Introducing Databricks AWS IAM Credential Passthrough
by Silvio Fiorito and Greg Owen
As more and more analytics move to the cloud, customers are faced with the challenge of how to control which users have access to what data. Cloud providers like AWS provide a rich set of features for Identity and Access Management (IAM) such as IAM users, roles, and policies. These features allow customers to securely manage access to their sensitive data.
Challenges with Identity and Access Management for analytics in the cloud
We see many AWS customers attempting to solve this challenge either using a combination of IAM roles and IAM Instance Profiles or with hard-coded IAM credentials. Customers use policies for controlling access to data on S3 or other AWS resources such as Kinesis, SQS, etc. They then use Instance Profiles to pass IAM role information to EC2 instances. This allows them to associate a single data access policy with EC2 instances upon bootup.
There are some challenges and limitations with these options, however:
- EC2 instances can only be assigned a single Instance Profile. This requires customers to run different EC2 instances each with different roles and access controls to access multiple data sets, thereby increasing complexity and costs
- Whether using Instance Profiles or hard-coded IAM credentials, users on an EC2 instance share the same identity when accessing resources, so user-level access controls aren’t possible and there is no audit trail of which user from an EC2 instance accessed what, with cloud-native logging such as Cloud Trail.
- Neither Instance Profiles or IAM credentials necessarily map to the access policies in the enterprise identity management system, such as LDAP or Active Directory groups, which requires managing a new set of entitlements across different systems
To work around these limitations, we see some customers turning to legacy or non-cloud native tools that broker access to cloud storage such as S3. Many of these tools were not designed with cloud storage in mind and in some cases might require custom extensions to Apache Spark with support for limited formats or poor performance. This places an additional operational burden on the customer in order to manage a new set of services and entitlements and negates the scalability, low-cost, and low-maintenance of directly using S3. For Databricks customers, these tools might also impact the usability and features we provide in the Databricks Runtime such as DBIO and Delta.
When we began designing a solution, our top priority was to integrate with the identity and access services provided natively by AWS. In particular, our focus was to leverage AWS Identity Federation with SAML Single Sign-On (SSO). Given that Databricks already supports SAML SSO, this was the most seamless option for having customers centralize data access within their Identity Provider (IdP) and have those entitlements passed directly to the code run on Databricks clusters.
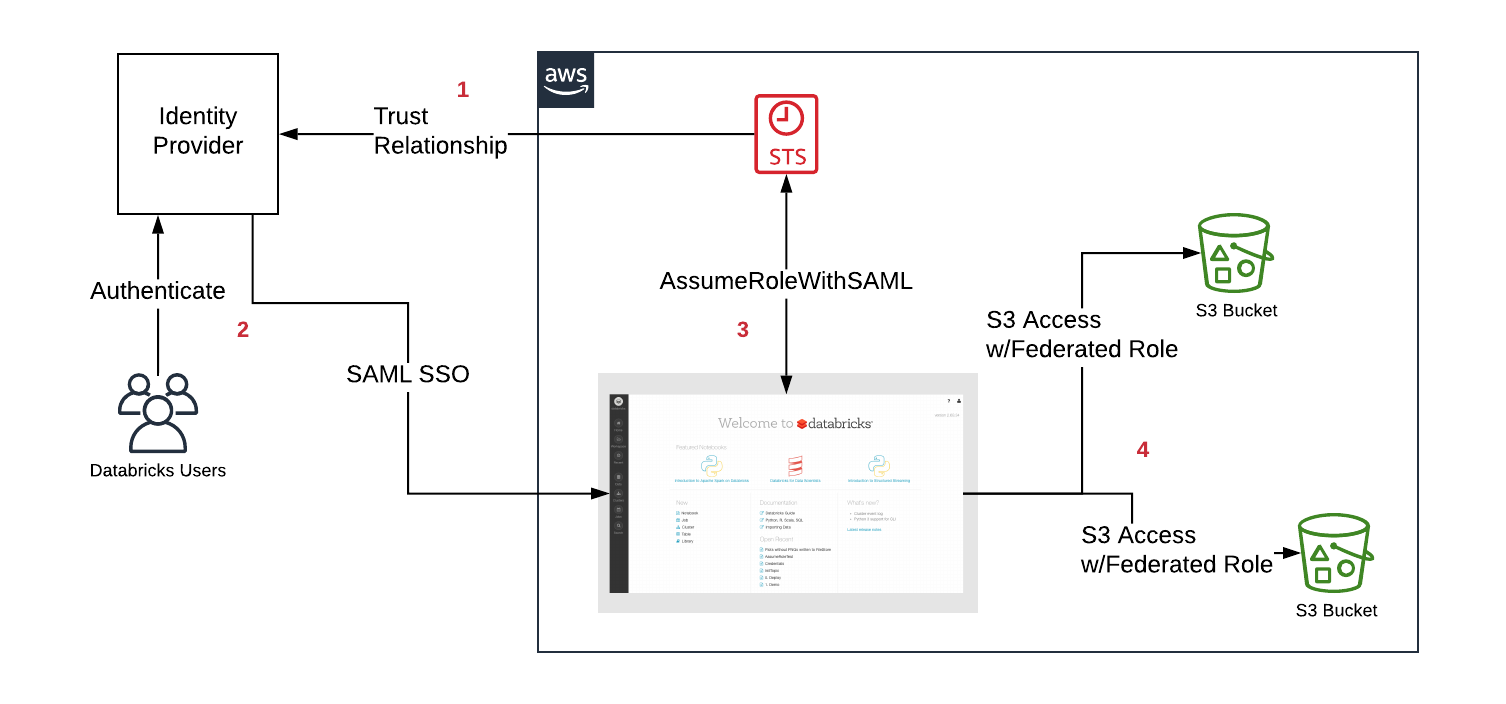
- First, the customer configures a trust relationship between their IdP and AWS accounts in order for the IdP to control which roles users can assume
- Users login to Databricks via SAML SSO, the entitlement to the roles are passed by the IdP
- Databricks calls the AWS Security Token Service (STS) and assumes the roles for the user by passing the SAML response and getting temporary tokens
- When a user accesses S3 from a Databricks cluster, Databricks runtime uses the temporary tokens for the user to perform the access automatically and securely
IAM credential passthrough with Databricks
In order to use IAM Credential Passthrough, customers first enable the required integration between their IdP and AWS accounts and must configure SAML SSO for Databricks. The rest is managed directly by the IdP and Databricks, such as what roles a user has permission to use or fetching temporary tokens from AWS.
In order to use federated roles, a new cluster configuration is available called “Credential Passthrough”.

A new API specifically for federated roles is available to users as part of DBUtils. First, users can list the roles they have available by calling dbutils.credentials.showRoles

In order to assume a specific role, user calls dbutils.credentials.assumeRole

From that point on, any S3 access within that notebook will use the chosen role. If a user does not explicitly assume a role, then the cluster will use the first role in the list.
In some cases, users may need to analyze multiple datasets that require different roles. In order to make the role selection transparent, bucket mounts can be used as well:
With bucket mounts defined, users can reference the DBFS paths without needing to select any roles. Users who can't assume the role specified by the mount point will not be able to access the mount point. This also allows joining across datasets requiring different roles and makes the experience seamless for end-users.
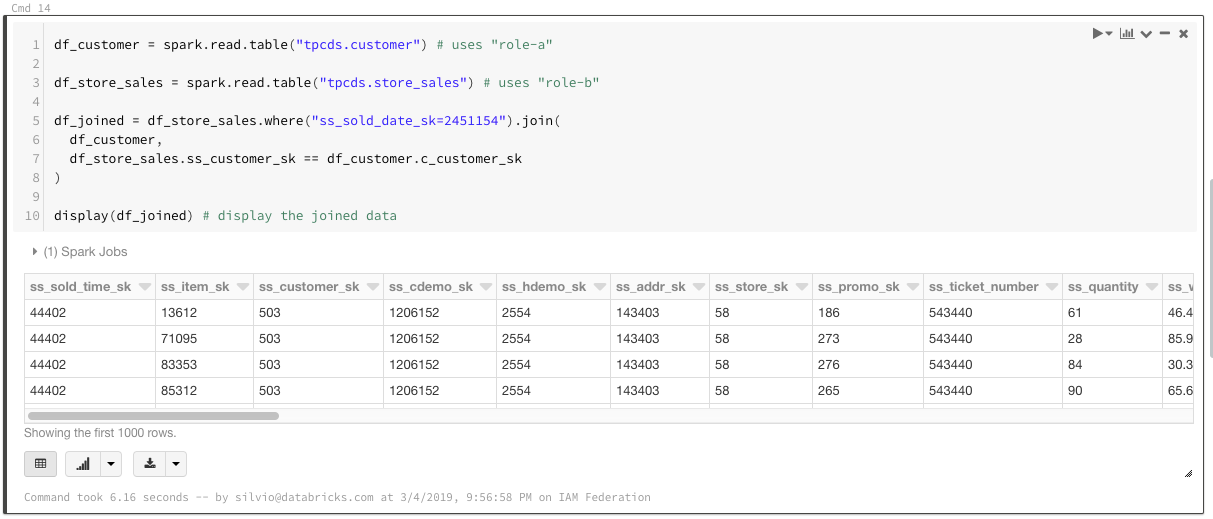
Since federated roles uniquely identify the user, it allows for more powerful data access controls on S3. One example would be to define “home directories” on S3 that let users save datasets to private locations only accessible by the owner. This is possible even though users may be sharing the same IAM role or even the same cluster.
https://www.youtube.com/watch?v=pqi1PgqragM
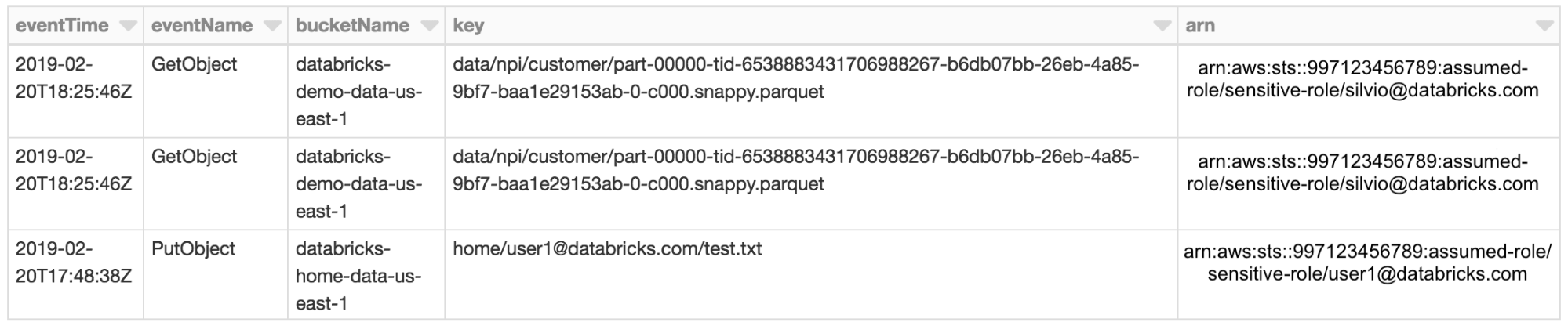
Since assumed roles identify the individual user, auditing is now available by simply enabling S3 object logging via Cloud Trail. All S3 access will be tied directly to the user via the ARN in Cloud Trail logs.
Conclusion
With the new IAM Credential Passthrough feature, we’re introducing more powerful data access controls that integrate directly with your enterprise identity platform. It provides seamless access control over your data without losing the reliability, scalability, and low-cost of S3. With Databricks process isolation you can still have the efficiency of safely sharing Spark cluster resources without having to manage additional tools in your environment. You can safely let your analysts, data scientists, and data engineers use the powerful features of the Databricks Unified Analytics Platform while keeping your data secure! IAM Credential Passthrough is in private preview right now, if you’d like to know more please contact your Databricks representative.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.