TensorFlow™ sur Databricks

Calcul distribué avec TensorFlow
TensorFlow prend en charge les calculs distribués, ce qui permet de calculer certaines portions d'un graphe sur différents processus, voire différents serveurs ! Cela permet également de distribuer les calculs sur des serveurs équipés de puissants GPU, d'exécuter d'autres calculs sur des serveurs mieux dotés en mémoire, etc. Sachez toutefois que l'interface n'est pas très pratique. Mais commençons par le début.
Voici notre premier script. Nous allons l'exécuter sur un seul processus avant de le répartir sur plusieurs.
Pour le moment, ce script ne devrait pas vous effrayer outre mesure. Nous avons une constante et trois équations de base. Le résultat (238) est affiché à la fin.
TensorFlow fonctionne un peu comme un modèle serveur-client. Le principe consiste à créer un groupe de workers qui vont faire l'essentiel du calcul. Vous créez ensuite une session sur l'un de ces workers afin qu'il calcule le graphe, éventuellement en distribuant certains aspects à d'autres clusters du serveur.
Pour ce faire, le worker principal doit connaître l'existence des autres workers. Nous allons pour cela créer un ClusterSpec et le passer à tous les workers. Le ClusterSpec repose sur un dictionnaire où la clé est un « job name » (nom de tâche) et où chaque tâche contient de nombreux workers.
En voici un schéma.
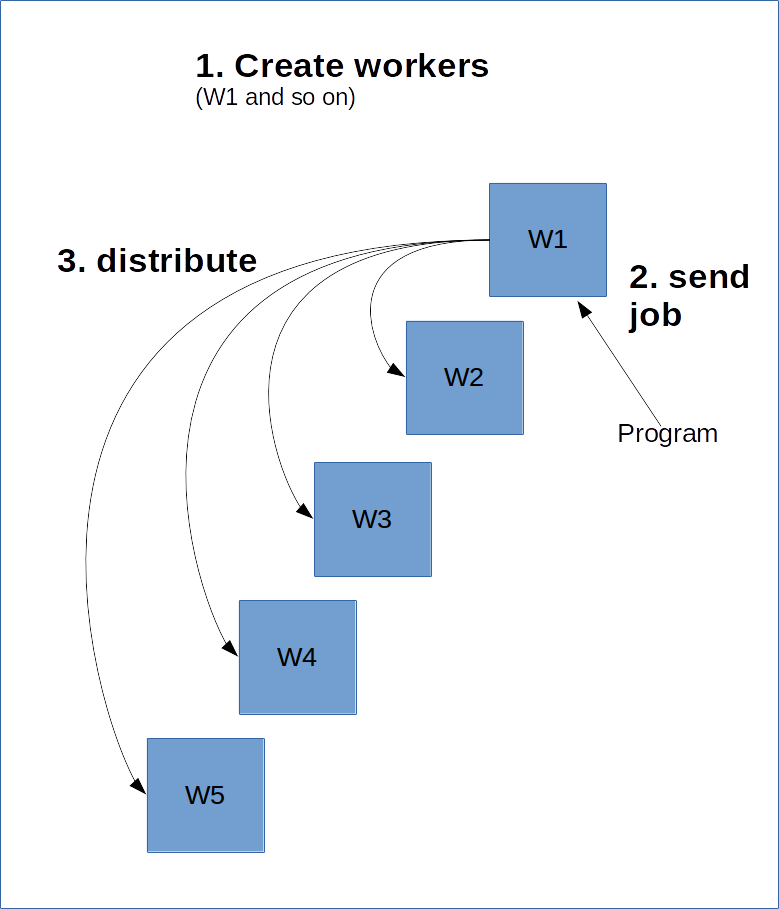
Le code suivant crée un ClusterSpec ayant « local » comme nom de tâche et deux processus worker.
Notez que ces processus ne sont pas initiés par ce code ; ce n'est qu'une simple référence au fait qu'ils le seront.
Il faut ensuite lancer le processus. Pour cela, nous créons un graphe pour l'un de ces workers et nous le lançons :
Le code ci-dessus lance le worker « localhost:2223 » sous la tâche « local ».
Ci-dessous, un script que vous pouvez exécuter dans la ligne de commande pour lancer les deux processus. Enregistrez le code sur votre ordinateur dans un fichier create_worker.py et exécutez-le avec python create_worker.py 0 puis python create_worker.py 1. Vous aurez besoin de deux terminaux distincts, car les scripts ne se terminent pas d'eux-mêmes (ils attendent des instructions).
Une fois que c'est fait, chaque terminal contient un serveur en cours d'exécution. Nous sommes prêts à passer à la distribution !
Le moyen le plus simple de « distribuer » la tâche consiste à créer simplement une session sur l'un des processus puis à y exécuter le graphe. Modifiez simplement la ligne « session » du code précédent comme suit :
Certes, ce n'est pas une véritable distribution, car cette opération envoie simplement la tâche à ce serveur. TensorFlow peut distribuer le traitement à d'autres ressources du cluster, mais ce n'est pas automatique. Nous pouvons forcer ce comportement en spécifiant des périphériques (comme nous l'avons fait avec les GPU dans la leçon précédente) :
Voilà, cette fois c'est une véritable distribution ! Nous affectons des tâches aux workers en utilisant le nom et le numéro de tâche. Le format est le suivant :
/job:JOB_NAME/task:TASK_NUMBER
En multipliant les tâches (pour identifier des ordinateurs équipés de GPU performants), nous pouvons distribuer le traitement de nombreuses façons différentes.
Map et Reduce
MapReduce est un paradigme très apprécié pour réaliser des opérations massives. Il comprend deux grandes étapes (bien qu'il y en ait quelques autres de plus dans la pratique).
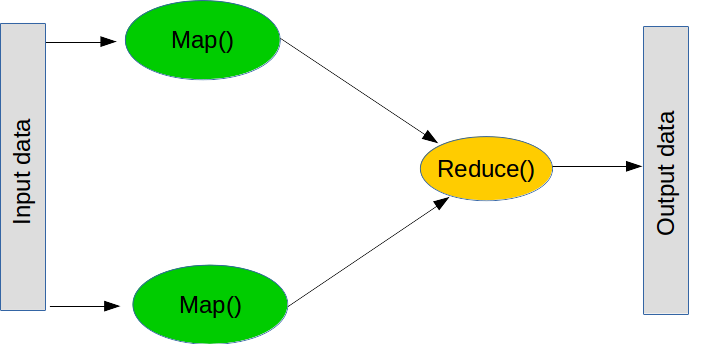
La première est map, qui signifie « prends cette liste d'objets et applique cette fonction à chacun d'entre eux ». L'opération map peut se faire en python classique, comme suit :
La deuxième étape est reduce, qui signifie « prends cette liste d'objets et combine-les à l'aide de cette fonction ». L'étape reduce consiste souvent à effectuer une somme : « prends cette liste de nombre et combine-les en les additionnant ». Pour obtenir ce résultat, on peut créer une fonction qui ajoute deux nombres. Reduce va alors prendre les deux premières valeurs de la liste, appliquer la fonction, puis appliquer la fonction au résultat, mais aussi à la valeur suivante de la liste. Dans le cas d'une somme, nous ajoutons les deux premiers nombres, puis le résultat obtenu au nombre suivant, et ainsi de suite jusqu'à la fin de la liste. Une fois encore, reduce fait partie de python (mais l'opération n'est pas distribuée) :
Notez que vous n'aurez normalement pas besoin d'utiliser reduce – utilisez simplement une boucle for.
Revenons à TensorFlow et à la distribution. Les opérations map et reduce sont des éléments essentiels dans de nombreux programmes non triviaux. Par exemple, une tâche d'apprentissage sur un ensemble peut envoyer différents modèles de machine learning à plusieurs workers, puis combiner les classifications pour former le résultat final. Autre exemple, un processus qui
Voici un autre script de base que nous allons distribuer :
Nous allons simplement modifier la conversion précédente pour obtenir une version distribuée :
Vous remarquerez que la distribution d'un calcul est beaucoup plus simple si vous pensez en termes de map et reduce. Tout d'abord, demandez-vous : « Comment puis-je diviser ce problème en sous-problèmes solubles indépendamment ? ». Cela correspond au map. Ensuite, « Comment puis-je combiner les réponses pour constituer le résultat final ? ». Et voilà votre reduce.
En machine learning, la méthode map la plus courante consiste simplement à diviser vos datasets. Les modèles linéaires et les réseaux de neurones sont souvent assez performants pour cela, car ils peuvent être entraînés individuellement puis combinés par la suite.
1) Remplacez le mot « local » de ClusterSpec par autre chose. Que devez-vous changer d'autre dans le script pour qu'il fonctionne ?
2) Le script de moyenne s'appuie actuellement sur le fait que les slices font la même taille. Essayez avec des slices de différentes tailles pour observer l'erreur. Corrigez ce problème en utilisant tf.size et la formule suivante, qui va combiner les moyennes des slices :
3) Vous pouvez spécifier un périphérique sur un ordinateur distant en modifiant la chaîne device. Par exemple, « /job:local/task:0/gpu:0 » va cibler le GPU de la tâche locale. Créez une tâche qui utilise un GPU distant. Si vous avez un deuxième ordinateur à portée de main, essayez de le faire en passant par le réseau.