Rilascio open source di Dicer: l'auto-sharder di Databricks
Creazione di servizi partizionati ad alta disponibilità su larga scala per prestazioni elevate e a basso costo
di Atul Adya, Colin Meek, Jonathan Ellithorpe, Vivek Jain e Yongxin Xu
- Rendere Dicer open source: stiamo ufficialmente rendendo Dicer open source, il sistema di auto-sharding fondamentale utilizzato in Databricks per creare servizi sharded veloci, scalabili e ad alta disponibilità.
- Cos'è Dicer e perché: descriviamo i problemi delle attuali architetture dei servizi, il motivo per cui sono necessari gli auto-sharder, il modo in cui Dicer risolve questi problemi e analizziamo le sue astrazioni principali e i suoi casi d'uso.
- Storie di successo: il sistema attualmente alimenta componenti di importanza critica come Unity Catalog e il nostro motore di orchestrazione di query SQL, dove ha eliminato con successo i cali di disponibilità e mantenuto tassi di hit della cache superiori al 90% durante i riavvii dei pod.
1. Annuncio
Oggi, siamo lieti di annunciare l'open-sourcing di uno dei nostri componenti infrastrutturali più critici, Dicer: l'auto-sharder di Databricks, un sistema fondamentale progettato per creare servizi sharded a bassa latenza, scalabili e altamente affidabili. È dietro le quinte di ogni principale prodotto Databricks, consentendoci di offrire un'esperienza utente costantemente veloce, migliorando al contempo l'efficienza della flotta e riducendo i costi del cloud. Dicer raggiunge questo obiettivo gestendo dinamicamente le assegnazioni di sharding per mantenere i servizi reattivi e resilienti anche in caso di riavvii, guasti e carichi di lavoro variabili. Come descritto in dettaglio in questo post su un blog, Dicer viene utilizzato per una varietà di casi d'uso, tra cui serving ad alte prestazioni, partizionamento del lavoro, pipeline di batch, aggregazione dei dati, multi-tenancy, soft leader election, utilizzo efficiente della GPU per carichi di lavoro di AI e altro ancora.
Rendendo Dicer disponibile alla comunità più ampia, siamo ansiosi di collaborare con l'industria e il mondo accademico per far progredire lo stato dell'arte nella creazione di sistemi distribuiti robusti, efficienti e ad alte prestazioni. Nel resto di questo post, discutiamo la motivazione e la filosofia di progettazione alla base di Dicer, condividiamo storie di successo relative al suo utilizzo in Databricks e forniamo una guida su come installare e sperimentare il sistema in autonomia.
2. Motivazione: superare le architetture stateless e partizionate staticamente
Databricks offre una suite di prodotti in rapida espansione per l'elaborazione dei dati, le analitiche e l'AI. Per supportare tutto questo su larga scala, gestiamo centinaia di servizi che devono gestire stati di dimensioni enormi, mantenendo al contempo la reattività. Storicamente, gli ingegneri di Databricks si erano affidati a due architetture comuni, ma entrambe hanno introdotto problemi significativi con la crescita dei servizi:
2.1. I costi nascosti delle architetture stateless
La maggior parte dei servizi di Databricks è nata con un modello stateless. In un tipico modello stateless, l'applicazione non conserva lo stato in memoria tra una richiesta e l'altra e deve rileggere i dati dal database a ogni richiesta. Questa architettura è intrinsecamente costosa poiché ogni richiesta comporta un accesso al database, aumentando sia i costi operativi sia la latenza [1].
Per mitigare questi costi, gli sviluppatori introducevano spesso una cache remota (come Redis o Memcached) per alleggerire il carico di lavoro del database. Sebbene questo migliorasse il throughput e la latenza, non riusciva a risolvere diverse inefficienze fondamentali:
- Latenza di rete: ogni richiesta paga ancora la "tassa" dei salti di rete verso il livello di caching.
- Overhead della CPU: cicli significativi vengono sprecati nella (de)serializzazione quando i dati si spostano tra la cache e l'applicazione [2].
- Il problema dell'"overread": i servizi stateless spesso recuperano oggetti interi o blob di grandi dimensioni dalla cache solo per utilizzare una piccola parte dei dati. Questi overread sprecano larghezza di banda e memoria, poiché l'applicazione scarta la maggior parte dei dati appena recuperati [2].
Il passaggio a un modello partizionato e la memorizzazione nella cache dello stato in memoria hanno eliminato questi livelli di overhead collocando lo stato direttamente con la logica che opera su di esso. Tuttavia, il partizionamento statico ha introdotto nuovi problemi.
2.2. La fragilità dello sharding statico
Prima di Dicer, i servizi sharded di Databricks si basavano su tecniche di sharding statico (ad es. hashing coerente). Sebbene questo approccio fosse semplice e consentisse ai nostri servizi di memorizzare in modo efficiente lo stato nella cache in memoria, ha introdotto tre problemi critici in produzione:
- Indisponibilità durante i riavvii e il dimensionamento automatico: la mancanza di coordinamento con un gestore di cluster ha comportato tempi di inattività o un peggioramento delle prestazioni durante le attività operative di manutenzione come gli aggiornamenti continui o durante il dimensionamento dinamico di un servizio. Gli schemi di partizionamento statico non sono riusciti ad adattarsi in modo proattivo alle modifiche dell'appartenenza al backend, reagendo solo dopo che un nodo era già stato rimosso.
- Split-brain e downtime prolungati durante i guasti: senza un coordinamento centrale, i client potrebbero sviluppare viste incoerenti dell'insieme di pod di backend in caso di arresto anomalo o mancata risposta intermittente dei pod. Ciò ha portato a scenari di "split-brain" (in cui due pod credevano di possedere la stessa chiave) o addirittura alla perdita totale del traffico di un cliente (in cui nessun pod credeva di possedere la chiave).
- Il problema della hot key: per definizione, lo sharding statico non può ribilanciare dinamicamente le assegnazioni delle chiavi o regolare la replica in risposta a variazioni del carico. Di conseguenza, una singola "hot key" sovraccaricherebbe un pod specifico, creando un collo di bottiglia che potrebbe trigger errori a cascata in tutta la flotta.
Man mano che i nostri servizi crescevano sempre di più per soddisfare la domanda, alla fine lo sharding statico si è rivelato un'idea terribile. Ciò ha portato alla convinzione comune tra i nostri ingegneri che le architetture stateless fossero il modo migliore per creare sistemi robusti, anche se ciò significava accettare i costi in termini di prestazioni e risorse. Questo accadde più o meno nel periodo in cui fu introdotto Dicer.
2.3. Ridefinire la narrativa del servizio partizionato
I rischi in produzione dello sharding statico, contrapposti ai costi di un'architettura stateless, hanno messo diversi dei nostri servizi più critici in una posizione difficile. Questi servizi si basavano sullo sharding statico per offrire un'esperienza utente scattante ai nostri clienti. Convertirli a un modello stateless avrebbe introdotto una significativa penalizzazione delle prestazioni, per non parlare dei costi aggiuntivi del cloud per noi.
Abbiamo creato Dicer per cambiare questa situazione. Dicer affronta le carenze fondamentali dello sharding statico introducendo un piano di controllo intelligente che aggiorna in modo continuo e asincrono le assegnazioni degli shard di un servizio. Reagisce a un'ampia gamma di segnali, tra cui lo stato di salute dell'applicazione, il carico, gli avvisi di terminazione e altri input ambientali. Di conseguenza, Dicer mantiene i servizi ad alta disponibilità e ben bilanciati anche durante i riavvii progressivi, gli arresti anomali, gli eventi di scalabilità automatica e i periodi di grave sbilanciamento del carico.
In quanto auto-sharder, Dicer si basa su una lunga serie di sistemi precedenti, tra cui Centrifuge [3], Slicer [4] e Shard Manager [5]. Nella prossima sezione presenteremo Dicer e descriveremo come ha contribuito a migliorare le prestazioni, l'affidabilità e l'efficienza dei nostri servizi.
3. Dicer: sharding dinamico per prestazioni elevate e alta disponibilità
Presentiamo ora una panoramica di Dicer, delle sue astrazioni principali e dei suoi vari casi d'uso. Continuate a seguirci per un approfondimento tecnico sulla progettazione e sull'architettura di Dicer in un futuro post su un blog.
3.1 Panoramica di Dicer
Dicer modella un'applicazione che serve richieste (o esegue un altro tipo di lavoro) associate a una chiave logica. Ad esempio, un servizio che gestisce i profili utente potrebbe usare gli ID utente come chiavi. Dicer esegue lo sharding dell'applicazione generando continuamente un'assegnazione di chiavi ai pod per mantenere il servizio ad alta disponibilità e con bilanciamento del carico.
Per scalare ad applicazioni con milioni o miliardi di chiavi, Dicer opera su intervalli di chiavi invece che su singole chiavi. Le applicazioni rappresentano le chiavi per Dicer utilizzando una SliceKey (un hash della chiave dell'applicazione) e un intervallo contiguo di SliceKey è chiamato Slice. Come mostrato nella Figura 1, un Assignment di Dicer è una raccolta di Slice che insieme coprono l'intero keyspace dell'applicazione, con ogni Slice assegnato a una o più Risorse (ad es. pod). Dicer divide, Merge, replica e riassegna dinamicamente gli Slice in risposta ai segnali di integrità e di carico dell'applicazione, garantendo che l'intero keyspace sia sempre assegnato a pod integri e che nessun singolo pod venga sovraccaricato. Dicer può anche rilevare le hot key, suddividerle in slice dedicati e assegnare tali slice a più pod per distribuire il carico.
La Figura 1 mostra un esempio di assegnazione Dicer su 3 pod (P0, P1 e P2) per un'applicazione sottoposta a sharding per ID utente, in cui l'utente con ID 13 è rappresentato da SliceKey K26 (cioè un hash dell'ID 13) ed è attualmente assegnato al pod P0. Un utente "hot" con ID utente 42, rappresentato da SliceKey K10, è stato isolato nella propria slice e assegnato a più pod per gestire il carico (P1 e P2).

{kind=link}
La Figura 2 mostra una panoramica di un'applicazione partizionata integrata con Dicer. I pod dell'applicazione apprendono l'assegnazione corrente tramite una libreria chiamata Slicelet (S per lato server). Lo Slicelet mantiene una cache locale dell'assegnazione più recente, recuperandola dal servizio Dicer e monitorando gli aggiornamenti. Quando riceve un'assegnazione aggiornata, lo Slicelet notifica l'applicazione tramite un'API listener.
Le assegnazioni osservate dagli Slicelet sono "eventually consistent", una scelta progettuale deliberata che dà priorità alla disponibilità e al ripristino rapido rispetto a forti garanzie sulla proprietà della chiave. Nella nostra esperienza, questo si è rivelato il modello giusto per la stragrande maggioranza delle applicazioni, anche se in futuro prevediamo di supportare garanzie più forti, in modo simile a Slicer e Centrifuge.
Oltre a tenersi aggiornate sull'assegnazione, le applicazioni utilizzano anche lo Slicelet per registrare il carico per chiave durante la gestione delle richieste o l'esecuzione di attività per una chiave. Lo Slicelet aggrega queste informazioni localmente e segnala in modo asincrono un riepilogo al servizio Dicer. Si noti che, come il monitoraggio delle assegnazioni, anche questo si verifica al di fuori del percorso critico dell'applicazione, garantendo prestazioni elevate.
I client di un'applicazione partizionata Dicer individuano il pod assegnato per una determinata chiave tramite una libreria chiamata Clerk (C per lato client). Come gli Slicelet, anche i Clerk mantengono attivamente una cache locale dell'assegnazione più recente in background per garantire prestazioni elevate per le ricerche di chiavi sul percorso critico.

Infine, Dicer Assigner è il servizio controller responsabile della generazione e della distribuzione delle assegnazioni in base ai segnali di integrità e di carico dell'applicazione. Al suo centro c'è un algoritmo di partizionamento che calcola aggiustamenti minimi attraverso suddivisioni di slice, unioni, replica/dereplica e spostamenti per mantenere le chiavi assegnate a pod integri e l'applicazione complessiva sufficientemente bilanciata nel carico. Il servizio Assigner è multi-tenant e progettato per fornire un servizio di partizionamento automatico per tutte le applicazioni partizionate all'interno di una regione. Ogni applicazione partizionata servita da Dicer è definita Target.
3.2 Ampia classe di applicazioni migliorate da Dicer
Dicer è utile per un'ampia gamma di sistemi perché la capacità di associare i carichi di lavoro a pod specifici garantisce miglioramenti significativi delle prestazioni. Abbiamo identificato diverse categorie principali di casi d'uso in base alla nostra esperienza in produzione.
Serving in-memory e su GPU
Dicer eccelle negli scenari in cui un ampio corpus di dati deve essere caricato e servito direttamente dalla memoria. Garantendo che le richieste per chiavi specifiche raggiungano sempre gli stessi pod, i servizi come i key-value store possono raggiungere una latenza inferiore al millisecondo e un throughput elevato, evitando al contempo l'overhead del recupero dei dati da uno storage remoto.
Dicer è anche molto adatto ai moderni carichi di lavoro di inferenza LLM, in cui il mantenimento dell'affinità è fondamentale. Gli esempi includono sessioni utente stateful che accumulano contesto in una cache KV per sessione, nonché implementazioni che servono un gran numero di adattatori LoRA e devono shardarli in modo efficiente su risorse GPU limitate.
Sistemi di controllo e schedulazione
Questo è uno dei casi d'uso più comuni in Databricks. Include sistemi come i gestori di clusters e i motori di orchestrazione delle query che monitorano continuamente le risorse per gestire la scalabilità, la pianificazione del compute e la multi-tenancy. Per operare in modo efficiente, questi sistemi mantengono localmente lo stato di monitoraggio e controllo, evitando la serializzazione ripetuta e consentendo risposte tempestive ai cambiamenti.
Cache remote
Dicer può essere utilizzato per creare cache remote distribuite ad alte prestazioni, cosa che abbiamo fatto in produzione presso Databricks. Utilizzando le funzionalità di Dicer, la nostra cache può essere scalata automaticamente e riavviata senza interruzioni, senza perdita di hit rate ed evitando lo sbilanciamento del carico dovuto alle hot key.
Partizionamento del lavoro e lavoro in background
Dicer è uno strumento efficace per la partizione di attività in background e flussi di lavoro asincroni su una flotta di server. Ad esempio, un servizio responsabile della pulizia o del garbage-collecting dello stato in una tabella di grandi dimensioni può utilizzare Dicer per garantire che ogni pod sia responsabile di un intervallo distinto e non sovrapposto del keyspace, evitando lavoro ridondante e contesa di lock.
Elaborazione a batch e aggregazione
Per i percorsi di scrittura a volume elevato, Dicer consente un'aggregazione efficiente dei record. Indirizzando i record correlati allo stesso pod, il sistema può batch gli aggiornamenti in memoria prima di eseguirne il commit nello storage persistente. Ciò riduce in modo significativo le operazioni di input/output al secondo richieste e migliora il throughput complessivo della pipeline di dati.
Selezione flessibile del leader
Dicer può essere utilizzato per implementare una selezione "soft" del leader designando un pod specifico come coordinatore principale per una determinata chiave o partizione. Ad esempio, uno scheduler di gestione può utilizzare Dicer per garantire che un singolo pod agisca come autorità primaria per la gestione di un gruppo di risorse. Sebbene Dicer fornisca attualmente una selezione del leader basata sull'affinità, funge da solida base per i sistemi che richiedono un primario coordinato senza il pesante overhead dei tradizionali protocolli di consenso. Stiamo esplorando miglioramenti futuri per fornire garanzie più solide sull'esclusione reciproca per questi carichi di lavoro.
Rendezvous e coordinamento
Dicer funge da punto di incontro naturale per i client distribuiti che necessitano di un coordinamento in tempo reale. Inoltrando tutte le richieste per una chiave specifica allo stesso pod, quel pod diventa un punto di incontro centrale in cui lo stato condiviso può essere gestito nella memoria locale senza hop di rete esterni.
Ad esempio, in un servizio di chat in tempo reale, due client che si uniscono alla stessa "Chat Room ID" vengono automaticamente instradati allo stesso pod. Ciò consente al pod di sincronizzare i loro messaggi e il loro stato istantaneamente in memoria, evitando la latenza di un database condiviso o di un back-plane complesso per la comunicazione.
4. Casi di successo
Numerosi servizi di Databricks hanno ottenuto vantaggi significativi con Dicer e di seguito evidenziamo alcune di queste storie di successo.
4.1 Unity Catalog
Unity Catalog (UC) è la soluzione di governance unificata per i dati e gli asset di IA sulla piattaforma Databricks. Progettato originariamente come servizio stateless, UC ha dovuto affrontare notevoli difficoltà di scalabilità con l'aumento della sua popolarità, a causa principalmente di un volume di lettura estremamente elevato. L'elaborazione di ogni richiesta richiedeva un accesso ripetuto al database di backend, introducendo una latenza proibitiva. Gli approcci convenzionali, come la memorizzazione nella cache remota (remote caching), non erano praticabili, poiché la cache doveva essere aggiornata in modo incrementale e rimanere "snapshot consistent" con lo storage. Inoltre, i cataloghi dei clienti possono avere dimensioni di gigabyte, il che rende costoso mantenere snapshot parziali o replicati in una cache remota senza introdurre un overhead sostanziale.
Per risolvere questo problema, il team ha integrato Dicer per creare una cache stateful in-memory partizionata. Questo cambiamento ha permesso a UC di sostituire costose chiamate di rete remote con chiamate a metodi locali, riducendo drasticamente il carico del database e migliorando la reattività. La figura seguente illustra il rollout iniziale di Dicer, seguito dal deployment dell'integrazione completa di Dicer. Sfruttando l'affinità stateful di Dicer, UC ha raggiunto un hit rate della cache del 90-95%, riducendo in modo significativo la frequenza dei round-trip del database.

{kind=link}
4.2 Motore di orchestrazione di query SQL
Il motore di orchestrazione delle query di Databricks, che gestisce la pianificazione delle query sui cluster Spark, era stato originariamente creato come un servizio stateful in-memory utilizzando il partizionamento statico. Con la scalabilità del servizio, i limiti di questa architettura sono diventati un notevole collo di bottiglia; a causa della semplice implementazione, la scalabilità richiedeva un ripartizionamento manuale, operazione estremamente laboriosa, e il sistema ha subito frequenti cali di disponibilità, anche durante i riavvii continui.
Dopo l'integrazione con Dicer, questi problemi di disponibilità sono stati eliminati (vedi Figura 4). Dicer ha azzerato i tempi di inattività durante i riavvii e gli eventi di scalabilità, consentendo al team di ridurre il lavoro ripetitivo e migliorare la robustezza del sistema abilitando la scalabilità automatica ovunque. Inoltre, la funzionalità di bilanciamento del carico dinamico di Dicer ha ulteriormente risolto il throttling cronico della CPU, garantendo prestazioni più costanti su tutta la flotta.
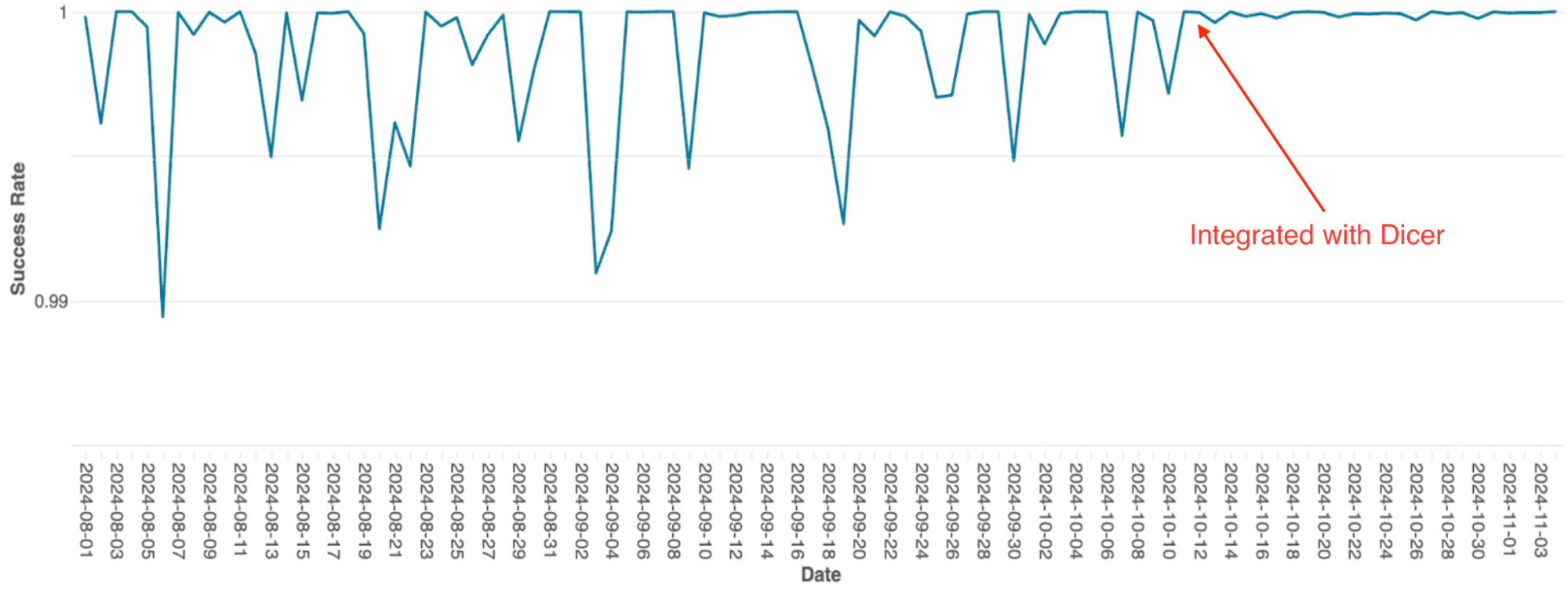
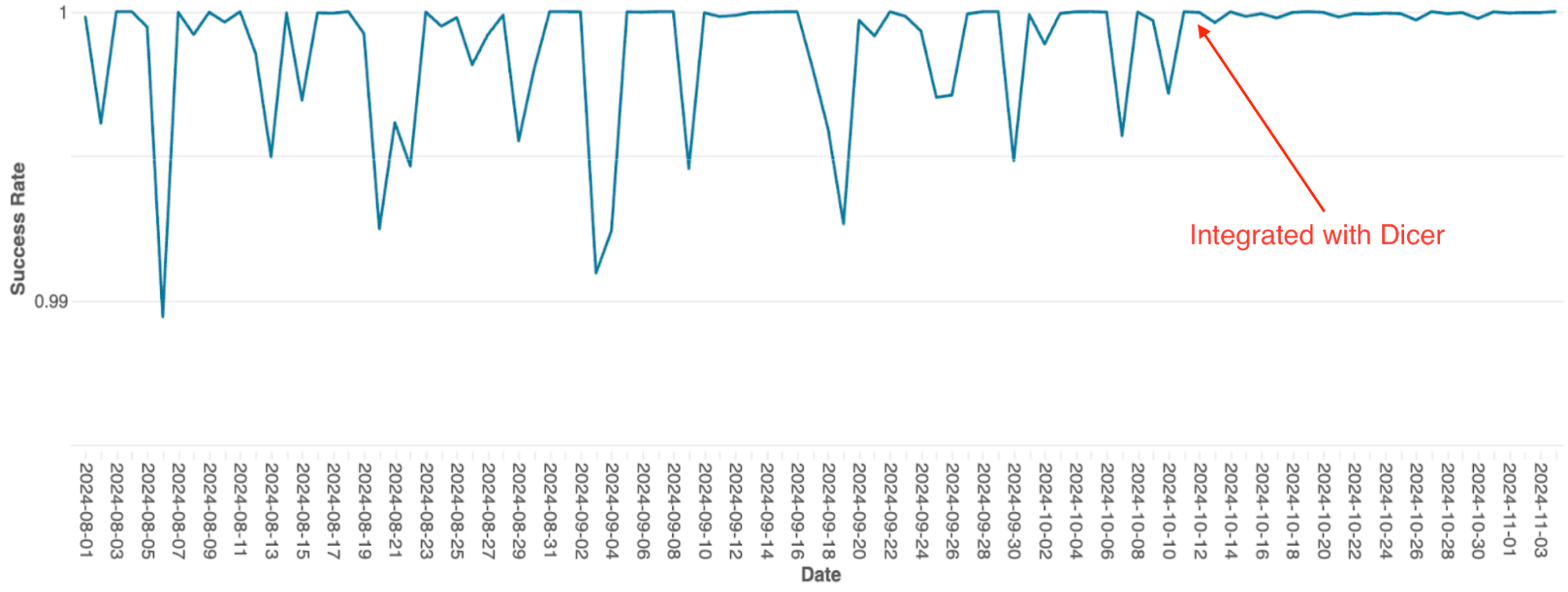{kind=link}
4.3 Cache remota Softstore
Per i servizi non sottoposti a sharding, abbiamo sviluppato Softstore, una cache chiave-valore remota distribuita. Softstore sfrutta una funzionalità di Dicer chiamata trasferimento di stato, che migra i dati tra i pod durante il resharding per preservare lo stato dell'applicazione. Ciò è particolarmente importante durante i rolling restart pianificati, in cui l'intero keyspace subisce inevitabilmente un rimescolamento. Nella nostra flotta di produzione, i riavvii pianificati rappresentano circa il 99,9% di tutti i riavvii, il che rende questo meccanismo di particolare impatto e consente riavvii senza interruzioni con un impatto trascurabile sui tassi di hit della cache. La Figura 5 mostra i tassi di hit di Softstore durante un rolling restart, in cui il trasferimento di stato mantiene un tasso di hit costante di circa l'85% per un caso d'uso rappresentativo, con la variabilità rimanente dovuta alle normali fluttuazioni del carico di lavoro.
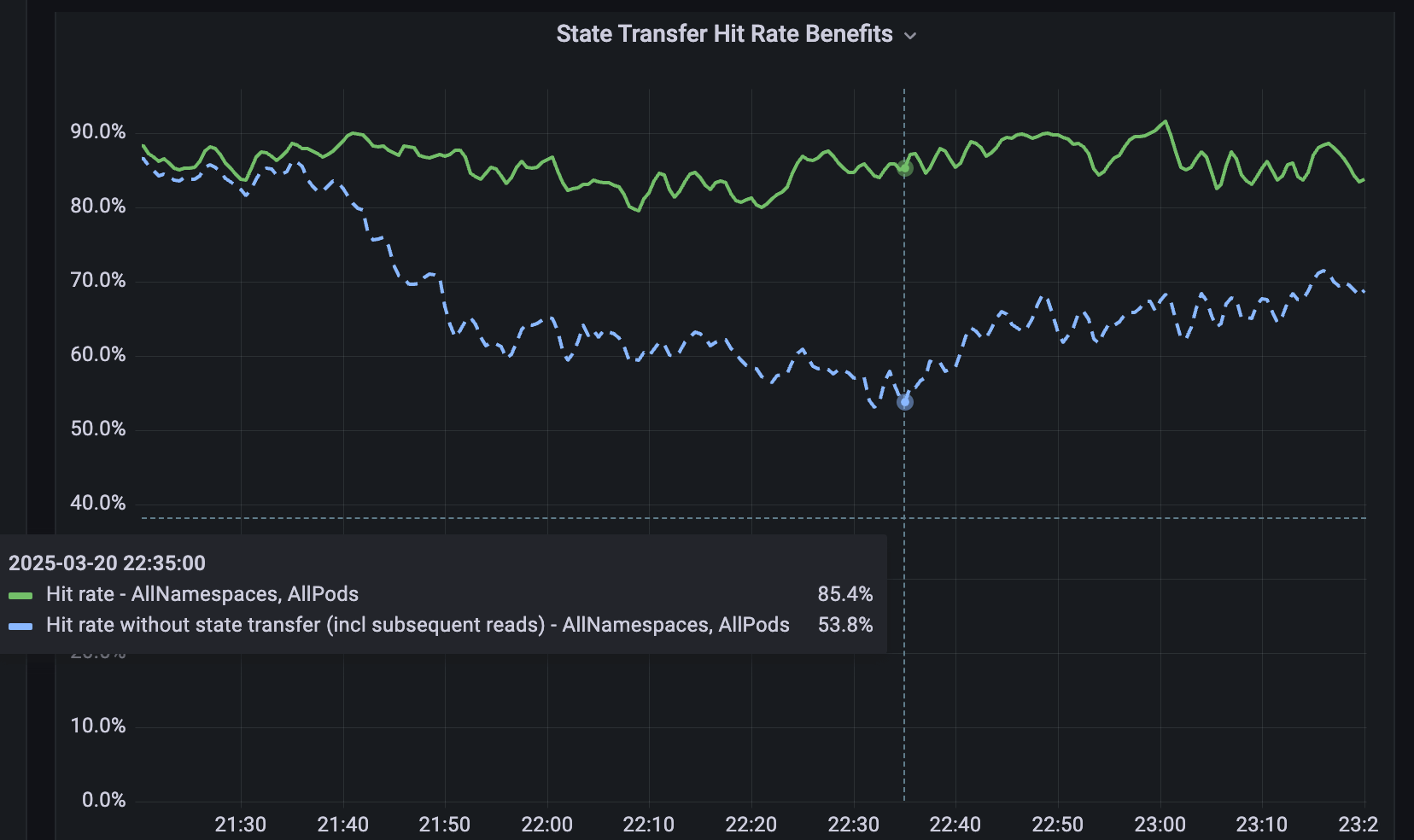
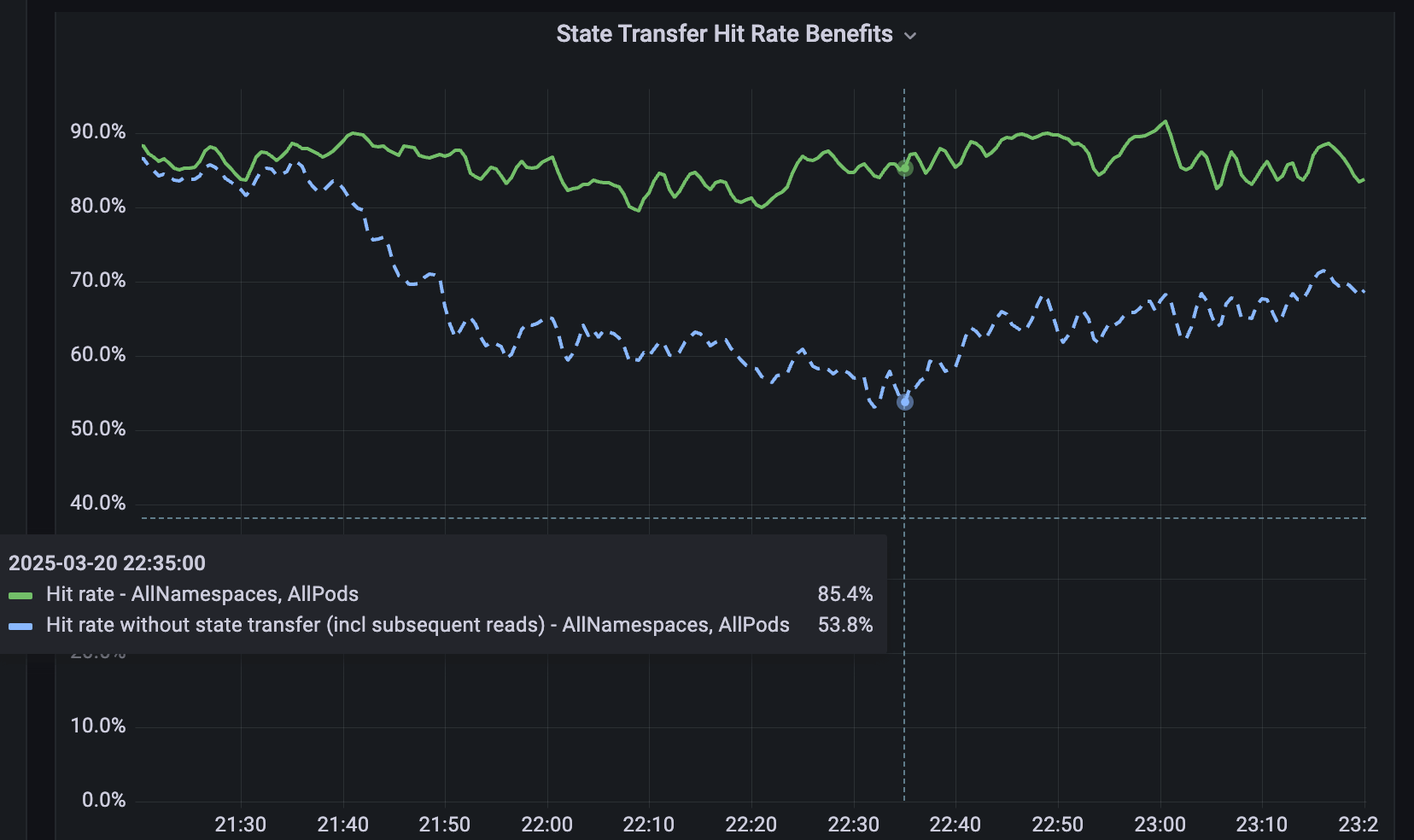{kind=link}
5. Ora puoi usarlo anche tu!
Puoi provare Dicer oggi sul tuo computer scaricandolo da qui. Una semplice demo per mostrarne l'utilizzo è disponibile qui: mostra una configurazione Dicer di esempio con un client e alcuni server per un'applicazione. Consulta il file README e la guida per l'utente di Dicer.
6. Funzionalità e articoli in arrivo
Dicer è un servizio critico utilizzato in tutta Databricks e il suo utilizzo è in rapida crescita. In futuro pubblicheremo altri articoli sul funzionamento e sulla progettazione interna di Dicer. Rilasceremo anche altre funzionalità man mano che le svilupperemo e le testeremo internamente, ad esempio librerie Java e Rust per client e server e le funzionalità di trasferimento di stato menzionate in questo post. Inviaci il tuo feedback e resta sintonizzato!
Se ti piace risolvere problemi ingegneristici complessi e vuoi unirti a Databricks, visita databricks.com/careers!
7. Riferimenti
[1] Ziming Mao, Jonathan Ellithorpe, Atul Adya, Rishabh Iyer, Matei Zaharia, Scott Shenker, Ion Stoica (2025). Ripensare il costo delle cache distribuite per i servizi di datacenter. Atti del 24° Workshop ACM su Hot Topics in Networks, 1–8.
[2] Atul Adya, Robert Grandl, Daniel Myers, Henry Qin. Fast key-value stores: An idea whose time has come and gone. Proceedings of the Workshop on Hot Topics in Operating Systems (HotOS ’19), 13–15 maggio 2019, Bertinoro, Italia. ACM, 7 pagine. DOI: 10.1145/3317550.3321434.
[3] Atul Adya, James Dunagan, Alexander Wolman. Centrifuge: Integrated Lease Management and Partitioning for Cloud Services. Atti del 7° USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2010.
[4] Atul Adya, Daniel Myers, Jon Howell, Jeremy Elson, Colin Meek, Vishesh Khemani, Stefan Fulger, Pan Gu, Lakshminath Bhuvanagiri, Jason Hunter, Roberto Peon, Larry Kai, Alexander Shraer, Arif Merchant, Kfir Lev-Ari. Slicer: Auto-Sharding for Datacenter Applications. Atti del 12° USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2016, pp. 739–753.
[5] Sangmin Lee, Zhenhua Guo, Omer Sunercan, Jun Ying, Chunqiang Tang, et al. Shard Manager: A Generic Shard Management Framework for Geo distributed Applications. Atti del 28° Simposio ACM SIGOPS sui principi dei sistemi operativi (SOSP), 2021. DOI: 10.1145/3477132.3483546.
[6] Atul Adya, Jonathan Ellithorpe. Servizi stateful: bassa latenza, efficienza, scalabilità — scegline tre. High Performance Transaction Systems Workshop (HPTS) 2024, Pacific Grove, California, 15-18 settembre 2024.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.