Elaborazione di dati geospaziali su larga scala con Databricks
di Nima Razavi e Michael Johns
Questo blog è obsoleto. Si prega di fare riferimento a questo blog su Spatial SQL per approcci aggiornati all'archiviazione ed elaborazione dei dati geospaziali all'interno del tuo Databricks Lakehouse.
L'evoluzione e la convergenza della tecnologia hanno alimentato un mercato vivace per dati geospaziali tempestivi e accurati. Ogni giorno miliardi di dispositivi portatili e IoT, insieme a migliaia di piattaforme di telerilevamento aereo e satellitare, generano centinaia di exabyte di dati basati sulla posizione. Questo boom dei big data geospaziali, combinato con i progressi nel machine learning, sta consentendo alle organizzazioni di tutti i settori di creare nuovi prodotti e capacità.
Ad esempio, numerose aziende forniscono servizi localizzati basati su droni come mappatura e ispezione di siti (fare riferimento a Sviluppo per il Cloud Intelligente e l'Edge Intelligente). Un altro settore in rapida crescita per i dati geospaziali sono i veicoli autonomi. Startup e aziende consolidate stanno accumulando grandi corpus di geodati altamente contestualizzati dai sensori dei veicoli per offrire la prossima innovazione nelle auto a guida autonoma (fare riferimento a Databricks alimenta l'ambizione di wejo di creare un ecosistema di dati per la mobilità). Anche i rivenditori e le agenzie governative stanno cercando di utilizzare i propri dati geospaziali. Ad esempio, l'analisi del traffico pedonale (fare riferimento a Creazione di un dataset di insight sul traffico pedonale) può aiutare a determinare la posizione migliore per aprire un nuovo negozio o, nel Settore Pubblico, migliorare la pianificazione urbana. Nonostante tutti questi investimenti nei dati geospaziali, esistono diverse sfide.
Sfide nell'Analisi Geospaziale su Larga Scala
La prima sfida riguarda la gestione della scala nelle applicazioni di streaming e batch. La pura proliferazione di dati geospaziali e gli SLA richiesti dalle applicazioni sovraccaricano i sistemi tradizionali di archiviazione ed elaborazione. I dati dei clienti sono fuoriusciti dagli attuali database geo scalati verticalmente nei data lake per molti anni a causa di pressioni come il volume dei dati, la velocità, il costo di archiviazione e l'applicazione rigorosa dello schema in fase di scrittura. Mentre le imprese hanno investito in dati geospaziali, poche hanno l'architettura tecnologica adeguata per preparare questi dataset grandi e complessi per l'analisi downstream. Inoltre, dato che i dati scalati sono spesso richiesti per casi d'uso avanzati, la maggior parte delle iniziative guidate dall'AI non riesce a passare dal pilota alla produzione.
La compatibilità con vari formati spaziali rappresenta la seconda sfida. Esistono molti diversi formati geospaziali specializzati stabiliti nel corso di molti decenni, nonché fonti di dati incidentali in cui le informazioni sulla posizione possono essere raccolte:
- Formati vettoriali come GeoJSON, KML, Shapefile e WKT
- Formati raster come ESRI Grid, GeoTIFF, JPEG 2000 e NITF
- Standard di navigazione come quelli utilizzati dai dispositivi AIS e GPS
- Geodatabase accessibili tramite connessioni JDBC / ODBC come PostgreSQL / PostGIS
- Formati di sensori remoti da piattaforme iperspettrali, multispettrali, Lidar e Radar
- Standard web OGC come WCS, WFS, WMS e WMTS
- Log geotaggati, immagini, video e social media
- Dati non strutturati con riferimenti di posizione
In questo post del blog, forniamo una panoramica degli approcci generali per affrontare le due principali sfide sopra elencate utilizzando la Databricks Unified Data Analytics Platform. Questa è la prima parte di una serie di post del blog sull'elaborazione di grandi volumi di dati geospaziali.
Scalare i Carichi di Lavoro Geospaziali con Databricks
Databricks offre una piattaforma unificata di analisi dati per analisi di big data e machine learning utilizzata da migliaia di clienti in tutto il mondo. È alimentata da Apache Spark™, Delta Lake e MLflow con un ampio ecosistema di integrazioni di librerie di terze parti e disponibili. Databricks UDAP offre sicurezza, supporto, affidabilità e prestazioni di livello enterprise su larga scala per i carichi di lavoro di produzione. I carichi di lavoro geospaziali sono tipicamente complessi e non esiste una singola libreria adatta a tutti i casi d'uso. Sebbene Apache Spark non offra nativamente tipi di dati spaziali, la community open source e le imprese hanno dedicato molti sforzi allo sviluppo di librerie spaziali, risultando in una miriade di opzioni tra cui scegliere.
Esistono generalmente tre pattern per scalare le operazioni geospaziali come join spaziali o vicini più prossimi:
- Utilizzo di librerie specializzate che estendono Apache Spark per l'analisi geospaziale. GeoSpark, GeoMesa, GeoTrellis e Rasterframes sono alcune di queste librerie utilizzate dai nostri clienti. Questi framework offrono spesso binding multilingua, hanno una scalabilità e prestazioni molto migliori rispetto agli approcci non formalizzati, ma possono anche comportare una curva di apprendimento.
- Integrazione di librerie a nodo singolo come GeoPandas, Geospatial Data Abstraction Library (GDAL) o Java Topology Service (JTS) in funzioni definite dall'utente (UDF) ad hoc per l'elaborazione in modo distribuito con Spark DataFrames. Questo è l'approccio più semplice per scalare i carichi di lavoro esistenti senza molte riscritture di codice; tuttavia, può introdurre svantaggi in termini di prestazioni poiché è più di tipo "lift-and-shift".
- Indicizzazione dei dati con sistemi a griglia e sfruttamento dell'indice generato per eseguire operazioni spaziali è un approccio comune per gestire carichi di lavoro su larga scala o computazionalmente ristretti. S2, GeoHex e H3 di Uber sono esempi di tali sistemi a griglia. Le griglie approssimano caratteristiche geografiche come poligoni o punti con un insieme fisso di celle identificabili, evitando così operazioni geospaziali costose e offrendo quindi un comportamento di scalabilità molto migliore. Gli implementatori possono scegliere tra griglie fisse a singola accuratezza, che possono essere un po' imprecise ma più performanti, o griglie con accuratezze multiple, che possono essere meno performanti ma mitigano l'imprecisione.
Gli esempi che seguono sono generalmente orientati verso un dataset di prelievo/rilascio taxi di NYC trovato qui. Verranno utilizzati anche dati delle zone taxi di NYC con geometrie come insieme di poligoni. Questo notebook ti guiderà attraverso le preparazioni e le pulizie effettuate per convertire i file CSV iniziali in Tabelle Delta Lake come fonte dati affidabile e performante.
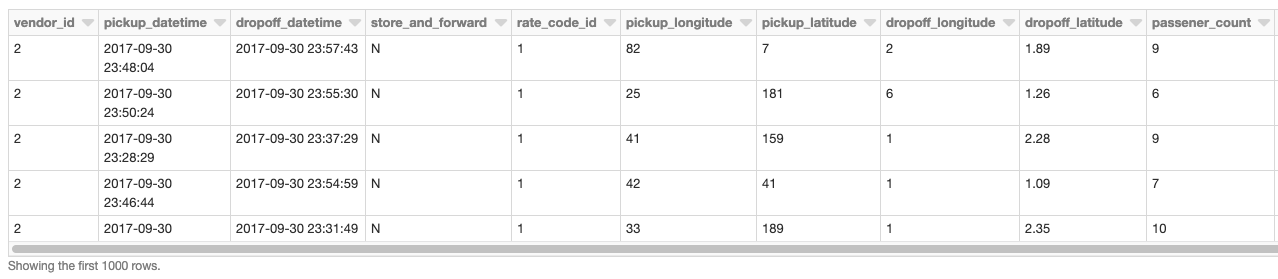
Il nostro DataFrame di base sono i dati di prelievo/rilascio taxi letti da una Tabella Delta Lake utilizzando Databricks.
Operazioni Geospaziali con Librerie Geospaziali per Apache Spark
Negli ultimi anni sono state sviluppate diverse librerie per estendere le capacità di Apache Spark per l'analisi geospaziale. Questi framework si occupano di registrare tipi definiti dall'utente (UDT) e funzioni (UDF) comunemente applicati in modo coerente, alleggerendo il carico che altrimenti graverebbe su utenti e team per scrivere logiche spaziali ad hoc. Si noti che in questo post del blog utilizziamo diversi framework spaziali scelti per evidenziare varie capacità. Comprendiamo che esistono altri framework oltre a quelli evidenziati che potresti voler utilizzare anche con Databricks per elaborare i tuoi carichi di lavoro spaziali.
In precedenza, abbiamo caricato i nostri dati di base in un DataFrame. Ora dobbiamo trasformare gli attributi di latitudine/longitudine in geometrie puntuali. Per fare ciò, useremo le UDF per eseguire operazioni sui DataFrame in modo distribuito. Fare riferimento ai notebook forniti alla fine del blog per i dettagli sull'aggiunta di questi framework a un cluster e alle chiamate di inizializzazione per registrare UDF e UDT. Per cominciare, abbiamo aggiunto GeoMesa al nostro cluster, un framework particolarmente abile nella gestione dei dati vettoriali. Per l'ingestione, stiamo principalmente sfruttando la sua integrazione di JTS con Spark SQL che ci consente di convertire e utilizzare facilmente le classi JTS geometry registrate. Utilizzeremo la funzione st_makePoint che, data una latitudine e una longitudine, crea un oggetto geometria Point. Poiché la funzione è una UDF, possiamo applicarla direttamente alle colonne.
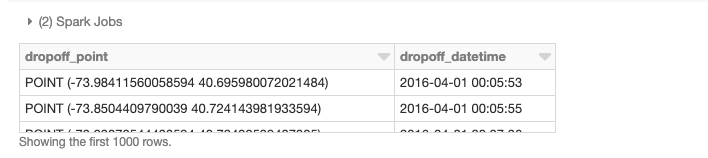
Possiamo anche eseguire join spaziali distribuiti, in questo caso utilizzando la UDF st_contains fornita da GeoMesa per produrre il join risultante di tutti i poligoni rispetto ai punti di prelievo.
Involucro di Librerie Single-Node in UDF
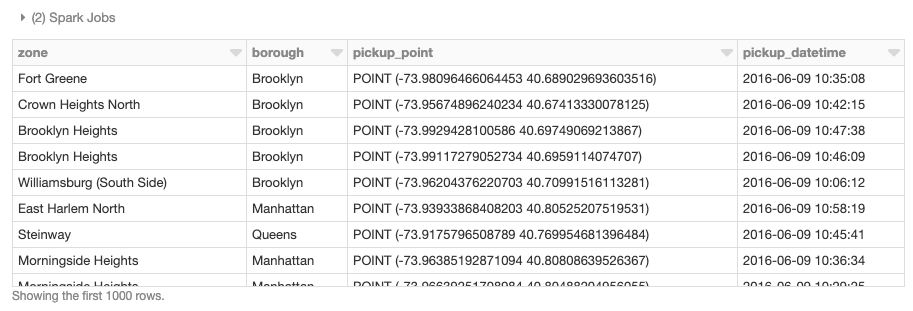
Oltre all'utilizzo di framework spaziali distribuiti appositamente progettati, le librerie single-node esistenti possono anche essere avvolte in UDF ad hoc per eseguire operazioni geospaziali sui DataFrame in modo distribuito. Questo pattern è disponibile per tutti i binding linguistici di Spark – Scala, Java, Python, R e SQL – ed è un approccio semplice per sfruttare i carichi di lavoro esistenti con modifiche minime al codice. Per dimostrare un esempio single-node, carichiamo i dati dei borough di New York e definiamo la UDF find_borough(...) per l'operazione point-in-polygon per assegnare ogni posizione GPS a un borough utilizzando geopandas. Ciò avrebbe potuto essere realizzato anche con una UDF vettorizzata per prestazioni ancora migliori.
Ora possiamo applicare la UDF per aggiungere una colonna al nostro Spark DataFrame che assegna un nome di borough a ogni punto di prelievo.
Sistemi a Griglia per l'Indicizzazione Spaziale
Le operazioni geospaziali sono intrinsecamente computazionalmente costose. Point-in-polygon, join spaziali, vicini più prossimi o aggancio a percorsi comportano tutti operazioni complesse. Indicizzando con sistemi a griglia, l'obiettivo è evitare del tutto le operazioni geospaziali. Questo approccio porta alle implementazioni più scalabili con l'avvertenza di operazioni approssimative. Ecco un breve esempio con H3.
Scalare le operazioni spaziali con H3 è essenzialmente un processo in due fasi. La prima fase consiste nel calcolare un indice H3 per ogni feature (punti, poligoni, …) definita come UDF geoToH3(...). La seconda fase consiste nell'utilizzare questi indici per operazioni spaziali come il join spaziale (point in polygon, k-nearest neighbors, ecc.), in questo caso definito come UDF multiPolygonToH3(...).
Ora possiamo applicare queste due UDF ai dati dei taxi di New York, nonché all'insieme di poligoni dei borough per generare l'indice H3.
Dato un insieme di punti lat/lon e un insieme di geometrie poligonali, è ora possibile eseguire il join spaziale utilizzando il campo h3index come condizione di join. Queste assegnazioni possono essere utilizzate per aggregare il numero di punti che rientrano in ciascun poligono, ad esempio. Di solito ci sono milioni o miliardi di punti che devono essere abbinati a migliaia o milioni di poligoni, il che richiede un approccio scalabile. Esistono altre tecniche non trattate in questo blog che possono essere utilizzate per l'indicizzazione a supporto delle operazioni spaziali quando un'approssimazione non è sufficiente.

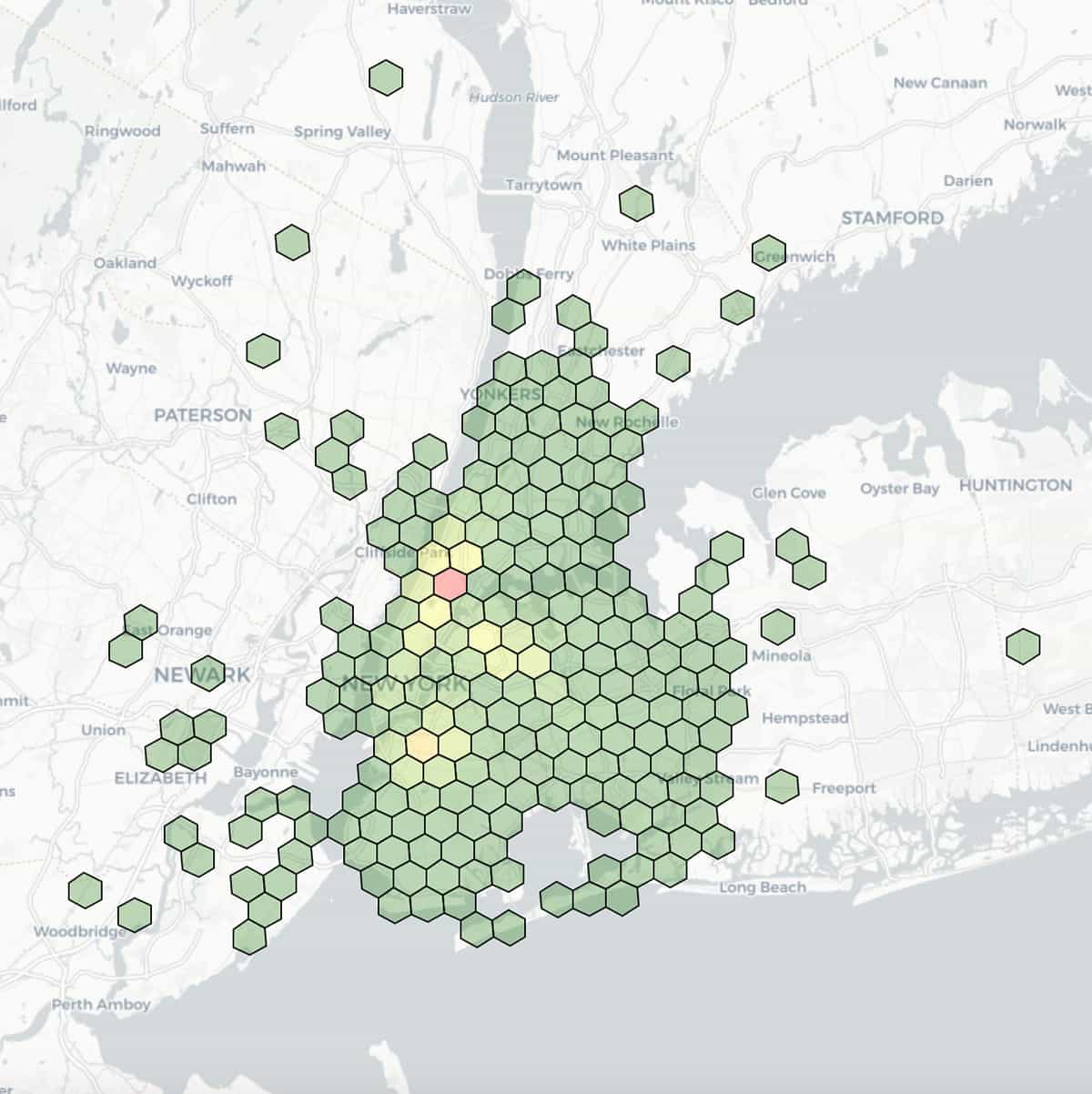
Ecco una visualizzazione delle località di discesa dei taxi, con latitudine e longitudine raggruppate in bin con una risoluzione di 7 (lunghezza del lato di 1,22 km) e colorate in base ai conteggi aggregati all'interno di ciascun bin.
Gestione dei formati spaziali con Databricks
I dati geospaziali coinvolgono punti di riferimento, come latitudine e longitudine, a località fisiche o estensioni sulla terra insieme a caratteristiche descritte da attributi. Sebbene ci siano molti formati di file tra cui scegliere, abbiamo selezionato una manciata di formati vettoriali e raster rappresentativi per dimostrare la lettura con Databricks.
Dati vettoriali
I dati vettoriali sono una rappresentazione del mondo memorizzata in coordinate x (longitudine), y (latitudine) in gradi, anche z (altitudine in metri) se si considera l'elevazione. I tre tipi di simboli di base per i dati vettoriali sono punti, linee e poligoni. Well-known-text (WKT), GeoJSON e Shapefile sono alcuni formati popolari per la memorizzazione di dati vettoriali che evidenziamo di seguito.
Leggiamo i dati NYC Taxi Zone con geometrie memorizzate come WKT. La struttura dati che vogliamo ottenere è un DataFrame che ci permetterà di standardizzare con altre API e fonti di dati disponibili, come quelle utilizzate altrove nel blog. Siamo in grado di convertire facilmente il contenuto testuale WKT trovato nel campo the_geom nella sua corrispondente classe JTS Geometry attraverso la chiamata UDF st_geomFromWKT(...).
GeoJSON è utilizzato da molti pacchetti GIS open source per codificare una varietà di strutture dati geografiche, comprese le loro caratteristiche, proprietà ed estensioni spaziali. Per questo esempio, leggeremo i confini dei quartieri di New York con l'approccio adottato a seconda del flusso di lavoro. Poiché i dati sono conformi a JSON, potremmo utilizzare il lettore JSON integrato di Databricks con .option("multiline","true") per caricare i dati con lo schema nidificato.

Da lì potremmo scegliere di sollevare uno qualsiasi dei campi a colonne di primo livello utilizzando la funzione explode integrata di Spark. Ad esempio, potremmo voler portare su geometria, proprietà e tipo e quindi convertire la geometria nella sua classe JTS corrispondente come mostrato con l'esempio WKT.

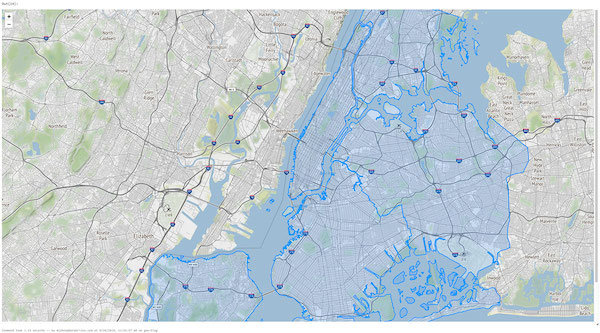
Possiamo anche visualizzare i dati NYC Taxi Zone all'interno di un notebook utilizzando un DataFrame esistente o renderizzando direttamente i dati con una libreria come Folium, una libreria Python per la visualizzazione di dati spaziali. Databricks File System (DBFS) viene eseguito su uno strato di storage distribuito che consente al codice di lavorare con formati di dati utilizzando standard familiari del file system. DBFS ha un FUSE Mount per consentire chiamate API locali che eseguono operazioni di lettura e scrittura di file, il che rende molto facile caricare dati con API non distribuite per il rendering interattivo. Nel comando Python open(...) di seguito, il prefisso "/dbfs/..." abilita l'uso di FUSE Mount.
Shapefile è un formato vettoriale popolare sviluppato da ESRI che memorizza la posizione geometrica e le informazioni sugli attributi delle caratteristiche geografiche. Il formato è costituito da una raccolta di file con un prefisso di nome file comune (*.shp, *.shx e *.dbf sono obbligatori) memorizzati nella stessa directory. Un'alternativa a shapefile è KML, utilizzato anche dai nostri clienti ma non mostrato per brevità. Per questo esempio, utilizziamo gli shapefile degli edifici di New York. Sebbene ci siano molti modi per dimostrare la lettura di shapefile, forniremo un esempio utilizzando GeoSpark. Il ShapefileReader integrato viene utilizzato per generare il DataFrame rawSpatialDf.
Registrando rawSpatialDf come vista temporanea, possiamo facilmente passare alla sintassi pura Spark SQL per lavorare con il DataFrame, inclusa l'applicazione di una UDF per convertire il WKT dello shapefile in Geometry.
Inoltre, possiamo utilizzare la visualizzazione integrata di Databricks per analisi inline come la creazione di grafici degli edifici più alti di New York.

Dati Raster
I dati raster memorizzano informazioni sulle caratteristiche in una matrice di celle (o pixel) organizzate in righe e colonne (discrete o continue). Immagini satellitari, fotogrammetria e mappe scansionate sono tutti tipi di dati di Osservazione della Terra (EO) basati su raster.
Il seguente esempio Python utilizza RasterFrames, un framework di analisi spaziale incentrato sui DataFrame, per leggere due bande di immagini Landsat-8 GeoTIFF (rosso e vicino infrarosso) e combinarle nell'Indice di Vegetazione a Differenza Normalizzata. Possiamo utilizzare questi dati per valutare la salute delle piante intorno a New York. Il modulo rf_ipython viene utilizzato per manipolare i contenuti di RasterFrame in una varietà di forme visivamente utili, come di seguito, dove le colonne di tile rosse, NIR e NDVI vengono renderizzate con rampe di colore, utilizzando il comando displayHTML(...) integrato di Databricks per mostrare i risultati all'interno del notebook.
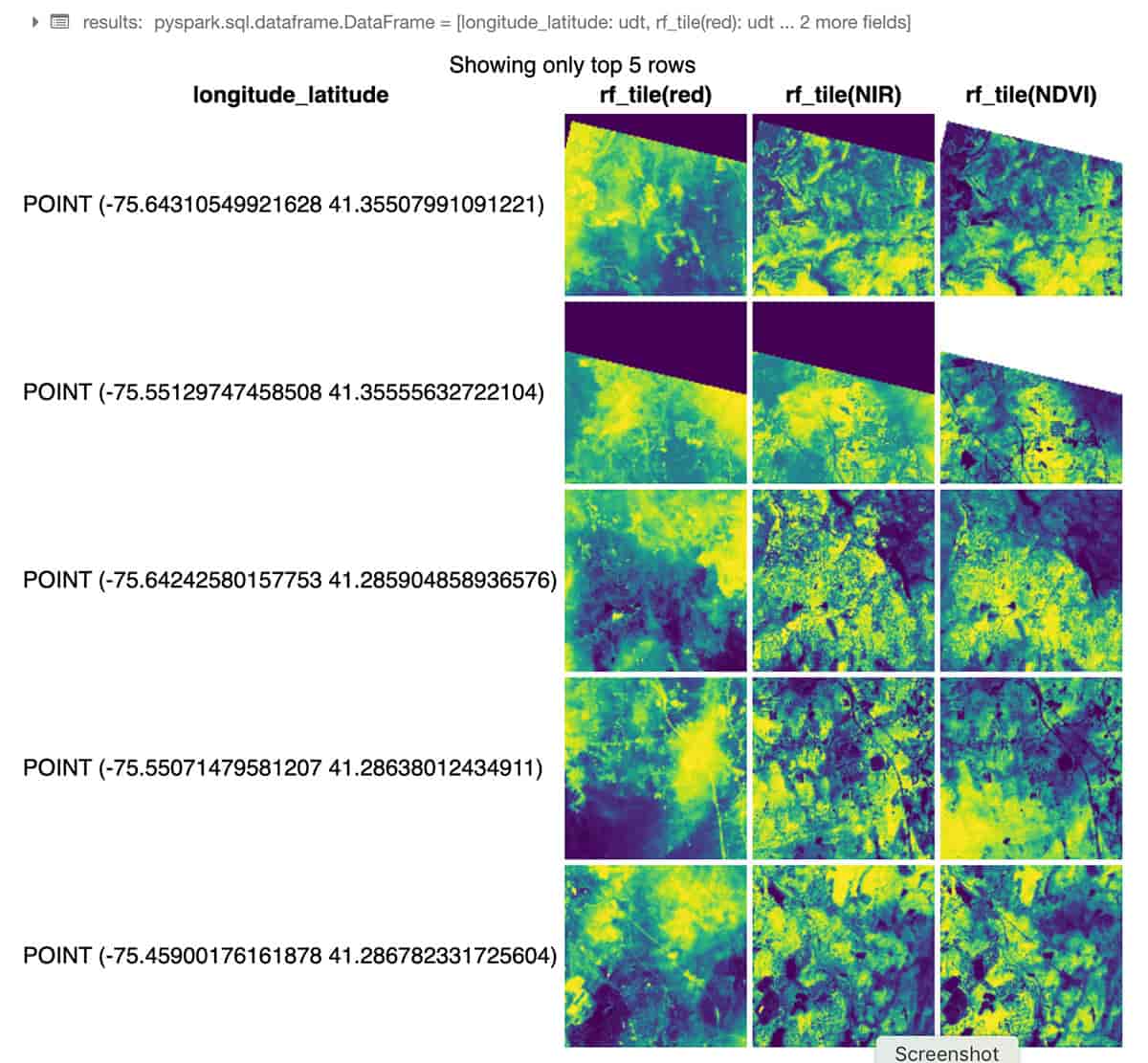
Attraverso il suo Spark DataSource personalizzato, RasterFrames può leggere vari formati raster, inclusi GeoTIFF, JP2000, MRF e HDF, da un'array di servizi. Supporta anche la lettura dei formati vettoriali GeoJSON e WKT/WKB. I contenuti di RasterFrame possono essere filtrati, trasformati, riassunti, ricampionati e rasterizzati tramite oltre 200 funzioni raster e vettoriali, come st_reproject(...) e st_centroid(...) utilizzate nell'esempio precedente. Fornisce API per Python, SQL e Scala, nonché interoperabilità con Spark ML.
GeoDatabase
I Geo database possono essere basati su file per dati su piccola scala o accessibili tramite connessioni JDBC / ODBC per dati su scala media. È possibile utilizzare Databricks per interrogare molti database SQL con il JDBC / ODBC Data Source integrato. La connessione a PostgreSQL viene mostrata di seguito, comunemente utilizzata per carichi di lavoro su piccola scala applicando estensioni PostGIS. Questo modello di connettività consente ai clienti di mantenere l'accesso esistente ai database.
Iniziare con l'Analisi Geospaziale su Databricks
Aziende ed enti governativi cercano di utilizzare dati georeferenziati insieme a fonti di dati aziendali per trarre insight azionabili e realizzare un'ampia gamma di casi d'uso innovativi. In questo blog abbiamo dimostrato come la Piattaforma di Analisi Dati Unificata Databricks possa scalare facilmente i carichi di lavoro geospaziali, consentendo ai nostri clienti di sfruttare la potenza del cloud per acquisire, archiviare e analizzare dati di dimensioni massive.
In un prossimo blog, approfondiremo argomenti più avanzati per l'elaborazione geospaziale su larga scala con Databricks. Troverai ulteriori dettagli sui formati spaziali e sui framework evidenziati esaminando il Notebook di Preparazione Dati, il Notebook GeoMesa + H3, il Notebook GeoSpark, il Notebook GeoPandas e il Notebook Rasterframes. Inoltre, rimani sintonizzato per una nuova sezione nella nostra documentazione specificamente dedicata agli argomenti geospaziali di interesse.
Prossimi Passi
- Partecipa al nostro prossimo webinar Geospatial Analytics and AI in the Public Sector per vedere una demo live che copre numerosi casi d'uso popolari
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.