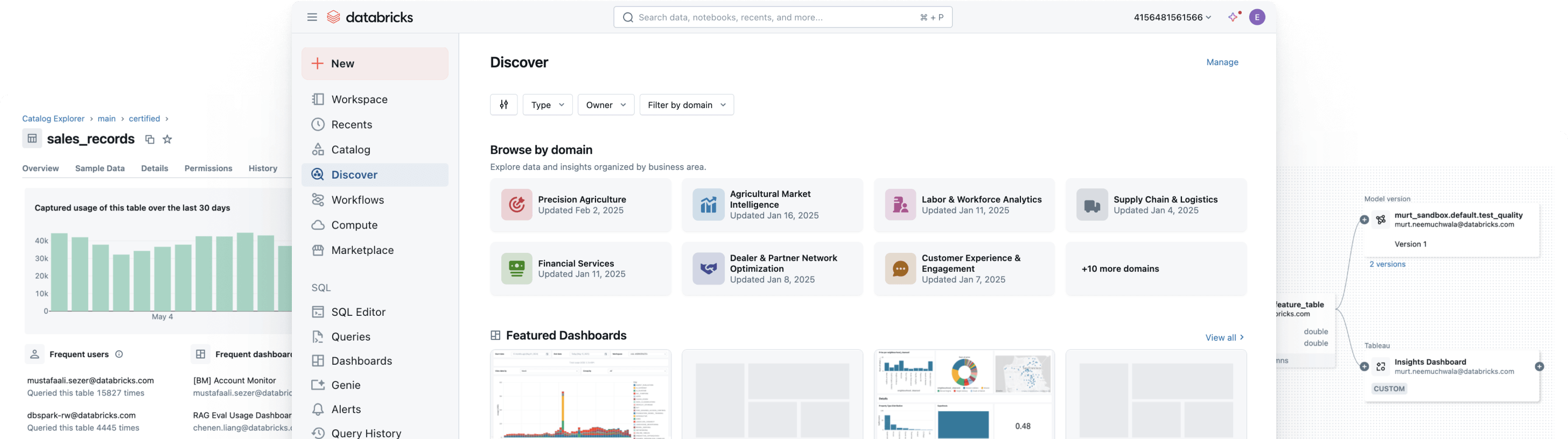
LES MEILLEURES ÉQUIPES RÉUSSISSENT AVEC UNE GOUVERNANCE UNIFIÉE ET OUVERTEEncadrez, découvrez, surveillez et partagez les données, en un seul et même endroit
Unifiez votre paysage de données, simplifiez la conformité et générez plus rapidement des insights fiables en misant sur une gouvernance ouverte et intelligente des données et de l'IAGouvernance unifiée
Mettez en place des contrôles cohérents pour encadrer la découverte, l'accès, la surveillance de la qualité et la conformité cohérents des données structurées et non structurées, des modèles ML et des indicateurs commerciaux, quel que soit le cloud. Une gouvernance unifiée, c'est l'assurance de réduire les risques, de simplifier les audits et d'accélérer l'accès aux données sans faire de compromis sur le contrôle.
Ouvert
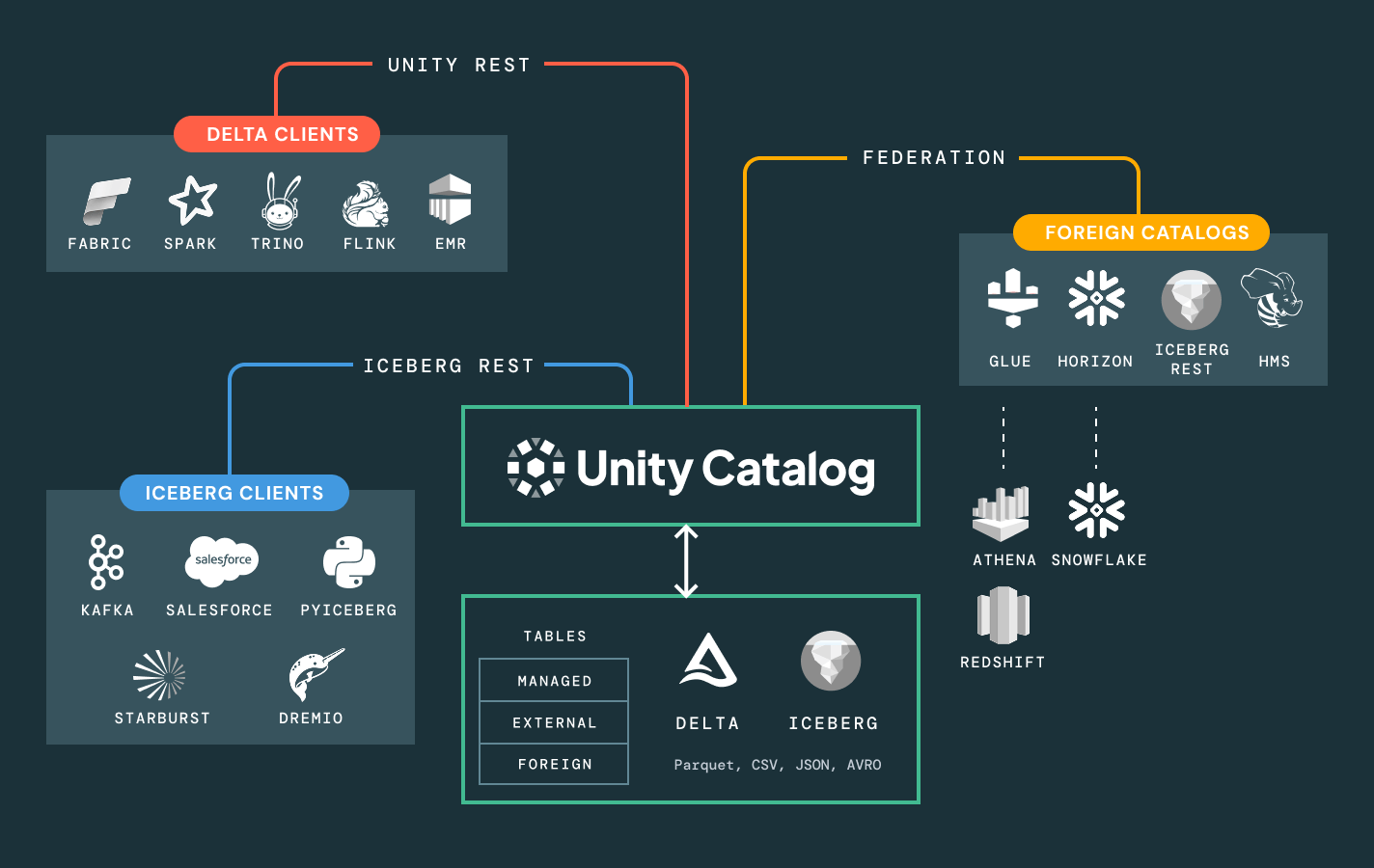
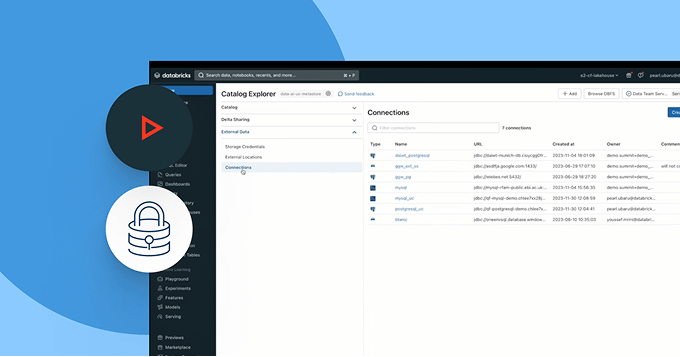
Libérez-vous des contraintes de plateforme. Exploitez tous les formats de lakehouse ouverts qui vous intéressent (Delta, Apache Iceberg™, Hudi, Parquet), connectez des sources de données externes sans migration et intégrez vos outils de BI et d'IA ainsi que votre catalogue grâce à des API ouvertes. Que vous partagiez des données en interne ou avec des partenaires, optez pour une collaboration sécurisée, évolutive et basée sur des normes ouvertes.
Intelligence intégrée
Allez au-delà de la découverte de données et de la gestion des accès : donnez du pouvoir aux utilisateurs grâce au contexte métier. Grâce à l'intégration de la traçabilité, des informations sur l'utilisation et de la sémantique métier, les utilisateurs peuvent trouver, comprendre et explorer les données plus rapidement. La documentation alimentée par l'IA, la recherche en langage naturel et les espaces de conversation aident les utilisateurs techniques et commerciaux à passer des données à la décision plus rapidement, avec l'appui d'un contexte commercial complet.
Gouvernance intelligente intégrée
Simplifiez la découverte, la conformité et la surveillance sur l'ensemble de votre environnement de données et d'IA avec une gouvernance intelligenteUn catalogue unifié pour toutes les données structurées, les données non structurées, les indicateurs commerciaux et les modèles d'IA, englobant des formats de données ouverts comme Delta Lake, Apache Iceberg, Hudi, Parquet et bien d'autres.

Autres fonctionnalités
Libérez toute la valeur commerciale de vos données avec une gouvernance unifiée
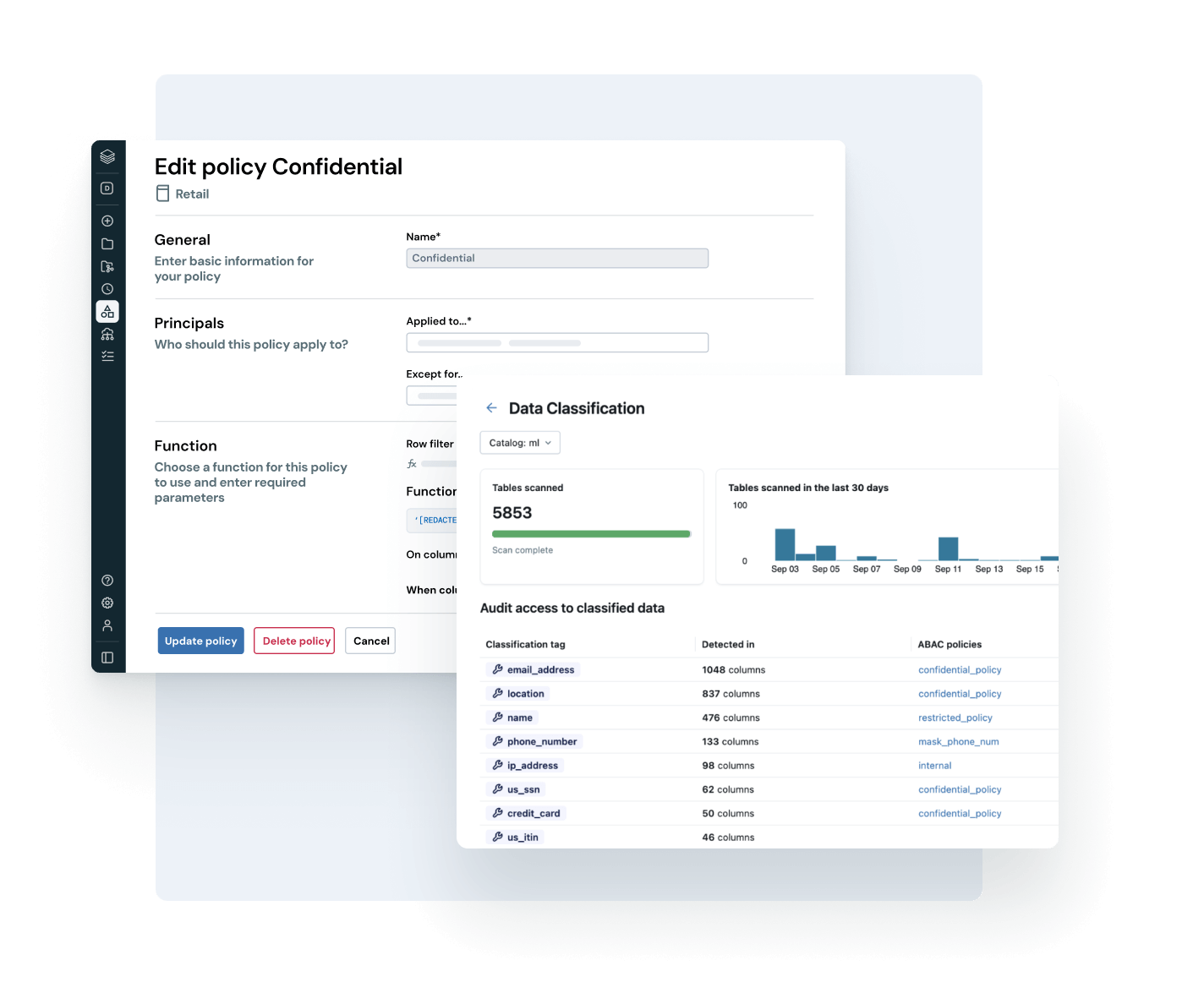
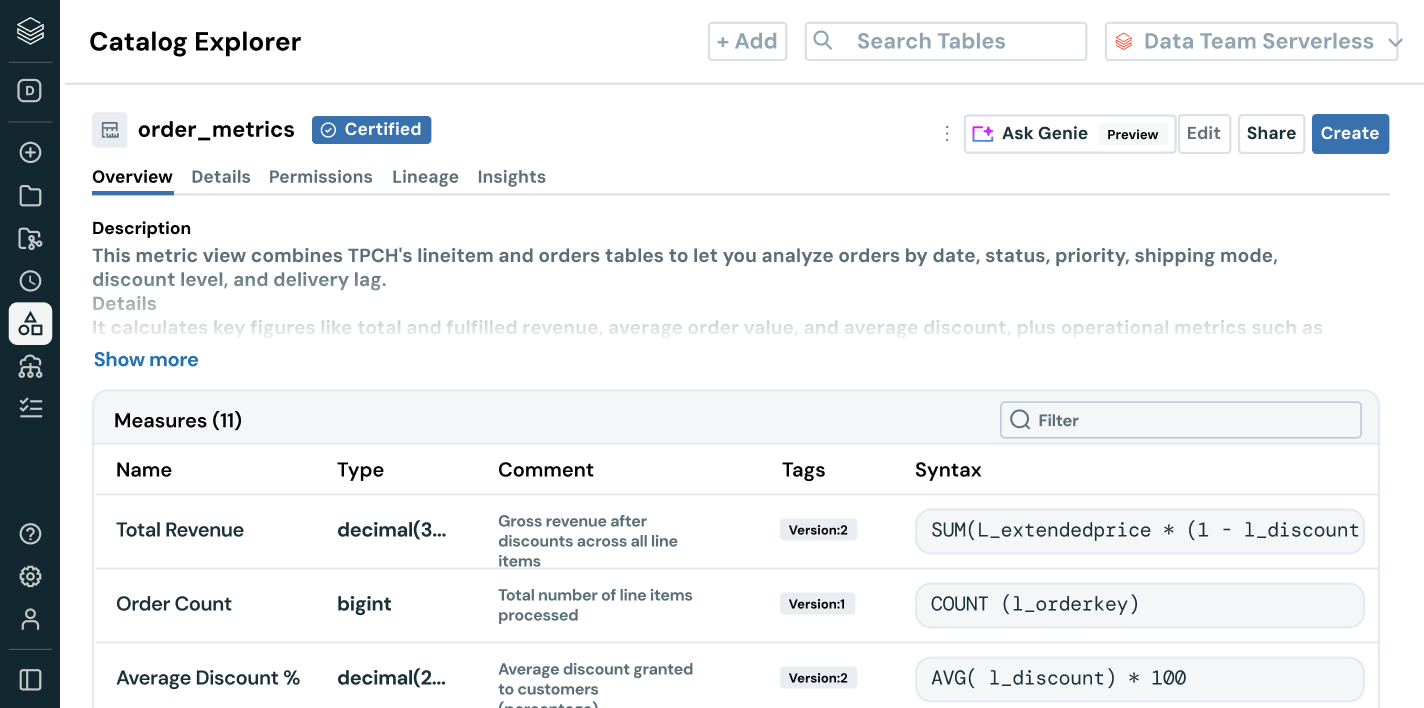
Donnez à chaque utilisateur les moyens de trouver et d'utiliser des données fiables
Rendez vos assets de données les plus précieux faciles à trouver et à comprendre dans toute l'entreprise.
- La découverte avec organisation automatique met en évidence les assets de données fiables et à fort impact
- La documentation, les tags et les insights d'utilisation alimentés par l'IA ajoutent un contexte riche
- La sémantique métier encadrée fournit des métriques cohérentes et fiables à l'ensemble des équipes et des outils
- L'interface conversationnelle d'AI/BI Genie aide les utilisateurs d'entreprise à explorer les données sans SQL
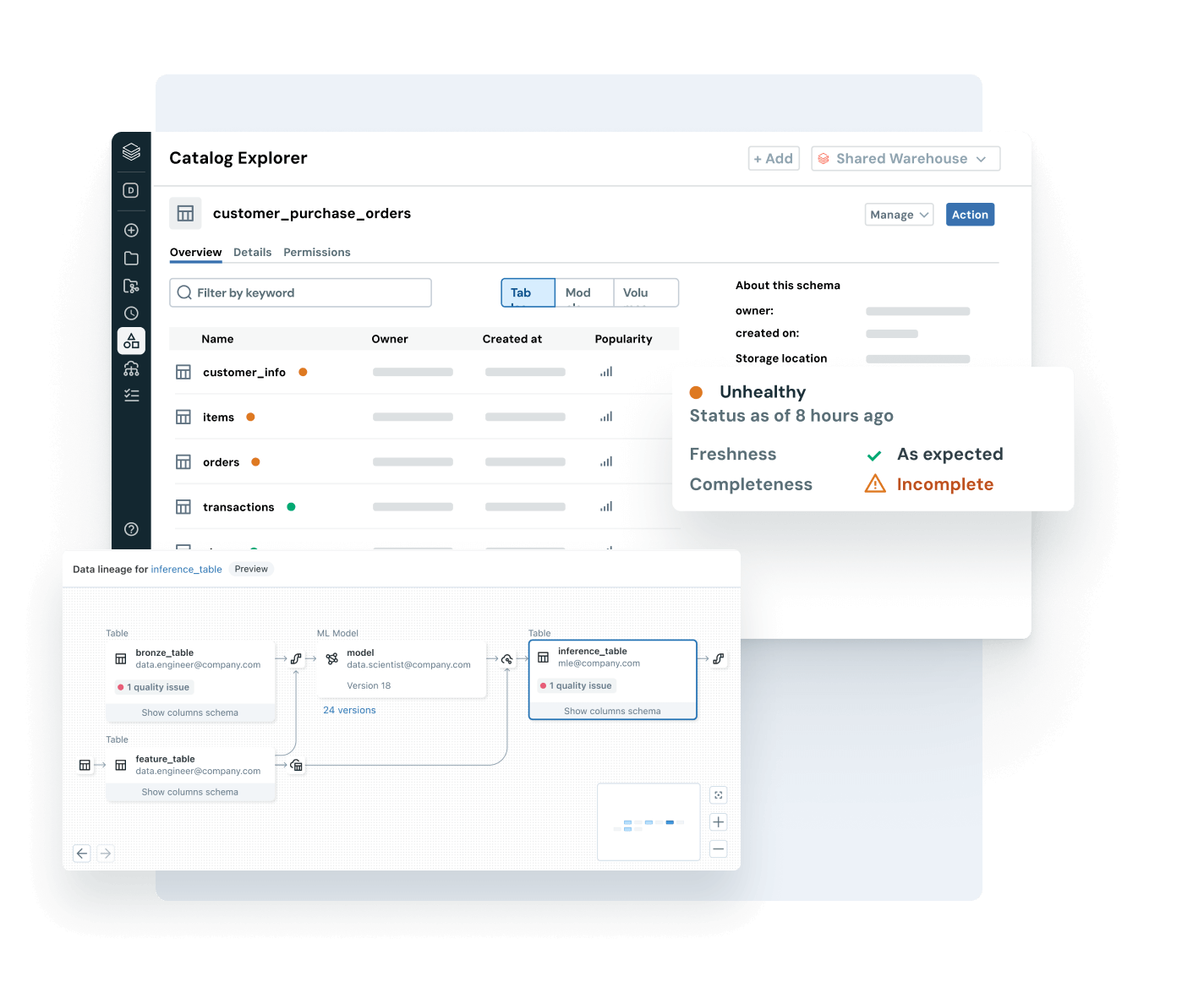
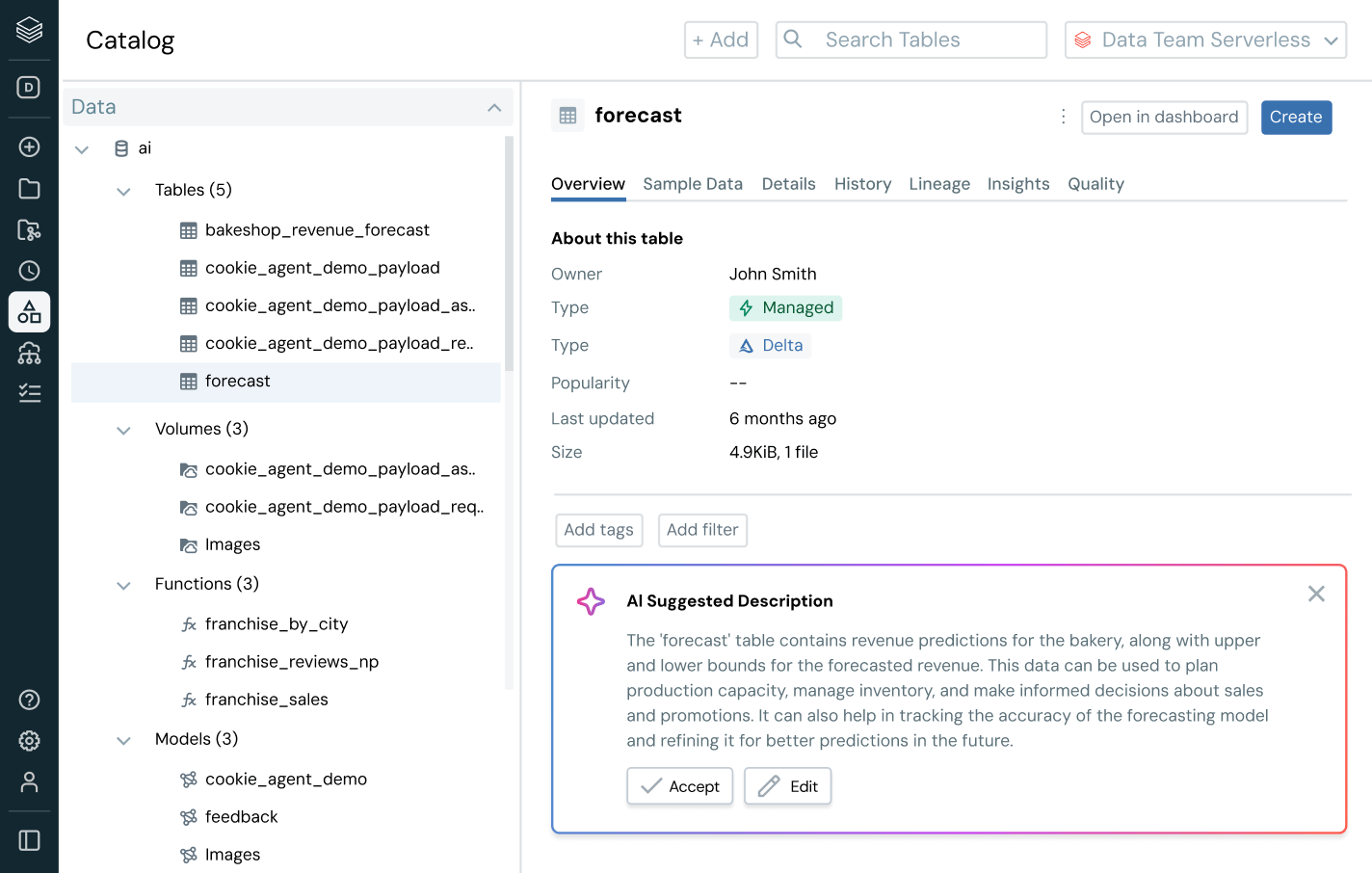
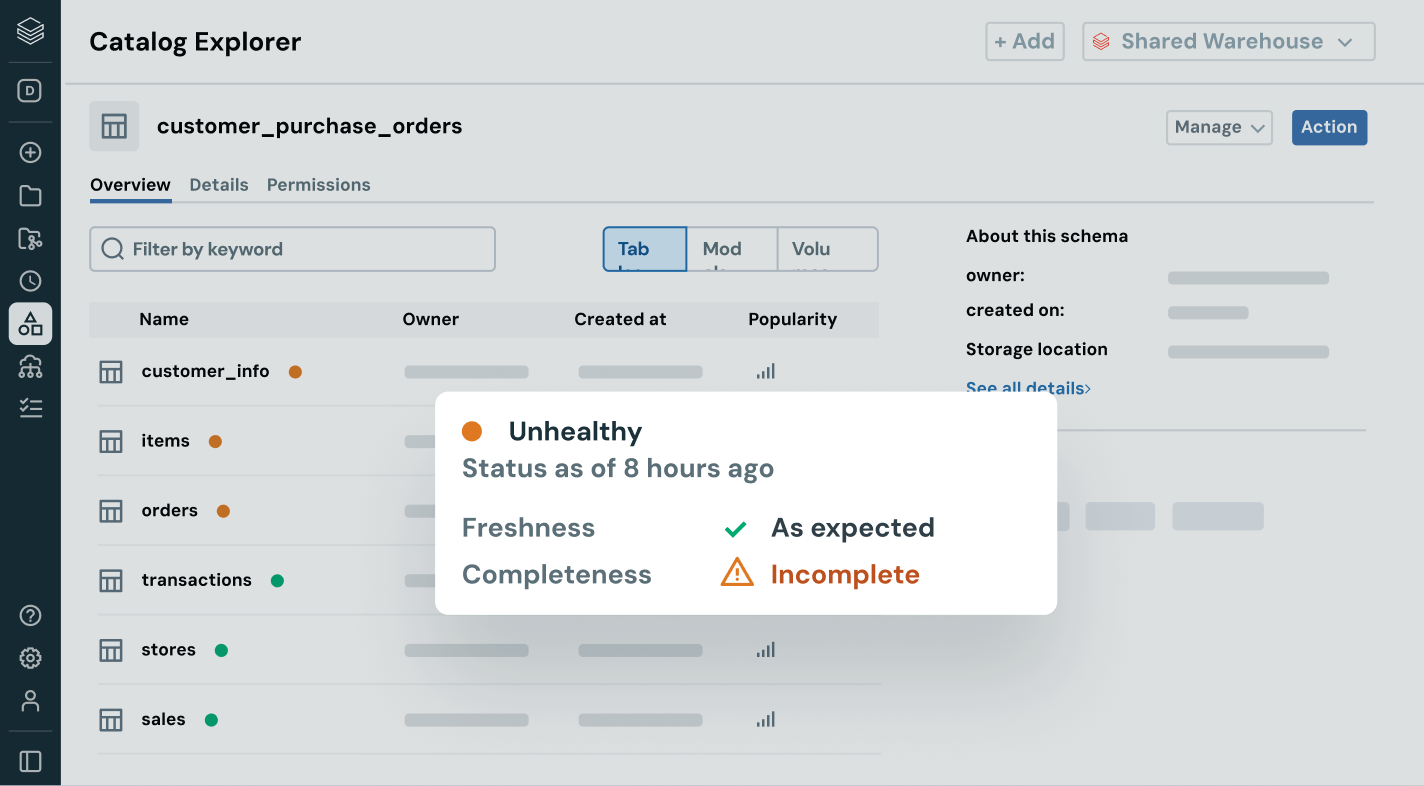
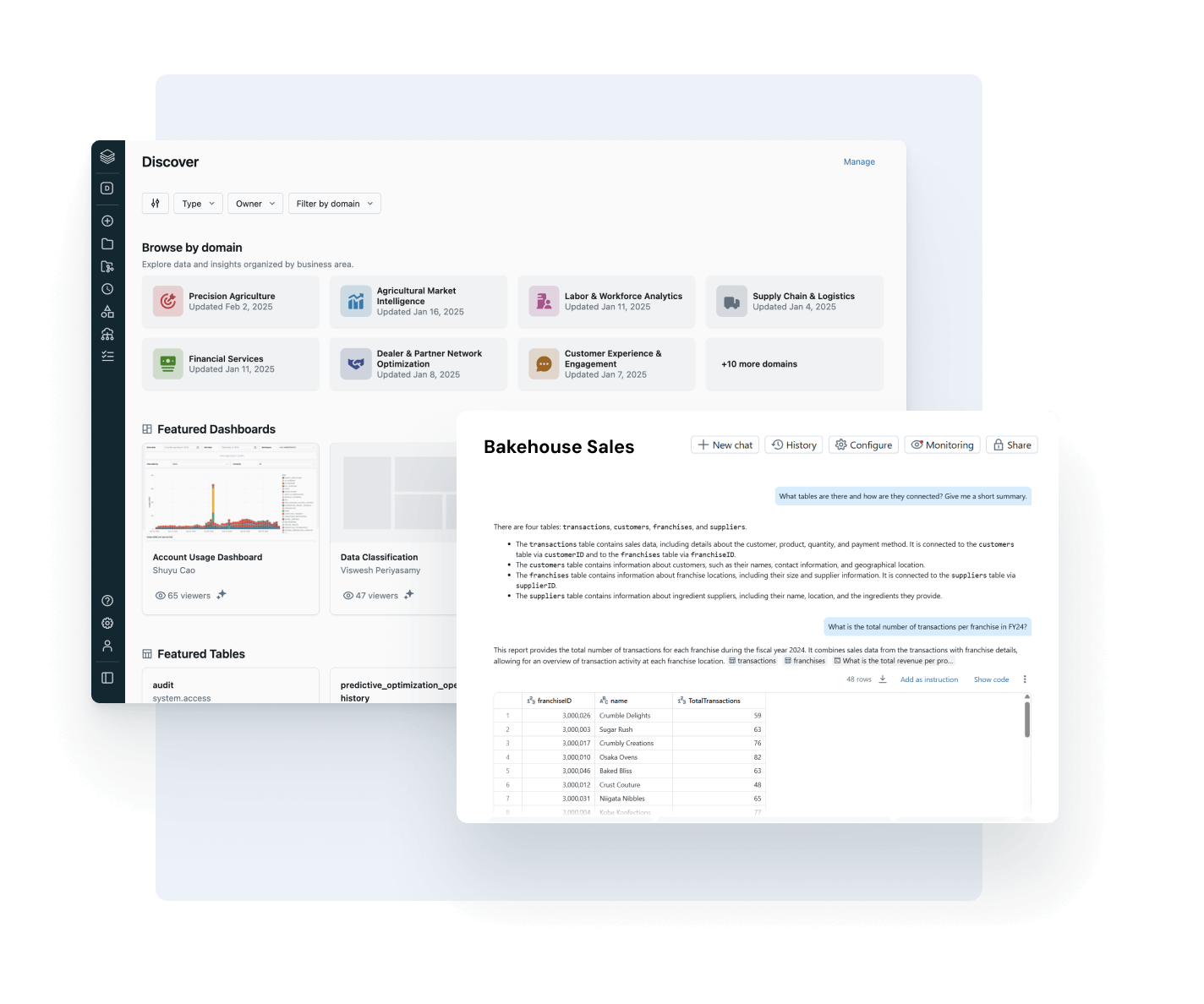
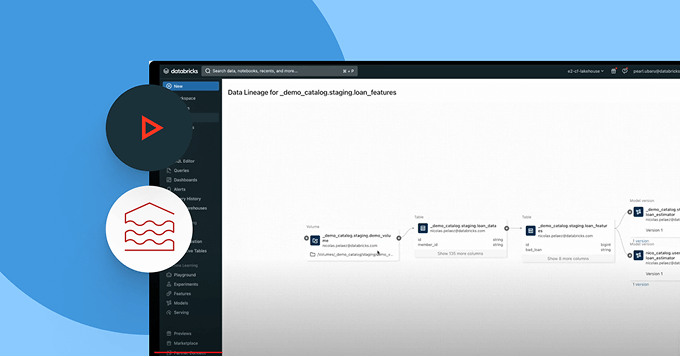
Assurez-vous que les données sur lesquelles vous comptez sont à jour, complètes et dignes de confiance
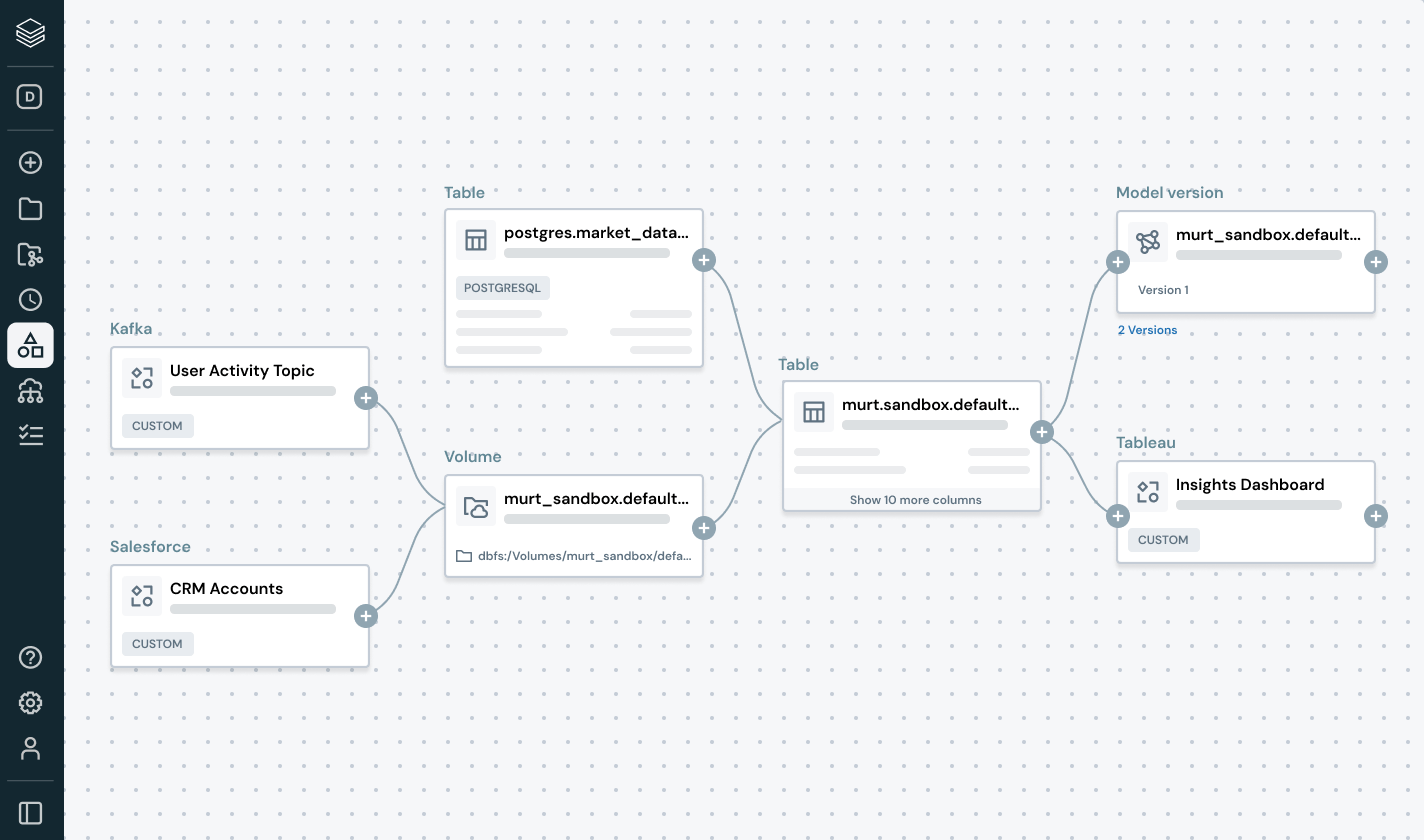
Détectez et résolvez proactivement les problèmes de données avec une visibilité complète sur la traçabilité et les signaux de qualité.
- Surveillez la santé des données grâce aux indicateurs d'obsolescence et d'exhaustivité et à la détection d'anomalies
- Assurez la traçabilité des données de bout en bout à travers les pipelines, les modèles et les tableaux de bord
- Évaluez l'impact en aval des pipelines de données et d'IA défectueux
- Renforcez la confiance en exposant des insights de qualité à côté de chaque asset
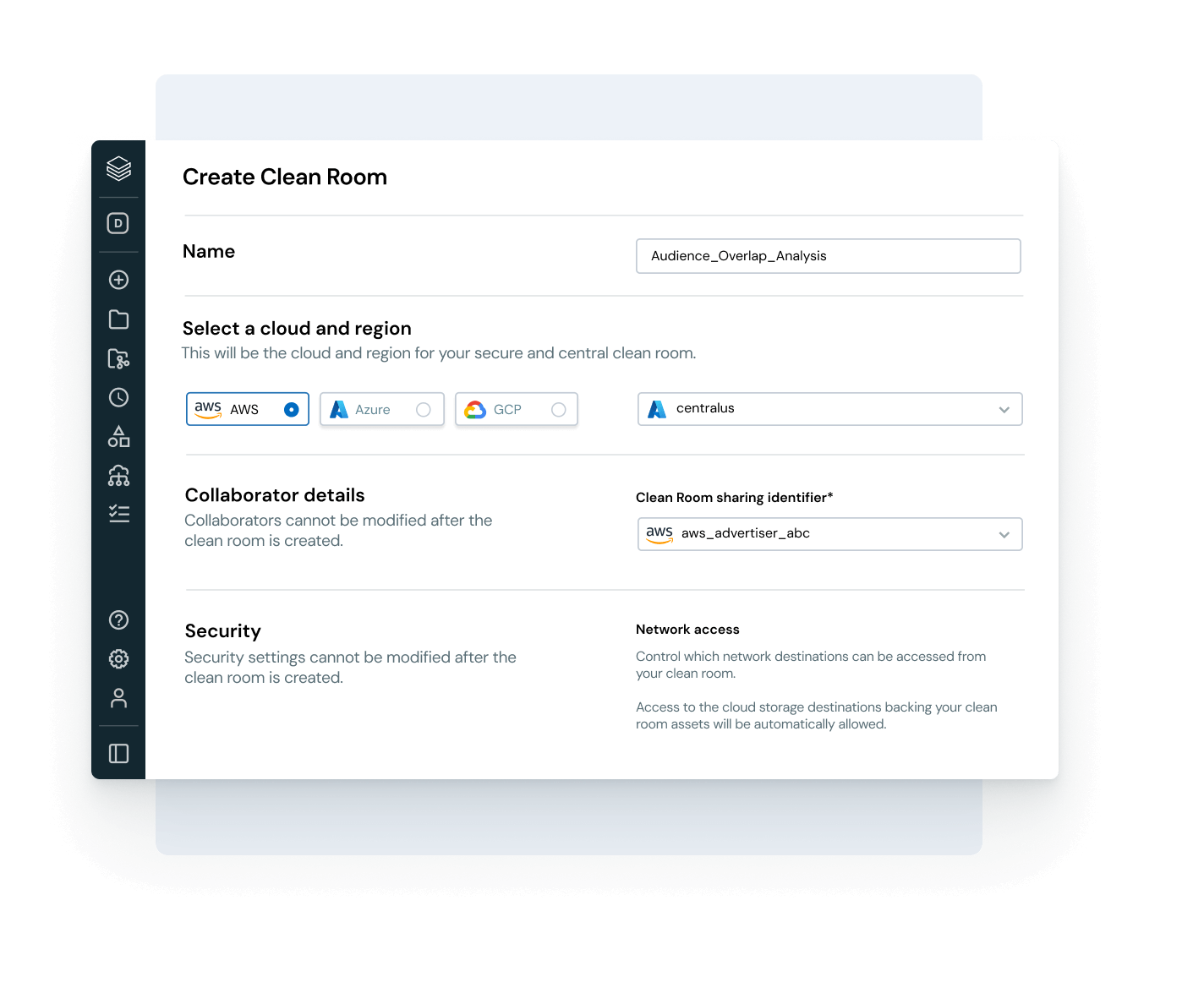
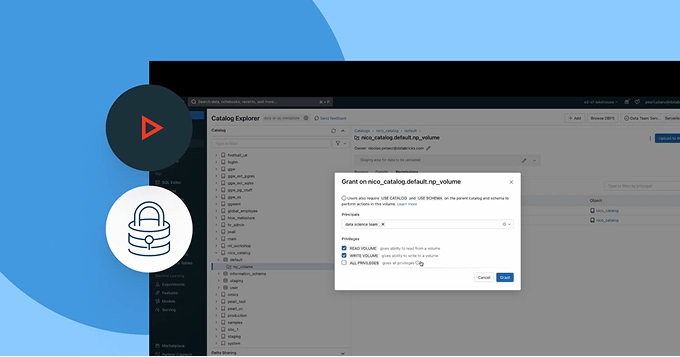
Facilitez une collaboration ouverte et sécurisée avec différents clouds et partenaires
Brisez les silos et développez le partage de données et d'IA, avec un contrôle de gouvernance complet.
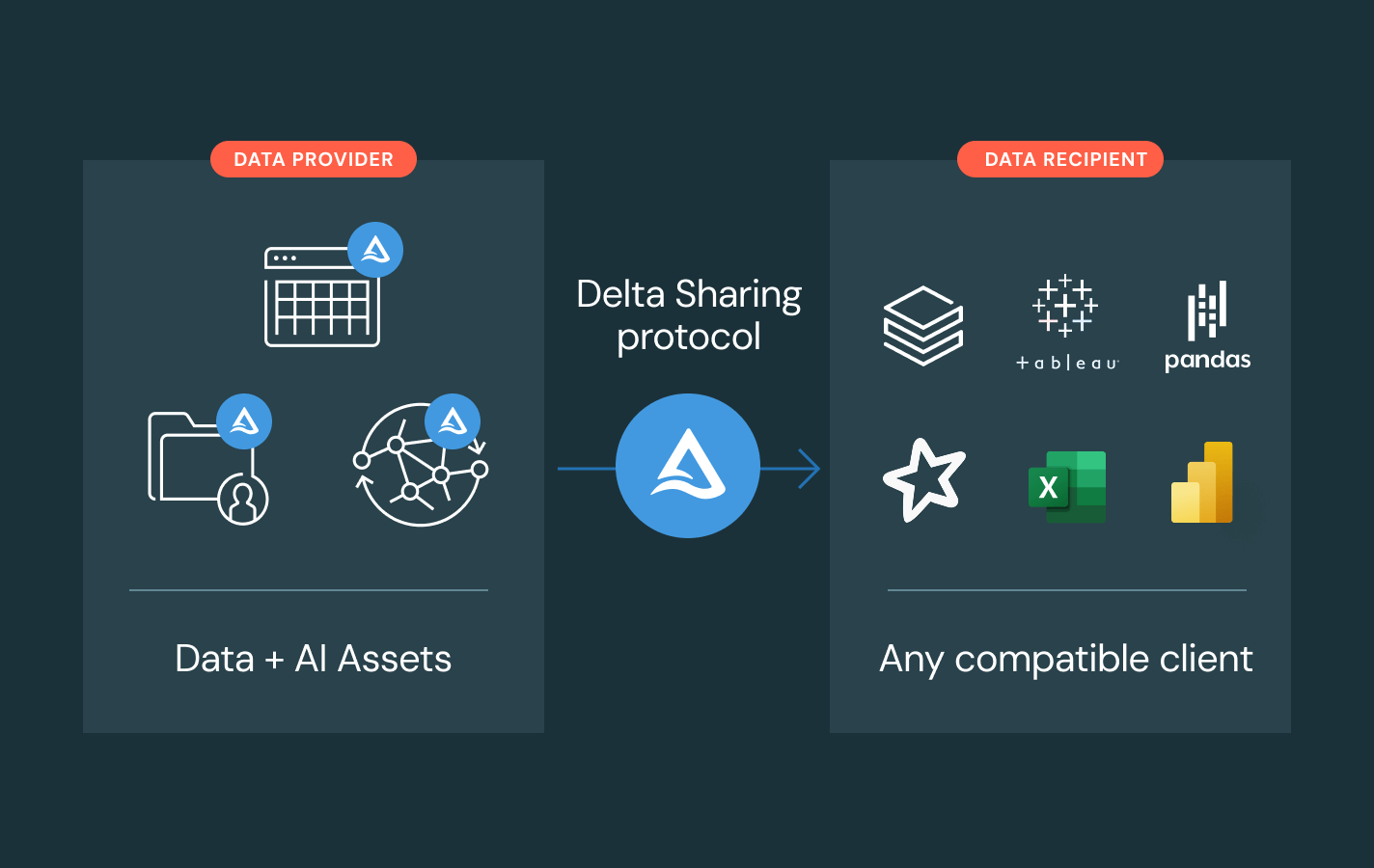
- Partagez des assets de données et d'IA gouvernés entre plusieurs équipes, clouds et partenaires grâce à Delta Sharing
- Utilisez les salles blanches pour une collaboration sécurisée et respectueuse de la vie privée
- Restez indépendants des fournisseurs grâce aux normes de partage ouvertes
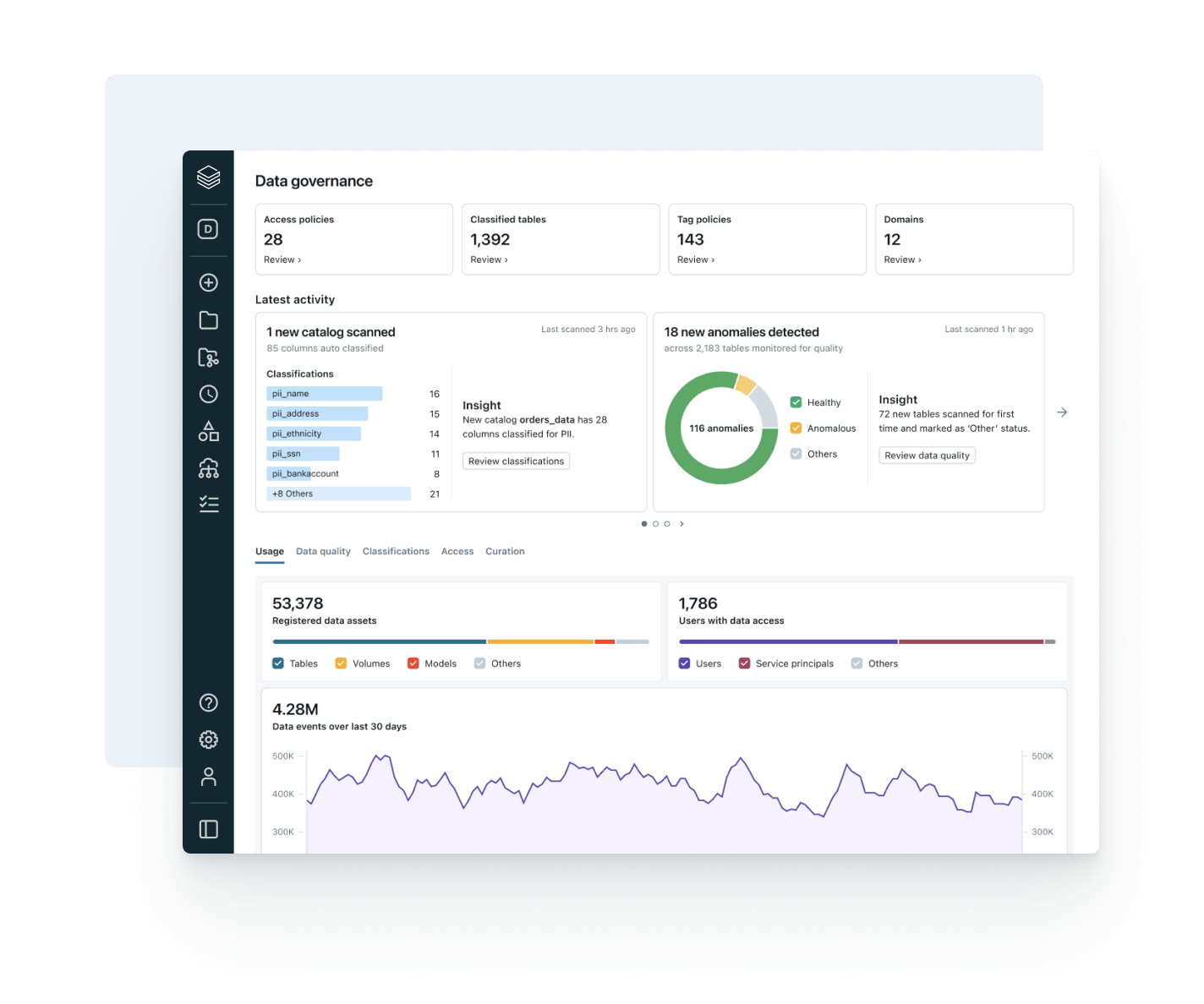
Alignez l'utilisation des données avec la valeur commerciale et le coût opérationnel
Utilisez l'observabilité intégrée pour optimiser les dépenses, stimuler l'adoption de la gouvernance et augmenter le ROI.
- Suivez les tendances de consommation de données des utilisateurs, des équipes et des unités commerciales
- Associez la traçabilité à l'utilisation du calcul et du stockage pour identifier les leviers d'optimisation
- Surveillez l'adoption des politiques et les tendances d'accès aux données dans une seule interface utilisateur
- Donnez aux propriétaires de data products la possibilité de mesurer et de chiffrer la valeur des données

En savoir plus
Explorez les produits qui étendent la puissance de Unity Catalog dans les domaines de la gouvernance, la collaboration et l'intelligence des données.
Databricks Clean Rooms
Analysez des données partagées de différents acteurs sans fournir d'accès direct aux données.

Databricks Marketplace
Une place de marché ouverte pour les produits de données, mais aussi les assets d'IA et d'analytique comme les modèles et les notebooks.

Delta Sharing
Une approche open source pour le partage multiplateforme des données et de l'IA. Partagez des données dynamiques dans le cadre d'une gouvernance centralisée et sans les répliquer.

AI/BI Genie
Une expérience conversationnelle, alimentée par l'IA générative, pour permettre aux équipes métier d'explorer les données et d'obtenir des insights en temps réel grâce au langage naturel.

Databricks Assistant
Décrivez votre tâche en langage naturel : l'Assistant génère les requêtes SQL, vous explique le code complexe et corrige automatiquement les erreurs.
Plate-forme d'intelligence de données Databricks
Explorez tout l'éventail des outils disponibles sur la Databricks Data Intelligence Platform pour intégrer les données et l'IA de toute votre organisation de façon fluide et transparente.
Passez à l'étape suivante
Explorez la documentation de Unity Catalog
Obtenez des conseils détaillés sur les fonctionnalités, la configuration et les bonnes pratiques dans la documentation de Unity Catalog pour AWS, Azure et GCP.
Explorez les démos de produits
Regardez les démos de Unity Catalog pour voir comment vous pouvez gouverner, découvrir et partager des assets de données et d'IA à travers tout votre environnement.




FAQ sur Unity Catalog
Prêts à devenir une entreprise axée sur les données et l'IA ?
Faites le premier pas de votre transformation data