10 trilioni di campioni al giorno: Scalare oltre l'infrastruttura di monitoraggio tradizionale in Databricks
Come abbiamo costruito una piattaforma di monitoraggio progettata per la crescita esponenziale di Databricks
di David Yuan, Yi Jin, Karan Bavishi, HC Zhu e Joey Beyda
- I sistemi di monitoraggio di Databricks gestiscono oltre 5 miliardi di serie temporali attive in tempo reale su AWS, Azure e GCP.
- Per mantenere questi sistemi affidabili e a bassa manutenzione nonostante la rapida scalabilità, abbiamo riprogettato i nostri livelli TSDB e di aggregazione personalizzando soluzioni di monitoraggio open-source.
- Di fronte a una forte crescita delle metriche di troubleshooting ad alta cardinalità, abbiamo sviluppato una nuova piattaforma basata su Lakehouse chiamata Hydra. Questo approccio ha sbloccato ricche capacità di debug su larga scala e con un costo di archiviazione 50 volte inferiore rispetto al nostro stack esistente.
L'infrastruttura di monitoraggio di Databricks è cresciuta di oltre tre volte nell'ultimo anno, tracciando ora 5 miliardi di serie temporali attive in tempo reale e ingerendo oltre 10 trilioni di campioni al giorno. A questa scala massiccia, abbiamo scoperto che le soluzioni pronte all'uso erano inefficienti o difficili da adattare alle nostre esigenze. Questo post condivide ciò che abbiamo costruito invece: una piattaforma scalabile che sfrutta il meglio dell'ecosistema di monitoraggio open-source, integrando personalizzazioni per le nostre esigenze uniche.
Gli ingegneri di Databricks si affidano a sistemi di monitoraggio che ci avvisano rapidamente sui problemi, automatizzano lo scaling e i rollback e abilitano il troubleshooting intelligente. Questi sistemi devono essere altamente affidabili in modo da poter essere certi di non operare alla cieca durante un potenziale incidente. Tuttavia, si è rivelato non facile sviluppare questa infrastruttura per la scala di Databricks:
- Oltre ai requisiti di scalabilità, affidabilità ed efficienza, gestiamo i nostri sistemi a livello globale in circa 70 regioni cloud su ciascuno dei 3 principali cloud. Dobbiamo supportare prestazioni equivalenti nonostante le differenze tra i cloud e persino tra le singole regioni.
- Di fronte a questa ampiezza e varietà, la gestione di infrastrutture su larga scala può diventare rapidamente insostenibile. Il sistema deve essere il più possibile "autonomo", auto-riparante e auto-scalante, piuttosto che i nostri oncall che gestiscono direttamente ogni stack regionale, pur fornendo interfacce semplici per gli utenti.
- Con la crescita dei carichi di lavoro serverless e AI su Databricks, il churn nella nostra infrastruttura è aumentato vertiginosamente, causando rapidi aumenti della cardinalità delle metriche. Non potevamo più elaborare e archiviare dati di monitoraggio ad alta cardinalità come abbiamo sempre fatto, ma miravamo ancora a mantenere i flussi di lavoro di debug su cui fanno affidamento gli ingegneri.
Di fronte a queste sfide, il vecchio stack di monitoraggio di Databricks era afflitto da problemi di affidabilità. Ci siamo prefissati di sviluppare una nuova piattaforma affidabile che soddisfacesse le aspettative dei nostri ingegneri. Da allora abbiamo affrontato 3 problemi chiave:
- Architettare un database di serie temporali (TSDB) affidabile ed efficiente
- Introdurre l'aggregazione delle metriche per proteggere i TSDB dalla cardinalità
- Abilitare il troubleshooting altamente dimensionale con il lakehouse di Databricks
Database di serie temporali Thanos
Cosa sono i TSDB?
I TSDB sono una componente fondamentale delle architetture tradizionali dei sistemi di monitoraggio. Questi database specializzati sono progettati per ingerire grandi quantità di dati di metriche di serie temporali e servire letture in tempo reale ad alta QPS e bassa latenza. Sono particolarmente ottimali per i modelli di query di monitoraggio come alert e aggiornamenti di dashboard, che richiedono l'emissione ripetuta dello stesso set di query e l'ottenimento di risultati fulminei basati sui dati più recenti.
I vecchi TSDB di Databricks erano stati costruiti per una scala di un ordine di grandezza inferiore e sono diventati un collo di bottiglia importante per noi negli ultimi anni. Infatti, il problema di affidabilità #1 per l'intera infrastruttura di monitoraggio era la difficoltà di scalare i nostri TSDB. Questa è un'operazione infrequente per molte altre aziende, ma qualcosa che dovevamo fare quasi quotidianamente data la crescita esponenziale di Databricks.
Quindi abbiamo sviluppato un nuovo TSDB nome in codice Pantheon, che è un fork del progetto open-source CNCF Thanos. Siamo riusciti a scalare fino a oltre 160 istanze di Thanos in tutte le regioni di tre provider cloud, con un totale di circa 5 miliardi di serie temporali attive in memoria e oltre 10 trilioni di campioni ingeriti giornalmente. La nostra istanza più grande ospita circa 300 milioni di serie temporali in memoria e supporta quasi 1.000 query PromQL al secondo; gestiamo anche piccole implementazioni a 3 nodi e tutto ciò che sta nel mezzo. A causa dell'ampiezza, della scala e della varietà delle nostre implementazioni, scopriamo spesso casi limite di Thanos e ottimizzazioni delle prestazioni e contribuiamo a questi alla comunità open-source.
La migrazione a Pantheon ci ha permesso di risparmiare milioni di dollari in costi cloud annuali, riducendo al contempo i tempi di inattività dell'infrastruttura di monitoraggio di circa 5 volte ed eliminando molte fonti di lavoro manuale. L'architettura di Pantheon è mostrata di seguito, e le sezioni seguenti spiegano diverse decisioni di progettazione chiave che hanno reso possibili questi risultati.
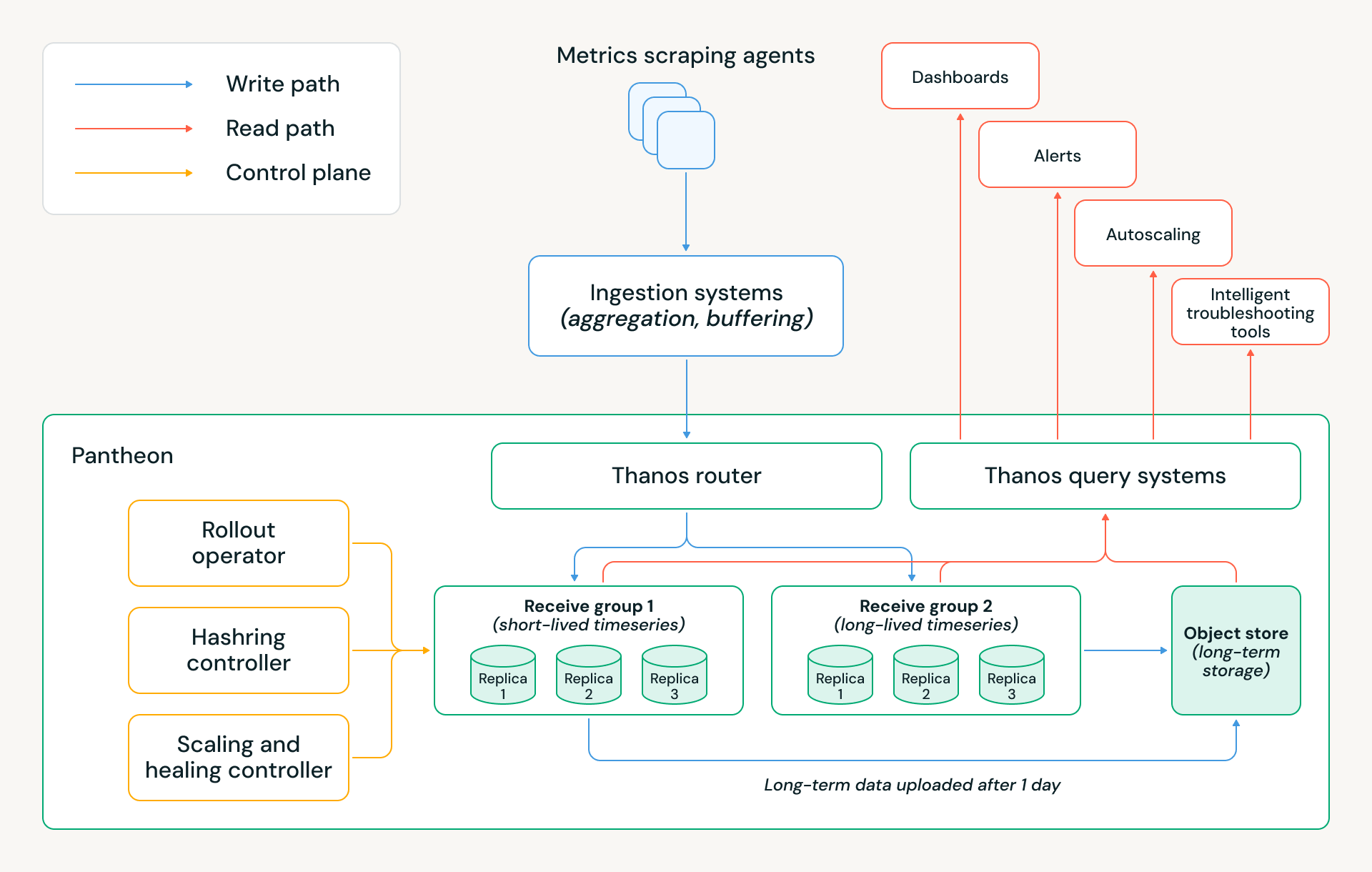
Architettura di storage
Un elemento chiave di Thanos è la sua architettura di storage a livelli. Le serie temporali più recenti sono mantenute in memoria, le serie temporali delle ultime 24 ore sono mantenute su disco e tutti i dati più vecchi sono mantenuti sullo storage a oggetti. Ciò significa che gli alert e altre query in tempo reale possono soddisfare requisiti di prestazioni rigorosi, poiché tipicamente dipendono dai dati più recenti. Allo stesso tempo, l'utilizzo dello storage a oggetti consente al sistema di disaccoppiare essenzialmente il calcolo dallo storage; un cluster può scalare senza dover ribilanciare tutti i suoi dati storici sui nodi del database.
Questa architettura ha affrontato il nostro collo di bottiglia chiave (scaleup) e ha gettato le basi per i risparmi sui costi di Pantheon. Abbiamo applicato diverse altre ottimizzazioni:
- Retention in memoria: Distribuiamo due gruppi di ricezione con criteri di retention in memoria distinti: uno ottimizzato per serie temporali di lunga durata da servizi persistenti, che mantiene due ore di campioni in memoria, e un altro ottimizzato per serie temporali di breve durata dai carichi di lavoro effimeri di Databricks, che mantiene solo 30 minuti di campioni in memoria. Questa divisione riflette la durata di vita che abbiamo osservato per i carichi di lavoro serverless su Databricks e riduce significativamente l'impronta di memoria e i costi del cloud preservando la correttezza.
- Struttura del gruppo di ricezione: Ogni gruppo è intenzionalmente implementato come tre StatefulSet isolati di Kubernetes, corrispondenti a tre repliche, invece di un singolo grande hash ring. Questo design preserva la replica a tre vie con scritture di quorum, fornendo al contempo un isolamento operativo e dei dati più forte. Questa configurazione ci consente di aggiornare o riavviare un intero StatefulSet in parallelo durante rilasci o rotazioni di nodi senza violare il quorum o influire sulla disponibilità di scrittura, il che semplifica materialmente le operazioni quotidiane.
- Multitenancy: Pantheon utilizza la multitenancy di Thanos per ospitare set di tenant disgiunti attraverso i gruppi di ricezione. A livello di router, applichiamo l'attribuzione dei tenant basata su regole, inferendo il tenant per ogni campione di dati ispezionando il nome della metrica e le etichette selezionate. Ciò consente ai campioni all'interno dello stesso batch di scrittura di essere indirizzati a tenant diversi - e quindi a gruppi di ricezione diversi - senza richiedere modifiche ai client upstream.
- Upload at-least-once: Per ottimizzare ulteriormente i costi preservando la correttezza, solo due dei tre StatefulSet caricano blocchi nello storage a oggetti. Ciò riduce il traffico di upload ridondante e i costi di storage cloud, mantenendo al contempo la durabilità dei dati e le garanzie di coerenza attraverso la replica e la semantica del quorum.
Piano di controllo Pantheon
Alla nostra scala globale, le operazioni manuali, l'automazione Kubernetes best-effort o i comportamenti Thanos standard non sono sufficienti. Ogni rilascio, evento di scaling o guasto dell'host deve essere gestito in modo sicuro, automatico e con il minimo intervento umano, preservando il quorum e la disponibilità dei dati. Per raggiungere questo obiettivo, Pantheon introduce un piano di controllo appositamente creato, responsabile dell'orchestrazione del ciclo di vita dei componenti Thanos e delle decisioni sulla capacità. È composto da tre controller chiave:
- Rollout Operator: Coordina rilasci e scaling su tre StatefulSet di ricezione isolati, garantendo il quorum sia per le letture che per le scritture. Abilita rilasci più rapidi tramite aggiornamenti paralleli degli StatefulSet, garantendo che al massimo una replica sia non disponibile in qualsiasi momento.
- Hashring Controller: Gestisce quali endpoint di ricezione sono visibili al router. Solo i pod sani e completamente pronti vengono aggiunti all'hashring, e le rimozioni vengono preparate durante lo scale-down o la manutenzione. Ciò disaccoppia la gestione del traffico dal ciclo di vita dei pod e previene violazioni accidentali del quorum o instradamenti parziali durante i cambiamenti dinamici del cluster.
- Autoscaling and Self-Healing Controller: Scala i cluster in base all'ingestione specifica di Pantheon e alla pressione delle risorse piuttosto che a segnali Kubernetes generici. Un sistema di guarigione integrato rileva e corregge continuamente le modalità di guasto comuni, come host difettosi, pod sovraccarichi o un WAL corrotto, consentendo al sistema di auto-recuperarsi senza intervento dell'operatore. Alla nostra scala, queste automazioni entrano in gioco decine di volte a settimana.
Cardinalità e aggregazione
Cos'è la cardinalità e perché è importante?
I proprietari delle metriche aggiungono spesso etichette come ID nodo o ID pod per aiutarli a eseguire il debug di problemi su dimensioni specifiche e mitigare gli incidenti più velocemente. Tuttavia, questo porta a una classica sfida di osservabilità: la gestione della cardinalità. La cardinalità di una metrica è il numero di combinazioni univoche delle sue etichette. Se il numero di pod che stai monitorando aumenta di 10 volte, aumenta anche la cardinalità di qualsiasi metrica con un'etichetta ID pod. La cardinalità è il principale fattore di scalabilità per un TSDB, e la crescita della cardinalità delle metriche esistenti aumenta i costi e la pressione di scalabilità su Pantheon.
La rapida crescita dell'infrastruttura è una sfida di cui siamo fortunati ad avere in Databricks. Contemporaneamente alla crescita significativa della nostra base di clienti e dell'utilizzo dei prodotti, molti clienti hanno recentemente adottato la nostra architettura di calcolo serverless, e la nostra piattaforma di calcolo serverless avvia decine di milioni di VM ogni giorno. Man mano che più carichi di lavoro passano al serverless, l'infrastruttura che monitoriamo diventa più soggetta a churn e la durata di queste etichette identificative continua a diminuire.
Ciò ha causato un aumento esponenziale della cardinalità, erodendo i vantaggi di scalabilità e costi di Pantheon. Pertanto, abbiamo dovuto diventare molto più intelligenti riguardo ai dati delle metriche che memorizzavamo. È qui che è entrata in gioco l'"aggregazione": eliminare etichette costose dai sistemi serverless durante l'ingestione, pur fornendo una vista aggregata dell'intera flotta ai proprietari dei servizi. Una strategia di aggregazione automatizzata per le metriche ci ha permesso di "curvare la curva" della crescita della cardinalità, garantendo che l'infrastruttura di monitoraggio non debba scalare più velocemente del resto di Databricks.
Architettura di aggregazione
Costruire un'infrastruttura di aggregazione affidabile su larga scala è difficile perché è stateful. Gli aggregatori che gestiscono milioni di contatori di input devono essere in grado di gestire correttamente i reset: se una serie temporale di input scompare, il valore di output aggregato dovrebbe continuare ad aumentare monotonicamente anziché diminuire. Con le metriche partizionate tra gli aggregatori, è necessario anche gestire scenari come riavvii di pod e squilibri di carico.
Questi problemi vengono spesso risolti utilizzando un sistema di messaggistica come Kafka per le assegnazioni di partizione e il mantenimento dei dati precedenti; questo è costoso su larga scala e aggiunge ritardi di ingestione che influiscono sui casi d'uso in tempo reale. L'approccio alternativo è memorizzare lo stato in memoria negli aggregatori e reindirizzare le metriche tra gli aggregatori per rispettare l'assegnazione. Tuttavia, ciò comporta perdite di dati quando un aggregatore viene ridistribuito; in una versione iniziale della nostra infrastruttura di aggregazione, questo comportamento rendeva le metriche aggregate quasi incomprensibili per i nostri utenti.
Per far funzionare tutto questo senza problemi, abbiamo invece sviluppato il nostro sistema di aggregazione utilizzando Telegraf e il servizio "auto-sharder" di Databricks Dicer. Questa architettura utilizza uno routing sticky intelligente invece di reindirizzare le metriche tra gli aggregatori, il che ha risolto i problemi di fallimento della ridistribuzione. Con altre ottimizzazioni che abbiamo aggiunto a Telegraf, siamo stati in grado di scalare la pipeline a oltre 1 GB/s nella nostra regione più grande e migliaia di regole di aggregazione.
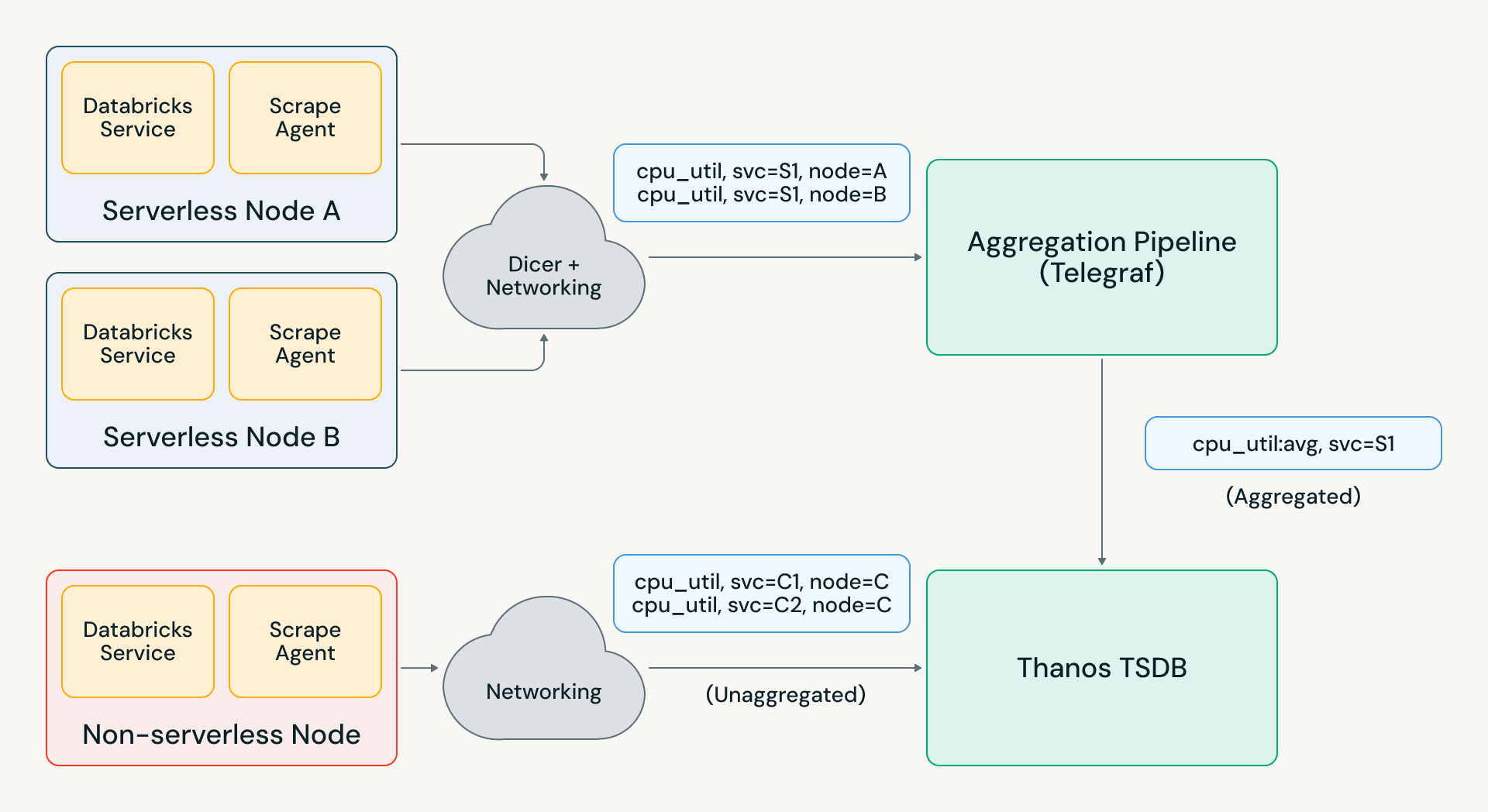
Questa nuova pipeline di aggregazione è diventata di fatto lo scudo che protegge i nostri TSDB dalla crescita della cardinalità a lungo termine e dagli improvvisi picchi di metriche. Ad esempio, un recente incidente nell'infrastruttura di Databricks ha causato un picco di carico di metriche da 2 a 5 volte in varie regioni. Telegraf ha assorbito la maggior parte di questo carico e Pantheon ha visto solo un picco del 20%, consentendo agli ingegneri di tutta l'azienda di eseguire query di debug e alerting senza alcun impatto.
Dati ad alta cardinalità sul lakehouse
Il problema con l'aggregazione
La nostra infrastruttura di aggregazione ci consente di proteggere Pantheon dalla crescita esponenziale della cardinalità, ma ciò ha un costo: rimuove le dimensioni esatte di cui gli ingegneri hanno bisogno durante gli incidenti. Considera una flotta globale con:
- Milioni di nodi attivi nelle ultime 2 ore
- Più tenant per nodo
- Carichi di lavoro di breve durata
- Autoscaling rapido
Le metriche aggregate ti dicono:
- L'utilizzo della CPU a livello di regione è elevato
- La latenza a livello di servizio sta aumentando
Ma non ti dicono:
- Quale tenant sta causando pressione sullo swap
- Quale nodo è crashato
- Quale shard è isolato
- Quale carico di lavoro è rumoroso
Gli ingegneri di Databricks avevano ancora bisogno di una soluzione per la risoluzione dei problemi dei flussi di lavoro che si basava su queste etichette ad alta cardinalità. Questi scenari "ago nel pagliaio" richiedevano l'archiviazione e l'elaborazione efficiente di enormi quantità di dati grezzi, cosa che Pantheon non poteva fare. Per supportare questi casi d'uso, abbiamo cercato un'architettura di archiviazione diversa che non fosse limitata dalla crescita della cardinalità.
Entra nel lakehouse!
La nostra intuizione chiave: il lakehouse di Databricks è una soluzione perfetta! Disaccoppia l'archiviazione (economico storage di oggetti + Delta Lake) dal calcolo (cluster di streaming + query) ed è massicciamente scalabile in entrambe le dimensioni.
Utilizzando il meglio delle capacità di Databricks, abbiamo sviluppato una nuova piattaforma per dati di troubleshooting grezzi chiamata Hydra, che ha reso il debug ad alta cardinalità pratico su larga scala. Hydra ingerisce 20 miliardi di serie temporali attive non aggregate da milioni di nodi in tutto il mondo, raggiungendo una freschezza dei dati end-to-end di 5 minuti e un costo di archiviazione dati 50 volte inferiore rispetto a Thanos.
Questi vantaggi sono stati resi possibili dal design nativo del lakehouse di Hydra:

- Utilizziamo Apache Spark™ Structured Streaming su Databricks per eseguire processi di ingestione continui che elaborano incrementalmente i dati delle metriche man mano che arrivano, scrivendoli in Delta Lake. Structured Streaming consente di esprimere calcoli di streaming nello stesso modo in cui si scrivono processi batch, ma con elaborazione incrementale continua e semantica exactly-once per un'ingestione affidabile.
- Per scoprire e ingerire in modo efficiente milioni di file di object storage, sfruttiamo Databricks Auto Loader, una sorgente Structured Streaming ad alta produttività che tiene traccia ed elabora incrementalmente i nuovi file senza richiedere elenchi manuali o gestione dello stato. Auto Loader persiste automaticamente i metadati sui file scoperti e scala per gestire schemi di arrivo quasi in tempo reale.
- Partizioniamo anche l'ingestione per regione, distribuendo processi di streaming indipendenti tra le aree geografiche. Ciò consente a ciascuna pipeline di scalare automaticamente in modo indipendente, riduce al minimo la latenza interregionale e diminuisce il raggio d'azione in caso di guasti. Insieme, queste scelte di progettazione consentono ai dati grezzi delle metriche di essere interrogabili entro pochi minuti dall'emissione, anche a volumi di miliardi di serie, mantenendo al contempo performanti i sistemi di dashboard.
Unificare le interfacce
La costruzione di Hydra non è stata solo una sfida infrastrutturale; è stata una sfida di progettazione dell'interfaccia. Fin dall'inizio, abbiamo progettato Hydra attorno ai Percorsi Utente Critici (CUJ) per i nostri ingegneri piuttosto che attorno ai livelli di archiviazione o alle pipeline di ingestione. Il nostro obiettivo era semplice: gli ingegneri dovrebbero essere in grado di lavorare con metriche ad alta cardinalità utilizzando le stesse interfacce su cui fanno già affidamento.
Query tramite Grafana
La maggior parte degli ingegneri inizia il proprio flusso di lavoro di debug in Grafana. Si aspettano di scrivere PromQL, utilizzare dashboard esistenti, approfondire le etichette e pivotare rapidamente durante gli incidenti.
Per preservare questo flusso di lavoro, Hydra si integra direttamente con Grafana abilitando query PromQL da eseguire sui dati archiviati in Databricks. Abbiamo creato uno strato di conversione da PromQL a SQL che traduce le espressioni PromQL in query SQL eseguite su tabelle Delta nel Lakehouse. Questo approccio consente agli ingegneri di continuare a utilizzare la sintassi e le dashboard PromQL familiari senza modifiche. Allo stesso tempo, le query sottostanti vengono eseguite su tabelle Delta su larga scala anziché su un TSDB in memoria.
Accesso SQL diretto in Databricks
Mentre Grafana è ideale per il debug live, alcune indagini richiedono analisi più approfondite. Gli ingegneri potrebbero dover unire metriche con metadati di deployment, correlare metriche con log, eseguire scansioni di ampie finestre temporali, eseguire il rilevamento di anomalie o esportare dataset per analisi avanzate.
Hydra espone anche le tabelle Delta sottostanti direttamente all'interno di Databricks. Gli ingegneri possono interrogare queste tabelle utilizzando Databricks SQL o notebook, consentendo analisi flessibili che vanno oltre i tradizionali flussi di lavoro di monitoraggio.
Poiché i dati risiedono nel Lakehouse, diventano unibili con altri set di dati aziendali e governati sotto gli stessi controlli di sicurezza e accesso. Questo trasforma i dati di osservabilità in un asset analitico di prima classe anziché in un silo di monitoraggio isolato.
Semantica delle metriche unificate
Un principio chiave di progettazione di Hydra è che gli ingegneri non dovrebbero aver bisogno di comprendere la nostra architettura di ingestione. Sia che una metrica venga acceduta tramite il percorso aggregato basato su TSDB, sia tramite il percorso della metrica grezza basato su Lakehouse, l'interfaccia rimane coerente.
I nomi delle metriche, la semantica delle etichette e le dimensioni dei metadati sono unificati tra gli ambienti. I team di servizio emettono metriche una volta utilizzando un'interfaccia standardizzata. La piattaforma gestisce l'aggregazione, la conservazione grezza, l'ingestione, l'archiviazione e l'instradamento delle query. Questo modello unificato riduce il carico cognitivo ed elimina la necessità per i team di gestire configurazioni separate per diversi backend di osservabilità.
In futuro, stiamo cercando di migliorare le prestazioni di Hydra in modo che raggiunga una freschezza dei dati simile a Pantheon e le due esperienze convergano ulteriormente.
Punti chiave
Per scalare l'infrastruttura di monitoraggio di Databricks, abbiamo dovuto ottimizzare per affidabilità, efficienza, operatività e percorsi degli sviluppatori. Per noi "scalare" ha significato più che semplicemente aumentare le nostre distribuzioni. Ha significato:
- Integrare resilienza e automazione nella nostra architettura fondamentale, per ottenere operazioni "hands-off" per questi sistemi globali e in continua evoluzione
- Ripensare dai principi fondamentali il tipo di sistemi necessari per vari casi d'uso di monitoraggio, dall'allerta alla risoluzione dei problemi all'analisi tra diverse origini dati
- Evolvere la nostra architettura mentre il resto dell'infrastruttura di Databricks si è trasformato al nostro fianco
Questi saranno percorsi senza fine per noi e sono illustrativi del motivo per cui l'ingegneria delle infrastrutture è uno spazio così dinamico in Databricks. Se ti piace risolvere complessi problemi di ingegneria e ti piacerebbe unirti a noi per questo viaggio, dai un'occhiata a databricks.com/careers!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.