Introduzione alle Pandas UDF per PySpark
Come eseguire il tuo codice Python nativo con PySpark, velocemente.
di Li Jin
Free Edition ha sostituito Community Edition, offrendo funzionalità avanzate senza costi. Inizia a usare Free Edition oggi stesso.
NOTA: Spark 3.0 ha introdotto un nuovo pandas UDF. Puoi trovare maggiori dettagli nel seguente post del blog: Nuovi Pandas UDF e suggerimenti di tipo Python nella prossima release di Apache Spark 3.0
Questo è un post della community ospitato da Li Jin, un ingegnere del software presso Two Sigma Investments, LP a New York. Questo blog è pubblicato anche su Two Sigma
Prova questo notebook in Databricks
AGGIORNAMENTO: Questo blog è stato aggiornato il 22 febbraio 2018 per includere alcune modifiche.
Questo post del blog introduce la funzionalità Pandas UDF (nota anche come Vectorized UDF) nella prossima release di Apache Spark 2.3, che migliora sostanzialmente le prestazioni e l'usabilità delle funzioni definite dall'utente (UDF) in Python.
Negli ultimi anni, Python è diventato il linguaggio predefinito per i data scientist. Pacchetti come pandas, numpy, statsmodel e scikit-learn hanno ottenuto una grande adozione e sono diventati i toolkit mainstream. Allo stesso tempo, Apache Spark è diventato lo standard de facto nell'elaborazione di big data. Per consentire ai data scientist di sfruttare il valore dei big data, Spark ha aggiunto un'API Python nella versione 0.7, con supporto per le funzioni definite dall'utente. Queste funzioni definite dall'utente operano una riga alla volta e quindi soffrono di un elevato overhead di serializzazione e invocazione. Di conseguenza, molte pipeline di dati definiscono UDF in Java e Scala e poi le invocano da Python.
I Pandas UDF basati su Apache Arrow ti offrono il meglio di entrambi i mondi: la capacità di definire UDF a basso overhead e ad alte prestazioni interamente in Python.
In Spark 2.3, ci saranno due tipi di Pandas UDF: scalare e grouped map. Successivamente, illustreremo il loro utilizzo con quattro esempi di programmi: Plus One, Cumulative Probability, Subtract Mean, Ordinary Least Squares Linear Regression.
Scalari Pandas UDF
Gli scalari Pandas UDF vengono utilizzati per vettorizzare operazioni scalari. Per definire uno scalare Pandas UDF, è sufficiente utilizzare @pandas_udf per annotare una funzione Python che accetta pandas.Series come argomenti e restituisce un altro pandas.Series della stessa dimensione. Di seguito illustriamo con due esempi: Plus One e Cumulative Probability.
Plus One
Calcolare v + 1 è un semplice esempio per dimostrare le differenze tra UDF riga per riga e scalari Pandas UDF. Si noti che gli operatori di colonna integrati possono fornire prestazioni molto più elevate in questo scenario.
Utilizzo di UDF riga per riga:
Utilizzo di Pandas UDF:
Gli esempi sopra definiscono un UDF riga per riga "plus_one" e uno scalare Pandas UDF "pandas_plus_one" che esegue la stessa computazione "plus one". Le definizioni degli UDF sono le stesse tranne i decoratori della funzione: "udf" vs "pandas_udf".
Nella versione riga per riga, la funzione definita dall'utente accetta un double "v" e restituisce il risultato di "v + 1" come double. Nella versione Pandas, la funzione definita dall'utente accetta un pandas.Series "v" e restituisce il risultato di "v + 1" come pandas.Series. Poiché "v + 1" è vettorizzato su pandas.Series, la versione Pandas è molto più veloce della versione riga per riga.
Si noti che ci sono due requisiti importanti quando si utilizzano scalari Pandas UDF:
- Le serie di input e output devono avere la stessa dimensione.
- Come una colonna viene suddivisa in più
pandas.Seriesè interno a Spark e, pertanto, il risultato della funzione definita dall'utente deve essere indipendente dalla suddivisione.
Cumulative Probability
Questo esempio mostra un uso più pratico dello scalare Pandas UDF: il calcolo della probabilità cumulativa di un valore in una distribuzione normale N(0,1) utilizzando il pacchetto scipy.
stats.norm.cdf funziona sia su un valore scalare che su pandas.Series, e questo esempio può essere scritto anche con gli UDF riga per riga. Similmente all'esempio precedente, la versione Pandas viene eseguita molto più velocemente, come mostrato più avanti nella sezione "Confronto delle prestazioni".
Grouped Map Pandas UDFs
Gli utenti Python hanno una buona familiarità con il pattern split-apply-combine nell'analisi dei dati. I Grouped map Pandas UDF sono progettati per questo scenario e operano su tutti i dati di un gruppo, ad esempio "per ogni data, applica questa operazione".
I Grouped map Pandas UDF prima suddividono uno Spark DataFrame in gruppi in base alle condizioni specificate nell'operatore groupby, applicano una funzione definita dall'utente (pandas.DataFrame -> pandas.DataFrame) a ciascun gruppo, combinano e restituiscono i risultati come un nuovo Spark DataFrame.
I Grouped map Pandas UDF utilizzano lo stesso decoratore di funzione pandas_udf degli scalari Pandas UDF, ma presentano alcune differenze:
- Input della funzione definita dall'utente:
- Scalare:
pandas.Series - Grouped map:
pandas.DataFrame
- Scalare:
- Output della funzione definita dall'utente:
- Scalare:
pandas.Series - Grouped map:
pandas.DataFrame
- Scalare:
- Semantica di raggruppamento:
- Scalare: nessuna semantica di raggruppamento
- Grouped map: definita dalla clausola "groupby"
- Dimensione dell'output:
- Scalare: uguale alla dimensione dell'input
- Grouped map: qualsiasi dimensione
- Tipi di ritorno nel decoratore della funzione:
- Scalare: un
DataTypeche specifica il tipo delpandas.Seriesrestituito - Grouped map: un
StructTypeche specifica il nome e il tipo di ogni colonna delpandas.DataFramerestituito
- Scalare: un
Successivamente, esamineremo due esempi per illustrare i casi d'uso dei Grouped map Pandas UDF.
Subtract Mean
Questo esempio mostra un semplice utilizzo dei Grouped map Pandas UDF: sottrarre la media da ogni valore nel gruppo.
In questo esempio, sottraiamo la media di v da ogni valore di v per ogni gruppo. La semantica di raggruppamento è definita dalla funzione "groupby", cioè ogni pandas.DataFrame di input alla funzione definita dall'utente ha lo stesso valore "id". Lo schema di input e output di questa funzione definita dall'utente sono gli stessi, quindi passiamo "df.schema" al decoratore pandas_udf per specificare lo schema.
I Grouped map Pandas UDF possono anche essere chiamati come funzioni Python standalone sul driver. Questo è molto utile per il debug, ad esempio:
Nell'esempio precedente, prima convertiamo un piccolo sottoinsieme di Spark DataFrame in un pandas.DataFrame, e poi eseguiamo subtract_mean come funzione Python standalone su di esso. Dopo aver verificato la logica della funzione, possiamo chiamare l'UDF con Spark sull'intero set di dati.
Ordinary Least Squares Linear Regression
L'ultimo esempio mostra come eseguire la regressione lineare OLS per ogni gruppo utilizzando statsmodels. Per ogni gruppo, calcoliamo beta b = (b1, b2) per X = (x1, x2) secondo il modello statistico Y = bX + c.
Questo esempio dimostra che le Pandas UDF di tipo grouped map possono essere utilizzate con qualsiasi funzione Python arbitraria: pandas.DataFrame -> pandas.DataFrame. La pandas.DataFrame restituita può avere un numero di righe e colonne diverso dall'input.
Confronto delle prestazioni
Infine, vogliamo mostrare un confronto delle prestazioni tra UDF riga per riga e Pandas UDF. Abbiamo eseguito micro benchmark per tre degli esempi sopra (più uno, probabilità cumulativa e sottrazione della media).
Configurazione e metodologia
Abbiamo eseguito il benchmark su un cluster Spark a nodo singolo su Databricks Community Edition.
Dettagli di configurazione:
Dati: Un DataFrame da 10 milioni di righe con una colonna Int e una colonna Double
Cluster: 6.0 GB di memoria, 0.88 Core, 1 DBU
Databricks runtime versione: Ultima RC (4.0, Scala 2.11)
Per l'implementazione dettagliata del benchmark, consulta il Notebook Pandas UDF.
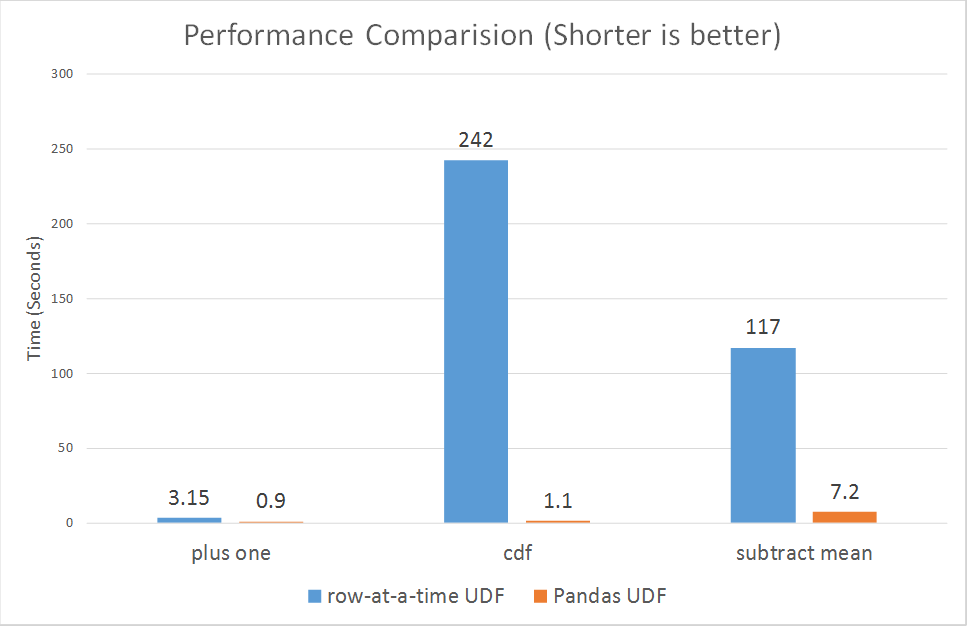
Come mostrato nei grafici, le Pandas UDF offrono prestazioni molto migliori rispetto alle UDF riga per riga, con un intervallo dal 3x a oltre 100x.
Conclusione e lavori futuri
L'imminente rilascio di Spark 2.3 pone le basi per migliorare sostanzialmente le capacità e le prestazioni delle funzioni definite dall'utente in Python. In futuro, prevediamo di introdurre il supporto per le Pandas UDF nelle aggregazioni e nelle funzioni finestra. I lavori correlati possono essere tracciati in SPARK-22216.
Le Pandas UDF sono un ottimo esempio dello sforzo della community di Spark. Vorremmo ringraziare Bryan Cutler, Hyukjin Kwon, Jeff Reback, Liang-Chi Hsieh, Leif Walsh, Li Jin, Reynold Xin, Takuya Ueshin, Wenchen Fan, Wes McKinney, Xiao Li e molti altri per i loro contributi. Infine, un ringraziamento speciale alla community di Apache Arrow per aver reso possibile questo lavoro.
Prossimi passi
Puoi provare il notebook Pandas UDF e questa funzionalità è ora disponibile come parte di Databricks Runtime 4.0 beta.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.